scrapy的安装,scrapy创建项目
简要:

scrapy的安装
# 1)pip install scrapy -i https://pypi.douban.com/simple(国内源)

一步到位

# 2) 报错1: building 'twisted.test.raiser' extension
# error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++
# Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
# 解决1
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
# Twisted‑20.3.0‑cp37‑cp37m‑win_amd64.whl
# cp是你的python版本
# amd是你的操作系统的版本

# 下载完成之后 使用pip install twisted的路径 安装
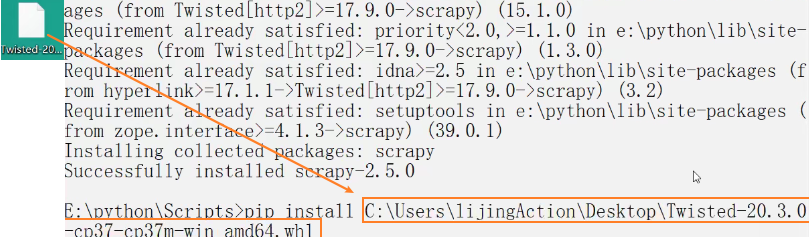
# 切记安装完twisted 再次安装scrapy
pip install scrapy -i https://pypi.douban.com/simple
# 3) 报错2:提示python -m pip install --upgrade pip
# 解决2 运行python -m pip install --upgrade pip
# 4) 报错3 win32的错误
# 解决3 pip install pypiwin32
# 5)使用 anaconda



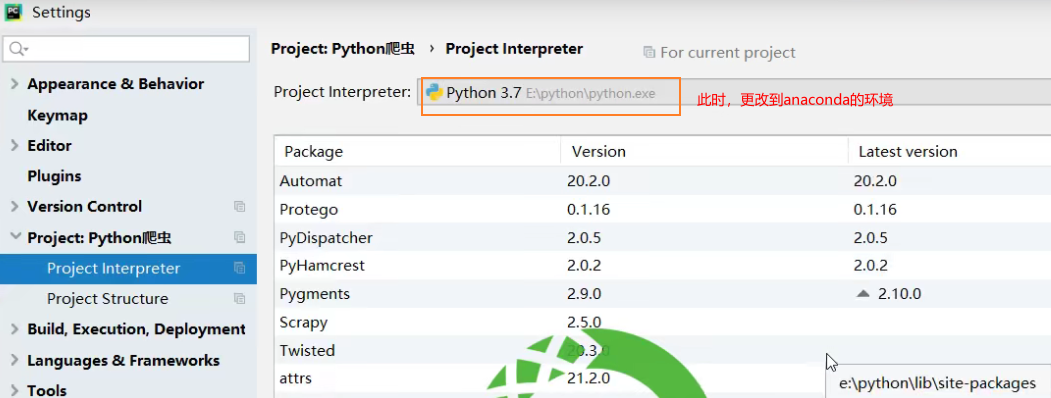

scrapy创建项目
cmd 到项目文件夹中


或者直接拖入
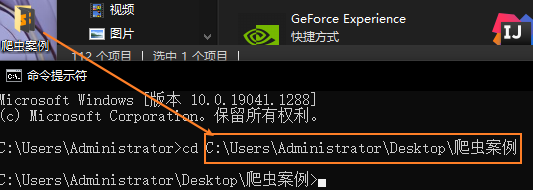
如果返回没有权限,使用管理员运行cmd
scrapy startproject scrapy_baidu
scrapy_baidu\下的文件夹


settings.py

spiders\baidu.py
import scrapy class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候 使用的值
name = 'baidu'
# 允许访问的域名
allowed_domains = ['http://www.baidu.com']
# 起始的url地址 指的是第一次要访问的域名
# start_urls 是在allowed_domains的前面添加一个http://
# 在 allowed_domains的后面添加一个/
start_urls = ['http://www.baidu.com/'] # 是执行了start_urls之后 执行的方法 方法中的response 就是返回的那个对象
# 相当于 response = urllib.request.urlopen()
# response = requests.get()
def parse(self, response):
print('你好世界')
scrapy的安装,scrapy创建项目的更多相关文章
- C++框架_之Qt的开始部分_概述_安装_创建项目_快捷键等一系列注意细节
C++框架_之Qt的开始部分_概述_安装_创建项目_快捷键等一系列注意细节 1.Qt概述 1.1 什么是Qt Qt是一个跨平台的C++图形用户界面应用程序框架.它为应用程序开发者提供建立艺术级图形界面 ...
- Django在Win7下安装与创建项目hello word示例
Django在Win7下的安装及创建项目hello word的例子 有关python 的django 框架安装与开发的小例子.Django在Win7下的安装及创建项目hello word.1.安装:命 ...
- mac下配置Node.js开发环境、express安装、创建项目
mac下配置Node.js开发环境.express安装.创建项目 一.node.js的安装 去官网下载对应的平台版本就可以了,https://nodejs.org 二.express安装 sudo n ...
- Webpack指南(一):安装,创建项目,配置文件,开发环境以及问题汇总
Webpack是一个现代 JavaScript 应用程序的静态模块打包器(module bundler).当 webpack 处理应用程序时,它会递归地构建一个依赖关系图(dependency gra ...
- vue-cli 3.0 安装和创建项目流程
使用前我们先了解下3.0较2.0有哪些区别 一.3.0 新加入了 TypeScript 以及 PWA 的支持二.部分命令发生了变化: 1.下载安装 npm install -g vue@cli 2. ...
- vue安装及创建项目的几种方式
原文地址:https://www.wjcms.net/archives/vue安装及创建项目的几种方式 VUE安装的方式 直接用 script标签 引入 对于制作原型或学习,你可以这样使用最新版本: ...
- python爬虫框架—Scrapy安装及创建项目
linux版本安装 pip3 install scrapy 安装完成 windows版本安装 pip install wheel 下载twisted,网址:http://www.lfd.uci.edu ...
- scrapy框架安装及创建
介绍:大而全的爬虫组件 使用Anaconda conda install -c conda-forge scrapy 一.安装: windows 1.下载 https://www.lfd.uci.ed ...
- Maven入门学习,安装及创建项目
一.maven介绍: 1.maven是一个基于项目对象模型(POM Project Object Model),通过配置文件管理项目的工具(项目管理工具). 2.maven主要功能:发布项目(从编译到 ...
- [Scrapy] Mac安装Scrapy
Mac安装Scrapy Mac版本 10.11 El Captain. 前一段想在Mac上用Scrapy,各种问题.有一个不错的工具:Anaconda. 安装Anaconda 下载地址 我还是下pyt ...
随机推荐
- AOJ/树与二叉搜索树习题集
ALDS1_7_A-RootedTree. Description: A graph G = (V, E) is a data structure where V is a finite set of ...
- java笔记(一直更新)
.equals()调用时,最好把equals前面放常量或者是确定有的,如果是前面是null,则会报空指针错误 也可以在调用前判断是否为null
- 容器化之路Docker网络核心知识小结,理清楚了吗?
Docker网络是容器化中最难理解的一点也是整个容器化中最容易出问题又难以排查的地方,加上使用Kubernets后大部分人即使是专业运维如果没有扎实的网络知识也很难定位容器网络问题,因此这里就容器网络 ...
- g++ 常用命令
g++ --help
- C程序内存布局
作为计算机专业的来说,程序入门基本都是从C语言开始的,了解C程序中的内存布局,对我们了解整个程序运行,分析程序出错原因,会起到事半功倍的作用 . C程序的内存布局包含五个段,分别是STACK(栈段), ...
- [Java]Sevlet
0 前言 对于Java程序员而言,Web服务器(如Tomcat)是后端开发绕不过去的坎.简单来看,浏览器发送HTTP请求给服务器,服务器处理后发送HTTP响应给浏览器. Web服务器负责对请求进行处理 ...
- JVM:Java中的引用
JVM:Java中的引用 本笔记是根据bilibili上 尚硅谷 的课程 Java大厂面试题第二季 而做的笔记 在原来的时候,我们谈到一个类的实例化 Person p = new Person() 在 ...
- Request failed with status code 500以及自引用循环Self referencing loop detected for property ‘xx‘ with type
错误Error: Request failed with status code 500 ,调试前端没问题,后端也没问题,还报错"连接超时" 在Network中找到错误Self r ...
- IDEA注释设置:从当前鼠标位置开始注释快捷键
在写xml或html注释时,经常出现注释出来的时候都是顶格的,前面包含一大段空格,并没有在鼠标位置开始. 可在设置中进行修改,其他代码格式修改方法类似
- CODING 助力江苏高速信息实现组织敏捷与研发敏捷,领跑智慧交通新基建
疫情之下的高速公路管控重任 江苏高速公路信息工程有限公司(以下简称:江苏高速信息)成立于 2002 年,是江苏交通控股旗下,专业从事高速公路领域机电系统集成.智能交通软硬件研发.大数据分析运营的高新技 ...