POI解析excel,将批量数据写入文件或数据库
.personSunflowerP { background: rgba(51, 153, 0, 0.66); border-bottom: 1px solid rgba(0, 102, 0, 1); border-top-left-radius: 7px; border-top-right-radius: 7px; color: rgba(255, 255, 255, 1); height: 1.8em; line-height: 1.8em; padding: 5px }
1.描述
采用java将excel文件中的特定数据解析出来,然后将数据写文文件或导入数据库。
常用的excel的数据有两种,一种是前几行有数据说明,另一种是全部为数据。需求可能是只要某几行或几列的数据。
如下:
第一种:前几行有数据说明,往往作为插入的字段
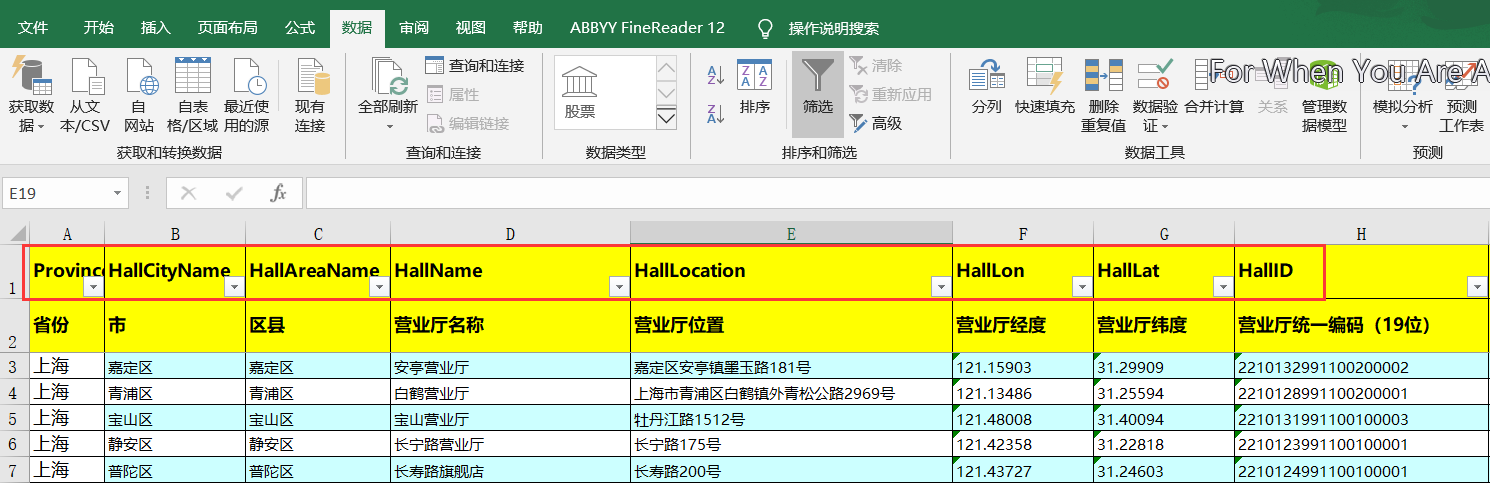
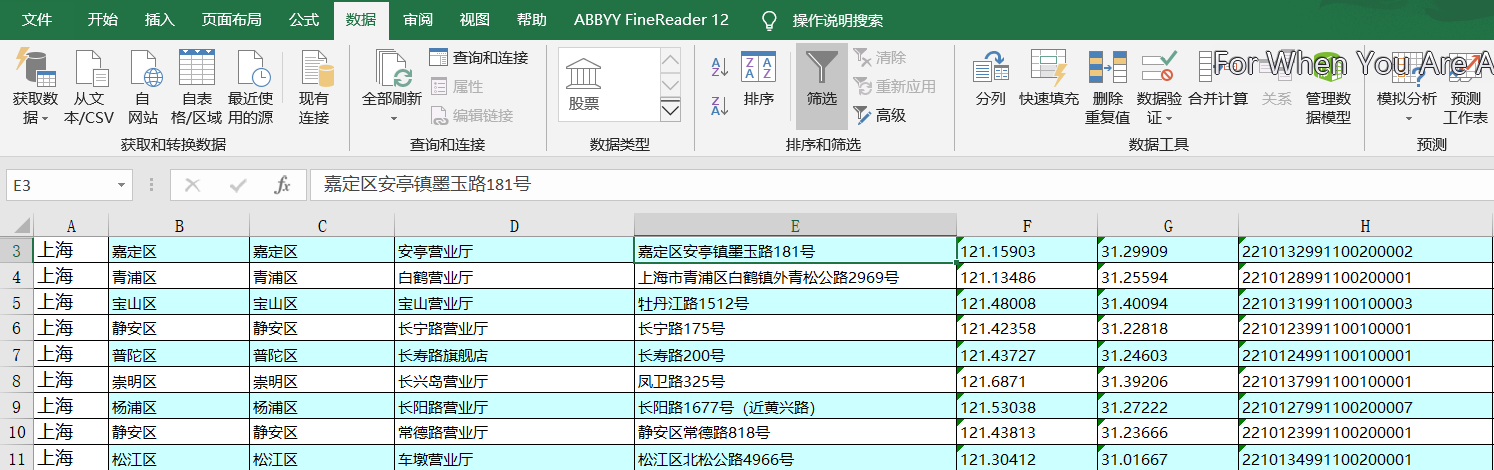
第二种:全部为数据
2.引入依赖jar包配置
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.17</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.17</version>
</dependency>
一个excel从程序层面来说,主要有四个属性,Workbook(工作表),Sheet(表单),Row(行), Cell(单元格)。思路是获取工作表,工作表只有一个,但Sheet表单往往可能存在多个,可循环获取表单;然后对每个表单的行进行解析,再解析每行的单元格;单元格中的内容又可分为多种:日期、数字、字符串、boolean类型值、公式、空值、非法字符等,都需要单独处理。
首先初始Workbook,获取该对象,通过该对象循环获取Sheet表单对象,若Sheet只有一页,直接通过workbook.getSheetAt(0);获取。或者通过Sheet的名称获取:workbook.getSheet(“营业厅信息”);获得Sheet对象后,通过sheet.getRow(rowNum);获取行的对象,拿到行的对象后,通过row.getCell(i)获取该行的某个单元格的对象,通过单元格的对象获取内容。
解析出来的数据可以写入txt文件,写成sql、csv等格式的数据,或者写入数据库。
3.下面是代码实现:
ParseExcelPubUtils.java
package cn.hxc.myExecel; import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map; import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.CellType;
import org.apache.poi.ss.usermodel.DateUtil;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook; /**
* @Description 按照Workbook,Sheet,Row,Cell一层一层往下读取。
* @author sun_flower
* 2020年2月28日 下午2:42:28
*/
public class ParseExcelPubUtils { /**
* 判断sheet是否为空
* @param sheet
* @return
* 2020年2月28日 下午4:50:22
*/
public static boolean isSheetEmpty(Sheet sheet) {
if(sheet.getLastRowNum() == 0 && sheet.getPhysicalNumberOfRows() == 0) {//sheet.getPhysicalNumberOfRows():返回物理定义的行数
System.err.println("该sheet为空,一行数据也没有");
return true;
}
return false;
} /**
* 解析Excel的单元格的内容
* @param cell 单元格
* @return
* 2020年2月28日 下午3:01:20
*/
public static String parseCell(Cell cell) {
CellType cellType = cell.getCellTypeEnum();
switch (cellType) {
case STRING:// 字符串
return cell.getStringCellValue();
case NUMERIC: // 数字、日期 数字类型 先将其cell格式设置成String读取,避免将数字1变成1.0的情况
if (DateUtil.isCellDateFormatted(cell)) {
SimpleDateFormat fmt = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
return fmt.format(cell.getDateCellValue()); // 日期型
} else {
//cell.setCellType(CellType.STRING); //读取数字:cell.getNumericCellValue()
//String cellValue = String.valueOf(cell.getStringCellValue());
double numericCellValue = cell.getNumericCellValue();
String cellValue = String.valueOf(numericCellValue);
if (cellValue.contains("E")) {
return String.valueOf(new Double(cell.getNumericCellValue()).longValue()); // 数字
}
if(cellValue.endsWith(".0")) {
cellValue = cellValue.substring(0, cellValue.length() - 2);
}
return cellValue;
}
case BOOLEAN:// Boolean
return String.valueOf(cell.getBooleanCellValue());
case FORMULA: //公式
return cell.getCellFormula();
case BLANK: // 空值
return "";
case ERROR:// 故障
return String.valueOf("非法字符:" + cell.getErrorCellValue());
default:
return "未知类型";
}
}
/**
* 默认获取第1个的Sheet
* @param workbook
* @param sheetName sheet的名称
* @return
* 2020年2月28日 下午3:02:11
*/
public static Sheet getSheet(Workbook workbook) {
return getSheet(workbook, 0);
}
/**
* 根据sheet的名称获取Sheet
* @param workbook
* @param sheetName sheet的名称
* @return
* 2020年2月28日 下午3:02:11
*/
public static Sheet getSheet(Workbook workbook, String sheetName) {
return workbook.getSheet(sheetName);
}
/**
* 获取第几个的Sheet
* @param workbook
* @param sheetIndex sheet所在的index
* @return
* 2020年2月28日 下午3:02:37
*/
public static Sheet getSheet(Workbook workbook, int sheetIndex) {
return workbook.getSheetAt(sheetIndex);
}
/**
* 从文件中获取Workbook解析对象
* @param filePath
* @return
* 2020年2月28日 下午3:03:23
*/
public static Workbook readWorkBookeType(String filePath) {
FileInputStream is = null;
try {
is = new FileInputStream(filePath);
if(filePath.toLowerCase().endsWith(".xlsx")) {//新版excel 2007以上
return new XSSFWorkbook(is);
} else if(filePath.toLowerCase().endsWith(".xls")) {//旧版excel 2003
return new HSSFWorkbook(is);
} else {
throw new RuntimeException("excel格式文件错误");
}
} catch (FileNotFoundException e) {
e.printStackTrace();
throw new RuntimeException("读取文件错误 == " + e.toString());
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException("excel格式文件错误 == " + e.toString());
} finally {
if(is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
} }
/**
* 检查是否是Excel文件
* @param file
* @return
* 2020年2月28日 下午3:03:49
*/
public boolean checkExcelFile(File file) {
// 判断文件是否存在
if (null == file) {
System.err.println("文件不存在!");
return false;
}
// 获得文件名
String fileName = file.getName();
// 判断文件是否是excel文件
if (!fileName.endsWith(".xls") && !fileName.endsWith(".xlsx")) {
System.err.println("不是excel文件!");
return false;
}
return true;
} }
注:若单元格的格式和内容均为数字,直接用获取字符串的方式 cell.getStringCellValue()获取,会报:Cannot get a NUMERIC value from a STRING cell 错误,原因是无法从纯数字的单元格 用获取String的方式获取。但是使用读取数字:cell.getNumericCellValue() 会将数字 1 变成 1.0 的情况,若能接收该情况,解决方法是先将该单元格,设置成字符格式,再用读取字符串的方式获取:
cell.setCellType(CellType.STRING); //读取数字:cell.getNumericCellValue()
String cellValue = String.valueOf(cell.getStringCellValue());
但是使用该种方式,仍然存在问题,存在double类型的数字时,精度会改变,如原值为:42.932517 ,经过上述方式运行后,变为:42.932516999999997的情况,我的解决方式是:然后以 cell.getStringCellValue()获取,对于是整数的情况,转为1.0后,将【.0】截掉:
double numericCellValue = cell.getNumericCellValue();
String cellValue = String.valueOf(numericCellValue); if (cellValue.contains("E")) {
return String.valueOf(new Double(cell.getNumericCellValue()).longValue()); // 数字
}
if(cellValue.endsWith(".0")) {
cellValue = cellValue.substring(0, cellValue.length() - 2);
}
ParseExcelListMap.java 以某一行作为字段(Map中的key),其他行作为值(Map的值),每一行的值形成一个Map,所有行作为一个List集合
package cn.hxc.myExecel; import java.util.LinkedHashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map; import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet; /**
* @Description 将excel中的数据解析成List<Map<E>>格式
* 以某一行作为字段(Map中的key),其他行作为值(Map的值)每一行的值形成一个Map,所有行作为一个List集合
* @author Huang Xiaocong
* 2020年2月28日 下午8:13:13
*/
public class ParseExcelListMap { /**
* 获取sheet的所有数据
* @param sheet
* @param headKey
* @return
* 2020年2月28日 下午6:17:52
* @author Huang Xiaocong
*/
public static List<Map<String, Object>> parseSheetToListMap(Sheet sheet, String[] headKey) {
return parseSheetToListMap(sheet, headKey, 0);
}
/**
* 从sheet的第startRow行开始获取数据组装成List<Map>格式
* @param sheet
* @param headKey 作为Map的key
* @param startRow 行号
* @return
* 2020年2月28日 下午2:42:54
* @author Huang Xiaocong
*/
public static List<Map<String, Object>> parseSheetToListMap(Sheet sheet, String[] headKey, int startRow) {
List<Map<String, Object>> contents = new LinkedList<Map<String, Object>>();
if(ParseExcelPubUtils.isSheetEmpty(sheet)) {
return contents;
}
Map<String, Object> tempMap = null;
int rowNumCount = sheet.getPhysicalNumberOfRows();
for (int rowNum = startRow; rowNum <= rowNumCount; rowNum++) {
Row row = sheet.getRow(rowNum);
if(null == row) { //该行为空
continue;
}
tempMap = parseSheetToMapByRow(row, headKey);
contents.add(tempMap);
}
System.out.println("总共读取了" + (rowNumCount - startRow + 1) + "行!");
return contents;
}
/**
* 从sheet的 第startRow行到第endRow行 第startCol列 到 第endCol列 开始获取数据组装成List<Map>格式
* @param sheet
* @param headKey 作为Map的key
* @param startRow 开始行
* @param endRow 结束行
* @param startCol 开始列
* @param endCol 结束列
* @return
* 2020年2月28日 下午8:13:36
* @author Huang Xiaocong
*/
public static List<Map<String, Object>> parseSheetToListMapByRowCol(Sheet sheet, String[] headKey, int startRow, int endRow, int startCol, int endCol) {
List<Map<String, Object>> contents = new LinkedList<Map<String, Object>>();
if(ParseExcelPubUtils.isSheetEmpty(sheet)) {
return contents;
}
if(endRow < startRow || endRow < 0) {
System.err.println("结束行不能小于开始行");
return contents;
}
Map<String, Object> tempMap = null;
for (int rowNum = startRow; rowNum <= endRow; rowNum++) {
Row row = sheet.getRow(rowNum);
if(null == row) { //该行为空
continue;
}
tempMap = parseSheetToMapByRow(row, headKey, startCol, endCol);
contents.add(tempMap);
}
System.out.println("读取了行:" + startRow + " - " + endRow + " ;列:" + startCol + " - " + endCol + " 之间的数据!");
return contents;
} /**
* 解析一行的数据
* @param row
* @param headKey
* @return
* 2020年2月28日 下午8:04:13
* @author Huang Xiaocong
*/
public static Map<String, Object> parseSheetToMapByRow(Row row, String[] headKey) {
Map<String, Object> retMap = new LinkedHashMap<String, Object>();
int cellNumCount = row.getPhysicalNumberOfCells();
for(int i = 0; i < cellNumCount && cellNumCount <= headKey.length; i++) {
Cell cell = row.getCell(i);
if(cell != null)
retMap.put(headKey[i], ParseExcelPubUtils.parseCell(cell).trim());
}
return retMap;
}
/**
* 解析一行中 从第startCol列 到 第endCol列 之间的数据
* @param row
* @param headKey
* @param startCol 开始列
* @param endCol 结束列
* @return
* 2020年2月28日 下午8:16:52
* @author Huang Xiaocong
*/
public static Map<String, Object> parseSheetToMapByRow(Row row, String[] headKey, int startCol, int endCol) {
Map<String, Object> retMap = new LinkedHashMap<String, Object>();
if(endCol < startCol || endCol < 0) {
System.err.println("结束列不能小于开始列");
return retMap;
}
int size = endCol - startCol;
for(int i = startCol, j = 0; i < endCol && j <= size; i++, j++) {
Cell cell = row.getCell(i);
if(cell != null)
retMap.put(headKey[j], ParseExcelPubUtils.parseCell(cell).trim());
}
return retMap;
}
/**
* 从sheet中获取某一行的数据
* @param sheet
* @param rowNum
* @return
* 2020年2月28日 下午3:55:29
* @author Huang Xiaocong
*/
public static String[] getExcelRowColData(Sheet sheet, int rowNum) {
Row row = sheet.getRow(rowNum);
if(null == row) {
System.err.println("该行数据为空");
return null;
}
return getExcelRowColData(row, 0, row.getPhysicalNumberOfCells());
}
/**
* 从excel中获取某一行开始 第startColIndex列到第endColIndex列之间 的数据
* @param sheet
* @param rowNum
* @param startColIndex
* @param endColIndex
* @return
* 2020年2月28日 下午8:19:44
* @author Huang Xiaocong
*/
public static String[] getExcelRowColData(Sheet sheet, int rowNum, int startColIndex, int endColIndex) {
Row row = sheet.getRow(rowNum);
if(null == row) {
System.out.println("该行数据为空");
return null;
}
int size = endColIndex-startColIndex;
String[] val = new String[size];
for (int i = startColIndex, j = 0; i < endColIndex && j <= size; i++, j++) {
val[j] = ParseExcelPubUtils.parseCell(row.getCell(i)).trim();
}
return val;
}
/**
* 解析一行数据 第startColIndex列到第endColIndex列之间 的数据
* @param row
* @param startColIndex
* @param endColIndex
* @return
* 2020年2月28日 下午8:04:19
* @author Huang Xiaocong
*/
public static String[] getExcelRowColData(Row row, int startColIndex, int endColIndex) {
int size = endColIndex-startColIndex;
String[] val = new String[size];
for (int i = startColIndex, j = 0; i < endColIndex && j <= size; i++, j++) {
val[j] = ParseExcelPubUtils.parseCell(row.getCell(i)).trim();
}
return val;
}
}
ParseExcelListList.java 以每一行中的值作为list集合,所有的行作为一个List集合
package cn.hxc.myExecel; import java.util.LinkedList;
import java.util.List; import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet; /**
* @Description 将数据解析成List<list<E>> 结构的数据形式 以每一行中的值作为list集合,所有的行作为一个List集合
* @author Huang Xiaocong
* 2020年2月28日 下午5:48:39
*/
public class ParseExcelListList { /**
* 从某行开始读取数据
* @param sheet
* @param startRow 开始行
* @return list嵌套list格式的数据
* 2020年2月28日 下午5:11:42
* @author Huang Xiaocong
*/
public static List<List<String>> parseSheetToListByRow(Sheet sheet, int startRow) { //
return parseSheetToListByRow(sheet, startRow, sheet.getPhysicalNumberOfRows());
}
/**
* 读取,某行到某行的数据
* @param sheet
* @param startRow 开始行
* @param endRow 结束行
* @return list嵌套list格式的数据
* 2020年2月28日 下午3:44:56
* @author Huang Xiaocong
*/
public static List<List<String>> parseSheetToListByRow(Sheet sheet, int startRow, int endRow) { //
List<List<String>> contents = new LinkedList<List<String>>();
if(ParseExcelPubUtils.isSheetEmpty(sheet)) {
return contents;
}
if(endRow < startRow || endRow < 0) {
System.err.println("结束行不能小于开始行");
return contents;
}
List<String> tempList = null;
Row row = null;
for (int rowNum = startRow; rowNum <= endRow; rowNum++) {
row = sheet.getRow(rowNum);
if(null == row) { //该行为空
continue;
}
tempList = parseSheetToListByCol(row, 0, row.getPhysicalNumberOfCells());
contents.add(tempList);
}
System.out.println("总共读取了" + (endRow - startRow + 1) + "行数据!");
return contents;
}
/**
* 从sheet读取某一行中从某列到某列的数据
* @param sheet
* @param rowNum 行号
* @param startCol 开始列
* @param endCol 结束列
* @return list格式的数据
* 2020年2月28日 下午5:02:31
* @author Huang Xiaocong
*/
public static List<String> parseSheetToListByCol(Sheet sheet, int rowNum, int startCol, int endCol) { //
List<String> contents = new LinkedList<String>();
if(ParseExcelPubUtils.isSheetEmpty(sheet)) {
return contents;
}
Row row = sheet.getRow(rowNum);
contents = parseSheetToListByCol(row, startCol, endCol);
return contents;
}
/**
* 从sheet读取行startRow 到 endRow 和startCol 到endCol之间的数据
* @param sheet
* @param startRow 开始行
* @param endRow 结束行
* @param startCol 开始列
* @param endCol 结束列
* @return
* 2020年2月28日 下午5:37:43
* @author Huang Xiaocong
*/
public static List<List<String>> parseSheetToListByRowCol(Sheet sheet, int startRow, int endRow, int startCol, int endCol) { //
List<List<String>> contents = new LinkedList<List<String>>();
if(ParseExcelPubUtils.isSheetEmpty(sheet)) {
return contents;
}
if(endRow < startRow || endRow < 0) {
System.err.println("结束行不能小于开始行");
return contents;
} List<String> tempList = null;
Row row = null;
for (int rowNum = startRow; rowNum <= endRow; rowNum++) {
row = sheet.getRow(rowNum);
if(null == row) { //该行为空
continue;
}
tempList = parseSheetToListByCol(row, startCol, endCol);
contents.add(tempList);
}
System.out.println("读取了行:" + startRow + " - " + endRow + " ;列:" + startCol + " - " + endCol + " 之间的数据!");
return contents;
}
/**
* 读取某一行中从某列到某列的数据
* @param row
* @param startCol
* @param endCol
* @return
* 2020年2月28日 下午5:02:24
* @author Huang Xiaocong
*/
public static List<String> parseSheetToListByCol(Row row, int startCol, int endCol) { //
List<String> contents = new LinkedList<String>();
if(endCol < startCol || endCol < 0) {
System.err.println("结束列不能小于开始列");
return contents;
}
if(null == row) { //该行为空
System.err.println("该行数据为空");
return contents;
}
for(int i = startCol; i < endCol; i++ ) {
Cell cell = row.getCell(i);
contents.add(ParseExcelPubUtils.parseCell(cell).trim());
}
return contents;
}
}
配置类 ExcelEntity.java 该部分可以写入配置文件
package cn.hxc.myExecel;
public class ExcelEntity {
/** sheet的名称*/
private String sheetName;
/** 第几个sheet*/
private int sheetIndex;
/** 第几行作为头信息*/
private int headRowNum;
/** 解析某行*/
private int indexRow;
/** 开始列*/
private int startColIndex;
/** 结束列*/
private int endColIndex;
/** 开始行*/
private int startRowIndex;
/** 结束行*/
private int endRowIndex;
/** 头信息*/
private String[] headKey;
/** 源文件及路径*/
private String sourceFilePath;
/** 保存的文件及路径*/
private String saveFilePath;
public String getSheetName() {
return sheetName;
}
public void setSheetName(String sheetName) {
this.sheetName = sheetName;
}
public int getSheetIndex() {
return sheetIndex;
}
public void setSheetIndex(int sheetIndex) {
this.sheetIndex = sheetIndex;
}
public int getHeadRowNum() {
return headRowNum;
}
public void setHeadRowNum(int headRowNum) {
this.headRowNum = headRowNum;
}
public int getIndexRow() {
return indexRow;
}
public void setIndexRow(int indexRow) {
this.indexRow = indexRow;
}
public int getStartColIndex() {
return startColIndex;
}
public void setStartColIndex(int startColIndex) {
this.startColIndex = startColIndex;
}
public int getEndColIndex() {
return endColIndex;
}
public void setEndColIndex(int endColIndex) {
this.endColIndex = endColIndex;
}
public int getStartRowIndex() {
return startRowIndex;
}
public void setStartRowIndex(int startRowIndex) {
this.startRowIndex = startRowIndex;
}
public int getEndRowIndex() {
return endRowIndex;
}
public void setEndRowIndex(int endRowIndex) {
this.endRowIndex = endRowIndex;
}
public String[] getHeadKey() {
return headKey;
}
public void setHeadKey(String[] headKey) {
this.headKey = headKey;
}
public String getSourceFilePath() {
return sourceFilePath;
}
public void setSourceFilePath(String sourceFilePath) {
this.sourceFilePath = sourceFilePath;
}
public String getSaveFilePath() {
return saveFilePath;
}
public void setSaveFilePath(String saveFilePath) {
this.saveFilePath = saveFilePath;
}
}
DataSaveToFileUtils.java 将数据写入文件:
package cn.hxc.myExecel; import java.io.BufferedWriter;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set; public class DataSaveToFileUtils { /**
* 对List<Map<V, E>>类型解析数据并保存
* @param data
* @param districtKey
* @param bWirter
* 2020年2月28日 下午9:34:47
*/
public static void parseDataSave(List<Map<String, Object>> data, String[] districtKey, BufferedWriter bWirter) {
int size = data.size();
Set<String> tempSet = new HashSet<String>();
for(int i = 0; i < size; i++) {
Map<String, Object> tempMap = data.get(i);
tempSet.add(parseData(tempMap, districtKey));
}
writeDataTo(new ArrayList<Object>(tempSet), bWirter);
}
/**
* 写入文件
* @param data
* @param bWirter
* 2020年2月29日 上午10:18:21
*/
public static void writeDataTo(List<Object> data, BufferedWriter bWirter) {
Iterator<Object> iterator = data.iterator();
try {
while (iterator.hasNext()) {
String str = iterator.next().toString();
bWirter.write(str); //写入
bWirter.newLine();
}
bWirter.newLine();
bWirter.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 对List<List<E>>类型解析数据并保存
* @param data
* @param bWirter
* 2020年2月28日 下午10:01:15
*/
public static void parseDataSave(List<List<String>> data, BufferedWriter bWirter) {
int size = data.size();
Set<String> tempSet = new HashSet<String>();
for(int i = 0; i < size; i++) {
List<String> tempList = data.get(i);
tempSet.add(parseData(tempList));
}
writeDataTo(new ArrayList<Object>(tempSet), bWirter);
}
/**
*
* @param data
* @return
* 2020年2月28日 下午10:01:03
*/
public static String parseData(List<String> data) {
StringBuilder sb = new StringBuilder();
for (String val : data) {
sb.append(val).append(" | ");
}
return sb.toString();
}
/**
*
* @param tempMap
* @param key
* @return
* 2020年2月28日 下午9:39:18
*/
public static String parseData(Map<String, Object> tempMap, String[] key) {
StringBuilder sb = new StringBuilder();
for (String valKey : key) {
sb.append(tempMap.get(valKey)).append(" , ");
}
return sb.toString();
} /**
* 缓存对象
* @param savePath 文件路径及名称
* @return 缓存对象
* 2020年2月28日 下午9:31:33
*/
public static BufferedWriter getBufferedWriter(String savePath) {
try {
return new BufferedWriter(new OutputStreamWriter(new FileOutputStream(savePath)));
} catch (FileNotFoundException e) {
System.err.println("文件不存在" + e.toString());
e.printStackTrace();
}
return null;
}
/**
* 关闭缓存流
* @param bWirter
* 2020年2月28日 下午9:31:24
*/
public static void flushAndClose(BufferedWriter bWirter) {
if(bWirter != null) {
try {
bWirter.flush();
bWirter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
4.测试类 Test.java 将上图中的数据解析,写入到文件中
package cn.hxc.myExecel; import java.io.BufferedWriter;
import java.util.List;
import java.util.Map; import org.apache.poi.ss.usermodel.Sheet; /**
* @Description 测试
* @author Huang Xiaocong
* 2020年2月29日 上午10:17:07
*/
public class Test { public static void main(String[] args) {
//下面方法的测试为:以某一行作为字段(Map中的key),其他行作为值(Map的值)每一行的值形成一个Map,所有行作为一个List集合
testMap();
//下面的测试为:以每一行中的值作为list集合,所有的行作为一个List集合
// testList();
}
public static void testMap() {
Test test = new Test();
ExcelEntity excelEntity = test.excelEntityInfo();
Sheet sheet = ParseExcelPubUtils.getSheet(ParseExcelPubUtils.readWorkBookeType(excelEntity.getSourceFilePath()), excelEntity.getSheetName()); // String[] headKey = ParseExcelToListMap.getExcelRowColData(sheet, 0);
//从第三行开始读取
// List<Map<String, Object>> contents = ParseExcelToListMap.parseSheetToListMap(sheet, headKey, excelEntity.getIndexRow());
//读取第7行 到第10行 第4列 到第10列的数据 头部也应这样截取
String[] headKey = ParseExcelListMap.getExcelRowColData(sheet,0, excelEntity.getStartColIndex(), excelEntity.getEndColIndex());
List<Map<String, Object>> contents = ParseExcelListMap.parseSheetToListMapByRowCol(sheet, headKey,
excelEntity.getStartRowIndex(), excelEntity.getEndRowIndex(), excelEntity.getStartColIndex(), excelEntity.getEndColIndex());
for(int i = 0; i < contents.size(); i++) {
Map<String, Object> map = contents.get(i);
for (Map.Entry<String, Object> entry : map.entrySet()) {
System.out.print(entry.getValue() + " | ");
}
System.out.println();
System.out.println("===========================================================================");
} //将contents数据保存到文件中
BufferedWriter bWirter = DataSaveToFileUtils.getBufferedWriter(excelEntity.getSaveFilePath());
DataSaveToFileUtils.parseDataSave(contents, headKey, bWirter);
DataSaveToFileUtils.flushAndClose(bWirter);
} public static void testList() {
Test test = new Test();
ExcelEntity excelEntity = test.excelEntityInfo();
excelEntity.setSaveFilePath("E:\\营业厅信息List.txt");
Sheet sheet = ParseExcelPubUtils.getSheet(ParseExcelPubUtils.readWorkBookeType(excelEntity.getSourceFilePath()), excelEntity.getSheetName());
//读取第7行 到第10行 第4列 到第10列的数据
List<List<String>> data = ParseExcelListList.parseSheetToListByRowCol(sheet,
excelEntity.getStartRowIndex(), excelEntity.getEndRowIndex(), excelEntity.getStartColIndex(), excelEntity.getEndColIndex()); BufferedWriter bWirter = DataSaveToFileUtils.getBufferedWriter(excelEntity.getSaveFilePath());
DataSaveToFileUtils.parseDataSave(data, bWirter);
DataSaveToFileUtils.flushAndClose(bWirter);
}
/**
* 设置Excel参数实体(可放在配置文件中)
* @return
* 2020年2月29日 上午10:16:27
*/
public ExcelEntity excelEntityInfo() {
ExcelEntity excelEntity = new ExcelEntity();
excelEntity.setSourceFilePath("E:\\TestData.xlsx");
excelEntity.setSaveFilePath("E:\\营业厅信息.txt");
excelEntity.setSheetIndex(0);
excelEntity.setSheetName("营业厅数据");
excelEntity.setIndexRow(2); excelEntity.setStartRowIndex(7);
excelEntity.setEndRowIndex(10);
excelEntity.setStartColIndex(4);
excelEntity.setEndColIndex(11);
return excelEntity;
} }
5.测试结果如下:
控制台打印的消息:

生成的文件信息:

POI解析excel,将批量数据写入文件或数据库的更多相关文章
- 你需要一个新的model实体的时候必须new一个.奇怪的问题: 使用poi解析Excel的把数据插入数据库同时把数据放在一个list中,返回到页面展示,结果页面把最后一条数据显示了N次
数据库显示数据正常被插 插入一条打印一次数据,也是正常的,但是执行完,list就全部变成了最后一条数据.很奇怪 单步调试 给list插入第一条数据 model是6607 连续插了多条数据都是6607 ...
- Pandas dataframe数据写入文件和数据库
转自:http://www.dcharm.com/?p=584 Pandas是Python下一个开源数据分析的库,它提供的数据结构DataFrame极大的简化了数据分析过程中一些繁琐操作,DataFr ...
- java读写excel文件( POI解析Excel)
package com.zhx.base.utils; import org.apache.poi.hssf.usermodel.HSSFWorkbook; import org.apache.poi ...
- poi解析Excel文件版本问题
poi解析Excel文件时有两种格式: HSSFWorkbook格式用来解析Excel2003(xls)的文件 XSSFWorkbook格式用来解析Excel2007(xlsx)的文件 如果用HSSF ...
- poi解析Excel内容
poi可以将指定目录下的Excel中的内容解析.读取到java程序中.下面是一个Demo: 使用poi需要导下包,如下: 首先是准备读取的Excel表,存放在"E:\programming\ ...
- POI导出Excel和InputStream存储为文件
POI导出Excel和InputStream存储为文件 本文需要说明的两个问题 InputStream如何保存到某个文件夹下 POI生成Excel POI操作utils类 代码如下.主要步骤如下: ...
- POI解析Excel时,如何获取单元格样式以及单元格Style的一些操作
最近,公司运营平台需要上传Excel文件并进行解析导入数据库,在开发完成后出现了一个始料不及的生产bug,下面是具体原因: 1.在用POI解析Excel时,默认如果Excel单元格中没有数据,且单元格 ...
- iOS VideoToolbox硬编H.265(HEVC)H.264(AVC):2 H264数据写入文件
本文档为iOS VideoToolbox硬编H.265(HEVC)H.264(AVC):1 概述续篇,主要描述: CMSampleBufferRef读取实际数据 序列参数集(Sequence Para ...
- 学习springMVC框架配置遇到的问题-数据写入不进数据库时的处理办法
配置完了,运行,数据写入不到数据库中,就应该想UserAction 中的handleRequest()方法有没有进去,然后就设置断点.如果发现程序没有进去,就再想办法进去.
随机推荐
- Center OS 7 通过Docker部署yapi
Center OS 7 通过Docker部署yapi 版本要求 Linux Center OS 7 安装Docker #Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看本页面的前 ...
- 痞子衡嵌入式:对比i.MXRT与LPC在RTC外设GPREG寄存器使用上的异同
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是对比i.MXRT与LPC在RTC外设GPREG寄存器使用上的异同. 本篇是 <在SBL项目实战中妙用i.MXRT1xxx里Syst ...
- Camunda工作流引擎简单入门
官网:https://camunda.com/ 官方文档:https://docs.camunda.org/get-started/spring-boot/project-setup/ 阅读新体验:h ...
- org.springframework.beans.BeanInstantiationException: Could not instantiate bean class [java.util.List]: Specified class
错误:org.springframework.beans.BeanInstantiationException: Could not instantiate bean class [java.util ...
- XCTF IgniteMe
一.查壳 结论: 1.用vc++编译的. 2.无壳,毕竟是一分的题 二.点击运行,发现不是爆破,而是找出注册机,汇编功力还在提升中,只能拖入ida来静态调试了 具体的见注释: 二.1点击进入关键函数 ...
- WPF教程一:创建Hello world来理解XAML的内容及编译
在实际的WPF开发中遇到很多再用Winform写法来写WPF的开发人员,很多时候项目进度延期.出现非必要的BUG等等.大多是因为开发人员虽然是再写WPF. 但是没有好好的学过WPF,就导致无法发挥出W ...
- cron表达式详解(转)
Cron表达式是一个字符串,字符串以5或6个空格隔开,分为6或7个域,每一个域代表一个含义,Cron有如下两种语法格式: (1) Seconds Minutes Hours DayofMonth Mo ...
- SQLITE数据库不支持远程访问
SQLITE数据库不支持远程访问 import sqlite3 conn=sqlite3.connect("dailiaq.db") cur=conn.cursor() def c ...
- [刘阳Java]_InternalResourceViewResolver视图解析器_第6讲
SpringMVC在处理器方法中通常返回的是逻辑视图,如何定位到真正的页面,就需要通过视图解析器 InternalResourceViewResolver是SpringMVC中比较常用视图解析器. 网 ...
- 初探SpringRetry机制
重试是在网络通讯中非常重要的概念,尤其是在微服务体系内重试显得格外重要.常见的场景是当遇到网络抖动造成的请求失败时,可以按照业务的补偿需求来制定重试策略.Spring框架提供了SpringRetry能 ...