BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
概
数据的长短尾效应是当前比较棘手的问题, 本文提出用分支网络来应对这一问题, 并取得了不错的结果.
主要内容
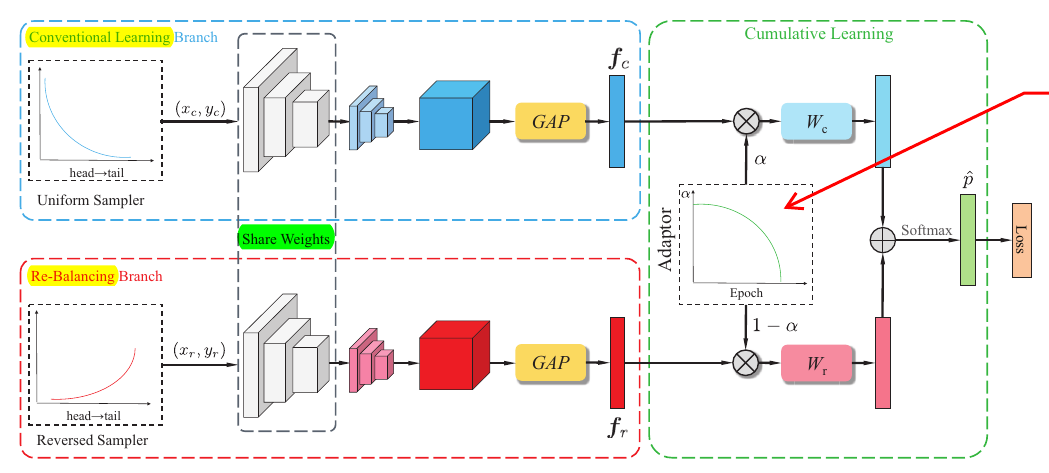
这篇文章的创新点是用两个分支来适应数据的不平衡.
如图所示, 上面的分支用于标准的训练, 而下面的分支则采用适合不平衡数据的训练方式: 即一般的训练是均匀的采样分布, 而非标准训练采用的是一个非均匀的依赖于样本分布的.
通过均匀采样得到\((x_c, y_c)\), 通过非均匀采样得到\((x_r, y_r)\), 分别喂入上下分支得到特征表示\(f_c\)和\(f_r\).
注意到, 上下两个分支是共享部分参数的, 作者实际选择的是残差网络, 设定为除了最后一个residual block外均是共享的.
根据\(f_c\)和\(f_r\)进一步得到
\]
即\([z_1, z_2,\cdots, z_C]^T\).
得到相应的概率向量
\]
最后通过下列损失函数进行训练
\]
实际上, \(\alpha\)就是一个调整标准训练和处理不平衡数据的权重.
采样方式
对于非均匀分布, 作者采取了如下方式构造采样分布, 假设每个类的样本数目为\(N_i, i=1,2,\ldots,C\). 则采样比例为
\]
其中\(w_i=\frac{1}{N_i}\).
权重\(\alpha\)
作者采用的是这样的一种方案
\]
其中\(T\)为当前的epoch, \(T_{max}\)为总的训练epochs.
在实际测试中, 作者也尝试了一些别的方案, 不过别的方案不如此方案理想.
直观上的解释就是, 训练过程会有普通的训练渐渐偏向re-balance的训练.
Inference phase
在推断过程中, 设定\(\alpha=0.5\).
代码
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition的更多相关文章
- 《Neural Network and Deep Learning》_chapter4
<Neural Network and Deep Learning>_chapter4: A visual proof that neural nets can compute any f ...
- neural network and deep learning笔记(1)
neural network and deep learning 这本书看了陆陆续续看了好几遍了,但每次都会有不一样的收获. DL领域的paper日新月异.每天都会有非常多新的idea出来,我想.深入 ...
- 树卷积神经网络Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning
树卷积神经网络Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning 2018-04-17 08:32:39 看_这是一 ...
- 论文笔记:Learning Attribute-Specific Representations for Visual Tracking
Learning Attribute-Specific Representations for Visual Tracking AAAI-2019 Paper:http://faculty.ucmer ...
- [论文阅读] A Discriminative Feature Learning Approach for Deep Face Recognition (Center Loss)
原文: A Discriminative Feature Learning Approach for Deep Face Recognition 用于人脸识别的center loss. 1)同时学习每 ...
- Neural Network Programming - Deep Learning with PyTorch with deeplizard.
PyTorch Prerequisites - Syllabus for Neural Network Programming Series PyTorch先决条件 - 神经网络编程系列教学大纲 每个 ...
- Learning to Compare: Relation Network for Few-Shot Learning 论文笔记
主要原理: 和Siamese Neural Networks一样,将分类问题转换成两个输入的相似性问题. 和Siamese Neural Networks不同的是: Relation Network中 ...
- 【转载】论文笔记系列-Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning
一. 引出主题¶ 深度学习领域一直存在一个比较严重的问题——“灾难性遗忘”,即一旦使用新的数据集去训练已有的模型,该模型将会失去对原数据集识别的能力.为解决这一问题,本文提出了树卷积神经网络,通过先将 ...
- Neural Network Programming - Deep Learning with PyTorch - YouTube
百度云链接: 链接:https://pan.baidu.com/s/1xU-CxXGCvV6o5Sksryj3fA 提取码:gawn
随机推荐
- ios加载html5 audio标签用js无法自动播放
html5 audio标签在ios 微信浏览器中是无法自动播放的,最近在做一个小的项目遇到这个问题,安卓和pc都是正常的,唯独ios不行,查阅了很多资料,找到了以下方法,也许不是最好用的方法,如果有更 ...
- Postman 中 Pre-request Script 常用 js 脚本
1. 生成一个MD5或SHA1加密的字符串str_md5,str_sha1 string1 = "123456"; var str_md5= CryptoJS.MD5(string ...
- 集合类——Collection、List、Set接口
集合类 Java类集 我们知道数组最大的缺陷就是:长度固定.从jdk1.2开始为了解决数组长度固定的问题,就提供了动态对象数组实现框架--Java类集框架.Java集合类框架其实就是Java针对于数据 ...
- 银联acp手机支付总结
总结: 1.手机调用后台服务端接口,获取银联返回的流水号tn 银联支付是请求后台,后台向银联下单,返回交易流水号,然后返回给用户,用户通过这个交易流水号,向银联发送请求,获取订单信息,然后再填写银行卡 ...
- OkHttp3 使用
导入 compile 'com.squareup.okhttp3:okhttp:3.3.0' GET请求 String url = "https://www.baidu.com/" ...
- linux 定时导出sql查询结果文件
如果想在服务器端生成sql查询结果的txt文件. 大体思路就是: 1.创建一个到处txt文件的sql脚本. set ARRAYSIZE 50 --从数据库往客户端一次发送记录数 set linesiz ...
- RAC(Reactive Cocoa)常见的类
导入ReactiveCocoa框架 在终端,进入Reactive Cocoa文件下 创建podfile 打开该文件 并配置 use_frameworks! pod 'ReactiveCocoa', ' ...
- transient关键字和volatile关键字
看到HashSet的源代码的时候,有一个关键字不太认识它..transient,百度整理之: Java的Serialization提供了一种持久化对象实例的机制,当持久化对象时,可能有一些特殊的对象数 ...
- 02_ubantu常用软件安装
软件更新-----------------------------------------------------------------进入系统后,什么也不要做,先去更新软件:如果网速慢的话,可以稍 ...
- 【Java基础】Java中new对象的过程
序言 联系我上次写的关于Java内存的文章,对象访问在 Java 语言中无处不在,是最普通的程序行为,但即使是最简单的访问,也会却涉及 Java 栈.Java 堆.方法区这三个最重要内存区域之间的关联 ...