Proximal Algorithms 5 Parallel and Distributed Algorithms
这一节,介绍并行算法的实现.
问题的结构
令\([n] = \{1, \ldots, n\}\). 给定\(c \subseteq [n]\), 让\(x_c \in \mathbb{R}^{|c|}\)表示向量\(x\in \mathbb{R}^n\)的一个子向量(以\(c\)为指标的对应部分).当\(\mathcal{P}=\{c_1, \ldots, c_N\}\)满足:
c_i \cap c_j = \emptyset, i \ne j
\]
时, 称\(\mathcal{P}\)为\([n]\)的一个分割.
函数\(f\)的\(\mathcal{P}-\)分割满足:
\]
其中\(f_i : \mathbb{R}^{|c_i|} \rightarrow \mathbb{R}\).
在这种情况下:
\]
所以,可以并行计算.
考虑下面的问题:
\]
如果假设\(f\)是\(\mathcal{P}-\)分割的, 而\(g\)是\(\mathcal{Q}-\)分割的,那么问题等价于:
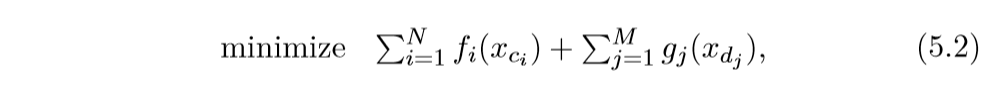
于是ADMM可以并行计算:

consensus
考虑下列问题如何进行并行计算:
\]
一个非常巧妙的变化:
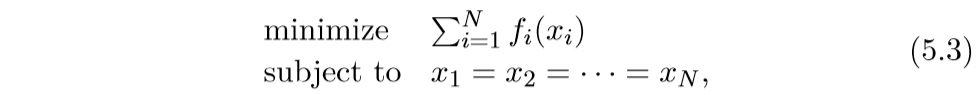
可以看到,这样子,函数就是可分了, 只是多了一个附加条件.
将上面的问题转化为:
\]
其中\(\mathcal{C}\)是consensus set:
\]
这样,问题就变成俩个可分函数了, 不过需要注意的是,二者的分割并不相同:
\]
而\(\mathcal{Q}\),即\(I_{\mathcal{C}}\)的分割为:
\]
注: 文中是\(i=1, 2, \ldots, N\)(我认为是作者的笔误).
这个时候的ADMM的第二步,即更新\(z\),可以直接为:
\]
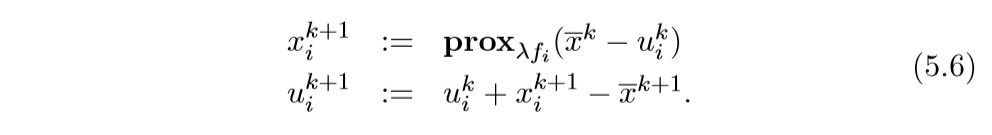
作者贴了一个比较形象的图来表示这种分割:

更为一般的情况
考虑下面的问题:
\]
其中\(c_i \subseteq [n]\), 但是\(c_i \cap c_j, i \ne j\)并不一定为空集.
进行同样的转换:
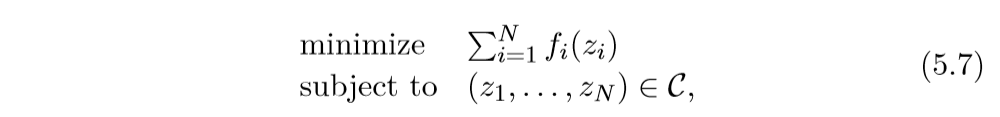
其中
\]
同样等价于:
\]
相应的有一张比较形象的图:

前一部分的分割是类似的, 后一部分的分割,就是怎么说呢,就像图上的行一样的分.
ADMM为:

其中\(F_i = \{j \in [N] | i \in c_j\}\)
Exchange 问题
Global exchange
交换问题具有如下形式:
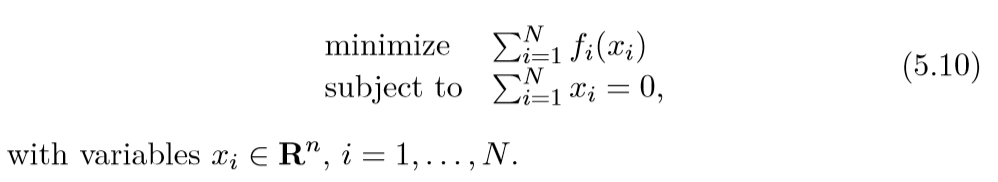
可以用一个实际问题来考量,每个\(i\)表示一个客户,\(x_i\)表示每个客户给予或者得到的总量,而\(f_i(x_i)\)表示该客户的效益,\(\sum_{i=1}^Nx_i=0\)这个条件表示,所以客户东西的总量是固定的,即收支平衡.
我们可以将此问题转化为(这个方法太好使了吧):
\]
其中
\]
我们知道,指示函数的proximal为投影算子, 于是:
\]
于是ADMM算法为:
更为一般的情况
有些时候,并不是所有客户都面对同一个市场,所以,每个\(x_i\)的维度什么对的也有区别:
\]
有点和consenus的一般情况比较类似.
Allocation
allocation problem:
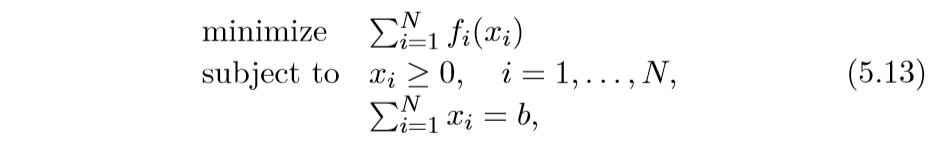
其中\(x_i \in \mathbb{R}^n\).
这个问题和交换问题也是相似的,区别在于总量\(b\), 而且要求\(x_i \ge 0\).
类似的,我们可以将上面的问题改写为:
\]
其中:
\]
所以相应的算法是:
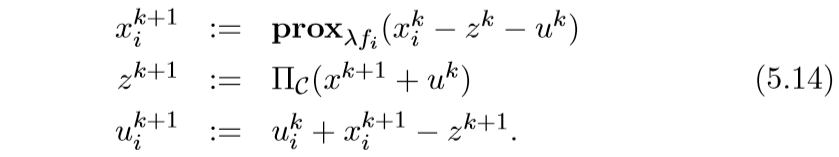
如何进行投影,会在下一节提到, 还有更加一般的情况,比如\(\sum_{i=1}^N x_i \le b\).
Proximal Algorithms 5 Parallel and Distributed Algorithms的更多相关文章
- Serialization and deserialization are bottlenecks in parallel and distributed computing, especially in machine learning applications with large objects and large quantities of data.
Serialization and deserialization are bottlenecks in parallel and distributed computing, especially ...
- ACM会议列表与介绍(2014/05/06)
Conferences ACM SEACM Southeast Regional Conference ACM Southeast Regional Conference the oldest, co ...
- Policy Gradient Algorithms
Policy Gradient Algorithms 2019-10-02 17:37:47 This blog is from: https://lilianweng.github.io/lil-l ...
- (转) An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms Table of contents: Gradient descent variants ...
- Matrix Factorization, Algorithms, Applications, and Avaliable packages
矩阵分解 来源:http://www.cvchina.info/2011/09/05/matrix-factorization-jungle/ 美帝的有心人士收集了市面上的矩阵分解的差点儿全部算法和应 ...
- An overview of gradient descent optimization algorithms
原文地址:An overview of gradient descent optimization algorithms An overview of gradient descent optimiz ...
- 【论文翻译】An overiview of gradient descent optimization algorithms
这篇论文最早是一篇2016年1月16日发表在Sebastian Ruder的博客.本文主要工作是对这篇论文与李宏毅课程相关的核心部分进行翻译. 论文全文翻译: An overview of gradi ...
- [转载]Maximum Flow: Augmenting Path Algorithms Comparison
https://www.topcoder.com/community/data-science/data-science-tutorials/maximum-flow-augmenting-path- ...
- Awesome Algorithms
Awesome Algorithms A curated list of awesome places to learn and/or practice algorithms. Inspired by ...
随机推荐
- 日常Java(测试 (二柱)修改版)2021/9/22
题目: 一家软件公司程序员二柱的小孩上了小学二年级,老师让家长每天出30道四则运算题目给小学生做. 二柱一下打印出好多份不同的题目,让孩子做了.老师看了作业之后,对二柱赞许有加.别的老师闻讯, 问二柱 ...
- Java面试基础--(出现次数最多的字符串)
题目:给定字符串,求出现次数最多的那个字母及次数,如有多个 重复则都输出. eg,String data ="aaavzadfsdfsdhshdWashfasdf": 思路: 1. ...
- jquery总结和注意事项
1.关于页面元素的引用通过jquery的$()引用元素包括通过id.class.元素名以及元素的层级关系及dom或者xpath条件等方法,且返回的对象为jquery对象(集合对象),不能直接调用dom ...
- Java 设计模式--策略模式,枚举+工厂方法实现
如果项目中的一个页面跳转功能存在10个以上的if else判断,想要做一下整改 一.什么是策略模式 策略模式是对算法的包装,是把使用算法的责任和算法本身分割开来,委派给不同的对象管理,最终可以实现解决 ...
- 【力扣】有序矩阵中第K小的元素
给定一个 n x n 矩阵,其中每行和每列元素均按升序排序,找到矩阵中第 k 小的元素.请注意,它是排序后的第 k 小元素,而不是第 k 个不同的元素. 示例: matrix = [ [ 1, 5, ...
- python3约瑟夫环问题
问题描述:n个人围成一个圈,从第一个人开始数1,数到第k个出局,然后下一个人继续从1数,求出局人编号 思路:将所有人编号放到数组里,一个人出局后,下一个人加上k对数组长度求余,得出下一个要删除的编号. ...
- 数据挖掘实战 - 天池新人赛o2o优惠券使用预测
数据挖掘实战 - o2o优惠券使用预测 一.前言 大家好,家人们.今天是2021/12/14号.上次更新是2021/08/29.上篇文章中说到要开两个专题,果不其然我鸽了,这一鸽就是三个多月.今天,我 ...
- 【划重点】Python遍历列表的四种方法
一.通过for循环直接遍历 user1 = ["宋江","林冲","卢俊义","吴用"] for user in use ...
- [BUUCTF]REVERSE——[GUET-CTF2019]re
[GUET-CTF2019]re 附件 步骤: 查壳儿,upx壳,64位程序 upx脱壳儿,然后扔进64位ida,通过检索字符串,找到有关flag的信息定位到关键函数 让我们输入flag,然后满足su ...
- Windows通过计划任务定时执行bat文件
第一步 第二步 第三步 第四步 第五步 第六步