TensorFlow.NET机器学习入门【4】采用神经网络处理分类问题
上一篇文章我们介绍了通过神经网络来处理一个非线性回归的问题,这次我们将采用神经网络来处理一个多元分类的问题。
这次我们解决这样一个问题:输入一个人的身高和体重的数据,程序判断出这个人的身材状况,一共三个类别:偏瘦、正常、偏胖。
处理流程如下:
1、收集数据
2、构建神经网络
3、训练网络
4、保存和消费模型
详细步骤如下:
1、收集数据
对于一个复杂的业务数据,在实际应用时应该是通过收集取得数据,本文的重点不在数据收集,所以我们将制造一批标准数据来进行学习。
关于人体的胖瘦问题,有一个BMI算法,即:BMI=weight / (height * height),当BMI小于18时,认为偏瘦,当BMI大于28时,认为偏胖,18到28之间,认为正常。
首先随机生成身高和体重的数据,然后计算BMI值,并对结果进行标记,其中,偏瘦标记为0,正常标记为1,偏胖标记为2 。代码如下:
/// <summary>
/// 加载训练数据
/// </summary>
/// <param name="total_size"></param>
private (NDArray, NDArray) PrepareData(int total_size)
{
float[,] arrx = new float[total_size, num_features];
int[] arry = new int[total_size]; for (int i = 0; i < total_size; i++)
{
float weight = (float)random.Next(30, 100) / 100;
float height = (float)random.Next(140, 190) / 100;
float bmi = (weight * 100) / (height * height); arrx[i, 0] = weight;
arrx[i, 1] = height; switch (bmi)
{
case var x when x < 18.0f:
arry[i] = 0;
break; case var x when x >= 18.0f && x <= 28.0f:
arry[i] = 1;
break; case var x when x > 28.0f:
arry[i] = 2;
break;
}
}
2、构建神经网络
相对于简单的非线性模型,本次的网络结构会稍微复杂一些:
// 网络参数
int num_features = 2; // data features
int num_classes = 3; // total output
/// <summary>
/// 构建网络模型
/// </summary>
private Model BuildModel()
{
// 网络参数
int n_hidden_1 = 64; // 1st layer number of neurons.
int n_hidden_2 = 64; // 2nd layer number of neurons. var model = keras.Sequential(new List<ILayer>
{
keras.layers.InputLayer(num_features),
keras.layers.Dense(n_hidden_1, activation:keras.activations.Relu),
keras.layers.Dense(n_hidden_2, activation:keras.activations.Relu),
keras.layers.Dense(num_classes, activation:keras.activations.Softmax)
}); return model;
}
首先,本次包含两层神经网络,激活函数均采用RELU,输出层激活函数采用Softmax函数。

和上一篇文章中的网络结构相比看上去复杂很多,但其本质实际上差别不大,只是多了一个Softmax函数。
请注意观察3个Output节点,如果只是看其中一个节点的话,它实际上就是一个普通的非线性模型。
由于1、2、3三个节点的数据之和不一定等于1,Softmax函数的目的就是要使得最终输出的三个数字之和为1,这样数字本身就可以表示概率了。其计算方法也非常简单:

最后我们看一下这个网络的摘要信息:
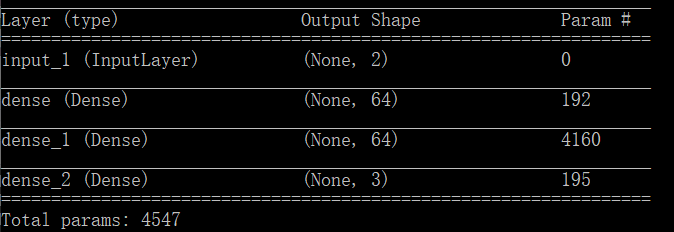
第一层网络的训练参数数量:(2+1)*64=192
第二层网络的训练参数数量:(64+1)*64=4160
输出层网络的训练参数数量:(64+1)*3=195
3、训练网络
(NDArray train_x, NDArray train_y) = PrepareData(1000);
model.compile(optimizer: keras.optimizers.Adam(0.001f),
loss: keras.losses.SparseCategoricalCrossentropy(),
metrics: new[] { "accuracy" });
model.fit(train_x, train_y, batch_size: 128, epochs: 300);
这里注意一点:损失函数采用稀疏分类交叉熵(SparseCategoricalCrossentropy)方法,对于分类任务,大部分时候都是采用分类交叉熵方法作为损失函数。
下面为二值交叉熵的实现公式:
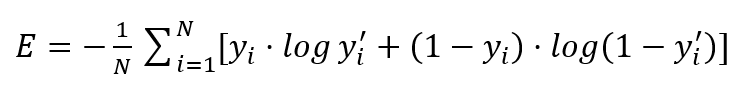
可以不用看公式,简单理解交叉熵的含义:就是如果标记值为1时预测值接近1 或 标记值为0时预测值接近0 则损失函数的值就会比较小。
比如标记值为[1,0,0],预测值为[0.99,0.01,0],则损失比较小,反之,如果预测值为[0.1,0.1,0.8],则损失比较大。
下面时一个二值交叉熵的实现方法:
private Tensor BinaryCrossentropy(Tensor x, Tensor y)
{
var shape = tf.reduce_prod(tf.shape(x));
var count = tf.cast(shape, TF_DataType.TF_FLOAT);
x = tf.clip_by_value(x, 1e-6f, 1.0f - 1e-6f);
var z = y * tf.log(x) + (1 - y) * tf.log(1 - x);
var result = -1.0f / count * tf.reduce_sum(z);
return result;
}
稀疏分类交叉熵和二值交叉熵的区别在于:二值交叉熵需要对标记结果进行独热编码(one-hot),而稀疏分类交叉熵则不需要。
前面提到,我们对分类结果进行标记,其中,偏瘦标记为0,正常标记为1,偏胖标记为2;而采用二值交叉熵进行计算时,偏瘦标记为[1,0,0],正常标记为[0,1,0],偏胖标记为[0,0,1] 。
4、保存和消费模型
训练完成后,我们通过消费这个模型来检查模型的准确性。
/// <summary>
/// 消费模型
/// </summary>
private void test(Model model)
{
int test_size = 20;
for (int i = 0; i < test_size; i++)
{
float weight = (float)random.Next(40, 90) / 100;
float height = (float)random.Next(145, 185) / 100;
float bmi = (weight * 100) / (height * height); var test_x = np.array(new float[1, 2] { { weight, height } });
var pred_y = model.Apply(test_x); Console.WriteLine($"{i}:weight={(float)weight} \theight={height} \tBMI={bmi:0.0} \tPred:{pred_y[0].numpy()}");
}
}
下面为测试结果:
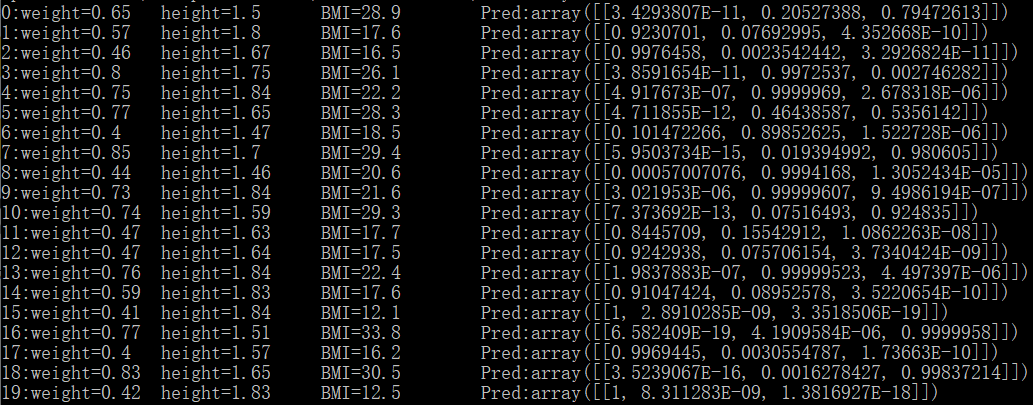
随便看两条数据:当BMI为30.5时,预测结果为[0,0.0016,0.9983];当BMI为12.5时,预测结果为:[1,0,0],可见结果还是准确的。
全部代码如下:


/// <summary>
/// 通过神经网络来实现多元分类
/// </summary>
public class NN_MultipleClassification_BMI
{
private readonly Random random = new Random(1); // 网络参数
int num_features = 2; // data features
int num_classes = 3; // total output . public void Run()
{
var model = BuildModel();
model.summary(); Console.WriteLine("Press any key to continue...");
Console.ReadKey(); (NDArray train_x, NDArray train_y) = PrepareData(1000);
model.compile(optimizer: keras.optimizers.Adam(0.001f),
loss: keras.losses.SparseCategoricalCrossentropy(),
metrics: new[] { "accuracy" });
model.fit(train_x, train_y, batch_size: 128, epochs: 300); test(model);
} /// <summary>
/// 构建网络模型
/// </summary>
private Model BuildModel()
{
// 网络参数
int n_hidden_1 = 64; // 1st layer number of neurons.
int n_hidden_2 = 64; // 2nd layer number of neurons. var model = keras.Sequential(new List<ILayer>
{
keras.layers.InputLayer(num_features),
keras.layers.Dense(n_hidden_1, activation:keras.activations.Relu),
keras.layers.Dense(n_hidden_2, activation:keras.activations.Relu),
keras.layers.Dense(num_classes, activation:keras.activations.Softmax)
}); return model;
} /// <summary>
/// 加载训练数据
/// </summary>
/// <param name="total_size"></param>
private (NDArray, NDArray) PrepareData(int total_size)
{
float[,] arrx = new float[total_size, num_features];
int[] arry = new int[total_size]; for (int i = 0; i < total_size; i++)
{
float weight = (float)random.Next(30, 100) / 100;
float height = (float)random.Next(140, 190) / 100;
float bmi = (weight * 100) / (height * height); arrx[i, 0] = weight;
arrx[i, 1] = height; switch (bmi)
{
case var x when x < 18.0f:
arry[i] = 0;
break; case var x when x >= 18.0f && x <= 28.0f:
arry[i] = 1;
break; case var x when x > 28.0f:
arry[i] = 2;
break;
}
} return (np.array(arrx), np.array(arry));
} /// <summary>
/// 消费模型
/// </summary>
private void test(Model model)
{
int test_size = 20;
for (int i = 0; i < test_size; i++)
{
float weight = (float)random.Next(40, 90) / 100;
float height = (float)random.Next(145, 185) / 100;
float bmi = (weight * 100) / (height * height); var test_x = np.array(new float[1, 2] { { weight, height } });
var pred_y = model.Apply(test_x); Console.WriteLine($"{i}:weight={(float)weight} \theight={height} \tBMI={bmi:0.0} \tPred:{pred_y[0].numpy()}");
}
}
}
【相关资源】
源码:Git: https://gitee.com/seabluescn/tf_not.git
项目名称:NN_MultipleClassification_BMI
TensorFlow.NET机器学习入门【4】采用神经网络处理分类问题的更多相关文章
- TensorFlow.NET机器学习入门【3】采用神经网络实现非线性回归
上一篇文章我们介绍的线性模型的求解,但有很多模型是非线性的,比如: 这里表示有两个输入,一个输出. 现在我们已经不能采用y=ax+b的形式去定义一个函数了,我们只能知道输入变量的数量,但不知道某个变量 ...
- TensorFlow.NET机器学习入门【5】采用神经网络实现手写数字识别(MNIST)
从这篇文章开始,终于要干点正儿八经的工作了,前面都是准备工作.这次我们要解决机器学习的经典问题,MNIST手写数字识别. 首先介绍一下数据集.请首先解压:TF_Net\Asset\mnist_png. ...
- TensorFlow.NET机器学习入门【6】采用神经网络处理Fashion-MNIST
"如果一个算法在MNIST上不work,那么它就根本没法用:而如果它在MNIST上work,它在其他数据上也可能不work". -- 马克吐温 上一篇文章我们实现了一个MNIST手 ...
- TensorFlow.NET机器学习入门【7】采用卷积神经网络(CNN)处理Fashion-MNIST
本文将介绍如何采用卷积神经网络(CNN)来处理Fashion-MNIST数据集. 程序流程如下: 1.准备样本数据 2.构建卷积神经网络模型 3.网络学习(训练) 4.消费.测试 除了网络模型的构建, ...
- TensorFlow.NET机器学习入门【8】采用GPU进行学习
随着网络越来约复杂,训练难度越来越大,有条件的可以采用GPU进行学习.本文介绍如何在GPU环境下使用TensorFlow.NET. TensorFlow.NET使用GPU非常的简单,代码不用做任何修改 ...
- TensorFlow.NET机器学习入门【0】前言与目录
曾经学习过一段时间ML.NET的知识,ML.NET是微软提供的一套机器学习框架,相对于其他的一些机器学习框架,ML.NET侧重于消费现有的网络模型,不太好自定义自己的网络模型,底层实现也做了高度封装. ...
- TensorFlow.NET机器学习入门【1】开发环境与类型简介
项目开发环境为Visual Studio 2019 + .Net 5 创建新项目后首先通过Nuget引入相关包: SciSharp.TensorFlow.Redist是Google提供的TensorF ...
- TensorFlow.NET机器学习入门【2】线性回归
回归分析用于分析输入变量和输出变量之间的一种关系,其中线性回归是最简单的一种. 设: Y=wX+b,现已知一组X(输入)和Y(输出)的值,要求出w和b的值. 举个例子:快年底了,销售部门要发年终奖了, ...
- 45、Docker 加 tensorflow的机器学习入门初步
[1]最近领导天天在群里发一些机器学习的链接,搞得好像我们真的要搞机器学习似的,吃瓜群众感觉好神奇呀. 第一步 其实也是最后一步,就是网上百度一下,Docker Toolbox,下载下来,下载,安装之 ...
随机推荐
- Beautiful Soup解析库的安装和使用
Beautiful Soup是Python的一个HTML或XML的解析库,我们可以用它来方便地从网页中提取数据.它拥有强大的API和多样的解析方式.官方文档:https://www.crummy.co ...
- 学习java的第九天
一.今日收获 1.java完全学习手册第二章程序流程控制中的顺序结构与选择结构 2.学习了java中选择的一些语句和关键词 二.今日问题 1.例题验证有错的情况 2.哔哩哔哩教学视频的一些术语不太理解 ...
- 25. Linux下gdb调试
1.什么是core文件?有问题的程序运行后,产生"段错误 (核心已转储)"时生成的具有堆栈信息和调试信息的文件. 编译时需要加 -g 选项使程序生成调试信息: gcc -g cor ...
- [web安全] 利用pearcmd.php从LFI到getshell
有一段时间没写blog了,主要是事多,加上学的有些迷茫,所以内耗比较大.害,沉下心好好学吧. 漏洞利用背景: 允许文件包含,但session等各种文件包含都已经被过滤了.ctf题中可以关注regist ...
- 【leetcode】212. Word Search II
Given an m x n board of characters and a list of strings words, return all words on the board. Each ...
- mysql删除数据后不释放空间问题
如果表的引擎是InnoDB,Delete From 结果后是不会腾出被删除的记录(存储)空间的. 需要执行:optimize table 表名; eg:optimize table eh_user_b ...
- 转 proguard 混淆工具的用法 (适用于初学者参考)
转自:https://www.cnblogs.com/lmq3321/p/10320671.html 一. ProGuard简介 附:proGuard官网 因为Java代码是非常容易反编码的,况且An ...
- spring boot集成swagger文档
pom <!-- swagger --> <dependency> <groupId>io.springfox</groupId> <artifa ...
- 【Linux】【Services】【MessageQueue】搭建高可用rabbitMQ
1. 简介 1.1. 官方网站: https://www.rabbitmq.com/ 1.2. 配置文档:https://docs.openstack.org/ha-guide/shared-mess ...
- 【Linux】【Commands】文本查看类
分屏查看命令:more和less more命令: more FILE 特点:翻屏至文件尾部后自动退出: less命令: less FILE head命令: 查看文件的前n行: head [option ...