Mysql—— 内连接、左连接、右连接以及全连接查询
CREATE TABLE `a_table` (
`a_id` int(11) DEFAULT NULL,
`a_name` varchar(10) DEFAULT NULL,
`a_part` varchar(10) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE TABLE `b_table` (
`b_id` int(11) DEFAULT NULL,
`b_name` varchar(10) DEFAULT NULL,
`b_part` varchar(10) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8

内连接
关键字:inner join on
语句:
select * from a_table a inner join b_table b on a.a_id = b.b_id;
执行结果:

说明:组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集(阴影)部分。

左连接(左外连接)
关键字:left join on / left outer join on
语句:
select * from a_table a left join b_table b on a.a_id = b.b_id;
执行结果:
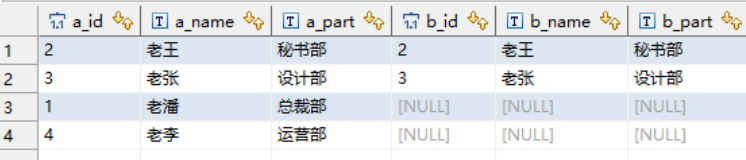
- left join 是left outer join的简写,它的全称是左外连接,是外连接中的一种。
- 左连接会显示主表(左表)的全部记录,右表只会显示符合连接条件的数据,不符合的为null

右连接(右外连接)
关键字:right join on / right outer join on
语句:
select * from a_table a right outer join b_table b on a.a_id = b.b_id;
执行结果:

- right join是right outer join的简写,它的全称是右外连接,是外连接中的一种。
- 与左(外)连接相反,右(外)连接,显示右表(主表)所有记录,左表只会显示符合连接条件的数据,不符合的为null

on、where、Having的区别
在使用left jion时,on和where条件的区别如下:
1、 on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
2、where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
on、where、having这三个都可以加条件的子句中,on是最先执行,where次之,having最后。有时候如果这先后顺序不影响中间结果的话,那最终结果是相同的。但因为on是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的。
根据上面的分析,可以知道where也应该比having快点的,因为它过滤数据后才进行sum,所以having是最慢的。但也不是说having没用,因为有时在步骤3还没出来都不知道那个记录才符合要求时,就要用having了。
在两个表联接时才用on的,所以在一个表的时候,就剩下where跟having比较了。在这单表查询统计的情况下,如果要过滤的条件没有涉及到要计算字段,那它们的结果是一样的,只是where可以使用rushmore技术,而having就不能,在速度上后者要慢。
如果要涉及到计算的字段,就表示在没计算之前,这个字段的值是不确定的,根据上篇写的工作流程,where的作用时间是在计算之前就完成的,而having就是在计算后才起作用的,所以在这种情况下,两者的结果会不同。
在多表联接查询时,on比where更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表后,再由where进行过滤,然后再计算,计算完后再由having进行过滤。由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什幺时候起作用,然后再决定放在那里
JOIN联表中ON,WHERE后面跟条件的区别
对于JOIN的连表操作,这里就不细述了,当我们在对表进行JOIN关联操作时,对于ON和WHERE后面的条件,不清楚大家有没有注意过,有什幺区别,可能有的朋友会认为跟在它们后面的条件是一样的,你可以跟在ON后面,如果愿意,也可以跟在WHERE后面。它们在ON和WHERE后面究竟有一个什幺样的区别呢?
在JOIN操作里,有几种情况。LEFT JOIN,RIGHT JOIN,INNER JOIN等。
为了清楚的表达主题所描述的问题,我简要的对LEFT,RIGHT,INNER这几种连接方式作一个说明。
下面就拿一个普通的博客系统的日志表(post)和分类表(category)来描述吧。
这里我们规定有的日志可能没有分类,有的分类可能目前没有属于它的文章。
1.LEFT JOIN:(保证找出左联表中的所有行)
查出所有文章,并显示出他们的分类:
SELECT p.title,c.category_name
FROM post p
LEFT JOIN category c ON p.cid = c.cid2.
RIGHT JOIN:(保证找出右联表中的所有行)
查询所有的分类,并显示出该分类所含有的文章数。
SELECT COUNT(p.id),c.category_name
FROM post p
RIGHT JOIN category c ON p.pid = c.cid3.
INNER JOIN:(找出两表中关联相等的行)
查询有所属分类的日志。(即那些没有所性分类的日志文章将不要我们的查询范围之内)。
SELECT p.title,c.category_name
FROM post p
INNER JOIN category c ON p.cid = c.cid.这种情况和直接两表硬关联等价。
现在我们回过头来看上面的问题。对于第一种情况,如果我们所ON 的条件写在WHERE 后面,将会出现什幺情况呢?即:
SELECT p.title,c.category_name
FROM post p
LEFT JOIN category c
WHERE p.cid = c.cid
对于第二种情况,我们同样按照上面的书写方式。
SELECT COUNT(p.id),c.category_name
FROM post p
RIGHT JOIN category c
WHERE p.pid = c.cid
如果运行上面的SQL语句,就会发现,它们已经过滤掉了一些不满足条件的记录,可能在这里,大家会产生疑问了,不是用了LEFT和RIGHT吗?它们可以保证左边或者右边的所有行被全部查询出来,为什幺现在不管用了呢?对于出现这种的问题,呵呵!是不是觉得有些不可思议。出现这种的问题,原因就在WHERE和ON这两个关键字后面跟条件。
好了,现在我也不调大家味口了,给大家提示答案吧。
对于JOIN参与的表的关联操作,如果需要不满足连接条件的行也在我们的查询范围内的话,我们就必需把连接条件放在ON后面,而不能放在WHERE后面,如果我们把连接条件放在了WHERE后面,那幺所有的LEFT,RIGHT,等这些操作将不起任何作用,对于这种情况,它的效果就完全等同于INNER连接。对于那些不影响选择行的条件,放在ON或者WHERE后面就可以。
记住:所有的连接条件都必需要放在ON后面,不然前面的所有LEFT,和RIGHT关联将作为摆设,而不起任何作用。
Mysql—— 内连接、左连接、右连接以及全连接查询的更多相关文章
- oracle 内连接(inner join)、外连接(outer join)、全连接(full join)
转自:https://premier9527.iteye.com/blog/1659689 建表语句: create table EMPLOYEE(EID NUMBER,DEPTID NUMBER,E ...
- Python进阶----多表查询(内连,左连,右连), 子查询(in,带比较运算符)
Python进阶----多表查询(内连,左连,右连), 子查询(in,带比较运算符) 一丶多表查询 多表连接查询的应用场景: 连接是关系数据库模型的主要特点,也是区别于其他 ...
- SQL-内连接、外连接(左、右)、交叉连接
本文测试基于以下两个表,student(左) \ teacher(右),使用数据库MariaDB,图形化界面HeidiSQL. 连接查询的概念:根据两个表或多个表的列之间的关系,从这些表中查询数据,即 ...
- Mysql常用sql语句(18)- union 全连接
测试必备的Mysql常用sql语句系列 https://www.cnblogs.com/poloyy/category/1683347.html 前言 其实Mysql并没有全连接,Oracle才有全连 ...
- 【MySQL 原理分析】之 Explain & Trace 深入分析全模糊查询走索引的原理
一.背景 今天,交流群有一位同学提出了一个问题.看下图: 之后,这位同学确实也发了一个全模糊查询走索引的例子: 到这我们可以发现,这两个sql最大的区别是:一个是查询全字段(select *),而一个 ...
- LINQ 内链接 左链接 右链接
原文地址:http://blog.sina.com.cn/s/blog_46e9573c01014fx2.html 1.左连接: var LeftJoin = from emp in ListOfEm ...
- 最常用SQL joins:内连接(交集)、左外连接、右外连接、左连接、右连接、全连接(并集),全外连接
1.内连接.两个表的公共部分用Inner join,Inner join是交集的部分. Select * from TableA A inner join TableB B on A.key=B.ke ...
- ORACLE 左连接 右连接 内连接 外连接 全连接 五中表连接方式
1.左连接 :left join 2.右连接:right join 3.内连接:inner join 4.外连接:outer join 5.全连接:full join
- 深入理解SQL的四种连接-左外连接、右外连接、内连接、全连接(转)
1.内联接(典型的联接运算,使用像 = 或 <> 之类的比较运算符).包括相等联接和自然联接. 内联接使用比较运算符根据每个表共有的列的值匹配两个表中的行.例如,检索 stude ...
- 【转】深入理解SQL的四种连接-左外连接、右外连接、内连接、全连接
[原文]:http://www.jb51.net/article/39432.htm 1.内联接(典型的联接运算,使用像 = 或 <> 之类的比较运算符).包括相等联接和自然联接. ...
随机推荐
- php设计模式--生成器模式
生成器模式 require "D:\\xxx\bild.php"; require "D:\\xxx\cx_bild.php"; require "D ...
- 使用python3中的2to3.py执行数据迁移
1.在python默认安装的位置找到Tools\scripts 2.找到2to3.py 3.在所在文件夹shift+右键打开终端 4.执行命令python 2to3.py -w 需要做数据迁移的数据路 ...
- C++ 可变数组实现
话不多说,直接上代码,看注释 template<class T> // 支持传入泛型,但string这种可变长度的类型还不支持 class Array { int mSize = 0, m ...
- Vulnhub实战-JIS-CTF_VulnUpload靶机👻
Vulnhub实战-JIS-CTF_VulnUpload靶机 下载地址:http://www.vulnhub.com/entry/jis-ctf-vulnupload,228/ 你可以从上面地址获取靶 ...
- Visual Studio 安装 C++
Visual Studio 安装 C++
- .net 5.0 ref文件夹的作用
ref目录里的dll是一个名为参考组件的东西,微软MSDN给的解释是 参考组件是一种特殊类型的程序集,仅包含表示库的公共API面所需的最小元数据数量.它们包括用于在构建工具中引用程序集时重要的所有成员 ...
- [no code][scrum meeting] Beta 1
$( "#cnblogs_post_body" ).catalog() 会议纪要 会议在微信群进行:集体反思alpha阶段博客分数尤其是scrum博客分数低的问题,讨论beta阶段 ...
- Charles的简单用法
Charles的简单用法 一.抓电脑上 http 包 二.显示请求的 Request 和 Response 三.抓取电脑上 https 包 1.安装根证书 2.在钥匙串中启用根证书 3.配置哪些需要抓 ...
- 2021.7.28考试总结[NOIP模拟26]
罕见的又改完了. T1 神炎皇 吸取昨天三个出规律的教训,开场打完T2 20pts直接大力打表1h. 但怎么说呢,我不懂欧拉函数.(其实exgcd都忘了 于是只看出最大平方因子,不得不线性筛,爆拿60 ...
- python2和python3并存下的pip使用
py -2 -m pip install *.whl py -3 -m pip intall *.wl