基于 RTF specification v1.7 的 RTF 文件解析及 OLE 对象提取(使用 Python 开发)
0x01 Office RTF 文件介绍
- RTF 文件也称富文本格式(Rich Text Format, 一般简称为 RTF),意为多文本格式是由微软公司开发的跨平台文档格式。大多数的文字处理软件都能读取和保存 RTF 文档。RTF 是一种非常流行的文件结构,很多文字编辑器都支持它,vb 等开发工具甚至还提供了 richtxtbox 的控件。

- RTF 和 DOC 文件一样,都属于 Microsoft Office 的范畴,和 DOC 文件类似,RTF 文件也可以进行文字编辑操作,甚至是插入 OLE 对象来增强文件的互操作性,例如公式编辑器、嵌入式 PPT 文件、嵌入式 DOC 文档、WordPad Document 以及位图文件等等。之后为了方便对 DOC 的兼容性操作,提供了将 RTF 文件嵌入 DOC 文档的功能。
- 在 RTF 文件解析和 OLE 对象交互的安全性方面,一直是安全行业以及 APT 组织关注的重点,属于 Office 文件二进制安全。OLE 全称嵌入式对象,是微软为了提升程序互操作性而研究出的成果,当然了其他厂商比如 Apple 和 Mozilla 也有自己的 OLE 嵌入式框架。所以基于这几点准备开发一个 Python 小脚本来解析 RTF 文件以及其中的 OLE 对象,但是网上有很多专门提供对 RTF 文档解析的库(Python 和 C/C++ 都有),为什么还要大费周章的重新写一个呢,因为不想用大炮打苍蝇,而且只是自己用而已。
0x02 根据 RTF Specification Version 1.7 分析 RTF 文件
- RTF Specification Version 1.7 是 RTF 的文件规范,就如下图所示:
- 这个版本是 1.7 版本,最新的版本好像是 1.9,按理说 RTF 文件如今的利用已经很广泛了,但是微软的最新的 RTF 文件规范就是搜不到。故使用较为旧的 1.7 版本,因为版本较旧在解析较新的文档时,还是有一些控制字解析不出来。
- 废话不多扯了,下面来分析 RTF 文件的解析方法。首先创建一个 RTF 文件,注意需要使用文档打开最好添加一些任意字符,不然文件的大小为 0(处于未初始化状态),之后使用 16 进制编辑器查看文件二进制内容。如下图所示,左边是 16 进制格式,右边是 ASCII 格式。从 ASCII 格式可以看出这个 RTF 文档除了字母还有一些字符,例如 "
\\“、”{“、”*“、”;",暂且将它们定为特殊字符。

- 这些特殊字符遵从 RTF 文件语法规范,RTF 语法规范有这几种:控制字、控制符、未格式化文本和组。未格式化文本就不用说了,就是文本文档。控制字是 RTF 用来标记打印控制符和管理文档信息的一种特殊格式的命令,一个控制字最长 32 个字符。控制字的使用格式如下
\字母序列<分隔符>,比如上图中的\rtf1和\ansi就是控制字;而组就更简单了,语法格式为{ },功能是文本、控制字、控制符的集合。最后是控制符,控制符由一个反斜线\跟随单个非字母字符组成,例如,\~代表一个不换行空格,控制符不需要分隔符。某些控制字, 称为引用,用于标记可能在同一文件中的其他位置出现的相关文本集合或者其他引用的开始位置。引用也可以是被使用的但是未必出现于文档中的文本。格式:\*\。
注:(1)组和控制字是解析 RTF 文件的十分重要的部分,起着框架和支撑作用,在指定算法时需要尤其小心,不然会导致后面的解析出现意想不到的 Bug(2)控制字、控制符、未格式化文本和组是排列组合或者顺序排列的关系,在没有专门说明的情况下不存在附属关系,所以解析时需要注意 (3)对于文档中的控制字在 RTF 文件规范中基本上都会有详细的解释
- 除了 RTF 语法规范还有就是 RTF 语法形式,这个比较易懂,如下图所示:

0x03 制定解析算法
- 解析 RTF 文件之前所必须要考虑的就是算法问题,好的算法能够精确对 RTF 语法进行分割和识别。
a) 组平衡算法
- 在解析正常的 RTF 文件时组一定是平衡的,举个例子:
{ { 1 } { { 2 } } },最外面的组嵌套着两个小组,第一个组包含文本字符 1,第二个组里面又包含一个组并且这个组包含文本字符 2。虽然说嵌套关系比较复杂,但是组的{和}始终是一样多的,因为始终需要完成包裹。当然了,这个是正常的文件,谁也不敢保证损坏的 RTF 文档当中的组也是平衡的,所以需要组平衡算法来判断组是否有损坏,代码如下图所示:
# 组平衡判断
def balance(data, seek):
local_1 = 0;
for i in data:
if(i == '{'):
local_1 += 1;
if(i == '}'):
local_1 -= 1;
local_1 += seek;
if(local_1 == 0):
return True;
return False;
- 算法很简单,循环遍历传入的数据 data,假如碰到
{就将 local_1 变量减去 1;同样的假如碰到}就将 local_1 变量加上 1,最后通过判断 local_1 是否为 0 来判断 data 中的组是否平衡。算法中的 seek 起着控制作用,一般情况下传入的是 0。
注:相比于正常的文件,其实损坏的文件也可以进行强制的解析,主要是通过算法修复损坏的组或者直接将损坏的组丢弃掉。由于组修复超出了文章的讨论范围,所以不在多述
b) 控制字和组分离算法
- 在组平衡的前提下可以开展组解析,组解析算法的目的就是将组分离开并储存在变量当中,由于组与组是嵌套关系所以解析时需要确定解析等级,比如
{ { 1 } { 2 { 3 } } { 4 } },在一级解析的情况下为{ { 1 } { 2 { 3 } } { 4 } },二级解析为{ { 1 } { 2 { 3 } } { 4 } },{ 1 },{ 2 { 3 } },{ 4 },三级解析为{ { 1 } { 2 { 3 } } { 4 } },{ 1 },{ 2 { 3 } },{ 3 },{ 4 },解析算法如下:
# 核心函数, 将数据解析, 得出控制字和组
def rtfAnalysis(data):
# 对数据进行组平衡判断
if(balance(data, 0) == False):
print("[-] 解析出错, RTF 组格式损坏");
exit(0);
# - 组控制字解析算法:
# 根据 RTF 1.7 文档规范以及解析的功能, 对 RTF 数据中的 \ 、 \\ 、 { 、 } 字符对文件进行分割, 达到分离
# 控制字和组的目的, 之后使用 python 独有的切片操作, 将分割后的字符储存在集合中, 最后返回集合, 达到分离
# 并解析 RTF 数据的目的, 本算法可能在效率上不及压入弹出算法
local_1 = 0; local_2 = 0; local_3 = 0; listgroup1 = []; listgroup2 = [];
for i in data:
if(i == '\\' and local_3 == 0):
if(data[local_1 + 1] != '*' and data[local_1 - 1] != '*' ):
listgroup1.append(i); listgroup2.append(local_1);
elif(data[local_1 + 1] == '*'):
listgroup1.append(i); listgroup2.append(local_1);
if(i == '{' or i == '}'):
local_3 = 1;
if(i == '{'):
if(local_2 == 0):
listgroup1.append(i); listgroup2.append(local_1);
local_2 += 1;
if(i == '}'):
local_2 -= 1;
if(local_2 == 0):
listgroup1.append(i); listgroup2.append(local_1);
local_3 = 0;
local_1 += 1;
local_1 = 0; local_2 = 0; local_3 = 0; listgroup3 = {};
for list1 in listgroup1:
if(local_1 < len(listgroup2) - 1):
if(list1 == '\\'):
listgroup3[listgroup2[local_1]] = data[listgroup2[local_1]:listgroup2[local_1 + 1]].strip();
elif(list1 == '{'):
listgroup3[listgroup2[local_1]] = data[listgroup2[local_1]:listgroup2[local_1 + 1] + 1];
else:
if(list1 != '}'):
listgroup3[listgroup2[local_1]] = data[listgroup2[local_1]:len(data) + 1].strip();
local_1 += 1;
return listgroup3;
- 上述算法首先使用第一个循环对 data 数据进行判断,如果遇到
}{\字符,就将它们的位置放入listgroup1数组。之后使用第二个循环对listgroup1数组进行遍历,利用 python 特有的切片操作分离出完整的控制字、控制符和组,并且将结果放入listgroup3中。最后返回listgroup3。
注:需要注意的是在第一个循环中的控制字判断的时候需要注意引用控制字,也就是
\*\。同样的在进行组操作的时候需要判断哪一个是组开头,并且哪一个是组结尾,这里使用了local2和local3两个变量帮助进行判断。在第二个循环当中的切片操作需要注意切片时不能大于整个 data 数据的大小,否则会发生数组越界异常
c) 组嵌套和控制字查找算法
- 组嵌套算法和组分离算法不同,组嵌套算法主要是为了识别组与组之间的嵌套关系的,比如分析一个 OLE 嵌入式对象,该对象可能在文件的任何位置(可能和 \rtf 控制字在同一级,也可能在文档区的某个组段落之中),这时就需要确定 OLE 对象所在的组是什么样的嵌套关系。控制字查找算法借鉴了移动窗口算法,使用移动窗口进行查找。代码如下:
# 查找特定的组, 记录其组嵌套关系, 并返回完整的组
def searchGroup(data, findStr):
WSize = len(findStr); WSPosition = [];
for i in range(len(data)+1):
if(i + WSize == len(data) - 3):
break;
CWData = data[i:i + WSize];
if(CWData == findStr):
WSPosition.append(i);
local_1 = 0; local_2 = 0; dict1 = {};
for m in WSPosition:
grouplist = [];
for n in data[0:m]:
if(n == '{'):
grouplist.append(local_1);
if(n == '}'):
grouplist.pop();
local_1 += 1;
dict1[m] = grouplist;
local_1 = 0;
return dict1;
- 上述代码当中的第一个循环用于查找特定的控制字,比如
/object对象控制字,首先计算出对象的大小WSize,之后使用data[i:i + WSize]切片操作将 data 数据中的/object查找出来,并且将它的位置储存在WSPosition中。而第二个循环用于确定组嵌套关系,使用的模拟堆栈压入和弹出操作,比如{ { } { {\object} } }这个例子,\object被包裹了两个组,因为上面的查找控制字算法得出了控制字的位置,所以进行切片操作,切片完成之后就会变成这个样子{ { } { {,之后进行循环遍历操作,如果遇到{就将其位置压入堆栈,如果遇到}就将最近压入的{的位置弹出来,所以就可以成功的避开完整的组,同时也得出了外面包裹的组的头位置,最后将这些信息储存在 dict1 中并返回。
注: 需要注意的是,第一个循环的滑动窗口不能越出 data 数据的最大大小,不然会引发数组越界异常
0x04 制定脚本功能
- 既然解析算法都已经定下来了,那么下面就需要考虑功能性的问题了。RTF 文档中的解析主要是对控制字进行解析,而各个控制字的解释在 RTF 文档格式规范中基本都有所提及,只是格式各不一样。考虑到本脚本主要是简单分析 RTF 文件格式和提取其中的 OLE 对象(如果有的话),所以不必将文档中的所有的控制字都给解析出来。基于此目的得出这样几个功能:(1) -l : 列出所有组和控制字符 (2) -i : 对文件进行基本解析 (3) -o : 解析文件中的 ole 对象。
a) 列出所有组和控制字符
- 基于控制字和组分离算法,将所有的控制字和组打印出来,并根据传入的参数制定打印的深度,也就是循环解析嵌套组的深度,目前支持 1 和 2 两个等级的深度。
b) 对文件进行基本解析
- 基本解析包括对 RTF 文件头和文档区头的基本解析,解析出诸如 RTF 版本信息、字符集、Unicode RTF 版本、创建时间、作者信息以及打印出各个控制字。
c) 解析文件中的 ole 对象
- 基于控制字查找算法,查找出本文档是否含有 OLE 嵌入式对象格式,如果含有的话,提炼出完整的 OLE 对象,并且打印出对象的基本信息和输入输出流。
0x05 编写脚本
- 首先在脚本的头部指定
#-*-coding:utf-8-*-,防止乱码。然后按照基本流程指定脚本的 main 函数。之后使用OptionParser库对传入的参数进行识别和控制,并且更具传入的参数转移到相应的函数进行处理,如下图所示:
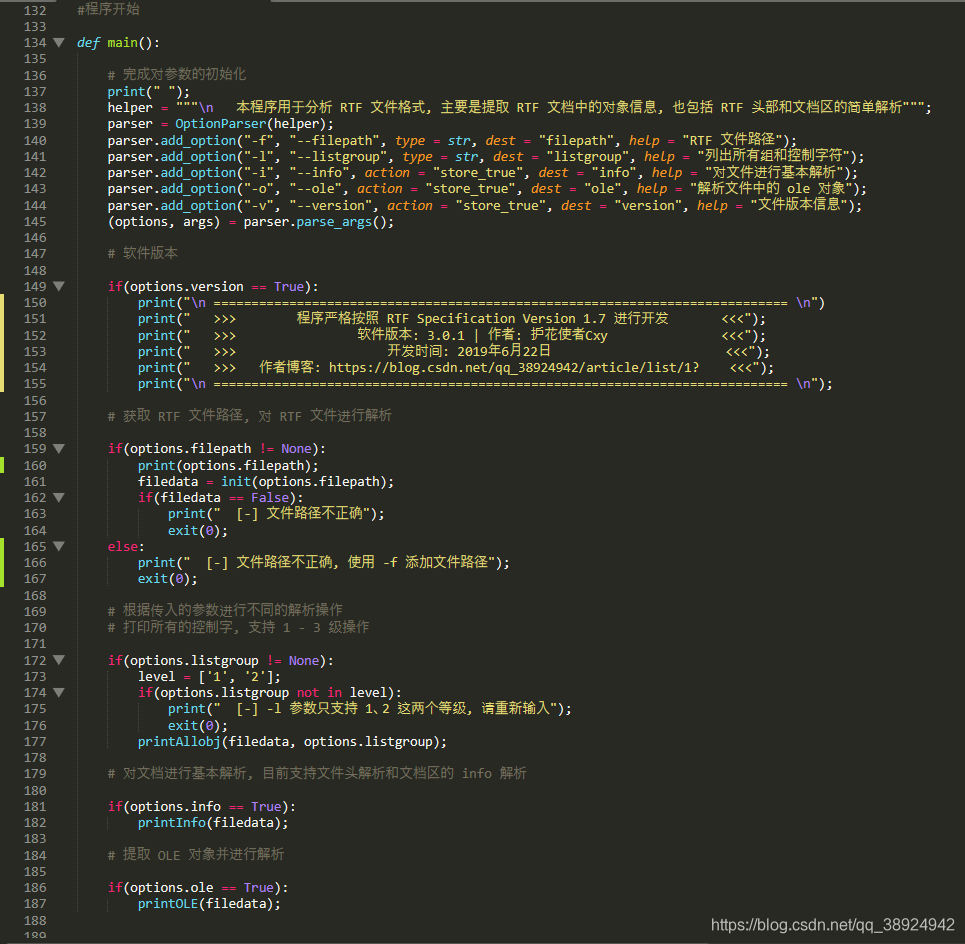
- 需要注意的是在使用函数进行处理之前,首先会使用
init()函数对使用 -f 参数传入的文件路径做基本判断,判断是否是一个标准的 RTF 文件,并且判断此文件是否存在。判断方法如下图所示:
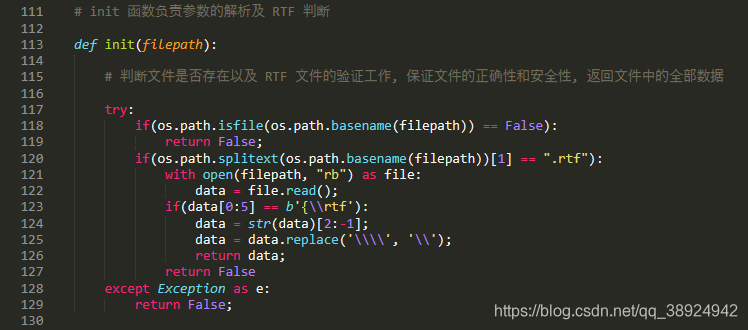
- 在文件判断成功之后就会进入文件处理环结:
a) 使用 printAllobj() 函数打印所有的组和控制字符
- 代码如下所示,根据解析的深度使用 rtfAnalysis 函数获取组和控制字的集合,并依次将它们打印出来。
# 根据解析的结果打印组和控制字
def printAllobj(data, level):
# 该函数主要为了打印出二级和三级列表下的组或控制字, 完成对 RTF 文件的基本解析
print(" [+] 开始解析: ");
print(" [*] 注: \">\" 代表一级组列表下的或控制字 ; \">>\" 代表二级列表下的组或控制字 ; \">>>\" 代表三级列表下的组或控制字");
print(" ")
group = rtfAnalysis(data);
local_1 = 0; local_2 = 0; local_3 = 0;
for i in group:
local_1 += 1;
if(group[i][0] == '{'):
print(" >>>", group[i][0:30], "......", group[i][-30:]);
listgroup = rtfAnalysis(group[i][1:-1]);
for m in listgroup:
local_2 += 1;
if(listgroup[m][0] == '{'):
print(" >>", listgroup[m][0:30], "......", listgroup[m][-30:]);
if(level == "2"):
listgroup1 = rtfAnalysis(listgroup[m][1:-1]);
for n in listgroup1:
local_3 += 1;
if(listgroup1[n][0] == '{'):
print(" >", listgroup1[n][0:30], "......", listgroup1[n][-30:]);
else:
if(listgroup1[n][1] == '\''):
pass
else:
print(" >", listgroup1[n]);
else:
if(listgroup[m][1] == '\''):
pass
else:
print(" >>", listgroup[m]);
else:
if(group[i][1] == '\''):
pass
else:
print(" >>>", group[i]);
print("\n [+] 解析完毕");
print(" [+] 结果:");
print(" [>] 一级对象或控制字总个数:", local_1, "|", "二级对象或控制字总个数:", local_2, "|", "三级对象或控制字总个数:", local_3);
print(" [>] RTF 对象格式完好, 不存在缺失状况\n");
print(" [+] 如需要更详细的了解某些控制字和组, 可以参照 RTF 规范文档");
b) 使用 printInfo() 函数对文档进行基本解析
- 代码如下所示:
# 打印 RTF 文件基本信息
def printInfo(data):
group1 = rtfAnalysis(data);
if(group1[0][0:5] != "{\\rtf"):
return False;
group2 = rtfAnalysis(group1[0][1:-1]);
group1 == {};
for i in group2:
if(group2[i][0] == '{'):
break;
group1[i] = group2[i];
RTF_characterSet = {"\\ansi":"ANSI (默认)", "\\mac":"Apple Macintosh", "\\pc":"IBM PC code page 437", "\\pca":"IBM PC code page 850"};
RTF_deffont = {"\\stshfdbch":"远东字符", "\\stshfloch":"ASCII字符", "\\stshfhich":"High-ANSI字符", "\\stshfbi":"Complex Scripts (BiDi)字符"};
RTF_group = {"\\fonttbl":"字体表", "\\filetbl":"文件表", "\\colortbl":"颜色表", "\\stylesheet":"样式表", "\\listtable":"编目表", " \\*\\rsidtbl":"RSID", "\\*\\generator":"生成器"};
# 开始解析 RTF 头部信息
print(" > 开始解析:\n\n # 文件头部信息:\n");
# 解析 RTF 版本
list1 = [];
for i in group1:
list1.append(group1[i]);
rtfN = list1[0];
rtfVersion = rtfN[rtfN.find("\\rtf") + len("\\rtf"):];
print(" [+] RTF 版本号:", rtfVersion);
# 解析字符集
local_1 = 0;
for m in list1:
for n in RTF_characterSet:
if(m == n):
print(" [+] 字符集:", n[1:]);
local_1 = 1;
if(local_1 == 0):
print(" [+] RTF 文件缺少字符集");
# 解析默认 Unicode RTF
for m in list1:
if(m.find("\\ansicpg") != -1):
print(" [+] Unicode RTF(\\ansicpg):", m[m.find("\\ansicpg") + len("\\ansicpg"):]);
# 解析控制字 deffont
local_1 = 0;
for m in list1:
for n in RTF_deffont:
if(m.find(n) != -1):
print(" [*]", n[1:], ":", m[m.find(n) + len(n):]);
local_1 = 1;
if(local_1 == 0):
print(" [+] RTF 文件缺少 deffont 控制字");
# 解析其他文件头部中存在的可被解析的组对象
print("\n [+] RTF 文件头部被解析出的其他对象: \n");
for m in group2:
for n in RTF_group:
if(group2[m].find(n) != -1):
print(" [+]", n,"(", RTF_group[n], ")");
print(" ");
# 开始解析 RTF 文档区信息
c) 使用 printOLE() 函数解析 RTF 文件的 OLE 对象
- 代码如下所示:
# 解析 RTF 文件的 OLE 对象
def printOLE(data):
olestr = "\\object";
if(balance(data, 0) == False):
print("[-] RTF 文件中的组不平衡, 文件可能损坏, 但不影响分析");
dict1 = searchGroup(data, olestr);
# 开始解析 RTF 文件中的 OLE 对象
print("# 开始解析 RTF 文件中的 OLE 对象...\n");
# 打印 RTF 文件中的对象个数
count = 0;
for i in dict1:
count += 1;
print(" [+] RTF 文件中的 OLE 对象个数:", count);
# 根据对象的首位置取出完整的对象
count = 1; count1 = 0; ole = {};
for m in dict1:
olestart = dict1[m][-1];
olend = olestart;
for n in data[olestart:]:
if(n == '{' or n == '}'):
if(n == '{'):
count += 1;
if(n == '}'):
count -= 1;
if(count == 1):
break;
olend += 1;
ole[m] = data[olestart:olend + 1];
# 打印对象的嵌套关系和基本信息
obj_objtype = {"\\objemb":"OLE嵌入对象类型", "\\objlink":"OLE链接对象类型", "\\objautlink":"OLE自动链接对象类型", "\\objsub":"Macintosh版管理签署对象类型", "\\objpub":"Macintosh版管理发布对象类型", "\\objicemb":"MS Word for Macintosh可安装命令(IC)嵌入对象类型", "\\objhtml":"超文本标记语言(HTML)控件对象类型", "\\objocx":"OLE控件类型"};
obj_objmod = {"\\linkself":"该对象为同一文档中的另一部分", "\\objlock":"锁定对象的所有更新操作", "\\objupdate":"强制对象在显示之前更新", "\\*\\objclass":"表示该对象类的文本参数", "\\objname":"表示该对象名称的文本参数", "\\objtime":"列出对象最后更新的时间"};
obj_objinfo = {"\\objhN":"N是以缇表示的对象的原始高度, 假定该对象具有图形表示特性", "\\objwN":"N是以缇表示的对象的原始宽度, 假定该对象具有图形表示特性", "\\objsetsize":"强制对象服务器将对象尺寸设置为客户端给出的尺寸", "\\objalignN":"N是以缇表示的应该对齐制表位的对象的左缩进距离, 用于正确放置公式编辑器方程", "\\objtransyN":"是以缇表示的对象应该参考于基线垂直移动的距离,用于正确放置数学方程式", "\\objcroptN":"N是以缇表示的顶端裁剪值", "\\objcropbN":"N是以缇表示的底端裁剪值", "\\objcroplN":"N是以缇表示的左裁剪值", "\\objcroprN":"N是以缇表示的右裁剪值", "\\objscalexN":"N是水平缩放百分比", "\\objscaleyN":"N是垂直缩放百分比"};
obj_objdata = {"\\objdata":"该子引用包含了特定格式表示的对象数据,OLE对象采用OLESaveToStream结构,这是一个引用控制字", "\\objalias":"该子引用包含了Macintosh编辑管理器发行对象的别名记录,这是一个引用控制字", "\\objsect":"该子引用包含了Macintosh编辑管理器发行对象的域记录,这是一个引用控制字"};
obj_objres = {"\\rsltrtf":"如果可能, 强制结果为RTF", "\\rsltpict":"如果可能, 强制结果为一个Windows图元文件或者MacPict图片格式", "\\rsltbmp":"如果可能, 强制结果为一个位图", "\\rslttxt":"如果可能, 强制结果为纯文本", "\\rslthtml":"如果可能, 强制结果为HTML", "\\rsltmerge":"无论获取任何新的结果均使用当前结果格式", "\\result":"结果目标在\\object目标引用中可选"};
count = 1; count2 = 1;
for k in dict1:
print("\n ======================================================================================================================= \n");
print(" [*] 开始解析第", count, "个对象 (对象处于文件的位置:", k,") : ");
print(" [1] 对象的嵌套关系:");
print(" [!] 一级对象嵌套二级对象, 二级对象嵌套三级对象, 以此类推");
for i in dict1[k]:
print(" ", count2, "级对象 ", data[i:i + 40]);
count2 += 1;
print("\n [+] 当前 OLE 对象处于", count2 - 1, "级嵌套中");
count2 = 0;
# 打印对象基本信息
print("\n [*] 对象的基本信息:");
CWord = rtfAnalysis(ole[k][1:-1]);
for m in CWord:
# 解析对象类型
for n in obj_objtype:
if(CWord[m] == n):
print(" [+] 对象类型:", n, "-", obj_objtype[n]);
# 解析对象信息
for n in obj_objmod:
if(CWord[m].find(n) != -1):
if(CWord[m].find("\\*\\") != -1):
print("\n [!] 对象信息:", n, CWord[m].split()[1][:-1], "-", obj_objmod[n]);
else:
print("\n [!] 对象信息:", n, "-", obj_objmod[n]);
# 解析对象尺寸、位置、裁剪与缩放
for n in obj_objinfo:
if(n.find("N") != -1):
ki = n[0:-1];
seek = CWord[m].find(ki);
if(seek != -1):
if(n.find("N") != -1):
print(" [+] 对象尺寸、位置、裁剪与缩放:", n, " N =", CWord[m][len(n):], "(", obj_objinfo[n], ")");
else:
print(" [+] 对象尺寸、位置、裁剪与缩放:", n, CWord[m][len(n):], "-", obj_objinfo[n]);
# 对象数据
for n in obj_objdata:
if(CWord[m].find(n) != -1 and CWord[m][0] == "{"):
print(" [!] 对象数据:", n, "-", obj_objdata[n]);
# 对象结果
for n in obj_objres:
if(CWord[m].find(n) != -1):
print(" [!] 对象结果:", n, "-", obj_objres[n]);
# 打印对象数据
length = 0;
print("\n [*] 对象输入数据(\\objdata):");
for i in CWord:
if(CWord[i].find("\\objdata") != -1):
length = len(CWord[i]);
print(" ", CWord[i][0:400], "......", CWord[i][-400:]);
print("\n [*] 数据大小: ", length, " 文件中的位置: ", i);
length = 0;
print("\n [*] 对象输出数据(\\result):");
for i in CWord:
if(CWord[i].find("\\result") != -1):
length = len(CWord[i]);
print(" ", CWord[i][0:400], "......", CWord[i][-400:]);
print("\n [*] 数据大小: ", length, " 文件中的位置: ", i);
count += 1;
0x05 脚本测试
- 测试文档以及内容:


a) 打印所有组和控制字
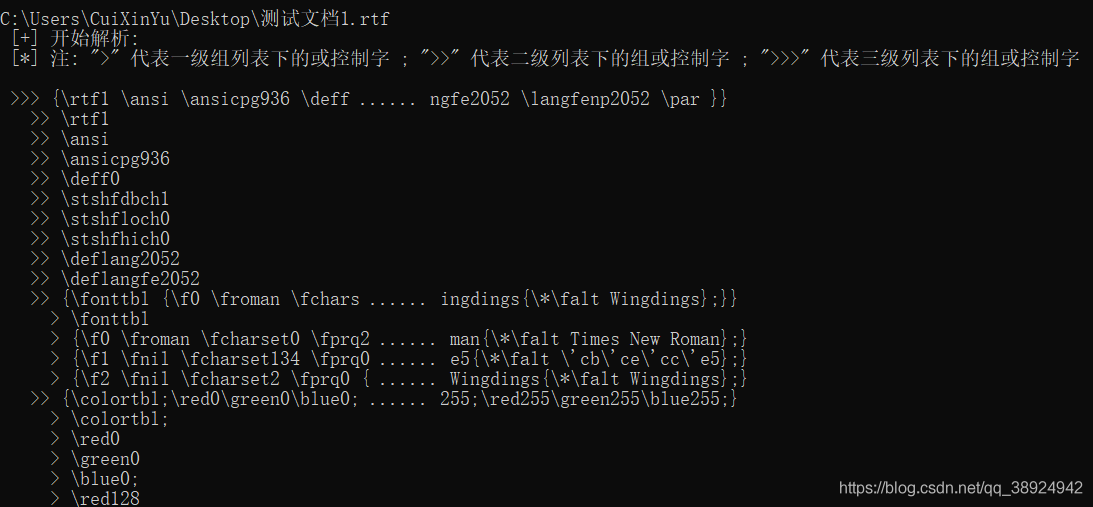
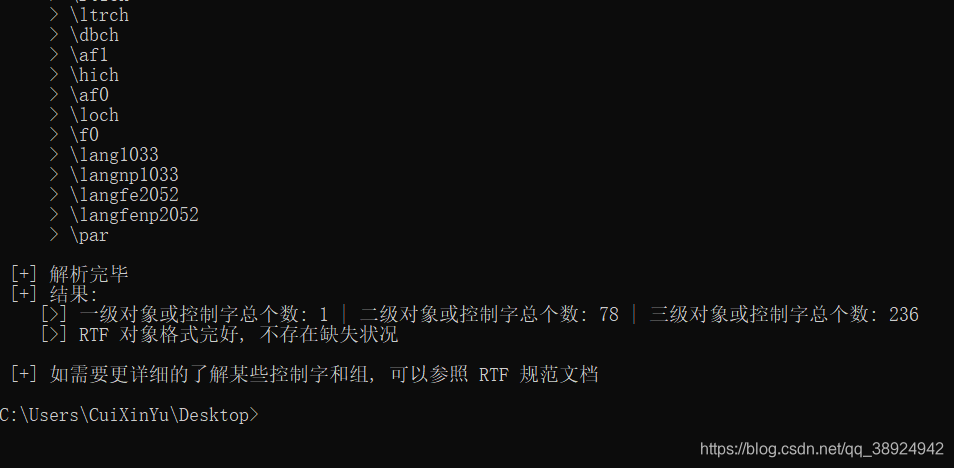
- 测试列出所有的组和控制字,查看是否正常:
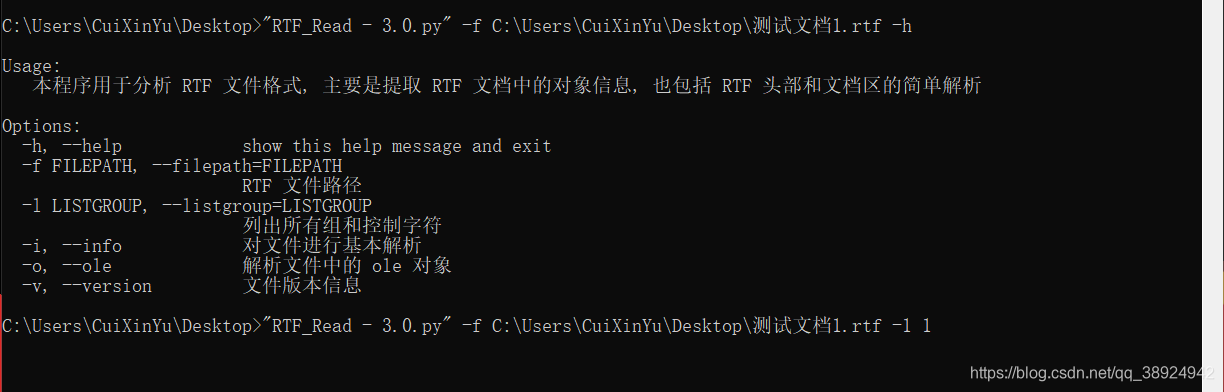
- 如下图所示成功打印出文件的所有组和控制字:
b) 对文件进行基本解析
- 测试使用 -i 参数对文件进行基本解析:

- 解析正常。

c) 解析文件中的 ole 对象
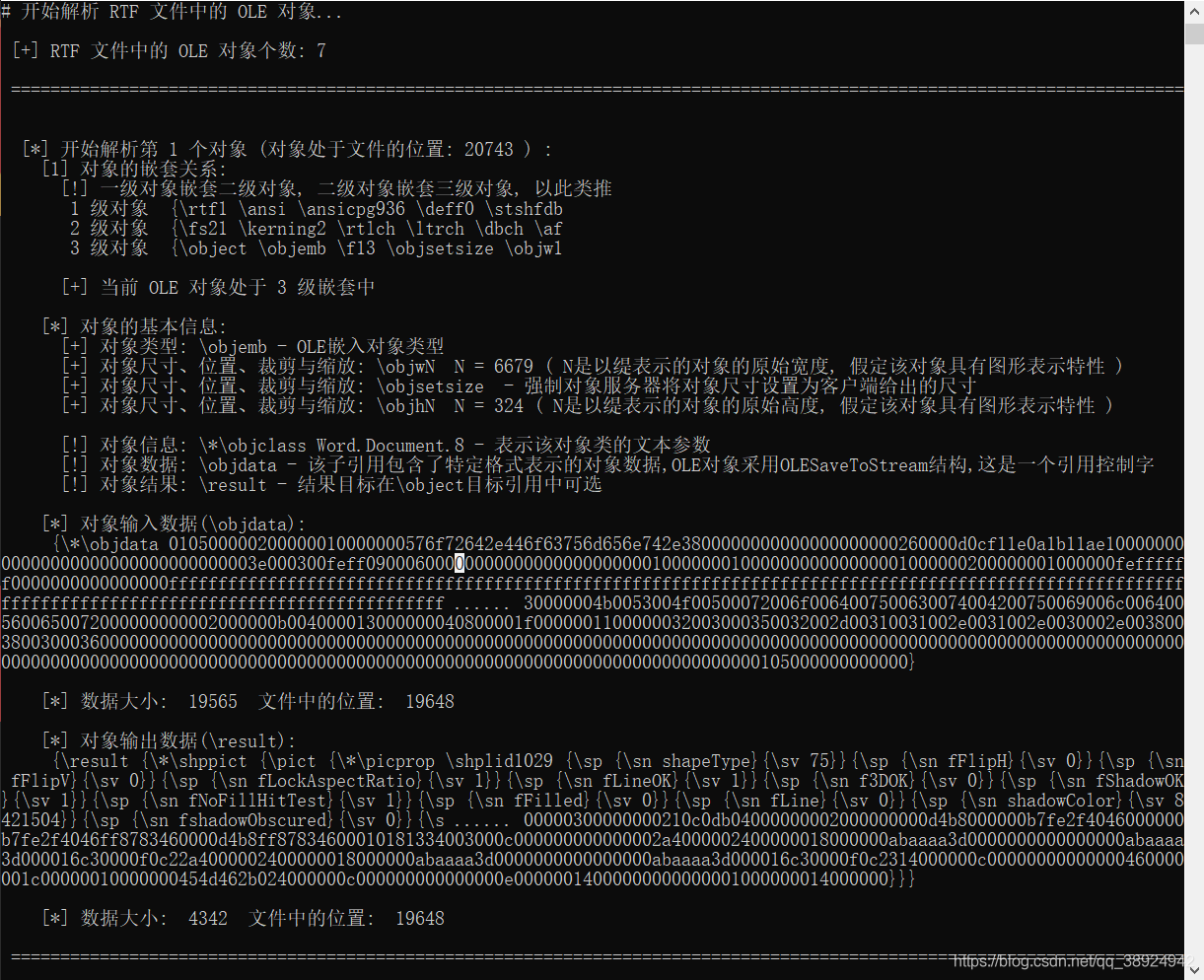
- 测试文档 2 及其内容:

- 如图所示,在测试文档 2 中插入了 7 个 OLE 对象。


- 测试使用 -o 参数解析 OLE 对象:
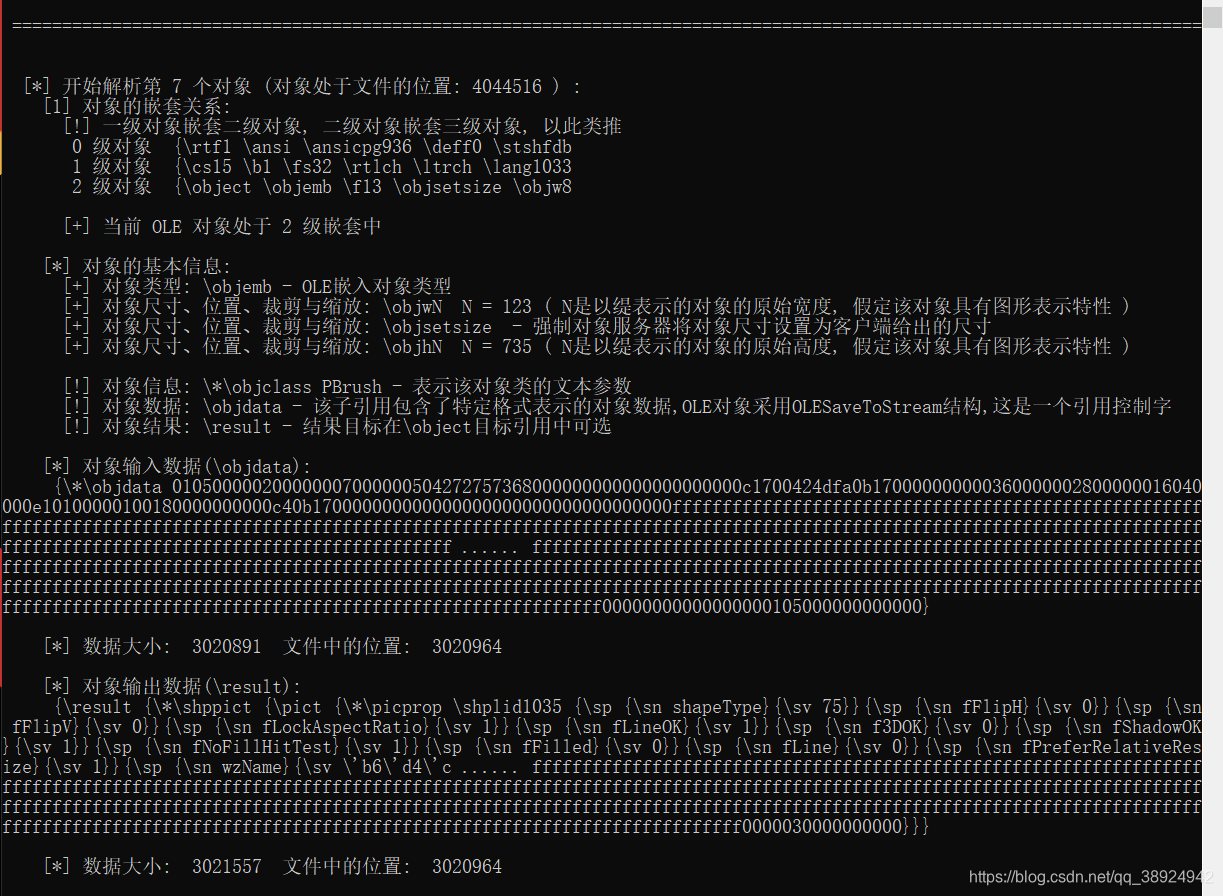
- 第一个对象解析正常。
 - 第七个对象(最后一个)解析正常。
- 第七个对象(最后一个)解析正常。
其实脚本测试的时候不一定使用正常的 RTF 文档进行解析,也可以使用各种畸形的文件进行测试
- python 脚本共享地址(百度云):https://pan.baidu.com/s/1andozoFEqiwKS5sGJc3ttA(提取码:k1lt)
- RTF 文件规范 v1.7:https://pan.baidu.com/s/11w-xGVoguP-jtpJ6ocpwSA(提取码:9xar)
- 测试文档:https://pan.baidu.com/s/1KfEwC5UPmQCLtxJ8wzSlvg(提取码:gz84)
本文到此结束,如有错误,欢迎指正
基于 RTF specification v1.7 的 RTF 文件解析及 OLE 对象提取(使用 Python 开发)的更多相关文章
- 基于Linux ALSA音频驱动的wav文件解析及播放程序 2012
本设计思路:先打开一个普通wav音频文件,从定义的文件头前面的44个字节中,取出文件头的定义消息,置于一个文件头的结构体中.然后打开alsa音频驱动,从文件头结构体取出采样精度,声道数,采样频率三个重 ...
- C#仪器数据文件解析-RTF文件
RTF格式文件大家并不陌生,但RTF文件的编码.解码却很难,因为RTF文件是富文本格式的,即文件中除了包含文本内容,还包含文本的格式信息,而这些信息并没有像后来的docx等采用XML来隔离格式和内容, ...
- Bittorrent Protocol Specification v1.0 中文
翻译:小马哥 日期:2004-5-22 BitTorrent 是一种分发文件的协议.它通过URL来识别内容,并且可以无缝的和web进行交互.它基于HTTP协议,它的优势是:如果有多个下载者并发的下载同 ...
- Atitit 基于图片图像 与文档混合文件夹的分类
Atitit 基于图片图像 与文档混合文件夹的分类 太小的文档(txt doc csv exl ppt pptx)单独分类 Mov10KminiDoc 但是可能会有一些书法图片迁移,因为他们很微小,需 ...
- The P4 Language Specification v1.0.2 Header and Fields
前言 本文参考P4.org网站给出的<The P4 Language Specification v1.0.2>的第二部分首部及字段,仅供学习:). 欢迎交流! Header and Fi ...
- 【科研论文】基于文件解析的飞行器模拟系统软件设计(应用W5300)
摘要: 飞行器模拟系统是复杂飞行器研制和使用过程中的重要设备,它可以用来模拟真实飞行器的输入输出接口,产生与真实系统一致的模拟数据,从而有效避免因使用真实飞行器带来的高风险,极大提高地面测发控系统的研 ...
- HubbleDotNet 最新绿色版,服务端免安装,基于eaglet 最后V1.2.8.9版本开发,bug修正,支持一键生成同步表
HubbleDotNet 是一个基于.net framework 的开源免费的全文搜索数据库组件.开源协议是 Apache 2.0.HubbleDotNet提供了基于SQL的全文检索接口,使用者只需会 ...
- 2019/01/17 基于windows使用fabric将gitlab的文件远程同步到服务器(git)
觉得django项目把本地更新push到gitlab,再执行fabric脚本从gitlab更新服务器项目挺方便的,当然从本地直接到服务器就比较灵活. 2019/01/17 基于windows使用fab ...
- ajax上传文件 基于jquery form表单上传文件
<script src="/static/js/jquery.js"></script><script> $("#reg-btn&qu ...
随机推荐
- 强化学习导论 课后习题参考 - Chapter 1,2
Reinforcement Learning: An Introduction (second edition) - Chapter 1,2 Chapter 1 1.1 Self-Play Suppo ...
- Go语言学习 学习资料汇总
从进入实验室以来,一直听小溪师兄说Go语言,但是第一学期的课很多,一直没有时间学习,现在终于空出来时间学习,按照我的学习习惯,我一般分为三步走 学习一门语言首先要知道学会了能干什么, 然后再把网上的资 ...
- python-自定义一个序列
python的序列可以包含多个元素,开发者只要实现符合序列要求的特殊方法,就可以实现自己的序列 序列最重要的特征就是可以包含多个元素,序列有关的特使方法: __len__(self):该方法的返回值决 ...
- JSP配置虚拟路径及虚拟主机
1.tomact解压后目录 bin:可执行文件(startup.bat shutdown.bat) conf:配置文件(server.xml) lib:tomcat以来的jar文件 log:日志文 ...
- 在SSM框架中如何将图片上传到数据库中
今天我们来看看SSM中如何将图片转换成二进制,最后传入到自己的数据库中,好了,废话不多说,我们开始今天的学习,我这里用的编辑器是IDEA 1.导入图片上传需要的jar依赖包 1 <depende ...
- (四)SpringBoot启动过程的分析-预处理ApplicationContext
-- 以下内容均基于2.1.8.RELEASE版本 紧接着上一篇(三)SpringBoot启动过程的分析-创建应用程序上下文,本文将分析上下文创建完毕之后的下一步操作:预处理上下文容器. 预处理上下文 ...
- 什么是SSR SSR有什么用 如何使用使用SSR
什么是SSR 以下信息来自维基百科: Shadowsocks(简称SS)是一种基于Socks5代理方式的加密传输协议,也可以指实现这个协议的各种开发包.当前包使用Python.C.C++.C#.Go语 ...
- PAT (Basic Level) Practice (中文)1065 单身狗 (25 分) 凌宸1642
PAT (Basic Level) Practice (中文)1065 单身狗 (25 分) 凌宸1642 题目描述: "单身狗"是中文对于单身人士的一种爱称.本题请你从上万人的大 ...
- 使用 Elastic 技术栈构建 Kubernetes全栈监控
以下我们描述如何使用 Elastic 技术栈来为 Kubernetes 构建监控环境.可观测性的目标是为生产环境提供运维工具来检测服务不可用的情况(比如服务宕机.错误或者响应变慢等),并且保留一些可以 ...
- 从零玩转第三方登录之QQ登录
从零玩转第三方登录之QQ登录 前言 在真正开始对接之前,我们先来聊一聊后台的方案设计.既然是对接第三方登录,那就免不了如何将用户信息保存.首先需要明确一点的是,用户在第三方登录成功之后, 我们能拿到的 ...