FlinkSQL使用自定义UDTF函数行转列-IK分词器
一、背景说明
本文基于IK分词器,自定义一个UDTF(Table Functions),实现类似Hive的explode行转列的效果,以此来简明开发过程。
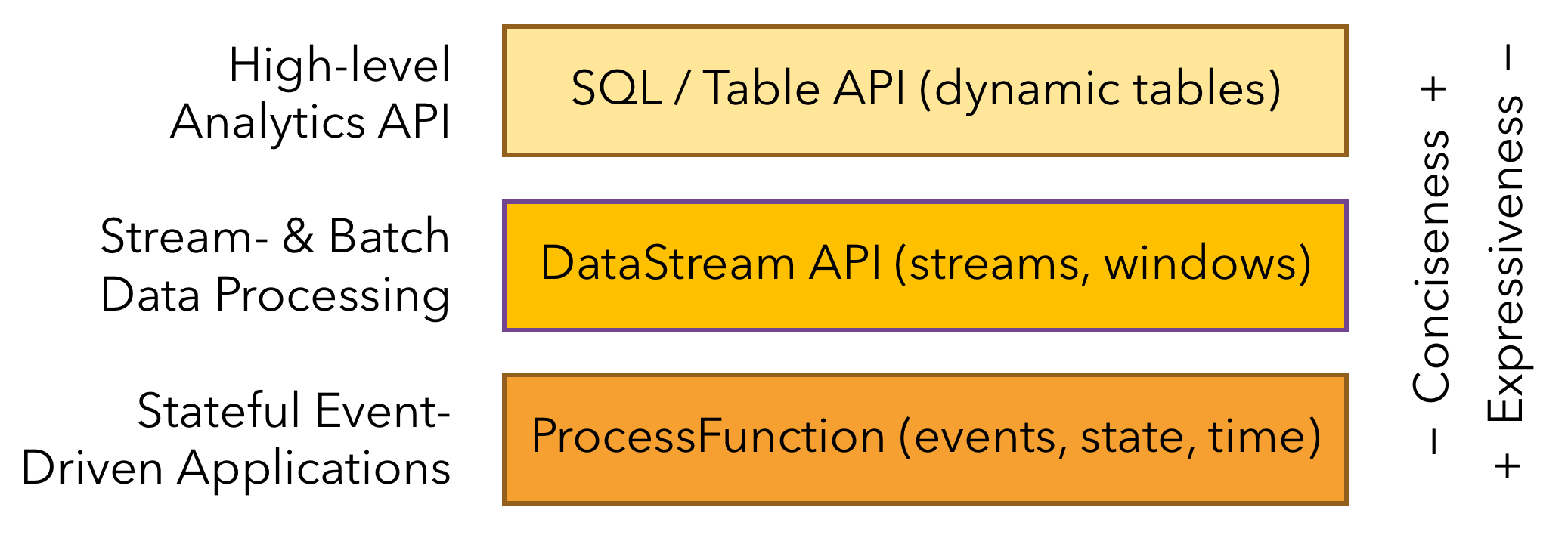
如下图Flink三层API接口中,Table API的接口位于最顶层也是最易用的一层,可以套用SQL语法进行代码编写,对于有SQL基础的能很快上手,但是不足之处在于灵活度有限,自有函数不能满足使用的时候,需要通过自定义函数实现,类似Hive的UDF/UDTF/UDAF自定义函数,在Flink也可以称之为Scalar Functions/Table Functions/Aggregate Functions。
二、效果预览
Kafka端建立生产者发送json片段:

IDEA侧消费数据处理后效果:

如上所示,形成类似Hive的exploed炸裂函数实现行转列的效果,当然也可以不用IK分词器,直接按空格进行split实现逻辑是一样的。
三、代码过程
由于Flink一般在流式环境使用,故这里数据源使用Kafka,并建立动态表的形式实现,以更好的贴近实际的业务环境。
- 工具类:
package com.test.UDTF;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
/**
* @author: Rango
* @create: 2021-05-04 16:50
* @description: 建立函数,继承TableFunction并建立eval方法
**/
@FunctionHint(output = @DataTypeHint("ROW<word STRING>"))
public class KeywordUDTF extends TableFunction<Row> {
//按官方文档说明,须按eval命名
public void eval(String value){
List<String> stringList = analyze(value);
for (String s : stringList) {
Row row = new Row(1);
row.setField(0,s);
collect(row);
}
}
//自定义分词方式
public List<String> analyze(String text){
//字符串转文件流
StringReader sr = new StringReader(text);
//建立分词器对象
IKSegmenter ik = new IKSegmenter(sr,true);
//ik分词后对象为Lexeme
Lexeme lex = null;
//分词后转入列表
List<String> keywordList = new ArrayList<>();
while(true){
try {
if ((lex = ik.next())!=null){
keywordList.add(lex.getLexemeText());
}else{
break;
}
} catch(IOException e) {
e.printStackTrace();
}
}return keywordList;
}
}
- 实现类
package com.test.UDTF;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* @author: Rango
* @create: 2021-05-04 17:11
* @description:
**/
public class KeywordStatsApp {
public static void main(String[] args) throws Exception {
//建立环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
//注册函数
tableEnv.createTemporaryFunction("ik_analyze", KeywordUDTF.class);
//建立动态表
tableEnv.executeSql("CREATE TABLE wordtable (" +
"word STRING" +
") WITH ('connector' = 'kafka'," +
"'topic' = 'keywordtest'," +
"'properties.bootstrap.servers' = 'hadoop102:9092'," +
"'properties.group.id' = 'keyword_stats_app'," +
"'format' = 'json')");
//未切分效果
Table wordTable = tableEnv.sqlQuery("select word from wordtable");
//利用自定义函数对文本进行分切,切分后计为1,方便后续统计使用
Table wordTable1 = tableEnv.sqlQuery("select splitword,1 ct from wordtable," +
"LATERAL TABLE(ik_analyze(word)) as T(splitword)");
tableEnv.toAppendStream(wordTable, Row.class).print("原格式>>>");
tableEnv.toAppendStream(wordTable1, Row.class).print("使用UDTF函数效果>>>");
env.execute();
}
}
- 补充下依赖
<properties>
<java.version>1.8</java.version>
<flink.version>1.12.0</flink.version>
<scala.version>2.12</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
学习交流,有任何问题还请随时评论指出交流。
FlinkSQL使用自定义UDTF函数行转列-IK分词器的更多相关文章
- solr添加中文IK分词器,以及配置自定义词库
Solr是一个基于Lucene的Java搜索引擎服务器.Solr 提供了层面搜索.命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式).它易于安装和配置,而且附带了一个基于H ...
- hive自定义UDTF函数叉分函数
hive自定义UDTF函数叉分函数 1.介绍 从聚合体日志中需要拆解出来各子日志数据,然后单独插入到各日志子表中.通过表生成函数完成这一过程. 2.定义ForkLogUDTF 2.1 HiveUtil ...
- 在论坛中出现的比较难的sql问题:19(row_number函数 行转列、sql语句记流水)
原文:在论坛中出现的比较难的sql问题:19(row_number函数 行转列.sql语句记流水) 最近,在论坛中,遇到了不少比较难的sql问题,虽然自己都能解决,但发现过几天后,就记不起来了,也忘记 ...
- Spark基于自定义聚合函数实现【列转行、行转列】
一.分析 Spark提供了非常丰富的算子,可以实现大部分的逻辑处理,例如,要实现行转列,可以用hiveContext中支持的concat_ws(',', collect_set('字段'))实现.但是 ...
- 31.IK分词器配置文件讲解以及自定义词库
主要知识点: 知道IK默认的配置文件信息 自定义词库 一.ik配置文件 ik配置文件地址:es/plugins/ik/config目录 IKAnalyzer.cfg.xml:用 ...
- 30.IK分词器配置文件讲解以及自定义词库
主要知识点: 知道IK默认的配置文件信息 自定义词库 一.ik配置文件 ik配置文件地址:es/plugins/ik/config目录 IKAnalyzer.cfg.xml:用 ...
- 利用IK分词器,自定义分词规则
IK分词源码下载地址:https://code.google.com/p/ik-analyzer/downloads/list lucene源码下载地址:http://www.eu.apache.or ...
- SqlServer PIVOT函数快速实现行转列,UNPIVOT实现列转行
我们在写Sql语句的时候没经常会遇到将查询结果行转列,列转行的需求,拼接sql字符串,然后使用sp_executesql执行sql字符串是比较常规的一种做法.但是这样做实现起来非常复杂,而在SqlSe ...
- SqlServer PIVOT函数快速实现行转列,UNPIVOT实现列转行(转)
我们在写Sql语句的时候没经常会遇到将查询结果行转列,列转行的需求,拼接sql字符串,然后使用sp_executesql执行sql字符串是比较常规的一种做法.但是这样做实现起来非常复杂,而在SqlSe ...
随机推荐
- python 操作符** (两个乘号就是乘方)
一个乘号*,如果操作数是两个数字,就是这两个数字相乘,如2*4,结果为8**两个乘号就是乘方.比如3**4,结果就是3的4次方,结果是81 *如果是字符串.列表.元组与一个整数N相乘,返回一个其所有元 ...
- MyBatis(八):MyBatis插件机制详解
MyBatis插件插件机制简介 MyBatis插件其实就是为使用者提供的自行拓展拦截器,主要是为了可以更好的满足业务需要. 在MyBatis中提供了四大核心组件对数据库进行处理,分别是Exec ...
- jQuery学习笔记(2) jQuery选择器
jQuery的选择器完全继承了CSS的风格,利用jQuery选择器,可以非常便捷和快速地找出特定的DOM元素,然后为它们添加相应的行为. 目录 目录 CSS选择器 jQuery选择器 jQuery选 ...
- Java 多线程 | 并发知识问答总结
写在最前面 这个项目是从20年末就立好的 flag,经过几年的学习,回过头再去看很多知识点又有新的理解.所以趁着找实习的准备,结合以前的学习储备,创建一个主要针对应届生和初学者的 Java 开源知识项 ...
- IPFS矿池集群方案详解
IPFS作为一项分布式存储技术,可以说是web3.0发展的基石.关于IPFS的产业,如存储.技术.矿机.矿池等也发展得非常迅速. 什么是单机挖矿? 单机挖矿就是一台机器就是一个节点,一台机器就完成挖矿 ...
- NetCore的缓存使用详例
关于我 作者博客|文章首发 缓存基础知识 缓存可以减少生成内容所需的工作,从而显著提高应用程序的性能和可伸缩性. 缓存最适用于不经常更改的 数据,生成 成本很高. 通过缓存,可以比从数据源返回的数据的 ...
- Kubernetes 用户流量接入方案
总结Kubernetes 生产环境用户流量接入方案 方案1 client -> ddos -> waf -> slb 7层域名 -> nginx端口 -> ingress ...
- java面试-CountDownLatch、CyclicBarrier、Semaphore谈谈你的理解
一.CountDownLatch 主要用来解决一个线程等待多个线程的场景,计数器不能循环利用 public class CountDownLatchDemo { public static void ...
- go中控制goroutine数量
控制goroutine数量 前言 控制goroutine的数量 通过channel+sync 使用semaphore 线程池 几个开源的线程池的设计 fasthttp中的协程池实现 Start Sto ...
- php添加excel更新数据表数据
公司有个需求,是用excel更新数据的,把错误的行列放到一个数组返回出来,正常的数据则插入,且返回数量 1.先需要引入phpspreadsheet,这里使用composer 安装 composer r ...