第二周Python笔记 数据类型 列表 字典
列表,拉锁式儿合并。
[ [a,b] for a,b in zip(list1,list2)]
#最笨的
a=[1,2,3,4,5]
b=[2,3,4,5,6]
d=[]
for i in range(len(a)):
c = []
c.append(a[i])
c.append(b[i])
d.append(c)
#列表垂直合并
In [8]: list3
Out[8]: [['11:00', '11:01', '11:02'], ['2', '2', '3']] In [9]: [[a,b] for a,b in zip(*list3)]
Out[9]: [['11:00', '2'], ['11:01', '2'], ['11:02', '3']]
#两个列表合并为元组
In [10]: [a for a in zip(list1,list2)]
Out[10]: [('11:00', '2'), ('11:01', '2'), ('11:02', '3')]
#一个列表顺序合并 date=[]
date_temp1=['1545225954.721;1545225955.115', '1545225955.215;1545225955.316;1545225955.422',
'1545225955.708;1545225955.817;1545225955.916', '1545225956.230;1545225956.319']
date_temp2=[]
for i in range(len(date_temp1)):
if date_temp1[i]:
date_temp2.append(date_temp1[i].split(';'))
print(date_temp2)
for i in date_temp2:
for j in i:
date.append(j)
字典key-value的删除、def(dict['key']) ; dict.pop(“key”)
查询value:dict.get(“key”)

查询所有keys,values()
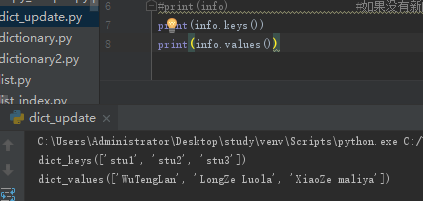
转换为列表.items()

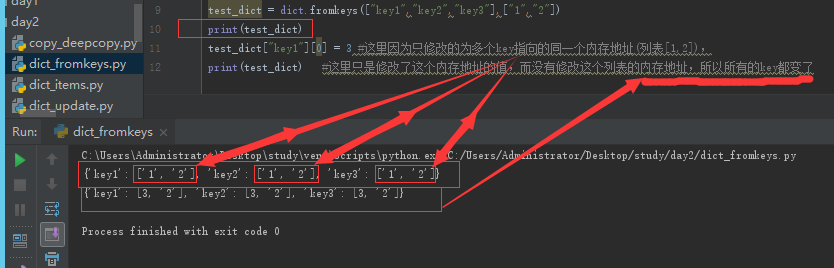
fromkeys([key1,key2,key....],"default_value)初始化一个字典:注意初始化的value为一个内存地址。

注意多层级的初始化字典的坑
for循环取值



省市县多级字典查询while死循环查询if判断,for遍历取值

省市县级查询,每一级都可以exit退出查询程序,或者back返回上级重新选择再查询。
应用重点知识:
elif可以多次进行判断使用,判断是输入back返回上一级,输入exit退出程序
每一个层级,如果是选择了输入exit,就赋值一个变量。然后break退出本次while循环,然后这个变量在退出while循环后,这个变量会存在。给上一个while循环做判断:进入每个层级的时候都先判断这个exit_变量是否存在,存在就依次退出while并向上级传递exit_变量的存在。依次退出直至退出整个程序。
补充新知识:判断变量是否存在
python中检测某个变量是否有定义
第一种方法使用内置函数locals():
'testvar' in locals().keys()
第二种方法使用内置函数dir():
'testvar' in dir()


while True:
if "exit_" in locals().keys(): #判断变量是否存在,存在就跳出循环:做退出程序用,
break
else:
pass
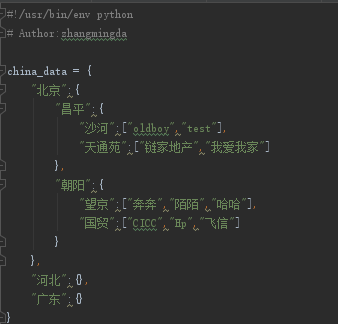
for i in china_data:
print(i)
input1 = input("查哪个省?quit/exit可退出")
if input1 in china_data:
while True:
if "exit_" in locals().keys(): #判断变量是否存在,存在就跳出循环:做退出程序用
break
else:
pass
for i in china_data[input1]:
print("\t",i)
input2 = input("\t\t查哪个市?back返回exit退出")
if input2 in china_data[input1]:
while True:
if "test_" in locals().keys(): #判断变量是否存在,存在就跳出循环:做退出程序用
break
else:
pass
for i in china_data[input1][input2]:
print("\t\t",i)
input3 = input("\t\t\t查哪个县?back返回exit退出")
if input3 in china_data[input1][input2]:
for i in china_data[input1][input2][input3]:
print("\t\t\t",i)
input4 = input("\t\t\t\t继续吗?back返回,exit退出")
if input4 == "back":
break
elif input4 == "exit": #【最底层查询后,如果输入exit就赋值一个变量传给上层循环做判断】
exit_ = 1
print("退出程序")
break
elif input3 == "back":
print("退出县级")
break
elif input3 == "exit": #【选择县级时如果输入exit就赋值一个变量传给上层循环做判断】
exit_ = 1
print("退出程序")
break
else:
print("您输入的县不存在,重新输入")
elif input2 == "back":
print("退出市级")
break
elif input2 == "exit": #【选择市级时,如果输入exit就赋值一个变量传给上层循环做判断】
print("退出程序")
exit_ = 1
break
else:
print("您输入的市不存在,重新输入")
elif input1 == "quit":
print("退出查询")
break
elif input1 == "exit": #【判断刚进入程序时(选择省级时),如果输入的市exit就退出程序】
exit_ = 1
print("退出程序")
break
else:
print("您输入的省不存在,重新输入")
第二周Python笔记 数据类型 列表 字典的更多相关文章
- 第二周Python笔记之 变量的三元运算
如果变量a小于b,则d的值取a变量的值,否则取c变量的值
- Python基本数据类型--列表、元组、字典、集合
一.Python基本数据类型--列表(List) 1.定义:[ ]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素. 2.列表的创建: # 方式一 list1 = ['name','ag ...
- Python基础数据类型-列表(list)和元组(tuple)和集合(set)
Python基础数据类型-列表(list)和元组(tuple)和集合(set) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客使用的是Python3.6版本,以及以后分享的 ...
- python基本数据类型之字典
python基本数据类型之字典 python中的字典是以键(key)值(value)对的形式储存数据,基本形式如下: d = {'Bart': 95, 'Michael': 34, 'Lisa': 5 ...
- python基础数据类型--列表(list)
python基础数据类型--列表(list) 列表是我们在后面经常用到的数据类型之一,通过列表可以对数据类型进行增.删.改.查等操作 一列表的增.删.改.查 1增: 1.1增加到最后 append ...
- 《Linux内核分析》第二周学习笔记
<Linux内核分析>第二周学习笔记 操作系统是如何工作的 郭垚 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/ ...
- Linux内核分析第二周学习笔记
linux内核分析第二周学习笔记 标签(空格分隔): 20135328陈都 陈都 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.co ...
- 三、python的数据类型 列表、元组、字典
1.list 列表 列表是由一序列特定顺序排列的元素组成的.可以把字符串,数字,字典等都可以任何东西加入到列表中,列表中的元素之间没有任何关系.列表也是自带下标的,默认也还是从0开始. List常用的 ...
- 20165326 java第二周学习笔记
学习笔记 一.理论学习 基本数据类型与数组 标识符的第一个字符不能是数字:标识符不能为关键字. 基本数据类型多数与c语言相同.重点如下: 1.逻辑类型boolean赋值true/false 2.浮点数 ...
随机推荐
- 多线程Reactor模式
目录 1.1 主服务器 2.1 IO请求handler+线程池 3.1 客户端 多线程Reactor模式旨在分配多个reactor每一个reactor独立拥有一个selector,在网络通信中大体设计 ...
- 『学了就忘』Linux文件系统管理 — 60、Linux中配置自动挂载
目录 1.自动挂载 2.如何查询系统下每个分区的UUID 3.配置自动挂载 4./etc/fstab文件修复 上一篇文章我们说明了手动分区讲解,对一块新硬盘进行了手动分区和挂载. 但是我们发现重启系统 ...
- CF1575G GCD Festival
\(\sum\sum gcd(i,j) \times gcd(a_i,a_j)\) 考虑枚举这个 \(gcd(i,j)\) . \(\sum_d \varphi(d)\sum_{i|d}\sum_{j ...
- Codeforces 1528F - AmShZ Farm(转化+NTT+推式子+第二类斯特林数)
Codeforces 题目传送门 & 洛谷题目传送门 神仙题,只不过感觉有点强行二合一(?). 首先考虑什么样的数组 \(a\) 符合条件,我们考虑一个贪心的思想,我们从前到后遍历,对于每一个 ...
- SSRF的原理和防范
背景 最近做的安全测评主要是SSRF,发现自己在这一块有挺大知识盲点,抓紧补一下. 1.介绍 SSRF(Server-Side Request Forgery:服务器端请求伪造),是一种攻击者利用服务 ...
- PDO的好处
产生原因 普通的SQL执行语句,由于研发人员对前端请求参数过滤不严谨,导致SQL被注入,从而影响数据库,带来风险 使用PDO后形成的语句 SELECT * FROM test WHERE id in ...
- RNA_seq 热图绘制
若已经拿到表达矩阵exprSet 若差异较大,进行log缩小不同样本的差距 1.热图全体 1 ##加载包 2 library(pheatmap) 3 4 ##缩小表达量差距 5 exprSet < ...
- 使用BRAKER2进行基因组注释
来自:https://www.jianshu.com/p/e6a5e1f85dda 使用BRAKER2进行基因组注释 BRAKER2是一个基因组注释流程,能够组合GeneMark,AUGUSTUS和转 ...
- Zabbix源码安装,使用service命令管理zabbix进程
1. 前期环境: Zabbix源代码解压包:/root/zabbix-3.0.27 Zabbix安装路径:/usr/local/zabbix-3.0.27 2. 复制启动脚本到 ...
- Excel-电话号码隐藏某几个数为*,起到保护信息作用;
9.电话号码隐藏某几个数为*,起到保护信息作用: 方法一: =SUBSTITUTE(AG2,MID(AG2,4,5),"*****") 解释函数: MID(目标字符串,裁剪起始位置 ...