java后端知识点梳理——java集合
集合概览
Java中的集合,从上层接口上看分为了两类,Map和Collection。Map是和Collection并列的集合上层接口,没有继承关系。
Java中的常见集合可以概括如下。
- Map接口和Collection接口是所有集合框架的父接口
- Collection接口的子接口包括:Set接口和List接口
- Map接口的实现类主要有:HashMap、TreeMap、HashtableLinkedHashMap、ConcurrentHashMap以及Properties等
- Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
- List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等
HashMap和Hashtable的区别有哪些?
- HashMap没有考虑同步,是线程不安全的;Hashtable使用了synchronized关键字,是线程安全的;
- HashMap允许null作为Key;Hashtable不允许null作为Key,Hashtable的value也不可以为null
HashMap是线程不安全的是吧?你可以举一个例子吗?
先别说快速失败机制
- HashMap线程不安全主要是考虑到了多线程环境下进行扩容可能会出现HashMap死循环
- Hashtable线程安全是由于其内部实现在put和remove等方法上使用synchronized进行了同步,所以对单个方法的使用是线程安全的。但是对多个方法进行复合操作时,线程安全性无法保证。 比如一个线程在进行get然后put更新的操作,这就是两个复合操作,在两个操作之间,可能别的线程已经对这个key做了改动,所以,你接下来的put操作可能会不符合预期。
快速失败(fast-fail)机制
快速失败是Java集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作时,有可能会产生fail-fast。
例如
假设存在两个线程(线程1 、线程2) , 线程1通过Iterator 在遍历集合 A 中的元素, 在某个时候线程2修改了集合A 的结构(是结构上面的修改,而 不是简单的修改集合元素的内容), 那么这个时候程序就会抛出异常从而产生快速失败机制。
原因
迭代器在遍历时直接访问集合中的内容, 并且在遍历过程中使用—个 modCount 变量。集合在被遍历期间如果内容发生变化, 就会改变modCount 的值。每当迭代器使用hashNext()/next()遍历下一个元素之前, 都会检测 modCount 变量是否为expectedmodCount 值,是的话就返回遍历; 否则抛出异常, 终止遍历。
解决方法
- 在遍历过程中, 所有涉及到改变modCount 值得地方全部加上synchronized。
- 使用线程安全的集合
hashmap
hashmap推荐看我的另一篇文章:
这里简单补充一下一致性Hash算法
一致性Hash:
客户端分片:哈希+顺时针(优化取余)
节点伸缩:只影响邻近节点,但是还是有数据迁移
翻倍伸缩:保证最小迁移数据和负载均衡
一致性Hash可以很好的解决稳定问题,可以将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到先遇到的一组存储节点存放。而当有节点加入或退出时,仅影响该节点在Hash环上顺时针相邻的后续节点,将数据从该节点接收或者给予。但这有带来均匀性的问题,即使可以将存储节点等距排列,也会在存储节点个数变化时带来数据的不均匀。而这种可能成倍数的不均匀在实际工程中是不可接受的。
【未完待续】
ConcurrentHashMap和Hashtable的区别?
ConcurrentHashMap结合了HashMap和Hashtable二者的优势。HashMap没有考虑同步,Hashtable考虑了同步的问题。但是Hashtable在每次同步执行时都要锁住整个结构。
ConcurrentHashMap锁的方式是稍微细粒度的,ConcurrentHashMap将hash表分为16个桶(默认值),诸如get,put,remove等常用操作只锁上当前需要用到的桶。
ConcurrentHashMap的具体实现方式(分段锁)
该类包含两个静态内部类MapEntry和Segment,前者用来封装映射表的键值对,后者用来充当锁的角色。
segment
Segment是一种可重入的锁ReentrantLock,每个Segment守护一个HashEntry数组里得元素,当对HashEntry数组的数据进行修改时,必须首先获得对应的Segment锁。
在JDK1.7及其之前ConcurrentHashMap实现线程安全的方法相对比较简单:
- 其内部将数据分为数个“段(Segment)”,其数量和并发级别有关系,具体是“大于等于并发级别的最小的2的幂次”。
- 每个segment使用单独的ReentrantLock(分段锁)。
- 如果操作涉及不同segment,则可以并发执行,如果是同一个segment则会进行锁的竞争和等待。
- 此设计的效率是高于synchronized的。
不过JDK8之后,ConcurrentHashMap舍弃了ReentrantLock,而重新使用了synchronized。其原因大致有一下几点:
- 加入多个分段锁浪费内存空间。
- 生产环境中, map 在放入时竞争同一个锁的概率非常小,分段锁反而会造成更新等操作的长时间等待。
- 为了提高 GC 的效率
新的ConcurrentHashMap中使用synchronized关键字+CAS操作保证了线程安全。
TreeMap有哪些特性?
TreeMap底层使用红黑树实现,TreeMap中存储的键值对按照键来排序。
- 如果Key存入的是字符串等类型,那么会按照字典默认顺序排序
- 如果传入的是自定义引用类型,比如说User,那么该对象必须实现Comparable接口,并且覆盖其compareTo方法;或者在创建TreeMap的时候,我们必须指定使用的比较器。
如下所示:
// 方式一:定义该类的时候,就指定比较规则
class User implements Comparable{
@Override
public int compareTo(Object o) {
// 在这里边定义其比较规则
return 0;
}
}
public static void main(String[] args) {
// 方式二:创建TreeMap的时候,可以指定比较规则
new TreeMap<User, Integer>(new Comparator<User>() {
@Override
public int compare(User o1, User o2) {
// 在这里边定义其比较规则
return 0;
}
});
}
引申:那么Comparable接口和Comparator接口有哪些区别呢?
- Comparable实现比较简单,但是当需要重新定义比较规则的时候,必须修改源代码,即修改User类里边的compareTo方法
- Comparator接口不需要修改源代码,只需要在创建TreeMap的时候重新传入一个具有指定规则的比较器即可。
补充:comparable 和comparator的区别?
comparable接口出自java.lang包,它有一个compareTo(Object obj)方法用来排序
comparator接口出自java.util包,它有一个compare(Object obj1 Object obj2) 方法用来排序
ArrayList和LinkedList有哪些区别?
- ArrayList底层使用了动态数组实现,实质上是一个动态数组
- LinkedList底层使用了双向链表实现,可当作堆栈、队列、双端队列使用
- ArrayList在随机存取方面效率高于LinkedList
- LinkedList在节点的增删方面效率高于ArrayList
- ArrayList必须预留一定的空间,当空间不足的时候,会进行扩容操作
- LinkedList的开销是必须存储节点的信息以及节点的指针信息
其实还有一个集合Vector,它是线程安全的ArrayList,但是已经被废弃,不推荐使用了。多线程环境下,我们可以使用CopyOnWriteArrayList替代ArrayList来保证线程安全。
HashSet和TreeSet有哪些区别?
- HashSet底层使用了Hash表实现。
- 保证元素唯一性的原理:判断元素的hashCode值是否相同。如果相同,还会继续判断元素的equals方法,是否为true
- TreeSet底层使用了红黑树来实现。
- 保证元素唯一性是通过Comparable或者Comparator接口实现
HashSet和HashMap
其实,HashSet的底层实现还是HashMap,只不过其只使用了其中的Key,具体如下所示:
- HashSet的add方法底层使用HashMap的put方法将key = e,value=PRESENT构建成key-value键值对,当此e存在于HashMap的key中,则value将会覆盖原有value,但是key保持不变,所以如果将一个已经存在的e元素添加中HashSet中,新添加的元素是不会保存到HashMap中,所以这就满足了HashSet中元素不会重复的特性。
- HashSet的contains方法使用HashMap得containsKey方法实现
LinkedHashMap和LinkedHashSet有了解吗?
LinkedHashMap内部的Entry继承于HashMap.Node,这两个类都实现了Map.Entry<K,V>
LinkedHashMap的Entry不光有value,next,还有before和after属性,这样通过一个双向链表,保证了各个元素的插入顺序
通过构造方法public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder), accessOrder传入true可以实现LRU缓存算法(访问顺序)
LinkedHashSet 底层使用LinkedHashMap实现,两者的关系类似与HashMap和HashSet的关系,大家可以自行类比。
什么是LRU算法?LinkedHashMap如何实现LRU算法?
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。思路如下

- 新数据插入到链表头部;
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
- 当链表满的时候,将链表尾部的数据丢弃。
关于【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUTest {
private static int size = 5;
public static void main(String[] args) {
Map<String, String> map = new LinkedHashMap<String, String>(size, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<String, String> eldest) {
return size() > size;
}
};
map.put("1", "1");
map.put("2", "2");
map.put("3", "3");
map.put("4", "4");
map.put("5", "5");
System.out.println(map.toString());
map.put("6", "6");
System.out.println(map.toString());
map.get("3");
System.out.println(map.toString());
map.put("7", "7");
System.out.println(map.toString());
map.get("5");
System.out.println(map.toString());
}
}
List和Set的区别?
- List是有序的并且元素是可以重复的
- Set是无序(LinkedHashSet除外)的,并且元素是不可以重复的
说明: 此处的有序和无序是指放入顺序和取出顺序是否保持一致
Iterator和ListIterator的区别是什么?
- Iterator可以遍历list和set集合;ListIterator只能用来遍历list集合
- Iterator前者只能前向遍历集合;ListIterator可以前向和后向遍历集合
- ListIterator其实就是实现了前者,并且增加了一些新的功能。
Iterato参考代码:
ArrayList<String> list = new ArrayList<>();
list.add("zhangsan");
list.add("lisi");
list.add("yangwenqiang");
// 创建迭代器实现遍历集合
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
Collection和Collections有什么关系?
Collection和Collections的关系: Collection是一个顶层集合接口,其子接口包括List和Set;而Collections是一个集合工具类,可以操作集合,比如说排序,二分查找,拷贝集合,寻找最大最小值等。 总而言之:带s的大都是工具类。
说在最后
附上集合接口和实现类的关系
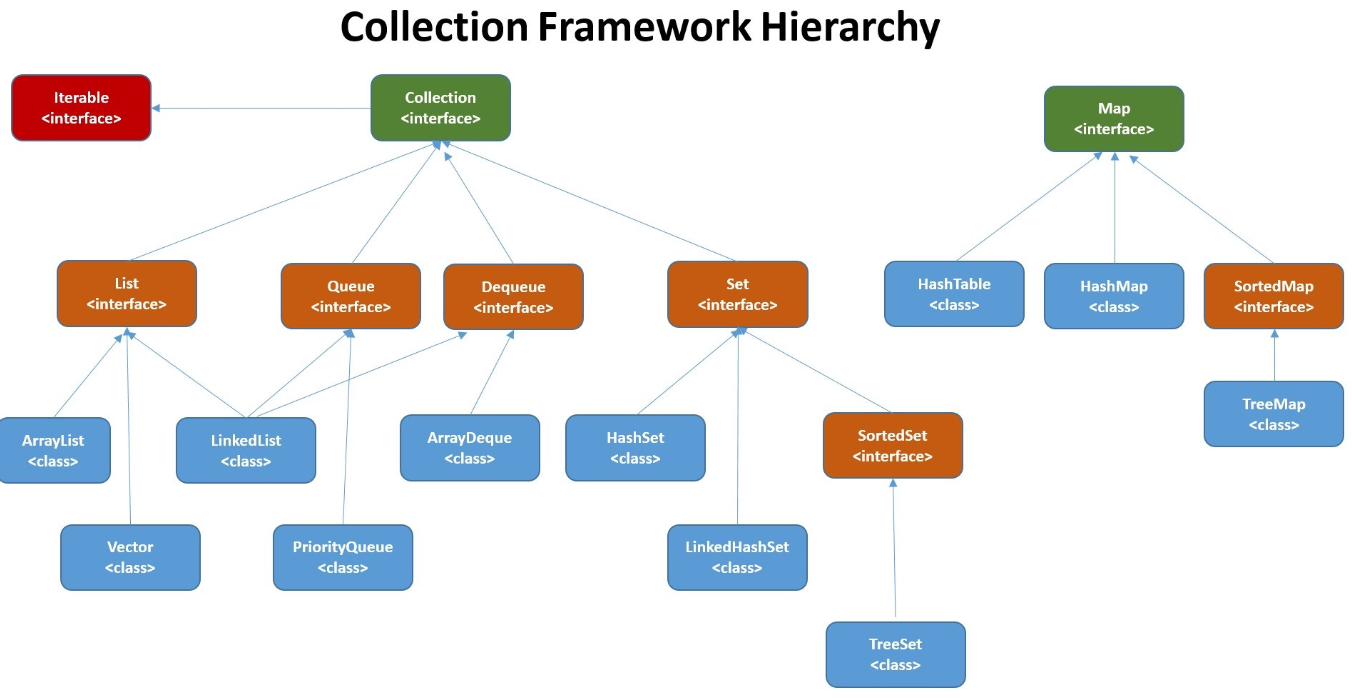
如果感兴趣,可以配合我的java集合面试题来看。
java后端知识点梳理——java集合的更多相关文章
- java后端知识点梳理——java基础
面向对象 java三大特性 封装: 将事务封装成一个类,达到解耦,隐藏细节的效果.通过get/set等方法,封装了内部逻辑,并保留了特定的接口与外界联系. 继承: 从一个已知的类中派生出一个新的类,新 ...
- java后端知识点梳理——Spring
开篇:感谢我是祖国的花朵,java3y,三太子敖丙等优秀博主!他们的文章为我学习java提供了莫大的帮助,膜拜大神! Spring的优点有哪些呢? Spring的依赖注入将对象之间的依赖关系交给了框架 ...
- java后端知识点梳理——多线程与高并发
进程与线程 进程是一个"执行中的程序",是系统进行资源分配和调度的一个独立单位 线程是进程的一个实体,一个进程中一般拥有多个线程. 线程和进程的区别 进程是操作系统分配资源的最小单 ...
- java后端知识点梳理——JVM
可以先看看我的深入理解java虚拟机笔记 深入理解java虚拟机笔记Chapter2 深入理解java虚拟机笔记Chapter3-垃圾收集器 深入理解java虚拟机笔记Chapter3-内存分配策略 ...
- java后端知识点梳理——web安全
跨域 当浏览器执行脚本时会检查是否同源,只有同源的脚本才会执行,如果不同源即为跨域. 这里的同源指访问的协议.域名.端口都相同. 同源策略是由 Netscape 提出的著名安全策略,是浏览器最核心.基 ...
- java后端知识点梳理——Redis
redis都支持哪些数据类型?应用场景有哪些? redis支持五种数据类型作为其Value,redis的Key都是字符串类型的. string:redis 中字符串 value 最大可为512M.可以 ...
- java后端知识点梳理——MySQL
MySQL的索引 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息,就像一本书的目录一样,可以加快查询速度.InnoDB 存储引擎的索引模型底层实现数据结构为 ...
- Java编程知识点梳理
1. elementAt() temp.elementAt(0) 返回temp这个vector里面存放的第一个元素--->也是一个vector类型. 2. 字符串空格分割 String [] ...
- java基础知识点梳理
前言 在别人追问我以下几个问题,自己在问题回答上不够全面和准确,对此自己把专门针对这几个问题进行总结! java相关问题 1.Java中构造方法跟普通方法的区别? 构造方法与普通方法的调用时机不同. ...
随机推荐
- hdu4908 中位数子串
题意: 给你N个数字组成的数列,然后问你这里面有多少个是以M为中位数的子序列. 思路: 首先分四中简单的情况求 (1) 就是只有他自己的那种情况 那么sum+1 ...
- CTF密码学常见加解密总结
CTF密码学常见加解密总结 2018年03月10日 19:35:06 adversity` 本文链接:https://blog.csdn.net/qq_40836553/article/details ...
- Java 中 RMI 的使用
RMI 介绍 RMI (Remote Method Invocation) 模型是一种分布式对象应用,使用 RMI 技术可以使一个 JVM 中的对象,调用另一个 JVM 中的对象方法并获取调用结果.这 ...
- Java_抽象
抽象的基本使用 抽象的关键字是abstract,可以用来修饰类(抽象类),还可以修饰方法(抽象方法). 1 //抽象类 2 public abstract class Animal{ 3 //抽象方法 ...
- [bug] ORACLE not available
参考 https://www.cnblogs.com/sank/p/10046277.html
- 安装SpecCPU2006 on Linux of CentOS6.3, gcc4.4.7
安装SpecCPU2006 on Linux of CentOS6.3, gcc4.4.7 由于在tools/bin目录中只有ia64-linux,所以在直接运行./install.sh脚本时,系统会 ...
- Tracert 命令
Tracert 命令 Tracert 命令的作用 Tracert命令诊断实用程序通过向目标计算机发送具有不同生存时间的ICMP数据包,来确定至目标计算机的路由,也就是说用来跟踪一个消息从一台计算机到另 ...
- testlink安装(mac os)
安装依赖:xampp.mysql.testlink 一.xampp安装(参考:https://blog.csdn.net/it_cgq/article/details/79430511) 1.下载xa ...
- Linux_计划任务
[Centos7.4] !!!测试环境我们首关闭防火墙和selinux:免得后面的测试会出现问题 [root@localhost ~]# systemctl stop firewalld [root@ ...
- 10.27-Redis-mz 深入浅出Redis
深入浅出Redis 1.Redis的发展史 Redis[Remote Directory Server]:远程服务器字典 2.下载安装Redis 1>Linux下安装Reids ...