HDFS 07 - HDFS 性能调优之 合并小文件
1 - 为什么要合并小文件
HDFS 擅长存储大文件:
我们知道,HDFS 中,每个文件都有各自的元数据信息,如果 HDFS 中有大量的小文件,就会导致元数据爆炸,集群管理的元数据的内存压力会非常大。
所以在项目中,把小文件合并成大文件,是一种很有用也很常见的优化方法。
2 - 合并本地的小文件,上传到 HDFS
将本地的多个小文件,上传到 HDFS,可以通过 HDFS 客户端的 appendToFile 命令对小文件进行合并。
在本地准备2个小文件:
# user1.txt 内容如下:
1,tom,male,16
2,jerry,male,10
# user2.txt 内容如下:
101,jack,male,19
102,rose,female,18
合并方式:
hdfs dfs -appendToFile user1.txt user2.txt /test/upload/merged_user.txt
合并后的文件内容:

3 - 合并 HDFS 的小文件,下载到本地
可以通过 HDFS 客户端的 getmerge 命令,将很多小文件合并成一个大文件,然后下载到本地。
# 先上传小文件到 HDFS:
hdfs dfs -put user1.txt user2.txt /test/upload
# 下载,同时合并:
hdfs dfs -getmerge /test/upload/user*.txt ./merged_user.txt
下载、合并后的文件内容:
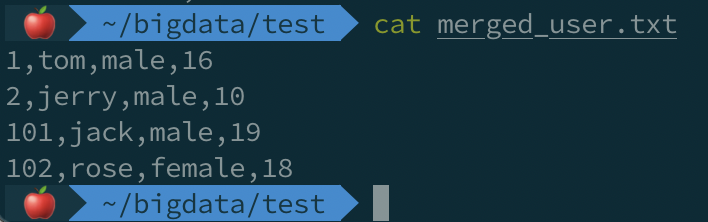
4 - 通过 Java API 实现文件合并和上传
代码如下(具体测试项目,可到 我的 GitHub 查看):
@Test
public void testMergeFile() throws Exception {
// 获取分布式文件系统
FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop:9000"), new Configuration(), "healchow");
FSDataOutputStream outputStream = fileSystem.create(new Path("/test/upload/merged_by_java.txt"));
// 获取本地文件系统
LocalFileSystem local = FileSystem.getLocal(new Configuration());
// 通过本地文件系统获取文件列表,这里必须指定路径
FileStatus[] fileStatuses = local.listStatus(new Path("file:/Users/healchow/bigdata/test"));
for (FileStatus fileStatus : fileStatuses) {
// 创建输入流,操作完即关闭
if (fileStatus.getPath().getName().contains("user")) {
FSDataInputStream inputStream = local.open(fileStatus.getPath());
IOUtils.copy(inputStream, outputStream);
IOUtils.closeQuietly(inputStream);
}
}
// 关闭输出流和文件系统
IOUtils.closeQuietly(outputStream);
local.close();
fileSystem.close();
}
合并的结果,和通过命令合并的完全一致:

版权声明
出处:博客园-瘦风的南墙(https://www.cnblogs.com/shoufeng)
感谢阅读,公众号 「瘦风的南墙」 ,手机端阅读更佳,还有其他福利和心得输出,欢迎扫码关注
本文版权归博主所有,欢迎转载,但 [必须在页面明显位置标明原文链接],否则博主保留追究相关人士法律责任的权利。
HDFS 07 - HDFS 性能调优之 合并小文件的更多相关文章
- Hive性能调优(一)----文件存储格式及压缩方式选择
合理使用文件存储格式 建表时,尽量使用 orc.parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量. 采用合 ...
- spark 性能调优(一) 性能调优的本质、spark资源使用原理、调优要点分析
转载:http://www.cnblogs.com/jcchoiling/p/6440709.html 一.大数据性能调优的本质 编程的时候发现一个惊人的规律,软件是不存在的!所有编程高手级别的人无论 ...
- [Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析
本課主題 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- Spark 常规性能调优
1. 常规性能调优 一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的,实现了最优的资源配置后,在此基础上再考虑进行后面论述的性 ...
- Spark的性能调优杂谈
下面这些关于Spark的性能调优项,有的是来自官方的,有的是来自别的的工程师,有的则是我自己总结的. 基本概念和原则 <1> 每一台host上面可以并行N个worker,每一个worke ...
- Informatica_(6)性能调优
六.实战汇总31.powercenter 字符集 了解源或者目标数据库的字符集,并在Powercenter服务器上设置相关的环境变量或者完成相关的设置,不同的数据库有不同的设置方法: 多数字符集的问题 ...
- MySQL性能调优与架构设计——第 15 章 可扩展性设计之Cache与Search的利用
第 15 章 可扩展性设计之Cache与Search的利用 前言: 前面章节部分所分析的可扩展架构方案,基本上都是围绕在数据库自身来进行的,这样是否会使我们在寻求扩展性之路的思维受到“禁锢”,无法更为 ...
- Hive(十)Hive性能调优总结
一.Fetch抓取 1.理论分析 Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算.例如:SELECT * FROM employees;在这种情况下,Hive可以简单 ...
- Spark的性能调优
下面这些关于Spark的性能调优项,有的是来自官方的,有的是来自别的的工程师,有的则是我自己总结的. Data Serialization,默认使用的是Java Serialization,这个程序员 ...
随机推荐
- Day001 电脑常用快捷键
电脑常用快捷键 Ctrl+C 复制 Ctrl+V 粘贴 Ctrl+A 全选 Ctrl+X 剪切 Ctrl+Z 撤销 Ctrl+S 保存 Alt+F4 关闭窗口(英雄联盟选英雄界面可以查看对面阵容(狗头 ...
- idea使用lombok不生效
问题: 在maven项目中引入lombok的依赖,可是依旧无法在实体类中生效 <dependency> <groupId>org.projectlombok</group ...
- spring boot pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/20 ...
- Jmeter和Postman做接口测试的区别,孰优孰劣?
区别1:用例组织方式 不同的目录结构与组织方式代表不同工具的测试思想,学习一个测试工具应该首先了解其组织方式. Jmeter的组织方式相对比较扁平,它首先没有WorkSpace(工作空间)的概念,直接 ...
- Govern Service 基于 Redis 的服务治理平台
Govern Service 基于 Redis 的服务治理平台(服务注册/发现 & 配置中心) Govern Service 是一个轻量级.低成本的服务注册.服务发现. 配置服务 SDK,通过 ...
- 小甲鱼零基础入门学习python--课后作业
[小甲鱼零基础入门学习python--课后作业] 小甲鱼零基础入门学习python--课后作业 本章内容: 1.基础部分的作业 2.函数部分的作业 3.字典.集合.文件部分作业 4.异常 5.Easy ...
- gitlab同步插件gitlab-mirrors报错<已解决,未找到原因>
今天下午在使用gitlab-mirrors同步插件时,发现一直在报错 # ~/gitlab-mirrors/add_mirror.sh --git --project-name manifests - ...
- 如何用WINPE备份电脑系统;电脑备份 听语音
如何用WINPE备份电脑系统:电脑备份 听语音 原创 | 浏览:1046 | 更新:2017-09-30 15:09 1 2 3 4 5 6 7 分步阅读 备份系统已经成为一种常态,我们在安装完成系统 ...
- coverage report
转载:http://blog.sina.cn/dpool/blog/s/blog_7853c3910102yn77.html VCS仿真可以分成两步法或三步法, 对Mix language, 必须用三 ...
- shell进阶之tree、pstree、lsof命令详解
一.tree命令详解: 主要功能是创建文件列表,将所有文件以树的形式列出来 -a 显示所有文件和目录. -A 使用ASNI绘图字符显示树状图而非以ASCII字符组合. -C 在文件和目录清单加上色彩, ...