Elasticsearch BM25相关度算法超详细解释

Photo by Pixabay from Pexels
前言:日常在使用Elasticsearch的搜索业务中多少会出现几次 “为什么这个Doc分数要比那个要稍微低一点?”、“为什么几分钟之前还是正确的结果现在确变了?”之类的疑问。
抱着深入探究的学习态度还是决定要把相关度评分算法摸透,本文内容基于目前的7.14版本,尽量以通俗易懂的话语详细解释这些概念。
1. Elasticsearch中的相关性计算
在正式进入算法解析阶段之前,先一步一步的补足相关的概念知识,这会帮助我们更好的学习和理解。
1.1 什么是相关性评分(relevance score)?
相关性评分(relevance score)是衡量每个文档与输入查询匹配的程度。默认情况下,Elasticsearch根据相关性评分对匹配的搜索结果进行排序。
相关性评分是一个正浮点数,在Search API的score元数据字段中返回。score越高,说明文档越相关。。。
一个简单的示例,首先通过bulk API 或者你熟悉的方式向索引里写入一些数据,这里以书名为例。
POST _bulk
{ "index" : { "_index" : "book_info", "_id" : "1" } }
{ "book_name" : "《大学》" }
{ "index" : { "_index" : "book_info", "_id" : "2" } }
{ "book_name" : "《中庸》" }
{ "index" : { "_index" : "book_info", "_id" : "3" } }
{ "book_name" : "《论语》" }
{ "index" : { "_index" : "book_info", "_id" : "4" } }
{ "book_name" : "《孟子》" }
{ "index" : { "_index" : "book_info", "_id" : "5" } }
{ "book_name" : "《道德经》" }
{ "index" : { "_index" : "book_info", "_id" : "6" } }
{ "book_name" : "《诗经》" }
{ "index" : { "_index" : "book_info", "_id" : "7" } }
{ "book_name" : "《春秋》" }
然后执行一个最简单的查询,搜索索引内书名匹配“诗经”这两个字的书籍信息
GET /book_info/_search
{
"query": {
"match": { "book_name": "诗经" }
}
}
//得到以下响应
{
"took" : 2,
........
"max_score" : 2.916673,
"hits" : [
{
"_index" : "book_info",
"_type" : "_doc",
"_id" : "6",
"_score" : 2.916673,
"_source" : {
"book_name" : "《诗经》"
}
},
{
"_index" : "book_info",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.99958265,
"_source" : {
"book_name" : "《道德经》"
}
}
]
}
}
可以看到结果如同预期的,《诗经》这本书的相关性评分为 2.916673 ,而第二本书因为只匹配了一个“经”字,所以得分较低。现在我们的目的就是彻底吃透这两个分数是如何计算的,以应对实际使用时的各种问题。
1.2 相关度评分是如何计算的?
Elasticsearch是基于 Lucene 之上的搜索引擎,这部分深入的内容以及概念留到后面补充,否则只会出现片面的描述或者陷入递归式的探究中。现在,先让我们囫囵吞枣的理解眼前的事物。
Elasticsearch中的相关性评分计算可以参考Elasticsearch文档相似模块的描述,传送门:Elasticsearch | Index Modules Similarity
在不做任何配置,默认的情况下我们可以使用以下三种相似度评分算法:
- BM25:Okapi BM 25算法。在Elasticearch和Lucene中默认使用的算法。
- classic: 在7.0.0中标记为过时。基于TF/IDF 算法,以前在Elasticearch和Lucene中的默认值。
- boolean:一个简单的布尔相似度算法,当不需要全文排序时可以使用,并且分数应该只基于查询项是否匹配。布尔相似度给查询一个简单的分数,等价于设置的Query Boost。
通过以上描述我们可以了解到,Elasticsearch中默认的评分算法是BM25算法,且其他两个选项一个被标记过时,一个不适用于全文检索排序。现在实际尝试一下上面提到的三种算法,由于classic算法已经被标记过时,这里直接在Mapping中使用classic会直接抛出异常并提示我们可以使用脚本自定义实现原本的classic算法
{
"type" : "illegal_argument_exception",
"reason" : "The [classic] similarity may not be used anymore. Please use the [BM25] similarity or build a custom [scripted] similarity instead."
}
按照文档中给出的示例编写索引Mapping:
//删除之前创建的索引
DELETE book_info
//创建自定义的索引并制定字段类型、相关度评分算法
PUT book_info
{
"mappings": {
"properties": {
//默认字段依旧采用BM25,并且对该字段赋值时自动复制到下面两个字段
"book_name": {
"type": "text",
"similarity": "BM25",
"copy_to": [
"book_name_classic",
"book_name_boolean"
]
},
//这个字段使用classic相关度算法
"book_name_classic": {
"type": "text",
"similarity": "my_classic"
},
//这个字段使用boolean相关度算法
"book_name_boolean": {
"type": "text",
"similarity": "boolean"
}
}
},
"settings": {
"number_of_shards": 1,
"similarity": {
"my_classic": {
"type": "scripted",
"script": {
"source": "double tf = Math.sqrt(doc.freq); double idf = Math.log((field.docCount+1.0)/(term.docFreq+1.0)) + 1.0; double norm = 1/Math.sqrt(doc.length); return query.boost * tf * idf * norm;"
}
}
}
}
}
之后用与上面相同的Bulk请求填充一下数据,即可观察相关性算法配置的结果,在这里不对结果进行解析。
GET /book_info/_search
{
"query": {
"match": {
"book_name": {
"query": "诗经"
}
}
}
}
GET /book_info/_search
{
"query": {
"match": {
"book_name_classic": {
"query": "诗经"
}
}
}
}
GET /book_info/_search
{
"query": {
"match": {
"book_name_boolean": {
"query": "诗经"
}
}
}
}
2. BM 25 算法
通过第一章的描述,我们知道了现在在Elasticsearch中的相关性评分默认采用BM25相似度算法,下面正式进入算法的学习阶段。
BM25全称Okapi BM25。Okapi 是使用它的第一个系统的名称,即Okapi信息检索系统,BM则是best matching的缩写。
BM25是基于TF-IDF算法并做了改进,基于概率模型的文档检索算法,目前BM25及其较新的变体(例如BM25F)代表了文档检索中使用的最先进的TF/IDF类检索功能。
现在,抛开中文分词器、同义词、停词等一切可能的干扰项,我们就使用最基本的Standard分词器,准备一点英文文档数据:
PUT _bulk
{ "index" : { "_index" : "people", "_id" : "1" } }
{ "title": "Shane" }
{ "index" : { "_index" : "people", "_id" : "2" } }
{ "title": "Shane C" }
{ "index" : { "_index" : "people", "_id" : "3" } }
{ "title": "Shane Connelly" }
{ "index" : { "_index" : "people", "_id" : "4" } }
{ "title": "Shane P Connelly" }
下面是BM25算法的标准公式,表示给定一个查询Q,包含关键字 q{1},...,q{n},文档D的BM 25分数计算公式为
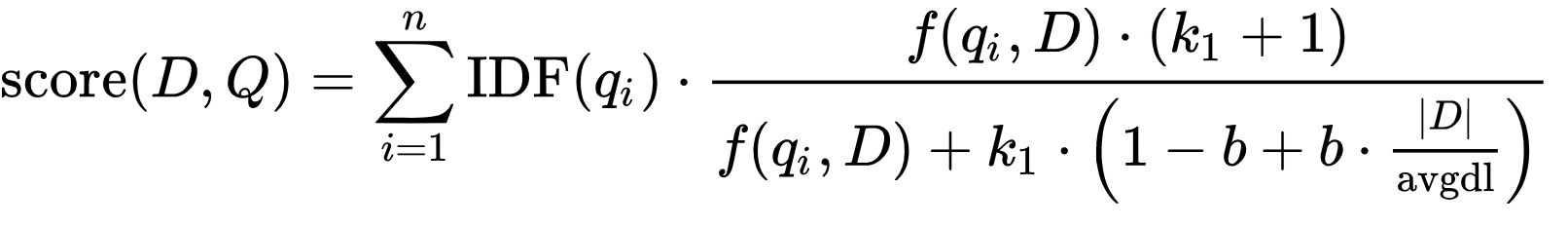
现在详细解释等式每个部分的含义
2.1 搜索项 qi及词频TF
\(q_i\) : 查询项,例如我搜索“Shane”,只有一个查询项,所以 \(q_0\) 是“Shane”。
如果我用英语搜索“Shane Connelly”,Elasticsearch将看到空格并将其标记为两个Term:
- \(q_0\) :Shane
- \(q_1\): Connelly
\(f(q_i,D)\) : D 是文档, Term Frequency (TF)是指Term在文档中出现的频率,即词频。Term在文档中出现的权重与频率成正比。用最通俗易懂的话来说就是查询的词语在文档中出现了多少次。
这很有直觉意义,例如我正在搜索Elasticsearch,一篇文章内提到了一次可能只是简单的引用,如果文章中出现了很多次Elasticsearch那就更有可能与我们的搜索内容相关。
2.2 逆文档频率 IDF
\(IDF(q_i)\): 查询项的逆文档频率,衡量这个词提供了多少信息,也就是说它在所有文档中是常见的还是罕见的。这
其中的含义是如果一个搜索词是非常罕见的词语(例如专业术语)且在某个文档中匹配了,则分数会提高;反之对于非常常见的匹配词降低分数。
TF-IDF中原本的逆文档频率公式是这样的:
\]
其中,变量\(N\)可以看做索引中的文档总数,\(n(q_i)\) 代表索引中包含查询项\(q_i\)的文档数量。
而BM25算法中对这个公式进行了一些改造,如下:
\]
以这一章开头写入的索引数据为例,假如我们在当前索引people 中搜索文本“Shane”,“Shane”这个词语出现在4个文档中,将这个数值代入到上面的公式则:
- \(n(q_i)\) : 索引文章中包含查询项Shane 的文档数量 = 4
- N:索引中的文档总数 = 4
\]
我们在Kibana中请求Elasticsearch的 explain 端点来验证分析一下
GET /people/_search
//Response, 验证一下我们的文档内容全部包含 Shane
{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "people",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : { "title" : "Shane" }},
{
"_index" : "people",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : { "title" : "Shane C" }},
{
"_index" : "people",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : { "title" : "Shane Connelly" }},
{
"_index" : "people",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.0,
"_source" : { "title" : "Shane P Connelly" }}
]
}
}
//然后调用explain
POST people/_explain/1
{
"query":{
"match":{
"title":"Shane"
}
}
}
//得到以下结果
{
"_index" : "people",
"_type" : "_doc",
"_id" : "1",
"matched" : true,
"explanation" : {
"value" : 0.13245323,
"description" : "weight(title:shane in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.13245323,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
//省去boost,重点看下面的idf
{
"value" : 0.105360515,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 4,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
}
//省去tf,重点看上面的idf
]
}
]
}
}
注意看73行计算的结果,和我们上面在公式里计算的结果是相同的。
2.3 字段长度与平均长度部分
现在把视角移到公式分母的右下角部分。其中\(|D|\)代表文档的长度,\(avgdl\) 代表平均字段长度(avgFieldLen)。
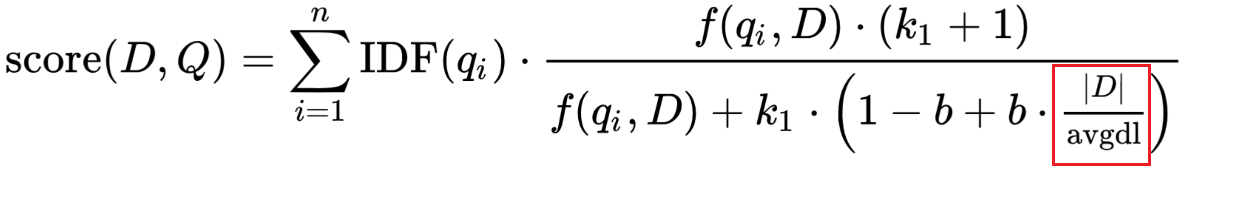
如果文档比平均值长,分母就会变大(降低分数),如果文档比平均值短,分母就会变小(提高分数)。注意,Elasticsearch中字段长度的实现是基于Term数量的(而不是字符长度之类的)。
考虑这个问题的方法是,文档中的词语越多(至少是与查询不匹配的术语),文档的得分就越低。同样,这也很直观:如果一份300页长的文档只提到过我的名字一次,那么它与我的关系可能不如一条只提到过我一次的文章段落。
2.4 可调节变量 b 和 k1
这是中BM25算法中可调节的两个参数,在使用Elasticsearch的过程中也可以作为一些特殊搜索场景的调优点。
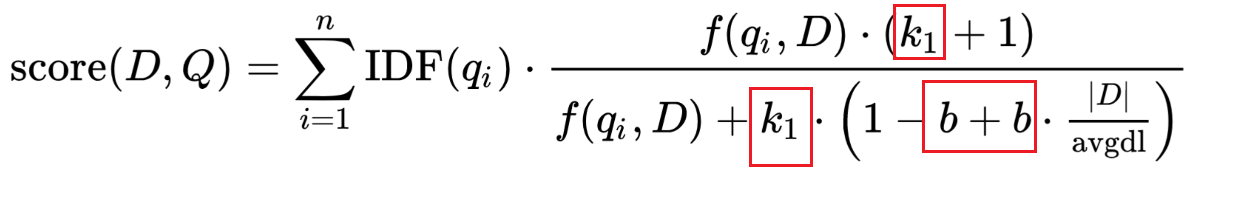
k1 : 控制非线性词频率归一化(饱和),Elasticsearch中默认值为1.2。用人能看懂的话说就是词语在文档中出现的次数对于得分的重要性。例如说我觉得在某些场景,一个搜索词在文档中出现越多则越接近我希望搜索的内容,就可以将这个参数调大一点。
b :控制文档长度对于分数的惩罚力度。变量b处于分母上,它乘以刚刚讨论过的字段长度的比值,Elasticsearch中的b 默认值为0.75。 如果b较大,则文档长度相对于平均长度的影响更大。 可以想象如果将b设置为0,那么长度比率的影响将完全无效,文档的长度将与分数无关。
另外Elasticsearch中还有一个参数 discount_overlaps 确定计算标准时是否忽略重叠标记(位置增量为0的标记,这种情况一般是同义词)。 默认情况下为true,这意味着在计算规范时不计算重叠标记。
k1值越高/越低,说明BM25“tf()”的曲线斜率发生变化。 这就改变了“词语出现的额外次数会增加额外分数”的方式。 k1的一种解释是,对于平均长度的文档,词频的值为所考虑的词语的最大分数的一半。 tf()≤k1时,tf()对评分的影响曲线增长迅速,tf() > k1时,影响曲线增长越来越慢。
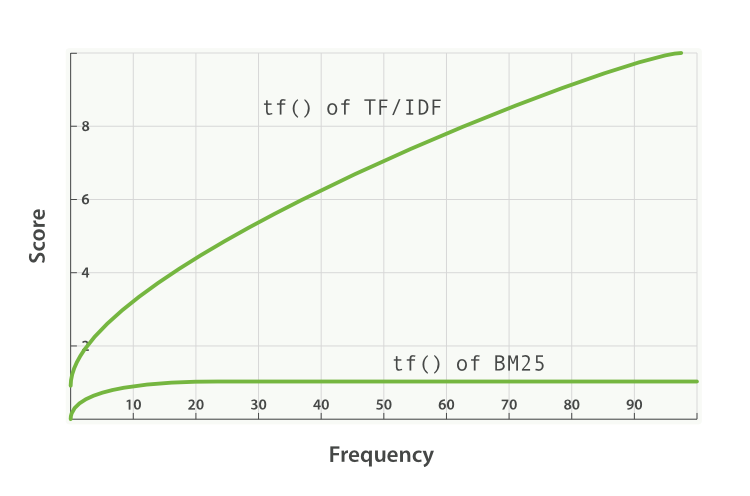
使用k1,我们可以控制以下问题的答案:
“ 在文档中添加第二个‘shane’比第一个‘shane’,再或者,第三个‘shane’与第二个‘shane’相比,对分数的贡献应该多多少?”
这句话有点拗口,但确实表达了正确的含义。换个问题,我在Google上搜索‘Elasticsearch’ ,出现的结果文章列表中匹配‘Elasticsearch’关键字的数量是非常重要的吗?
较高的k1意味着每一项的分数在该项的更多实例中可以相对更高地继续上升。 k1的值为0意味着除了IDF(qi)之外的所有东西都将被抵消 。
现在,我们在准备好的示例数据中验证一下上面两个参数的说明是否正确,先看看在不更改索引的默认情况下分数计算情况:
POST people/_explain/1
{
"query":{
"match":{
"title":"Shane"
}
}
}
//Response ,省去了Boost、idf等其他无关部分
{
"value" : 0.5714286,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 1.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 2.0,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
上面的代码块中是词频部分的计算结果,此时是默认的索引设置,k1 = 1.2, b=0.75 。在这种默认设置下文档的长度惩罚、词频相关较为均衡。例如现在加入一条混淆数据:
PUT people/_doc/5
{
"title": "Shane Shane P"
}
如果我们搜索关键字“Shane”则会发现这条数据虽然因为有两个单词匹配,但是因为文档长度而分数略低于完全匹配的1号文档:
GET /people/_search
{
"query":{
"match":{
"title":"Shane"
}
}
}
//Response
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 0.112004004,
"hits" : [
{
"_index" : "people",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.112004004,
"_source" : {
"title" : "Shane"
}
},
{
"_index" : "people",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.108539954,
"_source" : {
"title" : "Shane Shane P"
}
}
.......
]
}
}
假如我们希望能在文档中尽量匹配更多的搜索词,即使文档长度稍微长一点也没关系,则可以尝试着将 k1 增大, 同时降低 变量 b :
PUT /people2
{
"mappings": {
"properties": {
"title": {
"type": "text",
"similarity": "my_bm25"
}
}
},
"settings": {
"number_of_shards": 1,
"index": {
"similarity": {
"my_bm25": {
"type": "BM25",
"b": 0.5,
"k1": 1.5
}
}
}
}
}
PUT _bulk
{ "index" : { "_index" : "people2", "_id" : "1" } }
{ "title": "Shane" }
{ "index" : { "_index" : "people2", "_id" : "2" } }
{ "title": "Shane C" }
{ "index" : { "_index" : "people2", "_id" : "3" } }
{ "title": "Shane Connelly" }
{ "index" : { "_index" : "people2", "_id" : "4" } }
{ "title": "Shane P Connelly" }
{ "index" : { "_index" : "people2", "_id" : "5" } }
{ "title": "Shane Shane P" }
GET /people2/_search
{
"query": {
"match": {
"title": {
"query": "Shane"
}
}
}
}
现在,搜索的最佳结果将是我们期望的5号文档:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 0.11531627,
"hits" : [
{
"_index" : "people2",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.11531627,
"_source" : {
"title" : "Shane Shane P"
}
},
{
"_index" : "people2",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.10403533,
"_source" : {
"title" : "Shane"
}
}
......
]
}
}
3. 为什么要学习BM25
当我们在实际应用中,不能快速正确的找到文档时,首先要做的事情通常不是调整算法的参数b和k1。默认值b = 0.75和k1 = 1.2在大多数情境中都可以很好地工作。更加值得尝试的或许是调整业务逻辑对查询语句的应用,找出问题的规律并在应用端解决,例如:
在bool查询中为精确短语匹配之类的事情增加或添加常量分数
利用同义词来匹配用户可能感兴趣的其他单词
添加模糊、打印、语音匹配、词干提取和其他文本/分析组件,以帮助解决拼写错误、语言差异等问题。
添加或使用 Function Score 来衰减较旧文档或地理位置上离最终用户较远的文档的评分
如果业务上已经没有任何改动余地,走完了该走的路再来思考一下调整参数是否会带来一些好的改变。
基于以上这些考虑,为什么要理解BM25算法呢,我觉得更多是出于个人的追求和探索。
可以是为了在应用搜索时理解其内部到底发生了什么,如果结果的顺序不理想,是查询语句的问题还是索引文档的问题?
可以是为了触类旁通,可能在实际应用中还有其他的相似度算法,此时在有预备知识的情况下可以对比参考,学习更多内容。
。。。
4. 如何调节评分算法
首先对于BM25算法,所有数据/查询,都不存在“最佳”b和k1值。确定更改b和k1参数的用户可以通过计算每个增量逐步的寻找最佳点。Elasticsearch中的Rank Eval API 和Explain API都可以很好的帮助评估参数改变带来的影响。
在试验b和k1时,应该首先考虑它们的边界。从一些历史的经验中可以得到一些指导:
b 必须在0和1之间。许多实验以0.1左右的增量测试值,大多数实验似乎表明最佳b的范围在0.3-0.9 (Lipani, Lupu, Hanbury, Aizawa (2015);Taylor, Zaragoza, Craswell, Robertson, Burges (2006);Trotman, Puurula, Burgess (2014);等等)。
k1 通常在0到3的范围内进行实验。许多实验集中在0.1到0.2的增量上,大多数实验似乎表明最佳的k1在0.5-2.0范围内。
对于k1可以尝试着回答,“对于很长的文档我们什么时候认为一项可能是饱和的?”。比如书籍,很可能在一部作品中多次出现很多不同的术语,即使这些术语与整个作品并不是高度相关。例如,“眼睛”或“眼睛”在一本小说中可以出现数百次,即使“眼睛”不是这本书的主要主题之一。然而,一本书提到“眼睛”一千次,可能与眼睛有更多的关系。在这种情况下,你可能不希望项很快饱和,所以有人建议,当文本更长更多样化时,k1通常应该趋向于更大的数字。对于相反的情况,建议将k1设置在较低的一边。如果一篇短篇新闻没有与眼睛高度相关的主题,那么它就不太可能出现几十到几百次的“眼睛”。
对于b可以尝试着回答,“我们什么时候认为文档可能很长,什么时候这会影响到它与术语的相关性?”。高度具体的文档,如工程规范或专利是冗长的,以更具体的主题。它们的长度不太可能对相关性有害,b可能更适合更低。另一方面,涉及几个不同的主题广泛的方式——新闻文章(政治的文章可能涉及经济学、国际事务和某些公司),用户评论,等等。(通常是通过选择一个更大的受益b这样无关紧要的话题用户的搜索,包括垃圾邮件等,都受到处罚。
这些都是一般的起点,但最终应该测试设置的所有参数。这也展示了相关性是如何与相同索引中的类似文档紧密结合在一起的。
除此之外,Elasticsearch中还是很多其他算法可供选择,还可以通过脚本实现自己的评分算法。说起来,Elasticsearch为什么将BM25作为默认评分算法?k1 和 b 的默认值为什么是 1.2 和 0.75呢?
简短的答案是:工业实践与实验的结果,在算法或选择k1或b值方面似乎没有任何银弹,但在大多数情况下,k1 = 1.2和b = 0.75的BM25工作的非常好。
5. Elasticsearch中Shard对于评分的影响
虽然通过上面的知识我们了解的BM25的评分机制和参数选择,但索引内的文档、查询、参数并不是所有影响相关性分数的因素,索引分片也对分数有一些影响,这方面内容还是了解一下为好,否则出现问题的时候会一头雾水。
上面给出的示例都是在一个分片内的搜索,现在我们改变一下索引:
PUT book_info
{
"settings": {
"number_of_shards": 2,
"number_of_routing_shards":2,
"number_of_replicas": 0
}
}
PUT book_info/_doc/1?routing=0
{ "book_name" : "《诗经·风》" }
PUT book_info/_doc/2?routing=0
{ "book_name" : "《诗经·雅》" }
PUT book_info/_doc/3?routing=1
{ "book_name" : "《诗经·颂》" }
PUT book_info/_doc/4?routing=0
{ "book_name" : "《道德经》" }
PUT book_info/_doc/5?routing=1
{ "book_name" : "《易经》" }
GET /book_info/_search
{
"query": {
"match": {
"book_name": "诗经·颂"
}
}
}
在这种情况下,你会发现搜索《诗经·颂》时,诗经风、雅的文档得分是相同的(0.603535)
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.4499812,
"hits" : [
{
"_index" : "book_info",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.4499812,
"_routing" : "1",
"_source" : {
"book_name" : "《诗经·颂》"
}
},
{
"_index" : "book_info",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.603535,
"_routing" : "0",
"_source" : {
"book_name" : "《诗经·风》"
}
},
{
"_index" : "book_info",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.603535,
"_routing" : "0",
"_source" : {
"book_name" : "《诗经·雅》"
}
}
]
}
}
而反过来搜索诗经风、雅的时候,另外两本诗经的得分却不相同:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.5843642,
"hits" : [
{
"_index" : "book_info",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.5843642,
"_routing" : "0",
"_source" : {
"book_name" : "《诗经·风》"
}
},
{
"_index" : "book_info",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.80925685,
"_routing" : "1",
"_source" : {
"book_name" : "《诗经·颂》"
}
},
{
"_index" : "book_info",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.603535,
"_routing" : "0",
"_source" : {
"book_name" : "《诗经·雅》"
}
}
]
}
}
这是因为在Elasticsearch中按每个分片计算分数,而不是按整个索引计算分数。回忆一下上面BM25算法中的词频和逆文档频率部分的计算过程中,我们需要用到 索引文章中包含查询项的文档数量 和 索引中的文档总数,这些都是在分片内计算的。
现在用explain来验证一下这个说法:
//在不同的分片中分别查看分数计算情况
POST book_info/_explain/1?routing=0
{
"query": {
"match": { "book_name": "诗经·风" }
}
}
//只看IDF部分的影响,注意这里的包含查询项的文档数量小n是2,文档总数大N是3
{
"value" : 0.47000363,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
}
POST book_info/_explain/3?routing=1
{
"query": {
"match": { "book_name": "诗经·颂" }
}
}
//而在分片1中,包含查询项的文档数量小n是1,文档总数大N是2
{
"value" : 0.6931472,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 1,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 2,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
在这种例子中,“诗经”这个词在不同的索引分片内出现的频率是不同的,分数计算也当然不同。
如果开始在索引中加载几个文档,就问“为什么文档A的分数比文档B高/低”,有时答案是碎片与文档的比率相对较高,从而使分数在不同的碎片之间倾斜。有几种方法可以在各个碎片之间获得更一致的分数:
加载到索引中的文档越多,分片的统计数据就会变得越规范化。有了足够多的文档,词频统计数据的细微差异不足以影响到每个分片中的评分细节。
可以使用更低的碎片计数来减少术语频率的统计偏差。
尝试在请求中添加
search_type=dfs_query_then_fetch参数,该请求首先收集分布式词频(DFS =分布式词频搜索),然后使用它们计算分数。这种情况下返回的分数就像是索引只有一个shard一样。这个选项使用从运行搜索的所有分片收集的信息,全局计算分布式项频率。虽然提高了评分的准确性,但它增加了对每个分片的往返搜索时间,可能导致更慢的搜索请求。
参考链接
- https://en.wikipedia.org/wiki/Okapi_BM25
- https://en.wikipedia.org/wiki/Tf–idf
- https://www.elastic.co/guide/en/elasticsearch/reference/7.14/similarity.html
- https://www.elastic.co/cn/blog/practical-bm25-part-1-how-shards-affect-relevance-scoring-in-elasticsearch
- https://www.elastic.co/cn/blog/practical-bm25-part-2-the-bm25-algorithm-and-its-variables
Elasticsearch BM25相关度算法超详细解释的更多相关文章
- 人工鱼群算法超详细解析附带JAVA代码
01 前言 本着学习的心态,还是想把这个算法写一写,给大家科普一下的吧. 02 人工鱼群算法 2.1 定义 人工鱼群算法为山东大学副教授李晓磊2002年从鱼找寻食物的现象中表现的种种移动寻觅特点中得到 ...
- 干货 | 10分钟带你掌握branch and price(分支定价)算法超详细原理解析
00 前言 相信大家对branch and price的神秘之处也非常好奇了.今天我们一起来揭秘该算法原理过程.不过,在此之前,请大家确保自己的branch and bound和column gene ...
- Java进阶(十五)Java中设置session的详细解释
Java中设置session的详细解释 简单通俗的讲session就是象一个临时的容器,用来存放临时的东西.从你登陆开始就保存在session里,当然你可以自己设置它的有效时间和页面,举个简单的例子: ...
- Linux下函数调用堆栈帧的详细解释【转】
转自:http://blog.chinaunix.net/uid-30339363-id-5116170.html 原文地址:Linux下函数调用堆栈帧的详细解释 作者:cssjtuer http:/ ...
- in文件注意事项及详细解释
lammps做分子动力学模拟时,需要一个输入文件(input script),也就是in文件,以及关于体系的原子坐标之类的信息文件(data file)和势文件(potential file).lam ...
- Atitit .jvm 虚拟机指令详细解释
Atitit .jvm 虚拟机指令详细解释 1. 一.未归类系列A1 2. 数据mov系列2 2.1. 二.const系列2 2.2. 三.push系列2 2.3. ldc系列 该系列命令负责把数值常 ...
- NEMA-0183(GPRMC GPGGA)详细解释
NEMA-0183(GPRMC GPGGA)详细解释 nmea数据如下: $GPGGA,121252.000,3937.3032,N,11611.6046,E,1,05,2.0,45.9,M,-5. ...
- 影响ES相关度算分的因素
相关性算分 指文档与查询语句间的相关度,通过倒排索引可以获取与查询语句相匹配的文档列表 如何将最符合用户查询需求的文档放到前列呢? 本质问题是一个排序的问题,排序的依据是相关性算分,确定倒排索引哪 ...
- in文件注意事项及详细解释(转载)
转载自:https://www.cnblogs.com/sysu/p/10817315.html 和 https://www.cnblogs.com/panscience/p/4953940.h ...
随机推荐
- buu 红帽杯easyre
一.拖入ida静态分析 找到关键函数,然后 这步是可以得出前4个字符是flag,不知道为啥我这边的v15的内存地址为空,不然可以异或解出来的,ida日常抽风... 十次的base64加密,我用在线平台 ...
- ESP32-http server笔记
基于ESP-IDF4.1 #include <esp_wifi.h> #include <esp_event.h> #include <esp_log.h> #in ...
- Python如何设计面向对象的类(下)
本文将在上篇文章二维向量Vector2d类的基础上,定义表示多维向量的Vector类. 第1版:兼容Vector2d类 代码如下: from array import array import rep ...
- Js中关于构造函数,原型,原型链深入理解
在 ES6之前,在Javascript不存在类(Class)的概念,javascript中不是基于类的,而是通过构造函数(constructor)和原型链(prototype chains)实现的.但 ...
- ffiddler抓取手机(app)https包
很多同学有看过原文,但是按照原文还是没有设置成功(我就是其中一个)然后查了网上资料,在某些选项上进行增加,填写,配置通过.(和原文略有不同) 安装Fiddler,我们正常的流程在feiddler中设置 ...
- 管理员的基本防范措施 Linux系统安全及应用
系统安全及应用一.账号安全基本措施① 系统账号清理② 密码安全控制③ 命令历史限制④ 终端自动注销二.SU命令切换用户① 用途及用法② 验证密码③ 限制使用su命令的用户④ 查看su操作记录补充三.L ...
- CTF-wtc_rsa_bbq-writeup
wtc_rsa_bbq 题目信息: 附件: cry200 解题思路: 1.观察cry200文件,发现该文件是一个二进制文件,用二进制模式查看,发现开头为50 4B 03 04,判断该文件是一个zip文 ...
- 使用deepin系统自带命令切割视频使用lossless免费软件切割
1,使用ffmpeg命令:ffmpeg -ss 00:00:10 -i gaodengshuxue.mp4 -vcodec copy -acodec copy -t 00:00:20 output.m ...
- linux相关的常用站点
1 http://cdimage.ubuntu.com/ ubuntu各个发行版的总集服务器 2 http://www.rpmfind.net/ 各种RPM包
- Leetcode13. 罗马数字转整数Leetcode14. 最长公共前缀Leetcode15. 三数之和Leetcode16. 最接近的三数之和Leetcode17. 电话号码的字母组合
> 简洁易懂讲清原理,讲不清你来打我~ 输入字符串,输出对应整数 ![在这里插入图片描述](https://img-blog.csdnimg.cn/63802fda72be45eba98d9e4 ...