使用 python 把一个文件生成 C 语言中的数组并保存到头文件中
(一)要做什么
之前有这么一个需求,是要把一个二进制文件里面的数据,转换成 C 代码里面的数组,可以看之前的一篇文章:
NUC980 运行 RT-Thread 驱动 SPI 接口 OLED 播放 badapple
于是用 python 把这个功能给做了出来,原理非常简单,代码量也很小。
所处理的文件大小如下,用一个编辑器以二进制形式打开的话,一行16字节,一共 336448 行。
(二)实现功能
上代码,Show me your code.Talk is cheap.
import os
import time
start_time = time.time()
fileinfo = os.stat("badapple.bin")
line = fileinfo.st_size / 16
print(line)
首先导入 os、time 模块,os 模块用户获取所处理文件的大小,生成的头文件里面的数组每 16 字节一行,time 模块用于统计程序所使用时间,上述代码运行结果为:

336648 行,正好与之前看到的一致。
然后定义一个变量,用来存储最终的数据:
target = "#ifndef __BADAPPLE_H__ \n#define __BADAPPLE_H__\n\n const uint8_t badapple[] = \n{\n"
然后打开文件 badapple.bin,以二进制、只读方式打开,每次读取一字节,然后转换成二进制,与 0x 组成一个字节数据,保存到上述字符串中,每处理完 16 字节添加换行,处理完后关闭文件,代码如下:
f = open("badapple.bin", "rb")
for l in range(int(line)):
for j in range(16):
data = f.read(1)
he = "0x" + data.hex()
target = target + he + ","
print(l)
target = target + "\n"
target = target + "}; \n\n#endif\n"
print(target)
f.close()
由于全部数据有 30 多万行,不好测试,先只处理 badapple.bin 文件中的前 15 行,来测试下代码有没有问题,把上面代码中的第二行改为:
for l in range(15):
运行结果为:
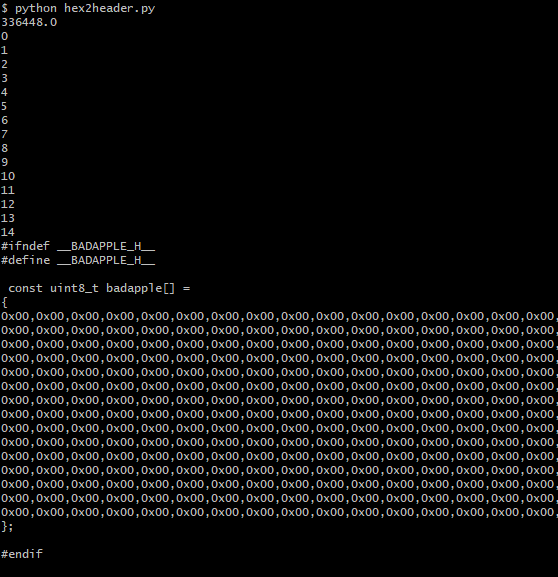
看上去是可以的,然后实现把转换出来的数据保存到文件中,并加上获取运行改代码所花时间,代码如下:
file = open("badapple.h","w")
file.write(target)
file.close()
end_time = time.time()
print(end_time - start_time)
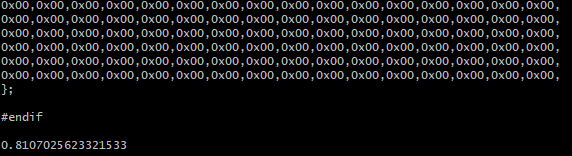
运行结果为:
所生成的文件为:
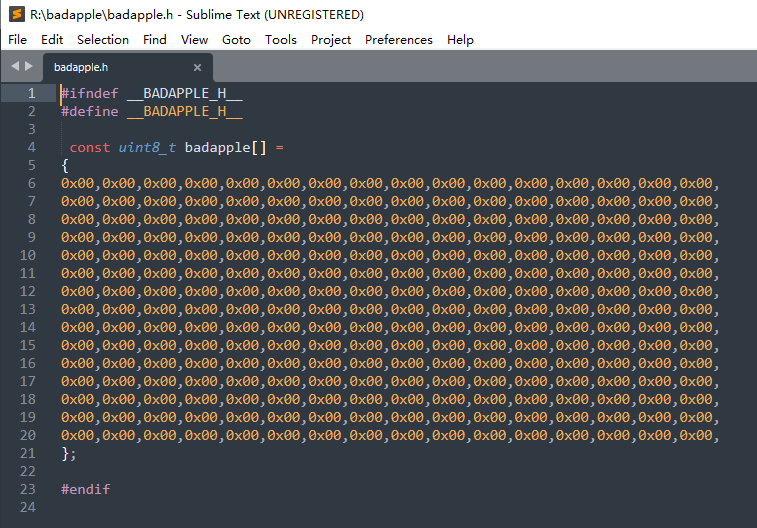
从所生成的文件来看,算是大功告成了,把所需处理行数改为实际文件的行数,就完成了。
然而,我还是图样图森破啊,我以为我在第二层,其实我在第五层。
第一次运行的时候,跑了几十分钟,停了,感觉所花时间大大久了,
出于对自己写的代码负责的态度,第二天下午 3 点多的时候,再次把这代码跑了起来,可是到了6点多还是没跑完,又中途结束了,
很好奇,究竟需要多长时间来跑,第三天,一早上就把代码跑了起来,结果是到了下午 6 点多,差不多 7 点才跑完,来看下运行的最后结果:
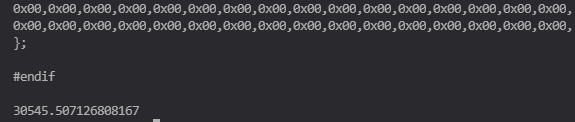
从数字来看,30545 秒,感觉也不是很大,可是转换为小时的话:
30545 / 60 / 60 = 8.4
居然达到了 8.4 个小时,这是生成的文件:
(三) 优化
要这么久时间来跑肯定是不实际的,修改下代码,之前是一个字节一个字节从文件里面读出来,这次改为每次从文件中读取 16 字节,转换,然后再读取16字节,知道结束,代码如下:
target = "#ifndef __BADAPPLE_H__ \n#define __BADAPPLE_H__\n\n const uint8_t badapple[] = \n{\n"
line = fileinfo.st_size / 16
print(line)
for l in range(int(line)):
data = f.read(16)
he = ""
for da in data:
he = he + hex(da) + ","
print(l)
target = target + he + "\n"
target = target + "}; \n\n#endif\n"
运行下,最后结果为:

2165 秒,大概是 36 分钟,也还是有点长。
再改改,对比下这 2 中方法,第二种是每次读出来的字节数是第一种的16倍,速度明显提升了,可以看出时间是损耗在从文件读取数据,那如果一次性把所用数据从文件种读取出来会不会更快呢?试了下,代码改为:
f = open("badapple.bin", "rb")
target = "#ifndef __BADAPPLE_H__ \n#define __BADAPPLE_H__\n\n const uint8_t badapple[] = \n{\n"
dat = f.read()
print(type(dat))
f.close()
whole = dat.__len__()
line = int(whole / 16)
for i in range(line):
temp = dat[i*16:i*16+16]
he = ""
for da in temp:
he = he + hex(da) + ","
target = target + he + "\n"
print(i)
target = target + "}; \n\n#endif\n"
运行了下,结果为:
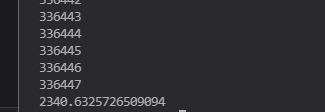
2340 秒,居然比第二种方法还长。
还有什么方法可以改进呢?现在时间估计是花在转换上面,在转换上有没有改进方法,目前还没找出来。
(四)做的更通用
那是不是说这段代码就完全没用,非也非也,用来转换小点的文件还是可以的,这不止可以转换二进制文件,还可以转换其他任何文件,比如图片、字库等,以下是转换一张图片运行的结果:
为了更通用,修了下代码,如下:

运行的时候需要传个参数,这个参数就是要处理的文件,最后生成的头文件、头文件里数组命名都是根据处理的文件的名字来设定的,运行过程中还显示处理进度,最后显示处理所花时间。比如把上述代码保存到文件 hex2header.py,比如要转换的文件为 test.pdf,用法为:
python hex2header.py test.pdf
实际运行为:
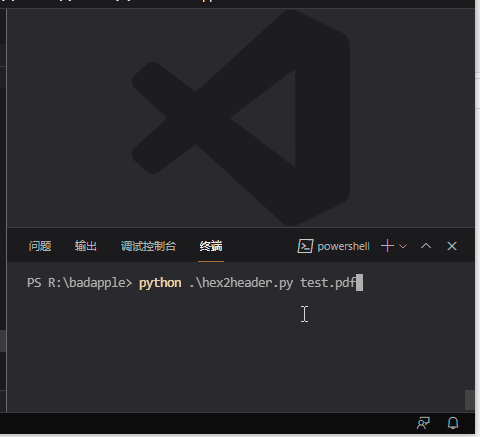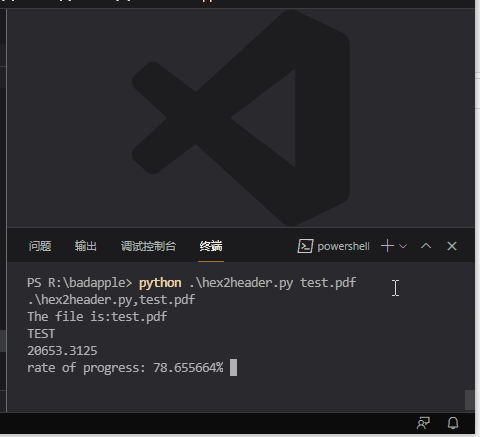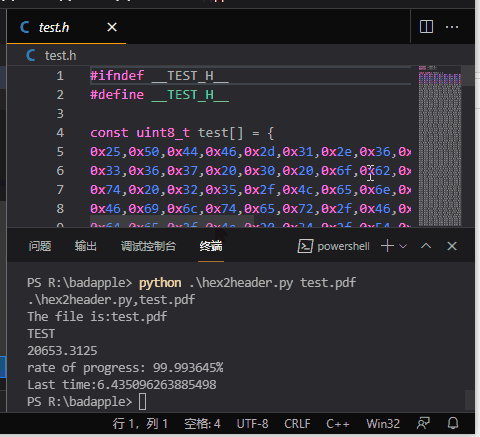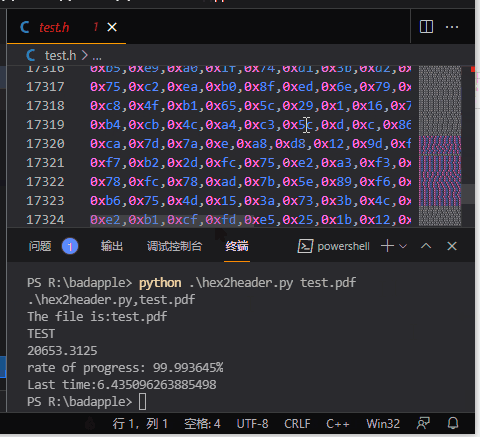
这示例转换了一个 323K 大小的 pdf 文件,每行 16 字节的话,大概 20653 行,花了6.4 秒的时间。
转载请注明出处:https://www.cnblogs.com/halin/
使用 python 把一个文件生成 C 语言中的数组并保存到头文件中的更多相关文章
- python脚本将json文件生成C语言结构体
1.引言 以前用过python脚本根据excel生成相关C语言代码,其实本质就是文件的读写,主要是逻辑问题,这次尝试将json文件生成C语言的结构体. 2.代码 这是一个json文件,生成这个结构体的 ...
- 利用POI抽取word中的图片并保存在文件中
利用POI抽取word中的图片并保存在文件中 poi.apache.org/hwpf/quick-guide.html 1.抽取word doc中的图片 package parse; import j ...
- 当Android工程中提示你找不到头文件,但你已经设置头文件路径了
虽然在Android.mk文件中,配置了LOCAL_C_INCLUDES路径,但是工程中的红色叉号一直提示找不到头文件 这时,你在工程树目录中展开Includes项,捣鼓捣鼓,重新build下,或许就 ...
- 为Python编写一个简单的C语言扩展模块
最近在看pytorh方面的东西,不得不承认现在这个东西比较火,有些小好奇,下载了代码发现其中计算部分基本都是C++写的,这真是要我对这个所谓Python语音编写的框架或者说是库感觉到一丢丢的小失落,细 ...
- [转]用Python做一个自动生成读表代码的小脚本
写在开始(本片文章不是写给小白的,至少你应该知道一些常识!) 大家在Unity开发中,肯定会把一些数据放到配置文件中,尤其是大一点的项目,每次开发一个新功能的时候,都要重复的写那些读表代码.非常烦.来 ...
- Python写一个批量生成账号的函数
批量生成账户信息,产生的账户由@sina.com结尾,长度由用户输入,产生多少条也由用户输入,用户名不能重复,用户名必须由大写字母.小写字母和数字组成. def Users(num,len): # n ...
- python写一个能生成三种一句话木马的脚本
代码: import time import os from threading import Thread import optparse def aspyijuhua(): try: juy=op ...
- Python强化训练笔记(七)——使用deque队列以及将对象保存为文件
collections模块中的deque对象是一个队列,它有着正常队列的先进先出原则.我们可以利用这个对象来实现数据的保存功能. 例如,现有一个猜数字大小的游戏,系统开始会随机roll点一个0-100 ...
- Python爬虫根据关键词爬取知网论文摘要并保存到数据库中【入门必学】
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:崩坏的芝麻 由于实验室需要一些语料做研究,语料要求是知网上的论文摘要 ...
随机推荐
- x小结:certutil -hashfile D:\1.exe MD5
在Win7上,MD5不要使用小写,在Win10上没有这个问题 x小结:certutil -hashfile D:\1.exe MD5certutil -hashfile D:\1.exe SHA1ce ...
- Iperf3网络性能测试工具详解教程
Iperf3网络性能测试工具详解教程 小M 2020年4月17日 运维 本文下载链接 [学习笔记]Iperf3网络性能测试工具.pdf 网络性能评估主要是监测网络带宽的使用率,将网络带宽利用最大化是保 ...
- wps中新罗马字体如何设置Times New Roman
word wps中新罗马字体如何设置Times New Roman ### WPS字体自带 Times New Roman ###
- Linux shell sed命令在文件行首行尾添加字符
昨天写一个脚本花了一天的2/3的时间,而且大部分时间都耗在了sed命令上,今天不总结一下都对不起昨天流逝的时间啊~~~ 用sed命令在行首或行尾添加字符的命令有以下几种: 假设处理的文本为test.f ...
- 【转】Jquery 使用Ajax获取后台返回的Json数据后,页面处理
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- RabbitMQ 集群原理
RabbitMQ默认集群原理 rabbitmq 本身是基于erlang编写,erlang语言天生具备分布式的特性(通过同步Erlang集群各节点的erlang cookie实现),RabbiteMQ天 ...
- EasyUI_使用datagrid分页 (Day_28)
本次分页涉及技术点 SSM+PageHelper+DatagrId 先来看下效果: 这是无条件分页,下一篇博客我们将讲有条件分页. 无论你是使用js加载table 还是直接使用标签. 使用datagr ...
- SpringBoot基础学习(二) SpringBoot全局配置文件及配置文件属性值注入
全局配置文件 全局配置文件能够对一些默认配置值进行修改.SpringBoot 使用一个名为 application.properties 或者 application.yaml的文件作为全局配置文件, ...
- GO学习-(19) Go语言基础之网络编程
Go语言基础之网络编程 现在我们几乎每天都在使用互联网,我们前面已经学习了如何编写Go语言程序,但是如何才能让我们的程序通过网络互相通信呢?本章我们就一起来学习下Go语言中的网络编程. 关于网络编程其 ...
- Jmeter - 把提取的响应结果设置成全局变量
1. 用正则表达式从响应结果中提取需要的字符 2.添加BeanShell 后置处理程序,${__setProperty(setcookies,${cookies},)} 用函数定义其为全局变量 3.调 ...