MapReduce原理深入理解(一)
1.MapReduce概念
1)MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
2)MapReduce是分布式运行的,由两个阶段组成:Map和Reduce,Map阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据。Reduce阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据【在这先把reduce理解为一个单独的聚合程序即可】。
3)MapReduce框架都有默认实现,用户只需要覆盖map()和reduce()两个函数,即可实现分布式计算,非常简单。
4)两个函数的形参和返回值都是<key、value>,使用的时候一定要注意构造<k,v>。
2.MapReduce核心思想
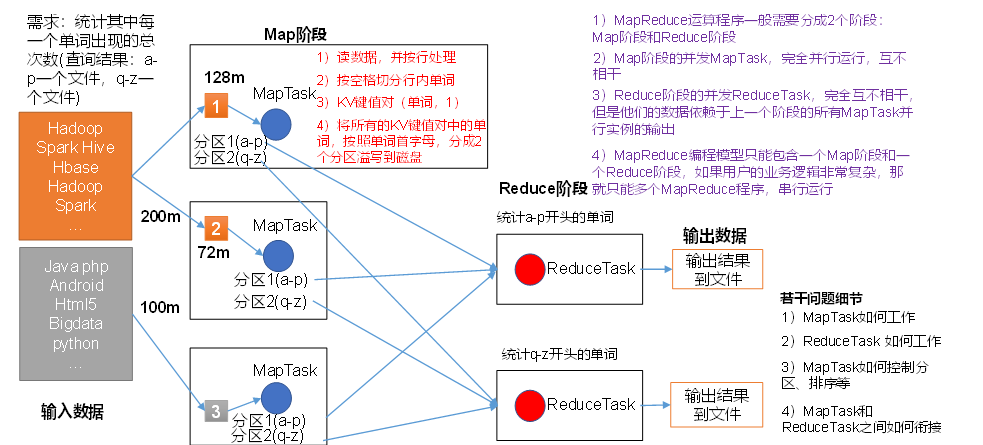
(1)分布式的运算程序往往需要分成至少2个阶段。
(2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
(3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
(4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。

3. MapReduce 中的shuffle

4.Mapreduce代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WordCount {
//分割任务
// 第一对kv,是决定数据输入的格式
// 第二队kv 是决定数据输出的格式
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/*map阶段数据是一行一行过来的
每一行数据都需要执行代码*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
LongWritable longWritable = new LongWritable(1);
String s = value.toString();
context.write(new Text(s), longWritable);
}
}
//接收Map端数据
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
/* reduce 聚合程序 每一个k都会调用一次
* 默认是一个节点
* key:每一个单词
* values:map端 当前k所对应的所有的v
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//设置统计的初始值为0
long sum = 0l;
for (LongWritable value : values) {
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
} /**
* 是当前mapreduce程序入口
* 用来构建mapreduce程序
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//创建一个job任务
Job job=Job.getInstance();
//指定job名称
job.setJobName("第一个mr程序");
//构建mr
//指定当前main所在类名(识别具体的类)
job.setJarByClass(WordCount.class);
//指定map端类
// 指定map输出的kv类型
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指定reduce端类
//指定reduce端输出的kv类型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); // 指定输入路径
Path in = new Path("/word");
FileInputFormat.addInputPath(job,in);
//输出路径指定
Path out = new Path("/output");
FileSystem fs = FileSystem.get(new Configuration());
//如果文件存在
if(fs.exists(out)){
fs.delete(out,true);
}
//存在
FileOutputFormat.setOutputPath(job,out); //启动
job.waitForCompletion(true);
System.out.println("MapReduce正在执行");
}
}
MapReduce原理深入理解(一)的更多相关文章
- MapReduce原理深入理解(二)
1.Mapreduce操作不需要reduce阶段 1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.f ...
- 大数据运算模型 MapReduce 原理
大数据运算模型 MapReduce 原理 2016-01-24 杜亦舒 MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计 ...
- MapReduce原理及其主要实现平台分析
原文:http://www.infotech.ac.cn/article/2012/1003-3513-28-2-60.html MapReduce原理及其主要实现平台分析 亢丽芸, 王效岳, 白如江 ...
- MapReduce 原理与 Python 实践
MapReduce 原理与 Python 实践 1. MapReduce 原理 以下是个人在MongoDB和Redis实际应用中总结的Map-Reduce的理解 Hadoop 的 MapReduce ...
- hadoop自带例子SecondarySort源码分析MapReduce原理
这里分析MapReduce原理并没用WordCount,目前没用过hadoop也没接触过大数据,感觉,只是感觉,在项目中,如果真的用到了MapReduce那待排序的肯定会更加实用. 先贴上源码 pac ...
- 04 MapReduce原理介绍
大数据实战(上) # MapReduce原理介绍 大纲: * Mapreduce介绍 * MapReduce2运行原理 * shuffle及排序 定义 * Mapreduce 最早是由googl ...
- Atitit 泛型原理与理解attilax总结
Atitit 泛型原理与理解attilax总结 1. 泛型历史11.1.1. 由来11.2. 为什么需要泛型,类型安全21.3. 7.泛型的好处22. 泛型的机制编辑22.1.1. 机制32.1.2. ...
- Hapoop原理及MapReduce原理分析
Hapoop原理 Hadoop是一个开源的可运行于大规模集群上的分布式并行编程框架,其最核心的设计包括:MapReduce和HDFS.基于 Hadoop,你可以轻松地编写可处理海量数据的分布式并行程序 ...
- Hadoop学习记录(4)|MapReduce原理|API操作使用
MapReduce概念 MapReduce是一种分布式计算模型,由谷歌提出,主要用于搜索领域,解决海量数据计算问题. MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce( ...
随机推荐
- Python Flask API实现方法-测试开发【提测平台】阶段小结(一)
微信搜索[大奇测试开],关注这个坚持分享测试开发干货的家伙. 本篇主要是对之前几次分享的阶阶段的总结,温故而知新,况且虽然看起来是一个小模块简单的增删改查操作,但其实涉及的内容点是非常的密集的,是非常 ...
- Linux文件系统只读 解决方案:
Linux系统Read-only file system,文件系统只读排查解决方案:文件系统只读机制:当文件系统自身的校验机制发现文件系统存在问题时,为避免文件系统受到进一步的损坏,系统会把文件系统设 ...
- sqli-labs lesson 38-45
从page3也就是less 38开始进入了堆叠注入(stacked injection) stacked injection: 简单来说就是进行SQL注入时注入了多条语句.因为之前我们都是只进行过注入 ...
- NOIP 模拟 $30\; \rm 毛二琛$
题解 \(by\;zj\varphi\) 原题问的就是对于一个序列,其中有的数之间有大小关系限制,问有多少种方案. 设 \(dp_{i,j}\) 表示在前 \(i\) 个数中,第 \(i\) 个的排名 ...
- noip 模拟4
咕 题都改不完怎么可能有空写题解啊啊啊
- ITIL学习笔记——ITIL入门小知识
1. 什么是ITIL? ITIL即IT基础架构库(Information Technology Infrastructure Library)由英国政府部门CCTA(Central Computing ...
- 测试框架unit之assertion断言使用详解
NUnit是.Net平台的测试框架,广泛用于.Net平台的单元测试和回归测试中,下面我们用示例详细学习一下他的使用方法 任何xUnit工具都使用断言进行条件的判断,NUnit自然也不例外,与其它的xU ...
- The Programmer's Oath程序员的誓言----鲍勃·马丁大叔(Bob Martin)
In order to defend and preserve the honor of the profession of computer programmers, I Promise that, ...
- STM32+Air202+Air530+HXDZ-30102-ACC心率血氧GPS采集上传到阿里云
所有资料都在QQ群1121445919 主要功能 HXDZ-30102-ACC采集心率血氧数据 STM32通过串口将数据转发到air202模块 air202将数据上传到阿里云平台进行展示与处理 整合合 ...
- Struts2之Json插件的使用
时间:2017-1-15 02:27 --普通方式处理异步请求: ServletActionContext.getResponse().getWriter().print("aa&qu ...