Tars | 第7篇 TarsJava Subset最终代码的测试方案设计
前言
中期汇报会后,对Tars Subset功能更加熟悉,并根据TarsGo的实现方式,对Java JDK实现代码进行翻新改造。于是有了以下两篇分析文章:
第5篇 基于TarsGo Subset路由规则的Java JDK实现方式(上篇)
https://www.cnblogs.com/dlhjw/p/15245113.html
第6篇 基于TarsGo Subset路由规则的Java JDK实现方式(下篇)
https://www.cnblogs.com/dlhjw/p/15245116.html
其中,《上篇》注重TarsGo分析,《下篇》注重TarsJava实现方式。不出意外的话,最终提交的考核成果就在下面的GitHub代码仓库中(以下简称“最终代码”),后续可能会有些许地方需要更改:
TarsJava 实现Subset路由规则JDK GitHub开源地址
https://github.com/dlhjw/TarsJava/commit/cc2fe884ecbe8455a8e1f141e21341f4f3dd98a3
最终代码与中期代码在整体思想逻辑上都是一致的都是:先判断Subset路由规则,再根据规则路由到定义的节点。不同点在于:中期在处理整个过程时,用一个方法filterEndpointsBySubset()实现;而最终的实现方式则是以subsetEndpointFilter()方法作为整个Subset流量路由的入口,通过subsetManager管理器调用getSubset()方法获取到路由规则的String类型的subset字段,与节点自身的subset字段一一比较过滤节点;其中Subset路由规则的判断封装在getSubset()方法里;
总的来说就是最终代码是在处理subset规则逻辑中增加了很多细节,比如:通过新增的registry接口获取subsetConf配置项;将获取到是配置项存入缓存中;以及将“判断Subset路由规则”进行层层封装,最终返回一个简单的String类型的subset字段与节点自身的subset字段比较等;
因此,在测试方案上相比较中期有些许区别,但总体上的单元测试原则是不变的:
- 首先构建前置条件;
- 调用测试方法;
- 输出测试结果;
其中的区别主要体现在前置条件的构建上,本篇将结合最终代码的实现逻辑,重点介绍其测试方案的设计;首先介绍测试方案的设计原则,接着针对五种情况(按比例单次、按比例多次、按参数精确、按参数正则路由与默认规则)做详细介绍与展示测试结果。
最终代码的Subset执行流程分析请参考下面这篇文章:
第8篇 TarsJava Subset最终代码的执行流程与原理分析
https://blog.csdn.net/dlhjw1412/article/details/119932752
《测试方案设计》与《执行流程分析》两篇文章相辅相成,相互观阅能更快更好地理解整个Subset的业务流程与输出示例;
1. SubsetConf配置项的结构
在中期,笔者使用一个map来模拟subset的流量规则;而在最终代码里,是用多个对象来模拟Subset的配置,这些对象是理解整个Subset流量过滤规则的基础的,因此很有必要在这里做个介绍;
1.1 SubsetConf
public class SubsetConf {
private boolean enanle;
private String ruleType;
private RatioConfig ratioConf;
private KeyConfig keyConf;
private Instant lastUpdate;
……
}
可以看出SubsetConf配置项里有以下属性:
- enanle:表示是否开启Subset流量管理功能;
- true:开启;false:关闭;
- ruleType:表示流量管理的类型;
- 目前有
ratio按比例和key按参数两种模式;
- 目前有
- RatioConfig:表示按比例路由配置项;
- 里面定义了路由比例与路径等信息,详情请参考《1.2 RatioConfig》
- KeyConfig:表示按参数路由配置项;
- 里面定义了规则key与路由路径等信息,详情请参考《1.3 KeyConfig》
- lastUpdate:表示该配置项上次更新时间,将在缓存那里起作用;
1.2 RatioConfig
public class RatioConfig {
private Map<String, Integer> rules;
……
}
RatioConfig里只有一个map类型的rules路由规则,其中key为一个String类型的subset字段,用来跟节点的subset字段匹配,value为路由权重,如:{ {"v1" , 20} , {"v2" , 60} , {"v3" , 20} }表示路由到subset字段为v1的节点的概率为0.2;路由到subset字段为v2的节点的概率为0.6;路由到subset字段为v3的节点的概率为0.2;
1.3 KeyConfig
public class KeyConfig {
private String defaultRoute;
private List<KeyRoute> rules;
……
}
KeyConfig里有两个属性,一个是defaultRoute默认路由路径;另一个是list类型的rules,里面是KeyRoute,其定义了按参数匹配的类型、规则key与路径,详情请见《1.4 KeyRoute》
1.4 KeyRoute
public class KeyRoute {
private String action = null;
private String value = null;
private String route = null;
public static final String TARS_ROUTE_KEY = "TARS_ROUTE_KEY";
……
}
KeyRoute里面有四个String类型的属性,如下:
- action:用来定义参数匹配的类型;
- 目前可设置的类型有:equals精确匹配、match正则匹配、default默认匹配;
- value:这就是大名鼎鼎的规则key了。当action=equals时,还需满足规则key与请求key匹配,才能进行精确匹配;当action=match时,还需满足规则key与请求key正则匹配,才能进行正则匹配;action=default对规则key没要求;
- route:用来规定路由路径,其值为一个String类型的subset字段,匹配到节点的subset字段;
- TARS_ROUTE_KEY:一个常量字段,为Tars请求体里的status(map类型)的key;
1.5 SubsetConf的结构示意图
上述提到的配置类联系结构图如下:

2. 测试方案设计
这里的测试主要指测试subsetEndpointFilter()根据subset过滤节点这一核心方法,在测试中构建前置条件最为复杂,因此将在2.1仔细介绍;
2.1 构建前置条件
从SubsetConf的结构图可以看出,按比例与参数路由的一些前置条件不同,比如按参数路由需要一个list类型的KeyRoute,而按比例路由则是用一个map类型的数据结构实现类似KeyRoute的功能;
除此之外,KeyRoute里的value为规则的key,其作用是与请求key做对比匹配,是参数匹配的必要不充分条件;这就要求构建前置条件时要考虑从Tars的请求体TarsServantRequest中的status属性(map类型)获取到键TARS_ROUTE_KEY的值value,而Tars的请求体又要通过分布式上下文信息DistributedContext获取;默认路由又不用考虑染色key……
因此,按比例与默认路由方式的前置条件包括:
- 一个Subset过滤器;
- 核心方法
subsetEndpointFilter的传入参数;- objectName:对象名;
- routeKey:上下文的染色key;
- activeEp:存活的节点列表及存活的节点;
- 一个SubsetManager管理器;
- RatioConfig比例路由规则;
- subsetConf配置项;
- 等;
可以通过以下代码实现、模拟:
//创建Subset过滤器
Subset subsetFilter = new Subset();
//模拟objectName
String objectName = "objectName";
//模拟routeKey
String routeKey = "routeKey";
//存活节点list列表
List<EndpointF> endpointFList = new ArrayList<EndpointF>();
Holder<List<EndpointF>> activeEp = new Holder<List<EndpointF>>(new ArrayList<EndpointF>());
//1. 给过滤器设置过滤规则
//1.1 创建SubsetManager管理器
SubsetManager subsetManager = new SubsetManager();
//1.1 设置比例路由规则
RatioConfig ratioConf = new RatioConfig();
Map<String , Integer> map = new HashMap<>();
map.put("v1",20);
map.put("v2",80);
//map.put("v3",20);
ratioConf.setRules(map);
//1.2 设置subsetConf,并加入缓存
SubsetConf subsetConf = new SubsetConf();
subsetConf.setEnanle(true);
subsetConf.setRuleType("ratio");
subsetConf.setRatioConf(ratioConf);
subsetConf.setLastUpdate( Instant.now() );
Map<String, SubsetConf> cache = new HashMap<>();
cache.put(objectName,subsetConf);
subsetManager.setCache(cache);
//1.3 给过滤器设置过滤规则和管理者
subsetFilter.setSubsetConf(subsetConf);
subsetFilter.setSubsetManager(subsetManager);
//2. 模拟存活节点
endpointFList.add(new EndpointF("host1",1,2,3,4,5,6,"setId1",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host2",1,2,3,4,5,6,"setId2",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host3",1,2,3,4,5,6,"setId3",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host4",1,2,3,4,5,6,"setId4",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v3"));
activeEp.setValue(endpointFList);
而按参数匹配路由方式的前置条件包括:
- 一个Subset过滤器;
- 核心方法
subsetEndpointFilter的传入参数;- objectName:对象名;
- routeKey:上下文的染色key;
- activeEp:存活的节点列表及存活的节点;
- 一个SubsetManager管理器;
- KeyConfig参数路由规则;
- KeyRoute参数路由属性;
- subsetConf配置项;
- Tars的请求体TarsServantRequest;
- 一个Session域,用来构建Tars请求体
- 分布式上下文信息DistributedContext;
- 等;
可以通过以下代码实现、模拟:
//创建Subset过滤器
Subset subsetFilter = new Subset();
//模拟objectName
String objectName = "objectName";
//模拟routeKey
String routeKey = "routeKey";
//存活节点list列表
List<EndpointF> endpointFList = new ArrayList<EndpointF>();
Holder<List<EndpointF>> activeEp = new Holder<List<EndpointF>>(new ArrayList<EndpointF>());
//定义一个Session域,用来构建Tars请求体
Session session;
//1. 给过滤器设置过滤规则
//1.1 创建SubsetManager管理器
SubsetManager subsetManager = new SubsetManager();
//1.1 设置参数路由规则,这里的KeyRoute的value为 “规则的染色key”
KeyConfig keyConf = new KeyConfig();
List<KeyRoute> krs = new LinkedList<>();
krs.add(new KeyRoute("match","routeKey","v1"));
keyConf.setRules(krs);
//1.2 设置subsetConf,并加入缓存
SubsetConf subsetConf = new SubsetConf();
subsetConf.setEnanle(true);
subsetConf.setRuleType("key");
subsetConf.setKeyConf(keyConf);
subsetConf.setLastUpdate( Instant.now() );
Map<String, SubsetConf> cache = new HashMap<>();
cache.put(objectName,subsetConf);
subsetManager.setCache(cache);
//1.3 给过滤器设置过滤规则和管理者
subsetFilter.setSubsetConf(subsetConf);
subsetFilter.setSubsetManager(subsetManager);
//1.4 模拟Tars “请求的染色key” TARS_ROUTE_KEY,但请求染色key和规则染色key匹配时,才能精确路由
//1.4.1 创建Tars的请求体TarsServantRequest
TarsServantRequest request = new TarsServantRequest( session );
//1.4.2 往请求体的status添加{TARS_ROUTE_KEY, "routeKey"}键值对
Map<String, String> status = new HashMap<>();
status.put("TARS_ROUTE_KEY", "routeKey");
request.setStatus(status);
//1.4.3 构建分布式上下文信息,将请求放入分布式上下文信息中,因为getSubset()的逻辑是从分布式上下文信息中取
DistributedContext distributedContext = new DistributedContextImpl();
distributedContext.put(DyeingSwitch.REQ,request);
//2. 模拟存活节点
endpointFList.add(new EndpointF("host1",1,2,3,4,5,6,"setId1",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host2",1,2,3,4,5,6,"setId2",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host3",1,2,3,4,5,6,"setId3",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host4",1,2,3,4,5,6,"setId4",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v3"));
activeEp.setValue(endpointFList);
2.2 调用测试方法
调用测试方法比较简单,用如下语句实现即可:
//4. 对存活节点按subset规则过滤
Holder<List<EndpointF>> filterActiveEp = subsetFilter.subsetEndpointFilter(objectName, routeKey, activeEp);
2.3 输出测试结果
输出测试结果也比较简单,在过滤前后都遍历一些节点列表,判断其是否起到过滤功能即可,可以用如下代码实现:
//3. 输出过滤前信息
System.out.println("过滤前节点信息如下:");
for( EndpointF endpoint : endpointFList){
System.out.println(endpoint.toString());
}
//5. 输出过滤结果
System.out.println("过滤后节点信息如下:");
for( EndpointF endpoint : filterActiveEp.getValue() ){
System.out.println(endpoint.toString());
}
如此,一个大概的测试方案就成型了,下面将介绍各路由方式的测试代码与测试结果;
3. 按比例路由规则 - 单次测试
测试代码如下:
/**
* 按比例路由规则 - 单次测试
* 没有测试registry获取subsetConf功能
*/
@Test
public void testRatioOnce() {
//1. 给过滤器设置过滤规则
//1.1 创建SubsetManager管理器
SubsetManager subsetManager = new SubsetManager();
//1.1 设置比例路由规则
RatioConfig ratioConf = new RatioConfig();
Map<String , Integer> map = new HashMap<>();
map.put("v1",20);
map.put("v2",80);
//map.put("v3",20);
ratioConf.setRules(map);
//1.2 设置subsetConf,并加入缓存
SubsetConf subsetConf = new SubsetConf();
subsetConf.setEnanle(true);
subsetConf.setRuleType("ratio");
subsetConf.setRatioConf(ratioConf);
subsetConf.setLastUpdate( Instant.now() );
Map<String, SubsetConf> cache = new HashMap<>();
cache.put(objectName,subsetConf);
subsetManager.setCache(cache);
//1.3 给过滤器设置过滤规则和管理者
subsetFilter.setSubsetConf(subsetConf);
subsetFilter.setSubsetManager(subsetManager);
//2. 模拟存活节点
endpointFList.add(new EndpointF("host1",1,2,3,4,5,6,"setId1",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host2",1,2,3,4,5,6,"setId2",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host3",1,2,3,4,5,6,"setId3",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host4",1,2,3,4,5,6,"setId4",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v3"));
activeEp.setValue(endpointFList);
//3. 输出过滤前信息
System.out.println("过滤前节点信息如下:");
for( EndpointF endpoint : endpointFList){
System.out.println(endpoint.toString());
}
//4. 对存活节点按subset规则过滤
Holder<List<EndpointF>> filterActiveEp = subsetFilter.subsetEndpointFilter(objectName, routeKey, activeEp);
//5. 输出过滤结果
System.out.println("过滤后节点信息如下:");
for( EndpointF endpoint : filterActiveEp.getValue() ){
System.out.println(endpoint.toString());
}
}
测试结果如下:

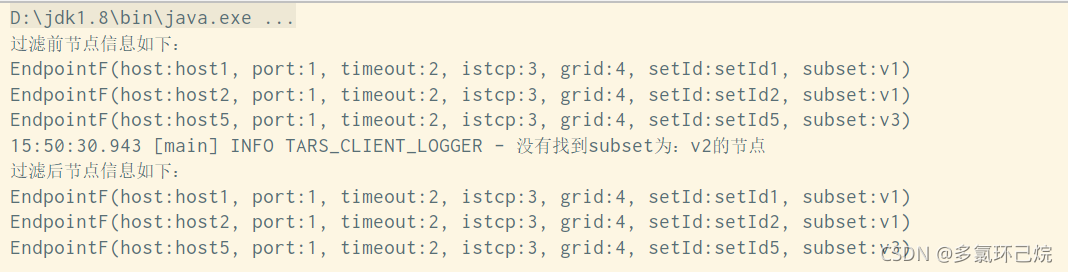
在上述情况下,如果我们将所有v2节点删除,即模拟经过按比例权重查找后匹配到节点subset字段为v2集合,但原来存活节点里却没有subset字段为v2的节点这种情况,将会输出一句错误信息,如下:
4. 按比例路由规则 - 多次测试
测试代码如下:
/**
* 按比例路由规则 - 多次测试
* 没有测试registry获取subsetConf功能
*/
@Test
public void testRatioTimes() {
//1. 给过滤器设置过滤规则
//1.1 创建SubsetManager管理器
SubsetManager subsetManager = new SubsetManager();
//1.1 设置比例路由规则
RatioConfig ratioConf = new RatioConfig();
Map<String , Integer> map = new HashMap<>();
map.put("v1",20);
map.put("v2",80);
map.put("v3",20);
ratioConf.setRules(map);
//1.2 设置subsetConf,并加入缓存
SubsetConf subsetConf = new SubsetConf();
subsetConf.setEnanle(true);
subsetConf.setRuleType("ratio");
subsetConf.setRatioConf(ratioConf);
subsetConf.setLastUpdate( Instant.now() );
Map<String, SubsetConf> cache = new HashMap<>();
cache.put(objectName,subsetConf);
subsetManager.setCache(cache);
//1.3 给过滤器设置过滤规则和管理者
subsetFilter.setSubsetConf(subsetConf);
subsetFilter.setSubsetManager(subsetManager);
//2. 模拟存活节点
endpointFList.add(new EndpointF("host1",1,2,3,4,5,6,"setId1",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host2",1,2,3,4,5,6,"setId2",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host3",1,2,3,4,5,6,"setId3",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host4",1,2,3,4,5,6,"setId4",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v3"));
activeEp.setValue(endpointFList);
//3. 循环times次
int times = 1000000;
int v1Times = 0;
int v2Times = 0;
int v3Times = 0;
int errTimes = 0;
for (int i = 0; i < times; i++) {
//对存活节点按subset规则过滤
Holder<List<EndpointF>> filterActiveEp = subsetFilter.subsetEndpointFilter(objectName, routeKey, activeEp);
String subsetValue = filterActiveEp.getValue().get(0).getSubset();
if("v1".equals(subsetValue)){
v1Times++;
} else if("v2".equals(subsetValue)){
v2Times++;
} else if("v3".equals(subsetValue)){
v3Times++;
} else {
errTimes++;
}
}
//输出结果
System.out.println("一共循环次数:" + times);
System.out.println("路由到v1次数:" + v1Times);
System.out.println("路由到v2次数:" + v2Times);
System.out.println("路由到v3次数:" + v3Times);
System.out.println("路由异常次数:" + errTimes);
}
测试结果如下:

这里如果我们将语句subsetConf.setEnanle(true);中的true置为false,可以发现没有起到路由功能,所有结点路由到v1那边,如下图所示:

如果我们给方法subsetEndpointFilter(objectName, routeKey, activeEp)中的routeKey传入参数为空字符串"",则会等比例随机路由,测试结果如下:

5. 按参数路由规则 - 精确匹配测试
测试代码如下:
/**
* 测试参数匹配 - 精确匹配
* 没有测试registry获取subsetConf功能
* 注意要成功必须routeKey和match匹配上
*/
@Test
public void testMatch() {
//1. 给过滤器设置过滤规则
//1.1 创建SubsetManager管理器
SubsetManager subsetManager = new SubsetManager();
//1.1 设置参数路由规则,这里的KeyRoute的value为 “规则的染色key”
KeyConfig keyConf = new KeyConfig();
List<KeyRoute> krs = new LinkedList<>();
krs.add(new KeyRoute("match","routeKey","v1"));
keyConf.setRules(krs);
//1.2 设置subsetConf,并加入缓存
SubsetConf subsetConf = new SubsetConf();
subsetConf.setEnanle(true);
subsetConf.setRuleType("key");
subsetConf.setKeyConf(keyConf);
subsetConf.setLastUpdate( Instant.now() );
Map<String, SubsetConf> cache = new HashMap<>();
cache.put(objectName,subsetConf);
subsetManager.setCache(cache);
//1.3 给过滤器设置过滤规则和管理者
subsetFilter.setSubsetConf(subsetConf);
subsetFilter.setSubsetManager(subsetManager);
//1.4 模拟Tars “请求的染色key” TARS_ROUTE_KEY,但请求染色key和规则染色key匹配时,才能精确路由
//1.4.1 创建Tars的请求体TarsServantRequest
TarsServantRequest request = new TarsServantRequest( session );
//1.4.2 往请求体的status添加{TARS_ROUTE_KEY, "routeKey"}键值对
Map<String, String> status = new HashMap<>();
status.put("TARS_ROUTE_KEY", "routeKey");
request.setStatus(status);
//1.4.3 构建分布式上下文信息,将请求放入分布式上下文信息中,因为getSubset()的逻辑是从分布式上下文信息中取
DistributedContext distributedContext = new DistributedContextImpl();
distributedContext.put(DyeingSwitch.REQ,request);
//2. 模拟存活节点
endpointFList.add(new EndpointF("host1",1,2,3,4,5,6,"setId1",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host2",1,2,3,4,5,6,"setId2",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host3",1,2,3,4,5,6,"setId3",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host4",1,2,3,4,5,6,"setId4",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v3"));
activeEp.setValue(endpointFList);
//3. 输出过滤前信息
System.out.println("过滤前节点信息如下:");
for( EndpointF endpoint : endpointFList){
System.out.println(endpoint.toString());
}
//4. 对存活节点按subset规则过滤
Holder<List<EndpointF>> filterActiveEp = subsetFilter.subsetEndpointFilter(objectName, routeKey, activeEp);
//5. 输出过滤结果
System.out.println("过滤后节点信息如下:");
for( EndpointF endpoint : filterActiveEp.getValue() ){
System.out.println(endpoint.toString());
}
}
测试结果如下:

这里如果我们使规则key与请求key不匹配,将起不到过滤功能,并输出一句错误日志,如下图所示:

6. 按参数路由规则 - 正则匹配测试
测试代码如下:
/**
* 测试参数匹配 - 正则匹配
* 没有测试registry获取subsetConf功能
* 注意要成功必须routeKey和match匹配上
*/
@Test
public void testEqual() {
//1. 给过滤器设置过滤规则
//1.1 创建SubsetManager管理器
SubsetManager subsetManager = new SubsetManager();
//1.1 设置参数路由规则,这里的KeyRoute的value为 “规则的染色key”
KeyConfig keyConf = new KeyConfig();
List<KeyRoute> krs = new LinkedList<>();
krs.add(new KeyRoute("equal","routeKey","v1"));
keyConf.setRules(krs);
//1.2 设置subsetConf,并加入缓存
SubsetConf subsetConf = new SubsetConf();
subsetConf.setEnanle(true);
subsetConf.setRuleType("key");
subsetConf.setKeyConf(keyConf);
subsetConf.setLastUpdate( Instant.now() );
Map<String, SubsetConf> cache = new HashMap<>();
cache.put(objectName,subsetConf);
subsetManager.setCache(cache);
//1.3 给过滤器设置过滤规则和管理者
subsetFilter.setSubsetConf(subsetConf);
subsetFilter.setSubsetManager(subsetManager);
//1.4 模拟Tars “请求的染色key” TARS_ROUTE_KEY,但请求染色key和规则染色key匹配时,才能精确路由
//1.4.1 创建Tars的请求体TarsServantRequest
TarsServantRequest request = new TarsServantRequest( session );
//1.4.2 往请求体的status添加{TARS_ROUTE_KEY, "routeKey"}键值对
Map<String, String> status = new HashMap<>();
status.put("TARS_ROUTE_KEY", "route*");
request.setStatus(status);
//1.4.3 构建分布式上下文信息,将请求放入分布式上下文信息中,因为getSubset()的逻辑是从分布式上下文信息中取
DistributedContext distributedContext = new DistributedContextImpl();
distributedContext.put(DyeingSwitch.REQ,request);
//2. 模拟存活节点
endpointFList.add(new EndpointF("host1",1,2,3,4,5,6,"setId1",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host2",1,2,3,4,5,6,"setId2",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host3",1,2,3,4,5,6,"setId3",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host4",1,2,3,4,5,6,"setId4",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v3"));
activeEp.setValue(endpointFList);
//3. 输出过滤前信息
System.out.println("过滤前节点信息如下:");
for( EndpointF endpoint : endpointFList){
System.out.println(endpoint.toString());
}
//4. 对存活节点按subset规则过滤
Holder<List<EndpointF>> filterActiveEp = subsetFilter.subsetEndpointFilter(objectName, routeKey, activeEp);
//5. 输出过滤结果
System.out.println("过滤后节点信息如下:");
for( EndpointF endpoint : filterActiveEp.getValue() ){
System.out.println(endpoint.toString());
}
}
测试结果如下:

这里如果我们使规则key与请求key正则匹配不上,跟精确匹配一样将起不到过滤功能,并输出一句错误日志,如下图所示:

7. 无路由规则测试
测试代码如下:
/**
* 测试默认路由
* 没有测试registry获取subsetConf功能
*/
@Test
public void testDefault() {
//1. 给过滤器设置过滤规则
//1.1 创建SubsetManager管理器
SubsetManager subsetManager = new SubsetManager();
//1.1 设置参数路由规则,这里的KeyRoute的value为 “规则的染色key”
KeyConfig keyConf = new KeyConfig();
List<KeyRoute> krs = new LinkedList<>();
krs.add(new KeyRoute("default","","v1"));
keyConf.setRules(krs);
//1.2 设置subsetConf,并加入缓存
SubsetConf subsetConf = new SubsetConf();
subsetConf.setEnanle(true);
subsetConf.setRuleType("key");
subsetConf.setKeyConf(keyConf);
subsetConf.setLastUpdate( Instant.now() );
Map<String, SubsetConf> cache = new HashMap<>();
cache.put(objectName,subsetConf);
subsetManager.setCache(cache);
//1.3 给过滤器设置过滤规则和管理者
subsetFilter.setSubsetConf(subsetConf);
subsetFilter.setSubsetManager(subsetManager);
//2. 模拟存活节点
endpointFList.add(new EndpointF("host1",1,2,3,4,5,6,"setId1",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host2",1,2,3,4,5,6,"setId2",7,8,9,10,"v1"));
endpointFList.add(new EndpointF("host3",1,2,3,4,5,6,"setId3",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host4",1,2,3,4,5,6,"setId4",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v2"));
endpointFList.add(new EndpointF("host5",1,2,3,4,5,6,"setId5",7,8,9,10,"v3"));
activeEp.setValue(endpointFList);
//3. 输出过滤前信息
System.out.println("过滤前节点信息如下:");
for( EndpointF endpoint : endpointFList){
System.out.println(endpoint.toString());
}
//4. 对存活节点按subset规则过滤
Holder<List<EndpointF>> filterActiveEp = subsetFilter.subsetEndpointFilter(objectName, routeKey, activeEp);
//5. 输出过滤结果
System.out.println("过滤后节点信息如下:");
for( EndpointF endpoint : filterActiveEp.getValue() ){
System.out.println(endpoint.toString());
}
}
测试结果如下:

最后
新人制作,如有错误,欢迎指出,感激不尽!
欢迎关注公众号,会分享一些更日常的东西!
如需转载,请标注出处!

Tars | 第7篇 TarsJava Subset最终代码的测试方案设计的更多相关文章
- Tars | 第8篇 TarsJava Subset最终代码的执行流程与原理分析
目录 前言 1. SubsetConf配置项的结构 1.1 SubsetConf 1.2 RatioConfig 1.3 KeyConfig 1.4 KeyRoute 1.5 SubsetConf的结 ...
- Tars | 第2篇 TarsJava SpingBoot启动与负载均衡源码初探
目录 前言 1. Tars客户端启动 @EnableTarsServer 2. Communicator通信器 3. 客户端的负载均衡调用器LoadBalance 最后 前言 通过源码分析可以得出这样 ...
- Tars | 第0篇 腾讯犀牛鸟开源人才培养计划Tars实战笔记目录
腾讯犀牛鸟开源人才培养计划Tars实战笔记目录 前言 在2021年夏,笔者参加了腾讯首届开源人才培养计划的Tars项目,负责Subset流量管理规则的Java语言JDK实现.其中写作几篇开源实战笔记, ...
- Tars | 第3篇 Tars中期汇报测试文档(Java语言实现Subset路由规则)
目录 前言 1. 任务介绍 2. 测试模拟方案 2.0 *前置工作 2.1 添加路由规则 2.2 添加存活节点 2.3 [输出]遍历输出当前存活节点 2.4 [核心]对存活节点按subset规则过滤 ...
- .Net判断一个对象是否为数值类型探讨总结(高营养含量,含最终代码及跑分)
前一篇发出来后引发了积极的探讨,起到了抛砖引玉效果,感谢大家参与. 吐槽一下:这个问题比其看起来要难得多得多啊. 大家的讨论最终还是没有一个完全正确的答案,不过我根据讨论结果总结了一个差不多算是最终版 ...
- 标准程序员系列-Github篇-初始化一个代码仓库
下面将一步步介绍怎样使用GitHub来初始化一个项目的版本控制仓库: 1. 到GitHub上注册自己的账号:https://github.com/ 2. 创建第一个代码仓库一个仓库相当于一个项目的代码 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Devops 开发运维高级篇之微服务代码上传和代码检查
Devops 开发运维高级篇之微服务代码上传和代码检查 微服务持续集成(1)-项目代码上传到Gitlab 微服务持续集成(2)-从Gitlab拉取项目源码 微服务持续集成(3)-提交到SonarQub ...
- 来自ebay内部的「软件测试」学习资料,覆盖GUI、API自动化、代码级测试及性能测试等,Python等,拿走不谢!...
在软件测试领域从业蛮久了,常有人会问我: 刚入测试一年,很迷茫,觉得没啥好做的-- 测试在公司真的不受重视,我是不是去转型做开发会更好? 资深的测试架构师的发展路径是怎么样的?我平时该怎么学习? 我 ...
随机推荐
- ContentObserver 内容观察者作用及特点
eg: 1.定义Uri public static Uri KEY_BROWSER_URI = Uri.parse("content://com.android.browser.provid ...
- RHCE_DAY06
iptables防火墙 ----匹配及停止 nerfilter/iptables:工作在主机或网络的边缘,对于进出本主机或网络的报文根据事先定义好的检查规则作匹配检测,对于能够被规则所匹配到的报文做出 ...
- Redis实战-详细配置-优雅的使用Redis注解/RedisTemplate
1. 简介 当我们对redis的基本知识有一定的了解后,我们再通过实战的角度学习一下在SpringBoot环境下,如何优雅的使用redis. 我们通过使用SpringBoot内置的Redis注解(文章 ...
- linux服务器下TCP抓包
1.首先ifconfig查看当前服务器的网卡信息 2.执行tcpdump -i ens160[网卡信息] -s 0 port 8080[监听的端口号] -w ./fileName.pcapng 3.可 ...
- 一张图带你搞懂Node事件循环
说一件重要的事儿:你还没关注公众号[前端印记],更多精彩内容等你探索-- 以下全文7000字,请在你思路清晰.精力充沛的时刻观看.保证你理解后很长时间忘不掉. Node事件循环 Node底层使用的语言 ...
- 题解 God Knows
传送门 这里有个线段树维护单调栈的神仙技巧 同机房dalao @Yubai的不同理解方式 yysy,我考场上连\(n^2\)的暴力都没搞出来 这里实际上求的是最小权极大上升子序列 但这个跟题目几乎没什 ...
- css生成彩色阴影
通常用css生成单色或者同色系的的阴影(box-shadow),其实可以通过巧妙的利用 filter: blur 模糊滤镜,可以生成渐变色或者说是颜色丰富的阴影效果,如图: 原理: 利用伪元素,生成一 ...
- flutter中修改键盘状态
当用户进行表格输入时,为更方便的方便用户操作,我们需要设置键盘状态方便用户点击,如当表格填写完成时,用户可以直接点击键盘下面的"完成"状态完成提交. 实现如下: TextFormF ...
- asp.net core的输入模型验证
数据验证特性RequiredAttribute:表示数据不能为空RegularExpressionAttribute:正则校验CompareAttribute:和某个属性比较RangeAttribut ...
- 【maven】私服搭建
转自:https://www.cnblogs.com/likehua/p/4552620.html 一.软件安装 地址:http://www.sonatype.org/nexus/thank-you- ...