Spark基础知识详解
Apache Spark是一种快速通用的集群计算系统。 它提供Java,Scala,Python和R中的高级API,以及支持通用执行图的优化引擎。 它还支持一组丰富的高级工具,包括用于SQL和结构化数据处理的Spark SQL,用于机器学习的MLlib,用于图形处理的GraphX和Spark Streaming。
Spark优点:
- 减少磁盘I/O:随着实时大数据应用越来越多,Hadoop作为离线的高吞吐、低响应框架已不能满足这类需求。HadoopMapReduce的map端将中间输出和结果存储在磁盘中,reduce端又需要从磁盘读写中间结果,势必造成磁盘IO成为瓶颈。Spark允许将map端的中间输出和结果存储在内存中,reduce端在拉取中间结果时避免了大量的磁盘I/O。Hadoop Yarn中的ApplicationMaster申请到Container后,具体的任务需要利用NodeManager从HDFS的不同节点下载任务所需的资源(如Jar包),这也增加了磁盘I/O。Spark将应用程序上传的资源文件缓冲到Driver本地文件服务的内存中,当Executor执行任务时直接从Driver的内存中读取,也节省了大量的磁盘I/O。
- 增加并行度:由于将中间结果写到磁盘与从磁盘读取中间结果属于不同的环节,Hadoop将它们简单的通过串行执行衔接起来。Spark把不同的环节抽象为Stage,允许多个Stage既可以串行执行,又可以并行执行。
- 避免重新计算:当Stage中某个分区的Task执行失败后,会重新对此Stage调度,但在重新调度的时候会过滤已经执行成功的分区任务,所以不会造成重复计算和资源浪费。
- 可选的Shuffle排序:HadoopMapReduce在Shuffle之前有着固定的排序操作,而Spark则可以根据不同场景选择在map端排序或者reduce端排序。
- 灵活的内存管理策略:Spark将内存分为堆上的存储内存、堆外的存储内存、堆上的执行内存、堆外的执行内存4个部分。Spark既提供了执行内存和存储内存之间是固定边界的实现,又提供了执行内存和存储内存之间是“软”边界的实现。Spark默认使用“软”边界的实现,执行内存或存储内存中的任意一方在资源不足时都可以借用另一方的内存,最大限度的提高资源的利用率,减少对资源的浪费。Spark由于对内存使用的偏好,内存资源的多寡和使用率就显得尤为重要,为此Spark的内存管理器提供的Tungsten实现了一种与操作系统的内存Page非常相似的数据结构,用于直接操作操作系统内存,节省了创建的Java对象在堆中占用的内存,使得Spark对内存的使用效率更加接近硬件。Spark会给每个Task分配一个配套的任务内存管理器,对Task粒度的内存进行管理。Task的内存可以被多个内部的消费者消费,任务内存管理器对每个消费者进行Task内存的分配与管理,因此Spark对内存有着更细粒度的管理。
基于以上所列举的优化,Spark官网声称性能比Hadoop快100倍,如图3所示。即便是内存不足需要磁盘I/O时,其速度也是Hadoop的10倍以上。

Hadoop与Spark执行逻辑回归时间比较
Spark还有其他一些特点。
- 检查点支持:Spark的RDD之间维护了血缘关系(lineage),一旦某个RDD失败了,则可以由父RDD重建。虽然lineage可用于错误后RDD的恢复,但对于很长的lineage来说,恢复过程非常耗时。如果应用启用了检查点,那么在Stage中的Task都执行成功后,SparkContext将把RDD计算的结果保存到检查点,这样当某个RDD执行失败后,在由父RDD重建时就不需要重新计算,而直接从检查点恢复数据。
- 易于使用。Spark现在支持Java、Scala、Python和R等语言编写应用程序,大大降低了使用者的门槛。自带了80多个高等级操作符,允许在Scala,Python,R的shell中进行交互式查询。
- 支持交互式:Spark使用Scala开发,并借助于Scala类库中的Iloop实现交互式shell,提供对REPL(Read-eval-print-loop)的实现。
- 支持SQL查询。在数据查询方面,Spark支持SQL及Hive SQL,这极大的方便了传统SQL开发和数据仓库的使用者。
- 支持流式计算:与MapReduce只能处理离线数据相比,Spark还支持实时的流计算。Spark依赖SparkStreaming对数据进行实时的处理,其流式处理能力还要强于Storm。
- 可用性高。Spark自身实现了Standalone部署模式,此模式下的Master可以有多个,解决了单点故障问题。Spark也完全支持使用外部的部署模式,比如YARN、Mesos、EC2等。
- 丰富的数据源支持:Spark除了可以访问操作系统自身的文件系统和HDFS,还可以访问Kafka、Socket、Cassandra、HBase、Hive、Alluxio(Tachyon)以及任何Hadoop的数据源。这极大地方便了已经使用HDFS、HBase的用户顺利迁移到Spark。
- 丰富的文件格式支持:Spark支持文本文件格式、Csv文件格式、Json文件格式、Orc文件格式、Parquet文件格式、Libsvm文件格式,也有利于Spark与其他数据处理平台的对接。
基本概念
要想对Spark有整体性的了解,推荐读者阅读Matei Zaharia的Spark论文。此处笔者先介绍Spark中的一些概念:
- RDD(resillient distributed dataset):弹性分布式数据集。Spark应用程序通过使用Spark的转换API可以将RDD封装为一系列具有血缘关系的RDD,也就是DAG。只有通过Spark的动作API才会将RDD及其DAG提交到DAGScheduler。RDD的祖先一定是一个跟数据源相关的RDD,负责从数据源迭代读取数据。
- DAG(Directed Acycle graph):有向无环图。在图论中,如果一个有向图无法从某个顶点出发经过若干条边回到该点,则这个图是一个有向无环图(DAG图)。Spark使用DAG来反映各RDD之间的依赖或血缘关系。
- Partition:数据分区。即一个RDD的数据可以划分为多少个分区。Spark根据Partition的数量来确定Task的数量。
- NarrowDependency:窄依赖。即子RDD依赖于父RDD中固定的Partition。NarrowDependency分为OneToOneDependency和RangeDependency两种。
- ShuffleDependency:Shuffle依赖,也称为宽依赖。即子RDD对父RDD中的所有Partition都可能产生依赖。子RDD对父RDD各个Partition的依赖将取决于分区计算器(Partitioner)的算法。
- Job:用户提交的作业。当RDD及其DAG被提交给DAGScheduler调度后,DAGScheduler会将所有RDD中的转换及动作视为一个Job。一个Job由一到多个Task组成。
- Stage:Job的执行阶段。DAGScheduler按照ShuffleDependency作为Stage的划分节点对RDD的DAG进行Stage划分(上游的Stage将为ShuffleMapStage)。因此一个Job可能被划分为一到多个Stage。Stage分为ShuffleMapStage和ResultStage两种。
- Task:具体执行任务。一个Job在每个Stage内都会按照RDD的Partition 数量,创建多个Task。Task分为ShuffleMapTask和ResultTask两种。ShuffleMapStage中的Task为ShuffleMapTask,而ResultStage中的Task为ResultTask。ShuffleMapTask和ResultTask类似于Hadoop中的 Map任务和Reduce任务。
Scala与Java的比较
目前越来越多的语言可以运行在Java虚拟机上,Java平台上的多语言混合编程正成为一种潮流。在混合编程模式下可以充分利用每种语言的特点和优势,以便更好地完成功能。Spark同时选择了Scala和Java作为开发语言,也是为了充分利用二者各自的优势。表1对这两种语言进行比较。
表1 Scala与Java的比较
|
Scala |
Java |
|
|
语言类型 |
面向函数为主,兼有面向对象 |
面向对象(Java8也增加了lambda函数编程) |
|
简洁性 |
非常简洁 |
不简洁 |
|
类型推断 |
丰富的类型推断,例如深度和链式的类型推断、 duck type 、隐式类型转换等,但也因此增加了编译时长 |
少量的类型推断 |
|
可读性 |
一般,丰富的语法糖导致的各种奇幻用法,例如方法签名、隐式转换 |
好 |
|
学习成本 |
较高 |
一般 |
|
语言特性 |
非常丰富的语法糖和更现代的语言特性,例如 Option 、模式匹配、使用空格的方法调用 |
丰富 |
|
并发编程 |
使用Actor的消息模型 |
使用阻塞、锁、阻塞队列等 |
注意:虽然Actor是Scala语言最初进行推广时,最吸引人的特性之一,但是随着Akka更加强大的Actor类库的出现,Scala已经在官方网站宣布废弃Scala自身的Actor编程模型,转而全面拥抱Akka提供的Actor编程模型。与此同时,从Spark2.0.0版本开始,Spark却放弃了使用Akka,转而使用Netty实现了自己的Rpc框架。遥想当年Scala“鼓吹”Actor编程模型优于Java的同步编程模型时,又有谁会想到如今这种场面呢?
Scala作为函数式编程的代表,天生适合并行运行,如果用Java语言实现相同的功能会显得非常臃肿。很多介绍Spark的新闻或文章经常以Spark内核代码行数少或API精炼等内容作为宣传的“法器”,这应该也是选择Scala的原因之一。另一方面,由于函数式编程更接近计算机思维,因此便于通过算法从大数据中建模,这也更符合Spark作为大数据框架的理念吧!
由于Java适合服务器、中间件开发,所以Spark使用Java更多的是开发底层的基础设施或中间件。
模块设计
整个Spark主要由以下模块组成:
- Spark Core:Spark的核心功能实现,包括:基础设施、SparkContext(Application通过SparkContext提交)、Spark执行环境(SparkEnv)、存储体系、调度系统、计算引擎、部署模式、任务提交与执行等。
- Spark SQL:提供SQL处理能力,便于熟悉关系型数据库操作的工程师进行交互查询。此外,还为熟悉Hive开发的用户提供了对Hive SQL的支持。
- Spark Streaming:提供流式计算处理能力,目前支持ApacheKafka、Apache Flume、Amazon Kinesis和简单的TCP套接字等数据源。在早期的Spark版本中还自带对Twitter、MQTT、ZeroMQ等的支持,现在用户想要支持这些工具必须自己开发实现。此外,Spark Streaming还提供窗口操作用于对一定周期内的流数据进行处理。
- GraphX:基于图论,实现的支持分布式的图计算处理框架。GraphX的基础是点、边等图论的理论。GraphX 基于图计算的Pregel模型提供了多种多样的Pregel API,这些Pregel API可以解决图计算中的常见问题。
- MLlib:Spark提供的机器学习库。MLlib提供了机器学习相关的统计、分类、回归等领域的多种算法实现。其一致的API接口大大降低了用户的学习成本。
Spark SQL、Spark Streaming、GraphX、MLlib的能力都是建立在核心引擎之上,如图

Spark各模块依赖关系
Spark核心功能
Spark Core中提供了Spark最基础与最核心的功能,主要包括:
- 基础设施:在Spark中有很多基础设施,被Spark中的各种组件广泛使用。这些基础设施包括Spark配置(SparkConf)、Spark内置的Rpc框架(在早期Spark版本中Spark使用的是Akka)、事件总线(ListenerBus)、度量系统。SparkConf用于管理Spark应用程序的各种配置信息。Spark内置的Rpc框架使用Netty实现,有同步和异步的多种实现,Spark各个组件间的通信都依赖于此Rpc框架。如果说Rpc框架是跨机器节点不同组件间的通信设施,那么事件总线就是SparkContext内部各个组件间使用事件——监听器模式异步调用的实现。度量系统由Spark中的多种度量源(Source)和多种度量输出(Sink)构成,完成对整个Spark集群中各个组件运行期状态的监控。
- SparkContext:通常而言,用户开发的Spark应用程序(Application)的提交与执行都离不开SparkContext的支持。在正式提交Application之前,首先需要初始化SparkContext。SparkContext隐藏了网络通信、分布式部署、消息通信、存储体系、计算引擎、度量系统、文件服务、Web UI等内容,应用程序开发者只需要使用SparkContext提供的API完成功能开发。
- SparkEnv:Spark执行环境(SparkEnv)是Spark中的Task运行所必须的组件。SparkEnv内部封装了Rpc环境(RpcEnv)、序列化管理器、广播管理器(BroadcastManager)、map任务输出跟踪器(MapOutputTracker)、存储体系、度量系统(MetricsSystem)、输出提交协调器(OutputCommitCoordinator)等Task运行所需的各种组件。
- 存储体系:Spark优先考虑使用各节点的内存作为存储,当内存不足时才会考虑使用磁盘,这极大地减少了磁盘I/O,提升了任务执行的效率,使得Spark适用于实时计算、迭代计算、流式计算等场景。在实际场景中,有些Task是存储密集型的,有些则是计算密集型的,所以有时候会造成存储空间很空闲,而计算空间的资源又很紧张。Spark的内存存储空间与执行存储空间之间的边界可以是“软”边界,因此资源紧张的一方可以借用另一方的空间,这既可以有效利用资源,又可以提高Task的执行效率。此外,Spark的内存空间还提供了Tungsten的实现,直接操作操作系统的内存。由于Tungsten省去了在堆内分配Java对象,因此能更加有效的利用系统的内存资源,并且因为直接操作系统内存,空间的分配和释放也更迅速。在Spark早期版本还使用了以内存为中心的高容错的分布式文件系统Alluxio(Tachyon)供用户进行选择。Alluxio能够为Spark提供可靠的内存级的文件共享服务。
- 调度系统:调度系统主要由DAGScheduler和TaskScheduler组成,它们都内置在SparkContext中。DAGScheduler负责创建Job、将DAG中的RDD划分到不同的Stage、给Stage创建对应的Task、批量提交Task等功能。TaskScheduler负责按照FIFO或者FAIR等调度算法对批量Task进行调度;为Task分配资源;将Task发送到集群管理器分配给当前应用的Executor上由Executor负责执行等工作。现如今,Spark增加了SparkSession和DataFrame等新的API,SparkSession底层实际依然依赖于SparkContext。
- 计算引擎:计算引擎由内存管理器(MemoryManager)、Tungsten、任务内存管理器(TaskMemoryManager)、Task、外部排序器(ExternalSorter)、Shuffle管理器(ShuffleManager)等组成。MemoryManager除了对存储体系中的存储内存提供支持和管理,还外计算引擎中的执行内存提供支持和管理。Tungsten除用于存储外,也可以用于计算或执行。TaskMemoryManager对分配给单个Task的内存资源进行更细粒度的管理和控制。ExternalSorter用于在map端或reduce端对ShuffleMapTask计算得到的中间结果进行排序、聚合等操作。ShuffleManager用于将各个分区对应的ShuffleMapTask产生的中间结果持久化到磁盘,并在reduce端按照分区远程拉取ShuffleMapTask产生的中间结果。
Spark扩展功能
为了扩大应用范围,Spark陆续增加了一些扩展功能,主要包括:
- Spark SQL:由于SQL具有普及率高、学习成本低等特点,为了扩大Spark的应用面,因此增加了对SQL及Hive的支持。Spark SQL的过程可以总结为:首先使用SQL语句解析器(SqlParser)将SQL转换为语法树(Tree),并且使用规则执行器(RuleExecutor)将一系列规则(Rule)应用到语法树,最终生成物理执行计划并执行的过程。其中,规则包括语法分析器(Analyzer)和优化器(Optimizer)。Hive的执行过程与SQL类似。
- Spark Streaming:Spark Streaming与Apache Storm类似,也用于流式计算。SparkStreaming支持Kafka、Flume、Kinesis和简单的TCP套接字等多种数据输入源。输入流接收器(Receiver)负责接入数据,是接入数据流的接口规范。Dstream是Spark Streaming中所有数据流的抽象,Dstream可以被组织为DStreamGraph。Dstream本质上由一系列连续的RDD组成。
- GraphX:Spark提供的分布式图计算框架。GraphX主要遵循整体同步并行计算模式(Bulk Synchronous Parallell,简称BSP)下的Pregel模型实现。GraphX提供了对图的抽象Graph,Graph由顶点(Vertex)、边(Edge)及继承了Edge的EdgeTriplet(添加了srcAttr和dstAttr用来保存源顶点和目的顶点的属性)三种结构组成。GraphX目前已经封装了最短路径、网页排名、连接组件、三角关系统计等算法的实现,用户可以选择使用。
- MLlib:Spark提供的机器学习框架。机器学习是一门涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多领域的交叉学科。MLlib目前已经提供了基础统计、分类、回归、决策树、随机森林、朴素贝叶斯、保序回归、协同过滤、聚类、维数缩减、特征提取与转型、频繁模式挖掘、预言模型标记语言、管道等多种数理统计、概率论、数据挖掘方面的数学算法。
Spark模型设计
1. Spark编程模型
正如Hadoop在介绍MapReduce编程模型时选择word count的例子,并且使用图形来说明一样,笔者对于Spark编程模型也选择用图形展现。
Spark 应用程序从编写到提交、执行、输出的整个过程如图所示。
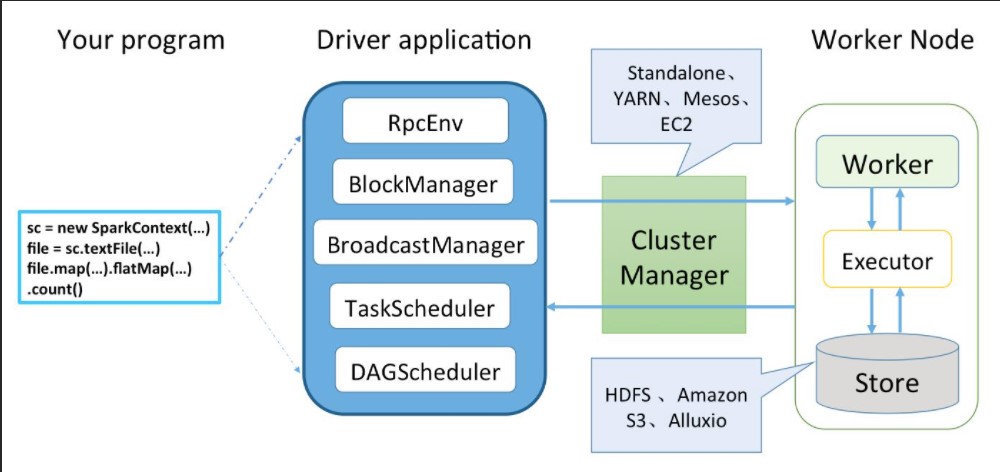
代码执行过程
图5中描述了Spark编程模型的关键环节的步骤如下。
1)用户使用SparkContext提供的API(常用的有textFile、sequenceFile、runJob、stop等)编写Driver application程序。此外,SparkSession、DataFrame、SQLContext、HiveContext及StreamingContext都对SparkContext进行了封装,并提供了DataFrame、SQL、Hive及流式计算相关的API。
2)使用SparkContext提交的用户应用程序,首先会通过RpcEnv向集群管理器(Cluster Manager)注册应用(Application)并且告知集群管理器需要的资源数量。集群管理器根据Application的需求,给Application分配Executor资源,并在Worker上启动CoarseGrainedExecutorBackend进程(CoarseGrainedExecutorBackend进程内部将创建Executor)。Executor所在的CoarseGrainedExecutorBackend进程在启动的过程中将通过RpcEnv直接向Driver注册Executor的资源信息,TaskScheduler将保存已经分配给应用的Executor资源的地址、大小等相关信息。然后,SparkContext根据各种转换API,构建RDD之间的血缘关系(lineage)和DAG,RDD构成的DAG将最终提交给DAGScheduler。DAGScheduler给提交的DAG创建Job并根据RDD的依赖性质将DAG划分为不同的Stage。DAGScheduler根据Stage内RDD的Partition数量创建多个Task并批量提交给TaskScheduler。TaskScheduler对批量的Task按照FIFO或FAIR调度算法进行调度,然后给Task分配Executor资源,最后将Task发送给Executor由Executor执行。此外,SparkContext还会在RDD转换开始之前使用BlockManager和BroadcastManager将任务的Hadoop配置进行广播。
3)集群管理器(Cluster Manager)会根据应用的需求,给应用分配资源,即将具体任务分配到不同Worker节点上的多个Executor来处理任务的运行。Standalone、YARN、Mesos、EC2等都可以作为Spark的集群管理器。
4)Task在运行的过程中需要对一些数据(例如中间结果、检查点等)进行持久化,Spark支持选择HDFS 、Amazon S3、Alluxio(原名叫Tachyon)等作为存储。
2.RDD计算模型
RDD可以看做是对各种数据计算模型的统一抽象,Spark的计算过程主要是RDD的迭代计算过程,如图6所示。RDD的迭代计算过程非常类似于管道。分区数量取决于Partition数量的设定,每个分区的数据只会在一个Task中计算。所有分区可以在多个机器节点的Executor上并行执行。
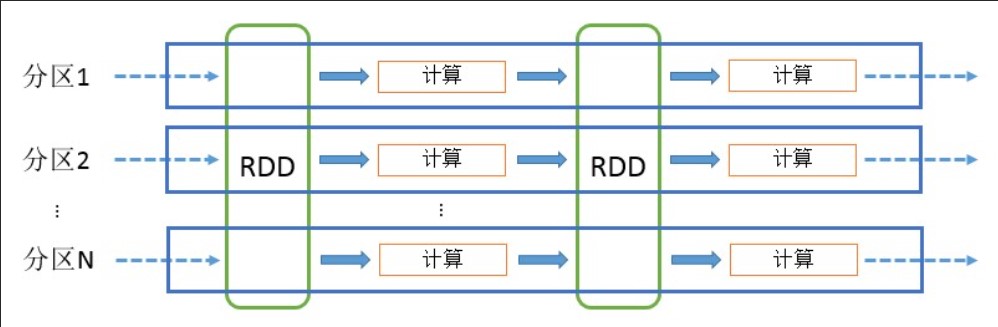
RDD计算模型
上图只是简单的从分区的角度将RDD的计算看作是管道,如果从RDD的血缘关系、Stage划分的角度来看,由RDD构成的DAG经过DAGScheduler调度后,将变成下图所示的样子。

DAGScheduler对由RDD构成的DAG进行调度
上图中共展示了A、B、C、D、E、F、G一共7个RDD。每个RDD中的小方块代表一个分区,将会有一个Task处理此分区的数据。RDD A经过groupByKey转换后得到RDD B。RDD C经过map转换后得到RDD D。RDD D和RDD E经过union转换后得到RDD F。RDD B和RDD F经过join转换后得到RDD G。从图中可以看到map和union生成的RDD与其上游RDD之间的依赖是NarrowDependency,而groupByKey和join生成的RDD与其上游的RDD之间的依赖是ShuffleDependency。由于DAGScheduler按照ShuffleDependency作为Stage的划分的依据,因此A被划入了ShuffleMapStage 1;C、D、E、F被划入了ShuffleMapStage 2;B和G被划入了ResultStage 3。
Spark基本架构
从集群部署的角度来看,Spark集群由集群管理器(Cluster Manager)、工作节点(Worker)、执行器(Executor)、驱动器(Driver)、应用程序(Application)等部分组成,它们之间的整体关系如下图所示。
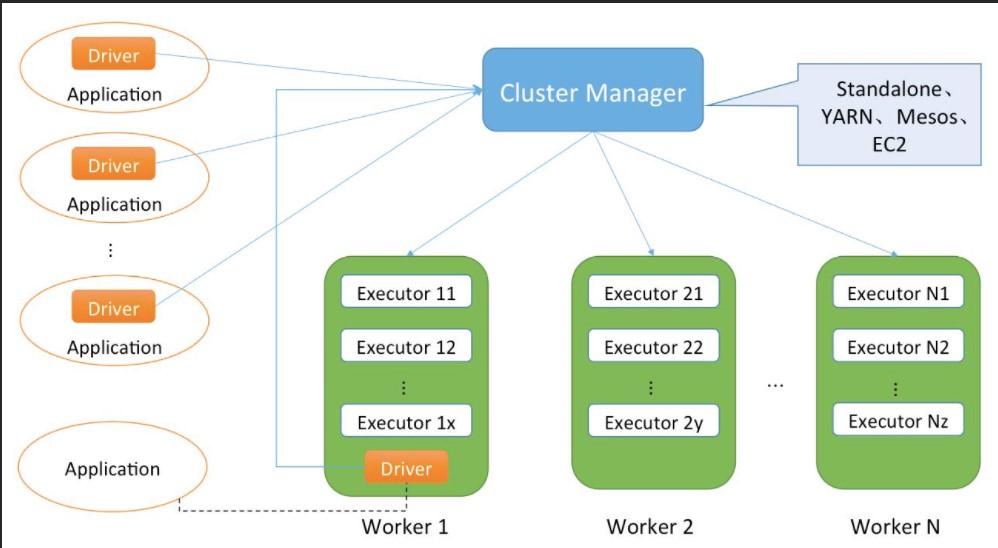
Spark基本架构图
下面结合图8对这些组成部分以及它们之间的关系进行介绍。
(1)Cluster Manager
Spark的集群管理器,主要负责对整个集群资源的分配与管理。Cluster Manager在Yarn部署模式下为ResourceManager;在Mesos部署模式下为Mesos master;在Standalone部署模式下为Master。Cluster Manager分配的资源属于一级分配,它将各个Worker上的内存、CPU等资源分配给Application,但是并不负责对Executor的资源分配。Standalone部署模式下的Master会直接给Application分配内存、CPU以及Executor等资源。目前,Standalone、YARN、Mesos、EC2等都可以作为Spark的集群管理器。
注意:这里提到了部署模式中的Standalone、Yarn、Mesos等模式,读者暂时知道这些内容即可,本书将在第9章对它们详细介绍。
(2)Worker
Spark的工作节点。在Yarn部署模式下实际由NodeManager替代。Worker节点主要负责以下工作:将自己的内存、CPU等资源通过注册机制告知Cluster Manager;创建Executor;将资源和任务进一步分配给Executor;同步资源信息、Executor状态信息给Cluster Manager等。在Standalone部署模式下,Master将Worker上的内存、CPU以及Executor等资源分配给Application后,将命令Worker启动CoarseGrainedExecutorBackend进程(此进程会创建Executor实例)。
(3)Executor
执行计算任务的一线组件。主要负责任务的执行以及与Worker、Driver的信息同步。
(4)Driver
Application的驱动程序,Application通过Driver与Cluster Manager、Executor进行通信。Driver可以运行在Application中,也可以由Application提交给Cluster Manager并由Cluster Manager安排Worker运行。
(4)Application
用户使用Spark提供的API编写的应用程序,Application通过Spark API将进行RDD的转换和DAG的构建,并通过Driver将Application注册到Cluster Manager。Cluster Manager将会根据Application的资源需求,通过一级分配将Executor、内存、CPU等资源分配给Application。Driver通过二级分配将Executor等资源分配给每一个任务,Application最后通过Driver告诉Executor运行任务。
来源: 《Spark内核设计的艺术 架构设计与实现》 --耿嘉安
转自:https://blog.csdn.net/zhanglong_4444/article/details/84976565?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164042392516780271937690%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164042392516780271937690&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~hot_rank-5-84976565.first_rank_v2_pc_rank_v29&utm_term=spark%E5%9F%BA%E7%A1%80&spm=1018.2226.3001.4449
Spark基础知识详解的更多相关文章
- RabbitMQ基础知识详解
什么是MQ? MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.MQ是消费-生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取队列中 ...
- Cisco路由技术基础知识详解
第一部分 请写出568A的线序(接触网络第一天就应该会的,只要你掐过,想都能想出来) .网卡MAC地址长度是( )个二进制位(16进制与2进制的换算关系,只是换种方式问,不用你拿笔去算) A.12 ...
- RabbitMQ,Apache的ActiveMQ,阿里RocketMQ,Kafka,ZeroMQ,MetaMQ,Redis也可实现消息队列,RabbitMQ的应用场景以及基本原理介绍,RabbitMQ基础知识详解,RabbitMQ布曙
消息队列及常见消息队列介绍 2017-10-10 09:35操作系统/客户端/人脸识别 一.消息队列(MQ)概述 消息队列(Message Queue),是分布式系统中重要的组件,其通用的使用场景可以 ...
- Python基础知识详解 从入门到精通(七)类与对象
本篇主要是介绍python,内容可先看目录其他基础知识详解,欢迎查看本人的其他文章Python基础知识详解 从入门到精通(一)介绍Python基础知识详解 从入门到精通(二)基础Python基础知识详 ...
- 直播一:H.264编码基础知识详解
一.编码基础概念 1.为什么要进行视频编码? 视频是由一帧帧图像组成,就如常见的gif图片,如果打开一张gif图片,可以发现里面是由很多张图片组成.一般视频为了不让观众感觉到卡顿,一秒钟至少需要16帧 ...
- 第157天:canvas基础知识详解
目录 一.canvas简介 1.1 什么是canvas?(了解) 1.2 canvas主要应用的领域(了解) 二.canvas绘图基础 2.0 sublime配置canvas插件(推荐) 2.1 Ca ...
- Redis基础知识详解(非原创)
文章大纲 一.Redis介绍二.Redis安装并设置开机自动启动三.Redis文件结构四.Redis启动方式五.Redis持久化六.Redis配置文件详解七.Redis图形化工具八.Java之Jedi ...
- Maven基础知识详解
1. 简介 Maven在Java领域的应用已经非常广泛了,有了Maven的存在是的开发人员在搭建.依赖.扩展和打包项目上变得非常简单. 2. Windows安装Maven 下载安装包 http ...
- 【干货】用大白话聊聊JavaSE — ArrayList 深入剖析和Java基础知识详解(二)
在上一节中,我们简单阐述了Java的一些基础知识,比如多态,接口的实现等. 然后,演示了ArrayList的几个基本方法. ArrayList是一个集合框架,它的底层其实就是一个数组,这一点,官方文档 ...
随机推荐
- java 输入输出IO流 IO异常处理try(IO流定义){IO流使用}catch(异常){处理异常}finally{死了都要干}
IO异常处理 之前我们写代码的时候都是直接抛出异常,但是我们试想一下,如果我们打开了一个流,在关闭之前程序抛出了异常,那我们还怎么关闭呢?这个时候我们就要用到异常处理了. try-with-resou ...
- call this的范围
var f1=function(){this.a="类f1的实例的a属性"}; f1代表一个类: f1.a='对象f1的a属性'; var f2=function(){};//类f ...
- PowerShell配置文件后门
PowerShell 配置文件是在 PowerShell 启动时运行的脚本. 在某些情况下,攻击者可以通过滥用PowerShell配置文件来获得持久性和提升特权.修改这些配置文件,以包括任意命 ...
- Android 控件使用教程(一)—— ListView 展示图片
起因 最近在看一些开源项目时,经常看到了RecyclerView,这是安卓5.0推出的一个新的控件,可以代替传统的ListView,已经这么久了还没有用过,所以决定试一试.另外在做这个的工程中看到了另 ...
- 【九度OJ】题目1205:N阶楼梯上楼问题 解题报告
[九度OJ]题目1205:N阶楼梯上楼问题 解题报告 标签(空格分隔): 九度OJ http://ac.jobdu.com/problem.php?pid=1205 题目描述: N阶楼梯上楼问题:一次 ...
- 【LeetCode】686. Repeated String Match 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 1017 - Brush (III)
1017 - Brush (III) PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: 32 MB Sami ...
- 如何改善win10录屏时声音降噪(消除杂音)
此文章是针对win10系统中安装Realtek声卡的麦克风出现杂音的设置办法 1. 打开win10的控制面板,找到"硬件和声音选项" 2. 进入"硬件和声音"选 ...
- Spring中的@Bean注解
@Bean 基础概念 @Bean:Spring的@Bean注解用于告诉方法,产生一个Bean对象,然后这个Bean对象交给Spring管理.产生这个Bean对象的方法Spring只会调用一次,随后这个 ...
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
目录 概 主要内容 positional encoding 额外的细节 代码 Mildenhall B., Srinivasan P. P., Tancik M., Barron J. T., Ram ...