Hadoop完整搭建过程(四):完全分布模式(服务器)
1 概述
上一篇文章介绍了如何使用虚拟机搭建集群,到了这篇文章就是实战了,使用真实的三台不同服务器进行Hadoop集群的搭建。具体步骤其实与虚拟机的差不多,但是由于安全组以及端口等等一些列的问题,会与虚拟机有所不同,废话不多说,下面正式开始。
2 约定
Master节点的ip用MasterIP表示,主机名用master表示- 两个
Worker节点的ip用Worker1IP/Worker2IP表示,主机名用worker1/worker2表示 - 这里为了演示方便统一使用
root用户登录,当然生产环境不会这样
3 (可选)本地Host
修改本地Host,方便使用主机名来进行操作:
sudo vim /etc/hosts
# 添加
MaterIP master
Worker1IP worker1
Worker2IP worker2
4 ssh
本机生成密钥对后复制公钥到三台服务器上:
ssh-keygen -t ed25519 -a 100 # 使用更快更安全的ed25519算法而不是传统的RSA-3072/4096
ssh-copy-id root@master
ssh-copy-id root@worker1
ssh-copy-id root@worker2
这时可以直接使用root@host进行连接了:
ssh root@master
ssh root@worker1
ssh root@worker2
不需要输入密码,如果不能连接或者需要输入密码请检查/etc/ssh/sshd_config或系统日志。
5 主机名
修改Master节点的主机名为master,两个Worker节点的主机名为worker1、worker2:
# Master节点
vim /etc/hostname
master
# Worker1节点
# worker1
# Worker2节点
# worker2
同时修改Host:
# Master节点
vim /etc/hosts
Worker1IP worker1
Worker2IP worker2
# Worker1节点
vim /etc/hosts
MasterIP master
Worker2IP worker2
# Worker1节点
vim /etc/hosts
MasterIP master
Worker1IP worker1
修改完成之后需要互ping测试:
ping master
ping worker1
ping worker2
ping不通的话应该是安全组的问题,开放ICMP协议即可:

6 配置基本环境
6.1 JDK
scp上传OpenJDK 11,解压并放置于/usr/local/java下,同时修改PATH:
export PATH=$PATH:/usr/local/java/bin
如果原来的服务器装有了其他版本的JDK可以先卸载:
yum remove java
注意设置环境变量后需要测试以下java,因为不同服务器的架构可能不一样:


比如笔者的Master节点为aarch64架构,而两个Worker都是x86_64架构,因此Master节点执行java时报错如下:

解决办法是通过yum install安装OpenJDK11:
yum install java-11-openjdk
6.2 Hadoop
scp上传Hadoop 3.3.0,解压并放置于/usr/local/hadoop下,注意选择对应的架构:
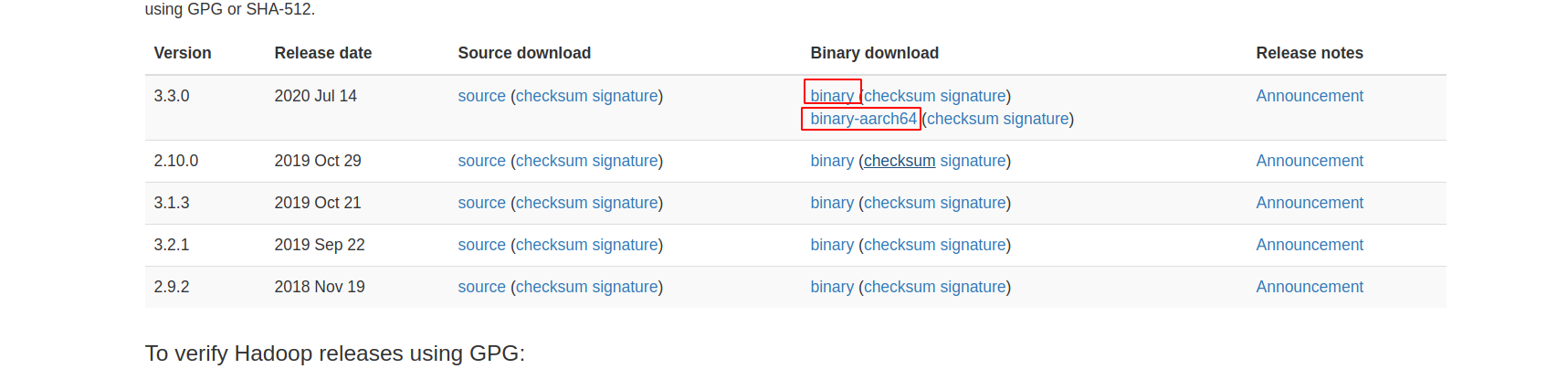
解压后修改以下四个配置文件:
etc/hadoop/hadoop-env.shetc/hadoop/core-site.xmletc/hadoop/hdfs-site.xmletc/hadoop/workers
6.2.1 hadoop-env.sh
修改JAVA_HOME环境变量即可:
export JAVA_HOME=/usr/local/java # 修改为您的Java目录
6.2.2 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>
</property>
</configuration>
具体选项与虚拟机方式的设置相同,这里不再重复叙述。
6.2.3 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
6.2.4 workers
worker1
worker2
6.2.5 复制配置文件
# 如果设置了端口以及私钥
# 加上 -P 端口 -i 私钥
scp /usr/local/hadoop/etc/hadoop/* worker1:/usr/local/hadoop/etc/hadoop/
scp /usr/local/hadoop/etc/hadoop/* worker2:/usr/local/hadoop/etc/hadoop/
7 启动
7.1 格式化HDFS
在Master中,首先格式化HDFS
cd /usr/local/hadoop
bin/hdfs namenode -format
如果配置文件没错的话就格式化成功了。
7.2 hadoop-env.sh
还是在Master中,修改/usr/local/hadoop/etc/hadoop/hadoop-env.sh,末尾添加:
HDFS_DATANODE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
7.3 启动
首先Master开放9000以及9870端口(一般安全组开放即可,如果开启了防火墙firewalld/iptables则添加相应规则),并在Master节点中启动:
sbin/start-dfs.sh
浏览器输入:
MasterIP:9870
即可看到如下页面:

如果看到Live Nodes数量为0请查看Worker的日志,这里发现是端口的问题:

并且在配置了安全组,关闭了防火墙的情况下还是如此,则有可能是Host的问题,可以把Master节点中的:
# /etc/hosts
127.0.0.1 master
删去,同样道理删去两个Worker中的:
# /etc/hosts
127.0.0.1 worker1
127.0.0.1 worker2
8 YARN
8.1 环境变量
修改/usr/local/hadoop/etc/hadoop/hadoop-env.sh,添加:
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
8.2 YARN配置
在两个Worker节点中修改/usr/local/hadoop/etc/hadoop/yarn-site.xml:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
8.3 开启YARN
Master节点中开启YARN:
cd /usr/local/hadoop
sbin/start-yarn.sh
同时Master的安全组开放8088以及8031端口。
8.4 测试
浏览器输入:
MasterIP:8088
应该就可以访问如下页面了:
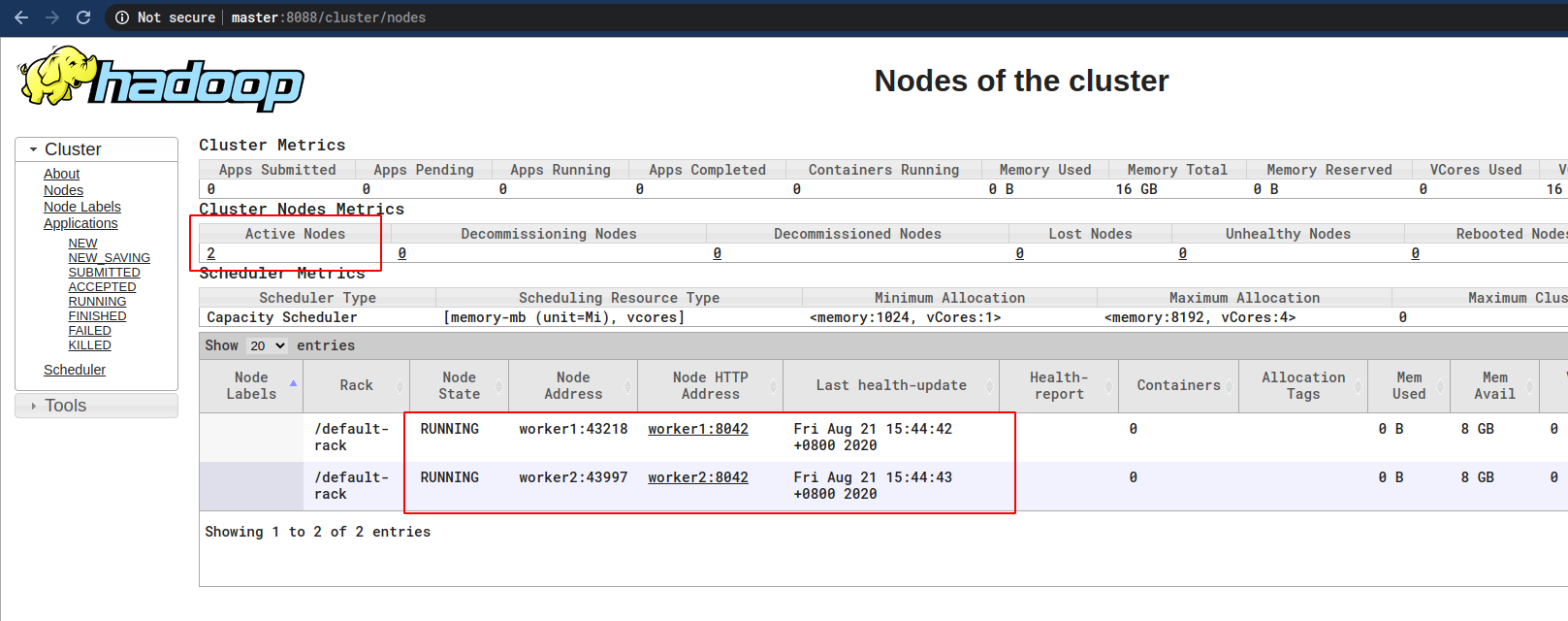
至此集群正式搭建完成。
9 参考
- 博客园-HDFS之五:Hadoop 拒绝远程 9000 端口访问
- How To Set Up a Hadoop 3.2.1 Multi-Node Cluster on Ubuntu 18.04 (2 Nodes)
- How to Install and Set Up a 3-Node Hadoop Cluster
Hadoop完整搭建过程(四):完全分布模式(服务器)的更多相关文章
- 本地+分布式Hadoop完整搭建过程
1 概述 Hadoop在大数据技术体系中极为重要,被誉为是改变世界的7个Java项目之一(剩下6个是Junit.Eclipse.Spring.Solr.HudsonAndJenkins.Android ...
- Hadoop完整搭建过程(三):完全分布模式(虚拟机)
1 完全分布模式 完全分布模式是比本地模式与伪分布模式更加复杂的模式,真正利用多台Linux主机来进行部署Hadoop,对集群进行规划,使得Hadoop各个模块分别部署在不同的多台机器上,这篇文章介绍 ...
- Hadoop完整搭建过程(二):伪分布模式
1 伪分布模式 伪分布模式是运行在单个节点以及多个Java进程上的模式.相比起本地模式,需要进行更多配置文件的设置以及ssh.YARN相关设置. 2 Hadoop配置文件 修改Hadoop安装目录下的 ...
- Hadoop完整搭建过程(一):本地模式
1 本地模式 本地模式是最简单的模式,所有模块都运行在一个JVM进程中,使用本地文件系统而不是HDFS. 本地模式主要是用于本地开发过程中的运行调试用,下载后的Hadoop不需要设置默认就是本地模式. ...
- 转载——Asp.Net MVC+EF+三层架构的完整搭建过程
转载http://www.cnblogs.com/zzqvq/p/5816091.html Asp.Net MVC+EF+三层架构的完整搭建过程 架构图: 使用的数据库: 一张公司的员工信息表,测试数 ...
- Hadoop环境搭建过程中遇到的问题以及解决方法
1.启动hadoop之前,ssh免密登录slave主机正常,使用命令start-all.sh启动hadoop时,需要输入slave主机的密码,说明ssh文件权限有问题,需要执行以下操作: 1)进入.s ...
- Asp.Net MVC+EF+三层架构的完整搭建过程
架构图: 使用的数据库: 一张公司的员工信息表,测试数据 解决方案项目设计: 1.新建一个空白解决方案名称为Company 2.在该解决方案下,新建解决方案文件夹(UI,BLL,DAL,Model) ...
- Hadoop环境搭建|第四篇:hive环境搭建
一.环境搭建 注意:hive版本不能太高,否则会出现兼容性问题 1.1.上传hive安装包 创建文件夹用于存放hive文件命令:mkdir hive 1.2.解压hive安装包 命令:tar -zxv ...
- Hadoop完全分布式搭建过程中遇到的问题小结
前一段时间,终于抽出了点时间,在自己本地机器上尝试搭建完全分布式Hadoop集群环境,也是借助网络上虾皮的Hadoop开发指南系列书籍一步步搭建起来的,在这里仅代表hadoop初学者向虾皮表示衷心的感 ...
随机推荐
- 【SpringMVC】 4.3 拦截器
SpringMVC学习记录 注意:以下内容是学习 北京动力节点 的SpringMVC视频后所记录的笔记.源码以及个人的理解等,记录下来仅供学习 第4章 SpringMVC 核心技术 4.3 拦截器 ...
- 【Notes_8】现代图形学入门——几何(基本表示方法、曲线与曲面)
几何 几何表示 隐式表示 不给出点的坐标,给数学表达式 优点 可以很容易找到点与几何之间的关系 缺点 找某特定的点很难 更多的隐式表示方法 Constructive Solid Geometry .D ...
- Linux没有ens33解决方案
一.前言 运行环境:window10+VMware14+Centos7 博主最近遇到一个比较郁闷的问题,在虚拟机上操作Linux系统查看IP的时候,发现没有ens33或者eth0了,试了很多办法都没有 ...
- 剑指 Offer 67. 把字符串转换成整数 + 字符串
剑指 Offer 67. 把字符串转换成整数 Offer_67 题目描述 题解分析 java代码 package com.walegarrett.offer; /** * @Author WaleGa ...
- 聊一聊和Nacos 2.0.0对接那些事
前言 nacos 2.0.0 已经发布了 alpha1, alpha2 和 beta 三个版本了,部分测试报告也已经出来了. Nacos2.0.0-ALPHA2 服务发现性能测试报告 Nacos 2. ...
- Web全段重点整理
1. HTML+CSS 1.1. HTML+CssDay01 1.1.1. 常用普通标签 常用标签如下 div span a p ul+li h1-h6 img 代码示例: <img src= ...
- C语言float和double输入问题
统计给定的n个数中,负数.零和正数的个数. Input 输入数据有多组,每组占一行,每行的第一个数是整数n(n<100),表示需要统计的数值的个数,然后是n个实数:如果n=0,则表示输入结 ...
- 2018.12-2019.1 TO-DO LIST
AC自动机 P3808 [模板]AC自动机(简单版)(完成时间:2018.12.06) P3796 [模板]AC自动机(加强版)(完成时间:2018.12.06) P2444 [POI2000]病毒( ...
- HashMap源码阅读(小白的java进阶)
OverView 构造方法 //构造方法 public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < ...
- classLoader动态加载技术
//加载器,apkPath为包含dex文件的.apk或jar路径,dexPath是优化后的dex文件路径,第三个表示libraryPath表示Native库的路径,最后是父类加载器 DexClassL ...