vivo 评论中台的流量及数据隔离实践
一、背景
vivo评论中台通过提供评论发表、点赞、举报、自定义评论排序等通用能力,帮助前台业务快速搭建评论功能并提供评论运营能力,避免了前台业务的重复建设和数据孤岛问题。目前已有vivo短视频、vivo浏览器、负一屏、vivo商城等10+业务接入。这些业务的流量大小和波动范围不同,如何保障各前台业务的高可用,避免因为某个业务的流量暴增导致其他业务的不可用?所有业务的评论数据都交由中台存储,他们的数据量大小不同、db压力不同,作为中台,应该如何隔离各个业务的数据,保障整个中台系统的高可用?
本文将和大家一起分享下vivo评论中台的解决方案,主要是从流量隔离和数据隔离两部分进行了处理。
二、流量隔离
2.1 流量分组
vivo浏览器业务亿级日活,实时热点新闻全网push,对于这类用户量大、流量大的重要业务,我们提供了单独的集群为他们提供服务,避免受到其他业务的影响。
vivo评论中台是通过Dubbo接口对外提供服务,我们通过Dubbo标签路由的方式对整个服务集群做了逻辑上的划分,一次 Dubbo 调用能够根据请求携带的 tag 标签智能地选择对应 tag 的服务提供者进行调用。如下图所示:
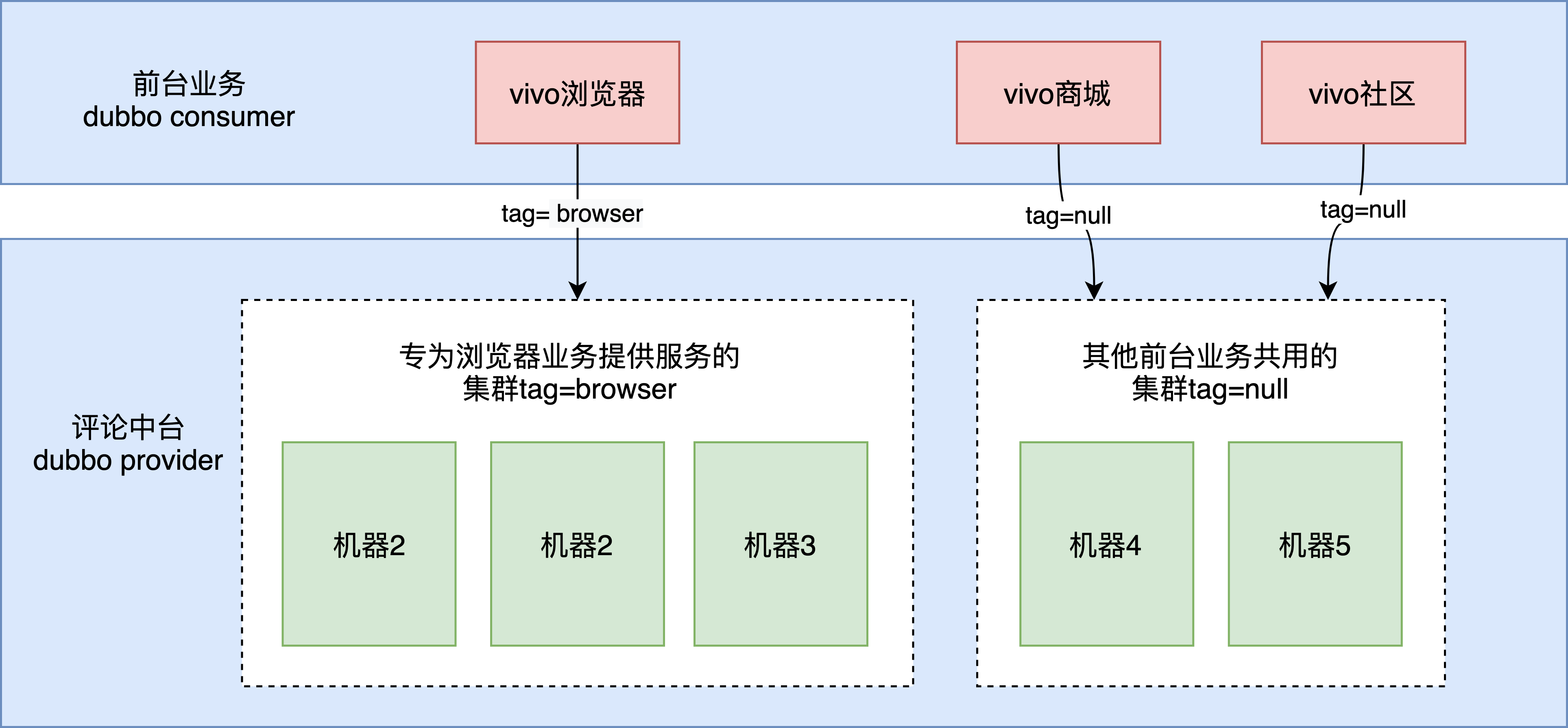
1)provider打标签:目前有两种方式可以完成实例分组,分别是动态规则打标和静态规则打标,其中动态规则相较于静态规则优先级更高,而当两种规则同时存在且出现冲突时,将以动态规则为准。公司内部的运维系统很好的支持了动态打标,通过对指定ip的机器打标即可(非docker容器,机器ip是固定的)。

2)前台consumer指定服务标签:发起请求时设置,如下;
前台指定中台的路由标签
RpcContext.getContext().setAttachment(Constants.REQUEST_TAG_KEY,"browser");
请求标签的作用域为每一次 invocation,只需要在调用评论中台服务前设置标签即可,前台业务调用其他业务的provider并不受该路由标签的影响。
2.2 多租户限流
大流量的业务我们通过单独的集群隔离出去了。但是独立部署集群成本高,不能为每个前台业务都独立部署一套集群。大部分情况下多个业务还是需要共用一套集群的,那么共用集群的服务遇到了突发流量如何处理呢?没错,限流呗!但是目前很多限流都是一刀切的方式对接口整体QPS做限流,这样的话某一前台业务的流量暴增会导致所有前台业务的请求都被限流。
这就需要多租户限流登场了(这里的一个租户可以理解为一个前台业务),支持对同一接口不同租户的流量进行限流处理,效果如下图:
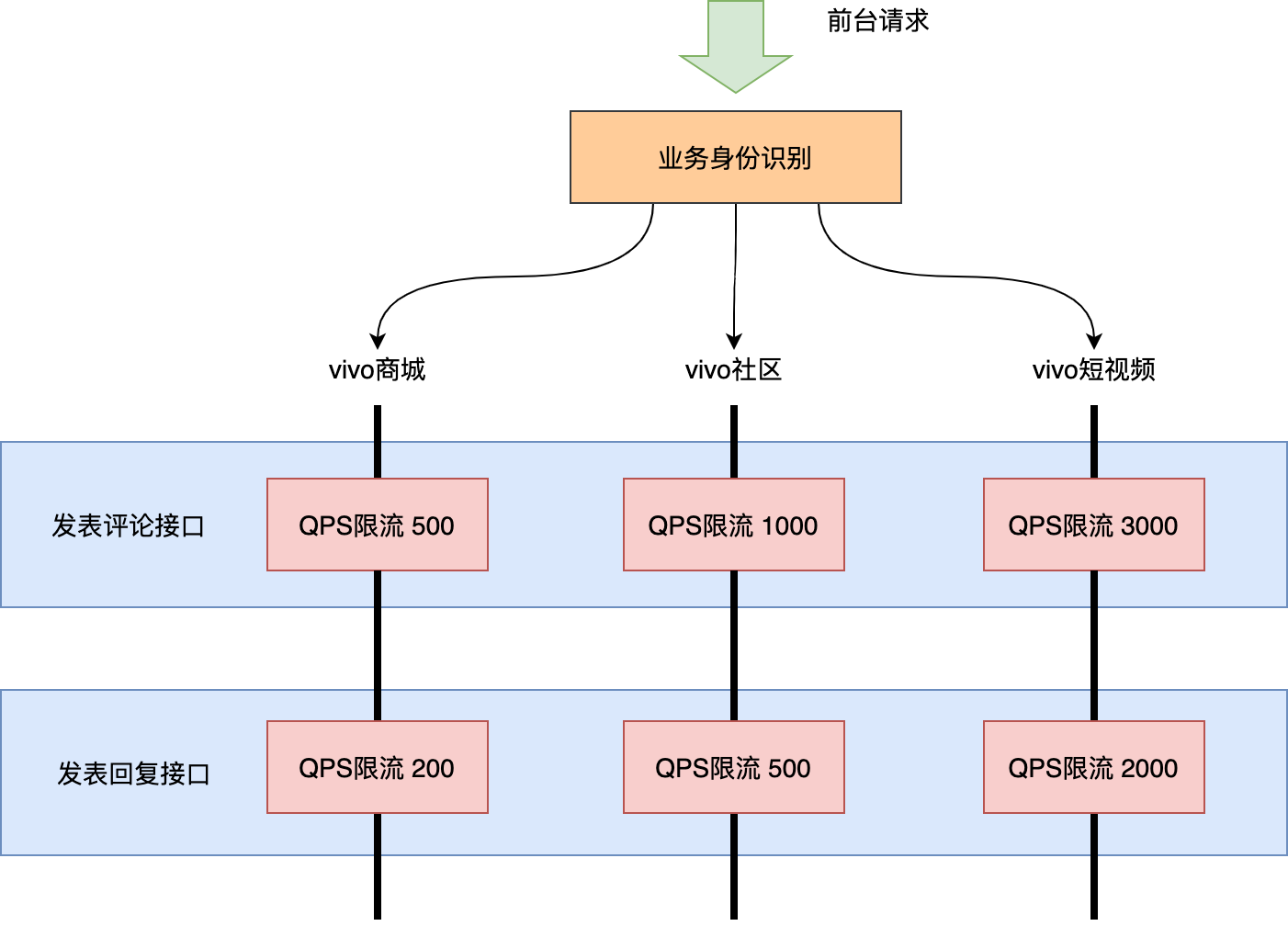
实现过程:
我们使用sentinel的热点参数限流特性,使用业务身份编码作为热点参数,为各业务配置不同的流控大小。
那么何为热点参数限流?首先得说下什么是热点,热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top n数据,并对其访问进行限制。比如:
商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制。
用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制。
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。Sentinel 利用 LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控。下图为评论场景示例:
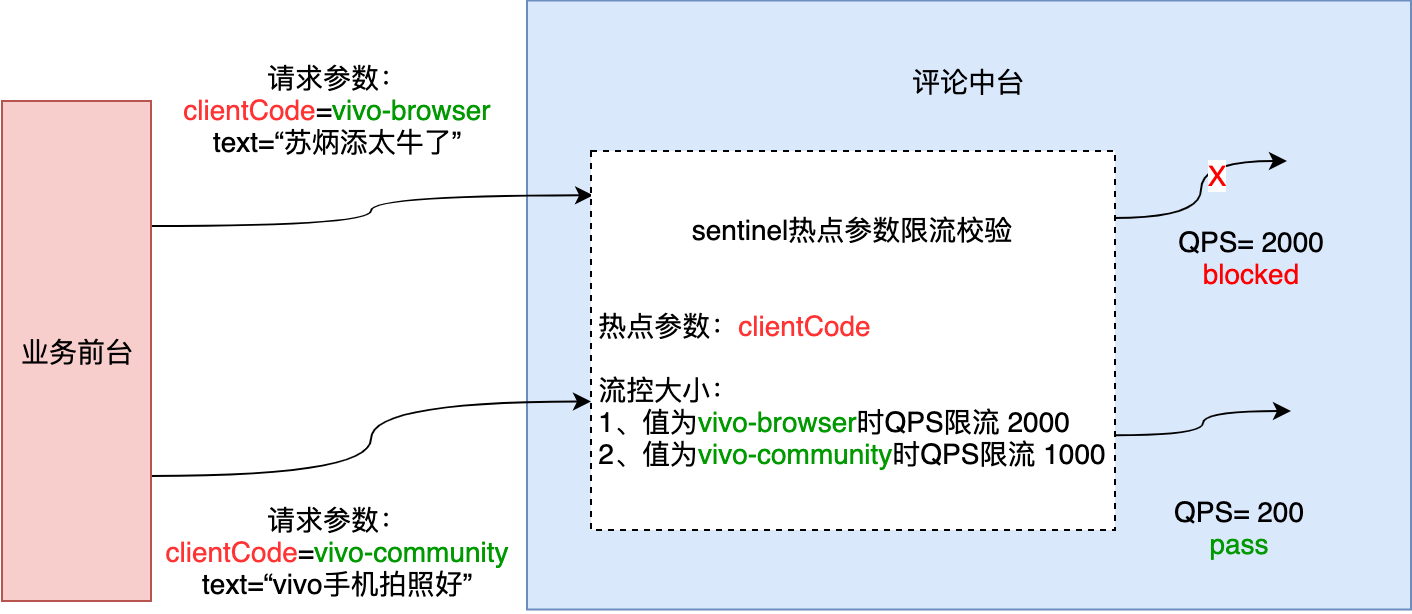
使用 Sentinel 来进行资源保护,主要分为几个步骤:定义资源、定义规则、规则生效处理。
1)定义资源:
在这里可以理解为各个中台API接口路径。
2)定义规则:
Sentienl支持规则很多QPS流控、自适应限流、热点参数限流、集群限流等等,这里我们用的是单机热点参数限流。
热点参数限流配置
{
"resource": "com.vivo.internet.comment.facade.comment.CommentFacade:comment(com.vivo.internet.comment.facade.comment.dto.CommentRequestDto)", // 需要限流的接口
"grade": 1, // QPS限流模式
"count": 3000, // 接口默认限流大小3000
"clusterMode": false, // 单机模式
"paramFieldName": "clientCode", // 指定热点参数名即业务方编码字段,这里是我们对sentinel组件做了优化,增加了该配置属性,用来指定参数对象的属性名作为热点参数key
"paramFlowItemList": [ // 热点参数限流规则
{
"object": "vivo-community", // 当clientCode为该值时,匹配该限流规则
"count": 1000, // 限流大小为1000
"classType": "java.lang.String"
},
{
"object": "vivo-shop", // 当clientCode为该值时,匹配该限流规则
"count": 2000, // 限流大小为2000
"classType": "java.lang.String"
}
]
}
3)规则生效处理:
当触发了限流规则后sentinel会抛出ParamFlowException异常,直接将异常抛给前台业务去处理是不优雅的。sentinel给我们提供了统一的异常回调处理入口DubboAdapterGlobalConfig,支持我们将异常转换为业务自定义结果返回。
自定义限流返回结果;
DubboAdapterGlobalConfig.setProviderFallback((invoker, invocation, ex) ->
AsyncRpcResult.newDefaultAsyncResult(FacadeResultUtils.returnWithFail(FacadeResultEnum.USER_FLOW_LIMIT), invocation));
我们做了哪些额外的优化:
1)公司内部的限流控制台尚不支持热点参数限流配置,因此我们增加了新的限流配置控制器,支持通过配置中心中动态下发限流配置。整体流程如下:
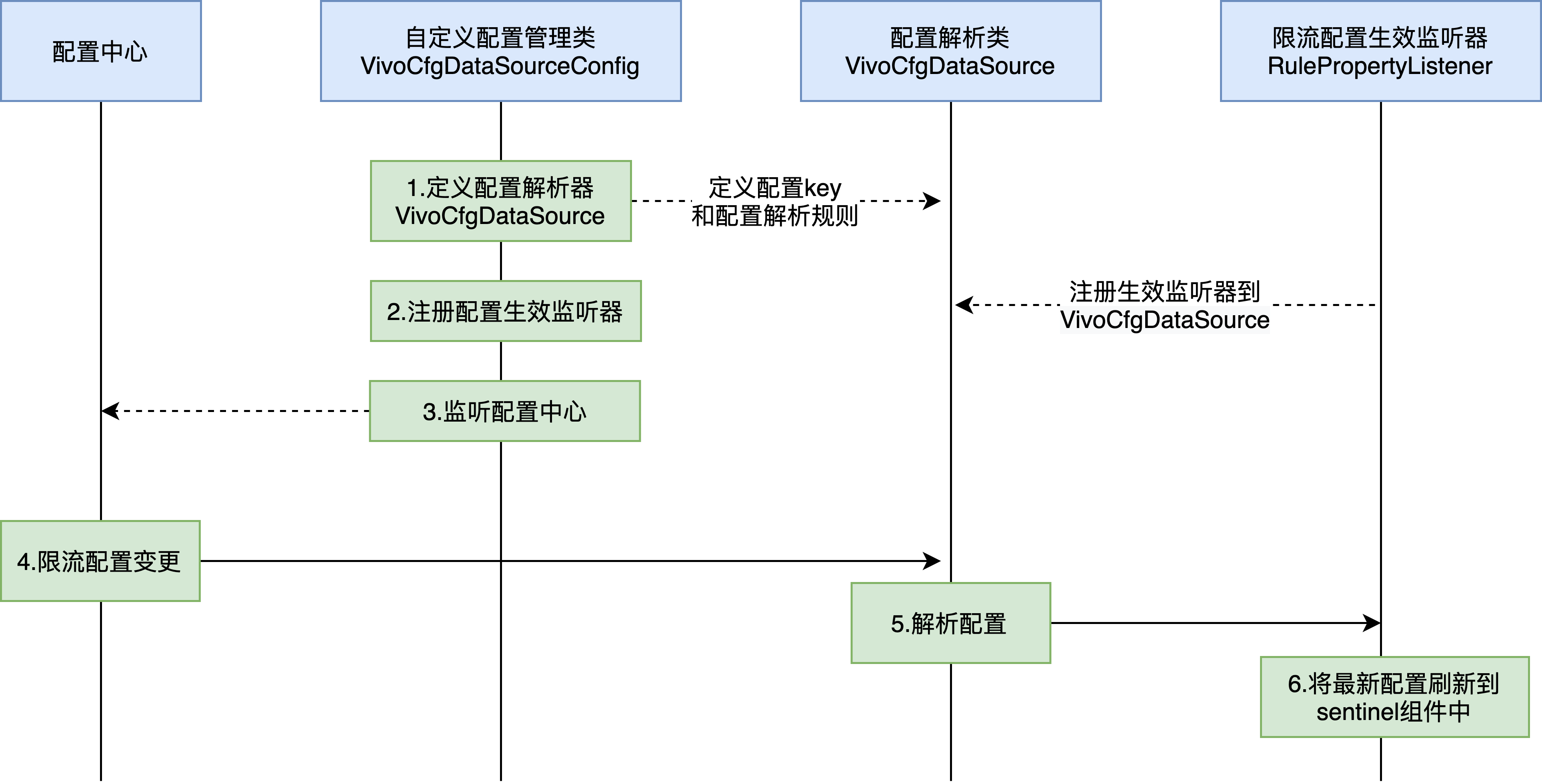
限流配置动态下发;
public class VivoCfgDataSourceConfig implements InitializingBean {
private static final String PARAM_FLOW_RULE_PREFIX = "sentinel.param.flow.rule";
@Override
public void afterPropertiesSet() {
// 定制配置解析对象
VivoCfgDataSource<List<ParamFlowRule>> paramFlowRuleVivoDataSource = new VivoCfgDataSource<>(PARAM_FLOW_RULE_PREFIX, sources -> sources.stream().map(source -> JSON.parseObject(source, ParamFlowRule.class)).collect(Collectors.toList()));
// 注册配置生效监听器
ParamFlowRuleManager.register2Property(paramFlowRuleVivoDataSource.getProperty());
// 初始化限流配置
paramFlowRuleVivoDataSource.init();
// 监听配置中心
VivoConfigManager.addListener(((item, type) -> {
if (item.getName().startsWith(PARAM_FLOW_RULE_PREFIX)) {
paramFlowRuleVivoDataSource.updateValue(item, type);
}
}));
}
}
2)原生sentinel指定限流热点参数的方式是两种:
第一种是指定接口方法的第n个参数;
第二种是方法参数继承ParamFlowArgument,实现ParamFlowKey方法,该方法返回值为热点参数value值。
这两种方式都不是特点灵活,第一种方式不支持指定对象属性;第二种方式需要我们改造代码,如果上线后某个接口参数没有继承ParamFlowArgument又想配置热点参数限流,那么只能通过改代码发版的方式解决了。因此我们对sentinel组件的热点参数限流源码做了些优化,增加「 指定参数对象的某个属性 」作为热点参数,并且支持对象层级的嵌套。很小的代码改动,却大大方便了热点参数的配置。
改造后的热点参数校验逻辑;
public static boolean passCheck(ResourceWrapper resourceWrapper, /*@Valid*/ ParamFlowRule rule, /*@Valid*/ int count,
Object... args) {
// 忽略部分代码
// Get parameter value. If value is null, then pass.
Object value = args[paramIdx];
if (value == null) {
return true;
}
// Assign value with the result of paramFlowKey method
if (value instanceof ParamFlowArgument) {
value = ((ParamFlowArgument) value).paramFlowKey();
}else{
// 根据classFieldName指定的热点参数获取热点参数值
if (StringUtil.isNotBlank(rule.getClassFieldName())){
// 反射获取参数对象中的classFieldName属性值
value = getParamFieldValue(value, rule.getClassFieldName());
}
}
// 忽略部分代码
}
三、MongoDB数据隔离
为什么要做数据隔离?这其中有两点原因,第一点:中台存储了前台不同业务的数据,在数据查询时各业务数据不能相互影响,不能A业务查询到B业务的数据。第二点:各业务的数据量级不同、对db操作的压力不同,如流量隔离中我们单独提供了一套服务集群给浏览器业务使用,那么浏览器业务使用的db同样需要单独配置一套,这样才能彻底和其他业务的服务压力隔离开。
vivo评论中台使用了MongoDB作为存储介质(关于数据库选型及Mongodb应用的细节有兴趣的同学可以看下我们之前的介绍《MongoDB 在评论中台的实践》),为了隔离不同业务方的数据,评论中台提供了两种数据隔离方案:物理隔离、逻辑隔离。
3.1 物理隔离
不同业务方的数据存储在不同的数据库集群中,这就需要我们系统支持MongoDB的多数据源。实现过程如下:
1) 寻找合适的切入点
通过分析spring-data-mongodb的执行过程的源码发现,在执行所有语句前都会去做一个getDB()获取数据库连接实例的动作,如下。
spring-data-mongodb db操作源码;
private <T> T executeFindOneInternal(CollectionCallback<DBObject> collectionCallback,
DbObjectCallback<T> objectCallback, String collectionName) {
try {
//关键代码getDb()
T result = objectCallback
.doWith(collectionCallback.doInCollection(getAndPrepareCollection(getDb(), collectionName)));
return result;
} catch (RuntimeException e) {
throw potentiallyConvertRuntimeException(e, exceptionTranslator);
}
}
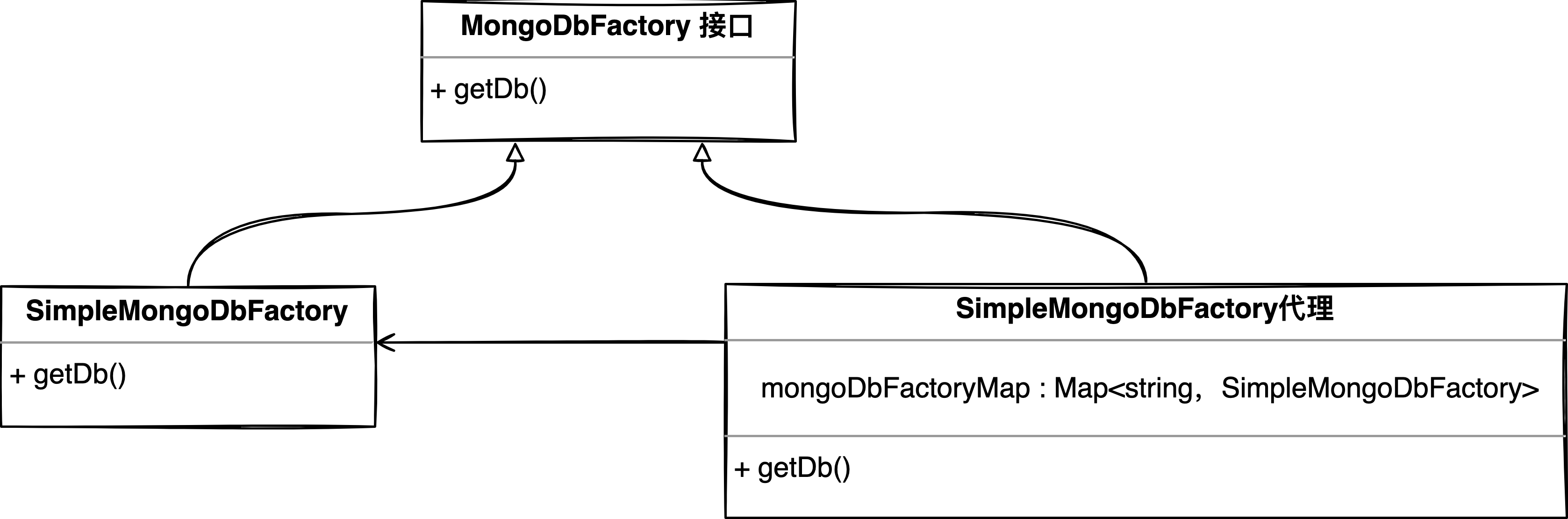
getDB()会执行org.springframework.data.mongodb.MongoDbFactory接口的getDb( )方法,默认情况下使用MongoDbFactory的SimpleMongoDbFactory实现,看到这里我们很自然的就能想到运用「代理模式」,用SimpleMongoDbFactory代理对象去替换SimpleMongoDbFactory,并在代理对象内部为每个MongoDB集配创建一个SimpleMongoDbFactory实例。
在执行db操作时执行代理对象的getDb( )操作,它只需要做两件事;
找到对应集群的SimpleMongoDbFactory对象
执行SimpleMongoDbFactory.getdb( )操作。
类关系图如下。
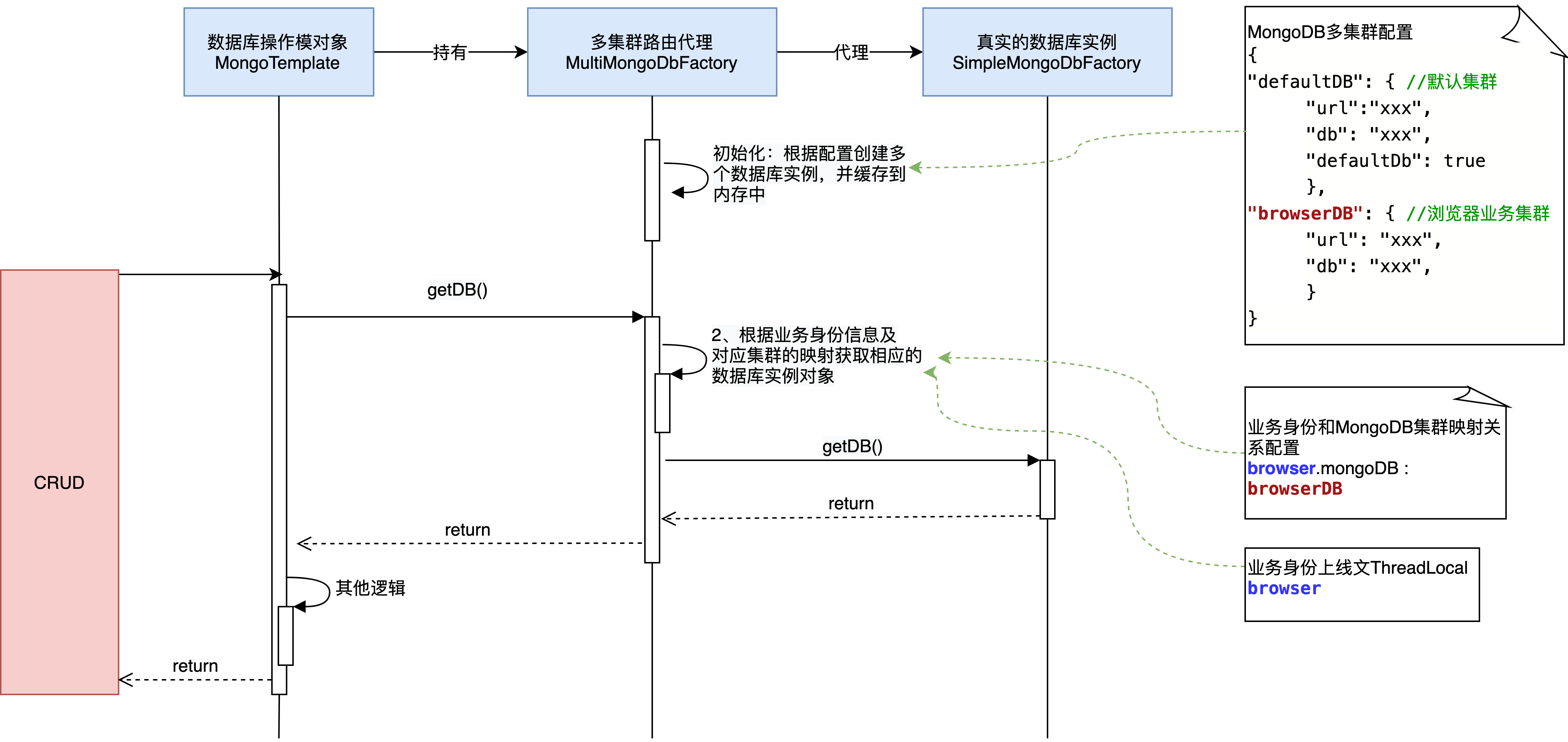
整体的执行过程如下:
3.1.2 核心代码实现
Dubbo filter获取业务身份并设置到上下文;
private boolean setCustomerCode(Object argument) {
// 从string类型参数中获取业务身份信息
if (argument instanceof String) {
if (!Pattern.matches("client.*", (String) argument)) {
return false;
}
// 设置业务身份信息到上下文中
CustomerThreadLocalUtil.setCustomerCode((String) argument);
return true;
} else {
// 从list类型中获取参数对象
if (argument instanceof List) {
List<?> listArg = (List<?>) argument;
if (CollectionUtils.isEmpty(listArg)) {
return false;
}
argument = ((List<?>) argument).get(0);
}
// 从object对象中获取业务身份信息
try {
Method method = argument.getClass().getMethod(GET_CLIENT_CODE_METHOD);
Object object = method.invoke(argument);
// 校验业务身份是否合法
ClientParamCheckService clientParamCheckService = ApplicationUtil.getBean(ClientParamCheckService.class);
clientParamCheckService.checkClientValid(String.valueOf(object));
// 设置业务身份信息到上下文中
CustomerThreadLocalUtil.setCustomerCode((String) object);
return true;
} catch (NoSuchMethodException | IllegalAccessException | InvocationTargetException e) {
log.debug("反射获取clientCode失败,入参为:{}", argument.getClass().getName(), e);
return false;
}
}
}
MongoDB集群的路由代理类;
public class MultiMongoDbFactory extends SimpleMongoDbFactory {
// 不同集群的数据库实例缓存:key为MongoDB集群配置名,value为对应业务的MongoDB集群实例
private final Map<String, SimpleMongoDbFactory> mongoDbFactoryMap = new ConcurrentHashMap<>();
// 添加创建好的MongoDB集群实例
public void addDb(String dbKey, SimpleMongoDbFactory mongoDbFactory) {
mongoDbFactoryMap.put(dbKey, mongoDbFactory);
}
@Override
public DB getDb() throws DataAccessException {
// 从上下文中获取前台业务编码
String customerCode = CustomerThreadLocalUtil.getCustomerCode();
// 获取该业务对应的MongoDB配置名
String dbKey = VivoConfigManager.get(ConfigKeyConstants.USER_DB_KEY_PREFIX + customerCode);
// 从连接缓存中获取对应的SimpleMongoDbFactory实例
if (dbKey != null && mongoDbFactoryMap.get(dbKey) != null) {
// 执行SimpleMongoDbFactory.getDb()操作
return mongoDbFactoryMap.get(dbKey).getDb();
}
return super.getDb();
}
}
自定义MongoDB操作模板;
@Bean
public MongoTemplate createIgnoreClass() {
// 生成MultiMongoDbFactory代理
MultiMongoDbFactory multiMongoDbFactory = multiMongoDbFactory();
if (multiMongoDbFactory == null) {
return null;
}
MappingMongoConverter converter = new MappingMongoConverter(new DefaultDbRefResolver(multiMongoDbFactory), new MongoMappingContext());
converter.setTypeMapper(new DefaultMongoTypeMapper(null));
// 使用multiMongoDbFactory代理生成MongoDB操作模板
return new MongoTemplate(multiMongoDbFactory, converter);
}
3.2 逻辑隔离
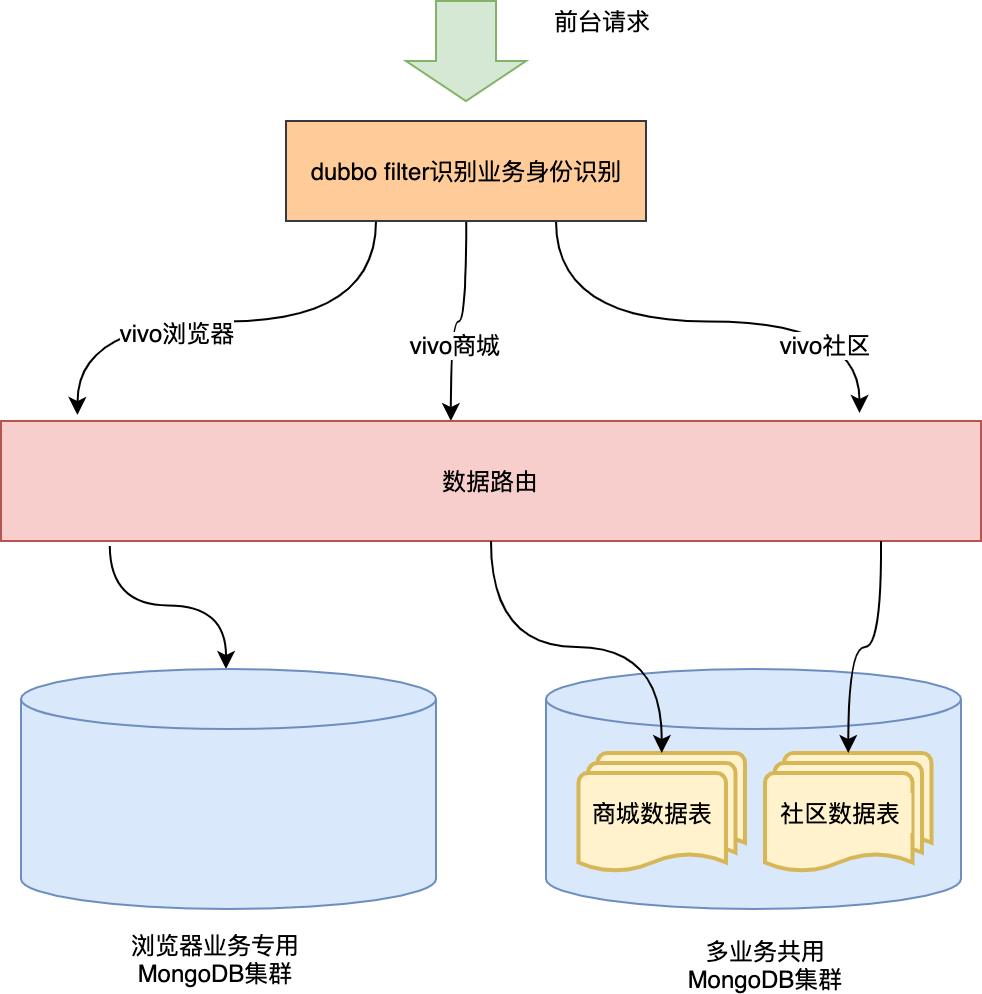
物理隔离是最彻底的数据隔离,但是我们不可能为每一个业务都去搭建一套独立的MongoDB集群。当多个业务共用一个数据库时,就需要做数据的逻辑隔离。
逻辑隔离一般分为两种:
一种是表隔离:不同业务方的数据存储在同一个数据库的不同表中,不同的业务操作不同的数据表。
一种是行隔离:不同业务方的数据存储在同一个表中,表中冗余业务方编码,在读取数据时通过业务编码过滤条件来实现隔离数据目的。
从实现成本及评论业务场景考虑,我们选择了表隔离的方式。实现过程如下:
1 )初始化数据表
每次有新业务对接时,我们都会为业务分配一个唯一的身份编码,我们直接使用该身份编码作为业务表表名的后缀,并初始化表,例如:商城评论表comment_info_vshop、社区评论表comment_info_community。
2) 自动寻表
直接利用spring-data-mongodb @Document注解支持Spel的能力,结合我们的业务身份信息上下文,实现自动寻表。
自动寻表
@Document(collection = "comment_info_#{T(com.vivo.internet.comment.common.utils.CustomerThreadLocalUtil).getCustomerCode()}")
public class Comment {
// 表字段忽略
}
两种隔离方式结合后的整体效果:
四、最后
通过上文的这些实践,我们很好的的支撑了不同量级的前台业务,并且做到了对业务代码无入侵,较好的解耦了技术和业务间的复杂度。另外我们对项目中使用到的Redis集群、ES集群对不同业务也做了隔离,大体思路和MongoDB的隔离类似,都是做一层代理,这里就不一一介绍了。
作者:vivo官网商城开发团队-Sun Daoming
vivo 评论中台的流量及数据隔离实践的更多相关文章
- MongoDB 在评论中台的实践
本文主要讲述 vivo 评论中台在数据库设计上的技术探索和实践. 一.业务背景 随着公司业务发展和用户规模的增多,很多项目都在打造自己的评论功能,而评论的业务形态基本类似.当时各项目都是各自设计实现, ...
- vivo 商品中台的可视化微前端实践
一.背景 在电商领域内,商品是一个重要组成部分,与其对应的商品管理系统,则负责商品的新建.编辑.复制等功能.随着商品管理系统的成熟稳定和业务上的扩展需求,催化出了商品中台的诞生.它可以将现有商品功能最 ...
- ThreadLocal 多线程并发,数据隔离
ThreadLocal: 创建一个线程本地变量. 本质:在ThreadLocal类中有一个Map,用于存储每一个线程的变量的副本. 优点:既实现多线程并发,游兼顾数据的安全性. 区别:Synchro ...
- Python_线程、线程效率测试、数据隔离测试、主线程和子线程
0.进程中的概念 三状态:就绪.运行.阻塞 就绪(Ready):当进程已分配到除CPU以外的所有必要资源,只要获得处理机便可立即执行,这时的进程状态成为就绪状态. 执行/运行(Running)状态:当 ...
- python开发 *进程数据隔离.守护进程,进程同步工具 * 180725
进程数据隔离.守护进程,进程同步工具 一.进程之间的数据隔离: from multiprocessing import Process n=100 #主程序中变量n= def func(): glob ...
- (25)线程---local数据隔离
线程之间本身是数据共享的,当多个线程同时修改一份数据的时候,数据就可能不 准确,特别是线程量特别大的时候,为了保证数据准确性: (1) 通过线程锁Lock (2)通过local数据隔离 from th ...
- 线程---local数据隔离
线程之间本身是数据共享的,当多个线程同时修改一份数据的时候,数据就可能不 准确,特别是线程量特别大的时候,为了保证数据准确性: (1) 通过线程锁Lock (2)通过local数据隔离 from th ...
- MSSQL · 最佳实践 · 利用文件组实现冷热数据隔离备份方案
文件组的基本知识点介绍完毕后,根据场景引入中的内容,我们将利用SQL Server文件组技术来实现冷热数据隔离备份的方案设计介绍如下. 设计分析 由于payment数据库过大,超过10TB,单次全量备 ...
- EEPlat PaaS中的多租户数据隔离模式
EEPlat PaaS支持三种租户的数据隔离技术:Sparce Column.tenantId字段隔离.每一个租户独立数据库. 1)Sparce Column,和Salesforce Appforce ...
随机推荐
- Codeforces 450C:Jzzhu and Chocolate(贪心)
C. Jzzhu and Chocolate time limit per test: 1 seconds memory limit per test: 256 megabytes input: st ...
- Go package(3):io包介绍和使用
IO 操作的基本分类 在计算机中,处理文件和网络通讯等,都需要进行 IO 操作,IO 即是 input/ouput,计算机的输入输出操作. Go语言中的 IO 操作封装在如下几个包中: io 为 IO ...
- <数据结构>BinarySearchTree的基本操作总结
目录 ADT 结构声明 核心操作集 各操作实现 Find(),Insert(),Delete() Traverse():前中后.层 ADT 结构声明 #include<stdio.h> # ...
- MySQL数据库安装Version5.7.25
1.说明 MySQL数据库大版本5.7的安装没有较大变化, 所以MySQL数据库Version5.7.25安装请参考:MySQL数据库安装Version5.7 上面文章中MySQL安装使用Versio ...
- Hangfire任务调度框架使用
1.HangFire简介 HangFire是一个免费简单实用的分布式后台定时调度服务,在现在.net开发中,人气算是很高的. HangFire提供了内置集成化的控制台,可以直观明了的查看作业调度情况, ...
- 一文让你明白Redis持久化(RDB、AOF)
为什么要持久化 Redis是内存数据库,如果不将内存中的数据库状态保存到磁盘中,那么一旦服务器进程退出,服务器的数据库状态就会消失(即断电即失).为了保证数据不丢失,我们需要将 内存中的数据存储到磁盘 ...
- 深入 Laravel 内核之 PHP 反射机制和依赖注入
结论: PHP中提供了反射类来解析类的结构: 通过反射类可以获取到类的构造函数及其参数和依赖: 给构造函数的参数递归设置默认值后,即可使用这些带默认值的参数通过 newInstanceArgs 实例化 ...
- TypeScript中文教程基础部分上----翻译自TS官方
为什么使用TS? js中每一个值在不同的操作运行中表现出一系列不同的行为,比如说下面这个例子: message.toLowerCase();message(); 逐行看下,第一行调用了message的 ...
- ConfigParser_读取配置文件信息
ConfigParse简介 ConfigParser 在python中是用来解析配置文件的内置模块,直接导入使用 import configparser 使用该模块可以对配置文件进行增.读.改.删操作 ...
- java mapreduce实现网站PV分析
原文链接: https://www.toutiao.com/i6765677128022229517/ PV 是Page Views的缩写,即页面浏览量,用户每一次对网站中的每个网页访问均被记录一次. ...