gc垃圾回收算法原理
三色标记法
以下是Golang GC算法的里程碑:
- v1.1 STW
- v1.3 Mark STW, Sweep 并行
- v1.5 三色标记法
- v1.8 hybrid write barrier(混合写屏障)
go的gc是基于 标记-清扫算法,并做了一定改进,减少了STW的时间。
标记-清扫(Mark And Sweep)算法
此算法主要有两个主要的步骤:
- 标记(Mark phase)
- 清除(Sweep phase)
第一步,找出不可达的对象,然后做上标记。
第二步,回收标记好的对象。
操作非常简单,但是有一点需要额外注意:mark and sweep算法在执行的时候,需要程序暂停!即 stop the world。
标记-清扫(Mark And Sweep)算法存在什么问题?
标记-清扫(Mark And Sweep)算法这种算法虽然非常的简单,但是还存在一些问题:
- STW,stop the world;让程序暂停,程序出现卡顿。
- 标记需要扫描整个heap
- 清除数据会产生heap碎片
这里面最重要的问题就是:mark-and-sweep 算法会暂停整个程序。
三色并发标记法
1.首先将程序创建的对象全部标记为白色
2.gc开始扫描,并将可达的对象标记为灰色
3.再从灰色对象中找到其引用的对象,将其标记为灰色,将自身标记成黑色
重复以上2、3步骤,直至没有灰色对象
4.对所有白色对象进行清除
gc和用户逻辑如何并行操作?
标记-清除(mark and sweep)算法的STW(stop the world)操作,就是runtime把所有的线程全部冻结掉,所有的线程全部冻结意味着用户逻辑是暂停的。这样所有的对象都不会被修改了,这时候去扫描是绝对安全的。
Go如何减短这个过程呢?标记-清除(mark and sweep)算法包含两部分逻辑:标记和清除。
我们知道Golang三色标记法中最后只剩下的黑白两种对象,黑色对象是程序恢复后接着使用的对象,如果不碰触黑色对象,只清除白色的对象,肯定不会影响程序逻辑。所以:清除操作和用户逻辑可以并发。
进程新生成对象的时候,GC该如何操作呢?不会乱吗?
Golang为了解决这个问题,引入了 写屏障这个机制。
写屏障:该屏障之前的写操作和之后的写操作相比,先被系统其它组件感知。
通俗的讲:就是在gc跑的过程中,可以监控对象的内存修改,并对对象进行重新标记。(实际上也是超短暂的stw,然后对对象进行标记)
在上述情况中,新生成的对象,一律都标位灰色!
那么,灰色或者黑色对象的引用改为白色对象的时候,Golang是该如何操作的?
看如下图,一个黑色对象引用了曾经标记的白色对象。
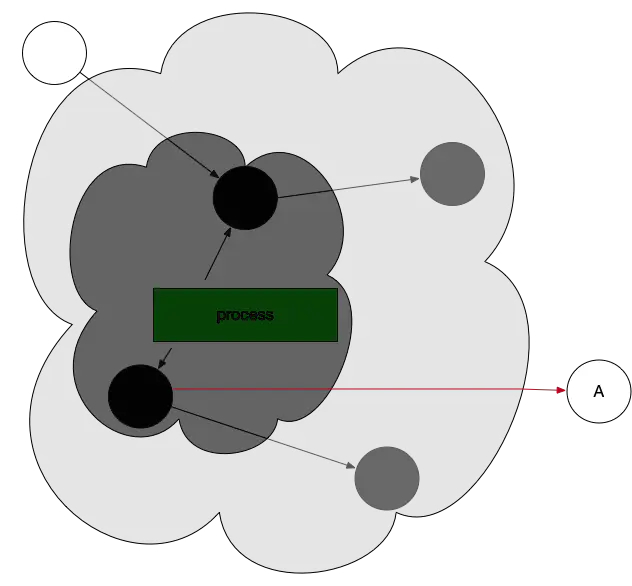
这时候,写屏障机制被触发,向GC发送信号,GC重新扫描对象并标位灰色。

因此,gc一旦开始,无论是创建对象还是对象的引用改变,都会先变为灰色。
堆栈
内存分配中的堆和栈
栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
堆栈缓存方式
栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放。
堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
申请到 栈内存 好处:函数返回直接释放,不会引起垃圾回收,对性能没有影响。
内存分配逃逸
所谓逃逸分析(Escape analysis)是指由编译器决定内存分配的位置,不需要程序员指定。
在函数中申请一个新的对象:
- 如果分配 在栈中,则函数执行结束可自动将内存回收;
- 如果分配在堆中,则函数执行结束可交给GC(垃圾回收)处理;
逃逸场景(什么情况才分配到堆中)
指针逃逸
package` `main` `type` `Student ``struct` `{`` ``Name string`` ``Age int``}` `func` `StudentRegister(name string, age int) *Student {`` ``s := new(Student) ``//局部变量s逃逸到堆` ` ``s.Name = name`` ``s.Age = age` ` ``return` `s``}` `func` `main() {`` ``StudentRegister(``"Jim"``, 18)``}
虽然 在函数 StudentRegister() 内部 s 为局部变量,其值通过函数返回值返回,s 本身为一指针,其指向的内存地址不会是栈而是堆,这就是典型的逃逸案例。
终端运行命令查看逃逸分析日志:
go build -gcflags=-m
输出
./main.go:16:6: can inline StudentRegister
./main.go:25:6: can inline main
./main.go:26:17: inlining call to StudentRegister
./main.go:16:22: leaking param: name
./main.go:17:10: new(Student) escapes to heap
./main.go:26:17: new(Student) does not escape
可见在StudentRegister()函数中,也即代码第10行显示”escapes to heap”,代表该行内存分配发生了逃逸现象。
栈空间不足逃逸(空间开辟过大)
package` `main` `func` `Slice() {`` ``s := make([]int, 1000, 1000)` ` ``for` `index, _ := ``range` `s {`` ``s[index] = index`` ``}``}` `func` `main() {`` ``Slice()``}
上面代码Slice()函数中分配了一个1000个长度的切片,是否逃逸取决于栈空间是否足够大。 直接查看编译提示,如下:
./main.go:20:6: can inline main
./main.go:13:11: make([]int, 1000, 1000) does not escape
所以只是1000的长度还不足以发生逃逸现象。然后就x10倍吧
./main.go:20:6: can inline main
./main.go:13:11: make([]int, 10000, 10000) escapes to heap
当切片长度扩大到10000时就会逃逸。
实际上当栈空间不足以存放当前对象时或无法判断当前切片长度时会将对象分配到堆中。
动态类型逃逸(不确定长度大小)
很多函数参数为interface类型,比如fmt.Println(a …interface{}),编译期间很难确定其参数的具体类型,也能产生逃逸。
如下代码所示:
package` `main` `import` `"fmt"` `func` `main() {`` ``s := ``"Escape"`` ``fmt.Println(s)``}
又或者像前面提到的例子:
func` `F() {`` ``a := make([]int, 0, 20) ``// 栈 空间小`` ``b := make([]int, 0, 20000) ``// 堆 空间过大 逃逸`` ` ` ``l := 20`` ``c := make([]int, 0, l) ``// 堆 动态分配不定空间 逃逸``}
闭包引用对象逃逸
Fibonacci数列的函数:
package` `main` `import` `"fmt"` `func` `Fibonacci() ``func``() int {`` ``a, b := 0, 1`` ``return` `func``() int {`` ``a, b = b, a+b`` ``return` `a`` ``}``}` `func` `main() {`` ``f := Fibonacci()` ` ``for` `i := 0; i < 10; i++ {`` ``fmt.Printf(``"Fibonacci: %d\n"``, f())`` ``}``}
Fibonacci()函数中原本属于局部变量的a和b由于闭包的引用,不得不将二者放到堆上,以致产生逃逸。
逃逸分析的作用是什么呢?
- 逃逸分析的好处是为了减少gc的压力,不逃逸的对象分配在栈上,当函数返回时就回收了资源,不需要gc标记清除。
- 逃逸分析完后可以确定哪些变量可以分配在栈上,栈的分配比堆快,性能好(逃逸的局部变量会在堆上分配 ,而没有发生逃逸的则有编译器在栈上分配)。
- 同步消除,如果你定义的对象的方法上有同步锁,但在运行时,却只有一个线程在访问,此时逃逸分析后的机器码,会去掉同步锁运行。
逃逸总结:
- 栈上分配内存比在堆中分配内存有更高的效率
- 栈上分配的内存不需要GC处理
- 堆上分配的内存使用完毕会交给GC处理
- 逃逸分析目的是决定内分配地址是栈还是堆
- 逃逸分析在编译阶段完成
函数传递指针真的比传值效率高吗?
传递指针相比值传递减少了底层拷贝,可以提高效率,但是拷贝的数据量较小,由于指针传递会产生逃逸,可能会使用堆,也可能增加gc的负担,所以指针传递不一定是高效的。
gc垃圾回收算法原理的更多相关文章
- GC垃圾回收算法
什么是GC垃圾回收呢.日常生活中我们去餐厅吃饭吃完饭,吃完饭走了餐具不用管,服务员在把餐具拿走,这是一种方式,服务员怎么知道他要来把餐具拿走呢,因为你走了,这个位置空了.服务员什么时候拿走餐具很重要, ...
- JAVA虚拟机垃圾回收算法原理
除了释放不再被引用的对象外,垃圾收集器还要处理堆碎块.新的对象分配了空间,不再被引用的对象被释放,所以堆内存的空闲位置介于活动的对象之间.请求分配新对象时可能不得不增大堆空间的大小,虽然可以使用的总空 ...
- Java GC 垃圾回收算法 内存分配
垃圾回收(Garbage Collection, GC)是Java不同于c与c++的重要特性之一. 他帮助Java自动清空堆中不再使用的对象. 由于不需要手动释放内存,程序员在编程中也可以减少犯错的机 ...
- 6.GC垃圾回收算法和垃圾收集器的关系
JAVAGC垃圾回收机制和常见垃圾回收算法 推荐博客:JVM垃圾回收机制和常见垃圾回收算法 JVM的内存结构.垃圾回收算法
- 关于GC垃圾回收的原理
.NET Framework 并不需要担心垃圾回收.但我们还是需要了解它的原理.才能让我们写出更高效的应用程序. .Net Framework 有一个GC(垃圾回收器),它会自动的帮我们把不需要的数据 ...
- GC: 垃圾回收算法
标记-清除算法标记-清除(Mark-Sweep)算法是最基础的算法,就如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象.之所以说 ...
- JVM中的垃圾回收算法GC
GC是分代收集算法:因为Young区,需要回收垃圾对象的次数操作频繁:Old区次数上较少收集:基本不动Perm区.每个区特点不一样,所以就没有通用的最好算法,只有合适的算法. GC的4大算法 1.引用 ...
- 小师妹学JVM之:GC的垃圾回收算法
目录 简介 对象的生命周期 垃圾回收算法 Mark and sweep Concurrent mark sweep (CMS) Serial garbage collection Parallel g ...
- go GC垃圾回收原理
目录 1.前言 2. 垃圾回收算法 3. Golang垃圾回收 3.1 垃圾回收原理 3.2 内存标记(Mark) 3.3 三色标记 3.4 Stop The World 4. 垃圾回收优化 4.1 ...
随机推荐
- deepin20使用snap并设置代理
snap下载 $ sudo apt update $ sudo apt install snapd https://snapcraft.io/docs/installing-snap-on-ubunt ...
- CMake语法—普通变量与子目录(Normal Variable And Subdirectory)
目录 CMake语法-普通变量与子目录(Normal Variable And Subdirectory) 1 CMake普通变量与子目录示例 1.1 代码目录结构 1.2 父目录CMakeLists ...
- java多态instanceof介绍
1 public static void method(Animal a) {//类型判断 2 a.eat(); 3 if(a instanceof Cat) {//instanceof:用于判断对象 ...
- Java中的方法内联
Java中的方法内联 1. 什么是方法内联 例如有下面的原始代码: static class B { int value; final int get() { return value; } } pu ...
- 学习JAVAWEB第十天
今天内容: 运行servlet到崩溃,一直是404 明天继续运行
- Typora + picgo + Chevereto 优雅地上传图片
需求:由于经常使用typora写文章,但是配合picgo使用的sm.ms图床,github图床等,速度不稳定,因此我们想要利用自己的服务器搭建自己的图床,将自己文章的图片上传到自己的服务器中,优雅地写 ...
- CSS之 sass、less、stylus 预处理器的使用方式
更详细区别参考文档:https://blog.csdn.net/pedrojuliet/article/details/72887490 使用变量: sass: 使用 $ 符号定义变量,如: $ba ...
- ApacheCN 机器学习译文集 20211111 更新
台湾大学林轩田机器学习笔记 机器学习基石 1 -- The Learning Problem 2 -- Learning to Answer Yes/No 3 -- Types of Learning ...
- python编写购物车
上次的学习又没有坚持下来,工作忙的不可开交,但我反思了一下还是自己没有下定决心好好学习,所以这次为期3个月的学习计划开始了,下面是这次学习后重新编写的购物车初版代码. 1 # 功能要求: 2 # 要求 ...
- Java Calendar类的使用总结【转】
感谢!原文地址:https://www.cnblogs.com/huangminwen/p/6041168.html Java Calendar类的使用总结 在实际项目当中,我们经常会涉及到对时间的处 ...