JIT in MegEngine
作者:王彪 | 旷视框架部异构计算组工程师
一、背景
什么是天元
旷视天元(MegEngine)是一个深度学习框架,它主要包含训练和推理两方面内容。训练侧一般使用 Python 搭建网络;而推理侧考虑到产品性能的因素,一般使用 C++ 语言集成天元框架。无论在训练侧还是推理侧,天元都担负着将训练和推理的代码运行到各种计算后端上的任务。目前天元支持的计算后端有 CPU、GPU、ARM 和一些领域专用的加速器,覆盖了云、端、芯等各个场景。
天元主要有三大特征:
1.训推一体,不管是训练任务还是推理任务都可以由天元一个框架来完成。
2.动静结合,天元同时支持动态图和静态图,并且动静之间的转换也非常方便。
3.多平台的高性能支持。
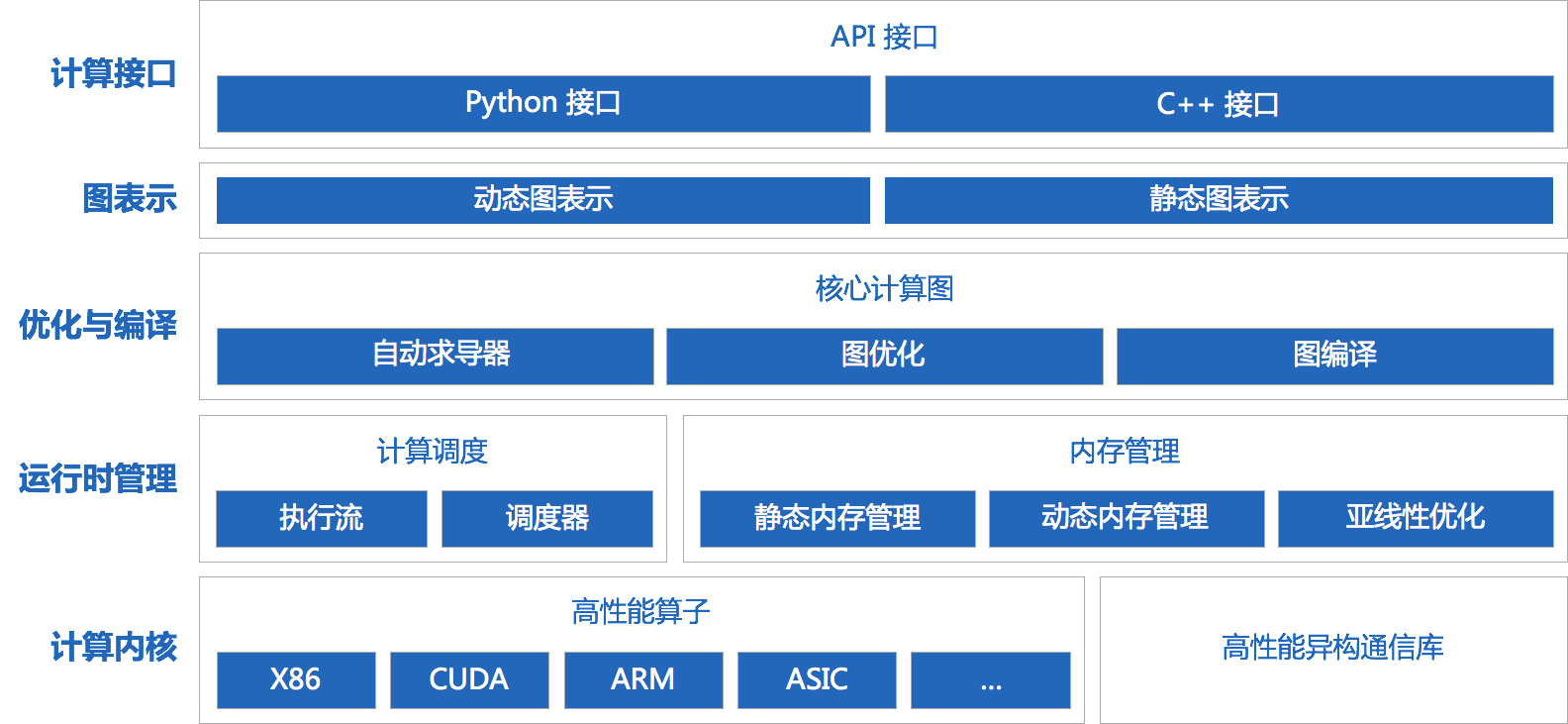
如图 1 所示,我们可以看到天元提供了 Python 和 C++ 两种接口。在图表示上分为动态图和静态图。运算层组件包括自动求导器、图优化和图编译等。天元的运行时模块包括内存管理和计算调度,其中内存管理包括静态内存管理和动态内存管理,以及亚线性内存优化技术。计算内核层包含了天元支持的所有计算后端,我们后续会开源出更多的计算后端。除此之外,天元还包含了一个高性能异构通信库,它一般会在多机多卡的场景下被用到。

动态图和静态图是相对的,在动态图下是没有计算图的概念的。但在静态图下,天元会维护一张计算图。如图 2 所示为天元中的计算图表示,图中圆形表示算子(operator),三角形表示输入。在天元框架中,动态图和静态图之间的转换只需要一条简单的语句即可完成,如下方代码所示:
if __name__ == '__main__’:
gm = ad.GradManager().attach(model.parameters())
opt = optim.SGD(model.parameters(), lr=0.0125, momentum=0.9, weight_decay=1e-4)
<em> # 通过 trace 转换为静态图</em>
@trace(symbolic=True)
def train():
with gm:
logits = model(image)
loss = F.loss.cross_entropy(logits, label)
gm.backward(loss)
opt.step()
opt.clear_grad()
return loss
loss = train()
loss.numpy()
什么是 AOT 和 JIT
AOT(Ahead Of Time) 和 JIT(Just In Time) 都是编译中的概念。以传统的 C/C++ 语言为例,我们写完代码之后,一般会通过编译器编译生成可执行文件,然后再执行该可执行文件获得执行结果。如果我们将从源代码编译生成可执行文件的过程称为 build 阶段,将执行可执行文件叫做 runtime 阶段的话,JIT 是没有build 阶段的,它只有 runtime 阶段。JIT 一般被用在解释执行的语言如 Python 中,JIT 会在代码执行的过程中检测热点函数,随后对热点函数进行重编译,下次运行时遇到热点函数则直接执行编译结果即可。这样做可以显著加快代码执行的速度。
什么是 MLIR
随着各种编程语言的出现,现代编译器也日趋多样化。特别是近年来随着深度学习的兴起,深度学习软件框架和 AI 领域专用硬件呈爆发式增长。不断增加的软件框架和 AI 硬件之间逐渐形成了一个越来越大的沟壑,如何将框架层对深度学习模型的描述精准高效的翻译成适应各类硬件的语言成为难点。MLIR(Multi-Level Intermediate Representation) 是一种可以在统一的基础架构下满足多样化需求的混合 IR。MLIR 可以满足包括但不限于以下的需求:
1.表达数据流图(如静态图模式下的 MegEngine Graph)
2.表达对该图做的优化和变换操作
3.进行各种算子优化如算子融合(kernel fusion)、循环融合、算子分块和内存格式(memory layout)转换等
4.自动代码生成、显式缓存管理、自动向量化
作为一个公用的 IR,MLIR 具有非常优秀的表达能力和可扩展性。MLIR 可以表达图层面的运算,同时可以表达传统编译器中的 IR 信息,也可以表示硬件专用的运算。这种不同属性,不同类型的运算的集合构成了 MLIR 中的方言(Dialect)。MLIR 还提供方便的机制实现不同方言之间的转换(Lowering Down),因此 MLIR 的一个通用优化将会在多个方面产生收益。接入 MLIR 也将有更大可能享受到它的生态好处,包括性能和扩展性等方面。
二、动机
为什么做
众所周知,深度学习模型中有很多 element-wise 操作,例如加减乘除算术运算和神经网络中的激活函数一般都是 element-wise 操作。天元将 element-wise 操作分为一元操作、二元操作和多元操作。一元操作主要有 RELU、ABS、SIN 和 COS 等等;二元操作有加法、减法、乘法和除法以及 MAX 等;多元操作有 FUSE-MUL-ADD3 和 FUSE-MUL-ADD4 等,它们分别计算的是 “ab+c” 以及 “ab+c*d”。
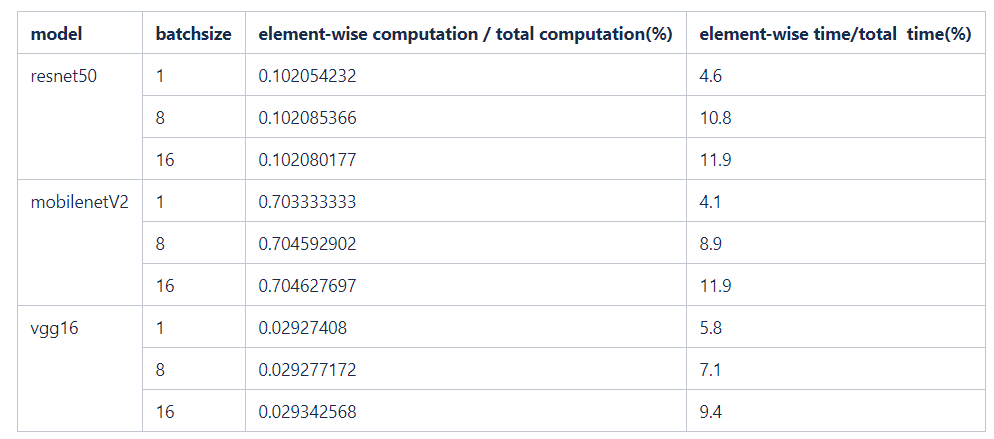
element-wise 操作在卷积神经网络中所占的地位不可忽视。如表 1 所示,我们选择公开的卷积神经网络训练模型,以纯 device kernel 的执行时间为基准统计卷积神经网络中element-wise 操作的重要性。
首先可以清晰的看到,element-wise 的计算量的占比相比于运行时间占比要低 1-2 个数量级。它的计算量占的非常少,但是它的运行时间占比非常多,这个结论是比较反直觉的。并且随着 batch size 的增加,这个现象也越来越明显。这是因为 element-wise 操作计算量较低但是访存量较高,即计算访存比较低,是一种典型的访存受限 (memory bound) 的操作。以 “a+b” 为例,我们首先要将 a 读到内存中,再将 b 读到内存中,做完一次加法之后,我们将结果 c 再写到内存中。整个过程要经过两次读和一次写才能完成一次计算,所以它的计算反应访存比非常低。针对访存受限的操作,优化计算时间实际上是没有没有太多的意义的,而应该集中精力优化访存,访存优化的常见的优化手段是融合 (fusion)。如果我们能将网络中连在一起的 element-wise 操作融合成一个算子,则将减少 element-wise 操作的访存量,增加计算访存比从而加速网络的整体性能。
为什么用 JIT 做
卷积神经网络有两个鲜明的特征。一个是静态图模式下的模型训练过程中模型的结构一般是不会变的跑;另一个是在模型训练的过程中,一般会经过很多个 iter/min-batch,不同的 iter/min-batch 之间输入张量形状(tensor shape)一般也不会变。基于卷积神经网络的这两个特征,我们决定应用 JIT 技术,原因如下:
1.只需要在首次运行的时候编译一次,随后的不同 iter/mini-batch 可以重用第一次编译出来的结果。
2.JIT 具有较强的可移植性,因为它在运行时获取平台信息,然后生成可以在该平台运行的代码。
3.JIT 可以解决 element-wise 模式组合爆炸的问题。
三、技术方案
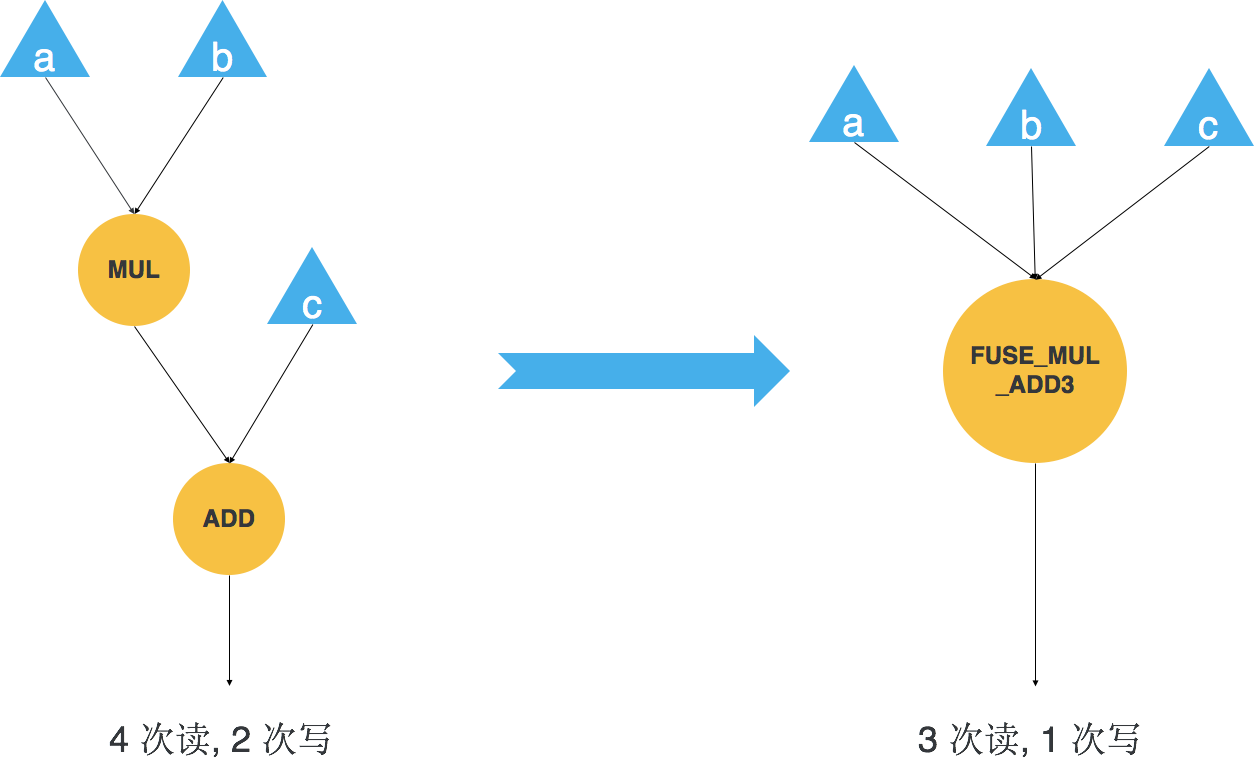
我们通过 Element-wise Fusion 可以把多个 element-wise 操作融合成一个,减少了算子数量也就减少了算子之间的读写次数。如图 3 所示计算图算的是 “a*b+c”,它需要 4 次读,2 次写。4 次读分别是乘法在读 a 和 b 两个输入,乘法其实还要写一个隐藏的输出,加法会读乘法的输出作为输入,以及加法读 c 作为输入。两次写分别是乘法和加法对它们结果的两次写操作,总共加起来是 4 次读,2 次写。
我们将其融合成一个算子 FUSE_MUL_ADD3,由于天元现在已经支持 FUSE_MUL_ADD3 这个 element-wise 模式,所以我们可以直接做模型手术将计算图从图 3 左侧形式转到图 3 右侧形式。对于融合之后的计算图,我们只需要 3 次读和 1 次写就可以完成等价计算,相比于融合前减少了 1 次读和 1 次写操作。
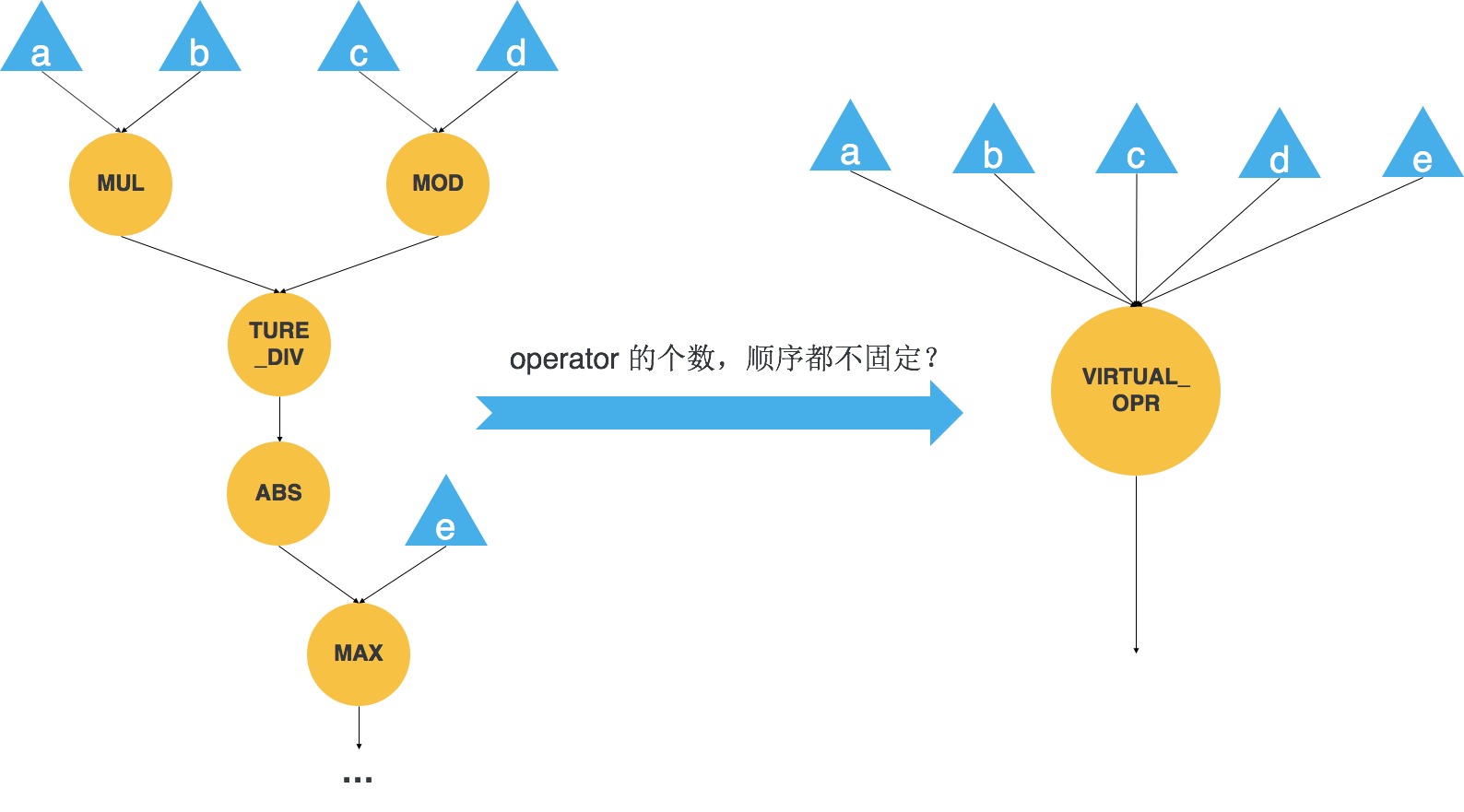
我们无法预测用户将搭出来怎样的一张计算图,考虑图 4 所示的计算图,其中 element-wise 的个数和顺序都不固定,显然我们不可能提前将各种 element-wise 模式的组合都写进天元的。在这种情况下,天元会创建一个虚拟的算子来表示整个可被融合的子图。有了虚拟算子的存在,接下来我们还要解决两个问题,一个是用虚拟算子替换原始计算图中可以被融合的子图,这个工作会在图优化阶段做;另一个是我们要动态生成虚拟算子的代码并执行。如果我们解决了这两个问题,我们就解决了整个问题。
图优化
为了将一张计算图中的可被融合的子图融合成一个算子,天元将进行检测(detection)和融合(fusion)两步操作,如下步骤 1-3 属于检测,步骤 4 则属于融合:
1.对原始计算图进行检测后生成 internal graph generator,一个 internal graph generator 对应一个唯一的子图
2.internal graph generator 稍后会生成 internal graph
3.由 internal graph 创建 JITExcutor 算子
4.将 JITExcutor 写回原始的计算图
检测
检测算法的主要功能是找出可以被融合的子图。为了方便描述,设 G 是计算图,opr 是图 G 中的算子,var 是 opr 的输入和输出。检测算法的输入是原始的计算图 G,输出是一个哈希表 M,表中存放的是检测出的可被融合子图的输出 var(记作 endpoint)与其对应的 internal graph generator。算法步骤如下:
1.按照逆拓扑序列遍历图 G 中的算子 opr
2.如果 opr 不是 Elemwise/PowC/TypeCvt/Reduce/Dimshuffle/JITExecutor,返回步骤1
3.如果 opr 的 input/output 数据类型不是 float32/float16,返回步骤1
4.process_opr(opr)
5.转到步骤 1

拓扑序列要求所有的父节点要先于它的子节点被访问到,与之对应的,逆拓扑序列就是所有的子节点要先于它的父节点被访问到。算法第 1 步中我们之所以按照逆拓扑序列遍历计算图,是因为要保证遍历到某个 opr 时,它的子节点都已经被遍历到了。这样算法可以查看该 opr 的所有的子节点是不是都在同一张子图中,如果是,那么当前 opr 就有很大的可能也在该子图中。算法的第 2 步和第 3 步实际上说明了天元中的 JIT 的限制。目前天元 JIT 仅支持 Elemwise/PowC/TypeCvt/Reduce/Dimshuffle 这几种 opr,而且只支持输入输出是 float32/float16 的数据类型。第 4 步详细流程如图 5 所示。需要注意的是算法会经过如下三个判断语句:
1.该 opr 的子节点是不是都已经在当前的这张子图中了?
2.该 opr 的输出的计算节点(compute node)是不是跟子图匹配?天元支持跨计算节点的计算图,例如计算图中一些 opr 可以运行在 CPU 上,一些 opr 可以运行在 GPU上。但目前天元不支持跨计算节点融合。
3.该 opr 的输出的 shape 是不是跟子图匹配?因为最终生成的代码本质上是一个大的循环,循环的维度就是 opr 输出的 shape,所以如果 shape 不匹配是不能被融合的。

图 6 中虚线框出来的即为检测算法检测出的两个可被融合的子图。
融合
融合算法的主要功能是将检测出来的子图融合成一个算子。融合算法的输入是原始的计算图和检测算法输出的那张哈希表 M,它的输出是经过融合的计算图 G‘。算法流程如下:
1.按照拓扑序列遍历图 G 中的算子 opr
2.若 opr 的输入 var 不是 endpoint, 返回步骤 1
3.从 M 中拿到 var 对应的 internal graph generator, 生成 internal graph
4.从 internal graph 创建 JITExecutor
5.写回原始的计算图 G
6.转到步骤 1 步骤 2 中如果一个 opr 的输入 var 不是 endpoint 则表示它是一个子图中的中间节点而不是子图的输出节点。步骤 3 中从 internal graph generator 到 internal graph 需要将子图的输入 var 替换为一个新的 opr JITPlaceholder。JITPlaceholder 中会存诸如子图的输入顺序这些额外信息,因为某些 element-wise 操作是对输入顺序敏感的。例如 a 对 b 取余和 b 对 a 取余显然具有不同的语义。
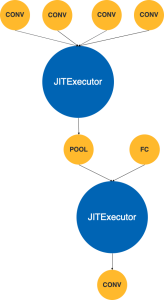
图 7 即为经过融合算法之后的计算图,截止到目前为止,我们已经完成了图优化方面的所有工作。
图编译
经过图优化之后,我们成功的将计算图中可被融合的子图融合成为一个新的算子,剩下的工作就是为这个新的算子生成代码了。JITExecutor 算子的运行时代码非常简单,先判断一下当前的可执行对象是不是已经存在,如果不存在则先编译出一个可执行对象,如已存在则直接运行。这段代码在运行时才会被执行到,所以称之为 JIT。当前天元支持三种 JIT 编译器后端,分别是 NVRTC(支持英伟达 GPU),Halide 和 MLIR。其中后两个编译后端支持的平台众多,但是 MLIR 具有更优秀的表达能力和扩展性,所以我们接下来以 MLIR 为例介绍代码生成、编译和执行的过程。
要想使用 MLIR 作为编译后端,首先我们需要定义和实现天元自己的方言(MGE Dialect),随后我们将 MGE Dialect 转换到 MLIR 既有的 Dialect 上,接下来的绝大部分工作都可以复用 MLIR 中的基础组件和工具完成。图 8 描述了 CPU 和 GPU 上大概的执行流程。
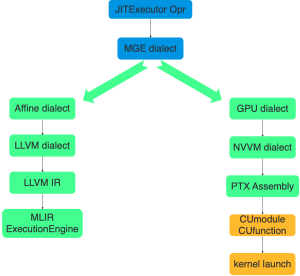
天元首先将 JITExecutor 算子内部的 internal graph 翻译成 MGE Dialect。在 CPU 上,MGE Dialect 会先 Lowering 到 Affine Dialect 上,然后会通过 LLVM 的组件 Lowering 到 LLVM Dialect 上,LLVM Dialect 可以被直接翻译成 LLVM IR。在这一步之后,其他优化工作都可以直接复用 LLVM 的基础组件。最后天元使用 MLIR ExecutionEngine 执行 LLVM IR 生成的代码。在 GPU 上,天元会先将 MGE Dialect Lowering 到 GPU Dialect上,随后 Lowering 到 NVVM Dialect,NVVM 会被翻译成 PTX 汇编。最后通过英伟达提供的 CUmodule 和 CUfunction 两个机制运行。
四、实验和分析
首先参考这篇文档 在天元中开启 JIT 支持。本次实验选了 resnet50, mobilenetV2 和 vgg16 三个业界广泛使用的模型,batch size 分别设置了 1, 8 和 16。测试硬件环境为 NVIDIA T4,软件环境为 MegEngine v1.2.0。
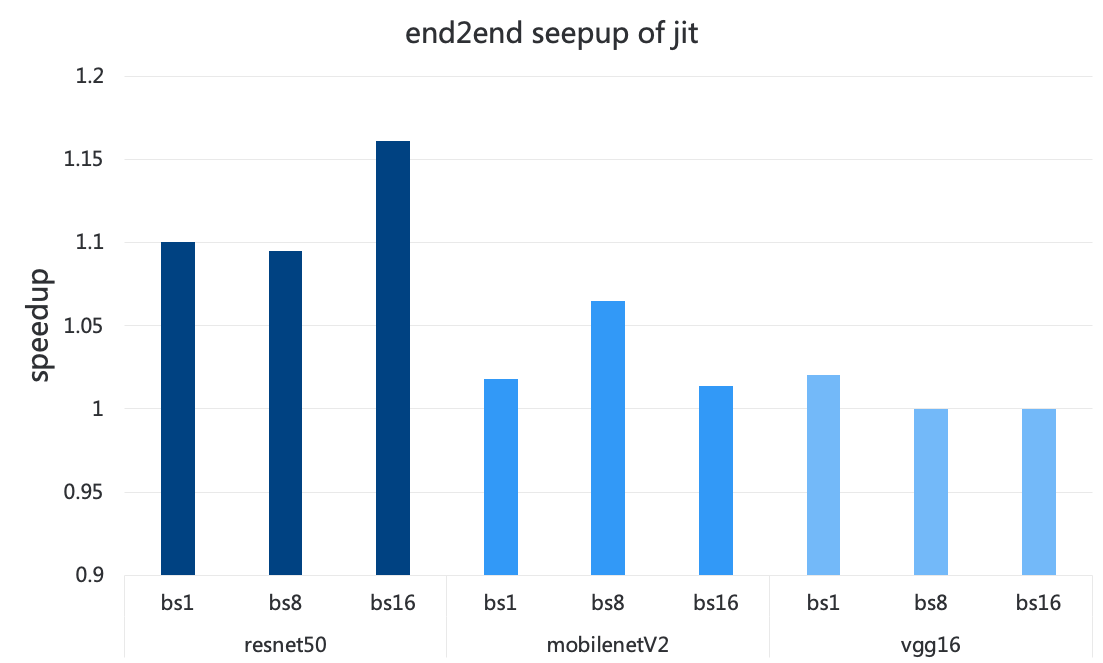
由图 9 可知,和不打开 JIT 支持相比,打开 JIT 支持后 resnet50 最高可以获得 16% 的加速比,mobilenet V2 则能获得 6% 到 7% 的加速比,而 vgg16 其实上没有明显加速效果。这是因为 vgg16 模型很大,可以被优化的 element-wise 操作比较少。JIT 的优化效果跟具体的模型是有紧密关系的。
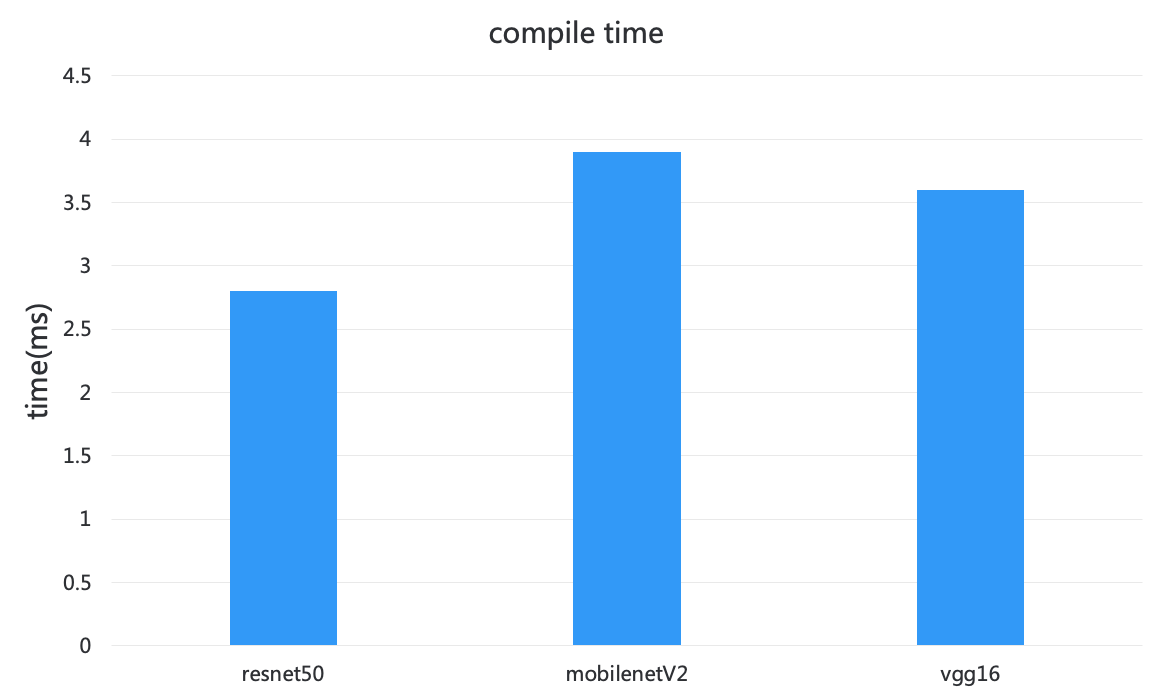
如果打开了 JIT 支持,那么天元首次运行的时候会有一次 JIT 编译的过程。JIT 编译耗时跟具体的编译的后端以及模型有关,如图 10 所示 resnet50 耗时 2.7 毫秒,mobilenetV2 耗时 3.9 毫秒。
五、总结和展望
本篇文章介绍了天元使用 JIT 实现将任意多个相邻的 element-wise 算子融合成一个算子的优化。我们在 T4 上用 MegEngine v1.2.0 实验,相比于优化前,resnet 50 最高可以获得 16% 的加速比。
以此为基,展望未来我们可能做的事情如下:
1.将 JIT 编译的结果先离线保存,线上直接将线下编译好的可执行对象读进内存。这种做法可以解决线上第一次运行慢的问题,但它可能会损失一部分可移植性,因为在一种设备上编译产生的可执行对象一般不能适配所有线上设备。 2.JIT 支持更多的算子。 3.JIT支持更多的数据类型,天元 JIT 优化暂时只支持 float32/float16 这两种数据类型。 4.动态图 JIT,也就是传统意义上的检测热点代码,重编译后再执行。
JIT in MegEngine的更多相关文章
- MegEngine计算图、MatMul优化解析
MegEngine计算图.MatMul优化解析 本文针对天元在推理优化过程中所涉及的计算图优化与 MatMul 优化进行深度解读,希望能够帮助广大开发者在利用天元 MegEngine「深度学习,简单开 ...
- MegEngine 框架设计
MegEngine 框架设计 MegEngine 技术负责人许欣然将带了解一个深度学习框架是如何把网络的定义逐步优化并最终执行的,从框架开发者的视角来看待深度学习. 背景 AI 浪潮一波又一波,仿佛不 ...
- MegEngine亚线性显存优化
MegEngine亚线性显存优化 MegEngine经过工程扩展和优化,发展出一套行之有效的加强版亚线性显存优化技术,既可在计算存储资源受限的条件下,轻松训练更深的模型,又可使用更大batch siz ...
- Megengine量化
Megengine量化 量化指的是将浮点数模型(一般是32位浮点数)的权重或激活值用位数更少的数值类型(比如8位整数.16位浮点数)来近似表示的过程. 量化后的模型会占用更小的存储空间,还能够利用许多 ...
- Mono 3.2.7发布,JIT和GC进一步改进
Mono 3.2.7已经发布,带来了很多新特性,如改进的JIT.新的面向LINQ的解释器以及使用了64位原生指令等等. 这是一次主要特性发布,累积了大约5个月的开发工作.看上去大部分改进都是底层的性能 ...
- 谁偷了我的热更新?Mono,JIT,iOS
前言 由于匹夫本人是做游戏开发工作的,所以平时也会加一些玩家的群.而一些困扰玩家的问题,同样也困扰着我们这些手机游戏开发者.这不最近匹夫看自己加的一些群,常常会有人问为啥这个游戏一更新就要重新下载,而 ...
- 谈谈JIT编译器和本机影像生成器(NGen.exe)
前言 在看<CLR>的时候,作者在开篇的时候提到了NGen.exe,前面一节执行程序集的代码中提到:程序或方法执行前会执行MSCorEE.dll中的JIT函数把要执行方法的IL转换成本地的 ...
- .Net JIT
.Net JIT(转) JIT
- 【Java】实战Java虚拟机之五“开启JIT编译”
今天开始实战Java虚拟机之五“开启JIT编译” 总计有5个系列 实战Java虚拟机之一“堆溢出处理” 实战Java虚拟机之二“虚拟机的工作模式” 实战Java虚拟机之三“G1的新生代GC” 实战Ja ...
随机推荐
- 03 Git 以及 其 GUI TortoiseGit 的下载与安装
前面也说过嘛,要紧跟大佬们的步伐--选择最受欢迎的版本控制系统. 而根据 [JetBrains](JetBrains: Essential tools for software developers ...
- python3实现几种常见的排序算法
python3实现几种常见的排序算法 冒泡排序 冒泡排序是一种简单的排序算法.它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来.走访数列的工作是重复地进行直到没有再需要 ...
- 生产环境部署Django项目
生产环境部署Django项目 1. 部署架构 IP地址 安装服务 172.16.1.251 nginx uwsgi(sock方式) docker mysql5.7 redis5 Nginx 前端We ...
- CentOS-磁盘扩容挂载目录
挂载 查看存储情况 $ df -kh 查看磁盘情况 $ fdisk -l fdisk创建分区(注:可操作存储上限为2TB)$ fdisk /dev/sdb根据提示,依次输入"n", ...
- Linux:CentOS7防火墙 开放端口配置
查看已开放的端口 firewall-cmd --list-ports 开放端口(开放后需要要重启防火墙才生效) firewall-cmd --zone=public --add-port=3338/t ...
- Linux导出未越狱Iphone10.3-QQ聊天记录
起因 手机当中的聊天记录已经快两年没有备份了,生怕某天QQ版本升级中丢失掉这些聊天记录,所想将这两年的聊天记录保存下来 查找了好多资料,结果10.3以后,IOS改变了策略,貌似不允许通过以前方法导出了 ...
- Linux守护进程列表/守护进程
在linux或者unix操作系统中在系统引导的时候会开启很多服务,这些服务就叫做守护进程.为了增加灵活性,root可以选择系统开启的模式,这些模式叫做运行级别,每一种运行级别以一定的方式配置系统. ...
- 什么是BSE
BSE (bridge system engineer) 是外包开发人员和客户之前的桥梁. 主要是将客户的需求准确的理解并传达给外包的开发人员,一般情况下也兼开发的 leader 工作. 参考: ht ...
- ARTS起始篇
ARTS简要说明(每周需要完成以下四项): Algorithm:每周至少做一道 leetcode 的算法题,编程训练.刻意练习. Review:需要阅读并点评至少一篇英文技术文章,这个是四项里面对我最 ...
- [刘阳Java]_Spring IoC原理_第2讲
Spring IoC(DI)是Spring框架的核心,所有对象的生命周期都是由它们来管理.对于弄懂Spring IOC是相当关键,往往我们第一次接触Spring IOC大家都是一头雾水.当然我们这篇文 ...