Yarn 集群环境 HA 搭建
环境准备
确保主机搭建 HDFS HA 运行环境
步骤一:修改 mapred-site.xml 配置文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop/
[root@node-01 hadoop]# vim mapred-site.xml
<configuration>
<!-- 配置MapReduce程序运行模式 为 yarn(不配置默认为 local 模式) -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 设置 hadoop 路径 -->
<property>
<name>mapreduce.application.classpath</name>
<value>/root/apps/hadoop-3.2.1/etc/hadoop:/root/apps/hadoop-3.2.1/share/hadoop/common/lib/*:/root/apps/hadoop-3.2.1/share/hadoop/common/*:/root/apps/hadoop-3.2.1/share/hadoop/hdfs:/root/apps/hadoop-3.2.1/share/hadoop/hdfs/lib/*:/root/apps/hadoop-3.2.1/share/hadoop/hdfs/*:/root/apps/hadoop-3.2.1/share/hadoop/mapreduce/lib/*:/root/apps/hadoop-3.2.1/share/hadoop/mapreduce/*:/root/apps/hadoop-3.2.1/share/hadoop/yarn:/root/apps/hadoop-3.2.1/share/hadoop/yarn/lib/*:/root/apps/hadoop-3.2.1/share/hadoop/yarn/*</value>
</property>
</configuration>
步骤二:修改yarn-env.sh 配置文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop
[root@node-01 hadoop]# echo 'export JAVA_HOME=${JAVA_HOME}' >> yarn-env.sh
步骤三:修改 yarn-site.xml 配置文件
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop/
[root@node-01 hadoop]# vim yarn-site.xml
<configuration>
<!-- 配置 NodeManager上运行的附属服务(指定 MapReduce 中 reduce 读取数据方式) -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置 yarn 集群标识 id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarncluster</value>
</property>
<!-- 启用 yarn HA(高可用) -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 配置 resourcemanager 逻辑 ids 名称-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置 resourcemanager1 启动主机名-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node-01</value>
</property>
<!-- 配置 resourcemanager2 启动主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node-02</value>
</property>
<!-- 配置 resourcemanager1 web 浏览器地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node-01:8088</value>
</property>
<!-- 配置 resourcemanager2 web 浏览器地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node-02:8088</value>
</property>
<!--配置 zk 集群地址-->
<property>
<name>hadoop.zk.address</name>
<value>node-01:2181,node-02:2181,node-03:2181</value>
</property>
<!-- 启用 resourcemanager 重启自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 有三种StateStore,分别是基于 zookeeper, HDFS, leveldb, HA 高可用集群必须用 ZKRMStateStore -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 配置自动检测硬件(默认关闭) -->
<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>
<!-- 配置 nodemanager 启动要求的最低配置-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
步骤四:scp 这个 yarn-site.xml 到其他节点
[root@node-01 ~]# cd /root/apps/hadoop-3.2.1/etc/hadoop/
[root@node-01 ~]# scp mapred-site.xml node-02:$PWD
[root@node-01 ~]# scp mapred-site.xml node-03:$PWD
[root@node-01 ~]# scp yarn-env.sh node-02:$PWD
[root@node-01 ~]# scp yarn-env.sh node-03:$PWD
[root@node-01 ~]# scp yarn-site.xml node-02:$PWD
[root@node-01 ~]# scp yarn-site.xml node-03:$PWD
步骤五:启动 yarn 集群
[root@node-01 ~]# start-yarn.sh
stop-yarn.sh :停止 yarn 集群
步骤六:用 jps 检查 yarn 的进程
[root@node-01 ~]# jps
16800 ResourceManager
12050 NameNode
11878 JournalNode
12362 DFSZKFailoverController
11739 QuorumPeerMain
16941 NodeManager
12174 DataNode
[root@node-02 ~]# jps
11616 JournalNode
13492 ResourceManager
11926 DataNode
11803 NameNode
11452 QuorumPeerMain
12046 DFSZKFailoverController
# 手动启动 node-02 和 node-03 nodemanger 进程
[root@node-02 ~]# yarn --daemon start nodemanager
[root@node-03 ~]# yarn --daemon start nodemanager
yarn --daemon stop nodemanager 停止nodemanger进程
步骤七:用 web 浏览器查看 yarn 的网页
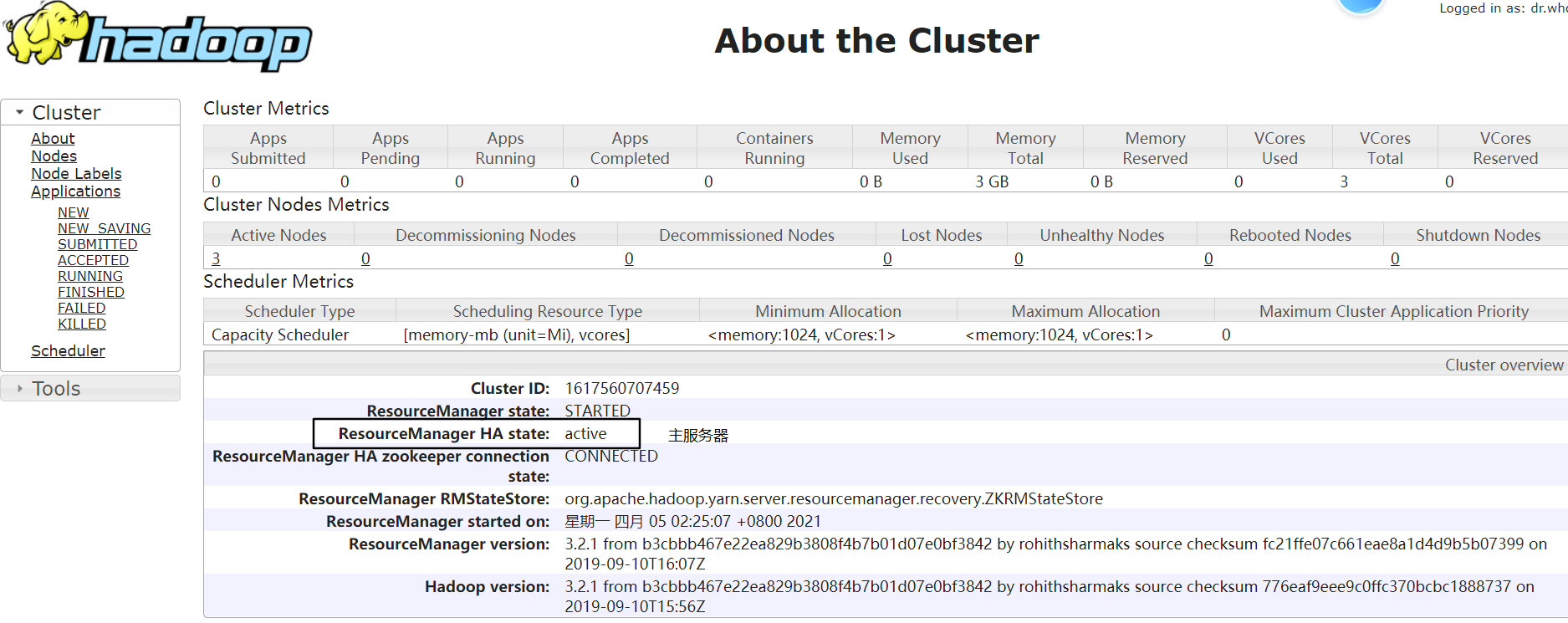
node-01:http://192.168.229.21:8088/cluster/cluster
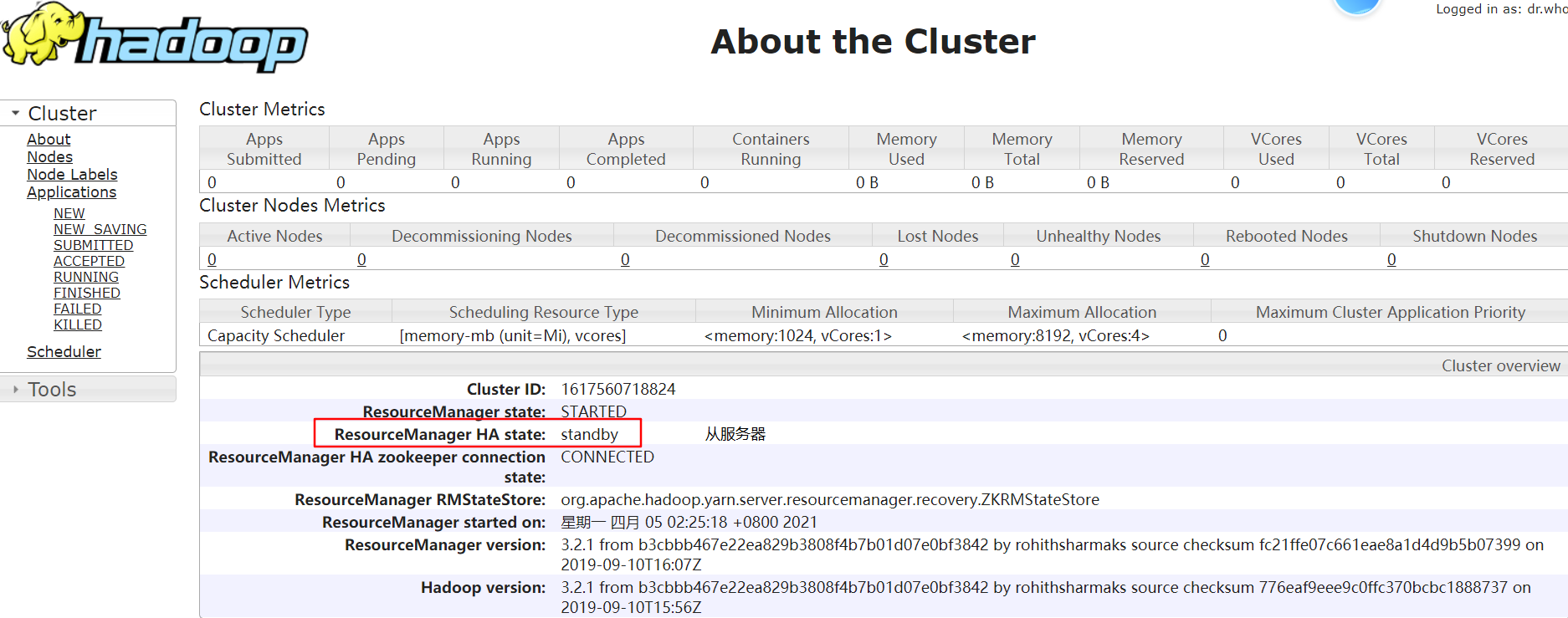
node-02:http://192.168.229.22:8088/cluster/cluster
步骤八:测试 ResourceManager 故障转移
# node-02 上关闭 resourcemanager 进程
[root@node-02 logs]# yarn --daemon stop resourcemanager
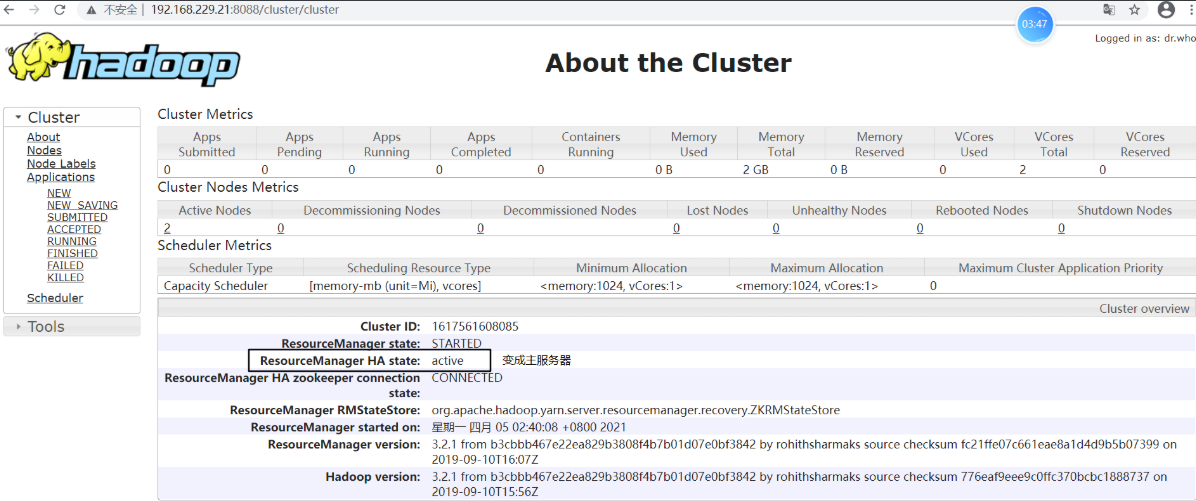
查看 node-01:http://192.168.229.21:8088/cluster/cluster,发现状态由 standby 变为 active,说明已经进行故障转移
将 node-02 上 resourcemanager 进程再次启动
[root@node-02 logs]# yarn --daemon start resourcemanager
这时,node-02 上的 resourcemanager 则变为 standby 状态,故障转移测试完成:)
步骤九:测试 Yarn 集群运行 wordcount 程序
将 wordcount 程序进行 Jar 打包并上传,执行 wordcount 程序
执行 MapReduce 程序命令格式:hadoop jar xxxx.jar 类全名(main 方法的类名和包名)
[root@node-01 ~]# ll
总用量 138368
drwxr-xr-x. 5 root root 69 4月 4 23:36 apps
-rw-r--r--. 1 root root 6870038 4月 8 13:12 MapReduceDemo-1.0-SNAPSHOT.jar
[root@node-01 hadoop]# hadoop jar MapReduceDemo-1.0-SNAPSHOT.jar wordcount.JobSubmitterLinuxToYarn
2021-04-08 20:00:17,739 INFO mapreduce.Job: Job job_1617883180833_0001 completed successfully #表示 Job 执行成功
Yarn 集群环境 HA 搭建的更多相关文章
- Linux下Hadoop2.7.3集群环境的搭建
Linux下Hadoop2.7.3集群环境的搭建 本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 基础环境 JDK的安 ...
- hadoop集群环境的搭建
hadoop集群环境的搭建 今天终于把hadoop集群环境给搭建起来了,能够运行单词统计的示例程序了. 集群信息如下: 主机名 Hadoop角色 Hadoop jps命令结果 Hadoop用户 Had ...
- Nacos集群环境的搭建与配置
Nacos集群环境的搭建与配置 集群搭建 一.环境: 服务器环境:CENTOS-7.4-64位 三台服务器IP:192.168.102.57:8848,192.168.102.59:8848,192. ...
- redis集群环境的搭建和错误分析
redis集群环境的搭建和错误分析 redis集群时,出现的几个异常问题 09 redis集群的搭建 以及遇到的问题
- ElasticSearch 5.2.2 集群环境的搭建
在之前 ElasticSearch 搭建好之后,我们通过 elasticsearch-header 插件在查看 ES 服务的时候,发现 cluster-health 显示的是 YELLOW. Why? ...
- zookeeper3台机器集群环境的搭建
三台机器zookeeper的集群环境搭建 Zookeeper 集群搭建指的是 ZooKeeper 分布式模式安装. 通常由 2n+1台 servers 组成. 这是因为为了保证 Leader 选举(基 ...
- 基于原生态Hadoop2.6 HA集群环境的搭建
hadoop2.6 HA平台搭建 一.条件准备 软件条件: Ubuntu14.04 64位操作系统, jdk1.7 64位,Hadoop 2.6.0, zookeeper 3.4.6 硬件条件 ...
- Linux下Hadoop2.6.0集群环境的搭建
本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 基础环境 JDK的安装与配置 现在直接到Oracle官网(http:/ ...
- Linux下Hadoop2.7.1集群环境的搭建(超详细版)
本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 一.基础环境 ...
随机推荐
- Kubernetes网络概念初探
------------恢复内容开始------------ Kubernetes网络是Kubernetes中一个核心概念.简而言之,Kubernetes网络模型可以确保集群上所有Kubernetes ...
- Leedcode算法专题训练(搜索)
BFS 广度优先搜索一层一层地进行遍历,每层遍历都是以上一层遍历的结果作为起点,遍历一个距离能访问到的所有节点.需要注意的是,遍历过的节点不能再次被遍历. 第一层: 0 -> {6,2,1,5} ...
- [Skill]VBA零基础入门及实践:根据链接展示图片
简介 VBA(Visual Basic for Applications)是依附在应用程序(例如Excel)中的VB语言.只要你安装了Office Excel就自动默认安装了VBA,同样Word和Po ...
- Dynamics CRM实体系列之视图
这一节开始讲视图.视图在Dynamics CRM中代表着实体的数据展示列表,通过这个列表可以对数据进行一个初步预览,也可以进行一些数据的定向筛选和搜索进行精确的浏览一部分数据.同时视图也是查看详细实体 ...
- redhat7.6 安装java和tomcat
使用yum 安装java # 首先查看是否安装yum rpm -qa | grep yum yum-3.4.3-161.el7.noarch # 显示这个表示已经安装了. # 查看是否安装java,没 ...
- 《图解HTTP》部分章节学习笔记整理
简介 此笔记为<图解HTTP>中部分章节的学习笔记. 目录 第1章 了解Web及网络基础 第2章 简单的HTTP协议 第4章 返回结果的HTTP状态码 第7章 确保web安全的HTTPS
- NoSQL & Redis 介绍、缓存穿透 & 击穿 & 雪崩
1. NoSql 简介 2. Redis 简介 2.1 Redis 的起源 2.2 缓存过期 & 缓存淘汰 3. 缓存异常 1)缓存穿透 2)缓存击穿 3)缓存雪崩 4)总结 1. NoSQL ...
- 用Qt(C++)实现如苹果般的亮屏效果
用Qt(C++)实现如苹果般的亮屏效果 苹果的亮屏效果可能有很多人没注意到,和其他大部分手机或电脑不同的是,苹果的亮屏特效不是简单的亮度变化,而是一个渐亮的过程.详细来说就是,图片中较亮的部分先显示出 ...
- Fiddler高级用法
Fiddler高级用法 1. 简单用法 Fiddler作为一个基于http协议的抓包工具,一直在业界有广泛使用.很多测试或者前端在使用Fiddler时,仅仅用于查看前端和服务端之间的请求信息.包括我作 ...
- 1070 Mooncake
Mooncake is a Chinese bakery product traditionally eaten during the Mid-Autumn Festival. Many types ...