【每天五分钟大数据-第一期】 伪分布式+Hadoopstreaming
说在前面
之前一段时间想着把 LeetCode 每个专题完结之后,就开始着手大数据和算法的内容。
想来想去,还是应该穿插着一起做起来。
毕竟,如果只写一类的话,如果遇到其他方面,一定会遗漏一些重要的点。
LeetCode 专题复盘,已经进行了一大半了。
大数据计划
正式开始有更新大数据想法的时候,想着把平常要注意的问题以及重要的知识点写出来。
可是之后想着咱们读者大部分是毕业前后的学生,还是从基础的开始分享。
很多人已经在 hive、HBASE、Spark、Flink 这几个方面使用的很熟练了,也有的人虽然使用了,但还是感觉对于大数据比较模糊。
后面一步一步都把基础的、核心的、重要的点给大家分享出来。
另外,这里的计划是每天或者每两天更新一个大数据的小知识点,每天 5 分钟了解和理解一个小的知识点。
后面会逐步把 HDFS、hive、Hase、Spark、YARN、Kafka、Zookeeper等逐个突破!
跟着这个专题看下去,一定会对大数据有一个本质的理解。

感受大数据
开始想着用什么内容作为开篇。
从感受开始吧!
既然是学习和感受大数据,那么,一个环境是必须要的。
下面咱们分三块内容进行分分享。
1、hadoop伪分布式环境搭建(需要的相关文件已经给大家准备好,文末可取!);
2、使用官方的 WordCount 程序进行感受;
3、自己写一个 hadoop Streaming 计算 WordCount。
ps:虽然伪分布式和wc老生常谈了,但是伪分布式用来测试功能还是不错的。另外,这两点作为大数据开篇也是完美的!
搭建一个伪分布式环境
我这边是在一台服务器上搭建的,配置是2核2G。
也可以在虚拟机上搭建!
第 ① 步 安装 jdk
官网下载地址:https://www.oracle.com/java/technologies/downloads/#java8
这边选择jdk8进行下载(文末取)
在创建 /usr/local/src/ 下,创建 java 文件,将 jdk 解压到这里。
mkdir -p /usr/local/src/java
tar -xvf jdk-8u311-linux-x64.tar -C /usr/local/java/src
第 ② 步 配置环境变量
直接在 /etc/profile 的行末进行配置,也可以根据自己实际情况进行配置。
vim /etc/profile
# 行末添加
export JAVA_HOME=/usr/local/src/java/jdk1.8.0_311/
export PATH=$JAVA_HOME/bin:$PATH
刷新配置:
source /etc/profile
验证java是否安装成功:
# java -version
java version "1.8.0_311"
Java(TM) SE Runtime Environment (build 1.8.0_311-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.311-b11, mixed mode)
此时,以上显示就是安装成功的!
第 ③ 步 上传 hadoop 压缩包(文末取)
这里选取的是 2.6.1,然后进行解压到指定目录
mkdir -p /usr/local/src/hadoop
tar -xvf hadoop-2.6.1.tar.gz -C /usr/local/src/hadoop/
第 ④ 步 修改 hadoop 配置文件
我们需要修改的文件有 5 个,位置都是在 /usr/local/src/hadoop/hadoop-2.6.1/etc/hadoop下
5 个文件分别为:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml.template
yarn-site.xml
4.1 hadoop-env.sh 文件
该文件主要是java环境的配置,使用 vim 打开之后,进行配置。
注意:这里一定是原始的路径,而非环境变量名
export JAVA_HOME=/usr/local/src/java/jdk1.8.0_311/
4.2 配置 core-site.xml
用于定义系统级别的参数,如HDFS URI 、Hadoop的临时目录等
<configuration>
<!-- 指定hadoop所使用文件系统schema(URI形式),这里我们使用的HDFS,以及主节点NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/hadoop-2.6.1/data</value>
</property>
</configuration>
4.3 配置 hdfs-site.xml
这里可以定义HDFS中文件副本数量,一般情况配置为 3,但是咱们今天是伪分布式,就一台机器,设置为 1 就好。
<configuration>
<!-- 指定HDFS副本数量,由于此次搭建是伪分布式,所以value指定为1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4.4 配置 mapred-site.xml 文件
系统给的是一个模板 mapred-site.xml.template 文件,首先拷贝一份进行配置
cp mapred-site.xml.template mapred-site.xml
然后进行yarn的主节点配置,以及 map 结果传递给 reduce 的 shuffle 机制。
<configuration>
<!-- 指定 yarn 的主节点地址(ResourceManager) -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!-- reduce 获取数据的方式,map 产生的结果传给 reduce 的机制(shuffle) -->
<property>
<name>yarn.nodemanager.aux.services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.5 配置 yarn-size.xml
配置ResourceManager ,nodeManager的通信端口,web监控端口等
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>0.0.0.0:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>0.0.0.0:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>0.0.0.0:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>0.0.0.0:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>
</configuration>
第 ⑤ 步 hadoop添加到环境变量
和 java 环境变量的配置一样,配置环境变量
vim /etc/profile
# 底部编辑
export HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.6.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH
刷新配置文件
source /etc/profile
第 ⑥ 步 初始化namenode
初始化 hdfs 格式,相当于格式化文件系统。
会往/usr/local/src/hadoop/hadoop-2.6.1/data写文件
hadoop namenode -format
显示格式化成功!

第 ⑦ 步 配置本地ssh 免密登录
如果没有配置本地 ssh 免密登录,则在配置中会一直提示让输入用户密码
yum -y install openssh-server
如果本地ssh正常就不用配置了
之后,
ssh-keygen -t rsa
一直 enter 下去:
[root@iZ2zebkqy02hia7o7gj8paZ sbin]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:oZgJuXGvxnk5pkkfd3r5CT/+uxq9nJMn2xJWk5pa6so root@iZ2zebkqy02hia7o7gj8paZ
The key's randomart image is:
+---[RSA 3072]----+
| |
| . |
| + . . .|
| = = . . o.|
| . + o S o..|
| . o . =o |
| * * . o.=..o |
| o * +.oo=.+=+.|
| o . .Eo+*+OO.|
+----[SHA256]-----+
之后,
cd ~/.ssh/
cp id_rsa.pub authorized_keys
验证一下:
ssh localhost
如果不用输入密码就跳转登录了,此时就 ok 了!
第 ⑧ 步 启动 hadoop 集群
启动的组件包括 HDFS 以及 yarn。
先启动 HDFS,再启动 yarn,均在 /usr/local/src/hadoop/hadoop-2.6.1/sbin下
./start-dfs.sh
./start-yarn.sh
正常的话,很快就启动了。
启动之后,使用 jps 看一下进程
35072 NodeManager
34498 DataNode
34644 SecondaryNameNode
34788 ResourceManager
34380 NameNode
82205 Jps
说明是成功的。
我这边是在服务器上配置的,所以想要访问 hdfs 或者 yarn,需要直接使用 ip 地址就可以访问了。
HDFS的web界面:ip:50070(ip更换为自己的地址)
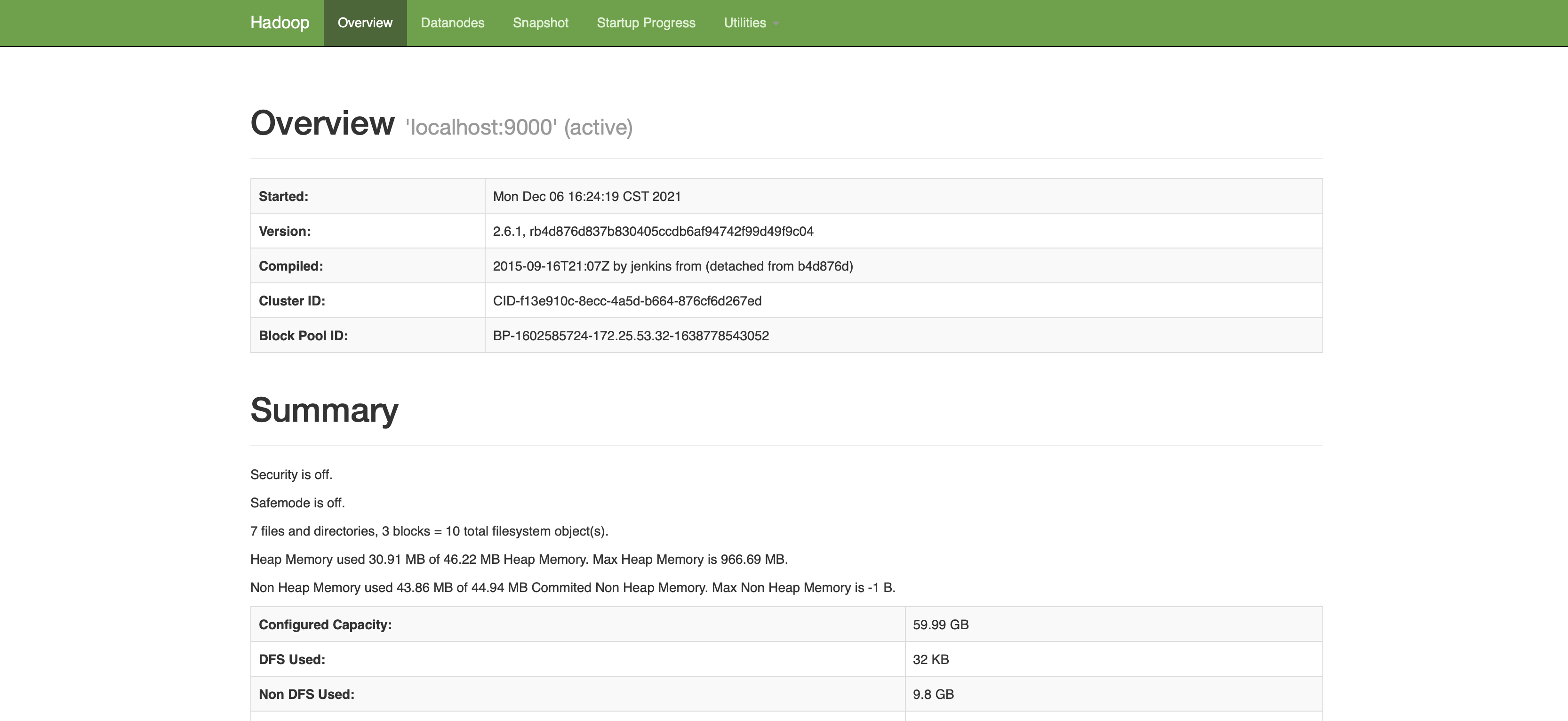
yarn的web界面:ip:8088(ip更换为自己的地址)
那到现在,一个伪分布式的集群就搭建好了,包括了HDFS、Yarn、MapReduce 等组件。
下面首先使用 hadoop 自带的一个例子实现 WordCount。
系统 WordCount 演示
首先,咱们看到系统自带的 WordCount 文件的 jar 包在 /usr/local/src/hadoop/hadoop-2.6.1/share/hadoop/mapreduce 下的 hadoop-mapreduce-examples-2.6.1.jar。
预备需要做的就是创建一个文本文件,然后使用提供的 jar 包进行对文本文件中单词的计数。
首先,创建两个文件,分别填入不同的内容。
在 /usr/local/src/hadoop/hadoop-2.6.1/data/ 下创建了 data1.txt 和 data2.txt。
vim data1.txt
vim data2.txt
data1.txt的内容
hadoop flink spark
kafka hive
hbase flink hadoop spark
spark
hbase spark hadoop
data2.txt的内容
hadoop flink spark
kafka hive hbase flink hadoop spark
spark hbase spark hadoop
然后,在 HDFS 创建/input 目录,并且把上述两个文件上传
# 创建 input 目录
hadoop dfs -mkdir /input
# 上传文件到 input 目录下
hadoop dfs -put data* /input/
查看,已经上传成功
hadoop dfs -ls /input
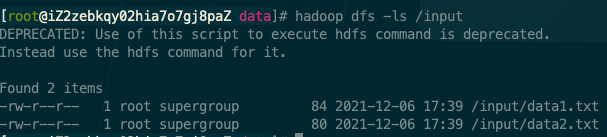
可以在 HDFS 的 web 界面进行查看。

使用自带的例子进行 WordCount 案例演示
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.1.jar wordcount /input /out

可以看到本地集群的 1 号任务。

最后,查看计算结果
[root@iZ2zebkqy02hia7o7gj8paZ hadoop-2.6.1]# hadoop dfs -ls /out
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Found 2 items
-rw-r--r-- 1 root supergroup 0 2021-12-06 18:28 /out/_SUCCESS
-rw-r--r-- 1 root supergroup 48 2021-12-06 18:28 /out/part-r-00000
[root@iZ2zebkqy02hia7o7gj8paZ hadoop-2.6.1]# hadoop dfs -text /out/part-r-00000
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
flink 4
hadoop 6
hbase 4
hive 2
kafka 2
spark 8
同样也可以在 web 页面进行查看。
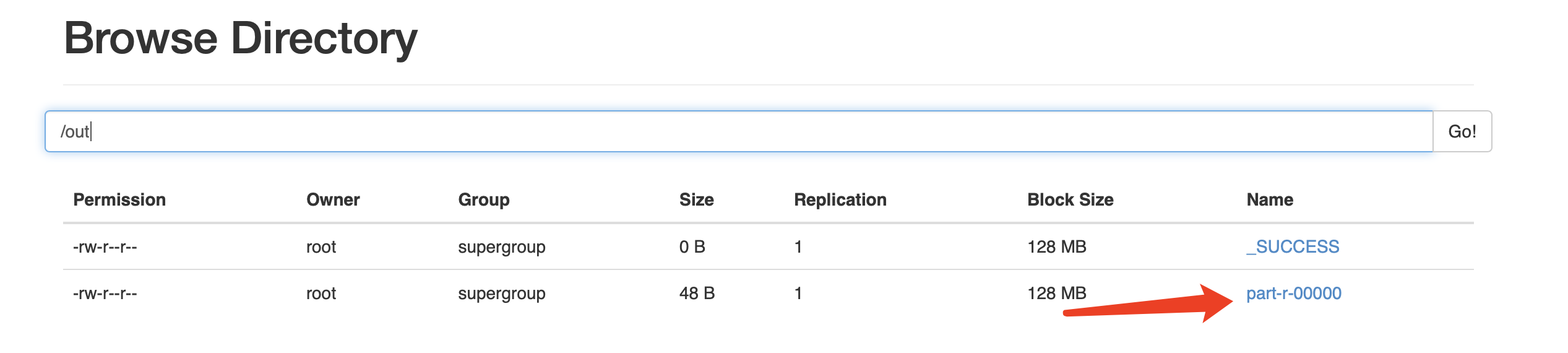
ok!至此,在伪分布式环境计算了第一个 MapReduce 任务。
系统案例感受完了,下面看看自己写一个 MapReduce 任务。
第一个 MR 程序
通常开发一个 MR(MapReduce)程序,是用 Java 来进行开发的,本身 hadoop 生态也是用 Java实现。
所以,使用 Java 开发 MR 是最好的选择。
但今天选取 Python 作为 MR 开发语言。
原因有二:其一、很多算法同学对于 Python 的友好是不言而喻的。其二、MR 程序本身担任的是离线任务,对实时性要求不高,但是对于开发效率的要求却不低,Python 开发的MR程序,开箱即用。但用 Java 的话,需要配置一些jar环境,然后打包,上传。。。
下面就用 Python 作为开发语言进行一个 WordCount 的实现。
官网这么说:
Hadoop streaming是Hadoop的一个工具, 它帮助用户创建和运行一类特殊的map/reduce作业, 这些特殊的map/reduce作业是由一些可执行文件或脚本文件充当mapper或者reducer。
例如:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-input myInputDirs \
-output myOutputDir \
-mapper /bin/cat \
-reducer /bin/wc
是的,看文档,咱们需要一个输入文件地址,一个输出文件地址。
另外,需要一个 mapper 程序以及一个 reducer 程序。
下面就开始搞吧!
首先,咱们需要一个 mapper 程序来进行将文件从标准输入进行读取
编写 mapper.py:
#!/usr/bin/python
import sys
import re
for line in sys.stdin:
words = re.split(" +", line.strip())
for word in words:
print("%s\t%s" % (word, "1"))
其中使用正则 re 是防止单词之间出现多个空格。
下面编写 reducer.py:
#!/usr/bin/python
import sys
sum = 0
last_word = None
for line in sys.stdin:
word = line.strip().split("\t")
if len(word) != 2:
continue
word = word[0]
if last_word is None:
last_word = word
if last_word != word:
print('\t'.join([last_word, str(sum)]))
last_word = word
sum = 0
sum += 1
print('\t'.join([last_word, str(sum)]))
下面可以先进性一番测试,通过一个shell命令即可:
cat input_file | python mapper.py | sort -k1 | python reducer.py
最后,就可以编写文档中提供的 Hadoop streaming 工具了。
编写 main.sh 调度 mapper 和 reducer:
#!/bin/bash
HADOOP_HOME="/usr/local/src/hadoop/hadoop-2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_PATH="/input"
OUTPUT_PATH="/out_streaming"
# 清空上次记录
${HADOOP_HOME} dfs -rmr ${OUTPUT_PATH}
${HADOOP_HOME} jar ${STREAM_JAR_PATH} \
-input ${INPUT_PATH} \
-output ${OUTPUT_PATH} \
-mapper "python mapper.py" \
-reducer "python reducer.py" \
-file ./mapper.py \
-file ./reducer.py
下面当然是执行该文件了:
-x 可以查看执行的详细信息
sh -x main.sh
现在看下结果:
[root@iZ2zebkqy02hia7o7gj8paZ script]# hadoop fs -ls /out_streaming
Found 2 items
-rw-r--r-- 1 root supergroup 0 2021-12-07 15:43 /out_streaming/_SUCCESS
-rw-r--r-- 1 root supergroup 48 2021-12-07 15:43 /out_streaming/part-00000
[root@iZ2zebkqy02hia7o7gj8paZ script]# hadoop fs -text /out_streaming/part-00000
flink 4
hadoop 6
hbase 4
hive 2
kafka 2
spark 8
现在显示的结果和上面使用系统默认wc提供程序的结果是一致的!
以上就是就关于「完虐大数据第一期」的全部分享了。
也本期算是作为一个大数据分享引子,下一期会把三台分布式集群的虚拟机分享出来,有需要的可以持续关注。
然后今天所有使用到的配置环境所需要的软件以及代码可以在公众号后台,回复“大数据第一期”进行获取!
如果感觉内容对你有些许的帮助!
期待朋友们的点赞、在看!评论 和 转发!
下期想看哪方面的,评论区告诉我!
好了~ 咱们下期再见!bye~~
【每天五分钟大数据-第一期】 伪分布式+Hadoopstreaming的更多相关文章
- 五分钟DBA:浅谈伪分布式数据库架构
[IT168 技术]12月25日消息,2010互联网行业技术研讨峰会今日在上海华东理工大学召开.本次峰会以“互联网行业应用最佳实践”为主题,定位于互联网架构设计.应用开发.应用运维管理,同时,峰会邀请 ...
- 大数据hadoop的伪分布式搭建
1.配置环境变量JDK配置 1.JDK安装 个人喜欢在 vi ~/.bash profile 下配置 export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91ex ...
- Hadoop 大数据第一天
大数据第一天 1.Hadoop生态系统 1.1 Hadoop v1.0 架构 MapReduce(用于数据计算) HDFS(用于存储数据) 1.2 Hadoop v2.0 架构 MapReduce(用 ...
- 第五章 大数据平台与技术 第12讲 大数据处理平台Spark
Spark支持多种的编程语言 对比scala和Java编程上节课的计数程序.相比之下,scala简洁明了. Hadoop的IO开销大导致了延迟高,也就是说任务和任务之间涉及到I/O操作.前一个任务完成 ...
- 互联网大规模数据分析技术(自主模式)第五章 大数据平台与技术 第10讲 大数据处理平台Hadoop
大规模的数据计算对于数据挖掘领域当中的作用.两大主要挑战:第一.如何实现分布式的计算 第二.分布式并行编程.Hadoop平台以及Map-reduce的编程方式解决了上面的几个问题.这是谷歌的一个最基本 ...
- Scala学习系列(一)——Scala为什么是大数据第一高薪语言
为什么是Scala 虽然在大数据领域Java的使用更普及,Python也有后来居上的势头,但Scala一直有着不可动摇的地位.我们熟悉的Spark,Kafka,Flink都是由Scala完成了其核心代 ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
- 第五章 大数据平台与技术 第13讲 NoSQL数据库
NoSQL不是不用SQL,是Not only SQL,不仅仅是结构化的查询. NoSQL兴起的原因 在Web2.0时代新浪一分钟可以发送两万条微博,苹果可以下载4.7万次应用. 数据的高并发性,同时有 ...
- 第五章 大数据平台与技术第11讲 MapReduce编程
在大规模的数据当中,需要分发任务,需要进行分布式的并行编程.Hadoop这样一种开源的大数据分析平台. Map阶段 Reduce阶段:相同的键把它聚集到一起之后,然后通过Reduce方式把相同的键聚集 ...
随机推荐
- Docker 安装 MySQL8
1. 环境准备 创建挂载数据目录和配置文件 mkdir -p /mnt/mysql/data /etc/mysql/conf touch /etc/mysql/conf/my.cnf 2. 拉取镜像 ...
- linux中解压.tgz, .tar.gz ,zip ,gz, .tar文件
转载:https://blog.csdn.net/fu6543210/article/details/7984578 将.tgz文件解压在当前目录: tar zxvf MY_NAME.tgz 将.ta ...
- SpringBoot教程(学习资源)
SpringBoot教程 SpringBoot–从零开始学SpringBoot SpringBoot教程1 SpringBoot教程2 --SpringBoot教程2的GitHub地址 SpringB ...
- Mysql多实例搭建部署
[部署背景] 公司测试环境需求多个数据库实例,但是只分配一台MySQL机器,所以进行多实例部署. [部署搭建] 创建软件包路径 mkdir /data/soft/package /dat ...
- QuantumTunnel:Netty实现
接上一篇文章内网穿透服务设计挖的坑,本篇来聊一下内网穿透的实现. 为了方便理解,我们先统一定义使用到的名词: UserClient:用户客户端,真实的请求发起方: UserServer:内网穿透-用户 ...
- JavaScript事件捕获冒泡与捕获
事件流 JavaScript中,事件流指的是DOM事件流. 概念 事件的传播过程即DOM事件流.事件对象在 DOM 中的传播过程,被称为"事件流".举个例子:开电脑这个事,首先你是 ...
- 子查询之 exists 和 in
exists exists用于检查一个子查询是否至少会返回一行数据(即检测行的存在),返回值为boolean型,true或false 语法 exists subquery /* 参数: subquer ...
- Are we ready for learned cardinality estimation?
Are we ready for learned Cardinality Estimation 摘要 文章包括三大部分: 对于一个静态的数据库,本文将五种基于学习的基数估计方法与九中传统的基数估计方法 ...
- Python基础(条件判断)
# age = 103 # if age < 90: # print('%s小于90' %age) # elif age > 90 and age < 95: # print('%s ...
- 编解码再进化:Ali266 与下一代视频技术
过去的一年见证了人类百年不遇的大事记,也见证了多种视频应用的厚积薄发.而因此所带来的视频数据量的爆发式增长更加加剧了对高效编解码这样的底层硬核技术的急迫需求. 新视频编解码标准 VVC 定稿不久之后, ...