MapReduce06 MapReduce工作机制
5 MapReduce工作机制(重点)
5.1 MapTask工作机制
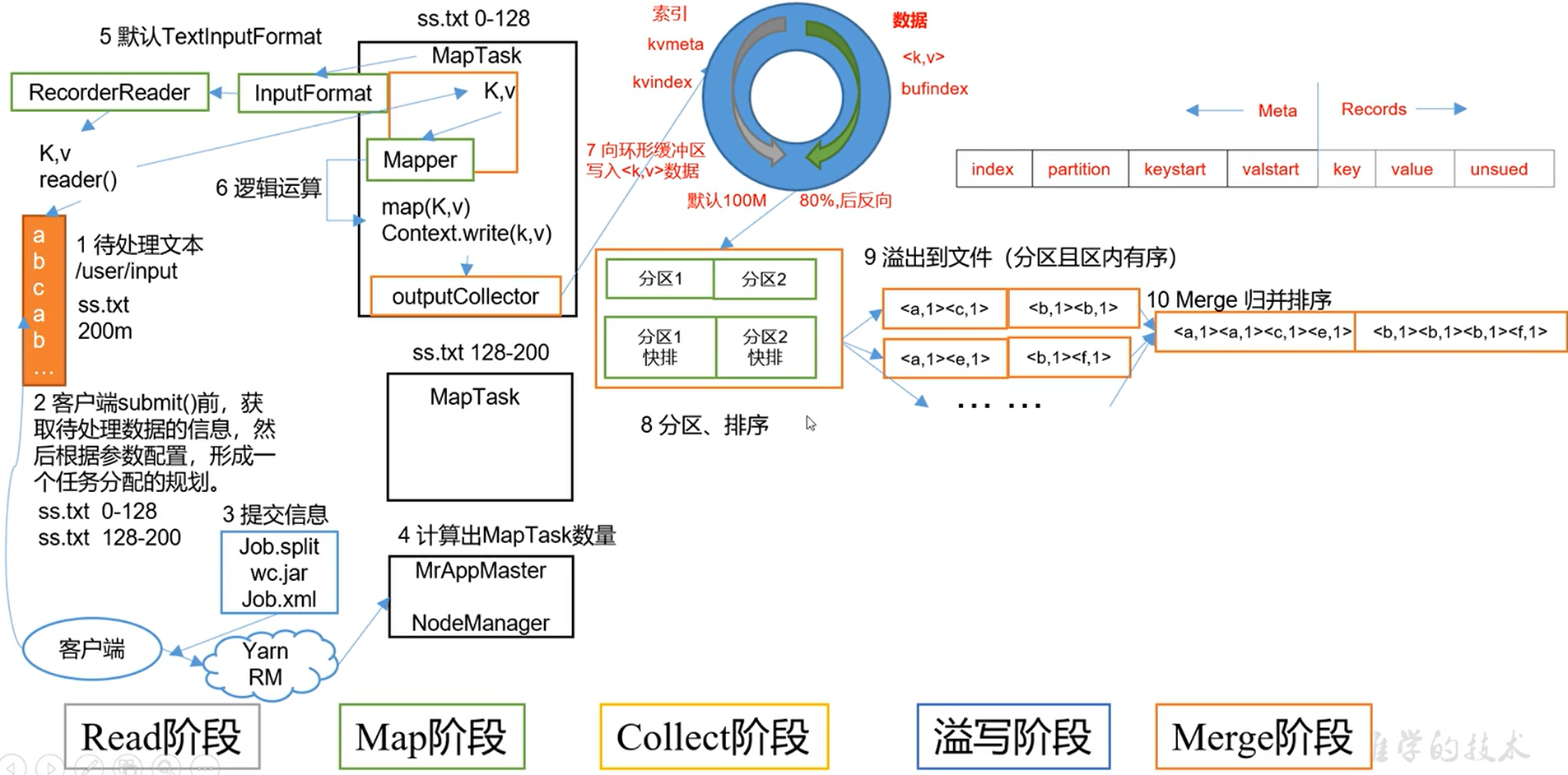
Read阶段
主要是Job的提交流程
1.切片划分
2.提交给Yarn
Job.split 切片信息
wc.jar 集群模式会提交,本地模式不会提交
Job.xml 配置信息
3.Yarn开启NodeManager(单个节点服务器资源老大) AppMaster(单个任务运行的老大) AppMaster开启对应的MapTask进入Map阶段
4.由InputFormat读取数据,默认TextInputFormat,读完之后返回给map,进入用户自己写的Mapper。一个MapTask产生一个文件
5.2 ReduceTask工作机制
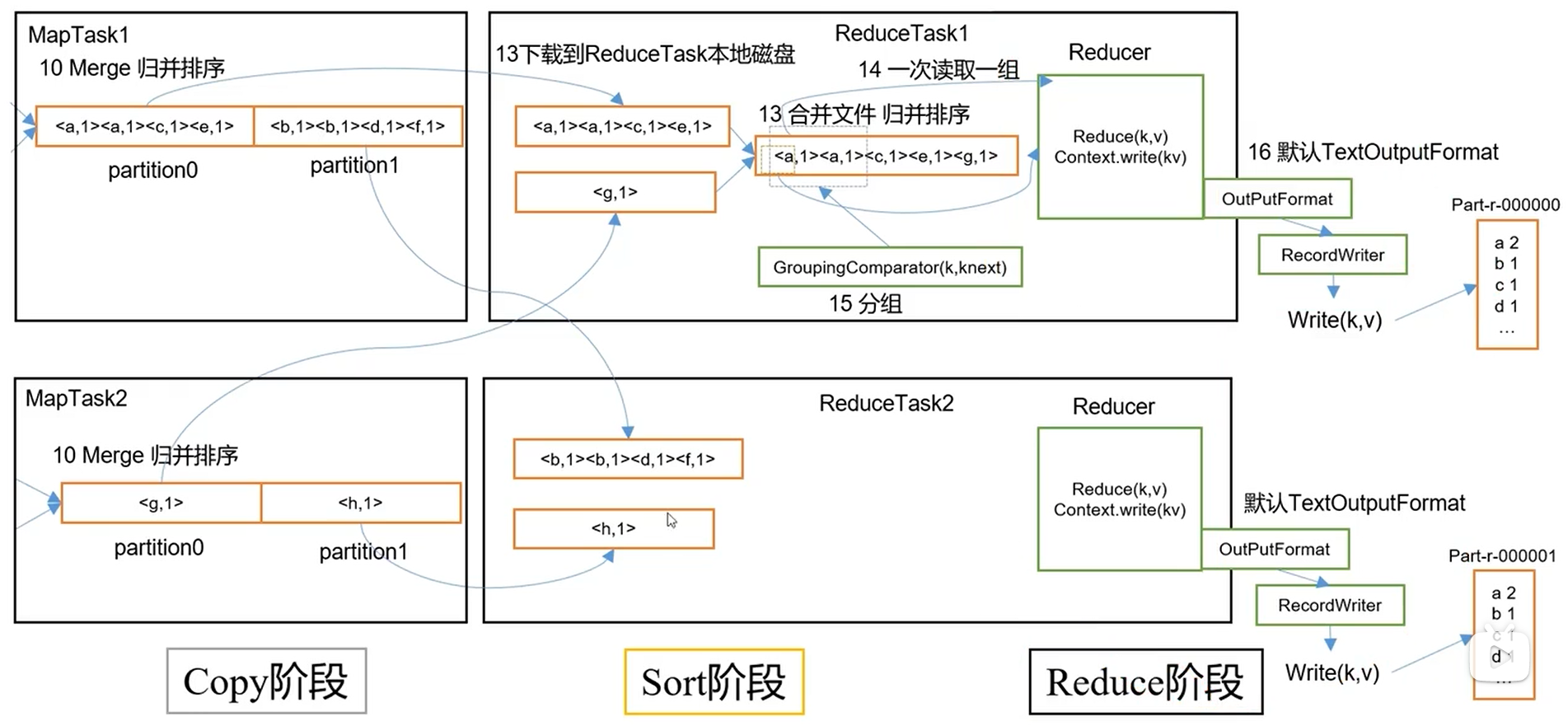
ReduceTask主动去抓取数据
5.3 ReduceTask并行度决定机制
MapTask并行度由切片个数决定,切片个数由输入文件和切片规则决定。
computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))
ReduceTask并行度由谁决定?
手动设置ReduceTask数量
//设置ReduceTasks的个数
job.setNumReduceTasks(5);
测试ReduceTask多少合适
注意事项
1.ReduceTask=0,表示没有Reduce阶段,输出文件个数和Map个数一致。
2.ReduceTask默认值就是1,所以输出文件个数为一个。
3.如果数据分布不均匀,就有可能在Reduce阶段产生数据倾斜(如136 1亿个,其他1个)
4.ReduceTask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个ReduceTask。
5.具体多少个ReduceTask,需要根据集群性能而定。
6.如果分区数不是1,但是ReduceTask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行。
MapReduce06 MapReduce工作机制的更多相关文章
- hadoop MapReduce 工作机制
摸索了将近一个月的hadoop , 在centos上配了一个伪分布式的环境,又折腾了一把hadoop eclipse plugin,最后终于实现了在windows上编写MapReduce程序,在cen ...
- MapReduce工作机制——Word Count实例(一)
MapReduce工作机制--Word Count实例(一) MapReduce的思想是分布式计算,也就是分而治之,并行计算提高速度. 编程思想 首先,要将数据抽象为键值对的形式,map函数输入键值对 ...
- hadoop知识点总结(一)hadoop架构以及mapreduce工作机制
1,为什么需要hadoop 数据分析者面临的问题 数据日趋庞大,读写都出现性能瓶颈: 用户的应用和分析结果,对实时性和响应时间要求越来越高: 使用的模型越来越复杂,计算量指数级上升. 期待的解决方案 ...
- 浅谈MapReduce工作机制
1.MapTask工作机制 整个map阶段流程大体如上图所示.简单概述:input File通过getSplits被逻辑切分为多个split文件,通通过RecordReader(默认使用lineRec ...
- [hadoop读书笔记] 第五章 MapReduce工作机制
P205 MapReduce的两种运行机制 第一种:经典的MR运行机制 - MR 1 可以通过一个简单的方法调用来运行MR作业:Job对象上的submit().也可以调用waitForCompleti ...
- MapReduce工作机制
MapReduce是什么? MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,MapReduce程序本质上是并行运行的,因此可以解决海量数据的计算问题. MapReduce ...
- yarn/mapreduce工作机制及mapreduce客户端代码编写
首先需要知道的就是在老版本的hadoop中是没有yarn的,mapreduce既负责资源分配又负责业务逻辑处理.为了解耦,把资源分配这块抽了出来,形成了yarn,这样不仅mapreudce可以用yar ...
- 图文详解MapReduce工作机制
job提交阶段 1.准备好待处理文本. 2.客户端submit()前,获取待处理数据的信息,然后根据参数配置,形成一个任务分配的规划. 3.客户端向Yarn请求创建MrAppMaster并提交切片等相 ...
- MapReduce的工作机制
<Hadoop权威指南>中的MapReduce工作机制和Shuffle: 框架 Hadoop2.x引入了一种新的执行机制MapRedcue 2.这种新的机制建议在Yarn的系统上,目前用于 ...
随机推荐
- linux下文件特殊权限设置位S和沾附位T(转载)
今天在创建文件的时候,发现了文件权限末尾有个T,之前没留意过,后来又用c创建(open)了两个文件来查看,在我没有指定权限(省略open的第三个参数)的时候,有时还会出现S,虽然还没弄懂什么时候会出现 ...
- Kill杀死Linux中的defunct进程(僵尸进程)
一.什么是defunct进程(僵尸进程)? 在 Linux 系统中,一个进程结束了,但是他的父进程没有等待(调用wait / waitpid)他,那么他将变成一个僵尸进程.当用ps命令观察进程的执行状 ...
- DeWeb 简介
DeWeb是一个可以直接将Delphi程序快速转换为网页应用的工具! 使用DeWeb, 开发者不需要学习HTML.JavaScript.Java.PHP.ASP.C#等新知识,用Delphi搞定一切. ...
- java核心技术 第3章 java基本程序设计结构
类名规范:以大写字母开头的名词 若由多个单词组成 每个单词的第一个字母应大写(驼峰命名法) 与.java文件名相同 运行程序:java ClassName(dos命令) 打印语句:System.ou ...
- Windows 防火墙
本文防火墙配置是基于 Windows Server 2008 R2 服务器进行叙述,其他Windows服务器版本仅供参考 防火墙安全策略 定义 :安全策略按照一定规则检查数据流是否可以通过防火墙的基本 ...
- Redis未授权总结
以前的笔记 简介 redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(so ...
- 日志框架-logtube
Logtube 是什么 logtube 框架是基于 slf4j的一个日志框架封装, 源码地址: https://github.com/logtube 基于 SLF4J框架, 扩展了日志输出格式 (兼容 ...
- 设计模式学习-使用go实现享元模式
享元模式 定义 优点 缺点 适用场景 代码实现 享元模式和单例模式的区别 参考 享元模式 定义 享元模式(Flyweight),运用共享技术有效的支持大量细粒度的对象. 享元模式的意图是复用对象,节省 ...
- dart系列之:dart中的异步编程
目录 简介 为什么要用异步编程 怎么使用 Future 异步异常处理 在同步函数中调用异步函数 总结 简介 熟悉javascript的朋友应该知道,在ES6中引入了await和async的语法,可以方 ...
- PAT A1060——string的常见用法详解
string 常用函数实例 (1)operator += 可以将两个string直接拼接起来 (2)compare operator 可以直接使用==.!=.<.<=.>.>= ...