MySQL Orchestrator自动导换+VIP切换
目录
Orchestrator总体结构...
测试环境信息...
Orchestrator详细配置...
SSH免密配置...
/etc/hosts配置...
visudo配置...
/etc/orchestrator.conf.json
orch_hook.sh.
orch_vip.sh.
MySQL Server配置...
测试导换...
启动orchestrator.
登录Web并发现实例...
切换前...
切换后...
Orchestrator是如何监测Master异常的...
总结...
参考资料
Orchestrator是最近非常流行的MySQL复制管理工具。相关的资料也相当的多,但是总是缺点什么。
那就是步骤不够详细,按照博客的操作,很多都无法成功。说实话,看了N多博客后,我倒腾了一周时间才成功。
特别是Orchestrator后台也使用MySQL存储,这样容易把人绕进去了(分不清参数哪个是Orchestrator用,哪个是连接mysql实例用了)。
所以在这个博客,我将使用Sqlite存储。并把每一步操作都详细列举出来。
Orchestrator总体结构

一图胜千言。上图就是Orchestrator的架构图。
图中:Sqlite/MySQL,是Orchestrator的后端存储数据库(存储监控的mysql复制实例的相关状态信息),可以选择MySQL,也可以选择SQLite。
/etc/orchestrator.conf.json是配置文件,Orchestrator启动时读取。
下面部分是监控的MySQL的实例,本例中,我是搭建的一主,两从。当然,实际上Orchestrator可以监控成百上千个MySQL复制集群。
测试环境信息
orch 192.168.56.130
host01 192.168.56.103
host02 192.168.56.104
host03: 192.168.56.105
Orchestrator详细配置
SSH免密配置
参考如下链接,在这里,我创建的是orch帐号。创建免费登录的作用是shell脚本通过ssh登录Mysql服务器进行VIP切换。
https://www.cnblogs.com/chasetimeyang/p/15064507.html
/etc/hosts配置
同样,用于Shell脚本。
- [orch@orch orchestrator]$ cat /etc/hosts
- 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
- ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
- 192.168.56.103 host01
- 192.168.56.104 host02
- 192.168.56.105 host03
- 192.168.56.130 orch
visudo配置
因为我的VIP shell导换脚本内,用到了sudo执行高权限命令。你可以通过如下方法把用户加入sudo权限。
$visudo
orch ALL=(ALL) NOPASSWD: ALL
/etc/orchestrator.conf.json
如下两个参数是连接要监控的MySQL实例的连接用户名和密码
"MySQLTopologyUser": "orchestrator",
"MySQLTopologyPassword": "orc_topology_password",
如下说明是Sqlite作为后端存储数据库
"BackendDB": "sqlite",
"SQLite3DataFile": "/usr/local/orchestrator/orchestrator.sqlite3",
如下参数是实例导换后,多长时间内不允许再次导换。默认是60分钟。
"FailureDetectionPeriodBlockMinutes": 5,
如下参数是指,恢复匹配任何实例。(你也可以配置匹配规则,如此满足规则是会自动导换。不满足的,出现问题时,只能手动导换)
"RecoverMasterClusterFilters": [
"*"
],
"RecoverIntermediateMasterClusterFilters": [
"*"
],
是否自动导换。
"ApplyMySQLPromotionAfterMasterFailover": true,
这个是导换后执行的脚本
"PostFailoverProcesses": [
"echo '(for all types) Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log",
"/home/orch/orch_hook.sh {failureType} {failureClusterAlias} {failedHost} {successorHost} >> /tmp/orch.log"
],
- [orch@orch ~]$ cat /etc/orchestrator.conf.json
- {
- "Debug": true,
- "EnableSyslog": false,
- "ListenAddress": ":3000",
- "MySQLTopologyUser": "orchestrator",
- "MySQLTopologyPassword": "orc_topology_password",
- "MySQLTopologyCredentialsConfigFile": "",
- "MySQLTopologySSLPrivateKeyFile": "",
- "MySQLTopologySSLCertFile": "",
- "MySQLTopologySSLCAFile": "",
- "MySQLTopologySSLSkipVerify": true,
- "MySQLTopologyUseMutualTLS": false,
- "BackendDB": "sqlite",
- "SQLite3DataFile": "/usr/local/orchestrator/orchestrator.sqlite3",
- "MySQLConnectTimeoutSeconds": 1,
- "DefaultInstancePort": 3306,
- "DiscoverByShowSlaveHosts": true,
- "InstancePollSeconds": 5,
- "DiscoveryIgnoreReplicaHostnameFilters": [
- "a_host_i_want_to_ignore[.]example[.]com",
- ".*[.]ignore_all_hosts_from_this_domain[.]example[.]com",
- "a_host_with_extra_port_i_want_to_ignore[.]example[.]com:3307"
- ],
- "UnseenInstanceForgetHours": 240,
- "SnapshotTopologiesIntervalHours": 0,
- "InstanceBulkOperationsWaitTimeoutSeconds": 10,
- "HostnameResolveMethod": "default",
- "MySQLHostnameResolveMethod": "@@hostname",
- "SkipBinlogServerUnresolveCheck": true,
- "ExpiryHostnameResolvesMinutes": 60,
- "RejectHostnameResolvePattern": "",
- "ReasonableReplicationLagSeconds": 10,
- "ProblemIgnoreHostnameFilters": [],
- "VerifyReplicationFilters": false,
- "ReasonableMaintenanceReplicationLagSeconds": 20,
- "CandidateInstanceExpireMinutes": 1,
- "AuditLogFile": "",
- "AuditToSyslog": false,
- "RemoveTextFromHostnameDisplay": ".mydomain.com:3306",
- "ReadOnly": false,
- "AuthenticationMethod": "",
- "HTTPAuthUser": "",
- "HTTPAuthPassword": "",
- "AuthUserHeader": "",
- "PowerAuthUsers": [
- "*"
- ],
- "ClusterNameToAlias": {
- "127.0.0.1": "test suite"
- },
- "ReplicationLagQuery": "",
- "DetectClusterAliasQuery": "SELECT SUBSTRING_INDEX(@@hostname, '.', 1)",
- "DetectClusterDomainQuery": "",
- "DetectInstanceAliasQuery": "",
- "DetectPromotionRuleQuery": "",
- "DataCenterPattern": "[.]([^.]+)[.][^.]+[.]mydomain[.]com",
- "PhysicalEnvironmentPattern": "[.]([^.]+[.][^.]+)[.]mydomain[.]com",
- "PromotionIgnoreHostnameFilters": [],
- "DetectSemiSyncEnforcedQuery": "",
- "ServeAgentsHttp": false,
- "AgentsServerPort": ":3001",
- "AgentsUseSSL": false,
- "AgentsUseMutualTLS": false,
- "AgentSSLSkipVerify": false,
- "AgentSSLPrivateKeyFile": "",
- "AgentSSLCertFile": "",
- "AgentSSLCAFile": "",
- "AgentSSLValidOUs": [],
- "UseSSL": false,
- "UseMutualTLS": false,
- "SSLSkipVerify": false,
- "SSLPrivateKeyFile": "",
- "SSLCertFile": "",
- "SSLCAFile": "",
- "SSLValidOUs": [],
- "URLPrefix": "",
- "StatusEndpoint": "/api/status",
- "StatusSimpleHealth": true,
- "StatusOUVerify": false,
- "AgentPollMinutes": 60,
- "UnseenAgentForgetHours": 6,
- "StaleSeedFailMinutes": 60,
- "SeedAcceptableBytesDiff": 8192,
- "PseudoGTIDPattern": "",
- "PseudoGTIDPatternIsFixedSubstring": false,
- "PseudoGTIDMonotonicHint": "asc:",
- "DetectPseudoGTIDQuery": "",
- "BinlogEventsChunkSize": 10000,
- "SkipBinlogEventsContaining": [],
- "ReduceReplicationAnalysisCount": true,
- "FailureDetectionPeriodBlockMinutes": 5,
- "FailMasterPromotionOnLagMinutes": 0,
- "RecoveryPeriodBlockSeconds": 3600,
- "RecoveryIgnoreHostnameFilters": [],
- "RecoverMasterClusterFilters": [
- "*"
- ],
- "RecoverIntermediateMasterClusterFilters": [
- "*"
- ],
- "OnFailureDetectionProcesses": [
- "echo 'Detected {failureType} on {failureCluster}. Affected replicas: {countSlaves}' >> /tmp/recovery.log"
- ],
- "PreGracefulTakeoverProcesses": [
- "echo 'Planned takeover about to take place on {failureCluster}. Master will switch to read_only' >> /tmp/recovery.log"
- ],
- "PreFailoverProcesses": [
- "echo 'Will recover from {failureType} on {failureCluster}' >> /tmp/recovery.log"
- ],
- "PostFailoverProcesses": [
- "echo '(for all types) Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log",
- "/home/orch/orch_hook.sh {failureType} {failureClusterAlias} {failedHost} {successorHost} >> /tmp/orch.log"
- ],
- "PostUnsuccessfulFailoverProcesses": [],
- "PostMasterFailoverProcesses": [
- "echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Promoted: {successorHost}:{successorPort}' >> /tmp/recovery.log"
- ],
- "PostIntermediateMasterFailoverProcesses": [
- "echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log"
- ],
- "PostGracefulTakeoverProcesses": [
- "echo 'Planned takeover complete' >> /tmp/recovery.log"
- ],
- "CoMasterRecoveryMustPromoteOtherCoMaster": true,
- "DetachLostSlavesAfterMasterFailover": true,
- "ApplyMySQLPromotionAfterMasterFailover": true,
- "PreventCrossDataCenterMasterFailover": false,
- "PreventCrossRegionMasterFailover": false,
- "MasterFailoverDetachReplicaMasterHost": false,
- "MasterFailoverLostInstancesDowntimeMinutes": 0,
- "PostponeReplicaRecoveryOnLagMinutes": 0,
- "OSCIgnoreHostnameFilters": [],
- "GraphiteAddr": "",
- "GraphitePath": "",
- "GraphiteConvertHostnameDotsToUnderscores": true,
- "ConsulAddress": "",
- "ConsulAclToken": "",
- "ConsulKVStoreProvider": "consul"
- }
orch_hook.sh
- #!/bin/bash
- isitdead=$1
- #cluster=$2
- oldmaster=$3
- newmaster=$4
- ssh=$(which ssh)
- logfile="/home/orch/orch_hook.log"
- interface='enp0s3'
- user=orch
- #VIP=$($ssh -tt ${user}@${oldmaster} "sudo ip address show dev enp0s3|grep -w 'inet'|tail -n 1|awk '{print \$2}'|awk -F/ '{print \$1}'")
- VIP='192.168.56.200'
- VIP_TEMP=$($ssh -tt ${user}@${oldmaster} "sudo ip address|sed -nr 's#^.*inet (.*)/32.*#\1#gp'")
- #remove '\r' at the end $'192.168.56.200\r'
- VIP_TEMP=$(echo $VIP_TEMP|awk -F"\\r" '{print $1}')
- if [ ${#VIP_TEMP} -gt 0 ]; then
- VIP=$VIP_TEMP
- fi
- echo ${VIP}
- echo ${interface}
- if [[ $isitdead == "DeadMaster" ]]; then
- if [ !-z ${!VIP} ] ; then
- echo $(date)
- echo "Revocering from: $isitdead"
- echo "New master is: $newmaster"
- echo "/home/orch/orch_vip.sh -d 1 -n $newmaster -i ${interface} -I $VIP -u ${user} -o ${oldmaster}"
- /home/orch/orch_vip.sh -d 1 -n $newmaster -i ${interface} -I $VIP -u ${user} -o ${oldmaster}
- else
- echo "Cluster does not exist!" | tee $logfile
- fi
- fi
orch_vip.sh
- #!/bin/bash
- function usage {
- cat << EOF
- usage: $0 [-h] [-d master is dead] [-o old master ] [-s ssh options] [-n new master] [-i interface] [-I] [-u SSH user]
- OPTIONS:
- -h Show this message
- -o string Old master hostname or IP address
- -d int If master is dead should be 1 otherweise it is 0
- -s string SSH options
- -n string New master hostname or IP address
- -i string Interface exmple eth0:1
- -I string Virtual IP
- -u string SSH user
- EOF
- }
- while getopts ho:d:s:n:i:I:u: flag; do
- case $flag in
- o)
- orig_master="$OPTARG";
- ;;
- d)
- isitdead="${OPTARG}";
- ;;
- s)
- ssh_options="${OPTARG}";
- ;;
- n)
- new_master="$OPTARG";
- ;;
- i)
- interface="$OPTARG";
- ;;
- I)
- vip="$OPTARG";
- ;;
- u)
- ssh_user="$OPTARG";
- ;;
- h)
- usage;
- exit 0;
- ;;
- *)
- usage;
- exit 1;
- ;;
- esac
- done
- if [ $OPTIND -eq 1 ]; then
- echo "No options were passed";
- usage;
- fi
- shift $(( OPTIND - 1 ));
- # discover commands from our path
- ssh=$(which ssh)
- arping=$(which arping)
- ip2util=$(which ip)
- #ip2util='ip'
- # command for adding our vip
- cmd_vip_add="sudo -n $ip2util address add $vip dev $interface"
- # command for deleting our vip
- cmd_vip_del="sudo -n $ip2util address del $vip/32 dev $interface"
- # command for discovering if our vip is enabled
- cmd_vip_chk="sudo -n $ip2util address show dev $interface to ${vip%/*}/32"
- # command for sending gratuitous arp to announce ip move
- cmd_arp_fix="sudo -n $arping -c 1 -I ${interface} ${vip%/*}"
- # command for sending gratuitous arp to announce ip move on current server
- #cmd_local_arp_fix="sudo -n $arping -c 1 -I ${interface} ${vip%/*}"
- cmd_local_arp_fix="$arping -c 1 -I ${interface} ${vip%/*}"
- vip_stop() {
- rc=0
- echo $?
- echo "$ssh ${ssh_options} -tt ${ssh_user}@${orig_master} \
- \"[ -n \"\$(${cmd_vip_chk})\" ] && ${cmd_vip_del} && \
- sudo -n ${ip2util} route flush cache || [ -z \"\$(${cmd_vip_chk})\" ]\""
- # ensure the vip is removed
- $ssh ${ssh_options} -tt ${ssh_user}@${orig_master} \
- "[ -n \"\$(${cmd_vip_chk})\" ] && ${cmd_vip_del} && \
- sudo -n ${ip2util} route flush cache || [ -z \"\$(${cmd_vip_chk})\" ]"
- rc=$?
- return $rc
- }
- vip_start() {
- rc=0
- # ensure the vip is added
- # this command should exit with failure if we are unable to add the vip
- # if the vip already exists always exit 0 (whether or not we added it)
- echo "$ssh ${ssh_options} -tt ${ssh_user}@${new_master} \
- \"[ -z \"\$(${cmd_vip_chk})\" ] && ${cmd_vip_add} && ${cmd_arp_fix} || [ -n \"\$(${cmd_vip_chk})\" ]\""
- $ssh ${ssh_options} -tt ${ssh_user}@${new_master} \
- "[ -z \"\$(${cmd_vip_chk})\" ] && ${cmd_vip_add} && ${cmd_arp_fix} || [ -n \"\$(${cmd_vip_chk})\" ]"
- rc=$?
- echo "vip started"
- #$cmd_local_arp_fix
- return $rc
- }
- vip_status() {
- $arping -c 1 -I ${interface} ${vip%/*}
- echo "$arping -c 1 -I ${interface} ${vip%/*}"
- if ping -c 1 -W 1 "$vip"; then
- return 0
- else
- return 1
- fi
- }
- if [[ $isitdead == 0 ]]; then
- echo "Online failover"
- if vip_stop; then
- if vip_start; then
- echo "$vip is moved to $new_master."
- else
- echo "Can't add $vip on $new_master!"
- exit 1
- fi
- else
- echo $rc
- echo "Can't remove the $vip from orig_master!"
- exit 1
- fi
- elif [[ $isitdead == 1 ]]; then
- echo "Master is dead, failover"
- # make sure the vip is not available
- if vip_status; then
- if vip_stop; then
- echo "$vip is removed from orig_master."
- else
- echo $rc
- echo "Couldn't remove $vip from orig_master."
- exit 1
- fi
- fi
- if vip_start; then
- echo "$vip is moved to $new_master."
- else
- echo "Can't add $vip on $new_master!"
- exit 1
- fi
- else
- echo "Wrong argument, the master is dead or live?"
- fi
MySQL Server配置
配置一下Master和不同的Slave的配置文件 (/etc/my.cnf)。所有配置参数可以一样,除了server_id。
需要注意的是每个MySQL的server_id必须不同。
- [mysqld]
- datadir=/var/lib/mysql
- socket=/var/lib/mysql/mysql.sock
- log-error=/var/lib/mysql/mysqld.log
- pid-file=/var/lib/mysql/mysqld.pid
- sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
- port = 3306
- #GTID:
- server_id=135 #服务器id
- gtid_mode=on #开启gtid模式
- enforce_gtid_consistency=on #强制gtid一致性,开启后对于特定create table不被支持
- #binlog
- log_bin=binlog
- log-slave-updates=1
- binlog_format=row #强烈建议,其他格式可能造成数据不一致
- #relay log
- skip_slave_start=1
- max_connect_errors=1000
- default_authentication_plugin = 'mysql_native_password'
- slave_net_timeout = 4
从机连接主机,并开启复制
- mysql>change master to master_host='master', master_port=3306, master_user='repl', master_password='Xiaopang*803',
- master_auto_position=1,MASTER_HEARTBEAT_PERIOD=2,MASTER_CONNECT_RETRY=1, MASTER_RETRY_COUNT=86400;
- mysql>start slave;
复制启动无误后。在Master上执行如下命令创建orchestrator用户并赋予权限(这就是上面Orachestrator用来连接MySQL复制实例的用户)
- CREATE USER 'orchestrator'@'%' IDENTIFIED BY 'orc_topology_password';
- GRANT SUPER, PROCESS, REPLICATION SLAVE, REPLICATION CLIENT, RELOAD ON *.* TO 'orchestrator'@'%';
测试导换
启动orchestrator
[orch@orch orchestrator]$ pwd
/usr/local/orchestrator
[root@orch orchestrator]# ./orchestrator --debug --config=/etc/orchestrator.conf.json http
登录Web并发现实例
我的orchestrator的IP地址是130。
http://192.168.56.130:3000/
发现新的实例是,填上当前的Master的实例IP与端口。

切换前
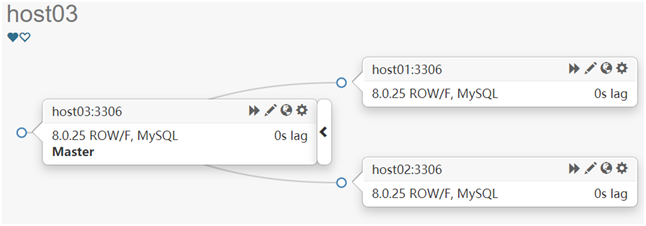
手动给host03增加一个VIP地址 192.168.56.200
[root@host03 ~]# ip addr add dev enp0s3 192.168.56.200/32
查看一下
[root@host03 ~]# ip addr show dev enp0s3
enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:9a:25:16 brd ff:ff:ff:ff:ff:ff
inet 192.168.56.105/24 brd 192.168.56.255 scope global enp0s3
valid_lft forever preferred_lft forever
inet 192.168.56.200/32 scope global enp0s3
valid_lft forever preferred_lft forever
inet6 fe80::bfdd:5d6a:d4f9:6f95/64 scope link
valid_lft forever preferred_lft forever
inet6 fe80::5a97:c3c9:a9df:466f/64 scope link tentative dadfailed
valid_lft forever preferred_lft forever
切换后
停止host03 MySQL
[root@host03 ~]#service mysqld stop
停止后,过了1分多钟,服务发了导换。新的拓扑结构变为如下
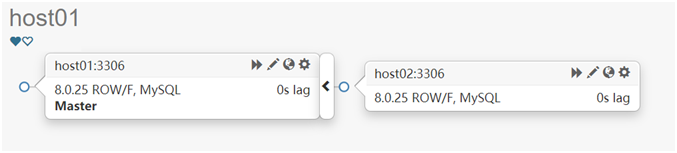
查看VIP是否也发生了切换。如下可以看到新的VIP已经切换到了新的主机host01上。
- [root@host01 ~]# ip addr show dev enp0s3
- 2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
- link/ether 08:00:27:28:0d:72 brd ff:ff:ff:ff:ff:ff
- inet 192.168.56.103/24 brd 192.168.56.255 scope global enp0s3
- valid_lft forever preferred_lft forever
- inet 192.168.56.200/32 scope global enp0s3
- valid_lft forever preferred_lft forever
- inet6 fe80::8428:fc7:68fc:1079/64 scope link
- valid_lft forever preferred_lft forever
- inet6 fe80::bfdd:5d6a:d4f9:6f95/64 scope link tentative dadfailed
- valid_lft forever preferred_lft forever
- inet6 fe80::5a97:c3c9:a9df:466f/64 scope link tentative dadfailed
- valid_lft forever preferred_lft forever
- [root@host03 ~]# ip addr show dev enp0s3
- 2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
- link/ether 08:00:27:9a:25:16 brd ff:ff:ff:ff:ff:ff
- inet 192.168.56.105/24 brd 192.168.56.255 scope global enp0s3
- valid_lft forever preferred_lft forever
- inet6 fe80::bfdd:5d6a:d4f9:6f95/64 scope link
- valid_lft forever preferred_lft forever
- inet6 fe80::5a97:c3c9:a9df:466f/64 scope link tentative dadfailed
- valid_lft forever preferred_lft forever
Orchestrator是如何监测Master异常的
Orchestrator不仅仅只依靠Master独立来判断的。实际上它还会联系各个Slave。
当Slave达成共识Master挂掉了时,这时Orchestrator才会发生导换。
如此能够保证更高的可靠性。
Failure detection
orchestrator uses a holistic approach to detect master and intermediate master failures.
In a naive approach, a monitoring tool would probe the master, for example, and alert when it cannot contact or query the master server. Such approach is susceptible to false positives caused by network glitches. The naive approach further mitigates false positives by running n tests spaced by t-long intervals. This reduces, in some cases, the chances of false positives, and then increases the response time in the event of real failure.
orchestrator harnesses the replication topology. It observes not only the server itself, but also its replicas. For example, to diagnose a dead master scenario, orchestrator must both:
- Fail to contact said master
- Be able to contact master's replicas, and confirm they, too, cannot see the master.
Instead of triaging the error by time, orchestrator triages by multiple observers, the replication topology servers themselves. In fact, when all of a master's replicas agree that they cannot contact their master, the replication topology is broken de-facto, and a failover is justified.
orchestrator's holistic failure detection approach is known to be very reliable in production.
总结
1)orch_hook脚本是从网上找的。相对于自己的环境改了一些地方。
这个肯定不完善,会存在一些bug。这个实验的另一目的也是验证Orchestrator的hook脚本的工作是否有效。
2)通过自己写脚本的方案,感觉还是容易出问题。其实,在有现成的更好的方案下,尽量不要自己写。
比如说,我觉得采用半同步+keepbyalive实现VIP的方案可能更好。一个Master两个Slave,一个配置为半同步(SlaveSync),其它的从结点配置为异步。
Master和SlaveSync,通过keepbyalive实现VIP切换(Orchestrator Hook启停keepbyalive服务实现VIP切换)
3)网上说有更佳的办法通过ProxySQL+Orchestartor,下次试一下。
参考资料
列出部分参考资料
https://www.cnblogs.com/zhoujinyi/p/10394389.html
https://www.jianshu.com/p/91833222581a
https://github.com/openark/orchestrator/
MySQL Orchestrator自动导换+VIP切换的更多相关文章
- Orchestrator+Proxysql 实现自动导换+应用透明读写分离
前面一篇博客我介绍了如何通过Orachestrator+脚本实现自动导换. 这一章,我来演示一下如何通过Orchestrator+Proxysql 实现自动导换+应用透明读写分离 总体架构 可选架构1 ...
- 设置MySQL服务自动运行
一般情况下,MySQL安装以后是自动运行的,不知道我这台机器是什么原因,MySQL不能自动运行,每次开机后都要手动运行mysqld.exe,比较麻烦,于是用以下方法将MySQL自动启动: 1. 运行c ...
- Eclipse Oxygen 解决 自动导包的问题
换成了 Eclipse 的Oxygen 版本 , 发现之前好用的自动导包功能不能用了 (Ctrl+Shift+O) 再 网上看资料 上面说 将 In Windows 替换为Editing Java ...
- MHA 实现VIP切换用到脚本
在MHA Manager端配置中,如果实现MHA的vip故障切换需要在配置文件/etc/masterha/app1/app1.cnf 中启用下面三个参数: master_ip_failover_scr ...
- 狗扑论坛 自动刷取VIP狗粮
狗扑论坛 自动刷取VIP狗粮 开始闲狗粮回复太慢就自己想了想去写一个,成功总是给我的哈哈. 自己花了一小时 时间慢慢学就慢慢写的 虽然代码简单 但是已经够自己用了 using System; usi ...
- MYSQL数据库自动本地/异地双备份/MYSQL增量备份
构建高安全电子商务网站之(网站文件及数据库自动本地/异地双备份)架构图 继续介绍Linux服务器文件备份,数据库备份,数据安全存储相关的电子商务系统架构.针对安全性有多种多样的解决方案,其中数据备份是 ...
- Android studio之更改快捷键及自动导包
更改AS中的代码提示快捷键,AS做的也挺智能的,在Keymap中可以选择使用eclipse的快捷键设置,但是虽然设置了,对有些快捷键还是不能使用,那么就需要我们手动去修改了. 在代码提示AS默认的快捷 ...
- MySQL的自动提交模式
默认情况下, MySQL启用自动提交模式(变量autocommit为ON).这意味着, 只要你执行DML操作的语句,MySQL会立即隐式提交事务(Implicit Commit).这个跟SQL S ...
- MySQL数据库--思维导图
MySQL数据库--思维导图
随机推荐
- Java IO学习笔记二:DirectByteBuffer与HeapByteBuffer
作者:Grey 原文地址:Java IO学习笔记二:DirectByteBuffer与HeapByteBuffer ByteBuffer.allocate()与ByteBuffer.allocateD ...
- Linux芯片驱动之SPI Controller
针对一款新的芯片,芯片厂商如何基于Linux编写对应的 SPI controller 驱动? 我们先看看 Linux SPI 的整体框架: 可以看到,最底层是硬件层,对应芯片内部 SPI contro ...
- hbase统计表的行数的三种方法
有些时候需要我们去统计某一个hbase表的行数,由于hbase本身不支持SQL语言,只能通过其他方式实现. 可以通过一下几种方式实现hbase表的行数统计工作: 这里有一张hbase表test:tes ...
- 一文带你了解.Net互斥锁
本文主要讲解.Net基于Threading.Mutex实现互斥锁 基础互斥锁实现 基础概念:和自旋锁一样,操作系统提供的互斥锁内部有一个数值表示锁是否已经被获取,不同的是当获取锁失败的时候,它不会反复 ...
- 【SQLite】教程06-SQLite表操作
创建表: CREATE TABLE 语句用于在任何给定的数据库创建一个新表.命名表.定义列.定义每一列的数据类型 查看表: 详细查看表: 重命名表: 删除表: 创建表并添加7条记录(第七条记录用了第二 ...
- 使用VS code编写C++无法实时检测代码的解决办法
更新:其实微软是有官方文档配置VS code 的C++的.地址是: https://code.visualstudio.com/docs/cpp 更改工作区后就发现不能再使用VS CODE愉快地写C+ ...
- 深度解读MRS IoTDB时序数据库的整体架构设计与实现
[本期推荐]华为云社区6月刊来了,新鲜出炉的Top10技术干货.重磅技术专题分享:还有毕业季闯关大挑战,华为云专家带你做好职业规划. 摘要:本文将会系统地为大家介绍MRS IoTDB的来龙去脉和功能特 ...
- .Net EF Core千万级数据实践
.Net 开发中操作数据库EF一直是我的首选,工作和学习也一直在使用.EF一定程度的提高了开发速度,开发人员专注业务,不用编写sql.方便的同时也产生了一直被人诟病的一个问题性能低下. EF Core ...
- VLAN的基础介绍与使用方法
一.VLAN概述与优势 二.VLAN的种类 三.VLAN的范围 四.VLAN的三种接口模式 五.VLAN的实例操作 一.VLAN概述与优势 VLAN(虚拟局域网)通过为子网提供数据链路连接来抽象出局域 ...
- ceph-csi组件源码分析(1)-组件介绍与部署yaml分析
更多ceph-csi其他源码分析,请查看下面这篇博文:kubernetes ceph-csi分析目录导航 ceph-csi组件源码分析(1)-组件介绍与部署yaml分析 基于tag v3.0.0 ht ...