HDFS简介及基本概念
(一)HDFS简介及其基本概念
HDFS(Hadoop Distributed File System)是hadoop生态系统的一个重要组成部分,是hadoop中的的存储组件,在整个Hadoop中的地位非同一般,是最基础的一部分,因为它涉及到数据存储,MapReduce等计算模型都要依赖于存储在HDFS中的数据。HDFS是一个分布式文件系统,以流式数据访问模式存储超大文件,将数据分块存储到一个商业硬件集群内的不同机器上。
这里重点介绍其中涉及到的几个概念:(1)超大文件。目前的hadoop集群能够存储几百TB甚至PB级的数据。(2)流式数据访问。HDFS的访问模式是:一次写入,多次读取,更加关注的是读取整个数据集的整体时间。(3)商用硬件。HDFS集群的设备不需要多么昂 贵和特殊,只要是一些日常使用的普通硬件即可,正因为如此,hdfs节点故障的可能性还是很高的,所以必须要有机制来处理这种单点故障,保证数据的可靠。(4)不支持低时间延迟的数据访问。hdfs关心的是高数据吞吐量,不适合那些要求低时间延迟数据访问的应用。(5)单用户写入,不支持任意修改。hdfs的数据以读为主,只支持单个写入者,并且写操作总是以添加的形式在文末追加,不支持在任意位置进行修改。
1、HDFS数据块
每个磁盘都有默认的数据块大小,这是文件系统进行数据读写的最小单位。这涉及到磁盘的相应知识,这里我们不多讲,后面整理一篇博客来记录一下磁盘的相应知识。
HDFS同样也有数据块的概念,默认一个块(block)的大小为128MB(HDFS的块这么大主要是为了最小化寻址开销),要在HDFS中存储的文件可以划分为多个分块,每个分块可以成为一个独立的存储单元。与本地磁盘不同的是,HDFS中小于一个块大小的文件并不会占据整个HDFS数据块。
对HDFS存储进行分块有很多好处:
- 一个文件的大小可以大于网络中任意一个磁盘的容量,文件的块可以利用集群中的任意一个磁盘进行存储。
- 使用抽象的块,而不是整个文件作为存储单元,可以简化存储管理,使得文件的元数据可以单独管理。
- 冗余备份。数据块非常适合用于数据备份,进而可以提供数据容错能力和提高可用性。每个块可以有多个备份(默认为三个),分别保存到相互独立的机器上去,这样就可以保证单点故障不会导致数据丢失。
2、namenode和datanode
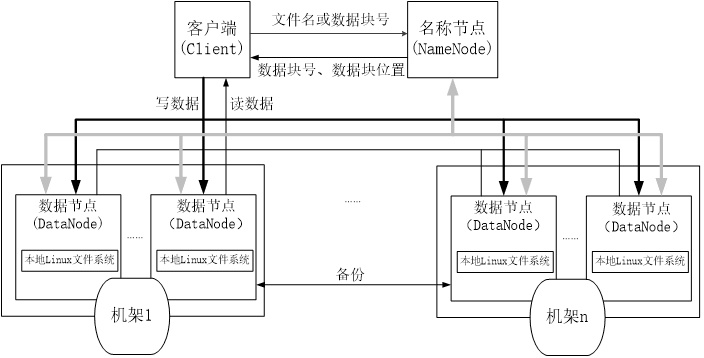
HDFS集群的节点分为两类:namenode和datanode,以管理节点-工作节点的模式运行,即一个namenode和多个datanode,理解这两类节点对理解HDFS工作机制非常重要。
namenode作为管理节点,它负责整个文件系统的命名空间,并且维护着文件系统树和整棵树内所有的文件和目录,这些信息以两个文件的形式(命名空间镜像文件和编辑日志文件)永久存储在namenode 的本地磁盘上。除此之外,同时,namenode也记录每个文件中各个块所在的数据节点信息,但是不永久存储块的位置信息,因为块的信息可以在系统启动时重新构建。
datanode作为文件系统的工作节点,根据需要存储并检索数据块,定期向namenode发送他们所存储的块的列表。

由此可见,namenode作为管理节点,它的地位是非同寻常的,一旦namenode宕机,那么所有文件都会丢失,因为namenode是唯一存储了元数据、文件与数据块之间对应关系的节点,所有文件信息都保存在这里,namenode毁坏后无法重建文件。因此,必须高度重视namenode的容错性。
为了使得namenode更加可靠,hadoop提供了两种机制:
- 第一种机制是备份那些组成文件系统元数据持久状态的文件,比如:将文件系统的信息写入本地磁盘的同时,也写入一个远程挂载的网络文件系统(NFS),这些写操作实时同步并且保证原子性。
- 第二种机制是运行一个辅助namenode,用以保存命名空间镜像的副本,在namenode发生故障时启用。(也可以使用热备份namenode代替辅助namenode)。
3、块缓存
数据通常情况下都保存在磁盘,但是对于访问频繁的文件,其对应的数据块可能被显式的缓存到datanode的内存中,以堆外缓存的方式存在,一些计算任务(比如mapreduce)可以在缓存了数据的datanode上运行,利用块的缓存优势提高读操作的性能。
4、联邦HDFS
namenode在内存中保存了文件系统中每个文件和每个数据块的引用关系,这意味着,当文件足够多时,namenode的内存将成为限制系统横向扩展的瓶颈。hadoop2.0引入了联邦HDFS允许系统通过添加namenode的方式实现扩展,每个namenode管理文件系统命名空间中的一部分,比如:一个namenode管理/usr下的文件,另外一个namenode管理/share目录下的文件。
5、HDFS的高可用性
通过备份namenode存储的文件信息或者运行辅助namenode可以防止数据丢失,但是依旧没有保证了系统的高可用性。一旦namenode发生了单点失效,那么必须能够快速的启动一个拥有文件系统信息副本的新namenode,而这个过程需要以下几步:(1)将命名空间的副本映像导入内存 (2)重新编辑日志 (3)接收足够多来自datanode的数据块报告,从而重建起数据块与位置的对应关系。
上述实际上就是一个namenode的冷启动过程,但是在数据量足够大的情况下,这个冷启动可能需要30分钟以上的时间,这是无法忍受的。
Hadoop2.0开始,增加了对高可用性的支持。采用了双机热备份的方式。同时使用一对活动-备用namenode,当活动namenode失效后,备用namenode可以迅速接管它的任务,这中间不会有任何的中断,以至于使得用户根本无法察觉。
为了实现这种双机热备份,HDFS架构需要作出以下几个改变:
- 两个namenode之间要通过高可用共享存储来实现编辑日志的共享
- datanode要同时向两个namenode发送数据块的报告信息
- 客户端要使用特定机制来处理namenode的失效问题
- 备用namenode要为活动namenode设置周期性的检查点,从中判断活动namenode是否失效
HDFS系统中运行着一个故障转移控制器,管理着将活动namenode转移为备用namenode的转换过程。同时,每一个namenode也运行着一个轻量级的故障转移控制器,主要目的就是监视宿主namenode是否失效,并在失效时实现迅速切换。
HDFS简介及基本概念的更多相关文章
- 【Hadoop】一、HDFS简介及基本概念
当需要存储的数据集的大小超过了一台独立的物理计算机的存储能力时,就需要对数据进行分区并存储到若干台计算机上去.管理网络中跨多台计算机存储的文件系统统称为分布式文件系统(distributed fi ...
- 01 HDFS 简介
01.HDFS简介 大纲: hadoop2 介绍 HDFS概述 HDFS读写流程 hadoop2介绍 框架的核心设计是HDFS(存储),mapReduce(分布式计算),YARN(资源管理),为海量的 ...
- HDFS简介【全面讲解】
http://www.cnblogs.com/chinacloud/archive/2010/12/03/1895369.html [一]HDFS简介HDFS的基本概念1.1.数据块(block)HD ...
- HDFS简介及相关概念
HDFS简介: HDFS在设计时就充分考虑了实际应用环境的特点,即硬件出错在普通服务集群中是一种常态,而不是异常. 因此HDFS主要实现了以下目标: 兼容廉价的硬件设备 HDFS设计了快速检测硬件故障 ...
- java大数据最全课程学习笔记(3)--HDFS 简介及操作
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 HDFS 简介及操作 HDFS概述 HDFS产出背景及定义 HDFS优缺点 HDFS组成架构 HDFS文件块大小 ...
- RabbitMQ入门教程(二):简介和基本概念
原文:RabbitMQ入门教程(二):简介和基本概念 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn ...
- 深入理解Java并发框架AQS系列(二):AQS框架简介及锁概念
深入理解Java并发框架AQS系列(一):线程 深入理解Java并发框架AQS系列(二):AQS框架简介及锁概念 一.AQS框架简介 AQS诞生于Jdk1.5,在当时低效且功能单一的synchroni ...
- HDFS简介
Hadoop是当今最为流行的大数据分析和处理工具. 其最先的思想来源于Google的三篇论文: GFS(Google File System):是 ...
- Hadoop 学习总结之一:HDFS简介
一.HDFS的基本概念 1.1.数据块(block) HDFS(Hadoop Distributed File System)默认的最基本的存储单位是64M的数据块. 和普通文件系统相同的是,HDFS ...
随机推荐
- 自动化测试 如何快速提取Json数据
Json作为一种轻量级的交换数据形式,由于其自身的一些优良特性比如包含有效信息多,易于阅读和解析. 使用Json的场景也很多,比如读取解析系列化的Json格式的数据,我们需要将一个Json的字符串解析 ...
- 如何在 PyCharm 中设置 Python 代码模板
#!/usr/bin/env python # -*- coding: utf-8 -*- # Created by iFantastic on $DATE if __name__ == '__mai ...
- springboot多个service互相调用的事务处理(十三)
在一个service的方法A中,调用另一个service的方法B,方法A和方法B均存在数据库插入操作,需要添加如下配置: @Transactional(rollbackFor = Exception. ...
- shell脚本(10)-流程控制while
一.while循环介绍 while循环与for一样,一般不知道循环次数使用for,不知道循环的次数时推荐使用while 二.while语法 while [ condition ] #条件为真才会循环, ...
- Netty 源码分析系列(一)Netty 概述
前言 关于Netty的学习,最近看了不少有关视频和书籍,也收获不少,希望把我知道的分享给你们,一起加油,一起成长.前面我们对 Java IO.BIO.NIO. AIO进行了分析,相关文章链接如下: 深 ...
- .NET 6 预览版 7 发布——最后一个预览版
原文:bit.ly/2VJxjxQ 作者:Richard 翻译:精致码农-王亮 说明:文中有大量的超链接,这些链接在公众号文章中被自动剔除,一部分包含超链接列表的小段落被我删减了,如果你对此感兴趣,请 ...
- JavaScript高级程序设计(第4版)-第一章学习
第一章 什么是Javascript 一.历史 JavaScript的名字怎么来的 首先,我们从javascript的历史开始了解,在以前的时候网页要验证某个必填字段是否填写,或者是判断输入的值的正确与 ...
- Vulhub-Mysql 身份认证绕过漏洞(CVE-2012-2122)
前言 当连接MariaDB/MySQL时,输入的密码会与期望的正确密码比较,由于不正确的处理,会导致即便是memcmp()返回一个非零值,也会使MySQL认为两个密码是相同的.也就是说只要知道用户名, ...
- Apache httpd的web服务
Apache httpd的web服务 适用于Unix/Linux下的web服务器软件 Apache httpd(开源且免费),虚拟主机,支持HTTPS协议,支持用户认证,支持单个目录的访问控制,支持U ...
- 知乎1578赞:Android 中为什么需要 Handler?
要理解 Handler,就得先理解 Android 的 Message 机制. 这里以用户滑动微信朋友圈为例,讲解一下 Android 的 Message 机制是怎么运行的,Message 机制中的各 ...