POJ 2976 Dropping tests 01分数规划 模板
| Time Limit: 1000MS | Memory Limit: 65536K | |
| Total Submissions: 6373 | Accepted: 2198 |
【Description】
In a certain course, you take n tests. If you get ai out of bi questions correct on test i, your cumulative average is defined to be
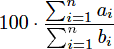 .
.
Given your test scores and a positive integer k, determine how high you can make your cumulative average if you are allowed to drop any k of your test scores.
Suppose you take 3 tests with scores of 5/5, 0/1, and 2/6. Without dropping any tests, your cumulative average is 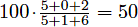 . However, if you drop the third test, your cumulative average becomes
. However, if you drop the third test, your cumulative average becomes 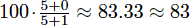 .
.
【Input】
The input test file will contain multiple test cases, each containing exactly three lines. The first line contains two integers, 1 ≤ n ≤ 1000 and 0 ≤ k < n. The second line contains n integers indicating ai for all i. The third line contains n positive integers indicating bi for all i. It is guaranteed that 0 ≤ ai ≤ bi ≤ 1, 000, 000, 000. The end-of-file is marked by a test case with n = k = 0 and should not be processed.
【Output】
For each test case, write a single line with the highest cumulative average possible after dropping k of the given test scores. The average should be rounded to the nearest integer.
【Sample Input】
3 1
5 0 2
5 1 6
4 2
1 2 7 9
5 6 7 9
0 0
【Sample Output】
83
100
【Hint】
To avoid ambiguities due to rounding errors, the judge tests have been constructed so that all answers are at least 0.001 away from a decision boundary (i.e., you can assume that the average is never 83.4997).
【算法分析】
所谓的01分数规划问题就是指这样的一类问题,给定两个数组,a[i]表示选取i的收益,b[i]表示选取i的代价。如果选取i,定义x[i]=1,否则x[i]=0。
每一个物品只有选或者不选两种方案,求一个选择方案即从其中选取k组a[i]/b[i],使得R=sigma(a[i]*x[i])/sigma(b[i]*x[i])取得最值,即所有选择物品的总收益/总代价的值最大或是最小。
01分数规划问题主要包含一般的01分数规划、最优比率生成树问题、最优比率环问题等。
来看目标式:
R=sigma(a[i]*x[i])/sigma(b[i]*x[i])
我们的目标是使得R达到最大或者最小,首先定义一个函数
F(L)=sigma(a[i]*x[i])-L*sigma(b[i]*x[i]),显然这只是对目标式的一个简单的变形。
分离参数,得到F(L):=sigma((a[i]-L*b[i])*x[i]),记d[i]=a[i]-L*b[i],那么F(L):=sigma(d[i]*x[i])。
接下来重点注意一下d[i]和F(L)的单调性。
如果我们已知了L,则所有的的d[i]是已知的,那么这里的贪心策略是为了得到一个最优的F(L),我们只需要将d[i]排序之后取其中的前k个或者后k个。也就是说,给定L,我们可以直接求出对应的F(L)。
接下来是F(L),因为b[i]是正的,显然F(L)对于L是单调递减的,这就启发我们可以通过某种方法把F(L)逼近至0,当F(L)=0时,即 sigma(a[i]*x[i])-L*sigma(b[i]*x[i])=0,那么此时的L就是最优值。
然后还要注意到的问题是,我们每次贪心地取d[i]中最小的k个,则最终使得F(L)趋于0的L会是最小的比值;如果每次贪心地取d[i]中最大的k个,则最终使得F(L)趋于0的L会是最大的比值。
考虑F(L):=sigma((a[i]-L*b[i])*x[i])式中,我们取了最后k个di[i]使得F(L)=0,则如果用此时的L去取全部的数,F(L)_tot将是小于零的,也即使得整个F(L)_tot趋于0的L_tot是小于L的。故L是取K组数的情况下,最大的比值。(这段说的有点绕口)
另外再注意到的一点是,如果将a[i]与b[i]上下颠倒,求解的方法相同,结果跟颠倒前也是刚好相对应的。
最后又想到了一个关键点,k的值对最后的结果会是什么影响:
贪心地说,为了使结果尽可能的大,k也要尽可能的大,即尽可能多的舍弃一些,剩下选取的数越少,均值越大
总结F(L)的两个重要性质如下就是:
1. F(L)单调递减
2. F(max(L)/min(L)) = 0
之后的逼近方法可以有两种选择
1.二分法
二分区间,不断把F(L)逼近至0,若F(L)<0说明L过大,若F(L)>0说明L过小,直到逼近得到一个最优的L;
/* ***********************************************
MYID : Chen Fan
LANG : G++
PROG : PKU_2976_Erfen
************************************************ */ #include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm> #define eps 1e-6 using namespace std; typedef struct nod
{
int a,b;
double r;
} node; bool op(node a,node b)
{
return a.r>b.r;
} node p[]; int main()
{
freopen("2976.txt","r",stdin); int n,k; while(scanf("%d%d",&n,&k))
{
if (n==&&k==) break; for (int i=;i<=n;i++) scanf("%d",&p[i].a);
for (int i=;i<=n;i++) scanf("%d",&p[i].b); int m=n-k;
double left=,right=;
while (left+eps<right)
{
double mid=(left+right)/;
for (int i=;i<=n;i++) p[i].r=p[i].a-mid*p[i].b;
sort(&p[],&p[n+],op);
double temp=;
for (int i=;i<=m;i++) temp+=p[i].r;
if (temp>) left=mid;
else right=mid;
} printf("%.0f\n",left*);
} return ;
}
2.Dinkelbach
从另外一个角度考虑,每次给定一个L,除了我们用来判定的F(L)之外,我们可以通过重新计算得到一个L',而且能够证明L'一定是更接近最优解的,那么我们可以考虑直接把L移动到L'上去。当L=L'时,说明已经没有更接近最优的解了,则此时的L就是最优解。
注意在Dinkelbach算法中,F(L)仍然是判定是否更接近最优解的工具,也即此时d[i]的选择仍然与之前相同,只是最后移动解的时候是把L直接移往L'
/* ***********************************************
MYID : Chen Fan
LANG : G++
PROG : PKU_2976_Dinkelbach
************************************************ */ #include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <cmath> #define eps 1e-6 using namespace std; typedef struct nod
{
int a,b,index;
double r;
} node; bool op(node a,node b)
{
return a.r>b.r;
} node p[]; int main()
{
freopen("2976.txt","r",stdin); int n,k; while(scanf("%d%d",&n,&k))
{
if (n==&&k==) break; for (int i=;i<=n;i++) scanf("%d",&p[i].a);
for (int i=;i<=n;i++) scanf("%d",&p[i].b); int m=n-k;
double l=,temp=;
while (fabs(l-temp)>=eps)
{
l=temp;
for (int i=;i<=n;i++) p[i].r=p[i].a-l*p[i].b;
sort(&p[],&p[n+],op);
int x=,y=;
for (int i=;i<=m;i++)
{
x+=p[i].a;
y+=p[i].b;
}
temp=(double)x/y;
} printf("%.0f\n",temp*);
} return ;
}
POJ 2976 Dropping tests 01分数规划 模板的更多相关文章
- POJ 2976 Dropping tests 01分数规划
给出n(n<=1000)个考试的成绩ai和满分bi,要求去掉k个考试成绩,使得剩下的∑ai/∑bi*100最大并输出. 典型的01分数规划 要使∑ai/∑bi最大,不妨设ans=∑ai/∑bi, ...
- $POJ$2976 $Dropping\ tests$ 01分数规划+贪心
正解:01分数规划 解题报告: 传送门! 板子题鸭,,, 显然考虑变成$a[i]-mid\cdot b[i]$,显然无脑贪心下得选出最大的$k$个然后判断是否大于0就好(,,,这么弱智真的算贪心嘛$T ...
- POJ - 2976 Dropping tests(01分数规划---二分(最大化平均值))
题意:有n组ai和bi,要求去掉k组,使下式值最大. 分析: 1.此题是典型的01分数规划. 01分数规划:给定两个数组,a[i]表示选取i的可以得到的价值,b[i]表示选取i的代价.x[i]=1代表 ...
- POJ 2976 Dropping tests(分数规划)
http://poj.org/problem?id=2976 题意: 给出ai和bi,ai和bi是一一配对的,现在可以删除k对,使得的值最大. 思路: 分数规划题,可以参考<挑战程序竞赛> ...
- [poj 2976] Dropping tests (分数规划 二分)
原题: 传送门 题意: 给出n个a和b,让选出n-k个使得(sigma a[i])/(sigma b[i])最大 直接用分数规划.. code: //By Menteur_Hxy #include & ...
- Dropping tests(01分数规划)
Dropping tests Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 8176 Accepted: 2862 De ...
- [poj2976]Dropping tests(01分数规划,转化为二分解决或Dinkelbach算法)
题意:有n场考试,给出每场答对的题数a和这场一共有几道题b,求去掉k场考试后,公式.的最大值 解题关键:01分数规划,double类型二分的写法(poj崩溃,未提交) 或者r-l<=1e-3(右 ...
- POJ2976 Dropping tests —— 01分数规划 二分法
题目链接:http://poj.org/problem?id=2976 Dropping tests Time Limit: 1000MS Memory Limit: 65536K Total S ...
- poj Dropping tests 01分数规划---Dinkelbach算法
果然比二分要快将近一倍.63MS.二分94MS. #include <iostream> #include <algorithm> #include <cstdio> ...
随机推荐
- VB 对象变量或with块变量未设置
先看错误代码,以下代码提示 对象变量或with块变量未设置: Dim obj As Object obj = WebBrowser1.Document.getElementById("swi ...
- apicloud教程1 (转载)
非常感谢APICloud官方给我版主职位,每天都看到很多朋友提出很多问题,我就借此机会写了一系列的教程,帮助大家从小白到高手之路.系列名称:<APICloud之小白图解教程系列>,会不定时 ...
- BigDecimal加减乘除运算
java.math.BigDecimal.BigDecimal一共有4个够造方法,让我先来看看其中的两种用法: 第一种:BigDecimal(double val)Translates a doubl ...
- 格式化格林威治时间(Wed Aug 01 00:00:00 CST 2012)
1.如果格林威治时间时间是date类型.(这种格式最简单) SimpleDateFormat df = new SimpleDateFormat("yyyyMMdd") ...
- HDU2050 由直线分割平面推广到折线分割平面
直线分割平面问题: 加入已有n-1条直线,那么再增加一条直线,最多增加多少个平面? 为了使增加的平面尽可能的多,我们应该使新增加的直线与前n条直线相交,且不存在公共交点.那么我们可以将新增加的这条直线 ...
- tab奇偶行颜色交替+插件
(function($){ $.fn.tableUI=function(options){ var defaults={ evenRowclass:"evenRow", oddro ...
- thunk技术
Thunk : 将一段机器码对应的字节保存在一个连续内存结构里, 然后将其指针强制转换成函数. 即用作函数来执行,通常用来将对象的成员函数作为回调函数. #include "stdafx.h ...
- mysql 初始化时root无密码
修改密码 update user set password=PASSWORD('123456') where User='root'; 添加用户设置权限 grant select,insert,upd ...
- java 类与对象
class XiyoujiRenwu { float height,weight; String head, ear; void speak(String s) { System.out.printl ...
- Python科学计算学习一 NumPy 快速处理数据
1 创建数组 (1) array(boject, dtype=None, copy=True, order=None, subok=False, ndmin=0) a = array([1, 2, 3 ...