Hibernate 学习教程
第6课 第一个演示样例HibernateHelloWorld 7
第7课 建立Annotation版本号的HellWorld 9
第9课Hibernate的重点学习:Hibernate的对象关系映射. 12
三、 Hibernate.cfg.xml:hbm2ddl.auto 16
六、 ehibernate.cfg.xml : show_sql 17
七、 hibernate.cfg.xml :format_sql 17
十一、 不须要(持久化)psersistence的字段. 18
第12课 使用hibernate工具类将对象模型生成关系模型. 19
一、 Configuration(AnnotationConfiguration) 29
二、 持久化对象(PersistentObject):. 35
(一) 唯一外键关联-单向(unilateralism) 37
(七) 多对一 存储(先存储group(对象持久化状态后,再保存user)):. 50
(七) 导出至数据库(hbmàddl)生成的SQL语句:. 53
八、 关联关系中的CRUD_Cascade_Fetch 63
第19课Hibernate查询(Query Language) 80
四、 工具类Projections提供对查询结果进行统计与分组操作. 91
第22课Query.list与query.iterate(不太重要) 93
二、 query.list()和query.iterate()的差别. 94
第1课 课程内容
1、 HelloWorld
a) Xml
b) Annotction
2、 Hibernate原理模拟-什么是O/RMapping以及为什么要有O/RMapping
3、 常风的O/R框架
4、 Hibernate基础配置
5、 Hibernate核心接口介绍
6、 对象的三种状态
7、 ID生成策略
8、 关系映射
9、 Hibernate查询(HQL)
10、 在Struts基础上继续完美BBS2009
11、 性能优化
12、 补充话题
第2课 Hibernate UML图

第3课 风格
1、 先脉络,后细节
2、 先操作、后原理
3、 重Annotation,轻xml配置文件
a) JPA (能够觉得EJB3的一部分)
b) Hibernate– extension
第4课 资源
a) hibernate-distribution-3.3.2.GA-dist.zip
b) hibernate-annotations-3.4.0.GA.zip
c) slf4j-1.5.10.zip (hibernate内部日志用)
2、 hibernatezh_CN文档
3、 hibernateannotateon references
第5课 环境准备
1、 下载hibernate3.3.2
2、 下载hibernate-annotations-3.4.0
3、 注意阅读hibernate compatibility matrix
4、 下载slf4j 1.5.8
第6课 第一个演示样例Hibernate HelloWorld
1、 建立新的java项目,名为hibernate_0100_HelloWorld
2、 学习建立User-liberary-hibernate,并增加相应的jar包
a) 项目右键-build path-configure build path-add library
b) 选择User-library ,在当中新建library,命名为hibernate
c) 在该library中增加hibernate所需的jar名
i. Hibernatecore
ii. /lib/required
iii. Slf-nopjar
3、 引入mysql的JDBC驱动名
4、 在mysql中建立相应的数据库以及表
a) Create databasehibernate;
b) Usehibernate;
c) Createtable Student (id int primary key, name varchar(20),age int);
5、 建立hibernate配置文件hibernate.cfg.xml
a) 从參考文档中copy
b) 改动相应的数据库连接
c) 凝视提暂时不须要的内容
6、 建立Student类
7、 建立Student映射文件Student.hbm.xml
a) 參考文档
8、 将映射文件增加到hibernate.cfg.xml
a) 參考文档
9、 写測试类Main,在Main中对Student对象进行直接的存储測试
- public staticvoid main(String[] args) {
- Configuration cfg = null;
- SessionFactory sf = null;
- Session session = null;
- Student s = new Student();
- s.setId(2);
- s.setName("s1");
- s.setAge(1);
- /*
- * org.hibernate.cfg.Configuration类的作用:
- * 读取hibernate配置文件(hibernate.cfg.xml或hiberante.properties)的.
- * new Configuration()默认是读取hibernate.properties
- * 所以使用new Configuration().configure();来读取hibernate.cfg.xml配置文件
- */
- cfg = new Configuration().configure();
- /*
- * 创建SessionFactory
- * 一个数据库相应一个SessionFactory
- * SessionFactory是线线程安全的。
- */
- sf = cfg.buildSessionFactory();
- try {
- //创建session
- //此处的session并非web中的session
- //session仅仅有在用时,才建立concation,session还管理缓存。
- //session用完后,必须关闭。
- //session是非线程安全,通常是一个请求一个session.
- session = sf.openSession();
- //手动开启事务(能够在hibernate.cfg.xml配置文件里配置自己主动开启事务)
- session.beginTransaction();
- /*
- * 保存数据,此处的数据是保存对象,这就是hibernate操作对象的优点,
- * 我们不用写那么多的JDBC代码,仅仅要利用session操作对象,至于hibernat怎样存在对象,这不须要我们去关心它,
- * 这些都有hibernate来完毕。我们仅仅要将对象创建完后,交给hibernate就能够了。
- */
- session.save(s);
- session.getTransaction().commit();
- } catch (HibernateException e) {
- e.printStackTrace();
- //回滚事务
- session.getTransaction().rollback();
- } finally {
- //关闭session
- session.close();
- sf.close();
- }
- }
- public static void main(String[] args) {
- Configuration cfg = null;
- SessionFactory sf = null;
- Session session = null;
- Student s = new Student();
- s.setId(2);
- s.setName("s1");
- s.setAge(1);
- /*
- * org.hibernate.cfg.Configuration类的作用:
- * 读取hibernate配置文件(hibernate.cfg.xml或hiberante.properties)的.
- * new Configuration()默认是读取hibernate.properties
- * 所以使用new Configuration().configure();来读取hibernate.cfg.xml配置文件
- */
- cfg = new Configuration().configure();
- /*
- * 创建SessionFactory
- * 一个数据库相应一个SessionFactory
- * SessionFactory是线线程安全的。
- */
- sf = cfg.buildSessionFactory();
- try {
- //创建session
- //此处的session并非web中的session
- //session仅仅有在用时,才建立concation,session还管理缓存。
- //session用完后,必须关闭。
- //session是非线程安全,通常是一个请求一个session.
- session = sf.openSession();
- //手动开启事务(能够在hibernate.cfg.xml配置文件里配置自己主动开启事务)
- session.beginTransaction();
- /*
- * 保存数据,此处的数据是保存对象,这就是hibernate操作对象的优点,
- * 我们不用写那么多的JDBC代码,仅仅要利用session操作对象,至于hibernat怎样存在对象,这不须要我们去关心它,
- * 这些都有hibernate来完毕。我们仅仅要将对象创建完后,交给hibernate就能够了。
- */
- session.save(s);
- session.getTransaction().commit();
- } catch (HibernateException e) {
- e.printStackTrace();
- //回滚事务
- session.getTransaction().rollback();
- } finally {
- //关闭session
- session.close();
- sf.close();
- }
- }
1、 FAQ:
a) 要调用newConfiguration().configure().buildSessionFactory(),而不是省略
* org.hibernate.cfg.Configuration类的作用:
*读取hibernate配置文件(hibernate.cfg.xml或hiberante.properties)的.
*new Configuration()默认是读取hibernate.properties
* 所以使用new Configuration().configure();来读取hibernate.cfg.xml配置文件
注意:在hibernate里的操作都应该放在事务里
第7课 建立Annotation版本号的HellWorld
注意:要求hibernate3.0版本号以后支持
1、 创建teacher表,create table teacher(id int primary key,namevarchar(20),title varchar(10));
2、 创建Teacher类
- public class Teacher {
- private int id;
- private String name;
- private String title;
- //设置主键使用@Id
- public int getId() {
- return id;
- }
- public void setId(int id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getTitle() {
- return title;
- }
- public void setTitle(String title) {
- this.title = title;
- }
- }
- public class Teacher {
- private int id;
- private String name;
- private String title;
- //设置主键使用@Id
- public int getId() {
- return id;
- }
- public void setId(int id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getTitle() {
- return title;
- }
- public void setTitle(String title) {
- this.title = title;
- }
- }
1、 在hibernate library中增加annotation的jar包
a) Hibernateannotations jar
b) Ejb3persistence jar
c) Hibernatecommon annotations jar
d) 注意文档中没有提到hibernate-common-annotations.jar文件
2、 參考Annotation文档建立相应的注解
- import javax.persistence.Entity;
- import javax.persistence.Id;
- /** @Entity 表示以下的这个Teacher是一个实体类
- * @Id 表示主键Id*/
- @Entity //***
- public class Teacher {
- private int id;
- private String name;
- private String title;
- //设置主键使用@Id
- @Id //***
- public int getId() {
- return id;
- }
- public void setId(int id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getTitle() {
- return title;
- }
- public void setTitle(String title) {
- this.title = title;
- }}
- import javax.persistence.Entity;
- import javax.persistence.Id;
- /** @Entity 表示以下的这个Teacher是一个实体类
- * @Id 表示主键Id*/
- @Entity //***
- public class Teacher {
- private int id;
- private String name;
- private String title;
- //设置主键使用@Id
- @Id //***
- public int getId() {
- return id;
- }
- public void setId(int id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getTitle() {
- return title;
- }
- public void setTitle(String title) {
- this.title = title;
- }}
1、 在hibernate.cfg.xml中建立映射<maping class=…/>
<mapping class="com.wjt276.hibernate.model.Teacher"/>
注意:<mapping>标签中使用的是class属性,而不是resource属性,而且使用小数点(.)导航,而不是”/”
2、 參考文档进行測试
- public staticvoid main(String[] args) {
- Teacher t = new Teacher();
- t.setId(1);
- t.setName("s1");
- t.setTitle("中级");
- //注此处并非使用org.hibernate.cfg.Configuration来创建Configuration
- //而使用org.hibernate.cfg.AnnotationConfiguration来创建Configuration,这样就能够使用Annotation功能
- Configuration cfg = new AnnotationConfiguration();
- SessionFactory sf = cfg.configure().buildSessionFactory();
- Session session = sf.openSession();
- session.beginTransaction();
- session.save(t);
- session.getTransaction().commit();
- session.close();
- sf.close();
- }
- public static void main(String[] args) {
- Teacher t = new Teacher();
- t.setId(1);
- t.setName("s1");
- t.setTitle("中级");
- //注此处并非使用org.hibernate.cfg.Configuration来创建Configuration
- //而使用org.hibernate.cfg.AnnotationConfiguration来创建Configuration,这样就能够使用Annotation功能
- Configuration cfg = new AnnotationConfiguration();
- SessionFactory sf = cfg.configure().buildSessionFactory();
- Session session = sf.openSession();
- session.beginTransaction();
- session.save(t);
- session.getTransaction().commit();
- session.close();
- sf.close();
- }
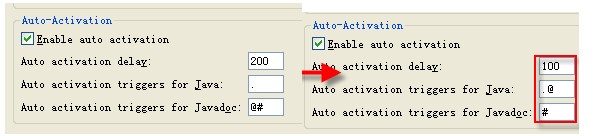
1、 FAQ:@ 后不给提示
解决方法:windows→Proferences→seach “Content Assist”设置Auto-Activation例如以下:
——————————————————————————————————————————————————————————————————————————————————————————————
第8课 什么是O/R Mapping
一、 定义:
ORM(ObjectRelational Mapping)---是一种为了解决面向对象与关系型数据库存在的互不匹配的现象的技术。简单说:ORM是通过使用描写叙述对象和数据库之间映射的元数据,将Java程序中的对象自己主动持久化到关系数据中。本质上就是将数据从一种形式转换到第二种形式。
分层后,上层不须要知道下层是怎样做了。
分层后,不能够循环依赖,通常是单向依赖。
一、 Hibernate的创始人:
Gavin King
二、 Hibernate做什么:
1、 就是将对象模型(实体类)的东西存入关系模型中,
2、 实体中类相应关系型库中的一个表,
3、 实体类中的一个属性会相应关系型数据库表中的一个列
4、 实体类的一个实例会相应关系型数据库表中的一条记录。
%%将对象数据保存到数据库、将数据库数据读入到对象中%%
OOA---面向对象的分析、面向对象的设计
OOD---设计对象化
OOP---面向对象的开发
阻抗不匹配---例JAVA类中有继承关系,但关系型数据库中不存在这个概念这就是阻抗不匹配。Hibernate能够解决问题
三、 Hibernate存在的原因:
1、 解决阻抗不匹配的问题;
2、 眼下不存在完整的面向对象的数据库(眼下都是关系型数据库);
3、 JDBC操作数据库非常繁琐
4、 SQL语句编写并非面向对象
5、 能够在对象和关系表之间建立关联来简化编程
6、 O/RMapping简化编程
7、 O/RMapping跨越数据库平台
8、 hibernate_0200_OR_Mapping_Simulation
四、 Hibernate的优缺点:
1、 不须要编写的SQL语句(不须要编辑JDBC),仅仅须要操作相应的对象就能够了,就能够能够存储、更新、删除、载入对象,能够提高生产效;
2、 由于使用Hibernate仅仅须要操作对象就能够了,所以我们的开发更对象化了;
3、 使用Hibernate,移植性好(仅仅要使用Hibernate标准开发,更换数据库时,仅仅须要配置相应的配置文件就能够了,不须要做其他任务的操作);
4、 Hibernate实现了透明持久化:当保存一个对象时,这个对象不须要继承Hibernate中的不论什么类、实现不论什么接口,仅仅是个纯粹的单纯对象—称为POJO对象(最纯粹的对象—这个对象没有继承第三方框架的不论什么类和实现它的不论什么接口)
5、 Hibernate是一个没有侵入性的框架,没有侵入性的框架我们一般称为轻量级框架
6、 Hibernate代码測试方便。
五、 Hibernate使用范围:
1. 针对某一个对象,简单的将它载入、编辑、改动,且改动仅仅是对单个对象(而不是批量的进行改动),这样的情况比較适用;
2. 对象之间有着非常清晰的关系(例:多个用户属于一个组(多对一)、一个组有多个用户(一对多));
3. 聚集性操作:批量性增加、改动时,不适合使用Hibernate(O/映射框架都不适合使用);
4. 要求使用数据库中特定的功能时不适合使用,由于Hibernate不使用SQL语句;
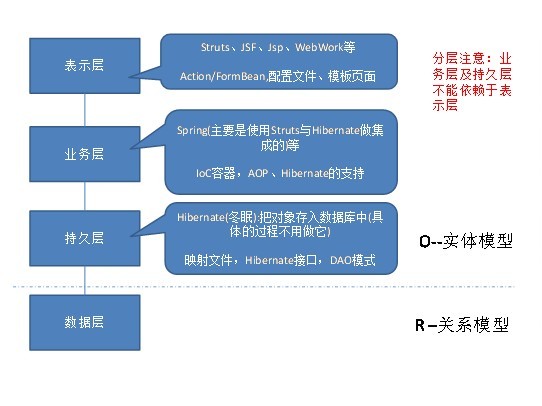
第9课 Hibernate的重点学习:Hibernate的对象关系映射
一、对象---关系映射模式
l 属性映射;
l 类映射:
l 关联映射:
n 一对一;
n 一对多;
n 多对多。
二、经常使用的O/R映射框架:
1、 Hibernate
2、 ApacheOJB
3、 JDO(是SUN提出的一套标准—Java数据对象)
4、 Toplink(Orocle公司的)
5、 EJB(2.0X中有CMP;3.0X提出了一套“Java持久化API”---JPA)
6、 IBatis(非常的轻量级,对JDBC做了一个非常非常轻量级的包装,严格说不是O/R映射框架,而是基于SQL的映射(提供了一套配置文件,把SQL语句配置到文件里,再配置一个对象进去,仅仅要訪问配置文件时,就可得到对象))
7、 JAP(是SUN公司的一套标准)
a) 意愿统一天下
第10课 模拟Hibernate原理(OR模拟)
我们使用一个项目来完毕
功能:有一个配置文件,文件里完毕表名与类名对象,字段与类属性相应起来。
測试驱动开发
一、 项目名称
hibernate_0200_OR_Mapping_Simulation
二、 原代码
- Test类:
- public staticvoid main(String[] args)throws Exception{
- Student s = new Student();
- s.setId(10);
- s.setName("s1");
- s.setAge(1);
- Session session = new Session();//此Session是我们自定义的Session
- session.save(s);
- }
- Test类:
- public static void main(String[] args) throws Exception{
- Student s = new Student();
- s.setId(10);
- s.setName("s1");
- s.setAge(1);
- Session session = new Session();//此Session是我们自定义的Session
- session.save(s);
- }
- Session类
- import java.lang.reflect.Method;
- import java.sql.Connection;
- import java.sql.DriverManager;
- import java.sql.PreparedStatement;
- import java.util.HashMap;
- import java.util.Map;
- import com.wjt276.hibernate.model.Student;
- public class Session {
- String tableName = "_Student";
- Map<String,String> cfs = new HashMap<String,String>();
- String[] methodNames;//用于存入实体类中的get方法数组
- public Session(){
- cfs.put("_id", "id");
- cfs.put("_name", "name");
- cfs.put("_age", "age");
- methodNames = new String[cfs.size()];
- }
- public void save(Student s)throws Exception{
- String sql = createSQL();//创建SQL串
- Class.forName("com.mysql.jdbc.Driver");
- Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/hibernate","root","root");
- PreparedStatement ps = conn.prepareStatement(sql);
- //
- for(int i =0; i < methodNames.length; i++){
- Method m = s.getClass().getMethod(methodNames[i]);//返回一个 Method 对象,它反映此 Class 对象所表示的类或接口的指定公共成员方法
- Class r = m.getReturnType();//返回一个 Class 对象,该对象描写叙述了此 Method 对象所表示的方法的正式返回类型
- if(r.getName().equals("java.lang.String")) {
- //对带有指定參数的指定对象调用由此 Method 对象表示的底层方法。
- //个别參数被自己主动解包,以便与基本形參相匹配,基本參数和引用參数都随需服从方法调用转换
- String returnValue = (String)m.invoke(s);
- ps.setString(i + 1, returnValue);
- }
- if(r.getName().equals("int")) {
- Integer returnValue = (Integer)m.invoke(s);
- ps.setInt(i + 1, returnValue);
- }
- if(r.getName().equals("java.lang.String")) {
- String returnValue = (String)m.invoke(s);
- ps.setString(i + 1, returnValue);
- }
- System.out.println(m.getName() + "|" + r.getName());
- }
- ps.executeUpdate();
- ps.close();
- conn.close();
- }
- private String createSQL() {
- String str1 = "";
- int index = 0;
- for(String s : cfs.keySet()){
- String v = cfs.get(s);//取出实体类成员属性
- v = Character.toUpperCase(v.charAt(0)) + v.substring(1);//将成员属性第一个字符大写
- methodNames[index] = "get" + v;//拼实体类成员属性的getter方法
- str1 += s + ",";//依据表中字段名拼成字段串
- index ++;
- }
- str1 = str1.substring(0,str1.length() -1);
- String str2 = "";
- //依据表中字段数,拼成?串
- for (int i =0; i < cfs.size(); i++){ str2 +="?,";}
- str2 = str2.substring(0,str2.length() -1);
- String sql = "insert into " + tableName +"(" + str1 +")" +" values (" + str2 +")";
- System.out.println(sql);
- return sql;
- }}
- Session类
- import java.lang.reflect.Method;
- import java.sql.Connection;
- import java.sql.DriverManager;
- import java.sql.PreparedStatement;
- import java.util.HashMap;
- import java.util.Map;
- import com.wjt276.hibernate.model.Student;
- public class Session {
- String tableName = "_Student";
- Map<String,String> cfs = new HashMap<String,String>();
- String[] methodNames;//用于存入实体类中的get方法数组
- public Session(){
- cfs.put("_id", "id");
- cfs.put("_name", "name");
- cfs.put("_age", "age");
- methodNames = new String[cfs.size()];
- }
- public void save(Student s) throws Exception{
- String sql = createSQL();//创建SQL串
- Class.forName("com.mysql.jdbc.Driver");
- Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/hibernate","root","root");
- PreparedStatement ps = conn.prepareStatement(sql);
- //
- for(int i = 0; i < methodNames.length; i++){
- Method m = s.getClass().getMethod(methodNames[i]);//返回一个 Method 对象,它反映此 Class 对象所表示的类或接口的指定公共成员方法
- Class r = m.getReturnType();//返回一个 Class 对象,该对象描写叙述了此 Method 对象所表示的方法的正式返回类型
- if(r.getName().equals("java.lang.String")) {
- //对带有指定參数的指定对象调用由此 Method 对象表示的底层方法。
- //个别參数被自己主动解包,以便与基本形參相匹配,基本參数和引用參数都随需服从方法调用转换
- String returnValue = (String)m.invoke(s);
- ps.setString(i + 1, returnValue);
- }
- if(r.getName().equals("int")) {
- Integer returnValue = (Integer)m.invoke(s);
- ps.setInt(i + 1, returnValue);
- }
- if(r.getName().equals("java.lang.String")) {
- String returnValue = (String)m.invoke(s);
- ps.setString(i + 1, returnValue);
- }
- System.out.println(m.getName() + "|" + r.getName());
- }
- ps.executeUpdate();
- ps.close();
- conn.close();
- }
- private String createSQL() {
- String str1 = "";
- int index = 0;
- for(String s : cfs.keySet()){
- String v = cfs.get(s);//取出实体类成员属性
- v = Character.toUpperCase(v.charAt(0)) + v.substring(1);//将成员属性第一个字符大写
- methodNames[index] = "get" + v;//拼实体类成员属性的getter方法
- str1 += s + ",";//依据表中字段名拼成字段串
- index ++;
- }
- str1 = str1.substring(0,str1.length() -1);
- String str2 = "";
- //依据表中字段数,拼成?串
- for (int i = 0; i < cfs.size(); i++){ str2 += "?,";}
- str2 = str2.substring(0,str2.length() -1);
- String sql = "insert into " + tableName + "(" + str1 + ")" + " values (" + str2 + ")";
- System.out.println(sql);
- return sql;
- }}
第11课 Hibernate基础配置
一、 提纲
1、 相应项目:hibernate_0300_BasicConfiguration
2、 介绍MYSQL的图形化client
3、 Hibernate.cfg.xml:hbm2ddl.auto
a) 先建表还是先建实体类
4、 搭建日志环境并配置显示DDL语句
5、 搭建Junit环境
a) 须要注意Junit的Bug
6、 ehibernate.cfg.xml: show_sql
7、 hibernate.cfg.xml:format_sql
8、 表名和类名不同,对表名进行配置
a) Annotation:@Table
b) Xml:自己查询
9、 字段名和属性同样
a) 默觉得@Basic
b) Xml中不用写column
10、 字段名和属性名不同
a) Annotation:@Column
b) Xml:自己查询
11、 不须要psersistence的字段
a) Annotation:@Transient
b) Xml:不写
12、 映射日期与时间类型,指定时间精度
a) Annotation:@Temporal
b) Xml:指定type
13、 映射枚举类型
a) Annotation:@Enumerated
b) Xml:麻烦
14、 字段映射的位置(field或者get方法)
a) Best practice:保持field和get/set方法的一致
15、 @Lob
16、 课外:CLOB BLOB类型的数据存取
17、 课外:Hibernate自定义数据类型
18、 Hibernate类型
二、 介绍MYSQL的图形化client
这样的软件网络非常多,主要自己动手做
三、 Hibernate.cfg.xml:hbm2ddl.auto
在SessionFactory创建时,自己主动检查数据库结构,或者将数据库schema的DDL导出到数据库. 使用 create-drop时,在显式关闭SessionFactory时,将drop掉数据库schema.取值 validate | update | create | create-drop
四、 搭建日志环境并配置显示DDL语句
我们使用slf接口,然后使用log4j的实现。
1、 首先引入log4j的jar包(log4j-1.2.14.jar),
2、 然后再引入slf4j实现LOG4J和适配器jar包(slf4j-log4j12-1.5.8.jar)
3、 最后创建log4j的配置文件(log4j.properties),并加以改动,仅仅要保留
log4j.logger.org.hibernate.tool.hbm2ddl=debug
五、 搭建Junit环境
1、首先引入Junit 类库 jar包 (junit-4.8.1.jar)
2、在项目名上右键→new→Source Folder→输入名称→finish
3、注意,你对哪个包进行測试,你就在測试下建立和那个包同样的包
4、建立測试类,须要在測试的方法前面增加”@Test”
- public class TeacherTest {
- private static SessionFactory sf =null;
- @BeforeClass//表示Junit此类被载入到内存中就运行这种方法
- public staticvoid beforClass(){
- sf = new AnnotationConfiguration().configure().buildSessionFactory();
- }
- @Test//表示以下的方法是測试用的。
- public void testTeacherSave(){
- Teacher t = new Teacher();
- t.setId(6);
- t.setName("s1");
- t.setTitle("中级");
- Session session = sf.openSession();
- session.beginTransaction();
- session.save(t);
- session.getTransaction().commit();
- session.close();
- }
- @AfterClass//Junit在类结果时,自己主动关闭
- public staticvoid afterClass(){
- sf.close();
- }}
- public class TeacherTest {
- private static SessionFactory sf = null;
- @BeforeClass//表示Junit此类被载入到内存中就运行这种方法
- public static void beforClass(){
- sf = new AnnotationConfiguration().configure().buildSessionFactory();
- }
- @Test//表示以下的方法是測试用的。
- public void testTeacherSave(){
- Teacher t = new Teacher();
- t.setId(6);
- t.setName("s1");
- t.setTitle("中级");
- Session session = sf.openSession();
- session.beginTransaction();
- session.save(t);
- session.getTransaction().commit();
- session.close();
- }
- @AfterClass//Junit在类结果时,自己主动关闭
- public static void afterClass(){
- sf.close();
- }}
六、 ehibernate.cfg.xml : show_sql
输出全部SQL语句到控制台. 有一个另外的选择是把org.hibernate.SQL这个log category设为debug。
取值: true | false
七、 hibernate.cfg.xml :format_sql
在log和console中打印出更美丽的SQL。
取值: true | false
True样式:
- 16:32:39,750 DEBUG SchemaExport:377 -
- create table Teacher (
- id integer not null,
- name varchar(255),
- title varchar(255),
- primary key (id)
- )
- 16:32:39,750 DEBUG SchemaExport:377 -
- create table Teacher (
- id integer not null,
- name varchar(255),
- title varchar(255),
- primary key (id)
- )
False样式:
- 16:33:40,484 DEBUG SchemaExport:377 - create table Teacher (id integer not null, name varchar(255), title varchar(255), primary key (id))
- 16:33:40,484 DEBUG SchemaExport:377 - create table Teacher (id integer not null, name varchar(255), title varchar(255), primary key (id))
八、 表名和类名不同,对表名进行配置
Annotation:使用 @Table(name=”tableName”) 进行注解
比如:
- /**
- * @Entity 表示以下的这个Teacher是一个实体类
- * @Table 表示映射到数据表中的表名,当中的name參数表示"表名称"
- * @Id 表示主键Id,一般放在getXXX前面
- */
- @Entity
- @Table(name="_teacher")
- public class Teacher {
- [……]
- }
- /**
- * @Entity 表示以下的这个Teacher是一个实体类
- * @Table 表示映射到数据表中的表名,当中的name參数表示"表名称"
- * @Id 表示主键Id,一般放在getXXX前面
- */
- @Entity
- @Table(name="_teacher")
- public class Teacher {
- [……]
- }
Xml:
- <class name="Student" table="_student">
- <class name="Student" table="_student">
九、 字段名和属性同样
Annotation:默觉得@Basic
注意:假设在成员属性没有增加不论什么注解,则默认在前面增加了@Basic
Xml中不用写column
十、 字段名和属性名不同
Annotation:使用@Column(name=”columnName”)进行注解
比如:
- /**
- * @Entity 表示以下的这个Teacher是一个实体类
- * @Table 表示映射到数据表中的表名,当中的name參数表示"表名称"
- * @Column 表示实体类成员属性映射数据表中的字段名,当中name參数指定一个新的字段名
- * @Id 表示主键Id
- */
- @Entity
- @Table(name="_teacher")
- public class Teacher {
- private int id;
- private String name;
- private String title;
- //设置主键使用@Id
- @Id
- public int getId() {
- return id;
- }
- @Column(name="_name")//字段名与属性不同一时候
- public String getName() {
- return name;
- }
- ……
- /**
- * @Entity 表示以下的这个Teacher是一个实体类
- * @Table 表示映射到数据表中的表名,当中的name參数表示"表名称"
- * @Column 表示实体类成员属性映射数据表中的字段名,当中name參数指定一个新的字段名
- * @Id 表示主键Id
- */
- @Entity
- @Table(name="_teacher")
- public class Teacher {
- private int id;
- private String name;
- private String title;
- //设置主键使用@Id
- @Id
- public int getId() {
- return id;
- }
- @Column(name="_name")//字段名与属性不同一时候
- public String getName() {
- return name;
- }
- ……
Xml:
- <property name="name" column="_name"/>
- <property name="name" column="_name"/>
十一、 不须要(持久化)psersistence的字段
就是不实体类的某个成员属性不须要存入数据库中
Annotation:使用@Transient 进行注解就能够了。
比如:
- @Transient
- public String getTitle() {
- return title;
- }
- @Transient
- public String getTitle() {
- return title;
- }
Xml:不写(就是不须要对这个成员属性进行映射)
十二、 映射日期与时间类型,指定时间精度
Annotation:使用@Temporal(value=TemporalType)来注解表示日期和时间的注解
当中TemporalType有三个值:TemporalType.TIMESTAMP 表示yyyy-MM-dd HH:mm:ss
TemporalType.DATE 表示yyyy-MM-dd
TemporalType.TIME 表示HH:mm:ss
- @Temporal(value=TemporalType.DATE)
- public Date getBirthDate() {
- return birthDate;
- }
- @Temporal(value=TemporalType.DATE)
- public Date getBirthDate() {
- return birthDate;
- }
注意:当使用注解时,属性为value时,则这个属性名能够省略,比如:@Temporal(TemporalType)
Xml:使用type属性指定hibernate类型
- <property name="birthDate" type="date"/>
- <property name="birthDate" type="date"/>
注意:hibernate日期时间类型有:date, time, timestamp,当然您也能够使用Java包装类
十二、 映射枚举类型
Annotation:使用@Enumerated(value=EnumType)来注解表示此成员属性为枚举映射到数据库
当中EnumType有二个值:①EnumType.STRING 表示直接将枚举名称存入数据库
②EnumType.ORDINAL 表示将枚举所相应的数值存入数据库
Xml:映射非常的麻烦,先要定义自定义类型,然后再使用这个定义的类型……
第12课 使用hibernate工具类将对象模型生成关系模型
(也就是实体类生成数据库中的表),完整代码例如以下:
package com.wjt276.hibernate;
import org.hibernate.cfg.AnnotationConfiguration;
import org.hibernate.cfg.Configuration;
import org.hibernate.tool.hbm2ddl.SchemaExport;
/**
* Hibernate工具<br/>
* 将对象模型生成关系模型(将对象生成数据库中的表)
* 把hbm映射文件(或Annotation注解)转换成DDL
* 生成数据表之前要求已经存在数据库
* 注:这个工具类建立好后,以后就不用建立了。以后直接Copy来用。
* @author wjt276
* @version 1.0 2009/10/16
*/
public classExportDB {
public static voidmain(String[] args){
/*org.hibernate.cfg.Configuration类的作用:
*读取hibernate配置文件(hibernate.cfg.xml或hiberante.properties)的.
*new Configuration()默认是读取hibernate.properties
*所以使用newConfiguration().configure();来读取hibernate.cfg.xml配置文件
*/
Configuration cfg = new AnnotationConfiguration().configure();
/*org.hibernate.tool.hbm2ddl.SchemaExport工具类:
*须要传入Configuration參数
*此工具类能够将类导出生成数据库表
*/
SchemaExport export = newSchemaExport(cfg);
/** 開始导出
*第一个參数:script是否打印DDL信息
*第二个參数:export是否导出到数据库中生成表
*/
export.create(true, true);
}}
运行刚刚建立的ExportDB类中的main()方法,进行实际的导出类。
第13课 ID主键生成策略
一、 Xml方式
<id>标签必须配置在<class>标签内第一个位置。由一个字段构成主键,假设是复杂主键<composite-id>标签
被映射的类必须定义相应数据库表主键字段。大多数类有一个JavaBeans风格的属性, 为每一个实例包括唯一的标识。<id> 元素定义了该属性到数据库表主键字段的映射。
<id
name="propertyName" (1)
type="typename" (2)
column="column_name" (3)
unsaved-value="null|any|none|undefined|id_value" (4)
access="field|property|ClassName" (5)
node="element-name|@attribute-name|element/@attribute|.">
<generatorclass="generatorClass"/>
</id>
(1) name (可选): 标识属性的名字(实体类的属性)。
(2) type (可选): 标识Hibernate类型的名字(省略则使用hibernate默认类型),也能够自己配置其他hbernate类型(integer, long, short, float,double, character, byte, boolean, yes_no, true_false)
(2) length(可选):当type为varchar时,设置字段长度
(3) column (可选 - 默觉得属性名): 主键字段的名字(省略则取name为字段名)。
(4) unsaved-value (可选 - 默觉得一个切合实际(sensible)的值): 一个特定的标识属性值,用来标志该实例是刚刚创建的,尚未保存。 这能够把这样的实例和从曾经的session中装载过(可能又做过改动--译者注) 但未再次持久化的实例区分开来。
(5) access (可选 - 默觉得property): Hibernate用来訪问属性值的策略。
假设 name属性不存在,会觉得这个类没有标识属性。
unsaved-value 属性在Hibernate3中差点儿不再须要。
还有一个另外的<composite-id>定义能够訪问旧式的多主键数据。 我们强烈不建议使用这样的方式。
<generator>元素(主键生成策略)
主键生成策略是必须配置
用来为该持久化类的实例生成唯一的标识。假设这个生成器实例须要某些配置值或者初始化參数, 用<param>元素来传递。
<id name="id"type="long" column="cat_id">
<generator class="org.hibernate.id.TableHiLoGenerator">
<param name="table">uid_table</param>
<param name="column">next_hi_value_column</param>
</generator>
</id>
全部的生成器都实现org.hibernate.id.IdentifierGenerator接口。 这是一个非常easy的接口;某些应用程序能够选择提供他们自己特定的实现。当然, Hibernate提供了非常多内置的实现。以下是一些内置生成器的快捷名字:
increment
用于为long, short或者int类型生成 唯一标识。仅仅有在没有其他进程往同一张表中插入数据时才干使用。 在集群下不要使用。
identity
对DB2,MySQL, MS SQL Server,Sybase和HypersonicSQL的内置标识字段提供支持。 返回的标识符是long, short 或者int类型的。 (数据库自增)
sequence
在DB2,PostgreSQL, Oracle, SAPDB, McKoi中使用序列(sequence), 而在Interbase中使用生成器(generator)。返回的标识符是long, short或者 int类型的。(数据库自增)
hilo
使用一个高/低位算法高效的生成long, short 或者 int类型的标识符。给定一个表和字段(默认各自是 hibernate_unique_key和next_hi)作为高位值的来源。 高/低位算法生成的标识符仅仅在一个特定的数据库中是唯一的。
seqhilo
使用一个高/低位算法来高效的生成long, short 或者 int类型的标识符,给定一个数据库序列(sequence)的名字。
uuid
用一个128-bit的UUID算法生成字符串类型的标识符, 这在一个网络中是唯一的(使用了IP地址)。UUID被编码为一个32位16进制数字的字符串,它的生成是由hibernate生成,一般不会反复。
UUID包括:IP地址,JVM的启动时间(精确到1/4秒),系统时间和一个计数器值(在JVM中唯一)。 在Java代码中不可能获得MAC地址或者内存地址,所以这已经是我们在不使用JNI的前提下的能做的最好实现了
guid
在MS SQL Server 和 MySQL 中使用数据库生成的GUID字符串。
native
依据底层数据库的能力选择identity,sequence 或者hilo中的一个。(数据库自增)
assigned
让应用程序在save()之前为对象分配一个标示符。这是 <generator>元素没有指定时的默认生成策略。(假设是手动分配,则须要设置此配置)
select
通过数据库触发器选择一些唯一主键的行并返回主键值来分配一个主键。
foreign
使用另外一个相关联的对象的标识符。通常和<one-to-one>联合起来使用。
二、 annotateon方式
使用@GeneratedValue(strategy=GenerationType)注解能够定义该标识符的生成策略
Strategy有四个值:
① 、AUTO- 能够是identity column类型,或者sequence类型或者table类型,取决于不同的底层数据库.
相当于native
② 、TABLE- 使用表保存id值
③ 、IDENTITY- identity column
④ 、SEQUENCE- sequence
注意:auto是默认值,也就是说没有后的參数则表示为auto
1、AUTO默认
@Id
@GeneratedValue
public int getId() {
return id;
}
或
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
public int getId() {
return id;
}
1、 对于mysql,使用auto_increment
2、 对于oracle使用hibernate_sequence(名称固定)
2、IDENTITY
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
public int getId() {
return id;
}
对DB2,MySQL, MS SQL Server,Sybase和HypersonicSQL的内置标识字段提供支持。 返回的标识符是long, short 或者int类型的。 (数据库自增)
注意:此生成策略不支持Oracle
3、SEQUENCE
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE)
public int getId() {
return id;
}
在DB2,PostgreSQL,Oracle, SAP DB, McKoi中使用序列(sequence), 而在Interbase中使用生成器(generator)。返回的标识符是long, short或者 int类型的。(数据库自增)
注意:此生成策略不支持MySQL
4、为Oracle指定定义的Sequence
a)、首先须要在实体类前面申明一个Sequence例如以下:
方法:@SequenceGenerator(name="SEQ_Name",sequenceName="SEQ_DB_Name")
參数注意:SEQ_Name:表示为申明的这个Sequence指定一个名称,以便使用
SEQ_DB_Name:表示为数据库中的Sequence指定一个名称。
两个參数的名称能够一样。
@Entity
@SequenceGenerator(name="teacherSEQ",sequenceName="teacherSEQ_DB")
public class Teacher {
……
}
b)、然后使用@GeneratedValue注解
方法:@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="SEQ_Name")
參数:strategy:固定为GenerationType.SEQUENCE
Generator:在实体类前面申明的sequnce的名称
@Entity
@SequenceGenerator(name="teacherSEQ",sequenceName="teacherSEQ_DB")
public class Teacher {
private int id;
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="teacherSEQ")
public int getId() {
return id;
}}
5、TABLE - 使用表保存id值
原理:就是在数据库中建立一个表,这个表包括两个字段,一个字段表示名称,还有一个字段表示值。每次在增加数据时,使用第一个字段的名称,来取值作为增加数据的ID,然后再给这个值累加一个值再次存入数据库,以便下次取出使用。
Table主键生成策略的定义:
@javax.persistence.TableGenerator(
name="Teacher_GEN", //生成策略的名称
table="GENERATOR_TABLE", //在数据库生成表的名称
pkColumnName = "pk_key", //表中第一个字段的字段名 类型为varchar,key
valueColumnName = "pk_value", //表中第二个字段的字段名 int ,value
pkColumnValue="teacher", //这个策略中使用该记录的第一个字段的值(key值)
initialValue = 1, //这个策略中使用该记录的第二个字段的值(value值)初始化值
allocationSize=1 //每次使用数据后累加的数值
)
这样运行后,会在数据库建立一个表,语句例如以下:
create tableGENERATOR_TABLE (pk_key varchar(255),pk_value integer )
结构:

而且表建立好后,就插入了一个记录,例如以下:
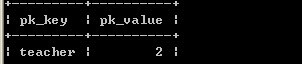
注:这条记录的pk_value值为2,是由于刚刚做例程序时,已经插入一条记录了。初始化时为1。
使用TABLE主键生成策略:
@Entity
@javax.persistence.TableGenerator(
name="Teacher_GEN", //生成策略的名称
table="GENERATOR_TABLE", //在数据库生成表的名称
pkColumnName = "pk_key", //表中第一个字段的字段名 类型为varchar,key
valueColumnName = "pk_value", //表中第二个字段的字段名 int ,value
pkColumnValue="teacher", //这个策略中使用该记录的第一个字段的值(key值)
initialValue = 1, //这个策略中使用该记录的第二个字段的值(value值)初始化值
allocationSize=1 //每次使用数据后累加的数值
)
public class Teacher {
private int id;
@Id
@GeneratedValue(strategy=GenerationType.TABLE,generator="Teacher_GEN")
public int getId() {
return id;}}
注意:这样每次在增加Teacher记录时,都会先到GENERATOR_TABLE表取pk_key=teacher的记录后,使用pk_value值作为记录的主键。然后再给这个pk_value字段累加1,再存入到GENERATOR_TABLE表中,以便下次使用。
这个表能够给无数的表作为主键表,仅仅是增加一条记录而以(须要保证table、pkColumnName、valueColumnName三个属性值一样就能够了。),这个主键生成策略能够跨数据库平台。
三、 联合主键
复合主键(联合主键):多个字段构成唯一性。
1、xml方式
a) 实例场景:核算期间
// 核算期间
public class FiscalYearPeriod {
private int fiscalYear; //核算年
private int fiscalPeriod; //核算月
private Date beginDate; //開始日期
private Date endDate; //结束日期
private String periodSts; //状态
public int getFiscalYear() {
return fiscalYear;
}
public void setFiscalYear(int fiscalYear) {
this.fiscalYear = fiscalYear;
}
public int getFiscalPeriod(){ return fiscalPeriod;}
public void setFiscalPeriod(int fiscalPeriod) {
this.fiscalPeriod =fiscalPeriod;
}
public DategetBeginDate() {return beginDate;}
public void setBeginDate(DatebeginDate) { this.beginDate = beginDate; }
public Date getEndDate(){return endDate;}
public void setEndDate(DateendDate) { this.endDate = endDate; }
public StringgetPeriodSts() { return periodSts;}
public voidsetPeriodSts(String periodSts) {this.periodSts = periodSts;}
}
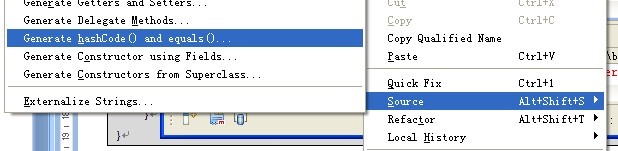
复合主键的映射,普通情况把主键相关的属性抽取出来单独放入一个类中。而这个类是有要求的:必需实现序列化接口(java.io.Serializable)(能够保存到磁盘上),为了确定这个复合主键类所相应对象的唯一性就会产生比較,对象比較就须要复写对象的hashCode()、equals()方法(复写方法例如以下图片),然后在类中引用这个复合主键类

b) 复合主键类:
复合主键必需实现java.io.Serializable接口
public class FiscalYearPeriodPKimplements java.io.Serializable {
private int fiscalYear;//核算年
private int fiscalPeriod;//核算月
public int getFiscalYear() {
return fiscalYear;
}
public void setFiscalYear(int fiscalYear) {
this.fiscalYear = fiscalYear;
}
public int getFiscalPeriod(){
return fiscalPeriod;
}
public void setFiscalPeriod(int fiscalPeriod) {
this.fiscalPeriod =fiscalPeriod;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime* result + fiscalPeriod;
result = prime* result + fiscalYear;
return result;
}
@Override
public boolean equals(Object obj){
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() !=obj.getClass())
return false;
FiscalYearPeriodPKother = (FiscalYearPeriodPK) obj;
if (fiscalPeriod != other.fiscalPeriod)
return false;
if (fiscalYear != other.fiscalYear)
return false;
return true;
}}
c) 实体类:(中引用了复合主键类)
public class FiscalYearPeriod{
private FiscalYearPeriodPK fiscalYearPeriodPK;//引用 复合主键类
private Date beginDate;//開始日期
private Date endDate;//结束日期
private String periodSts;//状态
public FiscalYearPeriodPK getFiscalYearPeriodPK() {
return fiscalYearPeriodPK;
}
public void setFiscalYearPeriodPK(FiscalYearPeriodPKfiscalYearPeriodPK) {
this.fiscalYearPeriodPK = fiscalYearPeriodPK;
}
………………
d) FiscalYearPeriod.hbm.xml映射文件
<hibernate-mapping>
<class name="com.bjsxt.hibernate.FiscalYearPeriod"table="t_fiscal_year_period">
<composite-id name="fiscalYearPeriodPK">
<key-property name="fiscalYear"/>
<key-property name="fiscalPeriod"/>
</composite-id>
<property name="beginDate"/>
<property name="endDate"/>
<property name="periodSts"/>
</class>
</hibernate-mapping>
e) 导出数据库输出SQL语句:
create table t_fiscalYearPeriod (fiscalYear integer not null, fiscalPeriodinteger not null, beginDate datetime, endDate datetime, periodSts varchar(255),primary key (fiscalYear, fiscalPeriod))//实体映射到数据就是两个字段构成复合主键
f) 数据库表结构:
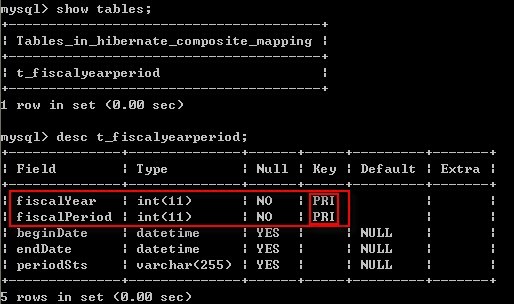
g) 复合主键关联映射数据存储:
session =HibernateUtils.getSession();
tx =session.beginTransaction();
FiscalYearPeriod fiscalYearPeriod = new FiscalYearPeriod();
//构造复合主键
FiscalYearPeriodPK pk = new FiscalYearPeriodPK();
pk.setFiscalYear(2009);
pk.setFiscalPeriod(11);
fiscalYearPeriod.setFiscalYearPeriodPK(pk);//为对象设置复合主键
fiscalYearPeriod.setEndDate(new Date());
fiscalYearPeriod.setBeginDate(new Date());
fiscalYearPeriod.setPeriodSts("Y");
session.save(fiscalYearPeriod);
h) 运行输出SQL语句:
Hibernate: insert into t_fiscalYearPeriod (beginDate, endDate, periodSts,fiscalYear, fiscalPeriod) values (?, ?, ?, ?, ?)
注:假设再存入同样复合主键的记录,就会出错。
i) 数据的载入:
数据载入非常easy,仅仅是主键是一个对象而以,不是一个普通属性。
2、annotation方式
以下是定义组合主键的几种语法:
将组件类注解为@Embeddable,并将组件的属性注解为@Id
将组件的属性注解为@EmbeddedId
将类注解为@IdClass,并将该实体中全部属于主键的属性都注解为@Id
a) 将组件类注解为@Embeddable,并将组件的属性注解为@Id
组件类:
@Embeddable
public class TeacherPK implementsjava.io.Serializable{
private int id;
private String name;
public int getId() {return id; }
public void setId(int id) {this.id = id;}
public String getName() { return name;}
public void setName(Stringname) { this.name = name;}
@Override
public boolean equals(Object o) { ……}
@Override
public int hashCode() { return this.name.hashCode(); }
}
将组件类的属性注解为@Id,实体类中组件的引用
@Entity
public class Teacher {
private TeacherPK pk;
private String title;
@Id
public TeacherPK getPk(){
return pk;
}}
b) 将组件的属性注解为@EmbeddedId
注意:仅仅须要在实体类中表示复合主键属性前注解为@Entity,表示此主键是一个复合主键
注意了,复合主键类不须要不论什么的注意。
@Entity
public class Teacher {
private TeacherPK pk;
private String title;
@EmbeddedId
public TeacherPK getPk(){
return pk;
}}
c) 类注解为@IdClass,主键的属性都注解为@Id
须要将复合主键类建立好,不须要进行不论什么注解
在实体类中不须要进行复合主键类的引用
须要在实体类前面注解为@IdClass,而且指定一个value属性,值为复合主键类的class
须要在实体类中进行复合主键成员属性前面注解为@Id
例如以下:
@Entity
@IdClass(TeacherPK.class)
public class Teacher {
//private TeacherPK pk;//不再须要
private int id;
private String name;
@Id
public int getId() {return id; }
public void setId(int id) { this.id = id; }
@Id
public String getName() {return name;}
public void setName(Stringname) {this.name = name;
}}
第14课 Hibernate核心开发接口(重点)
一、 Configuration(AnnotationConfiguration)
作用:进行配置信息的管理
目标:用来产生SessionFactory
能够在configure方法中指定hibernate配置文件,默认(不指定)时在classpath下载入hibernate.cfg.xml文件
载入默认的hibernate的配置文件
sessionFactory = newAnnotationConfiguration().configure().buildSessionFactory();
载入指定hibernate的配置文件
sessionFactory=newnnotationConfiguration().configure("hibernate.xml").buildSessionFactory();
仅仅须要关注一个方法:buildSessionFactory();
二、 SessionFactory
作用:主要用于产生Session的工厂(数据库连接池)
当它产生一个Session时,会从数据库连接池取出一个连接,交给这个Session
Session session = sessionFactory.getCurrentSession();
而且能够通过这个Session取出这个连接
关注两个方法:
getCurrentSession():表示当前环境没有Session时,则创建一个,否则不用创建
openSession(): 表示创建一个Session(3.0以后不经常使用),使用后须要关闭这个Session
双方法的差别:
①、openSession永远是每次都打开一个新的Session,而getCurrentSession不是,是从上下文找、仅仅有当前没有Session时,才创建一个新的Session
②、OpenSession须要手动close,getCurrentSession不须要手动close,事务提交自己主动close
③、getCurrentSession界定事务边界
上下文:
所指的上下文是指hibernate配置文件(hibernate.cfg.xml)中的“current_session_context_class”所指的值:(可取值:jta|thread|managed|custom.Class)
<property name="current_session_context_class">thread</property>
经常使用的是:①、thread:是从上下文找、仅仅有当前没有Session时,才创建一个新的Session,主要从数据界定事务
②、jta:主要从分布式界定事务,运行时须要Application Server来支持(Tomcat不支持)
③、managed:不经常使用
④、custom.Class:不经常使用
三、 Session
1、 管理一个数据库的任务单元
2、 save();
session.save(Object)
session的save方法是向数据库中保存一个对象,这种方法产生对象的三种状态
3、 delete()
session.delete(Object)
Object对象须要有ID
对象删除后,对象状态为Transistent状态
4、 load()
格式: Session.load(Class arg0,Serializable arg1) throws HibernateException
*arg0:须要载入对象的类,比如:User.class
*arg1:查询条件(实现了序列化接口的对象):例"4028818a245fdd0301245fdd06380001"字符串已经实现了序列化接口。假设是数值类类型,则hibernate会自己主动使用包装类,比如 1
* 此方法返回类型为Object,但返回的是代理对象。
* 运行此方法时不会马上发出查询SQL语句。仅仅有在使用对象时,它才发出查询SQL语句,载入对象。
* 由于load方法实现了lazy(称为延迟载入、赖载入)
* 延迟载入:仅仅有真正使用这个对象的时候,才载入(才发出SQL语句)
*hibernate延迟载入实现原理是代理方式。
* 採用load()方法载入数据,假设数据库中没有相应的记录,则会抛出异常对象不找到(org.hibernate.ObjectNotFoundException)
try {
session =sf.openSession();
session.beginTransaction();
User user =(User)session.load(User.class,1);
//仅仅有在使用对象时,它才发出查询SQL语句,载入对象。
System.out.println("user.name=" + user.getName());
//由于此的user为persistent状态,所以数据库进行同步为龙哥。
user.setName("发哥");
session.getTransaction().commit();
} catch (HibernateExceptione) {
e.printStackTrace();
session.getTransaction().rollback();
} finally{
if (session != null){
if(session.isOpen()){
session.close();
}
}
}
5、 Get()
格式:Session.get(Class arg0,Serializable arg1)方法
* arg0:须要载入对象的类,比如:User.class
* arg1:查询条件(实现了序列化接口的对象):
例"4028818a245fdd0301245fdd06380001"字符串已经实现了序列化接口。假设是基数类型,则hibernate会自己主动转换成包装类,如 1
返回值: 此方法返回类型为Object,也就是对象,然后我们再强行转换为须要载入的对象就能够了。
假设数据不存在,则返回null;
注:运行此方法时马上发出查询SQL语句。载入User对象
载入数据库中存在的数据,代码例如以下:
try {
session =sf.openSession();
session.beginTransaction();
* 此方法返回类型为Object,也就是对象,然后我们再强行转换为须要载入的对象就能够了。
假设数据不存在,则返回null
* 运行此方法时马上发出查询SQL语句。载入User对象。
*/
User user = (User)session.get(User.class, 1);
//数据载入完后的状态为persistent状态。数据将与数据库同步。
System.out.println("user.name=" + user.getName());
//由于此的user为persistent状态,所以数据库进行同步为龙哥。
user.setName("龙哥");
session.getTransaction().commit();
} catch(HibernateException e) {
e.printStackTrace();
session.getTransaction().rollback();
} finally{
if (session != null){
if(session.isOpen()){
session.close();
}
}
6、 load()与get()差别
①、 不存在相应记录时表现不一样;
②、 load返回的是代理对象,等到真正使用对象的内容时才发出sql语句,这样就要求在第一次使用对象时,要求session处于open状态,否则出错
③、 get直接从数据库载入,不会延迟载入
get()和load()仅仅依据主键查询,不能依据其他字段查询,假设想依据非主键查询,能够使用HQL
7、 update()
① 、用来更新detached对象,更新完毕后转为为persistent状态(默认更新全部字段)
② 更新transient对象会报错(没有ID)
③ 更新自己设定ID的transient对象能够(默认更新全部字段)
④ persistent状态的对象,仅仅要设定字段不同的值,在session提交时,会自己主动更新(默认更新全部字段)
⑤ 更新部分更新的字段(更改了哪个字段就更新哪个字段的内容)
a) 方法1:update/updatable属性
xml:设定<property>标签的update属性,设置在更新时是否參数更新
<property name="name" update="false"/>
注意:update可取值为true(默认):參与更新;false:更新时不參与更新
annotateon:设定@Column的updatable属性值,true參与更新,false:不參与更新
@Column(updatable=false)
public String getTitle(){return title;}
注意:此种方法非常少用,由于它不灵活
b) 方法二:dynamic-update属性
注意:此方法眼下仅仅适合xml方式,JAP1.0annotation没有相应的
在实体类的映射文件里的<class>标签中,使用dynamic-update属性,true:表示改动了哪个字段就更新哪个字段,其他字段不更新,但要求是同一个session(不能跨session),假设跨了session同样会更新全部的字段内容。
<class name="com.bjsxt.Student" dynamic-update="true">
代码:
@Test
public void testUpdate5() {
Sessionsession = sessionFactory.getCurrentSession();
session.beginTransaction();
Student s =(Student)session.get(Student.class, 1);
s.setName("zhangsan5");
//提交时,会仅仅更新name字段,由于此时的s为persistent状态
session.getTransaction().commit();
s.setName("z4");
Sessionsession2 = sessionFactory.getCurrentSession();
session2.beginTransaction();
//更新时,会更新全部的字段,由于此时的s不是persistent状态
session2.update(s);
session2.getTransaction().commit(); }
假设须要跨session实现更新改动的部分字段,须要使用session.merget()方法,合并字段内容
@Test
public void testUpdate6() {
Sessionsession = sessionFactory.getCurrentSession();
session.beginTransaction();
Student s =(Student)session.get(Student.class, 1);
s.setName("zhangsan6");
session.getTransaction().commit();
s.setName("z4");
Sessionsession2 = sessionFactory.getCurrentSession();
session2.beginTransaction();
session2.merge(s);
session2.getTransaction().commit()}
这样尽管能够实现部分字段更新,但这样会多出一条select语句,由于在字段数据合并时,须要比較字段内容是否已变化,就须要从数据库中取出这条记录进行比較
c) 使用HQL(EJBQL)面向对象的查询语言(建议)
@Test
public void testUpdate7() {
Sessionsession = sessionFactory.getCurrentSession();
session.beginTransaction();
Query q =session.createQuery(
"update Student s sets.name='z5' where s.id = 1");
q.executeUpdate();
session.getTransaction().commit();
}
8、 saveOrUpdate()
在运行的时候hibernate会检查,假设对象在数据库中已经有相应的记录(是指主键),则会更新update,否则会增加数据save
9、 clear()
清除session缓存
不管是load还是get,都会首先查找缓存(一级缓存,也叫session级缓存),假设没有,才会去数据库查找,调用clear()方法能够强制清除session缓存
Session session= sessionFactory.getCurrentSession();
session.beginTransaction();
Teacher t =(Teacher)session.load(Teacher.class, 1);
System.out.println(t.getName());
session.clear();
Teacher t2 =(Teacher)session.load(Teacher.class, 1);
System.out.println(t2.getName());
session.getTransaction().commit();
注意:这样就会发出两条SELECT语句,假设把session.clear()去除,则仅仅会发出一条SELECT语句,由于第二次load时,是使用session缓存中ID为1的对象,而这个对象已经在第一次load到缓存中 了。
10、 flush()
在hibernate中也存在flush这个功能,在默认的情况下session.commit()之前时,事实上运行了一个flush命令。
Session.flush功能:
n 清理缓存;
n 运行sql(确定是运行SQL语句(确定生成update、insert、delete语句等),然后运行SQL语句。)
Session在什么情况下运行flush:
① 默认在事务提交时运行;
注意:flush时,能够自己设定,使用session.setFlushMode(FlushMode)来指定。
session.setFlushMode(FlushMode);
FlushMode的枚举值:
l FlushMode.ALWAYS:任务一条SQL语句,都会flush一次
l FlushMode.AUTO :自己主动flush(默认)
l FlushMode.COMMIT: 仅仅有在commit时才flush
l FlushMode.MANUAL:手动flush。
l FlushMode.NEVER :永远不flush 此选项在性能优化时可能用,比方session取数据为仅仅读时用,这样就
不须要与数据库同步了
注意:设置flush模式时,须要在session开启事务之前设置。
② 能够显示的调用flush;
③ 在运行查询前,如:iterate.
注:假设主键生成策略是uuid等不是由数据库生成的,则session.save()时并不会发出SQL语句,仅仅有flush时才会发出SQL语句,但假设主键生成策略是native由数据库生成的,则session.save的同一时候就发出SQL语句。
11、 evict()
比如:session.evict(user)
作用:从session缓存(EntityEntries属性)中逐出该对象
可是与commit同一时候使用,会抛出异常
session = HibernateUtils.getSession();
tx = session.beginTransaction();
User1 user = new User1();
user.setName("李四");
user.setPassword("123");
user.setCreateTime(new Date());
user.setExpireTime(new Date());
//利用Hibernate将实体类对象保存到数据库中,由于user主键生成策略採用的是uuid,所以调用完毕save后,仅仅是将user纳入session的管理,不会发出insert语句,可是id已经生成,session中的existsInDatabase状态为false
session.save(user);
session.evict(user);//从session缓存(EntityEntries属性)中逐出该对象
//无法成功提交,由于hibernate在清理缓存时,在session的暂时集合(insertions)中取出user对象进行insert操作后须要更新entityEntries属性中的existsInDatabase为true,而我们採用evict已经将user从session中逐出了,所以找不到相关数据,无法更新,抛出异常。
tx.commit();
解决在逐出session缓存中的对象不抛出异常的方法:
在session.evict()之前进行显示的调用session.flush()方法就能够了。
session.save(user);
//flush后hibernate会清理缓存,会将user对象保存到数据库中,将session中的insertions中的user对象清除,而且会设置session中的existsInDatabase状态为false
session.flush();
session.evict(user);//从session缓存(EntityEntries属性)中逐出该对象
//能够成功提交,由于hibernate在清理缓存时,在Session的insertions中集合中无法找到user对象所以不会发出insert语句,也不会更新session中existsInDatabase的状态。
tx.commit();
第15课 持久化对象的三种状态
一、 瞬时对象(Transient Object):
使用new操作符初始化的对象不是立马就持久的。它们的状态是瞬时的,也就是说它们没有不论什么跟数据库表相关联的行为,仅仅要应用不再引用这些对象(不再被不论什么其他对象所引用),它们的状态将会丢失,并由垃圾回收机制回收
二、 持久化对象(Persistent Object):
持久实例是不论什么具有数据库标识的实例,它有持久化管理器Session统一管理,持久实例是在事务中进行操作的----它们的状态在事务结束时同数据库进行同步。当事务提交时,通过运行SQL的INSERT、UPDATE和DELETE语句把内存中的状态同步到数据库中。
三、 离线对象(Detached Object):
Session关闭之后,持久化对象就变为离线对象。离线表示这个对象不能再与数据库保持同步,它们不再受hibernate管理。
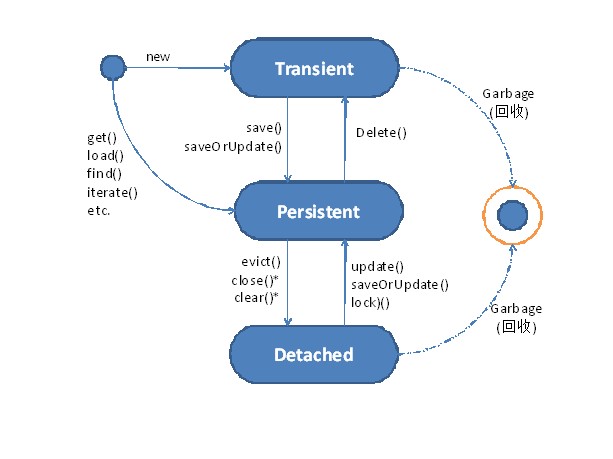
四、 三种状态的区分:
1、 有没有ID,(假设没有则是Transient状态)
2、 ID在数据库中有没有
3、 在内存里有没有(session缓存)
五、 总结:
Transient对象:随时可能被垃圾回收器回收(在数据库中没有于之相应的记录,应为是new初始化),而运行save()方法后,就变为Persistent对象(持久性对象),没有纳入session的管理
内存中一个对象,没有ID,缓存中也没有
Persistent对象:在数据库有存在的相应的记录,纳入session管理。在清理缓存(脏数据检查)的时候,会和数据库同步。
内存中有、缓存中有、数据库有(ID)
Detached对象:也可能被垃圾回收器回收掉(数据库中存在相应的记录,仅仅是没有不论什么对象引用它是指session引用),注引状态经过Persistent状态,没有纳入session的管理
内存有、缓存没有、数据库有(ID)
第16课 关系映射(重点)
注意:这里的关系是指:对象之间的关系,并非指数据库的关系,-----红色重要
存在以下关系:
1、 一对一
u 单向(主键、外键)
u 双向(主键、外键)
2、 一对多
u 单向
u 双向
3、 多对一
u 单向
u 双向
4、 多对多
u 单向
u 双向
5、 集合映射
u List
u Set
u Map
6、 继承关系(不重要)
u 单表
u 多表
u 一张主表、多张子表
7、 组件映射
u @Embeddable
u @Embedded
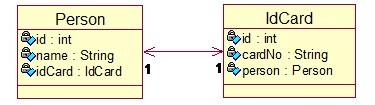
一、 一对一关联映射
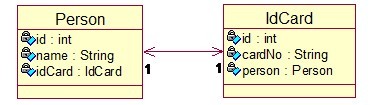
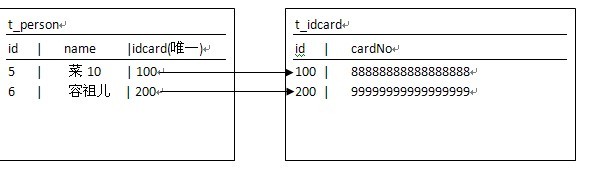
² 两个对象之间是一对一的关系,如Person-IdCard(人—身份证号)
² 有两种策略能够实现一对一的关联映射
Ø 主键关联:即让两个对象具有同样的主键值,以表明它们之间的一一相应的关系;数据库表不会有额外的字段来维护它们之间的关系,仅通过表的主键来关联。
Ø 唯一外键关联:外键关联,本来是用于多对一的配置,可是假设加上唯一的限制之后,也能够用来表示一对一关联关系。
对象模型
实体类:
/** 人-实体类 */
public class Person {
private int id;
private String name;
public int getId() {return id; }
public void setId(int id) {this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}
}
/**身份证-实体类*/
public class IdCard {
private int id;
private String cardNo;
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getCardNo(){ return cardNo;}
public void setCardNo(StringcardNo) {this.cardNo = cardNo;}
}
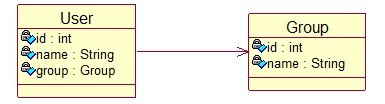
(一) 唯一外键关联-单向(unilateralism)
1、 说明:
人—-> 身份证号(PersonàIdCard),从IdCard看不到Person对象
2、 对象模型
须要在Person类中持有IdCard的一个引用idCard,则IdCard中没有Person的引用
3、 关系模型
关系模型目的:是实体类映射到关系模型(数据库中),是要求persion中增加一个外键指向idcard

4、 实体类:
注:IdCard是被引用对象,没有变化。
/** 人-实体类 */
public class Person {
private int id;
private String name;
private IdCard idCard;//引用IdCard对象
public int getId() {return id; }
public void setId(int id) {this.id = id;}
public String getName() {return name;}
public void setName(String name){this.name = name;}
public IdCard getIdCard() { return idCard;}
public void setIdCard(IdCardidCard) {this.idCard = idCard;}
}
5、 xml映射
IdCard实体类的映射文件:
由于IdCard是被引用的,所以没有什么特殊的映射
<hibernate-mapping>
<class name="com.wjt276.hibernate.IdCard" table="t_idcard">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="cardNo"/>
</class>
</hibernate-mapping>
Person实体类的映射文件
在映射时须要增加一个外键的映射,就是指定IdCard的引用的映射。这样映射到数据库时,就会自己主动增加一个字段并作用外键指向被引用的表
<hibernate-mapping>
<class name="com.wjt276.hibernate.Person" table="t_person">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name"/>
<!-- <many-to-one>:在多的一端(当前Person一端),增加一个外键(当前为idCard)指向一的一端(当前IdCard),但多对一 关联映射字段是能够反复的,所以须要增加一个唯一条件unique="true",这样就能够此字段唯一了。-->
<many-to-one name="idCard" unique="true"/>
</class>
</hibernate-mapping>
注意:这里的<many-to-one>标签中的name属性值并非数据库中的字段名,而是Person实体类中引用IdCard对象成员属性的getxxx方法后面的xxx(此处是getIdCard,所以是idCard),要求第一个字段小写。假设不指定column属性,则数据库中的字段名同name值
6、 annotateon注解映射
注意IdCard是被引用对象,除正常注解,无须要其他注解
/**身份证*/
@Entity
public class IdCard {
private int id;
private String cardNo;
@Id
@GeneratedValue
public int getId() {return id;}
public void setId(int id) { this.id = id;}
public String getCardNo(){return cardNo;}
public void setCardNo(StringcardNo) {this.cardNo = cardNo;}
}
而引用对象的实体类须要使用@OneToOne进行注解,来表面是一对一的关系
再使用@JoinColumn注解来为数据库表中这个外键指定个字段名称就能够了。假设省略@JoinColumn注解,则hibernate会自己主动为其生成一个字段名(好像是:被引用对象名称_被引用对象的主键ID)
/** 人-实体类 */
@Entity
public class Person {
private int id;
private IdCard idCard;//引用IdCard对象
private String name;
@Id
@GeneratedValue
public int getId() {return id;}
@OneToOne//表示一对一的关系
@JoinColumn(name="idCard")//为数据中的外键指定个名称
public IdCard getIdCard(){ return idCard;}
public String getName() {return name;}
public void setId(int id) {this.id = id;}
public void setIdCard(IdCardidCard) {this.idCard = idCard;}
public void setName(Stringname) {this.name = name;}
}
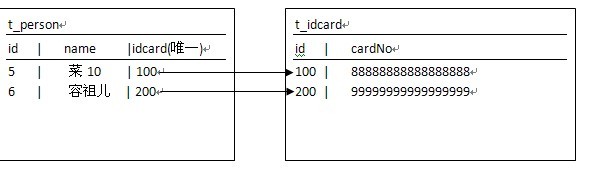
7、 生成的SQL语句:
create tableIdCard (
id integernot null auto_increment,
cardNo varchar(255),
primary key(id)
)
create tablePerson (
id integernot null auto_increment,
namevarchar(255),
idCardinteger,//新增加的外键
primary key(id)
)
alter tablePerson
add indexFK8E488775BE010483 (idCard),
addconstraint FK8E488775BE010483
foreign key(idCard) //外键
referencesIdCard (id)//引用IdCard的id字段

8、 存储測试
Session session = sf.getCurrentSession();
IdCard idCard = new IdCard();
idCard.setCardNo("88888888888888888888888");
session.beginTransaction();
// 假设先不保存idCard,则出抛出Transient异常,由于idCard不是持久化状态。
session.save(idCard);
Person person = new Person();
person.setName("菜10");
person.setIdCard(idCard);
session.save(person);
session.getTransaction().commit();
(二) 唯一外键关联-双向
1、 说明:
人<—-> 身份证号(Person<->IdCard)双向:互相持有对方的引用
2、 对象模型:
3、 关系模型:
关系模型没有任务变化,同单向
4、 实体类:
实体类,仅仅是相互持有对象的引用,而且要求getter和setter方法
5、 xml映射
Person实体类映射文件:同单向的没有变化
IdCard实体类映射文件:假设使用同样的方法映射,这样就会在表中也增加一个外键指向对象,但对象已经有一个外键指向自己了,这样就造成了庸字段,由于不须要在表另外增加字段,而是让hibernate在载入这个对象时,会依据对象的ID到对方的表中查询外键等于这个ID的记录,这样就把对象载入上来了。也同样须要使用<one-to-one>标签来映射,可是须要使用property-ref属性来指定对象持有你自己的引用的成员属性名称(是gettxxxx后面的名称),这样在生成数据库表时,就不会再增加一个多于的字段了。数据载入时hibernate会依据这些配置自己载入数据
<class name="com.wjt276.hibernate.IdCard" table="idcard">
<id name="id" column="id">
<generator class="native"/></id>
<property name="cardNo"/>
<!--<one-to-one>标签:告诉hibernate怎样载入其关联对象
property-ref属性:是依据哪个字段进行比較载入数据 -->
<one-to-one name="person" property-ref="idCard"/>
</class>
一对一 唯一外键 关联映射 双向 须要在还有一端(当前IdCard),增加<one-to-one>标签,指示hibernate怎样载入其关联对象(或引用对象),默认依据主键载入(载入person),外键关联映射中,由于两个实体採用的是person的外键来维护的关系,所以不能指定主键载入person,而要依据person的外键载入,所以採用例如以下映射方式:
<!--<one-to-one>标签:告诉hibernate怎样载入其关联对象
property-ref属性:是依据哪个字段进行比較载入数据 -->
<one-to-one name="person" property-ref="idCard"/>
6、 annotateon注解映射
Person注解映射同单向一样
IdCard注解映射例如以下:使用@OneToOne注解来一对一,但这样会在表中多加一个字段,由于须要使用对象的外键来载入数据,所以使用属性mappedBy属性在实现这个功能
@Entity
public class IdCard {
private int id;
private String cardNo;
private Person person;
//mappedBy:在指定当前对象在被Person对象的idCard做了映射了
//此值:当前对象持有引用对象中引用当前对象的成员属性名称(getXXX后的名称)
//由于Person对象的持有IdCard对象的方法是getIdCard()由于须要小写,所以为idCard
@OneToOne(mappedBy="idCard")
public Person getPerson(){return person;}
public void setPerson(Person person){this.person = person;}
@Id
@GeneratedValue
public int getId() {return id;}
public void setId(int id) { this.id = id;}
public String getCardNo(){return cardNo;}
public void setCardNo(StringcardNo) {this.cardNo = cardNo;}
}
7、 生成SQL语句
由于关系模型没有变化,也就是数据库的结构没有变化,仅仅是在数据载入时须要相互载入对方,这由hibernate来完毕。由于生成的sql语句同单向一样。
8、 存储測试
存储同单向一样
9、 总结:
规律:凡是双向关联,必设mappedBy
(三) 主键关联-单向(不重要)
主键关联:即让两个对象具有同样的主键值,以表明它们之间的一一相应的关系;数据库表不会有额外的字段来维护它们之间的关系,仅通过表的主键来关联。
1、 说明:
人—-> 身份证号(PersonàIdCard),从IdCard看不到Person对象
2、 对象模型
站在人的角度来看,对象模型与唯一外键关联一个,仅仅是关系模型不同
3、 关系模型
由于是person引用idcard,所以idcard要求先有值。而person的主键值不是自己生成的。而是參考idcard的值,person表中即是主键,同一时候也是外键
4、 实体类:
实体类同 一对一 唯一外键关联的实体类一个,在person对象中持有idcard对象的引用(代码见唯一外键关系)
5、 xml映射
IdCard映射文件,先生成ID
<class name="com.wjt276.hibernate.IdCard" table="t_idcard">
<id name="id"column="id">
<generator class="native"/>
</id>
<property name="cardNo"/>
</class>
Person实体类映射文件,ID是依据IdCard主键值
<class name="com.wjt276.hibernate.Person"table="t_person">
<id name="id"column="id">
<!--由于主键不是自己生成的,而是作为一个外键(来源于其他值),所以使用foreign生成策略
foreign:使用另外一个相关联的对象的标识符,通常和<one-to-one>联合起来使用。再使用元素<param>的属性值指定相关联对象(这里Person相关联的对象为idCard,则标识符为idCard的id)为了能够在载入person数据同一时候载入IdCard数据,所以须要使用一个标签<one-to-one>来设置这个功能。 -->
<generator class="foreign">
<!-- 元素<param>属性name的值是固定为property -->
<param name="property">idCard</param>
</generator>
</id>
<property name="name"/>
<!-- <one-to-one>标签
表示怎样载入它的引用对象(这里引用对象就指idCard这里的name值是idCard),同一时候也说是一对一的关系。 默认方式是依据主键载入(把person中的主键取出再到IdCard中来取相关IdCard数据。) 我们也说过此主键也作为一个外键引用 了IdCard,所以须要加一个数据库限制(外键约束)constrained="true" -->
<one-to-one name="idCard"constrained="true"/>
6、 annotateon注解映射
Person实体类注解
方法:仅仅须要使用@OneToOne注解一对一关系,再使用@PrimaryKeyJoinColumn来注解主键关系映射。
@Entity
public class Person {
private int id;
private IdCard idCard;//引用IdCard对象
private String name;
@Id
public int getId() {return id;}
@OneToOne//表示一对一的关系
@PrimaryKeyJoinColumn//注解主键关联映射
public IdCard getIdCard(){ return idCard;}
public String getName() {return name;}
public void setId(int id) {this.id = id;}
public void setIdCard(IdCard idCard){this.idCard = idCard;}
public void setName(Stringname) {this.name = name;}
}
IdCard实体类,不须要持有对象的引用,正常注解就能够了。
7、 生成SQL语句
生成的两个表并没有多余的字段,由于是通过主键在关键的
create tableIdCard (
id integernot null auto_increment,
cardNovarchar(255),
primary key (id)
)
create tablePerson (
id integernot null,
namevarchar(255),
primary key(id)
)
alter table person
add index FK785BED805248EF3 (id),
add constraint FK785BED805248EF3
foreign key (id) references idcard (id)
注意:annotation注解后,并没有映射出外键关键的关联,而xml能够映射,是主键关联不重要
8、 存储測试
session = HibernateUtils.getSession();
tx = session.beginTransaction();
IdCard idCard = new IdCard();
idCard.setCardNo("88888888888888888888888");
Person person = new Person();
person.setName("菜10");
person.setIdCard(idCard);
//不会出现TransientObjectException异常
//由于一对一主键关键映射中,默认了cascade属性。
session.save(person);
tx.commit();
9、 总结
让两个实体对象的ID保持同样,这样能够避免多余的字段被创建
<id name="id"column="id">
<!—person的主键来源idcard,也就是共享idCard的主键-->
<generator class="foreign">
<param name="property">idCard</param>
</generator>
</id>
<property name="name"/>
<!—one-to-one标签的含义:指示hibernate怎么载入它的关联对象,默认依据主键载入
constrained="true",表面当前主键上存在一个约束:person的主键作为外键參照了idCard-->
<one-to-one name="idCard" constrained="true"/>
(四) 主键关联-双向(不重要)
主键关联:即让两个对象具有同样的主键值,以表明它们之间的一一相应的关系;数据库表不会有额外的字段来维护它们之间的关系,仅通过表的主键来关联。
主键关联映射,实际是数据库的存储结构并没有变化,仅仅是要求双方都能够持有对象引用,也就是说实体模型变化,实体类都相互持有对方引用。
另外映射文件也变化了。

1、 xml映射
Person实体类映射文件不变,
IdCard例如以下:
<class name="com.wjt276.hibernate.IdCard" table="t_idcard">
<id name="id" column="id">
<generator class="native"/> </id>
<property name="cardNo"/>
<!—one-to-one标签的含义:指示hibernate怎么载入它的关联对象(这里的关联对象为person),默认依据主键载入-->
<one-to-one name="person"/>
</class>
2、 annotateon注解映射:
Person的注解不变,同主键单向注解
IdCard注解,仅仅须要在持有对象引用的getXXX前加上
@OneToOne(mappedBy="idCard") 例如以下:
@Entity
public class IdCard {
private int id;
private String cardNo;
private Person person;
@OneToOne(mappedBy="idCard")
public Person getPerson(){
return person;
}}
(五) 联合主键关联(Annotation方式)
实现上联合主键的原理同唯一外键关联-单向一样,仅仅是使用的是@JoinColumns,而不是@JoinColumn,实体类注解例如以下:
@OneToOne
@JoinColumns(
{
@JoinColumn(name="wifeId", referencedColumnName="id"),
@JoinColumn(name="wifeName", referencedColumnName="name")
}
)
public WifegetWife() {
return wife;
}
注意:@oinColumns注解联合主键一对一联系,然后再使用@JoinColumn来注解当前表中的外键字段名,并指定关联哪个字段,使用referencedColumnName指定哪个字段的名称
二、 component(组件)关联映射
(一) Component关联映射:
眼下有两个类例如以下:
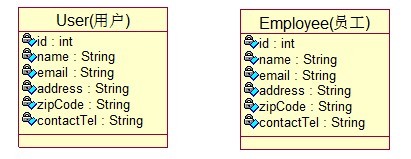
大家发现用户与员工存在非常多同样的字段,可是两者有不能够是同一个类中,这样在实体类中每次都要输入非常多信息,如今把联系信息抽取出来成为一个类,然后在用户、员工对象中引用就能够,例如以下:

值对象没有标识,而实体对象具有标识,值对象属于某一个实体,使用它反复使用率提升,而且更清析。
以上关系的映射称为component(组件)关联映射
在hibernate中,component是某个实体的逻辑组成部分,它与实体的根本差别是没有oid,component能够成为是值对象(DDD)。
採用component映射的优点:它实现了对象模型的细粒度划分,层次会更加分明,复用率会更高。
(二) User实体类:
public class User {
private int id;
private String name;
private Contact contact;//值对象的引用
public int getId() {return id;}
public void setId(int id) { this.id = id;}
public String getName() { return name;}
public void setName(Stringname) { this.name = name;}
public ContactgetContact() { return contact;}
public void setContact(Contactcontact) { this.contact = contact;}
}
(三) Contact值对象:
public class Contact {
private String email;
private String address;
private String zipCode;
private String contactTel;
public String getEmail(){ return email;}
public void setEmail(Stringemail) { this.email = email; }
public StringgetAddress() {return address;}
public void setAddress(Stringaddress) {this.address = address;}
public StringgetZipCode() {return zipCode;}
public void setZipCode(StringzipCode) {this.zipCode = zipCode;}
public StringgetContactTel() { return contactTel;}
public voidsetContactTel(String contactTel){this.contactTel = contactTel;}
}
(四) xml--User映射文件(组件映射):
<hibernate-mapping>
<class name="com.wjt276.hibernate.User" table="t_user">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name" column="name"/>
<!-- <component>标签用于映射Component(组件)关系
其内部属性正常映射。
-->
<component name="contact">
<property name="email"/>
<property name="address"/>
<property name="zipCode"/>
<property name="contactTel"/>
</component>
</class>
</hibernate-mapping>
(五) annotateon注解
使用@Embedded用于注解组件映射,表示嵌入对象的映射
@Entity
public class User {
private int id;
private String name;
private Contact contact;//值对象的引用
@Id
@GeneratedValue
public int getId() { return id;}
@Embedded//用于注解组件映射,表示嵌入对象的映射
public ContactgetContact() {return contact;}
public void setContact(Contactcontact) {this.contact = contact;}
Contact类是值对象,不是实体对象,是属于实体类的某一部分,因此没有映射文件
(六) 导出数据库输出SQL语句:
create table User (
id integer not null auto_increment,
address varchar(255),
contactTel varchar(255),
email varchar(255),
zipCode varchar(255),
name varchar(255),
primary key (id)
)
(七) 数据表结构:

注:尽管实体类没有基本联系信息,仅仅是有一个引用,但在映射数据库时全部都映射进来了。以后值对象能够反复使用,仅仅要在相应的实体类中增加一个引用就可以。
(八) 组件映射数据保存:
session =HibernateUtils.getSession();
tx =session.beginTransaction();
User user= new User();
user.setName("10");
Contactcontact = new Contact();
contact.setEmail("wjt276");
contact.setAddress("aksdfj");
contact.setZipCode("230051");
contact.setContactTel("3464661");
user.setContact(contact);
session.save(user);
tx.commit();
实体类中引用值对象时,不用先保存值对象,由于它不是实体类,它仅仅是一个附属类,而session.save()中保存的对象是实体类。
三、 多对一 –单向
场景:用户和组;从用户角度来,多个用户属于一个组(多对一 关联)
使用hibernate开发的思路:先建立对象模型(领域模型),把实体抽取出来。
眼下两个实体:用户和组两个实体,多个用户属于一个组,那么一个用户都会相应于一个组,所以用户实体中应该有一个持有组的引用。
(一) 对象模型图:
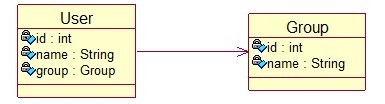
(二) 关系模型:
(三) 关联映射的本质:
将关联关系映射到数据库,所谓的关联关系是对象模型在内存中一个或多个引用。
(四) 实体类
User实体类:
public class User {
private int id;
private String name;
private Group group;
public Group getGroup() {return group; }
public void setGroup(Group group) {this.group = group;}
public int getId() {return id; }
public void setId(int id) { this.id = id;}
public String getName() {return name;}
public void setName(Stringname) { this.name = name;}}
Group实体类:
public class Group {
private int id;
private String name;
public int getId() {return id;}
public void setId(int id) { this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}
}
实体类建立完后,開始创建映射文件,先建立简单的映射文件:
(五) xml方式:映射文件:
1、 Group实体类的映射文件:
<hibernate-mapping>
<class name="com.wjt276.hibernate.Group" table="t_group">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name"/>
</class>
</hibernate-mapping>
2、 User实体类的映射文件:
<hibernate-mapping>
<class name="com.wjt276.hibernate.User" table="t_user">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name"/>
<!--<many-to-one> 关联映射 多对一的关系
name:是维护的属性(User.group),这样表示在多的一端表里增加一个字段名称为group,
但group与SQL中的关键字反复,所以须要又一次命名字段(column="groupid").这样这个字段(groupid)会作为外键參照数据库中group表(t_group也叫一的一端),也就是就在多的一 端增加一个外键指向一的一端。 -->
<many-to-one name="group" column="groupid"/>
</class>
</hibernate-mapping>
3、 ※<many-to-one>标签※:
比如:<many-to-one name="group" column="groupid"/>
<many-to-one> 关联映射 多对一的关系
name:是维护的属性(User.group),这样表示在多的一端表里增加一个字段名称为group,但group与SQL中的关键字反复,所以须要又一次命名字段(column="groupid").这样这个字段(groupid)会作为外键參照数据库中group表(t_group也叫一的一端),也就是就在多的一端增加一个外键指向一的一端。
这样导出至数据库会生成下列语句:
alter table t_user drop foreign keyFKCB63CCB695B3B5AC
drop table if exists t_group
drop table if exists t_user
create table t_group (id integer not nullauto_increment, name varchar(255), primary key (id))
create table t_user (id integer not nullauto_increment, name varchar(255), groupid integer,primary key (id))
alter table t_user add index FKCB63CCB695B3B5AC (groupid), add constraint FKCB63CCB695B3B5AC foreign key (groupid) referencest_group (id)
(六) annotation
Group(一的一端)注解仅仅须要正常的注解就能够了,由于在实体类中它是被引用的。
User*(多的一端):@ManyToOne来注解多一对的关键,而且用@JoinColumn来指定外键的字段名
@Entity
public class User {
private int id;
private String name;
private Group group;
@ManyToOne
@JoinColumn(name="groupId")
public Group getGroup() {
return group;
}
(七) 多对一 存储(先存储group(对象持久化状态后,再保存user)):
session = HibernateUtils.getSession();
tx =session.beginTransaction();
Groupgroup = new Group();
group.setName("wjt276");
session.save(group); //存储Group对象。
Useruser1 = new User();
user1.setName("菜10");
user1.setGroup(group);//设置用户所属的组
Useruser2 = new User();
user2.setName("容祖儿");
user2.setGroup(group);//设置用户所属的组
//開始存储
session.save(user1);//存储用户
session.save(user2);
tx.commit();//提交事务
运行后hibernate运行以下SQL语句:
Hibernate: insert into t_group (name) values (?)
Hibernate: insert into t_user (name, groupid) values (?, ?)
Hibernate: insert into t_user (name, groupid) values (?, ?)
注意:假设上面的session.save(group)不运行,则存储不存储不成功。则抛出TransientObjectException异常。
由于Group为Transient状,Object的id没有分配值。2610644
结果:persistent状态的对象是不能引用Transient状态的对象
以上代码操作,必须首先保存group对象,再保存user对象。我们能够利用cascade(级联)方式,不须要先保存group对象。而是直接保存user对象,这样就能够在存储user之前先把group存储了。
利用cascade属性是解决TransientObjectException异常的一种手段。
(八) 重要属性-cascade(级联):
级联的意思是指定两个对象之间的操作联运关系,对一个 对象运行了操作之后,对其指定的级联对象也须要运行同样的操作,取值:all、none、save_update、delete
1、 all:代码在全部的情况下都运行级联操作
2、 none:在全部情况下都不运行级联操作
3、 save-update:在保存和更新的时候运行级联操作
4、 delete:在删除的时候运行级联操作。
1、 xml
比如:<many-to-one name="group"column="groupid" cascade="save-update"/>
2、 annotation
cascade属性:其值: CascadeType.ALL 全部
CascadeType.MERGE save+ update
CascadeType.PERSIST
CascadeType.REFRESH
CascadeType.REMOVE
比如:
@ManyToMany(cascade={CascadeType.ALL})
注意:cascade仅仅是帮我们省了编程的麻烦而已,不要把它的作用看的太大
(九) 多对一 载入数据
代码例如以下:
session = HibernateUtils.getSession();
tx =session.beginTransaction();
Useruser = (User)session.load(User.class, 3);
System.out.println("user.name=" + user.getName());
System.out.println("user.group.name=" + user.getGroup().getName());
//提交事务
tx.commit();
运行后向SQL发出以下语句:
Hibernate: select user0_.id as id0_0_,user0_.name as name0_0_, user0_.groupid as groupid0_0_ from t_user user0_ whereuser0_.id=?
Hibernate: select group0_.id as id1_0_,group0_.name as name1_0_ from t_group group0_ where group0_.id=?
能够载入Group信息:由于採用了<many-to-one>这个标签,这个标签会在多的一端(User)加一个外键,指向一的一端(Group),也就是它维护了从多到一的这样的关系,多指向一的关系。当你载入多一端的数据时,它就能把一的这一端数据载入上来。当载入User对象后hibernate会依据User对象中的groupid再来载入Group信息给User对象中的group属性。
四、 一对多 - 单向
在对象模型中,一对多的关联关系,使用集合来表示。
实例场景:班级对学生;Classes(班级)和Student(学生)之间是一对多的关系。
(一) 对象模型:

(二) 关系模型:

一对多关联映射利用了多对一关联映射原理。
(三) 多对一、一对多的差别:
多对一关联映射:在多的一端增加一个外键指向一的一端,它维护的关系是多指向一的。
一对多关联映射:在多的一端增加一个外键指向一的一端,它维护的关系是一指向多的。
两者使用的策略是一样的,仅仅是各自所站的角度不同。
(四) 实体类
Classes实体类:
public class Classes {
private int id;
private String name;
//一对多通常使用Set来映射,Set是不可反复内容。
//注意使用Set这个接口,不要使用HashSet,由于hibernate有延迟载入,
private Set<Student>students = new HashSet<Student>();
public int getId() {return id; }
public void setId(int id) {this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}
}
Student实体类:
public class Student {
private int id;
private String name;
public int getId() {return id;}
public void setId(int id) { this.id = id;}
public String getName() {return name;}
public void setName(Stringname) { this.name = name;}
}
(五) xml方式:映射
1、 Student映射文件:
<hibernate-mapping>
<class name="com.wjt276.hibernate.Student" table="t_student">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name" column="name"/>
</class>
</hibernate-mapping>
2、 Classes映射文件:
<hibernate-mapping>
<class name="com.wjt276.hibernate.Classes" table="t_classess">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name" column="name"/>
<!--<set>标签 映射一对多(映射set集合),name="属性集合名称",然后在用<key>标签,在多的一端增加一个外键(column属性指定列名称)指向一的一端,再採用<one-to-many>标签说明一对多,还指定<set>标签中name="students"这个集合中的类型要使用完整的类路径(比如:class="com.wjt276.hibernate.Student") -->
<set name="students">
<key column="classesid"/>
<one-to-many class="com.wjt276.hibernate.Student"/>
</set>
</class>
</hibernate-mapping>
(六) annotateon注解
一对多 多的一端仅仅须要正常注解就能够了。
须要在一的一端进行注解一对多的关系。
使用@OneToMany
@Entity
public class Classes {
private int id;
private String name;
// 一对多通常使用Set来映射,Set是不可反复内容。
// 注意使用Set这个接口,不要使用HashSet,由于hibernate有延迟载入,
private Set<Student>students = new HashSet<Student>();
@OneToMany//进行注解为一对多的关系
@JoinColumn(name="classesId")//在多的一端注解一个字段(名为classessid)
public Set<Student>getStudents() {
return students;
}
(七) 导出至数据库(hbmàddl)生成的SQL语句:
create table t_classes (id integer not null auto_increment, namevarchar(255), primary key (id))
create table t_student (id integer not null auto_increment, namevarchar(255), classesid integer, primary key (id))
alter table t_student add index FK4B90757070CFE27A (classesid), add constraint FK4B90757070CFE27A foreign key (classesid) referencest_classes (id)
(八) 一对多 单向存储实例:
session = HibernateUtils.getSession();
tx =session.beginTransaction();
Studentstudent1 = new Student();
student1.setName("10");
session.save(student1);//必需先存储,否则在保存classess时出错.
Studentstudent2 = new Student();
student2.setName("祖儿");
session.save(student2);//必需先存储,否则在保存classess时出错.
Set<Student>students = new HashSet<Student>();
students.add(student1);
students.add(student2);
Classesclasses = new Classes();
classes.setName("wjt276");
classes.setStudents(students);
session.save(classes);
tx.commit();
(九) 生成的SQL语句:
Hibernate: insert into t_student (name) values (?)
Hibernate: insert into t_student (name) values (?)
Hibernate: insert into t_classes (name) values (?)
Hibernate: update t_student set classesid=? where id=?
Hibernate: update t_student set classesid=? where id=?
(十) 一对多,在一的一端维护关系的缺点:
由于是在一的一端维护关系,这样会发出多余的更新语句,这样在批量数据时,效率不高。
还有一个,当在多的一端的那个外键设置为非空时,则在增加多的一端数据时会错误发生,数据存储不成功。
(十一) 一对多 单向数据载入:
session = HibernateUtils.getSession();
tx =session.beginTransaction();
Classesclasses = (Classes)session.load(Classes.class, 2);
System.out.println("classes.name=" + classes.getName());
Set<Student> students = classes.getStudents();
for(Iterator<Student> iter = students.iterator();iter.hasNext();){
Studentstudent = iter.next();
System.out.println(student.getName());
}
tx.commit();
(十二) 载入生成SQL语句:
Hibernate: select classes0_.id as id0_0_, classes0_.name as name0_0_ fromt_classes classes0_ where classes0_.id=?
Hibernate: select students0_.classesid as classesid1_, students0_.id asid1_, students0_.id as id1_0_, students0_.name as name1_0_ from t_studentstudents0_ where students0_.classesid=?
五、 一对多 - 双向
是载入学生时,能够把班级载入上来。当然载入班级也能够把学生载入上来
1、 在学生对象模型中,要持有班级的引用,并改动学生映射文件就能够了。。
2、 存储没有变化
3、 关系模型也没有变化
(一) xml方式:映射
学生映射文件改动后的:
<class name="com.wjt276.hibernate.Student" table="t_student">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name" column="name"/>
<!--使用多对一标签映射 一对多双向,下列的column值必需与多的一端的key字段值一样。-->
<many-to-one name="classes" column="classesid"/>
</class>
假设在一对多的映射关系中採用一的一端来维护关系的话会存在以下两个缺点:①假设多的一端那个外键设置为非空时,则多的一端就存不进数据;②会发出多于的Update语句,这样会影响效率。所以经常使用对于一对多的映射关系我们在多的一端维护关系,并让多的一端维护关系失效(见以下属性)。
代码:
<class name="com.wjt276.hibernate.Classes" table="t_classes">
<id name="id"column="id">
<generator class="native"/>
</id>
<property name="name"column="name"/>
<!--
<set>标签 映射一对多(映射set集合),name="属性集合名称"
然后在用<key>标签,在多的一端增加一个外键(column属性指定列名称)指向一的一端
再採用<one-to-many>标签说明一对多,还指定<set>标签中name="students"这个集合中的类型
要使用完整的类路径(比如:class="com.wjt276.hibernate.Student")
inverse="false":一的一端维护关系失效(反转) :false:能够从一的一端维护关系(默认);true:从一的一端维护关系失效,这样假设在一的一端维护关系则不会发出Update语句。 -->
<set name="students"inverse="true">
<key column="classesid"/>
<one-to-many class="com.wjt276.hibernate.Student"/>
</set>
</class>
(二) annotateon方式注解
首先须要在多的一端持有一的一端的引用
由于一对多的双向关联,就是多对一的关系,我们一般在多的一端来维护关系,这样我们须要在多的一端实体类进行映射多对一,而且设置一个字段,而在一的一端仅仅须要进行映射一对多的关系就能够了,例如以下:
多的一端
@Entity
public class Student {
private int id;
private String name;
private Classes classes;
@ManyToOne
@JoinColumn(name="classesId")
public ClassesgetClasses() {
return classes;
}
一的一端
@Entity
public class Classes {
private int id;
private String name;
// 一对多通常使用Set来映射,Set是不可反复内容。
// 注意使用Set这个接口,不要使用HashSet,由于hibernate有延迟载入,
private Set<Student>students = new HashSet<Student>();
@OneToMany(mappedBy="classes")//进行注解为一对多的关系
public Set<Student>getStudents() {
return students;}
(三) 数据保存:
一对多 数据保存,从多的一端进行保存:
session = HibernateUtils.getSession();
tx =session.beginTransaction();
Classesclasses = new Classes();
classes.setName("wjt168");
session.save(classes);
Studentstudent1 = new Student();
student1.setName("10");
student1.setClasses(classes);
session.save(student1);
Studentstudent2 = new Student();
student2.setName("祖儿");
student2.setClasses(classes);
session.save(student2);
//提交事务
tx.commit();
注意:一对多,从多的一端保存数据比从一的一端保存数据要快,由于从一的一端保存数据时,会多更新多的一端的一个外键(是指定一的一端的。)
(四) 关于inverse属性:
inverse主要用在一对多和多对多双向关联上,inverse能够被设置到集合标签<set>上,默认inverse为false,所以我们能够从一的一端和多的一端维护关联关系,假设设置inverse为true,则我们仅仅能从多的一端维护关联关系。
注意:inverse属性,仅仅影响数据的存储,也就是持久化
(五) Inverse和cascade差别:
Inverse是关联关系的控制方向
Casecade操作上的连锁反应
(六) 一对多双向关联映射总结:
在一的一端的集合上使用<key>,在对方表中增加一个外键指向一的一端
在多的一端採用<many-to-one>
注意:<key>标签指定的外键字段必须和<many-to-one>指定的外键字段一致,否则引用字段的错误
假设在一的一端维护一对多的关系,hibernate会发出多余的update语句,所以我们一般在多的一端来维护关系。
六、 多对多 - 单向
Ø 一般的设计中,多对多关联映射,须要一个中间表
Ø Hibernate会自己主动生成中间表
Ø Hibernate使用many-to-many标签来表示多对多的关联
Ø 多对多的关联映射,在实体类中,跟一对多一样,也是用集合来表示的。
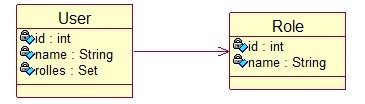
(一) 实例场景:
用户与他的角色(一个用户拥有多个角色,一个角色还能够属于多个用户)
(二) 对象模型:
(三) 关系模型:

(四) 实体类
Role实体类:
public class Role {
private int id;
private String name;
public int getId() return id;}
public void setId(int id) {this.id = id;}
public String getName() {return name;}
public void setName(Stringname) { this.name = name;}}
User实体类:
public class User {
private int id;
private String name;
private Set<User> roles = newHashSet<User>();// Role对象的集合
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}
public Set<User>getRoles() {return roles;}
public voidsetRoles(Set<User> roles) {this.roles = roles; }
(五) xml方式:映射
Role映射文件:
<class name="com.wjt276.hibernate.Role" table="t_role">
<id name="id">
<generator class="native"/>
</id>
<property name="name" column="name"/>
</class>
User映射文件:
<class name="com.wjt276.hibernate.User" table="t_user">
<id name="id"column="id">
<generator class="native"/>
</id>
<property name="name"/>
<!--使用<set>标签映射集合(set),标签中的name值为对象属性名(集合roles),而使用table属性是用于生成第三方表名称,例:table="t_user_role",可是第三方面中的字段是自己主动增加的,作为外键分别指向其他表。
所以表<key>标签设置,例:<key column="userid"/>,意思是:在第三方表(t_user_role)中增加一个外键而且指向当前的映射实体类所相应的表(t_user).使用<many-to-many>来指定此映射集合所对象的类(实例类),而且使用column属性增加一个外键指向Role实体类所相应的表(t_role) -->
<setname="roles" table="t_user_role">
<key column="userid"/>
<many-to-many class="com.wjt276.hibernate.Role" column="roleid"/>
</set>
</class>
(六) annotation注解方式
注意:由于是多对多单向(当然用户拥有多个角色,一个角色也可属性多个用户,但这里角色看不到用户),所以角色仅仅须要正常注解就能够了,
如今要使用@ManyToMany来注解多对多的关系,并使用@JoinTabel来注解第三方表的名称,再使用joinColumns属性来指定当前对象在第三方表中的字段名,而且这个字段会指向当前类相相应的表,最后再用inverseJoinColumns来指定当前类持有引用的实体类在第三方表中的字段名,而且指向被引用对象相相应的表,例如以下:
@Entity
public class User {
private int id;
private String name;
private Set<User> roles = new HashSet<User>();// Role对象的集合 @Id
@GeneratedValue
public int getId() {return id;}
@ManyToMany
@JoinTable(name="u_r",//使用@JoinTable标签的name属性注解第三方表名称
joinColumns={@JoinColumn(name="userId")},
//使用joinColumns属性来注解当前实体类在第三方表中的字段名称并指向该对象
inverseJoinColumns={@JoinColumn(name="roleId")}
//使用inverseJoinColumns属性来注解当前实体类持有引用对象在第三方表中的字段名称并指向被引用对象表
)
public Set<User> getRoles() {return roles;}
(七) 生成SQL语句
create table t_role (id integer not null auto_increment, namevarchar(255), primary key (id))
create table t_user (id integer not null auto_increment, namevarchar(255), primary key (id))
create table t_user_role (userid integer not null, roleid integer notnull, primary key (userid, roleid))
alter table t_user_role add index FK331DEE5F1FB4B2D4 (roleid), add constraint FK331DEE5F1FB4B2D4 foreign key (roleid) referencest_role (id)
alter table t_user_role add index FK331DEE5F250A083E(userid), add constraint FK331DEE5F250A083E foreign key (userid) referencest_user (id)
注:依据DDL语句能够看出第三方表的主键是一个复合主键(primary key (userid, roleid)),也就是说记录不能够有同样的数据。
(八) 数据库表及结构:
(九) 多对多关联映射 单向数据存储:
session = HibernateUtils.getSession();
tx =session.beginTransaction();
Role r1 = new Role();
r1.setName("数据录入人员");
session.save(r1);
Role r2 = new Role();
r2.setName("商务主管");
session.save(r2);
Role r3 = new Role();
r3.setName("大区经理");
session.save(r3);
User u1 = new User();
u1.setName("10");
Set<Role>u1Roles = new HashSet<Role>();
u1Roles.add(r1);
u1Roles.add(r2);
u1.setRoles(u1Roles);
User u2 = new User();
u2.setName("祖儿");
Set<Role>u2Roles = new HashSet<Role>();
u2Roles.add(r2);
u2Roles.add(r3);
u2.setRoles(u2Roles);
User u3 = new User();
u3.setName("成龙");
Set<Role>u3Roles = new HashSet<Role>();
u3Roles.add(r1);
u3Roles.add(r2);
u3Roles.add(r3);
u3.setRoles(u3Roles);
session.save(u1);
session.save(u2);
session.save(u3);
tx.commit();
发出SQL语句:
Hibernate: insert into t_role (name) values (?)
Hibernate: insert into t_role (name) values (?)
Hibernate: insert into t_role (name) values (?)
Hibernate: insert into t_user (name) values (?)
Hibernate: insert into t_user (name) values (?)
Hibernate: insert into t_user (name) values (?)
Hibernate: insert into t_user_role (userid, roleid)values (?, ?)
Hibernate: insert into t_user_role (userid, roleid)values (?, ?)
Hibernate: insert into t_user_role (userid, roleid)values (?, ?)
Hibernate: insert into t_user_role (userid, roleid)values (?, ?)
Hibernate: insert into t_user_role (userid, roleid)values (?, ?)
Hibernate: insert into t_user_role (userid, roleid)values (?, ?)
Hibernate: insert into t_user_role (userid, roleid)values (?, ?)
注:前三条SQL语句,增加Role记录,第三条到第六条增加User,最后7条SQL语句是在向第三方表(t_user_role)中增加多对多关系(User与Role关系)
(十) 多对多关联映射 单向数据载入:
session =HibernateUtils.getSession();
tx =session.beginTransaction();
User user =(User)session.load(User.class, 1);
System.out.println("user.name=" + user.getName());
for(Iterator<Role> iter = user.getRoles().iterator();iter.hasNext();){
Rolerole = (Role) iter.next();
System.out.println(role.getName());
}
tx.commit();
生成SQL语句:
Hibernate: select user0_.id as id0_0_, user0_.name as name0_0_ from t_useruser0_ where user0_.id=?
user.name=10
Hibernate: select roles0_.userid as userid1_, roles0_.roleid as roleid1_,role1_.id as id2_0_, role1_.name as name2_0_ from t_user_role roles0_ leftouter join t_role role1_ on roles0_.roleid=role1_.id where roles0_.userid=?
商务主管
数据录入人员
七、 多对多 - 双向
多对多关联映射 双向 双方都持有对象引用,改动对象模型,但数据的存储没有变化。
(一) xml方式:映射
再改动映射文件:
<class name="com.wjt276.hibernate.Role" table="t_role">
<id name="id">
<generator class="native"/>
</id>
<property name="name" column="name"/>
<!—order-by 属性是第三方表哪个字段进行排序-->
<set name="users" table="t_user_role"order-by="userid">
<key column="roleid"/>
<many-to-many class="com.wjt276.hibernate.User" column="userid"/>
</set> </class>
注:数据的存储与单向一样。但一般维护这个多对多关系,仅仅须要使用一方,而使还有一方维护关系失效。
总结:
<!— order-by 属性是第三方表哪个字段进行排序-->
<set name="users" table="t_user_role"order-by="userid">
<key column="roleid"/>
<many-to-many class="com.wjt276.hibernate.User" column="userid"/>
</set>
Ø table属性值必须和单向关联中的table属性值一致
Ø <key>中column属性值要与单向关联中的<many-to-many>标签中的column属性值一致
Ø 在<many-to-many>中的column属性值要与单向关联中<key>标签的column属性值一致。
(二) annotation注解方式
多对多关联映射 双向 双方都持有对象引用,改动对象模型,但数据的存储没有变化
仅仅须要改动注解映射就能够了。
User实体类注解没有变化和单向一样:
@Entity
public class User {
private int id;
private Set<User> roles = new HashSet<User>();// Role对象的集合 @Id
@GeneratedValue
public int getId() {return id;}
@ManyToMany
@JoinTable(name="u_r",//使用@JoinTable标签的name属性注解第三方表名称
joinColumns={@JoinColumn(name="userId")},//使用joinColumns属性来注解当前实体类在第三方表中的字段名称并指向该对象
inverseJoinColumns={@JoinColumn(name="roleId")}
//使用inverseJoinColumns属性来注解当前实体类持有引用对象在第三方表中的字段名称并指向被引用对象表
)
public Set<User> getRoles() {return roles;}
Role实体类注解也非常的简单:使用@ManyToMany注解,并使用mappedBy属性指定引用对象持有自己的的属性名
@Entity
public class Role {
private int id;
private String name;
private Set<User> users = newHashSet<User>();
@Id
@GeneratedValue
public int getId() {return id; }
@ManyToMany(mappedBy="roles")
public Set<User>getUsers() {return users;}
public voidsetUsers(Set<User> users) {this.users = users; }
多对多关联映射 双向 数据载入
session =HibernateUtils.getSession();
tx =session.beginTransaction();
Role role= (Role)session.load(Role.class, 1);
System.out.println("role.name=" + role.getName());
for(Iterator<User> iter = role.getUsers().iterator();iter.hasNext();){
Useruser = iter.next();
System.out.println("user.name=" + user.getName());
}
tx.commit();
生成SQL语句:
Hibernate: select role0_.id as id2_0_, role0_.name as name2_0_ from t_rolerole0_ where role0_.id=?
role.name=数据录入人员
Hibernate: select users0_.roleid as roleid1_, users0_.userid as userid1_,user1_.id as id0_0_, user1_.name as name0_0_ from t_user_role users0_ leftouter join t_user user1_ on users0_.userid=user1_.id where users0_.roleid=?order by users0_.userid
user.name=10
user.name=成龙
八、 关联关系中的CRUD_Cascade_Fetch
1、 设定cascade能够设定在持久化时对于关联对象的操作(CUD,R归Fetch管)
2、 cascade仅仅是帮助我们省了编程的麻烦而已,不要把它的作用看的太大
a) cascade的属性指明做什么操作的时候关系对象是绑在一起的
b) refresh=A里面须要读B改过之后的数据
3、 铁律:双向关系在程序中要设定双向关联
4、 铁律:双向一定须要设置mappedBy
5、 fetch
a) 铁律:双向不要两边设置Eager(会有多余的查询语句发出)
b) 对多方设置fetch的时候要慎重,结合详细应用,一般用Lazy不用eager,特殊情况(多方数量不多的能够考虑,提高效率的时候能够考虑)
6、 O/RMapping编程模型
a) 映射模型
i. jpa annotation
ii. hibernate annotation extension
b) 编程接口
i. jpa
ii. hibernate
c) 数据查询语言
i. HQL
ii. EJBQL(JPQL)
7、 要想删除或者更新,先做load,除了精确知道ID之外
8、 假设想消除关联关系,先设定关系为null,再删除相应记录,假设不删记录,该记录就变成垃圾数据
九、 集合映射
1、 Set
2、 List
a) @OrderBy
注意:List与Set注解是一样的,就是把Set更改为List就能够了
private List<User>users = new ArrayList<User>();
@OneToMany(mappedBy="group",
cascade={CascadeType.ALL}
)
@OrderBy("name ASC")//使用@OrderBy注解List中使用哪个字段进行排序,能够组合排序,中间使用逗号分开
public List<User>getUsers() { return users;}
public voidsetUsers(List<User> users) {this.users = users;}
3、 Map
a) @Mapkey
注解:关联模型中并没有变化,仅仅是注解发生了变化,而这个变化是给hibernate看的
Map在映射时,由于Key是唯一的,所以一般能够使用主键表示,然后在映射时使用@MapKey来注解使用哪个字段为key,例如以下:
private Map<Integer,User> users = new HashMap<Integer, User>();
@OneToMany(mappedBy="group", cascade=CascadeType.ALL)
@MapKey(name="id")//注解使用哪个字段为key
public Map<Integer,User> getUsers() { return users;}
public voidsetUsers(Map<Integer, User> users) {this.users = users;}
数据载入:
Session s = sessionFactory.getCurrentSession();
s.beginTransaction();
Group g =(Group)s.load(Group.class, 1);
for(Map.Entry<Integer,User> entry : g.getUsers().entrySet()) {
System.out.println(entry.getValue().getName());
}
s.getTransaction().commit();
十、 继承关联映射
继承映射:就是把类的继承关系映射到数据库里(首先正确的存储,再正确的载入数据)
(一) 继承关联映射的分类:
Ø 单表继承:每棵类继承树使用一个表(table per class hierarchy)
Ø 详细表继承:每一个子类一个表(table per subclass)
Ø 类表继承:每一个详细类一个表(table per concrete class)(有一些限制)
Ø 实例环境:动物Animal有三个基本属性,然后有一个Pig继承了它并扩展了一个属性,还有一个Brid也继承了而且扩展了一个属性
(二) 对象模型:
(三) 单表继承SINGLE_TABLE:
每棵类继承树使用一个表
把全部的属性都要存储表中,眼下至少须要5个字段,另外须要增加一个标识字段(表示哪个详细的子类)
t_animal
|
Id |
Name |
Sex |
Weight |
Height |
Type |
|
1 |
猪猪 |
true |
100 |
P |
|
|
2 |
鸟鸟 |
false |
50 |
B |
当中:
①、id:表主键
②、name:动物的姓名,全部的动物都有
③、sex:动物的性别,全部的动物都有
④、weight:猪(Pig)的重量,仅仅有猪才有,所以鸟鸟就没有重量数据
⑤、height:鸟(height)的调试,仅仅有鸟才有,所以猪猪就没有高度数据
⑥、type:表示动物的类型;P表示猪;B表示鸟
1、 实体类
Animal实体类:
public class Animal {
private int id;
private String name;
private boolean sex;
public int getId() {return id; }
public void setId(int id) { this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}
public boolean isSex() {return sex;}
public void setSex(boolean sex) {this.sex = sex;}
}
Pig实体类:
public class Pig extends Animal {
private int weight;
public int getWeight() {return weight;}
public void setWeight(int weight) {this.weight = weight;}
}
Bird实体类:
public class Bird extends Animal {
private int height;
public int getHeight() {return height;}
public void setHeight(int height) {this.height = height;}
}
2、 xml方式:映射
<class name="Animal" table="t_animal"lazy="false">
<id name="id">
<generator class="native"/>
</id>
<discriminator column="type" type="string"/>
<property name="name"/>
<property name="sex"/>
<subclass name="Pig" discriminator-value="P">
<property name="weight"/>
</subclass>
<subclass name="Bird" discriminator-value="B">
<property name="height"/>
</subclass>
</class>
1、理解怎样映射
由于类继承树肯定是相应多个类,要把多个类的信息存放在一张表中,必须有某种机制来区分哪些记录是属于哪个类的。
这样的机制就是,在表中增加一个字段,用这个字段的值来进行区分。用hibernate实现这样的策略的时候,有例如以下步骤:
父类用普通的<class>标签定义
在父类中定义一个discriminator,即指定这个区分的字段的名称和类型
如:<discriminator column=”XXX” type=”string”/>
子类使用<subclass>标签定义,在定义subclass的时候,须要注意例如以下几点:
Subclass标签的name属性是子类的全路径名
在Subclass标签中,用discriminator-value属性来标明本子类的discriminator字段(用来区分不同类的字段)
的值Subclass标签,既能够被class标签所包括(这样的包括关系正是表明了类之间的继承关系),也能够与class标
签平行。 当subclass标签的定义与class标签平行的时候,须要在subclass标签中,增加extends属性,里面的值
是父类的全路径名称。子类的其他属性,像普通类一样,定义在subclass标签的内部。
2、理解怎样存储
存储的时候hibernate会自己主动将鉴别字段值插入到数据库中,在载入数据的时候,hibernate能依据这个鉴别值
正确的载入对象
多态查询:在hibernate载入数据的时候能鉴别出正真的类型(instanceOf)
get支持多态查询
load仅仅有在lazy=false,才支持多态查询
hql支持多态查询
3、 annotation注解
父类中注解例如以下:
使用@Inheritance注解为继承映射,再使用strategy属性来指定继承映射的方式
strategy有三个值:InheritanceType.SINGLE_TABLE 单表继承
InheritanceType.TABLE_PER_CLASS 类表继承
InheritanceType.JOINED 详细表继承
再使用@DiscriminatorColumn注意标识字段的字段名,及字段类型
在类中使用@DiscriminatorValue来注解标识字段的值
@Entity
@Inheritance(strategy=InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(
name="discriminator",
discriminatorType=DiscriminatorType.STRING)
@DiscriminatorValue("person")
public class Person {private int id;private String name;
@Id
@GeneratedValue
public int getId() {return id;}
继承类中注解例如以下:
仅仅须要使用@DiscriminatorValue来注解标识字段的值
4、 导出后生成SQL语句:
create table t_animal (id integer not null auto_increment, typevarchar(255) not null, name varchar(255), sex bit, weight integer, heightinteger, primary key (id))
5、 数据库中表结构:
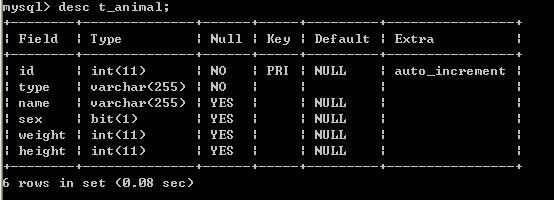
6、 单表继承数据存储:
session = HibernateUtils.getSession();
tx =session.beginTransaction();
Pig pig = new Pig();
pig.setName("猪猪");
pig.setSex(true);
pig.setWeight(100);
session.save(pig);
Bird bird = new Bird();
bird.setName("鸟鸟");
bird.setSex(false);
bird.setHeight(50);
session.save(bird);
tx.commit();
存储运行输出SQL语句:
Hibernate: insert into t_animal (name, sex, weight, type) values (?, ?, ?,'P')//自己主动确定无height字段,而且设置标识符为P
Hibernate: insert into t_animal (name, sex, height, type) values (?, ?, ?,'B') //自己主动确定无weight字段,而且设置标识符为B
解释:hibernate会依据单表继承映射文件的配置内容,自己主动在插入数据时哪个子类须要插入哪些字段,而且自己主动插入标识符字符值(在映射文件里配置了)
7、 单表继承映射数据载入(指定载入子类):
session =HibernateUtils.getSession();
tx =session.beginTransaction();
Pig pig =(Pig)session.load(Pig.class, 1);
System.out.println("pig.name=" + pig.getName());
System.out.println("pig.weight=" + pig.getWeight());
Bird bird =(Bird)session.load(Bird.class, 2);
System.out.println("bird.name" + bird.getName());
System.out.println("bird.height=" + bird.getHeight());
tx.commit();
8、 载入运行输出SQL语句:
Hibernate: select pig0_.id as id0_0_, pig0_.name as name0_0_, pig0_.sex assex0_0_, pig0_.weight as weight0_0_ from t_animal pig0_ where pig0_.id=? and pig0_.type='P'
//hibernate会依据映射文件自己主动确定哪些字段(尽管表中有height,但hibernate并不会载入)属于这个子类,而且确定标识符为B(已经在配置文件里设置了)
pig.name=猪猪
pig.weight=100
Hibernate: select bird0_.id as id0_0_, bird0_.name as name0_0_, bird0_.sexas sex0_0_, bird0_.height as height0_0_ from t_animal bird0_ where bird0_.id=?and bird0_.type='B'
//hibernate会依据映射文件自己主动确定哪些字段尽管表中有weight,但hibernate并不会载入属于这个子类,而且确定标识符为B(已经在配置文件里设置了)
bird.name=鸟鸟
bird.height=50
9、 单表继承映射数据载入(指定载入父类):
session = HibernateUtils.getSession();
tx =session.beginTransaction();
//不会发出SQL,返回一个代理类
Animal animal =(Animal)session.load(Animal.class, 1);
//发出SQL语句,而且载入全部字段的数据(由于使用父类载入对象数据)
System.out.println("animal.name=" + animal.getName());
System.out.println("animal.sex=" + animal.isSex());
tx.commit();
载入运行生成SQL语句:
Hibernate: select animal0_.id as id0_0_, animal0_.name as name0_0_,animal0_.sex as sex0_0_, animal0_.weight asweight0_0_, animal0_.height as height0_0_, animal0_.type as type0_0_ from t_animal animal0_ where animal0_.id=?
//注:由于使用父类载入数据,所以hibernate会将全部字段(height、weight、type)的数据全部载入,而且条件中没有识别字段type(也就不区分什么子类,把全部子类全部载入上来。)
10、 单表继承映射数据载入(指定载入父类,看是否能鉴别真实对象):
session = HibernateUtils.getSession();
tx =session.beginTransaction();
//不会发出SQL语句(load默认支持延迟载入(lazy)),返回一个animal的代理对象(此代理类是继承Animal生成的,也就是说是Animal一个子类)
Animal animal =(Animal)session.load(Animal.class, 1);
//由于在上面返回的是一个代理类(父类的一个子类),所以animal不是Pig
//通过instanceof是反应不出正直的对象类型的,因此load在默认情况下是不支持多态查询的。
if (animal instanceof Pig) {
System.out.println("是猪");
} else {
System.out.println("不是猪");//这就是结果
}
System.out.println("animal.name=" + animal.getName());
System.out.println("animal.sex=" + animal.isSex());
tx.commit();
11、 多态查询:
在hibernate载入数据的时候能鉴别出正直的类型(通过instanceof)
get支持多态查询;load仅仅有在lazy=false,才支持多态查询;HQL支持多态查询
12、 採用load,通过Animal查询,将<class>标签上的lazy设置为false
session = HibernateUtils.getSession();
tx = session.beginTransaction();
//会发出SQL语句,由于设置lazy为false,不支持延迟载入
Animal animal =(Animal)session.load(Animal.class, 1);
//能够正确的推断出Pig的类型,由于lazy=false,返回详细的Pid类型
//此时load支持多态查询
if (animal instanceof Pig) {
System.out.println("是猪");//结果
} else {
System.out.println("不是猪");
}
System.out.println("animal.name=" + animal.getName());
System.out.println("animal.sex=" + animal.isSex());
tx.commit();
13、 採用get,通过Animal查询,能够推断出正直的类型
session = HibernateUtils.getSession();
tx = session.beginTransaction();
//会发出SQL语句,由于get不支持延迟载入,返回的是正直的类型,
Animal animal =(Animal)session.load(Animal.class, 1);
//能够推断出正直的类型
//get是支持多态查询
if (animal instanceof Pig) {
System.out.println("是猪");//结果
} else {
System.out.println("不是猪");
}
System.out.println("animal.name=" + animal.getName());
System.out.println("animal.sex=" + animal.isSex());
tx.commit();
14、 採用HQL查询,HQL是否支持多态查询
List animalList = session.createQuery("from Animal").list();
for (Iteratoriter = animalList.iterator(); iter.hasNext();) {
Animal a = (Animal)iter.next();
//能够正确鉴别出正直的类型,HQL是支持多态查询的。
if (a instanceof Pig) {
System.out.println("是Pig");
} else if (a instanceof Bird) {
System.out.println("是Bird");
}
}
15、 通过HQL查询表中全部的实体对象
* HQL语句:session.createQuery("fromjava.lang.Object").list();
* 由于全部对象都是继承Object类
List list = session.createQuery("from java.lang.Object").list();
for (Iteratoriter = list.iterator(); iter.hasNext();){
Object o =iter.next();
if (o instanceof Pig) {
System.out.println("是Pig");
} else {
System.out.println("是Bird");
}
}
(四) 详细表继承JOINED:
每一个类映射成一个表(table per subclass)
对象模型不用变化,存储模型须要变化

1、 关系模型:
每一个类映射成一个表(table per subclass)
注:由于须要每一个类都映射成一张表,所以Animal也映射成一张表(t_animal),表中字段为实体类属性
而pig子类也须要映射成一张表(t_pid),但为了与父类联系须要增加一个外键(pidid)指向父类映射成的表(t_animal),字段为子类的扩展属性。Bird子类同样也映射成一张表(t_bird),也增加一个外键(birdid)指向父类映射成的表(t_animal),字段为子类的扩展属性。
2、 xml方式(每一个类映射成一个表):
<class name="com.wjt276.hibernate.Animal" table="t_animal">
<id name="id"column="id"><!-- 映射主键 -->
<generator class="native"/>
</id>
<property name="name"/><!-- 映射普通属性 -->
<property name="sex"/>
<!--<joined-subclass>标签:继承映射 每一个类映射成一个表 -->
<joined-subclass name="com.wjt276.hibernate.Pig" table="t_pig">
<!-- <key>标签:会在相应的表(当前映射的表)里,增加一个外键 , 參照指向当前类的父类(当前Class标签对象的表(t_animal))-->
<key column="pigid"/>
<property name="weight"/>
</joined-subclass>
<joined-subclass name="com.wjt276.hibernate.Bird" table="t_bird">
<key column="birdid"/>
<property name="height"/>
</joined-subclass>
</class>
1、理解怎样映射
这样的策略是使用joined-subclass标签来定义子类的。父类、子类,每一个类都相应一张数据库表。
在父类相应的数据库表中,实际上会存储全部的记录,包括父类和子类的记录;在子类相应的数据库表中,
这个表仅仅定义了子类中所特有的属性映射的字段。子类与父类,通过同样的主键值来关联。实现这样的策略的时候,
有例如以下步骤:
父类用普通的<class>标签定义就可以
父类不再须要定义discriminator字段
子类用<joined-subclass>标签定义,在定义joined-subclass的时候,须要注意例如以下几点:
Joined-subclass标签的name属性是子类的全路径名
Joined-subclass标签须要包括一个key标签,这个标签指定了子类和父类之间是通过哪个字段来关联的。
如:<key column=”PARENT_KEY_ID”/>,这里的column,实际上就是父类的主键相应的映射字段名称。
Joined-subclass标签,既能够被class标签所包括(这样的包括关系正是表明了类之间的继承关系),
也能够与class标签平行。 当Joined-subclass标签的定义与class标签平行的时候,须要在Joined-subclass
标签中,增加extends属性,里面的值是父类的全路径名称。子类的其他属性,像普通类一样,定义在joined-subclass标签的内部。
3、 annotation注解
由于,子类生成的表须要引用父类生成的表,所以仅仅须要在父类设置详细表继承映射就能够了,其他子类仅仅须要使用@Entity注解就能够了
@Entity
@Inheritance(strategy=InheritanceType.JOINED)
public class Person {
private int id;
private String name;
@Id
@GeneratedValue
public int getId() {return id;}
4、 导出输出SQL语句:
create table t_animal (id integer notnull auto_increment, name varchar(255), sex bit, primary key (id))
create table t_bird (birdid integernot null, height integer, primary key (birdid))
create table t_pig (pigid integer notnull, weight integer, primary key (pigid))
altertable t_bird add index FKCB5B05A4A554009D(birdid), add constraint FKCB5B05A4A554009D foreign key (birdid) referencest_animal (id)
alter table t_pig add index FK68F8743FE77AC32 (pigid), add constraint FK68F8743FE77AC32 foreign key (pigid) references t_animal (id)
//共生成三个表,并在子类表中各有一个外键參照指向父类表
数据的存储,不须要其他的任务变化,直接使用单表继承存储就能够了,载入也是一样。
详细表继承效率没有单表继承高,可是单表继承会出现多余的庸于字段,详细表层次分明
(五) 类表继承TABLE_PER_CLASS
每一个详细类映射成一个表(table per concreteclass)(有一些限制)
对象模型不用变化,存储模型须要变化
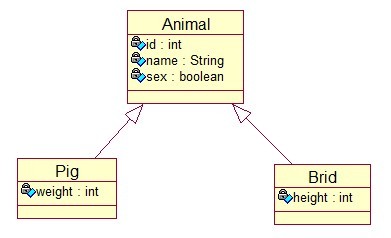
1、 关系模型:
每一个详细类(Pig、Brid)映射成一个表(table per concrete class)(有一些限制)
t_pig
|
Id |
Name |
Sex |
Weight |
|
1 |
猪猪 |
True |
100 |
t_bird
|
Id |
Name |
Sex |
Height |
|
2 |
鸟鸟 |
False |
50 |
2、 xml方式:映射文件:
<class name="com.wjt276.hibernate.Animal" table="t_animal">
<id name="id"column="id"><!-- 映射主键 -->
<generator class="assigned"/><!-- 每一个详细类映射一个表主键生成策略不可使用native --> </id>
<property name="name"/><!-- 映射普通属性 -->
<property name="sex"/>
<!--使用<union-subclass>标签来映射"每一个详细类映射成一张表"的映射关系
,实现上上面的表t_animal尽管映射到数据库中,但它没有不论什么作用。 -->
<union-subclass name="com.wjt276.hibernate.Pig" table="t_pig">
<property name="weight"/>
</union-subclass>
<union-subclass name="com.wjt276.hibernate.Bird" table="t_bird">
<property name="height"/>
</union-subclass>
</class>
理解怎样映射
这样的策略是使用union-subclass标签来定义子类的。每一个子类相应一张表,而且这个表的信息是完备的,
即包括了全部从父类继承下来的属性映射的字段(这就是它跟joined-subclass的不同之处,
joined-subclass定义的子类的表,仅仅包括子类特有属性映射的字段)。实现这样的策略的时候,有例如以下步骤:
父类用普通<class>标签定义就可以
子类用<union-subclass>标签定义,在定义union-subclass的时候,须要注意例如以下几点:
Union-subclass标签不再须要包括key标签(与joined-subclass不同)
Union-subclass标签,既能够被class标签所包括(这样的包括关系正是表明了类之间的继承关系),
也能够与class标签平行。 当Union-subclass标签的定义与class标签平行的时候,须要在Union-subclass
标签中,增加extends属性,里面的值是父类的全路径名称。子类的其他属性,像普通类一样,
定义在Union-subclass标签的内部。这个时候,尽管在union-subclass里面定义的仅仅有子类的属性,
可是由于它继承了父类,所以,不须要定义其他的属性,在映射到数据库表的时候,依旧包括了父类的所
有属性的映射字段。
注意:在保存对象的时候id是不能反复的(不能使用自增生成主键)
3、 annotation注解
仅仅须要对父类进行注解就能够了,
由于子类表的ID是不能够反复,所以一般的主键生成策略已经不适应了,仅仅有表主键生成策略。
首先使用@Inheritance(strategy=InheritanceType.TABLE_PER_CLASS)来注解继承映射,而且使用详细表继承方式,使用@TableGenerator来申明一个表主键生成策略
再在主键上@GeneratedValue(generator="t_gen", strategy=GenerationType.TABLE)来注解生成策略为表生成策略,而且指定表生成策略的名称
继承类仅仅须要使用@Entity进行注解就能够了
@Entity
@Inheritance(strategy=InheritanceType.TABLE_PER_CLASS)
@TableGenerator(
name="t_gen",
table="t_gen_table",
pkColumnName="t_pk",
valueColumnName="t_value",
pkColumnValue="person_pk",
initialValue=1,
allocationSize=1
)
public class Person {
private int id;
private String name;
@Id
@GeneratedValue(generator="t_gen", strategy=GenerationType.TABLE)
public int getId() {return id;}
4、 导出输出SQL语句:
create table t_animal (id integer not null, name varchar(255), sex bit, primary key (id))
create table t_bird (id integer not null, name varchar(255), sex bit, height integer, primary key(id))
create table t_pig (id integer not null, name varchar(255), sex bit, weight integer, primary key(id))
注:表t_animal、 t_bird、t_pig并非自增的,是由于bird、pig都是animal类,也就是说animal不能够有同样的ID号(Bird、Pig是类型,仅仅是存储的位置不同而以)
5、 数据库表结构例如以下:
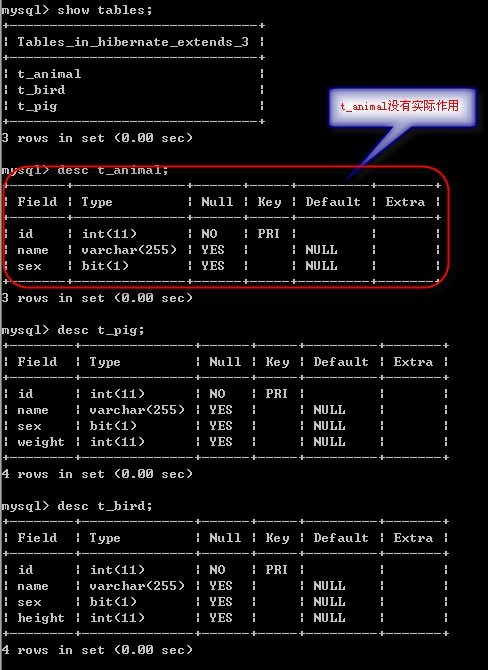
注:假设不想t_animal存在(由于它没有实际的作用),能够设置<class>标签中的abstract="true"(抽象表),这样在导出至数据库时,就不会生成t_animal表了。
<class name="com.wjt276.hibernate.Animal" table="t_animal" abstract="true">
<id name="id"column="id"><!-- 映射主键 -->
…………
(六) 三种继承关联映射的差别:
1、 第一种:它把全部的数据都存入一个表中,优点:效率好(操作的就是一个表);缺点:存在庸于字段,假设将庸于字段设置为非空,则就无法存入数据;
2、 第二种:层次分明,缺点:效率不好(表间存在关联表)
3、 第三种:主键字段不能够设置为自增主键生成策略。
一般使用第一种
第17课hibernate树形结构(重点)
树形结构:也就是文件夹结构,有父文件夹、子文件夹、文件等信息,而在程序中树形结构仅仅是称为节点。
一棵树有一个根节点,而根节点也有一个或多个子节点,而一个子节点有且仅有一个父节点(当前除根节点外),而且也存在一个或多个子节点。
也就是说树形结构,重点就是节点,也就是我们须要关心的节点对象。
节点:一个节点有一个ID、一个名称、它所属的父节点(根节点无父节点或为null),有一个或多的子节点等其他信息。
Hibernate将节点抽取出成实体类,节点相对于父节点是“多对一”映射关系,节点相对于子节点是“一对多”映射关系。
一、 节点实体类:
/** * 节点*/
public class Node {
private int id; //标识符
private String name; //节点名称
private int level; //层次,为了输出设计
private boolean leaf; //是否为叶子节点,这是为了效率设计,可有可无
//父节点:由于多个节点属于一个父节点,因此用hibernate映射关系说是“多对一”
private Node parent;
//子节点:由于一个节点有多个子节点,因此用hibernate映射关系说是“一对多”
private Set children;
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getName() {return name;}
public void setName(Stringname) { this.name = name;}
public int getLevel() { return level;}
public void setLevel(int level) {this.level = level;}
public boolean isLeaf() {return leaf;}
public void setLeaf(boolean leaf) {this.leaf = leaf;}
public Node getParent() {return parent;}
public void setParent(Nodeparent) {this.parent = parent;}
public SetgetChildren() {return children;}
public void setChildren(Setchildren) {this.children = children;}}
二、 xml方式:映射文件:
<class name="com.wjt276.hibernate.Node" table="t_node">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name"/>
<property name="level"/>
<property name="leaf"/>
<!— 一对多:增加一个外键,參照当前表t_node主键, 而属性parent类型为Node,也就是当前类,则会在同一个表中增加这个字段,參照这个表的主键-->
<many-to-one name="parent" column="pid"/>
<!--<set>标签是映射一对多的方式,增加一个外键,參照主键。-->
<set name="children" lazy="extra"inverse="true">
<key column="pid"/>
<one-to-many class="com.wjt276.hibernate.Node"/>
</set>
</class>
三、 annotation注解
由于树型节点全部的数据,在数据库中仅仅是存储在一个表中,而对于实体类来说,节点对子节点来说是一对多的关系,而对于父节点来说是多对一的关系。因此能够在一个实体类中注解。例如以下
@Entity
public class Node {
private int id; // 标识符
private String name; // 节点名称
private int level; // 层次,为了输出设计
private boolean leaf; // 是否为叶子节点,这是为了效率设计,可有可无
// 父节点:由于多个节点属于一个父节点,因此用hibernate映射关系说是“多对一”
private Node parent;
// 子节点:由于一个节点有多个子节点,因此用hibernate映射关系说是“一对多”
private Set<Node> children = newHashSet<Node>();
@Id
@GeneratedValue
public int getId() {return id;}
@OneToMany(mappedBy="parent")
public Set<Node>getChildren() {return children;}
@ManyToOne
@JoinColumn(name="pid")
public Node getParent() {return parent;}
四、 測试代码:
public class NodeTest extends TestCase {
//測试节点的存在
public void testSave1(){
NodeManage.getInstanse().createNode("F:\\hibernate\\hibernate_training_tree");
}
//測试节点的载入
public void testPrintById(){
NodeManage.getInstanse().printNodeById(1);
}}
五、 相应的类代码:
public classNodeManage {
private static NodeManage nodeManage= newNodeManage();
private NodeManage(){}//由于要使用单例,所以将其构造方法私有化
//向外提供一个接口
public static NodeManage getInstanse(){
return nodeManage;
}
/**
* 创建树
*@param filePath 须要创建树文件夹的根文件夹
*/
public void createNode(String dir) {
Session session = null;
try {
session =HibernateUtils.getSession();
session.beginTransaction();
File root = new File(dir);
//由于第一个节点无父节点,由于是null
this.saveNode(root, session, null,0);
session.getTransaction().commit();
} catch (HibernateException e) {
e.printStackTrace();
session.getTransaction().rollback();
} finally {
HibernateUtils.closeSession(session);
}}
/**
* 保存节点对象至数据库
*@param file 节点所相应的文件
*@param session session
*@param parent 父节点
*@param level 级别
*/
public void saveNode(File file, Sessionsession, Node parent, int level) {
if (file == null ||!file.exists()){return;}
//假设是文件则返回true,则表示是叶子节点,否则为文件夹,非叶子节点
boolean isLeaf = file.isFile();
Node node = new Node();
node.setName(file.getName());
node.setLeaf(isLeaf);
node.setLevel(level);
node.setParent(parent);
session.save(node);
//进行循环迭代子文件夹
File[] subFiles = file.listFiles();
if (subFiles != null &&subFiles.length > 0){
for (int i = 0; i <subFiles.length ; i++){
this.saveNode(subFiles[i],session, node, level + 1);
}}}
/**
* 输出树结构
*@param id
*/
public void printNodeById(int id) {
Session session = null;
try {
session =HibernateUtils.getSession();
session.beginTransaction();
Node node =(Node)session.get(Node.class, 1);
printNode(node);
session.getTransaction().commit();
} catch (HibernateException e) {
e.printStackTrace();
session.getTransaction().rollback();
} finally {
HibernateUtils.closeSession(session);
}
}
private void printNode(Node node) {
if (node == null){ return; }
int level = node.getLevel();
if (level > 0){
for (int i = 0; i < level; i++){
System.out.print(" |");
}
System.out.print("--");
}
System.out.println(node.getName() +(node.isLeaf() ? "" : "[" + node.getChildren().size() +"]"));
Set children = node.getChildren();
for (Iterator iter =children.iterator(); iter.hasNext(); ){
Node child = (Node)iter.next();
printNode(child);
}}}
第18课作业-学生、课程、分数的映射关系
一、 设计
1、 实体类(表)
2、 导航(编程方便)
a) 通过学生 取出 学生所先的课程
b) 可是通过课程 取出 学该课程的 学生不好。学的学生太多
c) 确定编程的方式
3、 能够利用联合主键映射能够,
a) 学生生成一个表
b) 课程生成一个表
c) 再生成一个表,主键是联合主键(学生ID、课程ID) + 学生共生成一个表
4、 也能够利用一对多,多对多 都能够(推荐)
a) 学生生成一个表
b) 课程生成一个表
c) 分数生成一个表,而且有两个外键,分别指向学生、课程表
二、 代码:
* 课程
@Entity
public class Course {
private int id;
private String name;
@Id
@GeneratedValue
public int getId() {return id;}
public void setId(int id) { this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}}
* 分数
@Entity
@Table(name = "score")
public class Score {
private int id;
private int score;
private Student student;
private Course course;
@Id
@GeneratedValue
public int getId() {return id;}
@ManyToOne
@JoinColumn(name = "student_id")
public StudentgetStudent() {return student;}
@ManyToOne
@JoinColumn(name = "score_id")
public Course getCourse(){ return course;}
public int getScore() { return score;}
public void setScore(int score) {this.score = score;}
public void setStudent(Studentstudent) {this.student = student;}
public void setCourse(Coursecourse) {this.course = course;}
public void setId(int id) { this.id = id;}}
* 学生通过课程能够导航到分数
@Entity
public class Student {
private int id;
private String name;
private Set<Course> courses = newHashSet<Course>();
@Id
@GeneratedValue
public int getId() {return id;}
@ManyToMany
@JoinTable(name = "score", //此表就是Score实体类在数据库生成的表叫score
joinColumns= @JoinColumn(name = "student_id"),
inverseJoinColumns= @JoinColumn(name = "course_id")
)
public Set<Course>getCourses() {return courses;}
public voidsetCourses(Set<Course> courses) {this.courses = courses;}
public void setId(int id) { this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}}
三、 注意
在Student实体类中的使用的第三方表使用了两个字段,而hibernate会使这两个字段生成联合主键,这并非我们须要的结果,由于我们须要手动到数据库中改动。这样才干够存储数据,否则数据存储不进去。这可能是hibernate的一个小bug
第19课Hibernate查询(Query Language)
HQL VS EJBQL
一、 Hibernate能够使用的查询语言
1、 NativeSQL:本地语言(数据库自己的SQL语句)
2、 HQL :Hibernate自带的查询语句,能够使用HQL语言,转换成详细的方言
3、 EJBQL:JPQL 1.0,能够觉得是HQL的一个子节(重点)
4、 QBC:Query By Cretira
5、 QBE:Query By Example
注意:上面的功能是从1至5的比較,1的功能最大,5的功能最小
二、 实例一
1、 版块
/** 版块*/
@Entity
public class Category {
private int id;
private String name;
@Id
@GeneratedValue
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}}
2、 主题
/**主题*/
@Entity
public class Topic {
private int id;
private String title;
private Category category;
//private Category category2;
private Date createDate;
public DategetCreateDate() {return createDate;}
public void setCreateDate(DatecreateDate) {this.createDate = createDate;}
@ManyToOne(fetch=FetchType.LAZY)
public CategorygetCategory() { return category;}
public voidsetCategory(Category category) {this.category = category; }
@Id
@GeneratedValue
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getTitle(){return title;}
public void setTitle(Stringtitle) {this.title = title;}}
3、 主题回复
/**主题回复*/
@Entity
public class Msg {
private int id;
private String cont;
private Topic topic;
@ManyToOne
public Topic getTopic() {return topic;}
public void setTopic(Topictopic) {this.topic = topic;}
@Id
@GeneratedValue
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getCont() {return cont;}
public void setCont(Stringcont) {this.cont = cont;}}
4、 暂时类
/**暂时类 */
public class MsgInfo { //VO DTO Value Object username p1 p2UserInfo->User->DB
private int id;
private String cont;
private String topicName;
private String categoryName;
public MsgInfo(int id, String cont,String topicName, String categoryName) {
super();
this.id = id;
this.cont = cont;
this.topicName = topicName;
this.categoryName =categoryName;
}
public StringgetTopicName() {return topicName;}
public voidsetTopicName(String topicName) {this.topicName = topicName;}
public StringgetCategoryName() {return categoryName;}
public voidsetCategoryName(String categoryName) {
this.categoryName =categoryName;
}
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getCont() {return cont;}
public void setCont(Stringcont) {this.cont = cont;}}
三、 实体一測试代码:
//初始化数据
@Test
public void testSave() {
Sessionsession = sf.openSession();
session.beginTransaction();
for(int i=0; i<10; i++){
Categoryc = new Category();
c.setName("c" + i);
session.save(c);
}
for(int i=0; i<10; i++){
Categoryc = new Category();
c.setId(1);
Topic t= new Topic();
t.setCategory(c);
t.setTitle("t" + i);
t.setCreateDate(new Date());
session.save(t);
}
for(int i=0; i<10; i++){
Topic t= new Topic();
t.setId(1);
Msg m = new Msg();
m.setCont("m" + i);
m.setTopic(t);
session.save(m);
}
session.getTransaction().commit();
session.close();
}
/** QL:from + 实体类名称 */
Query q =session.createQuery("from Category");
List<Category>categories = (List<Category>)q.list();
for(Category c : categories) {
System.out.println(c.getName());
}
/* 能够为实体类起个别名,然后使用它 */
Query q =session.createQuery("from Category c wherec.name > 'c5'");
List<Category>categories = (List<Category>)q.list();
for(Category c : categories) {
System.out.println(c.getName());
}
//排序
Query q =session.createQuery("from Category c orderby c.name desc");
List<Category>categories = (List<Category>)q.list();
for(Category c : categories) {
System.out.println(c.getName());
}
* 为载入上来的对象属性起别名,还能够使用
Query q =session.createQuery("select distinct c fromCategory c order by c.name desc");
List<Category>categories = (List<Category>)q.list();
for(Category c : categories) {
System.out.println(c.getName());
}
/*Query q = session.createQuery("from Category c where c.id > :minand c.id < :max");
//q.setParameter("min",2);
//q.setParameter("max",8);
q.setInteger("min",2);
q.setInteger("max",8);*/
* 能够使用冒号(:),作为占位符,来接受參数使用。例如以下(链式编程)
Query q =session.createQuery("from Category c wherec.id > :min and c.id < :max")
.setInteger("min", 2)
.setInteger("max", 8);
List<Category>categories = (List<Category>)q.list();
for(Category c : categories) {
System.out.println(c.getId()+ "-" + c.getName());
}
Query q =session.createQuery("from Category c wherec.id > ? and c.id < ?");
q.setParameter(0, 2)
.setParameter(1, 8);
// q.setParameter(1, 8);
List<Category>categories = (List<Category>)q.list();
for(Category c : categories) {
System.out.println(c.getId()+ "-" + c.getName());
}
//分页
Query q =session.createQuery("from Category c orderby c.name desc");
q.setMaxResults(4);//每页显示的最大记录数
q.setFirstResult(2);//从第几条開始显示,从0開始
List<Category>categories = (List<Category>)q.list();
for(Category c : categories) {
System.out.println(c.getId()+ "-" + c.getName());
}
Query q =session.createQuery("select c.id, c.name from Category c order by c.namedesc");
List<Object[]>categories = (List<Object[]>)q.list();
for(Object[] o : categories) {
System.out.println(o[0] + "-" + o[1]);
}
//设定fetch type 为lazy后将不会有第二条sql语句
Query q =session.createQuery("from Topic t wheret.category.id = 1");
List<Topic>topics = (List<Topic>)q.list();
for(Topic t : topics) {
System.out.println(t.getTitle());
//System.out.println(t.getCategory().getName());
}
//设定fetch type 为lazy后将不会有第二条sql语句
Query q =session.createQuery("from Topic t wheret.category.id = 1");
List<Topic>topics = (List<Topic>)q.list();
for(Topic t : topics) {
System.out.println(t.getTitle());
}
Query q =session.createQuery("from Msg m wherem.topic.category.id = 1");
for(Object o : q.list()) {
Msg m = (Msg)o;
System.out.println(m.getCont());
}
//了解就可以
//VO Value Object
//DTO data transfer object
Query q =session.createQuery("select newcom.bjsxt.hibernate.MsgInfo(m.id, m.cont, m.topic.title, m.topic.category.name)from Msg");
for(Object o : q.list()) {
MsgInfo m = (MsgInfo)o;
System.out.println(m.getCont());
}
//动手測试left right join
//为什么不能直接写Category名,而必须写t.category
//由于有可能存在多个成员变量(同一个类),须要指明用哪一个成员变量的连接条件来做连接
Query q =session.createQuery("select t.title, c.namefrom Topic t join t.category c "); //join Category c
for(Object o : q.list()) {
Object[] m = (Object[])o;
System.out.println(m[0] + "-" + m[1]);
}
//学习使用uniqueResult
Query q = session.createQuery("from Msg m where m = :MsgToSearch "); //不重要
Msg m = new Msg();
m.setId(1);
q.setParameter("MsgToSearch", m);
Msg mResult =(Msg)q.uniqueResult();
System.out.println(mResult.getCont());
Query q =session.createQuery("select count(*) fromMsg m");
long count = (Long)q.uniqueResult();
System.out.println(count);
Query q = session.createQuery("select max(m.id), min(m.id), avg(m.id), sum(m.id)from Msg m");
Object[] o =(Object[])q.uniqueResult();
System.out.println(o[0] + "-" + o[1] + "-" + o[2] + "-" + o[3]);
Query q =session.createQuery("from Msg m where m.idbetween 3 and 5");
for(Object o : q.list()) {
Msg m = (Msg)o;
System.out.println(m.getId()+ "-" + m.getCont());
}
Query q =session.createQuery("from Msg m where m.idin (3,4, 5)");
for(Object o : q.list()) {
Msg m = (Msg)o;
System.out.println(m.getId()+ "-" + m.getCont());
}
//is null 与 is notnull
Query q =session.createQuery("from Msg m where m.contis not null");
for(Object o : q.list()) {
Msg m = (Msg)o;
System.out.println(m.getId()+ "-" + m.getCont());
}
四、 实例二
注意:实体二,实体类,仅仅是在实体一的基础上改动了Topic类,增加了多对一的关联关系
@Entity
@NamedQueries({
@NamedQuery(name="topic.selectCertainTopic", query="from Topic t where t.id = :id")
})
/*@NamedNativeQueries(
{
@NamedNativeQuery(name="topic.select2_5Topic",query="select * from topic limit 2, 5")
})*/
public class Topic {
private int id;
private String title;
private Category category;
private Date createDate;
private List<Msg> msgs = newArrayList<Msg>();
@OneToMany(mappedBy="topic")
public List<Msg> getMsgs() {return msgs;}
public void setMsgs(List<Msg> msgs) {this.msgs = msgs;}
public Date getCreateDate() {return createDate;}
public void setCreateDate(Date createDate) {this.createDate = createDate; }
@ManyToOne(fetch=FetchType.LAZY)
public Category getCategory() { return category;}
public void setCategory(Category category) {this.category = category;}
@Id
@GeneratedValue
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getTitle() { return title;}
public void setTitle(String title) {this.title = title;}}
五、 实例二測试代码
注意:測试数据是实例一的測试数据
//is empty and is not empty
Query q =session.createQuery("from Topic t wheret.msgs is empty");
for(Object o : q.list()) {
Topic t = (Topic)o;
System.out.println(t.getId()+ "-" + t.getTitle());
}
Query q =session.createQuery("from Topic t wheret.title like '%5'");
for(Object o : q.list()) {
Topic t = (Topic)o;
System.out.println(t.getId()+ "-" + t.getTitle());
}
Query q =session.createQuery("from Topic t wheret.title like '_5'");
for(Object o : q.list()) {
Topic t = (Topic)o;
System.out.println(t.getId()+ "-" + t.getTitle());
}
//不重要
Query q = session.createQuery("select lower(t.title)," +
"upper(t.title)," +
"trim(t.title)," +
"concat(t.title,'***')," +
"length(t.title)" +
" from Topict ");
for(Object o : q.list()) {
Object[] arr = (Object[])o;
System.out.println(arr[0] + "-" + arr[1] + "-" + arr[2] + "-" + arr[3] + "-" + arr[4] + "-");
}
Query q =session.createQuery("select abs(t.id)," +
"sqrt(t.id)," +
"mod(t.id,2)" +
" from Topict ");
for(Object o : q.list()) {
Object[] arr =(Object[])o;
System.out.println(arr[0] + "-" + arr[1] + "-" + arr[2] );
}
Query q = session.createQuery("selectcurrent_date, current_time, current_timestamp, t.id from Topic t");
for(Object o : q.list()) {
Object[] arr =(Object[])o;
System.out.println(arr[0] + " | " + arr[1] + " | " + arr[2] + " | " + arr[3]);
}
Query q =session.createQuery("from Topic t wheret.createDate < :date");
q.setParameter("date", new Date());
for(Object o : q.list()) {
Topic t = (Topic)o;
System.out.println(t.getTitle());
}
Query q =session.createQuery("select t.title,count(*) from Topic t group by t.title") ;
for(Object o : q.list()) {
Object[] arr =(Object[])o;
System.out.println(arr[0] + "|" + arr[1]);
}
Query q = session.createQuery("selectt.title, count(*) from Topic t group by t.title having count(*) >= 1") ;
for(Object o : q.list()) {
Object[] arr =(Object[])o;
System.out.println(arr[0] + "|" + arr[1]);
}
Query q =session.createQuery("from Topic t where t.id< (select avg(t.id) from Topic t)") ;
for(Object o : q.list()) {
Topic t = (Topic)o;
System.out.println(t.getTitle());
}
Query q =session.createQuery("from Topic t where t.id< ALL (select t.id from Topic t where mod(t.id, 2)= 0) ") ;
for(Object o : q.list()) {
Topic t = (Topic)o;
System.out.println(t.getTitle());
}
//用in 能够实现exists的功能
//可是exists运行效率高
// t.id not in (1)
Query q =session.createQuery("from Topic t where notexists (select m.id from Msg m where m.topic.id=t.id)") ;
// Query q =session.createQuery("from Topic t where exists (select m.id from Msg mwhere m.topic.id=t.id)") ;
for(Object o : q.list()) {
Topic t = (Topic)o;
System.out.println(t.getTitle());
}
//update and delete
//规范并没有说明是不是要更新persistent object,所以假设要使用,建议在单独的trasaction中运行
Query q =session.createQuery("update Topic t sett.title = upper(t.title)") ;
q.executeUpdate();
q = session.createQuery("from Topic");
for(Object o : q.list()) {
Topic t = (Topic)o;
System.out.println(t.getTitle());
}
session.createQuery("update Topic t set t.title = lower(t.title)")
.executeUpdate();
//不重要
Query q =session.getNamedQuery("topic.selectCertainTopic");
q.setParameter("id", 5);
Topic t =(Topic)q.uniqueResult();
System.out.println(t.getTitle());
//Native(了解)
SQLQuery q =session.createSQLQuery("select *from category limit 2,4").addEntity(Category.class);
List<Category>categories = (List<Category>)q.list();
for(Category c : categories) {
System.out.println(c.getName());
}
public void testHQL_35() {
//尚未实现JPA命名的NativeSQL
}
第20课 Query by Criteria(QBC)
QBC(Query By Criteria)查询方式是Hibernate提供的“更加面向对象”的一种检索方式。QBC在条件查询上比HQL查询更为灵活,而且支持运行时动态生成查询语句。
在Hibernate应用中使用QBC查询通常经过3个步骤
(1)使用Session实例的createCriteria()方法创建Criteria对象
(2)使用工具类Restrictions的相关方法为Criteria对象设置查询对象
(3)使用Criteria对象的list()方法运行查询,返回查询结果
一、 实体代码:
注意:数据是使用Hibernate查询章节的数据
//criterion 标准/准则/约束
Criteria c =session.createCriteria(Topic.class) //from Topic
.add(Restrictions.gt("id", 2)) //greater than = id > 2
.add(Restrictions.lt("id", 8)) //little than = id < 8
.add(Restrictions.like("title", "t_"))
.createCriteria("category")
.add(Restrictions.between("id", 3, 5)) //category.id >= 3 and category.id <=5
;
//DetachedCriterea
for(Object o : c.list()) {
Topic t = (Topic)o;
System.out.println(t.getId()+ "-" + t.getTitle());
}
二、 Restrictions使用方法
Hibernate中Restrictions的方法 说明
Restrictions.eq =
Restrictions.allEq 利用Map来进行多个等于的限制
Restrictions.gt >
Restrictions.ge >=
Restrictions.lt <
Restrictions.le <=
Restrictions.between BETWEEN
Restrictions.like LIKE
Restrictions.in in
Restrictions.and and
Restrictions.or or
Restrictions.sqlRestriction 用SQL限定查询
============================================
QBE (QueryBy Example)
Criteria cri = session.createCriteria(Student.class);
cri.add(Example.create(s)); //s是一个Student对象
list cri.list();
实质:创建一个模版,比方我有一个表serial有一个 giftortoy字段,我设置serial.setgifttoy("2"),
则这个表中的全部的giftortoy为2的数据都会出来
2: QBC (Query By Criteria) 主要有Criteria,Criterion,Oder,Restrictions类组成
session = this.getSession();
Criteria cri = session.createCriteria(JdItemSerialnumber.class);
Criterion cron = Restrictions.like("customer",name);
cri.add(cron);
list = cri.list();
==============================
Hibernate中 Restrictions.or()和Restrictions.disjunction()的差别是什么?
比較运算符
HQL运算符 QBC运算符 含义
= Restrictions.eq() 等于
<> Restrictions.not(Exprission.eq()) 不等于
> Restrictions.gt() 大于
>= Restrictions.ge() 大于等于
< Restrictions.lt() 小于
<= Restrictions.le() 小于等于
is null Restrictions.isnull() 等于空值
is not null Restrictions.isNotNull() 非空值
like Restrictions.like() 字符串模式匹配
and Restrictions.and() 逻辑与
and Restrictions.conjunction() 逻辑与
or Restrictions.or() 逻辑或
or Restrictions.disjunction() 逻辑或
not Restrictions.not() 逻辑非
in(列表) Restrictions.in() 等于列表中的某一个值
ont in(列表) Restrictions.not(Restrictions.in())不等于列表中随意一个值
between x and y Restrictions.between() 闭区间xy中的随意值
not between x and y Restrictions.not(Restrictions..between()) 小于值X或者大于值y
3: HQL
String hql = "select s.name ,avg(s.age) from Student s group bys.name";
Query query = session.createQuery(hql);
list = query.list();
....
4: 本地SQL查询
session = sessionFactory.openSession();
tran = session.beginTransaction();
SQLQuery sq = session.createSQLQuery(sql);
sq.addEntity(Student.class);
list = sq.list();
tran.commit();
5: QID
Session的get()和load()方法提供了依据对象ID来检索对象的方式。该方式被用于事先知道了要检索对象ID的情况。
三、 工具类Order提供设置排序方式
Order.asc(String propertyName)
升序排序
Order.desc(String propertyName)
降序排序
四、 工具类Projections提供对查询结果进行统计与分组操作
Porjections.avg(String propertyName)
求某属性的平均值
Projections.count(String propertyName)
统计某属性的数量
Projections.countDistinct(String propertyName)
统计某属性的不同值的数量
Projections.groupProperty(String propertyName)
指定一组属性值
Projections.max(String propertyName)
某属性的最大值
Projections.min(String propertyName)
某属性的最小值
Projections.projectionList()
创建一个新的projectionList对象
Projections.rowCount()
查询结果集中记录的条数
Projections.sum(String propertyName)
返回某属性值的合计
五、 QBC分页查询
Criteria为我们提供了两个实用的方法:setFirstResult(intfirstResult)和setMaxResults(int maxResults).
setFirstResult(int firstResult)方法用于指定从哪一个对象開始检索(序号从0開始),默觉得第一个对象(序号为0);setMaxResults(int maxResults)方法用于指定一次最多检索出的对象数目,默觉得全部对象。
Session session = HibernateSessionFactory.getSessionFactory().openSession();
Transaction ts = null;
Criteria criteria = session.createCriteria(Order.class);
int pageSize = 15;
int pageNo = 1;
criteria.setFirstResult((pageNo-1)*pageSize);
criteria.setMaxResults(pageSize);
Iterator it = criteria.list().iterator();
ts.commit();
HibernateSessionFactory.closeSession();
六、 QBC复合查询
复合查询就是在原有的查询基础上再进行查询。比如在顾客对定单的一对多关系中,在查询出全部的顾客对象后,希望在查询定单中money大于1000的定单对象。
Session session = HibernateSessionFactory.getSessionFactory().openSession();
Transaction ts = session.beginTransaction();
Criteria cuscriteria = session.createCriteria(Customer.class);
Criteria ordCriteria = cusCriteria.createCriteria("orders");
ordCriteria.add(Restrictions.gt("money", new Double(1000)));
Iterator it = cusCriteria.list().iterator();
ts.commit();
HibernateSessionFactory.closeSession();
七、 QBC离线查询
离线查询又叫DetachedCriteria查询,它能够在Session之外进行构造,仅仅有在须要运行查询时才与Session绑定。Session session =HibernateSessionFactory.getSessionFactory().openSession();
Transaction ts =session.beginTransaction();
Criteria cuscriteria =session.createCriteria(Customer.class);
Criteria ordCriteria =cusCriteria.createCriteria("orders");
ordCriteria.add(Restrictions.gt("money",new Double(1000)));
Iterator it =cusCriteria.list().iterator();
ts.commit();
HibernateSessionFactory.closeSession();
第21课 Query By Example(QBE)
QBE查询就是检索与指定样本对象具有同样属性值的对象。因此QBE查询的关键就是样本对象的创建,样本对象中的全部非空属性均将作为查询条件。QBE查询的功能子集,尽管QBE没有QBC功能大,可是有些场合QBE使用起来更为方便。
工具类Example为Criteria对象指定样本对象作为查询条件
一、 实例代码
Session session = sf.openSession();
session.beginTransaction();
Topic tExample = new Topic();
tExample.setTitle("T_");
Example e = Example.create(tExample)
.ignoreCase().enableLike();
Criteria c = session.createCriteria(Topic.class)
.add(Restrictions.gt("id", 2))
.add(Restrictions.lt("id", 8))
.add(e);
for(Object o : c.list()) {
Topic t = (Topic)o;
System.out.println(t.getId() + "-" + t.getTitle());
}
session.getTransaction().commit();
session.close();
Session session = HibernateSessionFactory.getSessionFactory().openSession();
Transaction ts = session.beginTransaction();
Customer c = new Customer();
c.setCname("Hibernate");
Criteria criteria = session.createCriteria(Customer.class);
Criteria.add(Example.create(c));
Iterator it = criteria.list().iterator();
ts.commit();
HibernateSessionFactory.closeSession();
第22课 Query.list与query.iterate(不太重要)
一、 query.iterate查询数据
* query.iterate()方式返回迭代查询
* 会開始发出一条语句:查询全部记录ID语句
* Hibernate: select student0_.id as col_0_0_from t_student student0_
* 然后有多少条记录,会发出多少条查询语句。
* n + 1问题:n:有n条记录,发出n条查询语句;1 :发出一条查询全部记录ID语句。
* 出现n+1的原因:由于iterate(迭代查询)是使用缓存的,
第一次查询数据时发出查询语句载入数据并增加到缓存,以后再查询时hibernate会先到ession缓存(一级缓存)中查看数据是否存在,假设存在则直接取出使用,否则发出查询语句进行查询。
session= HibernateUtils.getSession();
tx = session.beginTransaction();
/**
* 出现N+1问题
* 发出查询id列表的sql语句
* Hibernate: select student0_.id as col_0_0_ from t_student student0_
*
* 再依次发出依据id查询Student对象的sql语句
* Hibernate: select student0_.id as id1_0_, student0_.name as name1_0_,
* student0_.createTime as createTime1_0_, student0_.classesid as classesid1_0_
* from t_student student0_ where student0_.id=?
*/
Iterator students = session.createQuery("fromStudent").iterate();
while (students.hasNext()){
Student student =(Student)students.next();
System.out.println(student.getName());
}
tx.commit();
二、 query.list()和query.iterate()的差别
先运行query.list(),再运行query.iterate,这样不会出现N+1问题,
* 由于list操作已经将Student对象放到了一级缓存中,所以再次使用iterate操作的时候
* 它首先发出一条查询id列表的sql,再依据id到缓存中取数据,仅仅有在缓存中找不到相应的
* 数据时,才会发出sql到数据库中查询
Liststudents = session.createQuery("from Student").list();
for (Iterator iter = students.iterator();iter.hasNext();){
Student student =(Student)iter.next();
System.out.println(student.getName());
} System.out.println("---------------------------------------------------------");
// 不会出现N+1问题,由于list操作已经将数据增加到一级缓存。
Iterator iters =session.createQuery("from Student").iterate();
while (iters.hasNext()){
Student student =(Student)iters.next();
System.out.println(student.getName());
}
三、 两次query.list()
* 会再次发出查询sql
* 在默认情况下list每次都会向数据库发出查询对象的sql,除非配置了查询缓存
* 所以:尽管list操作已经将数据放到一级缓存,但list默认情况下不会利用缓存,而再次发出sql
* 默认情况下,list会向缓存中放入数据,但不会使用数据。
Liststudents = session.createQuery("from Student").list();
for (Iterator iter = students.iterator();iter.hasNext();){
Student student =(Student)iter.next();
System.out.println(student.getName());
}
System.out.println("------------------------------------------------");
//会再次发现SQL语句进行查询,由于默认情况list仅仅向缓存中放入数据,不会使用缓存中数据
students = session.createQuery("fromStudent").list();
for (Iterator iter = students.iterator();iter.hasNext();){
Student student =(Student)iter.next();
System.out.println(student.getName());
}
第23课性能优化策略
1、 注意session.clear()的动用,尤其在不断分页循环的时候
a) 在一个大集合中进行遍历,遍历msg,取出当中的含有敏感字样的对象
b) 第二种形式的内存泄露 //面试是:Java有内存泄漏吗?
2、 1 + N问题 //典型的面试题
a) Lazy
b) BatchSize 设置在实体类的前面
c) joinfetch
3、 list 和 iterate不同之处
a) list取全部
b) Iterate先取ID,等用到的时候再依据ID来取对象
c) session中list第二次发出,仍会到数据库查询
d) iterate第二次,首先找session级缓存
第24课hibernate缓存
一、 Session级缓存(一级缓存)
一级缓存非常短和session的生命周期一致,因此也叫session级缓存或事务级缓存
hibernate一级缓存
那些方法支持一级缓存:
* get()
* load()
* iterate(查询实体对象)
怎样管理一级缓存:
*session.clear(),session.evict()
怎样避免一次性大量的实体数据入库导致内存溢出
* 先flush,再clear
假设数据量特别大,考虑採用jdbc实现,假设jdbc也不能满足要求能够考虑採用数据本身的特定导入工具
二、 二级缓存
Hibernate默认的二级缓存是开启的。
二级缓存也称为进程级的缓存,也可称为SessionFactory级的缓存(由于SessionFactory能够管理二级缓存),它与session级缓存不一样,一级缓存仅仅要session关闭缓存就不存在了。而二级缓存则仅仅要进程在二级缓存就可用。
二级缓存能够被全部的session共享
二级缓存的生命周期和SessionFactory的生命周期一样,SessionFactory能够管理二级缓存
二级缓存同session级缓存一样,仅仅缓存实体对象,普通属性的查询不会缓存
二级缓存一般使用第三方的产品,如EHCache
配置二级缓存的配置文件:模板文件位于hibernate\etc文件夹下(如ehcache.xml),将模板存放在ClassPath文件夹中,一般放在根文件夹下(src文件夹下)
<ehcache>
<!-- 设置当缓存对象益出时,对象保存到磁盘时的保存路径。
如 d:\xxxx
The following properties aretranslated:
user.home - User's home directory
user.dir - User's current workingdirectory
java.io.tmpdir - windows的暂时文件夹 -->
<diskStore path="java.io.tmpdir"/>
<!--默认配置/或对某一个类进行管理
maxInMemory - 缓存中能够存入的最多个对象数
eternal - true:表示永不失效,false:不是永久有效的。
timeToIdleSeconds - 空暇时间,当第一次訪问后在空暇时间内没有訪问,则对象失效,单位为秒
timeToLiveSeconds - 被缓存的对象有效的生命时间,单位为秒
overflowToDisk 当缓存中对象数超过核定数(益出时)时,对象是否保存到磁盘上。true:保存;false:不保存
假设保存,则保存路径在标签<diskStore>中属性path指定
-->
<defaultCache
maxElementsInMemory="10000"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"
/>
</ehcache>
Hibernate中二级缓存默认就是开启的,也能够显示的开启
二级缓存是hibernate的配置文件设置例如以下:
<!--开启二级缓存,hibernate默认的二级缓存就是开启的 -->
<property name="hibernate.cache.use_second_level_cache">true</property>
改动hibernate的 配置文件,指定二级缓存提供商,例如以下:
<!--指定二级缓存提供商-->
<property name="hibernate.cache.provider_class">
org.hibernate.cache.EhCacheProvider
</property>
以下为常见缓存提供商:
|
Cache |
Provider class |
Type |
Cluster Safe |
Query Cache Supported |
|
Hashtable (not intended for production use) |
org.hibernate.cache.HashtableCacheProvider |
memory |
yes |
|
|
EHCache |
org.hibernate.cache.EhCacheProvider |
memory, disk |
yes |
|
|
OSCache |
org.hibernate.cache.OSCacheProvider |
memory, disk |
yes |
|
|
SwarmCache |
org.hibernate.cache.SwarmCacheProvider |
clustered (ip multicast) |
yes (clustered invalidation) |
|
|
JBoss TreeCache |
org.hibernate.cache.TreeCacheProvider |
clustered (ip multicast), transactional |
yes (replication) |
yes (clock sync req.) |
a) xml方式:指定哪些实体类使用二级缓存:
方法一:在实体类映射文件里,使用<cache>来指定那个实体类使用二级缓存,例如以下:
<cache
usage="transactional|read-write|nonstrict-read-write|read-only" (1)
region="RegionName" (2)
include="all|non-lazy" (3)
/>
(1) usage(必须)说明了缓存的策略: transactional、 read-write、nonstrict-read-write或read-only。
(2) region (可选, 默觉得类或者集合的名字(class orcollection role name)) 指定第二级缓存的区域名(name of the secondlevel cache region)
(3) include (可选,默觉得 all) non-lazy 当属性级延迟抓取打开时, 标记为lazy="true"的实体的属性可能无法被缓存
另外(首选?), 你能够在hibernate.cfg.xml中指定<class-cache>和 <collection-cache> 元素。
这里的usage 属性指明了缓存并发策略(cache concurrency strategy)。
策略:仅仅读缓存(Strategy:read only)
假设你的应用程序仅仅需读取一个持久化类的实例,而无需对其改动, 那么就能够对其进行仅仅读 缓存。这是最简单,也是实用性最好的方法。甚至在集群中,它也能完美地运作。
<class name="eg.Immutable" mutable="false">
<cache usage="read-only"/>
....
</class>
策略:读/写缓存(Strategy:read/write)
假设应用程序须要更新数据,那么使用读/写缓存 比較合适。 假设应用程序要求“序列化事务”的隔离级别(serializable transaction isolation level),那么就决不能使用这样的缓存策略。 假设在JTA环境中使用缓存,你必须指定hibernate.transaction.manager_lookup_class属性的值, 通过它,Hibernate才干知道该应用程序中JTA的TransactionManager的详细策略。 在其他环境中,你必须保证在Session.close()、或Session.disconnect()调用前, 整个事务已经结束。 假设你想在集群环境中使用此策略,你必须保证底层的缓存实现支持锁定(locking)。Hibernate内置的缓存策略并不支持锁定功能。
<class name="eg.Cat" .... >
<cache usage="read-write"/>
....
<set name="kittens" ... >
<cache usage="read-write"/>
....
</set>
</class>
策略:非严格读/写缓存(Strategy: nonstrictread/write)
假设应用程序仅仅偶尔须要更新数据(也就是说,两个事务同一时候更新同一记录的情况非常不常见),也不须要十分严格的事务隔离,那么比較适合使用非严格读/写缓存策略。假设在JTA环境中使用该策略,你必须为其指定hibernate.transaction.manager_lookup_class属性的值, 在其他环境中,你必须保证在Session.close()、或Session.disconnect()调用前, 整个事务已经结束。
策略:事务缓存(transactional)
Hibernate的事务缓存策略提供了全事务的缓存支持, 比如对JBoss TreeCache的支持。这样的缓存仅仅能用于JTA环境中,你必须指定为其hibernate.transaction.manager_lookup_class属性。
没有一种缓存提供商能够支持上列的全部缓存并发策略。下表中列出了各种提供器、及其各自适用的并发策略。
表 19.2. 各种缓存提供商对缓存并发策略的支持情况(Cache Concurrency Strategy Support)
|
Cache |
read-only |
nonstrict-read-write |
read-write |
transactional |
|
Hashtable (not intended for production use) |
yes |
yes |
yes |
|
|
EHCache |
yes |
yes |
yes |
|
|
OSCache |
yes |
yes |
yes |
|
|
SwarmCache |
yes |
yes |
||
|
JBoss TreeCache |
yes |
yes |
注:此方法要求:必须要标签<cache>放在<id>标签之前
<class name="com.wjt276.hibernate.Student"table="t_student">
<!-- 指定实体类使用二级缓存 -->
<cache usage="read-only"/>//***********
<id name="id"column="id">
<generator class="native"/>
</id>
<property name="name"column="name"/>
<!--
使用多对一标签映射 一对多双向,下列的column值必需与多的一端的key字段值一样。
-->
<many-to-one name="classes"column="classesid"/>
</class>
方法二:在hibernate配置文件(hibernate.cfg.xml)使用<class-cache>标签中指定
要求:<class-cache>标签必须放在<maping>标签之后。
<hibernate-configuration>
<session-factory>
…………
<mapping resource="com/wjt276/hibernate/Classes.hbm.xml"/>
<mapping resource="com/wjt276/hibernate/Student.hbm.xml"/>
<class-cache class="com.wjt276.hibernate.Student"usage="read-only"/>
</session-factory>
</hibernate-configuration>
一般推荐使用方法一。
b) annotation注解
为了优化数据库訪问,你能够激活所谓的Hibernate二级缓存.该缓存是能够按每一个实体和集合进行配置的.
@org.hibernate.annotations.Cache定义了缓存策略及给定的二级缓存的范围. 此注解适用于根实体(非子实体),还有集合.
@Entity
@Cache(usage= CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
publicclass Forest { ... }
@OneToMany(cascade=CascadeType.ALL,fetch=FetchType.EAGER)
@JoinColumn(name="CUST_ID")
@Cache(usage =CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
public SortedSet<Ticket> getTickets(){
return tickets;
}
@Cache(
CacheConcurrencyStrategy usage(); (1)
String region() default ""; (2)
String include() default"all"; (3)
)
|
(1) |
usage: 给定缓存的并发策略(NONE, READ_ONLY, NONSTRICT_READ_WRITE, READ_WRITE, TRANSACTIONAL) |
|
(2) |
region (可选的):缓存范围(默觉得类的全限定类名或是集合的全限定角色名) |
|
(3) |
include (可选的):值为all时包括了全部的属性(proterty), 为non-lazy时仅含非延迟属性(默认值为all) |
没有变化,近似于静态的数据。
1、 清除指定实体类的全部数据
SessionFactory.evict(Student.class);
2、 清除指定实体类的指定对象
SessionFactory.evict(Student.class, 1);//第二个參数是指定对象的ID,就能够清除指定ID的对象
使用SessionFactory清除二级缓存
Sessionsession = null;
try {
session = HibernateUtils.getSession();
session.beginTransaction();
Student student = (Student)session.load(Student.class, 1);
System.out.println("student.name=" +student.getName());
session.getTransaction().commit();
}catch(Exception e) {
e.printStackTrace();
session.getTransaction().rollback();
}finally {
HibernateUtils.closeSession(session);
}
//管理二级缓存
SessionFactory factory = HibernateUtils.getSessionFactory();
//factory.evict(Student.class);
factory.evict(Student.class, 1);
try {
session = HibernateUtils.getSession();
session.beginTransaction();
//会发出查询sql,由于二级缓存中的数据被清除了
Student student = (Student)session.load(Student.class, 1);
System.out.println("student.name=" +student.getName());
session.getTransaction().commit();
}catch(Exception e) {
e.printStackTrace();
session.getTransaction().rollback();
}finally {
HibernateUtils.closeSession(session);
}
Sessionsession = null;
try {
session = HibernateUtils.getSession();
session.beginTransaction();
//仅向二级缓存读数据,而不向二级缓存写数据
session.setCacheMode(CacheMode.GET);
Student student =(Student)session.load(Student.class, 1);
System.out.println("student.name=" +student.getName());
session.getTransaction().commit();
}catch(Exception e) {
e.printStackTrace();
session.getTransaction().rollback();
}finally {
HibernateUtils.closeSession(session);
}
try {
session = HibernateUtils.getSession();
session.beginTransaction();
//发出sql语句,由于session设置了CacheMode为GET,所以二级缓存中没有数据
Student student =(Student)session.load(Student.class, 1);
System.out.println("student.name=" +student.getName());
session.getTransaction().commit();
}catch(Exception e) {
e.printStackTrace();
session.getTransaction().rollback();
}finally {
HibernateUtils.closeSession(session);
}
try {
session = HibernateUtils.getSession();
session.beginTransaction();
//仅仅向二级缓存写数据,而不从二级缓存读数据
session.setCacheMode(CacheMode.PUT);
//会发出查询sql,由于session将CacheMode设置成了PUT
Student student =(Student)session.load(Student.class, 1);
System.out.println("student.name=" +student.getName());
session.getTransaction().commit();
}catch(Exception e) {
e.printStackTrace();
session.getTransaction().rollback();
}finally {
HibernateUtils.closeSession(session);
}
CacheMode參数用于控制详细的Session怎样与二级缓存进行交互。
· CacheMode.NORMAL - 从二级缓存中读、写数据。
· CacheMode.GET - 从二级缓存中读取数据,仅在数据更新时对二级缓存写数据。
· CacheMode.PUT - 仅向二级缓存写数据,但不从二级缓存中读数据。
· CacheMode.REFRESH - 仅向二级缓存写数据,但不从二级缓存中读数据。通过hibernate.cache.use_minimal_puts的设置,强制二级缓存从数据库中读取数据,刷新缓存内容。
如若须要查看二级缓存或查询缓存区域的内容,你能够使用统计(Statistics) API。
Map cacheEntries = sessionFactory.getStatistics()
.getSecondLevelCacheStatistics(regionName)
.getEntries();
此时,你必须手工打开统计选项。可选的,你能够让Hibernate更人工可读的方式维护缓存内容。
hibernate.generate_statistics true
hibernate.cache.use_structured_entries true
load默认使用二级缓存,iterate默认使用二级缓存
list默认向二级缓存中加数据,可是查询时候不使用
三、 查询缓存
查询缓存,是用于缓存普通属性查询的,当查询实体时缓存实体ID。
默认情况下关闭,须要打开。查询缓存,对list/iterator这样的操作会起作用。
能够使用<property name=”hibernate.cache.use_query_cache”>true</property>来打开查询缓存,默觉得关闭。
所谓查询缓存:即让hibernate缓存list、iterator、createQuery等方法的查询结果集。假设没有打开查询缓存,hibernate将仅仅缓存load方法获得的单个持久化对象。
在打开了查询缓存之后,须要注意,调用query.list()操作之前,必须显式调用query.setCachable(true)来标识某个查询使用缓存。
查询缓存的生命周期:当前关联的表发生改动,那么查询缓存生命周期结束
注意查询缓存依赖于二级缓存,由于使用查询缓存须要打开二级缓存
查询缓存的配置和使用:
* 在hibernate.cfg.xml文件里启用查询缓存,如:
<propertyname="hibernate.cache.use_query_cache">true</property>
* 在程序中必须手动启用查询缓存,如:
query.setCacheable(true);
比如:
session= HibernateUtils.getSession();
session.beginTransaction();
Query query = session.createQuery("selects.name from Student s");
//启用查询查询缓存
query.setCacheable(true);
List names = query.list();
for (Iterator iter=names.iterator();iter.hasNext();) {
String name =(String)iter.next();
System.out.println(name);
}
System.out.println("-------------------------------------");
query = session.createQuery("selects.name from Student s");
//启用查询查询缓存
query.setCacheable(true);
//没有发出查询sql,由于启用了查询缓存
names = query.list();
for (Iteratoriter=names.iterator();iter.hasNext(); ) {
String name =(String)iter.next();
System.out.println(name);
}
session.getTransaction().commit();
Session session = sf.openSession();
session.beginTransaction();
List<Category>categories = (List<Category>)session.createQuery("from Category")
.setCacheable(true).list();
session.getTransaction().commit();
session.close();
Session session2 = sf.openSession();
session2.beginTransaction();
List<Category>categories2 = (List<Category>)session2.createQuery("from Category")
.setCacheable(true).list();
session2.getTransaction().commit();
session2.close();
注:查询缓存的生命周期与session无关。
查询缓存仅仅对query.list()起作用,query.iterate不起作用,也就是query.iterate不使用
四、 缓存算法
1、 LRU、LFU、FIFO
第25课 事务并发处理
一、 数据库的隔离级别:并发性作用。
1、 ReadUncommited(未提交读):没有提交就能够读取到数据(发出了Insert,但没有commit就能够读取到。)非常少用
2、 ReadCommited(提交读):仅仅有提交后才干够读,经常使用,
3、 RepeatableRead(可反复读):mysql默认级别, 必需提交才干见到,读取数据时数据被锁住。
4、 Serialiazble(序列化读):最高隔离级别,串型的,你操作完了,我才干够操作,并发性特别不好,
|
隔离级别 |
是否存在脏读 |
是否存在不可反复读 |
是否存在幻读 |
|
Read Uncommitted(未提交读) |
Y |
Y |
Y |
|
Read Commited(提交读) |
N |
Y(可採用悲观锁解决) |
Y |
|
Repeatable Read(可反复读) |
N |
N |
Y |
|
Serialiazble(序列化读) |
脏读:没有提交就能够读取到数据称为脏读
不可反复读:再反复读一次,数据与你上的不一样。称不可反复读。
幻读:在查询某一条件的数据,開始查询的后,别人又增加或删除些数据,再读取时与原来的数据不一样了。
1、 Mysql查看数据库隔离级别:
方法:select@@tx_isolation;

2、 Mysql数据库改动隔离级别:
方法:set transactionisolation level 隔离级别名称;
比如:改动为未提交读:settransaction isolation level read uncommitted;
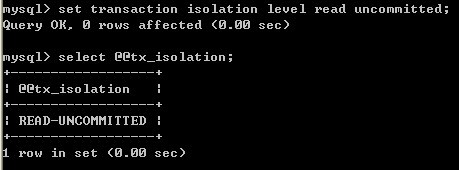
二、 事务概念(ACID)
ACID即:事务的原子性、一致性、独立性及持久性
事务的原子性:是指一个事务要么全部运行,要么不运行.也就是说一个事务不可能仅仅运行了一半就停止了.比方你从取款机取钱,这个事务能够分成两个步骤:1划卡,2出钱.不可能划了卡,而钱却没出来.这两步必须同一时候完毕.要么就不完毕.
事务的一致性:是指事务的运行并不改变数据库中数据的一致性.比如,完整性约束了a+b=10,一个事务改变了a,那么b也应该随之改变.
事务的独立性:是指两个以上的事务不会出现交错运行的状态.由于这样可能会导致数据不一致.
事务的持久性:是指事务运行成功以后,就系统的更新是永久的.不会无缘无故的回滚.
三、 事务并发时可能出现故障
1、第一类丢失更新(Lost Update)
|
时间 |
||
第26课hibernate悲观锁、乐观锁
Hibernate谈到悲观锁、乐观锁,就要谈到数据库的并发问题,数据库的隔离级别越高它的并发性就越差
并发性:当前系统进行了序列化后,当前读取数据后,别人查询不了,看不了。称为并发性不好
数据库隔离级别:见前面章级
一、 悲观锁
悲观锁:具有排他性(我锁住当前数据后,别人看到不此数据)
悲观锁一般由数据机制来做到的。
1、 悲观锁的实现
通常依赖于数据库机制,在整修过程中将数据锁定,其他不论什么用户都不能读取或改动(如:必需我改动完之后,别人才干够改动)
2、 悲观锁的适用场景:
悲观锁一般适合短事务比較多(如某一数据取出后加1,马上释放)
长事务占有时间(假设占有1个小时,那么这个1小时别人就不能够使用这些数据),不经常使用。
3、 实例:
yon
用户1、用户2 同一时候读取到数据,可是用户2先 -200,这时数据库里的是800,如今用户1也開始-200,可是用户1刚才读取到的数据是1000,如今用户用刚刚一開始读取的数据1000-200为800,而用户1在更新时数据库里的是用房更新的数据800,按理说用户1应该是800-200=600,而如今是800,这样就造成的更新丢失。这样的情况该怎样处理呢,可採用两种方法:悲观锁、乐观锁。先看看悲观锁:用户1读取数据后,用锁将其读取的数据锁上,这时用户2是读取不到数据的,仅仅实用户1释放锁后用户2才干够读取,同样用户2读取数据也锁上。这样就能够解决更新丢失的问题了。
实体类:
public class Inventory {
private int itemNo;
privateString itemName;
private int quantity;
public intgetItemNo() {
return itemNo;
}
public voidsetItemNo(intitemNo) {
this.itemNo =itemNo;
}
publicString getItemName() {
return itemName;
}
public voidsetItemName(String itemName) {
this.itemName =itemName;
}
public intgetQuantity() {
return quantity;
}
public voidsetQuantity(intquantity) {
this.quantity =quantity;
}
}
映射文件:
<hibernate-mapping>
<class name="com.wjt276.hibernate.Inventory"table="t_inventory">
<id name="itemNo">
<generator class="native"/>
</id>
<property name="itemName"/>
<property name="quantity"/>
</class>
</hibernate-mapping>
4、 悲观锁的使用
假设须要使用悲观锁,肯定在载入数据时就要锁住,通常採用数据库的for update语句。
Hibernate使用Load进行悲观锁载入。
Session.load(Classarg0, Serializable arg1, LockMode arg2) throws HibernateException
LockMode:悲观锁模式(一般使用LockMode.UPGRADE)
session= HibernateUtils.getSession();
tx = session.beginTransaction();
Inventory inv =(Inventory)session.load(Inventory.class, 1,LockMode.UPGRADE);
System.out.println(inv.getItemName());
inv.setQuantity(inv.getQuantity()-200);
session.update(inv);
tx.commit();
5、 运行输出SQL语句:
Hibernate:select inventory0_.itemNo as itemNo0_0_, inventory0_.itemName as itemName0_0_,inventory0_.quantity as quantity0_0_ from t_inventory inventory0_ where inventory0_.itemNo=?for update //在select语句中增加for update进行使用悲观锁。
脑白金
Hibernate:update t_inventory set itemName=?, quantity=? where itemNo=?
注:仅仅实用户释放锁后,别的用户才干够读取
注:假设使用悲观锁,那么lazy(悚载入无效)
二、 乐观锁
乐观锁:不是锁,是一种冲突检測机制。
乐观锁的并发性较好,由于我改的时候,别人随边改动。
乐观锁的实现方式:经常使用的是版本号的方式(每一个数据表中有一个版本号字段version,某一个用户更新数据后,版本号号+1,还有一个用户改动后再+1,当用户更新发现数据库当前版本号号与读取数据时版本号号不一致(等于小于数据库当前版本号号),则更新不了。
Hibernate使用乐观锁须要在映射文件里配置项才可生效。
实体类:
public classInventory {
private int itemNo;
privateString itemName;
private int quantity;
private int version;//Hibernate用户实现版本号方式乐观锁,但须要在映射文件里配置
public intgetItemNo() {
return itemNo;
}
public voidsetItemNo(intitemNo) {
this.itemNo =itemNo;
}
publicString getItemName() {
return itemName;
}
public voidsetItemName(String itemName) {
this.itemName =itemName;
}
public intgetQuantity() {
return quantity;
}
public voidsetQuantity(intquantity) {
this.quantity =quantity;
}
public intgetVersion() {
return version;
}
public voidsetVersion(intversion) {
this.version =version;
}
}
映射文件
<hibernate-mapping>
<!-- 映射实体类时,须要增加一个开启乐观锁的属性
optimistic-lock="version" 共同拥有好几种方式:
- none -version - dirty - all
同一时候须要在主键映射后面映射版本号号字段
-->
<class name="com.wjt276.hibernate.Inventory"table="t_inventory"optimistic-lock="version">
<id name="itemNo">
<generator class="native"/>
</id>
<version name="version"/><!—必需配置在主键映射后面 -->
<property name="itemName"/>
<property name="quantity"/>
</class>
</hibernate-mapping>
导出输出SQL语句:
createtable t_inventory (itemNo integer not null auto_increment, versioninteger not null, itemName varchar(255), quantity integer,primary key (itemNo))
注:增加的版本号字段version,还是我们来维护的,是由hibernate来维护的。
乐观锁在存储数据时不用关心
Hibernate 学习教程的更多相关文章
- 大量Javascript/JQuery学习教程电子书合集
[推荐分享]大量Javascript/JQuery学习教程电子书合集,送给有需要的人 不收藏是你的错^_^. 经证实,均可免费下载. 资源名称 资源大小 15天学会jQuery(完整版).pd ...
- [推荐分享]大量Javascript/JQuery学习教程电子书合集,送给有需要的人
不收藏是你的错^_^. 经证实,均可免费下载. 资源名称 资源大小 15天学会jQuery(完整版).pdf 274.79 KB 21天学通JavaScript(第2版)-顾宁燕扫描版.pdf ...
- Hibernate学习之——搭建log4j日志环境
昨天讲了Hibernate开发环境的搭建以及实现一个Hibernate的基础示例,但是你会发现运行输出只有sql语句,很多输出信息都看不见.这是因为用到的是slf4j-nop-1.6.1.jar的实现 ...
- Hibernate学习笔记(二)
2016/4/22 23:19:44 Hibernate学习笔记(二) 1.1 Hibernate的持久化类状态 1.1.1 Hibernate的持久化类状态 持久化:就是一个实体类与数据库表建立了映 ...
- Hibernate学习笔记(一)
2016/4/18 19:58:58 Hibernate学习笔记(一) 1.Hibernate框架的概述: 就是一个持久层的ORM框架. ORM:对象关系映射.将Java中实体对象与关系型数据库中表建 ...
- Deep Learning 19_深度学习UFLDL教程:Convolutional Neural Network_Exercise(斯坦福大学深度学习教程)
理论知识:Optimization: Stochastic Gradient Descent和Convolutional Neural Network CNN卷积神经网络推导和实现.Deep lear ...
- WebPack 简明学习教程
WebPack 简明学习教程 字数1291 阅读22812 评论11 喜欢35 WebPack是什么 一个打包工具 一个模块加载工具 各种资源都可以当成模块来处理 网站 http://webpack. ...
- Hibernate 学习笔记一
Hibernate 学习笔记一 今天学习了hibernate的一点入门知识,主要是配置domain对象和表的关系映射,hibernate的一些常用的配置,以及对应的一个向数据库插入数据的小例子.期间碰 ...
- MyBatis入门学习教程-使用MyBatis对表执行CRUD操作
上一篇MyBatis学习总结(一)--MyBatis快速入门中我们讲了如何使用Mybatis查询users表中的数据,算是对MyBatis有一个初步的入门了,今天讲解一下如何使用MyBatis对use ...
随机推荐
- Burp Suite抓包、截包和改包
Burp Suite..呵呵.. 听说Burp Suite是能够监測.截取.改动我们訪问web应用的数据包,这么牛X? 条件:本地网络使用代理.由Burp Suite来代理.也就是说,每一个流出外网的 ...
- hdu1542(线段树——矩形面积并)
题目连接:http://acm.hdu.edu.cn/showproblem.php?pid=1542 分析:离散化+扫描线+线段树 #pragma comment(linker,"/STA ...
- Cocos2d-x3.0 Button
Size widgetSize = Director::getInstance()->getWinSize(); Text* alert = Text::create("Layout& ...
- cocos2d-x 旅程開始--(实现瓦片地图中的碰撞检測)
转眼隔了一天了,昨天搞了整整一下午加一晚上,楞是没搞定小坦克跟砖头的碰撞检測,带着个问题睡觉甚是难受啊!还好今天弄成功了.只是感觉程序不怎么稳定啊.并且发现自己写的东西让我重写一遍的话我肯定写不出来. ...
- 最牛B的编程套路
最近,我大量阅读了Steve Yegge的文章.其中有一篇叫“Practicing Programming”(练习编程),写成于2005年,读后令我惊讶不已: 与你所相信的恰恰相反,单纯地每天埋头于工 ...
- MyBatis一级缓存引起的无穷递归
MyBatis一级缓存引起的无穷递归 引言: 最近在项目中参与了一个领取优惠劵的活动,当多个用户领取同一张优惠劵的时候,使用了数据库锁控制并发,起初的设想是:如果多个人同时领一张劵,第一个到达的人领取 ...
- bash,bg,bind,break,builtin,caller,compgen, complete,compopt,continue,declare,dirs,disown,enable,eval,exec,expo
bash,bg,bind,break,builtin,caller,compgen, complete,compopt,continue,declare,dirs,disown,enable,eval ...
- KSImageNamed-Xcode
KSImageNamed-Xcode 非常的给力的XCODE图片浏览插件; What is this? Can't remember whether that image you just add ...
- hdu4336压缩率大方的状态DP
Card Collector Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) T ...
- 通过openssh远程登录时的延迟问题解决
Linux下的ssh 服务器一般用的都是open-ssh,可是发现有些时候通过ssh连接服务器时总会有大概10秒钟左右的延迟. 一开始以为是openssh的安全策略,防止端口扫描,后来发现自己想多了. ...