K-Means 算法(转载)
K-Means 算法
在数据挖掘中, k-Means 算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
问题
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?于是就出现了我们的K-Means算法(Wikipedia链接)
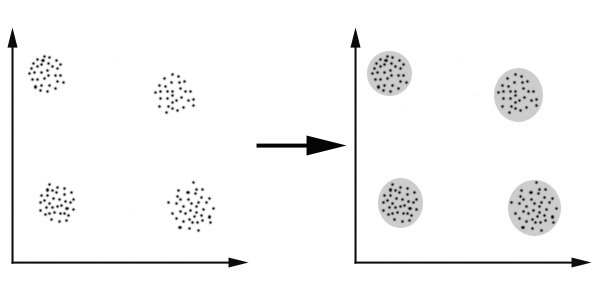
K-Means 要解决的问题
算法概要
这个算法其实很简单,如下图所示:
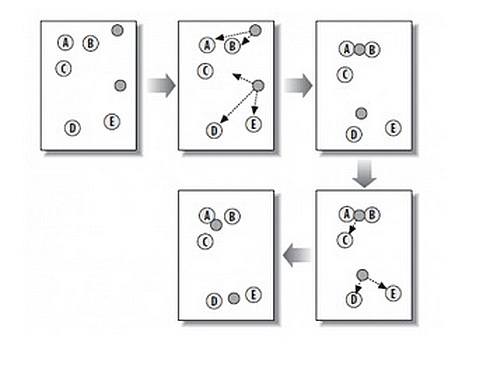
K-Means 算法概要
从上图中,我们可以看到,A, B, C, D, E 是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
- 随机在图中取K(这里K=2)个种子点。
- 然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
- 接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
- 然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
这个算法很简单,但是有些细节我要提一下,求距离的公式我不说了,大家有初中毕业水平的人都应该知道怎么算的。我重点想说一下“求点群中心的算法”
求点群中心的算法
一般来说,求点群中心点的算法你可以很简的使用各个点的X/Y坐标的平均值。不过,我这里想告诉大家另三个求中心点的的公式:
1)Minkowski Distance 公式 —— λ 可以随意取值,可以是负数,也可以是正数,或是无穷大。
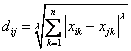
2)Euclidean Distance 公式 —— 也就是第一个公式 λ=2 的情况
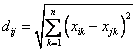
3)CityBlock Distance 公式 —— 也就是第一个公式 λ=1 的情况
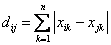
这三个公式的求中心点有一些不一样的地方,我们看下图(对于第一个 λ 在 0-1之间)。



(1)Minkowski Distance (2)Euclidean Distance (3) CityBlock Distance
上面这几个图的大意是他们是怎么个逼近中心的,第一个图以星形的方式,第二个图以同心圆的方式,第三个图以菱形的方式。
K-Means的演示
如果你以”K Means Demo“为关键字到Google里查你可以查到很多演示。这里推荐一个演示
http://home.dei.polimi.it/matteucc/Clustering/tutorial_html/AppletKM.html
操作是,鼠标左键是初始化点,右键初始化“种子点”,然后勾选“Show History”可以看到一步一步的迭代。
注:这个演示的链接也有一个不错的 K Means Tutorial 。
K-Means ++ 算法
K-Means主要有两个最重大的缺陷——都和初始值有关:
- K 是事先给定的,这个 K 值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。( ISODATA 算法通过类的自动合并和分裂,得到较为合理的类型数目 K)
- K-Means算法需要用初始随机种子点来搞,这个随机种子点太重要,不同的随机种子点会有得到完全不同的结果。(K-Means++算法可以用来解决这个问题,其可以有效地选择初始点)
我在这里重点说一下 K-Means++算法步骤:
- 先从我们的数据库随机挑个随机点当“种子点”。
- 对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
- 然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。
- 重复第(2)和第(3)步直到所有的K个种子点都被选出来。
- 进行K-Means算法。
相关的代码你可以在这里找到“implement the K-means++ algorithm”(墙) 另,Apache 的通用数据学库也实现了这一算法
K-Means 算法应用
看到这里,你会说,K-Means算法看来很简单,而且好像就是在玩坐标点,没什么真实用处。而且,这个算法缺陷很多,还不如人工呢。是的,前面的例子只是玩二维坐标点,的确没什么意思。但是你想一下下面的几个问题:
1)如果不是二维的,是多维的,如5维的,那么,就只能用计算机来计算了。
2)二维坐标点的X, Y 坐标,其实是一种向量,是一种数学抽象。现实世界中很多属性是可以抽象成向量的,比如,我们的年龄,我们的喜好,我们的商品,等等,能抽象成向量的目的就是可以让计算机知道某两个属性间的距离。如:我们认为,18岁的人离24岁的人的距离要比离12岁的距离要近,鞋子这个商品离衣服这个商品的距离要比电脑要近,等等。
只要能把现实世界的物体的属性抽象成向量,就可以用K-Means算法来归类了。
在 《k均值聚类(K-means)》 这篇文章中举了一个很不错的应用例子,作者用亚洲15支足球队的2005年到1010年的战绩做了一个向量表,然后用K-Means把球队归类,得出了下面的结果,呵呵。
- 亚洲一流:日本,韩国,伊朗,沙特
- 亚洲二流:乌兹别克斯坦,巴林,朝鲜
- 亚洲三流:中国,伊拉克,卡塔尔,阿联酋,泰国,越南,阿曼,印尼
其实,这样的业务例子还有很多,比如,分析一个公司的客户分类,这样可以对不同的客户使用不同的商业策略,或是电子商务中分析商品相似度,归类商品,从而可以使用一些不同的销售策略,等等。
最后给一个挺好的算法的幻灯片:http://www.cs.cmu.edu/~guestrin/Class/10701-S07/Slides/clustering.pdf
(全文完)
kmeans聚类理论篇
前言
kmeans是最简单的聚类算法之一,但是运用十分广泛。最近在工作中也经常遇到这个算法。kmeans一般在数据分析前期使用,选取适当的k,将数据分类后,然后分类研究不同聚类下数据的特点。
本文记录学习kmeans算法相关的内容,包括算法原理,收敛性,效果评估聚,最后带上R语言的例子,作为备忘。
算法原理
kmeans的计算方法如下:
1 随机选取k个中心点
2 遍历所有数据,将每个数据划分到最近的中心点中
3 计算每个聚类的平均值,并作为新的中心点
4 重复2-3,直到这k个中线点不再变化(收敛了),或执行了足够多的迭代
时间复杂度:O(I*n*k*m)
空间复杂度:O(n*m)
其中m为每个元素字段个数,n为数据量,I为跌打个数。一般I,k,m均可认为是常量,所以时间和空间复杂度可以简化为O(n),即线性的。
算法收敛
从kmeans的算法可以发现,SSE其实是一个严格的坐标下降(Coordinate Decendet)过程。设目标函数SSE如下:
SSE( ,
, ,…,
,…, ) =
) = 
采用欧式距离作为变量之间的聚类函数。每次朝一个变量 的方向找到最优解,也就是求偏倒数,然后等于0,可得
的方向找到最优解,也就是求偏倒数,然后等于0,可得
c_i= 其中m是c_i所在的簇的元素的个数
其中m是c_i所在的簇的元素的个数
也就是当前聚类的均值就是当前方向的最优解(最小值),这与kmeans的每一次迭代过程一样。所以,这样保证SSE每一次迭代时,都会减小,最终使SSE收敛。
由于SSE是一个非凸函数(non-convex function),所以SSE不能保证找到全局最优解,只能确保局部最优解。但是可以重复执行几次kmeans,选取SSE最小的一次作为最终的聚类结果。
0-1规格化
由于数据之间量纲的不相同,不方便比较。举个例子,比如游戏用户的在线时长和活跃天数,前者单位是秒,数值一般都是几千,而后者单位是天,数值一般在个位或十位,如果用这两个变量来表征用户的活跃情况,显然活跃天数的作用基本上可以忽略。所以,需要将数据统一放到0~1的范围,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。具体计算方法如下:

其中 属于A。
属于A。
轮廓系数
轮廓系数(Silhouette Coefficient)结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果。该值处于-1~1之间,值越大,表示聚类效果越好。具体计算方法如下:
- 对于第i个元素x_i,计算x_i与其同一个簇内的所有其他元素距离的平均值,记作a_i,用于量化簇内的凝聚度。
- 选取x_i外的一个簇b,计算x_i与b中所有点的平均距离,遍历所有其他簇,找到最近的这个平均距离,记作b_i,用于量化簇之间分离度。
- 对于元素x_i,轮廓系数s_i = (b_i – a_i)/max(a_i,b_i)
- 计算所有x的轮廓系数,求出平均值即为当前聚类的整体轮廓系数
从上面的公式,不难发现若s_i小于0,说明x_i与其簇内元素的平均距离小于最近的其他簇,表示聚类效果不好。如果a_i趋于0,或者b_i足够大,那么s_i趋近与1,说明聚类效果比较好。
K值选取
在实际应用中,由于Kmean一般作为数据预处理,或者用于辅助分类贴标签。所以k一般不会设置很大。可以通过枚举,令k从2到一个固定值如10,在每个k值上重复运行数次kmeans(避免局部最优解),并计算当前k的平均轮廓系数,最后选取轮廓系数最大的值对应的k作为最终的集群数目。
实际应用
下面通过例子(R实现,完整代码见附件)讲解kmeans使用方法,会将上面提到的内容全部串起来
|
1
2
3
|
library(fpc) # install.packages("fpc")data(iris)head(iris) |
加载实验数据iris,这个数据在机器学习领域使用比较频繁,主要是通过画的几个部分的大小,对花的品种分类,实验中需要使用fpc库估计轮廓系数,如果没有可以通过install.packages安装。
|
1
2
3
4
5
6
7
8
9
|
# 0-1 正规化数据min.max.norm <- function(x){ (x-min(x))/(max(x)-min(x))}raw.data <- iris[,1:4]norm.data <- data.frame(sl = min.max.norm(raw.data[,1]), sw = min.max.norm(raw.data[,2]), pl = min.max.norm(raw.data[,3]), pw = min.max.norm(raw.data[,4])) |
对iris的4个feature做数据正规化,每个feature均是花的某个不为的尺寸。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# k取2到8,评估KK <- 2:8round <- 30 # 每次迭代30次,避免局部最优rst <- sapply(K, function(i){ print(paste("K=",i)) mean(sapply(1:round,function(r){ print(paste("Round",r)) result <- kmeans(norm.data, i) stats <- cluster.stats(dist(norm.data), result$cluster) stats$avg.silwidth }))})plot(K,rst,type='l',main='轮廓系数与K的关系', ylab='轮廓系数') |
评估k,由于一般K不会太大,太大了也不易于理解,所以遍历K为2到8。由于kmeans具有一定随机性,并不是每次都收敛到全局最小,所以针对每一个k值,重复执行30次,取并计算轮廓系数,最终取平均作为最终评价标准,可以看到如下的示意图,

当k取2时,有最大的轮廓系数,虽然实际上有3个种类。
|
1
2
3
4
5
6
7
8
|
# 降纬度观察old.par <- par(mfrow = c(1,2))k = 2 # 根据上面的评估 k=2最优clu <- kmeans(norm.data,k)mds = cmdscale(dist(norm.data,method="euclidean"))plot(mds, col=clu$cluster, main='kmeans聚类 k=2', pch = 19)plot(mds, col=iris$Species, main='原始聚类', pch = 19)par(old.par) |
聚类完成后,有源原始数据是4纬,无法可视化,所以通过多维定标(Multidimensional scaling)将纬度将至2为,查看聚类效果,如下

可以发现原始分类中和聚类中左边那一簇的效果还是拟合的很好的,右测原始数据就连在一起,kmeans无法很好的区分,需要寻求其他方法。
kmeans最佳实践
1. 随机选取训练数据中的k个点作为起始点
2. 当k值选定后,随机计算n次,取得到最小开销函数值的k作为最终聚类结果,避免随机引起的局部最优解
3. 手肘法选取k值:绘制出k--开销函数闪点图,看到有明显拐点(如下)的地方,设为k值,可以结合轮廓系数。
4. k值有时候需要根据应用场景选取,而不能完全的依据评估参数选取。

参考
[2] 坐标下降法(Coordinate Decendent)
[3] 数据规格化
[4] 维基百科--轮廓系数
[5] kmeans算法介绍
[6] 降为方法—多维定标
[7] Week 8 in Machine Learning, by Andrew NG, Coursera
K-means聚类算法
K-means也是聚类算法中最简单的一种了,但是里面包含的思想却是不一般。最早我使用并实现这个算法是在学习韩爷爷那本数据挖掘的书中,那本书比较注重应用。看了Andrew Ng的这个讲义后才有些明白K-means后面包含的EM思想。
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x,比如假设宇宙中的星星可以表示成三维空间中的点集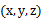 。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
在聚类问题中,给我们的训练样本是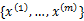 ,每个
,每个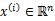 ,没有了y。
,没有了y。
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
|
1、 随机选取k个聚类质心点(cluster centroids)为 2、 重复下面过程直到收敛 { 对于每一个样例i,计算其应该属于的类
对于每一个类j,重新计算该类的质心
} |
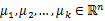 。
。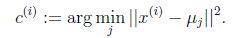
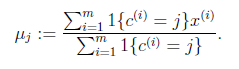
K是我们事先给定的聚类数, 代表样例i与k个类中距离最近的那个类,
代表样例i与k个类中距离最近的那个类, 的值是1到k中的一个。质心
的值是1到k中的一个。质心 代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为
代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为 ,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心
,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心 (对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
下图展示了对n个样本点进行K-means聚类的效果,这里k取2。

K-means面对的第一个问题是如何保证收敛,前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数(distortion function)如下:

J函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当前J没有达到最小值,那么首先可以固定每个类的质心 ,调整每个样例的所属的类别
,调整每个样例的所属的类别 来让J函数减少,同样,固定
来让J函数减少,同样,固定 ,调整每个类的质心
,调整每个类的质心 也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,
也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时, 和c也同时收敛。(在理论上,可以有多组不同的
和c也同时收敛。(在理论上,可以有多组不同的 和c值能够使得J取得最小值,但这种现象实际上很少见)。
和c值能够使得J取得最小值,但这种现象实际上很少见)。
由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的 和c输出。
和c输出。
下面累述一下K-means与EM的关系,首先回到初始问题,我们目的是将样本分成k个类,其实说白了就是求每个样例x的隐含类别y,然后利用隐含类别将x归类。由于我们事先不知道类别y,那么我们首先可以对每个样例假定一个y吧,但是怎么知道假定的对不对呢?怎么评价假定的好不好呢?我们使用样本的极大似然估计来度量,这里是就是x和y的联合分布P(x,y)了。如果找到的y能够使P(x,y)最大,那么我们找到的y就是样例x的最佳类别了,x顺手就聚类了。但是我们第一次指定的y不一定会让P(x,y)最大,而且P(x,y)还依赖于其他未知参数,当然在给定y的情况下,我们可以调整其他参数让P(x,y)最大。但是调整完参数后,我们发现有更好的y可以指定,那么我们重新指定y,然后再计算P(x,y)最大时的参数,反复迭代直至没有更好的y可以指定。
这个过程有几个难点,第一怎么假定y?是每个样例硬指派一个y还是不同的y有不同的概率,概率如何度量。第二如何估计P(x,y),P(x,y)还可能依赖很多其他参数,如何调整里面的参数让P(x,y)最大。这些问题在以后的篇章里回答。
这里只是指出EM的思想,E步就是估计隐含类别y的期望值,M步调整其他参数使得在给定类别y的情况下,极大似然估计P(x,y)能够达到极大值。然后在其他参数确定的情况下,重新估计y,周而复始,直至收敛。
上面的阐述有点费解,对应于K-means来说就是我们一开始不知道每个样例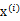 对应隐含变量也就是最佳类别
对应隐含变量也就是最佳类别 。最开始可以随便指定一个
。最开始可以随便指定一个 给它,然后为了让P(x,y)最大(这里是要让J最小),我们求出在给定c情况下,J最小时的
给它,然后为了让P(x,y)最大(这里是要让J最小),我们求出在给定c情况下,J最小时的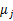 (前面提到的其他未知参数),然而此时发现,可以有更好的
(前面提到的其他未知参数),然而此时发现,可以有更好的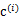 (质心与样例
(质心与样例 距离最小的类别)指定给样例
距离最小的类别)指定给样例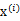 ,那么
,那么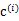 得到重新调整,上述过程就开始重复了,直到没有更好的
得到重新调整,上述过程就开始重复了,直到没有更好的 指定。这样从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量
指定。这样从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量 ,M步更新其他参数
,M步更新其他参数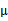 来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
K-Means 算法(转载)的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- K-means算法
K-means算法很简单,它属于无监督学习算法中的聚类算法中的一种方法吧,利用欧式距离进行聚合啦. 解决的问题如图所示哈:有一堆没有标签的训练样本,并且它们可以潜在地分为K类,我们怎么把它们划分呢? ...
- GJM : 数据结构 - 轻松看懂机器学习十大常用算法 [转载]
转载请联系原文作者 需要获得授权,非法转载 原文作者将享受侵权诉讼 文/不会停的蜗牛(简书作者)原文链接:http://www.jianshu.com/p/55a67c12d3e9 通过本篇文章可以 ...
- 用Python从零开始实现K近邻算法
KNN算法的定义: KNN通过测量不同样本的特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.K通 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- 《机器学习实战》学习笔记一K邻近算法
一. K邻近算法思想:存在一个样本数据集合,称为训练样本集,并且每个数据都存在标签,即我们知道样本集中每一数据(这里的数据是一组数据,可以是n维向量)与所属分类的对应关系.输入没有标签的新数据后,将 ...
- [Machine-Learning] K临近算法-简单例子
k-临近算法 算法步骤 k 临近算法的伪代码,对位置类别属性的数据集中的每个点依次执行以下操作: 计算已知类别数据集中的每个点与当前点之间的距离: 按照距离递增次序排序: 选取与当前点距离最小的k个点 ...
- k近邻算法的Java实现
k近邻算法是机器学习算法中最简单的算法之一,工作原理是:存在一个样本数据集合,即训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据和所属分类的对应关系.输入没有标签的新数据之后, ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
随机推荐
- 转 如何高效使用和管理Bitmap--图片缓存管理模块的设计与实现
上周为360全景项目引入了图片缓存模块.因为是在Android4.0平台以上运作,出于惯性,都会在设计之前查阅相关资料,尽量避免拿一些以前2.3平台积累的经验来进行类比处理.开发文档中有一个 Bitm ...
- poj 3628 Bookshelf 2 基本01背包
题目大意:FJ有n头奶牛,和一个高为h的架子,给出每头奶牛高度,求使奶牛叠加起来超过架子的最低高度是多少. 题目思路:求出奶牛叠加能达到的所有高度,并用dp[]保存,最后进行遍历,找出与h差最小的dp ...
- UITabBar 蓝色
效果图1: 第一种解决办法(有局限性): 但是,但是!!!!!虽然不用写代码看起来好方便,在iOS9和8上貌似都没问题.然后我默默地 拿出了自己的小4,发现还似蓝色... 第二种解决办法:(彻底): ...
- 计算n!的位数<Math>
题意:如题目. 方法一:<TLE> * 可设想n!的结果是不大于10的M次幂的数,即n!<=10^M(10的M次方),则不小于M的最小整数就是 n!的位数,对 * 该式两边取对数,有 ...
- HTML 引用Css样式的四种方式
不才,只知道HTML引用CSS样式有四种方式,内部引用和外部引用各两种,因为老是忘记细节,记下了随时翻阅亦可方便如我般的初学者 内部引用方式1: 直接在标签内用 style 引用,如: <div ...
- Spring 笔记1
1.在java开发领域,Spring相对于EJB来说是一种轻量级的,非侵入性的Java开发框架,曾经有两本很畅销的书<Expert one-on-one J2EE Design and Deve ...
- Python之路: 模版篇
模块 随着python越来越强大,相同的代码也在不段复杂.为了能够更好更方便的维护,人们越来越愿意把很多写出来的功能函数保存在不同的文件夹中,这样在用的时候调用,不用的时候可以忽略.这就是模块的由 ...
- Android 之 ServiceManager与服务管理
ServiceMananger是android中比较重要的一个进程,它是在init进程启动之后启动,从名字上就可以看出来它是用来管理系统中的service.比如:InputMethodService. ...
- andorid之摄像头驱动流程--MTK平台
原文地址:andorid之摄像头驱动流程--MTK平台 作者:守候心田 camera成像原理: 景物通过镜头生产光学图像投射到sensor表面上,然后转为模拟电信号,经过数模变成数字图像信号,在经过D ...
- Openlayers修改矢量要素并且可捕捉
<!DOCTYPE html><html> <head> <meta http-equiv="Content-Type" content= ...