Python--校园网爬虫记
查成绩,算分数,每年的综合测评都是个固定的过程,作为软件开发者,这些过程当然可以交给代码去做,通过脚本进行网络请求获取数据,然后直接进行计算得到基础分直接填表就好了,查成绩再手动计算既容易出错也繁琐,所以本篇的内容就是开发一个爬虫脚本取抓取成绩表,至于综合测评计算,这个没什么意义这里就不说了,分数都有了就都够了。
我们的目的就是通过编写脚本,模仿浏览器进行请求获取源码,再进行解析本地化(或者直接计算)
要抓取到数据,其实方案不止一种,这里会介绍两种不同的方案,达到同样的目的:
- 模仿浏览器进行请求(速度快)
- 操作浏览器进行请求(速度慢)
先说第一种,这种方案是普遍的爬虫技术,因为爬取的内容不多,对速度要求也不够,所以就是很简单的一个爬虫过程:
- 分析请求
- 模仿请求
对于普通的校园网,一般不做流量限制,所以就算请求频繁,也基本不用担心IP被封禁,所以编写爬虫代码可以不用太过担心。先说我所在学校的校园网,是杭州方正软件公司开发的。
① 分析请求
分析请求很简单,就是使用浏览器进行请求,然后分析每个请求所发送和接收的信息,这里最简单应该是使用chrome的开发者模式(F12打开)

输入用户名和密码,勾选已认真阅读,接着点击登陆,这样右边的网络窗口中会检查到所有的网络请求,我们只需要找到对应登陆的一个(这里会带有表单):

这个时候,我们可以通过一些测试工具,尝试进行请求对应的这个地址,并且把表单提交上去试试登陆能否成功,如果成功的话,脚本也就可以模拟这个请求,这里用的是chrome商店的一个工具Postman,用法很简单:

登陆成功之后,我们再进行查询成绩:

这里可以看到这次得到了两个新的请求(上图红框的前两个)
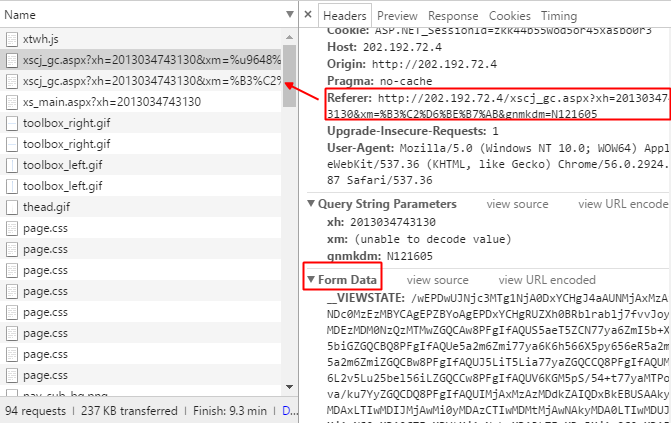
仔细观察会发现,第一个请求头中的Referer指向的是第二个请求的地址,所以可以知道,第二个请求是先于第一个请求发送的。其次,我们发现这个请求中也有表单。
再看第二个请求:

它的Referer指向第三个请求,而这个第三个请求实际上登陆成功之后,就已经存在了,它就是请求到主界面的,而这个请求的类型是Get,所以也表明,第三个请求没有传递任何信息给这个请求。
整理可以知道,流程是这样的:
登陆成功后跳转:http://202.192.72.4/xs_main.aspx?xh=2013034743130
点击查询成绩按钮请求:http://202.192.72.4/xscj_gc.aspx?xh=2013034743130&xm=%B3%C2%D6%BE%B7%AB&gnmkdm=N121605 (Get)
点击查询在校成绩请求:http://202.192.72.4/xscj_gc.aspx?xh=2013034743130&xm=%u9648%u5fd7%u5e06&gnmkdm=N121605 (Post)
所以,我们先来模拟第二个,这个请求是Get类型,所以直接请求即可,但是会发现请求会失败,原因是服务器不能知道我们已经进行登陆了:

所以最先想到的办法是带上第一个请求得到的Cookie,但是也是不行,这个时候要用到上面说的Referer标识,这个标识会告诉服务器请求来源,因为登陆成功会在服务器进行登记,这个标记会让服务器知道请求来源于登陆成功的账号:

此时请求返回正常,我们在源码中可以发现有两个隐藏的<input>标签:


这两个标签传递的,其实是第三个请求的参数,这个时候,模拟第三个请求,并且添加对应的Referer(第二个请求的URL),会发现请求也成功了:
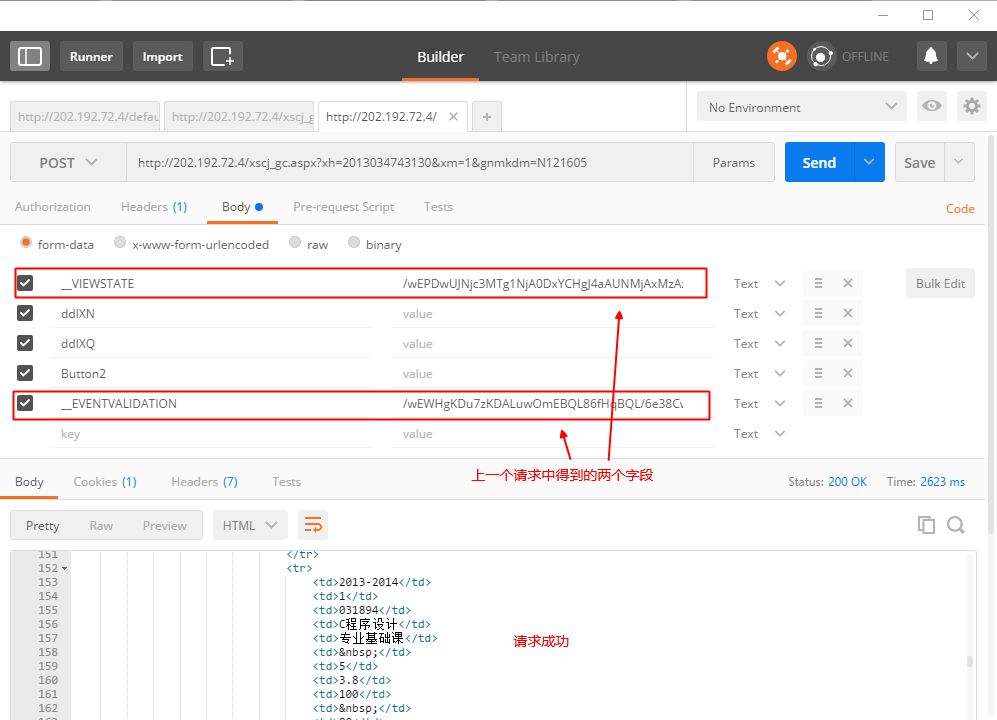
这个请求中的url中的一个参数xm被我更改为1了,原本使用的是一种unicode加密编码,把用户名编码过去了,但是实际上这个参数并没有实际意义,%u的格式会破坏Python程序,所以这里直接改成1了。
② 模仿请求
请求分析完毕,就可以开始写代码了:
用到的包:
import requests, xlwt, os
from bs4 import BeautifulSoup
登录:
def login(s, number, password):
print '正在登录账号:'+number
url = 'http://202.192.72.4/default_gdsf.aspx'
data = {'__EVENTTARGET': 'btnDL',
'TextBox1': number,
'TextBox2': password,
'__VIEWSTATE': '/wEPDwULLTExNzc4NDAyMTBkGAEFHl9fQ29udHJvbHNSZXF1aXJlUG9zdEJhY2tLZXlfXxYBBQVjaGtZRIgvS19wi/UKxQv2qDEuCtWOjJdl',
'chkYD': 'on',
'__EVENTVALIDATION': '/wEWCgKFvrvOBQLs0bLrBgLs0fbZDAK/wuqQDgKAqenNDQLN7c0VAuaMg+INAveMotMNAuSStccFAvrX56AClqUwdU9ySl1Lo85TvdUwz0GrJgI='}
s.post(url, data)
return s.cookies
登录操作没有给后面的请求传递任何参数,这里的Cookies不是必须的,但是登录是必须的,这样告诉服务器我们后面的请求才是合法的。
点击查询成绩按钮:
def get_data_for_grade(s, number, password):
url = 'http://202.192.72.4/xscj_gc.aspx?xh=' + number + '&xm=%B3%C2%D6%BE%B7%AB&gnmkdm=N121605'
referer = 'http://202.192.72.4/xs_main.aspx?xh=' + number
cookies = login(s, number, password)
response = s.get(url=url, headers={'Referer': referer}, allow_redirects=False, cookies=cookies)
source = response.text
soup = BeautifulSoup(source, 'html.parser')
view_state = soup.find('input', attrs={'id': '__VIEWSTATE'})['value']
event_validation = soup.find('input', attrs={'id': '__EVENTVALIDATION'})['value']
states = {'view_state': view_state, 'event_validation': event_validation, 'cookies': cookies, 'origin': url}
return states
第五行队请求设置Referer,接着通过BeautifulSoup解析源码得到两个隐藏的<input>标签里面value值,第三个请求要用到。
查询所有成绩请求:
def check_info(s, number, password):
url = 'http://202.192.72.4/xscj_gc.aspx?xh=' + number + '&xm=1&gnmkdm=N121605'
states = get_data_for_grade(s, number, password)
print '登录成功,正在拉取成绩'
data = {
'__VIEWSTATE': states['view_state'],
'ddlXN': '',
'ddlXQ': '',
'Button2': '',
'__EVENTVALIDATION': states['event_validation']
}
response = s.post(url, data=data, cookies=states['cookies'], headers={'Referer': states['origin']},
allow_redirects=False)
return response.text
得到成绩单源码之后,就可以进行解析了,这里解析存放到xls表格中:
def writeToFile(source):
print '正在写入文档'
wb = xlwt.Workbook(encoding='utf-8', style_compression=0)
soup = BeautifulSoup(source, "html.parser")
span = soup.find('span', attrs={'id': 'Label5'})
sheet = wb.add_sheet('成绩单', cell_overwrite_ok=True)
table = soup.find(attrs={'id': 'Datagrid1'})
lines = table.find_all('tr')
for i in range(len(lines)):
tds = lines[i].find_all('td')
for j in range(len(tds)):
sheet.write(i, j, tds[j].text)
try:
os.remove(span.text + '.xls')
except:
pass
wb.save(span.text + '.xls')
最后遍历学号进行爬取,这里只爬取默认账号密码的成绩:
for i in range(1, 55):
num = ''
s = requests.session()
try:
if i <= 9:
writeToFile(check_info(s, num[:12] + str(i), num[:12] + str(i)))
else:
writeToFile(check_info(s, num[:11] + str(i), num[:11] + str(i)))
except:
pass
s.close()


第二种方案,是通过模拟浏览器来进行登录,点击按钮等操作获取成绩,这里用到的是自动化测试框架Selenium。
这种方案的优点是我们不需要像第一种那样要去分析请求,只需要告诉浏览器要怎么做就行了,但是缺点是速度慢。
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
from bs4 import BeautifulSoup
import xlwt
import os class Script():
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(10)
# self.driver.maximize_window()
self.base_url = "http://202.192.72.4/"
self.verificationErrors = []
self.accept_next_alert = True def test_jb(self, num):
driver = self.driver
driver.get(self.base_url + "/default_gdsf.aspx")
driver.find_element_by_id("TextBox1").clear()
driver.find_element_by_id("TextBox1").send_keys(num)
driver.find_element_by_id("TextBox2").clear()
driver.find_element_by_id("TextBox2").send_keys(num)
driver.find_element_by_id("chkYD").click()
driver.find_element_by_id("btnDL").click()
WebDriverWait(driver, 5).until(EC.alert_is_present()).accept()
self.open_and_click_menu(driver)
retry = 0
while retry <= 2:
try:
driver.switch_to.frame(driver.find_element_by_id('iframeautoheight'))
WebDriverWait(driver, 5).until(EC.visibility_of_element_located((By.XPATH, "//input[@id='Button2']")))
break
except:
print '重新点击按钮'
driver.switch_to.parent_frame()
self.open_and_click_menu(driver)
retry += 1
else:
print '重试失败' source = driver.page_source
driver.find_element_by_xpath("//input[@id='Button2']").click() def source_change(driver):
if source == driver.page_source:
return False
else:
return driver.page_source self.writeToFile(WebDriverWait(driver, 10).until(source_change))
driver.quit() def open_and_click_menu(self, driver):
menu1 = WebDriverWait(driver, 5).until(EC.visibility_of_element_located((By.XPATH, "//ul[@class='nav']/li[5]")))
menu2 = driver.find_element_by_xpath("//ul[@class='nav']/li[5]/ul/li[3]")
ActionChains(driver).move_to_element(menu1).move_to_element(menu2).click(menu2).perform() def is_element_present(self, how, what):
try:
self.driver.find_element(by=how, value=what)
except NoSuchElementException as e:
return False
return True def is_alert_present(self):
try:
self.driver.switch_to_alert()
except NoAlertPresentException as e:
return False
return True def close_alert_and_get_its_text(self):
try:
alert = self.driver.switch_to_alert()
alert_text = alert.text
if self.accept_next_alert:
alert.accept()
else:
alert.dismiss()
return alert_text
finally:
self.accept_next_alert = True def tearDown(self):
self.driver.quit()
self.assertEqual([], self.verificationErrors) @staticmethod
def writeToFile(source):
wb = xlwt.Workbook(encoding='utf-8', style_compression=0)
soup = BeautifulSoup(source, "html.parser")
span = soup.find('span', attrs={'id': 'Label5'})
sheet = wb.add_sheet('成绩单', cell_overwrite_ok=True)
table = soup.find(attrs={'id': 'Datagrid1'})
lines = table.find_all('tr')
for i in range(len(lines)):
tds = lines[i].find_all('td')
for j in range(len(tds)):
sheet.write(i, j, tds[j].text)
try:
os.remove(span.text + '.xls')
except:
pass
wb.save(span.text + '.xls') if __name__ == "__main__":
# unittest.main()
s = Script() for i in range(1, 50):
num = ''
s.setUp()
try:
if i <= 9:
s.test_jb(num[:12] + str(i))
else:
s.test_jb(num[:11] + str(i))
except:
pass
这种方法的意义只是熟悉一下自动化测试框架,因为速度实在太慢了,也就不详细介绍了,这里粗略说一下,其实原理就是通过查到网页中对应的控件,进行点击或者悬浮于上面等等的操作,一步一步的到达最后的成绩单,要做的是控制整个流程,明确在什么时候应该停一下等控件出现,什么时候要去点击。
而且到目前为止,这个框架还是有一些Bug的,比如火狐浏览器的驱动无法实现在一个按钮上Hover的操作等等。
Python--校园网爬虫记的更多相关文章
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- python分布式爬虫打造搜索引擎--------scrapy实现
最近在网上学习一门关于scrapy爬虫的课程,觉得还不错,以下是目录还在更新中,我觉得有必要好好的做下笔记,研究研究. 第1章 课程介绍 1-1 python分布式爬虫打造搜索引擎简介 07:23 第 ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- [Python] 网络爬虫和正则表达式学习总结
以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset.beachmark等等.但是,对于实际的工业需求来说,爬取网络的数据是必须的并且是首要的.最近在国内一家互联网公司实习, ...
- python简易爬虫来实现自动图片下载
菜鸟新人刚刚入住博客园,先发个之前写的简易爬虫的实现吧,水平有限请轻喷. 估计利用python实现爬虫的程序网上已经有太多了,不过新人用来练手学习python确实是个不错的选择.本人借鉴网上的部分实现 ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
随机推荐
- CSS3-----图片翻页效果的展示
在开发一个网站的过程中各种翻页效果数不胜数,在这里我将介绍一下简单的一种方法就是使用css3的旋转即可实现这种常见的效果: 显示效果如下: 首先是页面的布局,不用那么复杂; a标签的href属性,一般 ...
- HTTP协议系列(3)---包括WebSocket简单介绍
一.HTTPS HTTP是超文本传输协议,那HTTPS是什么尼?要明白HTTPS是什么先要明白HTTP的缺点,想一下我们在使用HTTP的时候会有那些缺点尼? 1.通信使用的明文(不加密),内容 ...
- python练习_购物车(简版)
python练习_购物车(简版) 需求: 写一个python购物车可以输入用户初始化金额 可以打印商品,且用户输入编号,即可购买商品 购物时计算用户余额,是否可以购买物品 退出结算时打印购物小票 以下 ...
- 蓝桥杯java试题《洗牌》
问题描述 小弱T在闲暇的时候会和室友打扑克,输的人就要负责洗牌.虽然小弱T不怎么会洗牌,但是他却总是输. 渐渐地小弱T发现了一个规律:只要自己洗牌,自己就一定会输.所以小弱T认为自己洗牌不够均匀,就独 ...
- 关于Coursera上的斯坦福机器学习课程的编程作业提交问题
学习Coursera上的斯坦福机器学习课程的时候,需要向其服务器提交编程作业,我遇到如下问题: 'Submission failed: unexpected error: urlread: Peer ...
- We Chall-Training: LSB-Writeup
MarkdownPad Document html,body,div,span,applet,object,iframe,h1,h2,h3,h4,h5,h6,p,blockquote,pre,a,ab ...
- Exiting the Matrix: Introducing Metasploit's Hardware Bridge
Metasploit is an amazing tool. You can use it to maneuver through vast networks, pivoting through se ...
- Python学习--17 进程和线程
线程是最小的执行单元,而进程由至少一个线程组成.如何调度进程和线程,完全由操作系统决定,程序自己不能决定什么时候执行,执行多长时间. 进程 fork调用 通过fork()系统调用,就可以生成一个子进程 ...
- 读书笔记 effective c++ Item 5 了解c++默认生成并调用的函数
1 编译器会默认生成哪些函数 什么时候空类不再是一个空类?答案是用c++处理的空类.如果你自己不声明,编译器会为你声明它们自己版本的拷贝构造函数,拷贝赋值运算符和析构函数,如果你一个构造函数都没有声 ...
- Jenkins的安装与系统配置
Jenkins的安装 Jenkins的安装需要一个安装包:http://pan.baidu.com/s/1hqQBruc,也可以去Jenkins官网上下载,Jenkins的官网地址 http://Je ...