【Machine Learning in Action --2】K-近邻算法改进约会网站的配对效果
摘自:《机器学习实战》,用python编写的(需要matplotlib和numpy库)
海伦一直使用在线约会网站寻找合适自己的约会对象。尽管约会网站会推荐不同的人选,但她没有从中找到喜欢的人。经过一番总结,她发现曾交往过三种类型的人:
1.不喜欢的人( 以下简称1 );
2.魅力一般的人( 以下简称2 );
3.极具魅力的人(以下简称3 )
尽管发现了上述规律,但海伦依然无法将约会网站推荐的匹配对象归入恰当的分类。她觉得可以在周一到周五约会哪些魅力一般的人,而周末则更喜欢与那些极具魅力的人为伴。海伦希望我们的分类软件可以更好的帮助她将匹配对象划分到确切的分类中。此外海伦还收集了一些约会网站未曾记录的数据信息,她认为这些数据更有助于匹配对象的归类。
我们先提取一下这个案例的目标:根据一些数据信息,对指定人选进行分类(1或2或3)。为了使用kNN算法达到这个目标,我们需要哪些信息?前面提到过,就是需要样本数据,仔细阅读我们发现,这些样本数据就是“ 海伦还收集了一些约会网站未曾记录的数据信息 ”。好的,下面我们就开始吧!
----1.收集数据
海伦收集的数据是记录一个人的三个特征:每年获得的飞行常客里程数;玩视频游戏所消耗的时间百分比;每周消费的冰淇淋公升数。数据是txt格式文件,如下图,前三列依次是三个特征,第四列是分类(1:不喜欢的人,2:魅力一般的人,3:极具魅力的人),每一行代表一个人。
---- 2.准备数据:从文本文件中解析数据
何为准备数据?之前收集到了数据,放到了txt格式的文档中了,看起来也比较规整,但是计算机并不认识啊。计算机需要从txt文档中读取数据,并把数据进行格式化,也就是说存到矩阵中,用矩阵来承装这些数据,这样才能使用计算机处理。
需要两个矩阵:一个承装三个特征数据,一个承装对应的分类。于是,我们定义一个函数,函数的输入时数据文档(txt格式),输出为两个矩阵。
代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from numpy import * #引入科学计算包numpy
import operator #经典python函数库,运算符模块 def file2matrix(filename):
fr=open(filename)
arrayOLines=fr.readlines()
numberOfLines=len(arrayOLines)
returnMat=zeros((numberOfLines,3))
classLabelVector=[]
index=0
for line in arrayOLines:
line=line.strip()
listFromLine=line.split('\t')
returnMat[index,:]=listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index+=1
return returnMat,classLabelVector
简要解读代码:首先打开文件,读取文件的行数,然后初始化之后要返回的两个矩阵(returnMat、classLabelsVector),然后进入循环,将每行的数据各就各位分配给returnMat和classLabelsVector。
在python命令提示符下面输入以下命令:
>>> import kNN
>>> reload(kNN)
>>> datingDataMat,datingLabels=kNN.file2matrix('datingTestSet2.txt')
>>> datingDataMat
array([[ 4.09200000e+04, 8.32697600e+00, 9.53952000e-01],
[ 1.44880000e+04, 7.15346900e+00, 1.67390400e+00],
[ 2.60520000e+04, 1.44187100e+00, 8.05124000e-01],
...,
[ 2.65750000e+04, 1.06501020e+01, 8.66627000e-01],
[ 4.81110000e+04, 9.13452800e+00, 7.28045000e-01],
[ 4.37570000e+04, 7.88260100e+00, 1.33244600e+00]])
>>> datingLabels[0:20]
[3, 2, 1, 1, 1, 1, 3, 3, 1, 3, 1, 1, 2, 1, 1, 1, 1, 1, 2, 3]
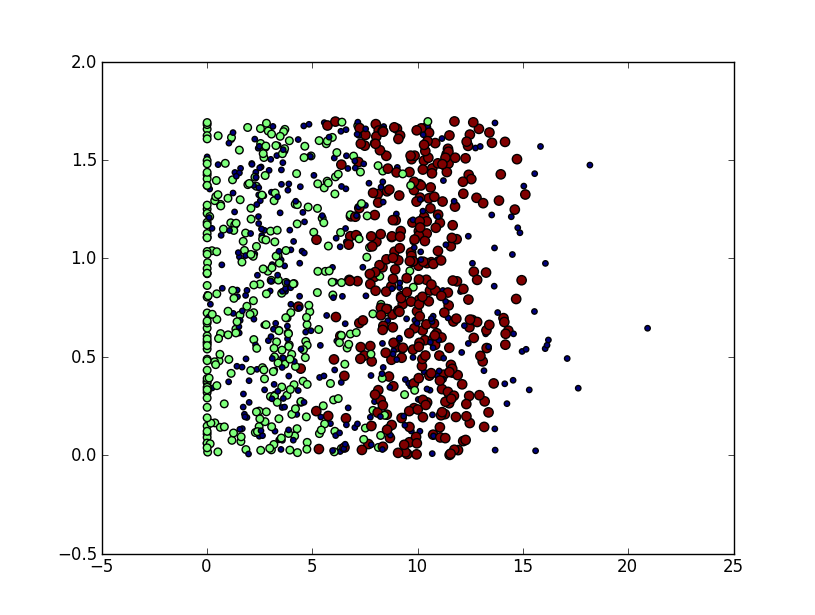
----3.分析数据:使用Matplotlib创建散点图
Matplotlib库提供的scatter函数支持个性化标记散点图上的点。散点图使用了datingDataMat矩阵的第二、三列数据,分别表示特征值“玩视频游戏所耗时间百分比”和“每周所消耗的冰淇淋公升数”。
>>> import matplotlib
>>> import kNN
>>> datingDataMat,datingLabels=kNN.file2matrix('datingTestSet2.txt')
>>> import matplotlib >>> import matplotlib.pyplot as plt
>>> fig=plt.figure()
>>> ax=fig.add_subplot(111)
>>>ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))
<matplotlib.collections.PathCollection object at 0x03C85C70>
>>> plt.show()
----4.设计算法:用kNN算法
k-近邻算法的目的就是找到新数据的前k个邻居,然后根据邻居的分类来确定该数据的分类。
首先要解决的问题,就是什么是邻居?当然就是“距离”近的了,不同人的距离怎么确定?这个有点抽象,不过我们有每个人的3个特征数据。每个人可以使用这三个特征数据来代替这个人——三维点。比如样本的第一个人就可以用(40920, 8.326976, 0.953952)来代替,并且他的分类是3。那么此时的距离就是点的距离:
A点(x1, x2, x3),B点(y1, y2, y3),这两个点的距离就是:(x1-y1)^2+(x2-y2)^2+(x3-y3)^2的平方根。求出新数据与样本中每个点的距离,然后进行从小到大排序,前k位的就是k-近邻,然后看看这k位近邻中占得最多的分类是什么,也就获得了最终的答案。
这个处理过程也是放到一个函数里的,代码如下:
#inX:用户分类的输入向量,即将对其进行分类
#dataSet:训练样本集
#labels:标签向量 def classifyO(inX,dataSet,labels,k):
#距离计算
dataSetSize=dataSet.shape[0] #得到数组的行数,即知道有几个训练数据
diffMat=tile(inX,(dataSetSize,1))-dataSet #tile是numpy中的函数,tile将原来的一个数组,扩充成了4个一样的数组;diffMat得到目标与训练数值之间的差值
sqDiffMat=diffMat**2 #各个元素分别平方
sqDistances=sqDiffMat.sum(axis=1)
distances=sqDistances**0.5 #开方,得到距离
sortedDistIndicies=distances.argsort() #升序排列
#选择距离最小的k个点
classCount={}
for i in range(k):
voteIlabel=labels[sortedDistIndicies[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
#排序
sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
简要解读代码:该函数的4个参数分别为新数据的三个特征inX、样本数据特征集(上一个函数的返回值)、样本数据分类(上一个函数的返回值)、k,函数返回位新数据的分类。第二行dataSetSize获取特征集矩阵的行数,第三行为新数据与样本各个数据的差值,第四行取差值去平方,之后就是再取和,然后平方根。代码中使用的排序函数都是python自带的。
好了,现在我们可以分析数据了,不过,有一点不知道大家有没有注意,我们回到那个数据集,第一列代表的特征数值远远大于其他两项特征,这样在求距离的公式中就会占很大的比重,致使两点的距离很大程度上取决于这个特征,这当然是不公平的,我们需要的三个特征都均平地决定距离,所以我们要对数据进行处理, 希望处理之后既不影响相对大小又可以不失公平 :
这种方法叫做,归一化数值,通过这种方法可以把每一列的取值范围划到0~1或-1~1:,处理的公式为:
newValue = (oldValue - min)/(max - min)
归一化数值的函数代码为:
def autoNorm(dataSet):
minVals=dataSet.min(0)
maxVals=dataSet.max(0)
ranges=maxVals-minVals
normDataSet=zeros(shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet-tile(minVals,(m,1))
normDataSet=normDataSet/tile(ranges,(m,1))
return normDataSet,ranges,minVals
在python命令提示符下,重新加载kNN.py模块,执行autoNorm函数,检测函数的执行结果:
>>>import kNN
>>>reload(kNN)
>>> normMat,ranges,minVals=kNN.autoNorm(datingDataMat)
>>> normMat
array([[ 0.44832535, 0.39805139, 0.56233353],
[ 0.15873259, 0.34195467, 0.98724416],
[ 0.28542943, 0.06892523, 0.47449629],
...,
[ 0.29115949, 0.50910294, 0.51079493],
[ 0.52711097, 0.43665451, 0.4290048 ],
[ 0.47940793, 0.3768091 , 0.78571804]])
>>> ranges
array([ 9.12730000e+04, 2.09193490e+01, 1.69436100e+00])
>>> minVals
array([ 0. , 0. , 0.001156])
---5.测试算法:作为完整程序验证分类器
经过了格式化数据、归一化数值,同时我们也已经完成kNN核心算法的函数,现在可以测试了,测试代码为:
def datingClassTest():
hoRatio=0.10
datingDataMat,datingLabels=file2matrix('datingTestSet.txt')
normMat,ranges,minVals=autoNorm(datingDataMat)
m=normMat.shape[0]
numTestVecs=int(m*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult=classifyO(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with:%d,the real answer is :%d" %(classifierResult,datingLabels[i])
if(classifierResult !=datingLabels[i]):errorCount+=1.0
print "the total error rate is: %f"%(errorCount/float(numTestVecs))
通过测试代码我们可以在回忆一下这个例子的整体过程:
- 读取txt文件,提取里面的数据到datingDataMat、datingLabels;
- 归一化数据,得到归一化的数据矩阵;
- 测试数据不止一个,这里需要一个循环,依次对每个测试数据进行分类。
代码中大家可能不太明白hoRatio是什么。注意,这里的测试数据并不是另外一批数据而是之前的数据集里的一部分,这样我们可以把算法得到的结果和原本的分类进行对比,查看算法的准确度。在这里,海伦提供的数据集又1000行,我们把前100行作为测试数据,后900行作为样本数据集,现在大家应该可以明白hoRatio是什么了吧。
在python命令提示符下重新加载kNN.py模块,并输入kNN.datingClassTest(),执行分类器测试程序,我们将得到下面的输出结果:
>>> kNN.datingClassTest()
the classifier came back with:3,the real answer is :3
the classifier came back with:2,the real answer is :2
the classifier came back with:1,the real answer is :1
the classifier came back with:1,the real answer is :1
the classifier came back with:1,the real answer is :1
...
the classifier came back with:3,the real answer is :3
the classifier came back with:2,the real answer is :2
the classifier came back with:1,the real answer is :1
the classifier came back with:3,the real answer is :1
the total error rate is: 0.050000
---6.使用算法:构建完整可用系统
上面我们已经在数据上对分类器进行了测试,现在终于可以使用这个分类器为海伦来对人们分类。我们会给海伦一小段程序,通过改程序海伦会在约会网站上找到某个人并输入他的信息。程序会给出她对对方喜欢程度的预测值。
将下列代码加入到kNN.py并重新加载kNN.
def classifyPerson():
resultList=['not at all','in small doses','in large doses']
percentTats=float(raw_input("percentage of time apent playing video games?"))
ffMiles=float(raw_input("frequent flier miles earned per year?"))
iceCream=float(raw_input("liters of ice cream consumed per year?"))
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
normMat,ranges,minVals=autoNorm(datingDataMat)
inArr=array([ffMiles,percentTats,iceCream])
classifierResult=classifyO((inArr-minVals)/ranges,normMat,datingLabels,3)
print "You will probably like this person:",resultList[classifierResult-1]
为了解程序的十几运行效果,输入如下命令:
>>> kNN.classifyPerson()
percentage of time apent playing video games?10
frequent flier miles earned per year?10000
liters of ice cream consumed per year?0.5
You will probably like this person: in small doses
总结:
整体的代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from numpy import * #引入科学计算包numpy
import operator #经典python函数库,运算符模块 #算法核心
#inX:用户分类的输入向量,即将对其进行分类
#dataSet:训练样本集
#labels:标签向量
def classifyO(inX,dataSet,labels,k):
#距离计算
dataSetSize=dataSet.shape[0] #得到数组的行数,即知道有几个训练数据
diffMat=tile(inX,(dataSetSize,1))-dataSet #tile是numpy中的函数,tile将原来的一个数组,扩充成了4个一样的数组;diffMat得到目标与训练数值之间的差值
sqDiffMat=diffMat**2 #各个元素分别平方
sqDistances=sqDiffMat.sum(axis=1)
distances=sqDistances**0.5 #开方,得到距离
sortedDistIndicies=distances.argsort() #升序排列
#选择距离最小的k个点
classCount={}
for i in range(k):
voteIlabel=labels[sortedDistIndicies[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
#排序
sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def file2matrix(filename):
fr=open(filename)
arrayOLines=fr.readlines()
numberOfLines=len(arrayOLines)
returnMat=zeros((numberOfLines,3))
classLabelVector=[]
index=0
for line in arrayOLines:
line=line.strip()
listFromLine=line.split('\t')
returnMat[index,:]=listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index+=1
return returnMat,classLabelVector def autoNorm(dataSet):
minVals=dataSet.min(0)
maxVals=dataSet.max(0)
ranges=maxVals-minVals
normDataSet=zeros(shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet-tile(minVals,(m,1))
normDataSet=normDataSet/tile(ranges,(m,1))
return normDataSet,ranges,minVals def datingClassTest():
hoRatio=0.10
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
normMat,ranges,minVals=autoNorm(datingDataMat)
m=normMat.shape[0]
numTestVecs=int(m*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult=classifyO(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with:%d,the real answer is :%d" %(classifierResult,datingLabels[i])
if(classifierResult !=datingLabels[i]):errorCount+=1.0
print "the total error rate is: %f"%(errorCount/float(numTestVecs)) def classifyPerson():
resultList=['not at all','in small doses','in large doses']
percentTats=float(raw_input("percentage of time apent playing video games?"))
ffMiles=float(raw_input("frequent flier miles earned per year?"))
iceCream=float(raw_input("liters of ice cream consumed per year?"))
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
normMat,ranges,minVals=autoNorm(datingDataMat)
inArr=array([ffMiles,percentTats,iceCream])
classifierResult=classifyO((inArr-minVals)/ranges,normMat,datingLabels,3)
print "You will probably like this person:",resultList[classifierResult-1]
运行一下代码:
>>>import kNN
>>> kNN.classifyPerson()
percentage of time apent playing video games?10
frequent flier miles earned per year?10000
liters of ice cream consumed per year?0.5
You will probably like this person: in small doses
最后的错误率为0.05。
【Machine Learning in Action --2】K-近邻算法改进约会网站的配对效果的更多相关文章
- 使用K近邻算法改进约会网站的配对效果
1 定义数据集导入函数 import numpy as np """ 函数说明:打开并解析文件,对数据进行分类:1 代表不喜欢,2 代表魅力一般,3 代表极具魅力 Par ...
- k-近邻(KNN)算法改进约会网站的配对效果[Python]
使用Python实现k-近邻算法的一般流程为: 1.收集数据:提供文本文件 2.准备数据:使用Python解析文本文件,预处理 3.分析数据:可视化处理 4.训练算法:此步骤不适用与k——近邻算法 5 ...
- 使用k-近邻算法改进约会网站的配对效果
---恢复内容开始--- < Machine Learning 机器学习实战>的确是一本学习python,掌握数据相关技能的,不可多得的好书!! 最近邻算法源码如下,给有需要的入门者学习, ...
- 机器学习读书笔记(二)使用k-近邻算法改进约会网站的配对效果
一.背景 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可以进行如下分类 不喜欢的人 魅力一般的人 极具魅 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- KNN算法项目实战——改进约会网站的配对效果
KNN项目实战——改进约会网站的配对效果 1.项目背景: 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可 ...
- k-近邻算法-优化约会网站的配对效果
KNN原理 1. 假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系. 2. 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较. a. 计算新 ...
- kNN分类算法实例1:用kNN改进约会网站的配对效果
目录 实战内容 用sklearn自带库实现kNN算法分类 将内含非数值型的txt文件转化为csv文件 用sns.lmplot绘图反映几个特征之间的关系 参考资料 @ 实战内容 海伦女士一直使用在线约会 ...
- 《机器学习实战》之k-近邻算法(改进约会网站的配对效果)
示例背景: 我的朋友海伦一直使用在线约会网站寻找合适自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现曾交往过三种类型的人: (1)不喜欢的人: (2)魅力一般 ...
随机推荐
- Eight
Eight 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1043/http://acm.split.hdu.edu.cn/showproblem.ph ...
- 大数据时代之hadoop(三):hadoop数据流(生命周期)
了解hadoop,首先就需要先了解hadoop的数据流,就像了解servlet的生命周期似的.hadoop是一个分布式存储(hdfs)和分布式计算框架(mapreduce),但是hadoop也有一个很 ...
- C#的面向对象
一.面向对象编程(OOP)是将现实中的事物抽象花,其设计的重点就是类的设计. 二.类是面向对象编程的设计核心,实际上是一种复杂的数据类型.将不同类型的数据和与这些数据就相关的操作封装在一起,就构成类. ...
- hibernate与spring整合实现transaction
实现transaction时出现了大大小小的问题,这里会一一详解. 先贴出applicationContext.xml <?xml version="1.0" encodin ...
- 网页弹出窗口工具推荐之jqmodal
各种在jquery基础上实现的弹出窗口,有详细的开发说明文档.在项目中快速实现网页中弹出窗口的需求.基本能满足各种弹出窗口的需求 其官方网址如下http://jquery.iceburg.net/jq ...
- C语言 - 大小端问题
目前使用的机器都是使用字节BYTE来存储的. 对于跨越多字节的对象,必须搞清楚两个规则: 这个对象的地址是什么 在存储器中如何按照这些字节的存放的书序 对于一个整型对象 a=0x12345678,一共 ...
- Gentoo/Funtoo USE标记介绍
Gentoo/Funtoo USE标记 USE的简单理解如下:一个软件不只包含软件本身,还包括其组件,如,文档,插件,GUI支持等.USE就是用来标记是否要安装软件的同时安装这些组件. 声明USE标记 ...
- Gentoo安装详解(五)-- 安装X桌面环境
安装X桌面环境: 安装Xorg: 检测显卡信息: dmesg | grep video lspci | grep -i VGA 配置INPUT_DEVICE.VIDEO_CARDS变量: 在安装Xor ...
- Openjudge-计算概论(A)-统计字符数
描述: 判断一个由a-z这26个字符组成的字符串中哪个字符出现的次数最多输入第1行是测试数据的组数n,每组测试数据占1行,是一个由a-z这26个字符组成的字符串每组测试数据之间有一个空行,每行数据不超 ...
- winform实现矩形框截图
使用方法如下: private void button1_Click(object sender, EventArgs e) { s.GerScreenFormRectangle(); } priva ...