flume安装及配置
Flume安装
介绍
Flume本身的安装比较简单(flume的介绍请参考http://blog.csdn.net/rzhzhz/article/details/7448633),安装前先说明几个概念,先看flume的架构
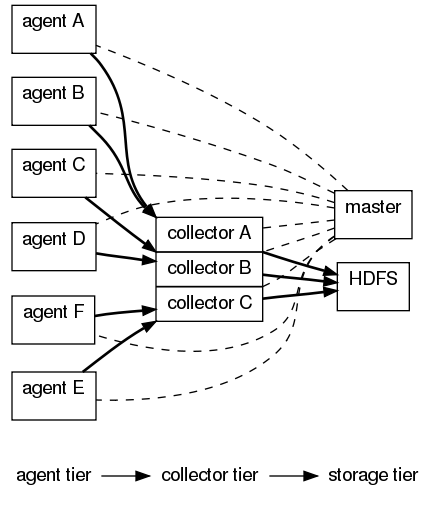
1. Flume分三种角色
Mater: master负责配置及通信管理,是集群的控制器。
Collector: collector用于对数据进行聚合,往往会产生一个更大的流,然后加载到storage中。
Agent: Agent用于采集数据,agent是flume中产生数据流的地方,同时,agent会将产生的数据流传输到collector
2. Collector和Agent的配置数据必须指定Source(可以理解为数据入口)和Sink(可以理解为数据出口)
常用的source如:
text(“filename”):将文件filename作为数据源,按行发送
tail(“filename”):探测filename新产生的数据,按行发送出去
fsyslogTcp(5140):监听TCP的5140端口,并且接收到的数据发送出去
常用的sink如:
console[("format")] :直接将将数据显示在桌面上
text(“txtfile”):将数据写到文件txtfile中
dfs(“dfsfile”):将数据写到HDFS上的dfsfile文件中
syslogTcp(“host”,port):将数据通过TCP传递给host节点
具体介绍可以参考
http://blog.csdn.net/rzhzhz/article/details/7457956
http://blog.csdn.net/rzhzhz/article/details/7449662
安装
1. 下载解压安装
a) Flume的下载地址http://archive.cloudera.com/cdh/3/
b) 这里所说的安装包括jdk,flume本身及zookeeper的安装,这里就不再赘述jdk的安装过程。Zookeeper集群安装请参考http://blog.csdn.net/rzhzhz/article/details/7448894
c) 把下载好的flume包解压到相应位置(flume集群每台机器都需安装),以下以$FLUME_HOME代替安装路径,至于以哪个用户安装按本身实际情况而定。
d) 我们暂且先配置一个master,一个collector,一个agent,主机名对应如下
Mater: master
Collector : collector
Agent : agent
2. 配置相关路径
a) 这里要配置相关路径无非也就是因为flume在启动的时候如果依赖到相关软件(如java,hadoop,zookeeper)时会去其根目录下加载jar包和去conf目录下加载配置文件
b) 我习惯在/etc/profile下配置export,当然你也可以去$FLUME_HOME/bin目录下flume-env.sh配置(由flume-env.sh.template改名而成)
配置大致如下(内容仅供参考,加载过程大家可参考$FLUME_HOME/bin/flume脚本内容)
|
#Java export JAVA_HOME=/usr/java/jdk1.6.0_25 export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin #hadoop export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin #zookeeper export ZOOKEEPER_HOME=/usr/local/zookeeper export PATH=$PATH:$ZOOKEEPER_HOME/bin #flume export FLUME_HOME=/usr/local/flume export FLUME_CONF_DIR=$FLUME_HOME/conf export PATH=$PATH:$FLUME_HOME/bin |
3. 修改配置文件
a) $FLUME_HOME/conf目录下本身有flume-conf.xml和flume-site.xml.template两个文件,flume-conf.xml是默认的配置文件,虽说也可以修改,但不建议修改,用户配置应该在flume-site.xml(由flume-site.xml.template改名而成)文件中(即相当于覆盖flume-conf.xml文件中的原有配置)。flume-site.xml文件应该是针对节点在集群中的不同角色而做不同的修改(详细的配置参数可以参考flume-conf.xml,针对不同角色做了分门别类,一目了然),这里就不具体描述了,可参考http://blog.csdn.net/rzhzhz/article/details/7457956。
b) Collector和Agent的用户配置文件中flume-site.xml必须指定master的地址flume.master.servers,如下:
|
<property> <name>flume.master.servers</name> <value>master</value> </property> |
4. 启动zookeeper集群
a) 这里zookeeper集群会在master的配置文件里配置。
|
<property> <name>flume.master.zk.use.external</name> <value>true</value> </property> <property> <name>flume.master.zk.servers</name> <value>master:2181,collector:2181,agent:2181</value> </property> |
flume.master.zk.use.external 是否使用外部zookeeper集群
flume.master.zk.servers zookeeper集群地址
b) 如果不配置则使用flume内部提供的zookeeper。flume使用使用zookeeper进行管理和负载均衡.
c) 关于zookeeper保存的master的配置数据是可以配置(flume.master.store)的,可以选择存在zookeeper中(zookeeper),也可以选择存储在内存中(memory)
5. 启动master,collector,Agent
a) 启动master: flume master
b) 启动node(collector): flume node_nowatch
c) 启动node(agent): flume node_nowatch
后两者的启动方式是一样的,只是在配置参数中有所差异
启动node的时候可以选择指定node的名字的参数 -n ,默认为主机名
如(flume node_nowatch –n node1)
6. 查看
a) Web查看
Master :
http://master:35871/flumemaster.jsp
可以在master页面查看和配置node参数
node :
http://collector:35862/flumeagent.jsp
http://agent:35862/flumeagent.jsp
单机部署的时候,如果启动了多个node,则端口以此增加(如35863,35864)
b) Shell连接(简略介绍下,更详细的命令请参考help)
flume shell
collect master
7. 在master修改节点配置
a) 这里我们其实可以这样先易后难,不要一开始就弄复杂的配置,这样很难定位错误,还有flume本身的错误基本就是在控制台输出,这与我们的调试思路有点违背,我们一般的查错首先都会想到日志文件,但它的日志文件实在是没什么东西
b) 配置界面大致如下

当然你也可以在shell端配置,此处就不多做介绍。
Web界面配置步骤如下
首先选择configure node选择要选择的node,或者指定不存在于list中的节点(or specify another node)
配置source
配置sink
提交
提交之后可以在master的界面查看是否成功,大致如下图

c) Collector配置
SOURCE: collectorSource(35853)
监听35853端口,接受agent发送的消息
SINK: collectorSink("file:///tmp/flume/collected","sink")
将数据加载到文件中
d) Agent配置
SOURCE: console
从控制台接受输入
SINK: agentE2ESink( "collector",35853 )
指定collector的名字及端口
下面简单介绍一下调试流程
首先我们可以这么配置 先配置最简单的source ,console(控制台输入)
最简单的sink,collectorSink("file:///tmp/flume/collected", "file")
然后看file:///tmp/flume/collected文件目录下是否有控制台输入的内容
调试成功后说明agent与collector是相通的。
再把source换成text或者其他再做调试
最后把sink换成hdfs或者hbase什么的
8. 配置生效(自动),查看结果
略
flume安装及配置的更多相关文章
- Flume简介与使用(一)——Flume安装与配置
Flume简介与使用(一)——Flume安装与配置 Flume简介 Flume是一个分布式的.可靠的.实用的服务——从不同的数据源高效的采集.整合.移动海量数据. 分布式:可以多台机器同时运行采集数据 ...
- CentOS6安装各种大数据软件 第七章:Flume安装与配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- flume安装及配置介绍(二)
注: 环境: skylin-linux Flume的下载方式: wget http://www.apache.org/dyn/closer.lua/flume/1.6.0/apache-flume-1 ...
- Flume 安装和配置
安装步骤 1.安装jdk,1.6版本以上 2.上传flume的安装包 3.解压安装 4.在conf目录下,创建一个配置文件,比如:template.conf(名字可以不固定,后缀也可以不固定) 5.配 ...
- CentOS6安装各种大数据软件 第九章:Hue大数据可视化工具安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Flume的安装与配置
Flume的安装与配置 一. 资源下载 资源地址:http://flume.apache.org/download.html 程序地址:http://apache.fayea.com/fl ...
- 具体说明 Flume介绍、安装和配置
社论: 本文总结"Hadoop生态系统"中的当中一员--Apache Flume 写在前面二: 所用软件说明: 一.什么是Apache Flume 官网:Flume is a di ...
- 3.flume安装以及环境配置
1.安装jdk 我这里已经安装过了,这里就不演示了 2.安装flume 安装cdh版本的,http://archive.cloudera.com/cdh5/cdh/5/ 安装完毕之后,配置环境变量. ...
随机推荐
- 数独 (dfs)
自从2006年3月10日至11日的首届数独世界锦标赛以后,数独这项游戏越来越受到人们的喜爱和重视.据说,在2008北京奥运会上,会将数独列为一个单独的项目进行比赛,冠军将有可能获得的一份巨大的奖品—— ...
- HTML5 Introduction
1. HTML5 History HTML4.01 –1999.12 HTML5 – 2014.10– Done (8 years) In2006, WHATWG&W3C, decide to ...
- 挑逗B少年搞计划10 假设你是愿意用我的心脏层剥离一层~
这些天都非常推迟考试啊.然后,学校已安排一周培训,是的.在延迟学习,大狼医院我真的是正常水平. 幸好我们周六周日不让放假了,不然预计进度直接就停了.这两天也是抽出了时间把敲了一下三层的 ...
- Struts2流程
Struts2流程 1.client浏览器初始化时发出HTTP请求 2.依据web.xml配置,上述请求被FilterDispatcher接收 3.依据struts.xml配置,找到须要调用的Acti ...
- WPF 辅助开发工具
原文:WPF 辅助开发工具 以下介绍的工具均为免费版,有些是源代码开放,希望对大家有用. Kaxaml 轻量级XAML 编辑器,可以同时进行图像和XAML 代码的编辑.最终生成开发人员想要的XAML ...
- WeakReference and WeakHashMap
弱引用通过WeakReference类实现,弱引用和软引用很像,但弱引用的引用级别更低.对于只有弱引用的对象而言,当系统垃圾回收机制运行时,不管系统北村是否足够,总会回收该对象所占用的内存.当然,并不 ...
- 百度地图API 添加自定义标注 多点标注
原文:百度地图API 添加自定义标注 多点标注 分四个文件 location.php map.css 图片 数据库 数据库配置自己改下 -------------------------------- ...
- cocos2dx3.2 推断音效是否播放
SimpleAudioEngine类中增加一函数 例如以下 bool isEffectPlaying(unsigned int nSoundId); 定义例如以下 bool SimpleAudioEn ...
- javascript中类的属性研究
原文:javascript中类的属性研究 本篇文章主要针对javascript的属性进行分析,由于javascript是一种基于对象的语言,本身没有类的概念,所以对于javascript的类的定义有很 ...
- zsh的安装与配置
参考: http://cnbin.github.io/blog/2015/06/01/mac-zsh-an-zhuang-he-shi-yong/ http://www.cnblogs.com/ios ...