[Attention Is All You Need]论文笔记
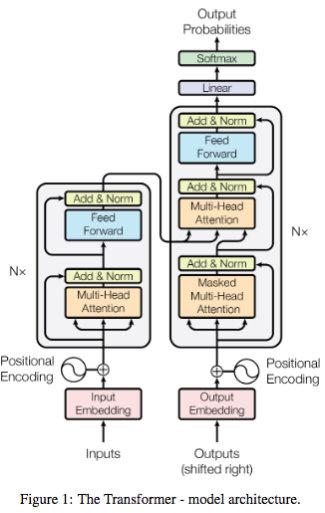
残差网络的优势
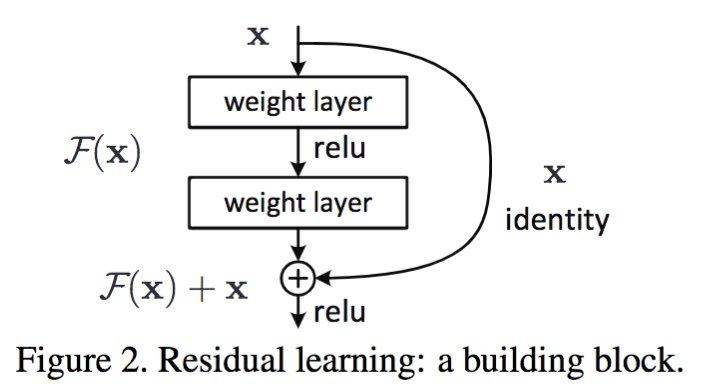
残差网络使用网络学习的是残差,能够解决网络极深度条件下性能退化问题。残差网络论文中提到残差网络不是解决梯度消失和梯度膨胀,残差网络用来解决网络层数加深,在训练集上性能变差的问题。 [为什么可以解决?] 残差网络是多个浅层网络的集成,从x到最后的输出y可以有多个路径,每个路径看作一种模型。[个人理解]
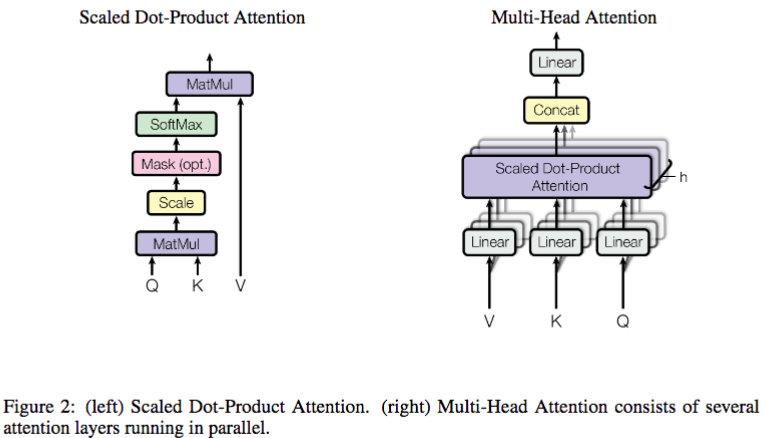
【为什么除以dk?】 假设两个 dk 维向量每个分量都是一个相互独立的服从标准正态分布的随机变量,那么他们的点乘的方差就是 dk,每一个分量除以 sqrt(d_k) 可以让点乘的方差变成 1。



[Attention Is All You Need]论文笔记的更多相关文章
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- 论文笔记:语音情感识别(四)语音特征之声谱图,log梅尔谱,MFCC,deltas
一:原始信号 从音频文件中读取出来的原始语音信号通常称为raw waveform,是一个一维数组,长度是由音频长度和采样率决定,比如采样率Fs为16KHz,表示一秒钟内采样16000个点,这个时候如果 ...
- attention发展历史及其相应论文
这个论文讲述了attention机制的发展历史以及在发展过程的变体-注意力机制(Attention Mechanism)在自然语言处理中的应用 上面那个论文提到attention在CNN中应用,有一个 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
随机推荐
- asp.net之大文件断点续传
ASP.NET上传文件用FileUpLoad就可以,但是对文件夹的操作却不能用FileUpLoad来实现. 下面这个示例便是使用ASP.NET来实现上传文件夹并对文件夹进行压缩以及解压. ASP.NE ...
- 《挑战30天C++入门极限》 对C++中引用的补充说明(实例)
对C++中引用的补充说明(实例) #include <iostream> #include <string> using namespace std; ...
- 浅析python迭代器及生成器函数
1. 什么是迭代协议? 迭代协议主要包括两方面的协议集,一种是迭代器协议,另一种是可迭代协议.对于迭代器协议来说,其要求迭代器对象在能够在迭代环境中一次产生一个结果.对于可迭代协议来说,就是一个对象序 ...
- Java通过JDBC连接MySQL数据库(一)
JDBC JAVA Database Connectivity java 数据库连接 为什么会出现JDBC SUN公司提供的一种数据库访问规则.规范, 由于数据库种类较多,并且java语言使用比较广泛 ...
- [转载]运行中的DLL自升级
最近手头有个需求:dll需要注入到某个进程常驻,该dll具备自我升级能力,当发现新的可用版本时,立即Free自己,加载新的.下面是一个实现方案: 开启一个监听线程,从网络上拉新的可用版本,下载放到 ...
- PrivateIpAddresses Array of String 实例主网卡的内网IP列表。 PublicIpAddresses Array of String 实例主网卡的公网IP列表。 注意:此字段可能返回 null,表示取不到有效值。
https://cloud.tencent.com/document/api/213/15753 浮动 IP 地址 https://cloud.google.com/solutions/best-pr ...
- java使用json-lib库的json工具类.
import net.sf.ezmorph.object.DateMorpher;import net.sf.json.JSONArray;import net.sf.json.JSONObject; ...
- Mac 终端显示git分支
1 进入你的home目录 cd ~ 2 编辑.bashrc文件 vi .bashrc 3 将下面的代码加入到文件的最后处 function git_branch { branch="`git ...
- Leetcode: Campus Bikes II
On a campus represented as a 2D grid, there are N workers and M bikes, with N <= M. Each worker a ...
- 【转】把sqlite3数据导入到MySQL中
之前我们默认使用的是SQLite数据库,我们开发完成之后,里面有许多数据.如果我们想转换成Mysql数据库,那我们先得把旧数据从SQLite导出,然后再导入到新的Mysql数据库里去. 1.SQLit ...