HDFS中的数据块(Block)
我们在分布式存储原理总结中了解了分布式存储的三大特点:
- 数据分块,分布式的存储在多台机器上
- 数据块冗余存储在多台机器以提高数据块的高可用性
- 遵从主/从(master/slave)结构的分布式存储集群
HDFS作为分布式存储的实现,肯定也具有上面3个特点。
HDFS分布式存储:
在HDFS中,数据块默认的大小是128M,当我们往HDFS上上传一个300多M的文件的时候,那么这个文件会被分成3个数据块:

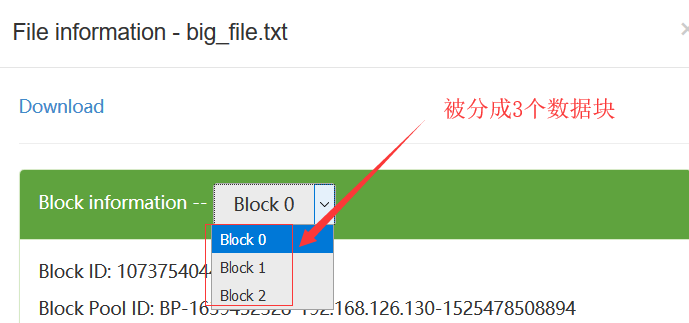
所有的数据块是分布式的存储在所有的DataNode上:
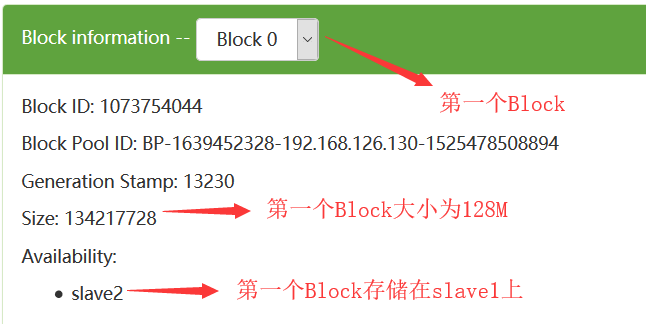

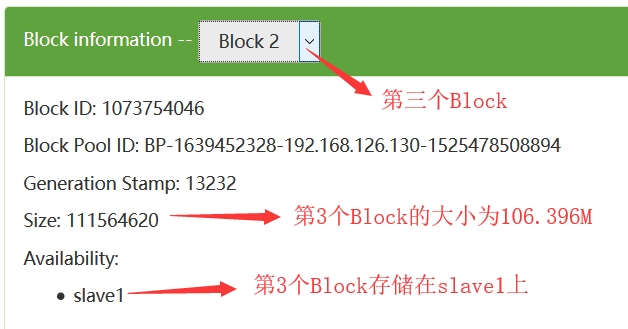
为了提高每一个数据块的高可用性,在HDFS中每一个数据块默认备份存储3份,在这里我们看到的只有1份,是因为我们在hdfs-site.xml中配置了如下的配置:
<property>
<name>dfs.replication</name>
<value>1</value>
<description>表示数据块的备份数量,不能大于DataNode的数量,默认值是3</description>
</property>
我们也可以通过如下的命令,将文件/user/hadoop-twq/cmd/big_file.txt的所有的数据块都备份存储3份:
hadoop fs -setrep 3 /user/hadoop-twq/cmd/big_file.txt
我们可以从如下可以看出:每一个数据块都冗余存储了3个备份
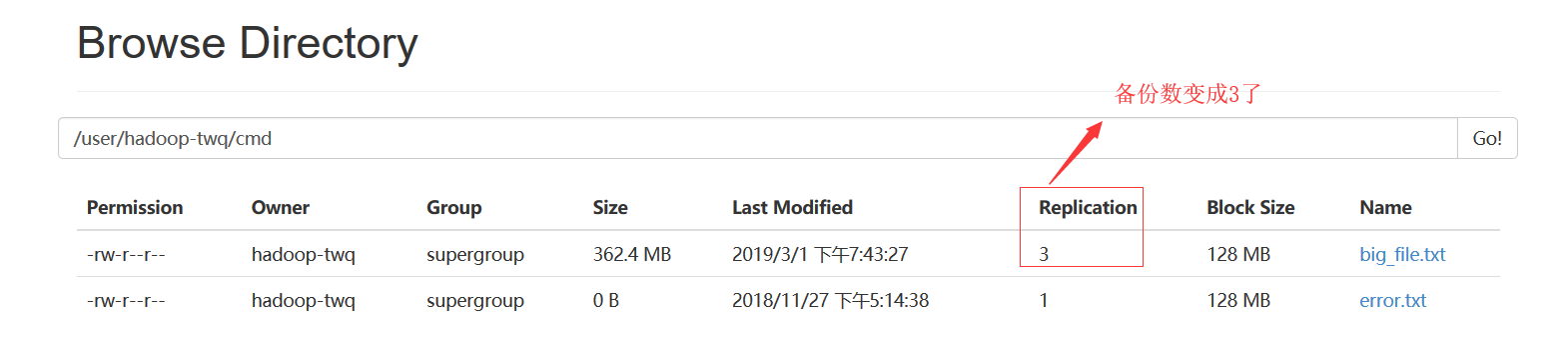

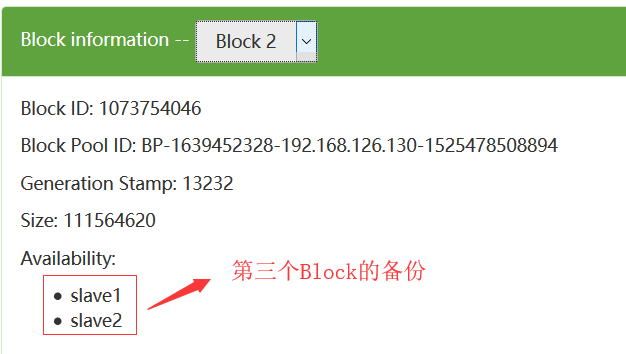
在这里,可能会问这里为什么看到的是2个备份呢?这个是因为我们的集群只有2个DataNode,所以最多只有2个备份,即使你设置成3个备份也没用,所以我们设置的备份数一般都是比集群的DataNode的个数相等或者要少
一定要注意:当我们上传362.4MB的数据到HDFS上后,如果数据块的备份数是3个话,那么在HDFS上真正存储的数据量大小是:362.4MB * 3 = 1087.2MB
注意:我们上面是通过HDFS的WEB UI来查看HDFS文件的数据块的信息,除了这种方式查看数据块的信息,我们还可以通过命令fsck来查看
数据块的实现
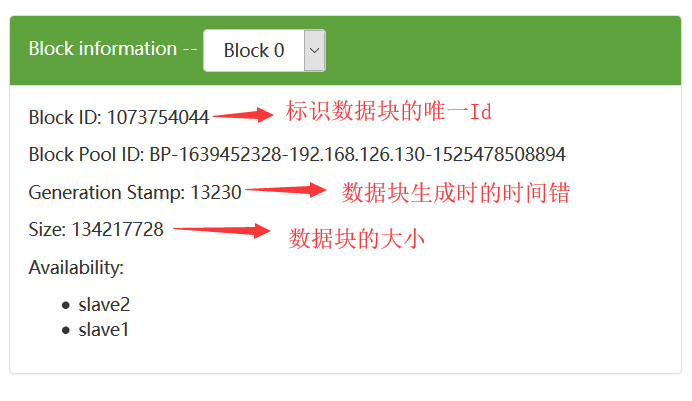
在HDFS的实现中,数据块被抽象成类org.apache.hadoop.hdfs.protocol.Block(我们以下简称Block)。在Block类中有如下几个属性字段:
public class Block implements Writable, Comparable<Block> {
private long blockId; // 标识一个Block的唯一Id
private long numBytes; // Block的大小(单位是字节)
private long generationStamp; // Block的生成时间戳
}
我们从WEB UI上的数据块信息也可以看到:
一个Block除了存储上面的3个字段信息,还需要知道这个Block含有多少个备份,每一个备份分别存储在哪一个DataNode上,为了存储这些信息,HDFS中有一个名为org.apache.hadoop.hdfs.server.blockmanagement.BlockInfoContiguous(下面我们简称为BlockInfo)的类来存储这些信息,这个BlockInfo类继承Block类,如下:

BlockInfo类中只有一个非常核心的属性,就是名为triplets的数组,这个数组的长度是3*replication,replication表示数据块的备份数。这个数组中存储了该数据块所有的备份数据块对应的DataNode信息,我们现在假设备份数是3,那么这个数组的长度是3*3=9,这个数组存储的数据如下:

也就是说,triplets包含的信息:
- triplets[i]:Block所在的DataNode;
- triplets[i+1]:该DataNode上前一个Block;
- triplets[i+2]:该DataNode上后一个Block;
其中i表示的是Block的第i个副本,i取值[0,replication)。
我们在HDFS的NameNode中的Namespace管理中讲到了,一个HDFS文件包含一个BlockInfo数组,表示这个文件分成的若干个数据块,这个BlockInfo数组实际上就是我们这里说的BlockInfoContiguous数组。以下是INodeFile的属性:
public class INodeFile {
private long header = 0L; // 用于标识存储策略ID、副本数和数据块大小的信息
private BlockInfoContiguous[] blocks; // 该文件包含的数据块数组
}
那么,到现在为止,我们了解到了这些信息:文件包含了哪些Block,这些Block分别被实际存储在哪些DataNode上,DataNode上所有Block前后链表关系。
如果从信息完整度来看,以上信息数据足够支持所有关于HDFS文件系统的正常操作,但还存在一个使用场景较多的问题:怎样通过blockId快速定位BlockInfo?
我们其实可以在NameNode上用一个HashMap来维护blockId到Block的映射,也就是说我们可以使用HashMap<Block, BlockInfo>来维护,这样的话我们就可以快速的根据blockId定位BlockInfo,但是由于在内存使用、碰撞冲突解决和性能等方面存在问题,Hadoop团队之后使用重新实现的LightWeightGSet代替HashMap,该数据结构本质上也是利用链表解决碰撞冲突的HashTable,但是在易用性、内存占用和性能等方面表现更好。
HDFS为了解决通过blockId快速定位BlockInfo的问题,所以引入了BlocksMap,BlocksMap底层通过LightWeightGSet实现。
在HDFS集群启动过程,DataNode会进行BR(BlockReport,其实就是将DataNode自身存储的数据块上报给NameNode),根据BR的每一个Block计算其HashCode,之后将对应的BlockInfo插入到相应位置逐渐构建起来巨大的BlocksMap。前面在INodeFile里也提到的BlockInfo集合,如果我们将BlocksMap里的BlockInfo与所有INodeFile里的BlockInfo分别收集起来,可以发现两个集合完全相同,事实上BlocksMap里所有的BlockInfo就是INodeFile中对应BlockInfo的引用;通过Block查找对应BlockInfo时,也是先对Block计算HashCode,根据结果快速定位到对应的BlockInfo信息。至此涉及到HDFS文件系统本身元数据的问题基本上已经解决了。
BlocksMap内存估算
HDFS将文件按照一定的大小切成多个Block,为了保证数据可靠性,每个Block对应多个副本,存储在不同DataNode上。NameNode除需要维护Block本身的信息外,还需要维护从Block到DataNode列表的对应关系,用于描述每一个Block副本实际存储的物理位置,BlocksMap结构即用于Block到DataNode列表的映射关系,BlocksMap是常驻在内存中,而且占用内存非常大,所以对BlocksMap进行内存的估算是非常有必要的。我们先看下BlocksMap的内部结构:
以下的内存估算是在64位操作系统上且没有开启指针压缩功能场景下
以下的内存估算是在64位操作系统上且没有开启指针压缩功能场景下
class BlocksMap {
private final int capacity; // 占 4 字节
// 我们使用GSet的实现者:LightWeightGSet
private GSet<Block, BlockInfoContiguous> blocks; // 引用类型占8字节
}
可以得出BlocksMap的直接内存大小是对象头16字节 + 4字节 + 8字节 = 28字节
Block的结构如下:
public class Block implements Writable, Comparable<Block> {
private long blockId; // 标识一个Block的唯一Id 占 8字节
private long numBytes; // Block的大小(单位是字节) 占 8字节
private long generationStamp; // Block的生成时间戳 占 8字节
}
可以得出Block的直接内存大小是对象头16字节 + 8字节 + 8字节 + 8字节 = 40字节
BlockInfoContiguous的结构如下:
public class BlockInfoContiguous extends Block {
private BlockCollection bc; // 引用类型占8字节
private LightWeightGSet.LinkedElement nextLinkedElement; // 引用类型占8字节
private Object[] triplets; // 引用类型 8字节 + 数组对象头24字节 + 3*3(备份数假设为3)*8 = 104字节
}
可以得出BlockInfoContiguous的直接内存大小是对象头16字节 + 8字节 + 8字节 + 104字节 = 136字节
LightWeightGSet的结构如下:
public class LightWeightGSet<K, E extends K> implements GSet<K, E> {
private final LinkedElement[] entries; // 引用类型 8字节 + 数组对象头24字节 = 32字节
private final int hash_mask; // 4字节
private int size = 0; // 4字节
private int modification = 0; // 4字节
}
LightWeightGSet本质是一个链式解决冲突的哈希表,为了避免rehash过程带来的性能开销,初始化时,LightWeightGSet的索引空间直接给到了整个JVM可用内存的2%,并且不再变化。 所以LightWeightGSet的直接内存大小为:对象头16字节 + 32字节 + 4字节 + 4字节 + 4字节 + (2%*JVM可用内存) = 60字节 + (2%*JVM可用内存)
假设集群中共1亿Block,NameNode可用内存空间固定大小128GB,则BlocksMap占用内存情况:
BlocksMap直接内存大小 + (Block直接内存大小 + BlockInfoContiguous直接内存大小) * 100M + LightWeightGSet直接内存大小
即:
28字节 + (40字节 + 136字节) * 100M + 60字节 + (2%*128G) = 19.7475GB
上面为什么是乘以100M呢? 因为100M = 100 * 1024 * 1024 bytes = 104857600 bytes,约等于1亿字节,而上面的内存的单位都是字节的,我们乘以100M,就相当于1亿Block
BlocksMap数据在NameNode整个生命周期内常驻内存,随着数据规模的增加,对应Block数会随之增多,BlocksMap所占用的JVM堆内存空间也会基本保持线性同步增加。
HDFS中的数据块(Block)的更多相关文章
- HDFS源码分析之数据块Block、副本Replica
我们知道,HDFS中的文件是由数据块Block组成的,并且为了提高容错性,每个数据块Block都会在不同数据节点DataNode上有若干副本Replica.那么,什么是Block?什么又是Replic ...
- java程序向hdfs中追加数据,异常以及解决方案
今天在学习hdfs时,遇到问题,就是在向hdfs中追加数据总是报错,在经过好几个小时的努力之下终于将他搞定 解决方案如下:在hadoop的hdfs-sit.xml中添加一下三项 <propert ...
- Linux启动kettle及linux和windows中kettle往hdfs中写数据(3)
在xmanager中的xshell运行进入图形化界面 sh spoon.sh 新建一个job
- hbase使用MapReduce操作4(实现将 HDFS 中的数据写入到 HBase 表中)
实现将 HDFS 中的数据写入到 HBase 表中 Runner类 package com.yjsj.hbase_mr2; import com.yjsj.hbase_mr2.ReadFruitFro ...
- Sqoop2 将hdfs中的数据导出到MySQL
1.进入sqoop2终端: [root@master /]# sqoop2 2.为客户端配置服务器: sqoop:000> set server --host master --port 120 ...
- 使用sqoop往hdfs中导入数据供hive使用
sqoop import -fs hdfs://x.x.x.x:8020 -jt local --connect "jdbc:oracle:thin:@x.x.x.x:1521:testdb ...
- Spark向HDFS中存储数据
程序如下: import org.apache.spark.sql.Row; import org.apache.spark.SparkConf; import org.apache.spark.ap ...
- S7-1200在博途V16中新建数据块(DB)
硬件环境: S7-1200 CPU V4.4(6ES7 212-1AE40-0XB0) 软件环境: (1)Windows 10 Professional SP1 64位 (2)STEP7 V16 SP ...
- HBase结合MapReduce批量导入(HDFS中的数据导入到HBase)
HBase结合MapReduce批量导入 package hbase; import java.text.SimpleDateFormat; import java.util.Date; import ...
随机推荐
- PHP设计模式 - 模板方法模式
模板模式准备一个抽象类,将部分逻辑以具体方法以及具体构造形式实现,然后声明一些抽象方法来迫使子类实现剩余的逻辑.不同的子类可以以不同的方式实现这些抽象方法,从而对剩余的逻辑有不同的实现.先制定一个顶级 ...
- hive学习(1)
什么是Hive Hive是基于Hadoop的一个数据仓库工具(E抽取T转换L加载),可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. 本质是:将HQL转化成MapReduce程序 Hive ...
- C++的派生类构造函数是否要带上基类构造函数
//public:Student(int s_age):People(s_age) //C++的派生类构造函数后面是否带上基类构造函数,取决于基类构造函数是否需要传入参数,如果要参数,就一定带上:不需 ...
- Linux05 文件或目录的权限(ls、lsattr、chattr、chmod、chown、chgrp、file)
一.查看文件或目录的权限:ls -al 文件名/目录名 keshengtao@LAPTOP-F9AFU4OK:~$ ls -al total drwxr-xr-x keshengtao keshen ...
- 13 IO流(十)——BufferedReader/BufferedWriter 装饰流
Buffered字符包装流 与Buffered字节装饰流一样,只不过是对字符流进行包装. 需要注意的地方 Buffered字符流在Reader与Writer上有两个新的方法:String readLi ...
- 开源图像识别库OpenCV基于Maven的开发环境准备
1.安装 JDK 8+,并设置 JAVA_HOME 环境变量 2.安装 Maven,并将 “/bin” 子目录设置到 path 环境变量 3.下载 OpenCV,官网传送门 也可以直接下载本人瘦身之后 ...
- Linux sftp命令
sftp是Secure File Transfer Protocol的缩写,安全文件传送协议.可以为传输文件提供一种安全的网络的加密方法.sftp 与 ftp 有着几乎一样的语法和功能.SFTP 为 ...
- java之hibernate之关联映射之多对一单向关联
1.在之前学习了单表的crud操作.在实际应用中,大都是多表关联操作,这篇会学习如何处理多表之间的关系. 2.考察书籍表和书籍分类表的关系.书籍表和书籍分类表之间是多对一的关系.数据库的表设计为: 3 ...
- c# 异步( Async ) 不是多线程
c# 异步( Async ) 不是多线程 误解 async 在调试 xxxxAsync() 方法的时候,常常会看到调试器界面中会多出一些线程,直觉上误认为 Async 冠名的函数是多线程. 对于 ...
- atan、atanf、atanl、atan2、atan2f、atan2l
很久不发博客了,今天在园中计算各种角,于是复习下fan正切函数 计算x的反正切值 (atan.atanf和 atanl) 或y/x 的反正切值 (atan2.atan2f和 atan2l). ...