32、reduceByKey和groupByKey对比
一、groupByKey
1、图解
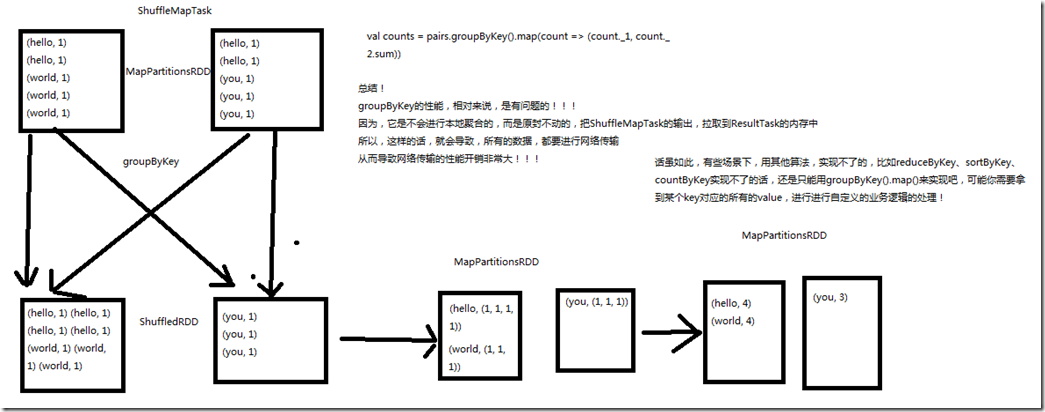
val counts = pairs.groupByKey().map(wordCounts => (wordCounts._1, wordCounts._2.sum)) groupByKey的性能,相对来说,是有问题的; 因为,它是不会进行本地聚合的,而是原封不动的,把ShuffleMapTask的输出,拉取到ResultTask的内存中,所以这样的话,会导致,所有的数据,都要进行网络传输,
从而导致网络传输的性能开销很大; 但是,有些场景下,用其他算法实现不了的,比如reduceByKey,sortByKey,countByKey实现不了的话,还是只能用groupByKey().map()来实现,比如可能你需要拿到
某个key对应的所有的value,进行自定义的业务逻辑处理;
二、reduceByKey
1、图解
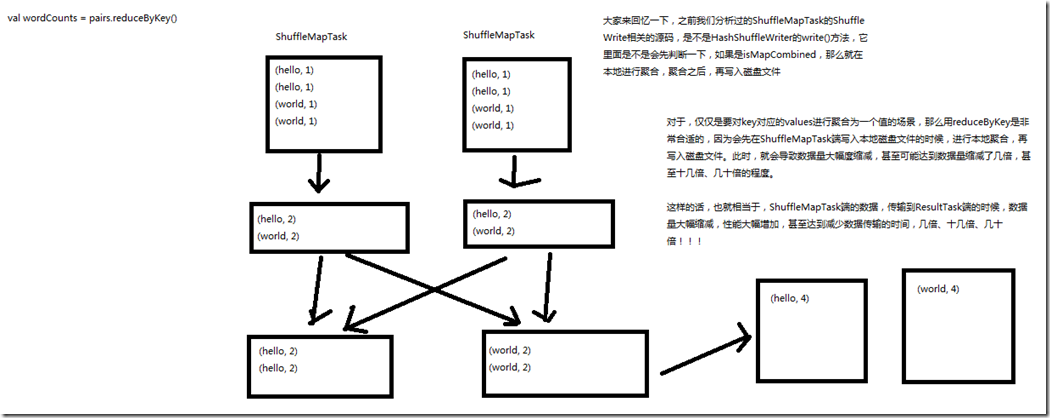
val counts = pairs.reduceByKey(_ + _) HashShuffleWriter的writer()方法,是先判断了一下,如果是isMapCombined,那么就在本地进行聚合,聚合之后,再写入磁盘文件; 对于,仅仅是要对key对应的values进行聚合为一个值的场景,用reduceByKey是非常合适的,因为会先在ShuffleMapTask端写入本地磁盘文件的时候,
进行本地聚合,再写入磁盘文件,此时,就会导致数据量大幅度缩减,甚至可能达到数据量缩减了几倍,甚至十几倍、几十倍的程度; 这样的话,也就相当于,ShuffleMapTask端的数据,传输到ReduceTasl端的数据,数据量大幅度缩减,性能大幅度增加,甚至达到减少数据量的时间,几倍、十几倍、几十倍; 如果能用reduceByKey,那就用reduceByKey,因为它会在map端,先进行本地combine,可以大大减少要传输到reduce端的数据量,减小网络传输的开销。
只有在reduceByKey处理不了时,才用groupByKey().map()来替代。
32、reduceByKey和groupByKey对比的更多相关文章
- 转载-reduceByKey和groupByKey的区别
原文链接-https://www.cnblogs.com/0xcafedaddy/p/7625358.html 先来看一下在PairRDDFunctions.scala文件中reduceByKey和g ...
- reduceByKey和groupByKey的区别
先来看一下在PairRDDFunctions.scala文件中reduceByKey和groupByKey的源码 /** * Merge the values for each key using a ...
- spark RDD,reduceByKey vs groupByKey
Spark中有两个类似的api,分别是reduceByKey和groupByKey.这两个的功能类似,但底层实现却有些不同,那么为什么要这样设计呢?我们来从源码的角度分析一下. 先看两者的调用顺序(都 ...
- reduceByKey和groupByKey区别与用法
在spark中,我们知道一切的操作都是基于RDD的.在使用中,RDD有一种非常特殊也是非常实用的format——pair RDD,即RDD的每一行是(key, value)的格式.这种格式很像Pyth ...
- 【Spark算子】:reduceByKey、groupByKey和combineByKey
在spark中,reduceByKey.groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结: 我的代码实践:https://github.com/wwcom ...
- spark:reducebykey与groupbykey的区别
从源码看: reduceBykey与groupbykey: 都调用函数combineByKeyWithClassTag[V]((v: V) => v, func, func, partition ...
- scala flatmap、reduceByKey、groupByKey
1.test.txt文件中存放 asd sd fd gf g dkf dfd dfml dlf dff gfl pkdfp dlofkp // 创建一个Scala版本的Spark Context va ...
- spark新能优化之reduceBykey和groupBykey的使用
val counts = pairs.reduceByKey(_ + _) val counts = pairs.groupByKey().map(wordCounts => (wordCoun ...
- 【spark】常用转换操作:reduceByKey和groupByKey
1.reduceByKey(func) 功能: 使用 func 函数合并具有相同键的值. 示例: val list = List("hadoop","spark" ...
随机推荐
- 如何用navicat导入数据?
介绍了如何使用navicat导入数据到数据库 0背景介绍 这里用的软件版本号是11.2.7 1选择要导入的数据库,右击选择导入向导 2 选择导入数据文件的类型 根据要导入数据文件的类型,选择对应的导入 ...
- python3-使用requests模拟登录网易云音乐
# -*- coding: utf-8 -*- from Crypto.Cipher import AES import base64 import random import codecs impo ...
- JAVA日期格式化yyyyMMddHHmmssSSS
String nowtime = new SimpleDateFormat("yyyyMMddHHmmssSSS").format(new Date());
- node的启动环境
在开发的时候开发环境和正式环境用的接口地址是不一样的端口号可能也不一样,这时候就需要区分端口号,具体方法如下: 在package.json文件的scripts中设置启动命令的时候区分开发和正式: &q ...
- vue使用vuex大体结构
store1.js const state = {} const mutations = {} const actions = {} const getters = {} export default ...
- css小技巧 --> 单标签实现单行文字居中,多行文字居左
可能出现的尺寸场景: 代码如下: <!DOCTYPE html> <html lang="zh"> <head> <meta charse ...
- ..\USER\stm32f10x.h(428): error: #67: expected a "}" ADC1_2_IRQn = 18, /*!
MDK软件编译,出现如下错误: ..\USER\stm32f10x.h(428): error: #67: expected a "}" ADC1_2_IRQn = 18, /*! ...
- 大数据的前世今生【Hadoop、Spark】
一.大数据简介 大数据是一个很热门的话题,但它是什么时候开始兴起的呢? 大数据[big data]这个词最早在UNIX用户协会的会议上被使用,来自SGI公司的科学家在其文章“大数据与下一代基础架构 ...
- Android笔记(四十六) Android中的数据存储——XML(二)PULL解析
PULL 的工作原理: XML pull提供了开始元素和结束元素.当某个元素开始时,可以调用parser.nextText()从XML文档中提取所有字符数据.当解析到一个文档结束时,自动生成EndDo ...
- Springboot手动获取bean
使用如下工具类即可 package com.rio.ums.spa.commons.utils; import org.springframework.beans.BeansException; im ...