hbase运行原理
HBase特点
1)海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正式因为Hbase良好的扩展性,才为海量数据的存储提供了便利。
2)列式存储
这里的列式存储其实说的是列族存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3)极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。
备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
4)高并发
由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
5)稀疏
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
HBase的数据模型
HBase的架构
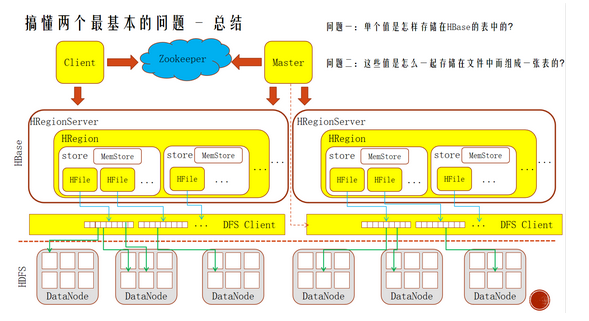
Hfile
HBase的读写缓存机制
hbase运行原理的更多相关文章
- Hbase:原理和设计
转载自:http://www.sysdb.cn/index.php/2016/01/10/hbase_principle/ ,感谢原作者. 简介 HBase —— Hadoop Database的简称 ...
- Hadoop 综合揭秘——HBase的原理与应用
前言 现今互联网科技发展日新月异,大数据.云计算.人工智能等技术已经成为前瞻性产品,海量数据和超高并发让传统的 Web2.0 网站有点力不从心,暴露了很多难以克服的问题.为此,Google.Amazo ...
- Hadoop(六)MapReduce的入门与运行原理
一 MapReduce入门 1.1 MapReduce定义 Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架: Mapreduce核心功能是将用 ...
- Hadoop运行原理总结(详细)
本编随笔是小编个人参照个人的笔记.官方文档以及网上的资料等后对HDFS的概念以及运行原理进行系统性地归纳,说起来真的惭愧呀,自学了很长一段时间也没有对Hadoop知识点进行归纳,有时候在实战中或者与别 ...
- 【HBase】二、HBase实现原理及系统架构
整个Hadoop生态中大量使用了master-slave的主从式架构,如同HDFS中的namenode和datanode,MapReduce中的JobTracker和TaskTracker,YAR ...
- Hbase概念原理扫盲
一.Hbase简介 1.什么是Hbase Hbase的原型是google的BigTable论文,收到了该论文思想的启发,目前作为hadoop的子项目来开发维护,用于支持结构化的数据存储. Hbase是 ...
- HBase 底层原理详解(深度好文,建议收藏)
HBase简介 HBase 是一个分布式的.面向列的开源数据库.建立在 HDFS 之上.Hbase的名字的来源是 Hadoop database,即 Hadoop 数据库.HBase 的计算和存储能力 ...
- iis6.0与asp.net的运行原理
这几天上网翻阅了不少前辈们的关于iis和asp.net运行原理的博客,学的有点零零散散,花了好长时间做了一个小结(虽然文字不多,但也花了不少时间呢),鄙人不才,难免有理解不道的地方,还望前辈们不吝赐教 ...
- ASP.NET Core 运行原理剖析2:Startup 和 Middleware(中间件)
ASP.NET Core 运行原理剖析2:Startup 和 Middleware(中间件) Startup Class 1.Startup Constructor(构造函数) 2.Configure ...
随机推荐
- git合并不同仓库下的分支
1.把lib合并到pro $ git remote -v origin git@192.168.1.1:lib.git (fetch) origin git@192.168.1.1:lib.git ( ...
- 第22课 weak_ptr弱引用智能指针
一. weak_ptr的概况 (一)weak_ptr的创建 1. 直接初始化:weak_ptr<T> wp(sp); //其中sp为shared_ptr类型 2. 赋值: wp1 = sp ...
- 使用Linq判断DataTable数据是否重复
我们一般系统在导入数据的时候,一般都是通过NPOI将excel数据转换成DataTable,然后将DataTable导入到数据库.在数据导入的过程中,其实很重要的一部就是检查DataTable中的数据 ...
- a2 任意角度选取设置
思岚的激光雷达A2固定角度是0-360°,但是由于结构空间限制往往无法得到360°的数据,如何设置获取任意角度呢?咨询过思岚的技术支持,得到的回答是:“我们已经不支持ROS系统..”让人有点蛋疼.., ...
- IntelliJ IDEA 提交代码时出现:Code analysis failed with exception: com.intellij.psi......
IntelliJ IDEA 提交代码时出现:Code analysis failed with exception: com.intellij.psi...... 错误原因: 当我们勾选Perform ...
- Oracle Hint用法整理笔记
目录 1./+ result_cache / 2./+ connect_by_filtering / 3./+ no_unnset / 4./+ index(表别名 索引名) / 5./+ INDEX ...
- golang net之http server
golang 版本:1.12.9 简单的HTTP服务器代码: package main import ( "net/http" ) type TestHandler struct ...
- ubutun16.04 安装编译glog日志库
glog 是一个 C++ 日志库,它提供 C++ 流式风格的 API.在安装 glog 之前需要先安装 gflags,这样 glog 就可以使用 gflags 去解析命令行参数(可以参见gflags ...
- Mysql 工具mysqlbinlog
[1]mysqlbinlog工具 在Windows环境下,安装完成Mysql后,在安装目录bin下会存在mysqlbinlog.exe应用程序. binlog是二进制内容文件,人类是无法直视的.而my ...
- service的yaml说明
apiVersion: v1 kind: Service metadata: name: nginx-service labels: app: nginx spec: ports: - port: 8 ...