[技术博客]使用CDN加快网站访问速度
[技术博客]使用CDN加快网站访问速度
2s : most users are willing to wait
10s : the limit for keeping the user’s attention focused on the dialogue
15s : tolerant time limit of most users
-- Fiona Fui-Hoon Nah, in A study on tolerable waiting time: how long are Web users willing to wait?, 2007
网站访问速度是用户体验的重要组成部分。用户往往会给一个响应快速的网站较好的评价,而对于一个经常卡顿的网站则会留下团队技术水平较低的印象。(举例:美赛官网)因此,我们在beta阶段对网站进行了各种优化,使用了缓存,CDN,优化加载等等手段,大幅提升了网站的访问速度。我们打算首先就遇到的加载慢的问题进行分析,之后介绍一下我们的解决方案与采取的技术,最后对比一下优化的效果。
目录
1. 发现问题
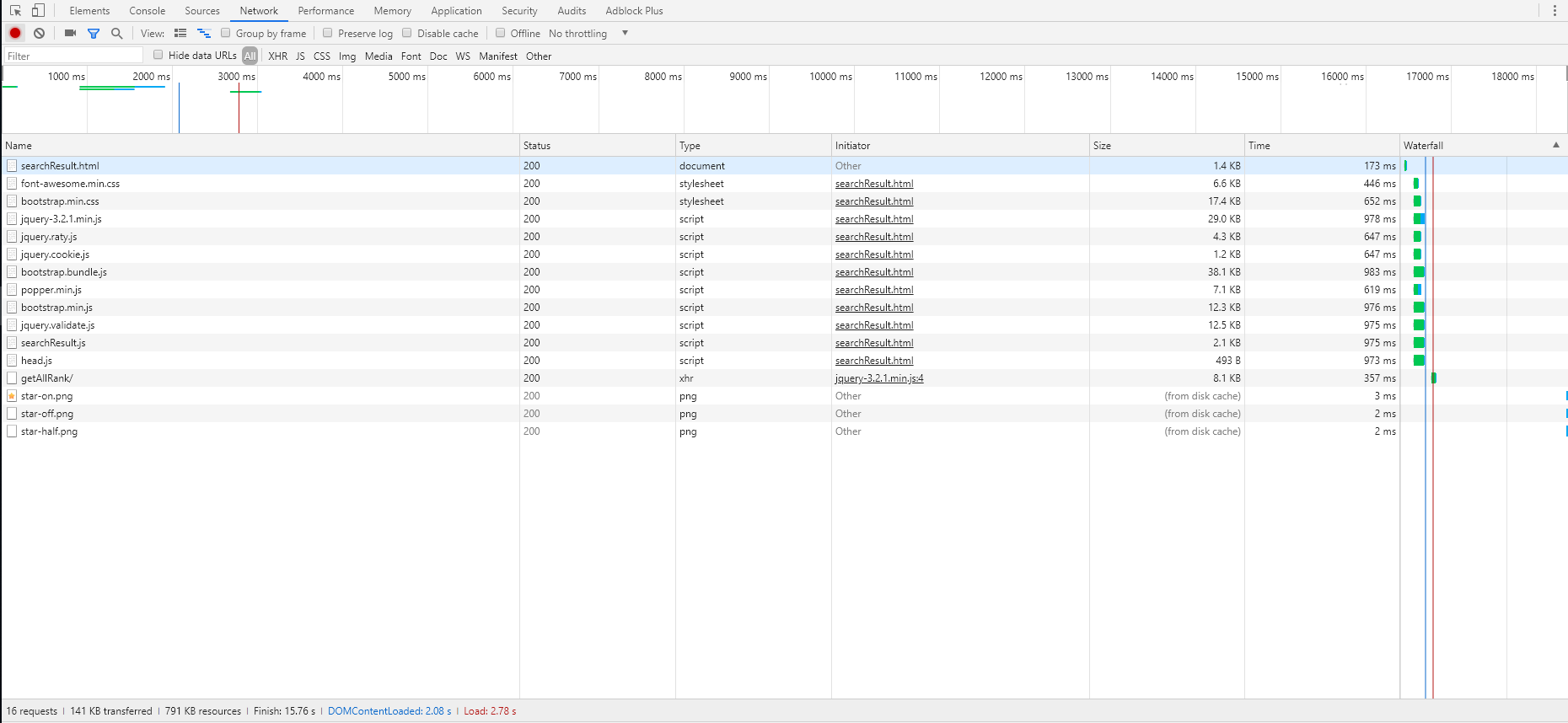
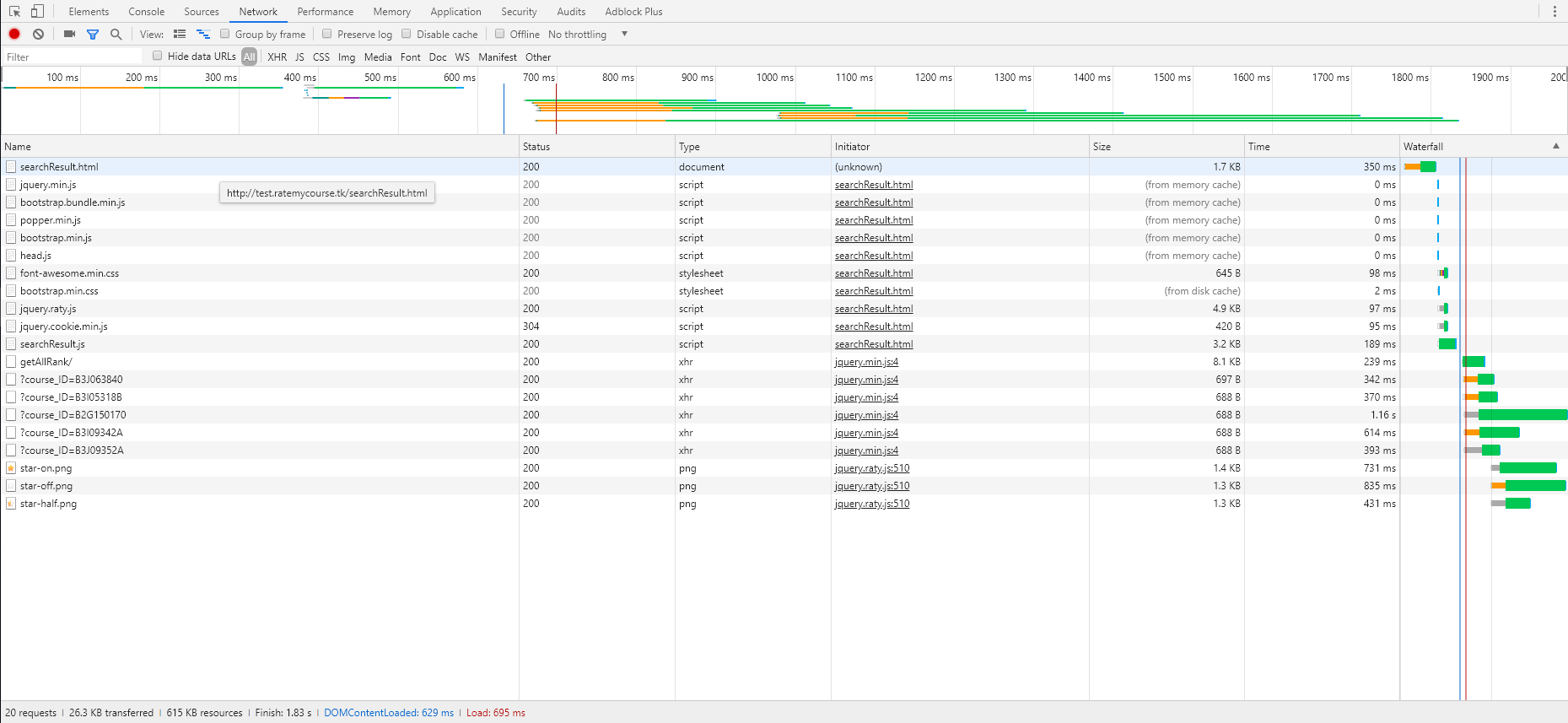
在我们的网站被攻击后(详细),我们决定采用CDN进行网站防护。在调研了各家公司的产品并检查了空空如也的预算后我们决定采用CloudFlare的免费防护方案,并将网站部署在GitHub学生包薅资本主义羊毛搞来的vps上。在解决了恶意攻击问题后,我们又遇到了新的问题:网站加载较慢。首页平均要5秒左右加载,而搜索页在条数比较多时甚至需要20秒左右加载完成。
2. 分析问题
2.1. 网页加载时间与瀑布图
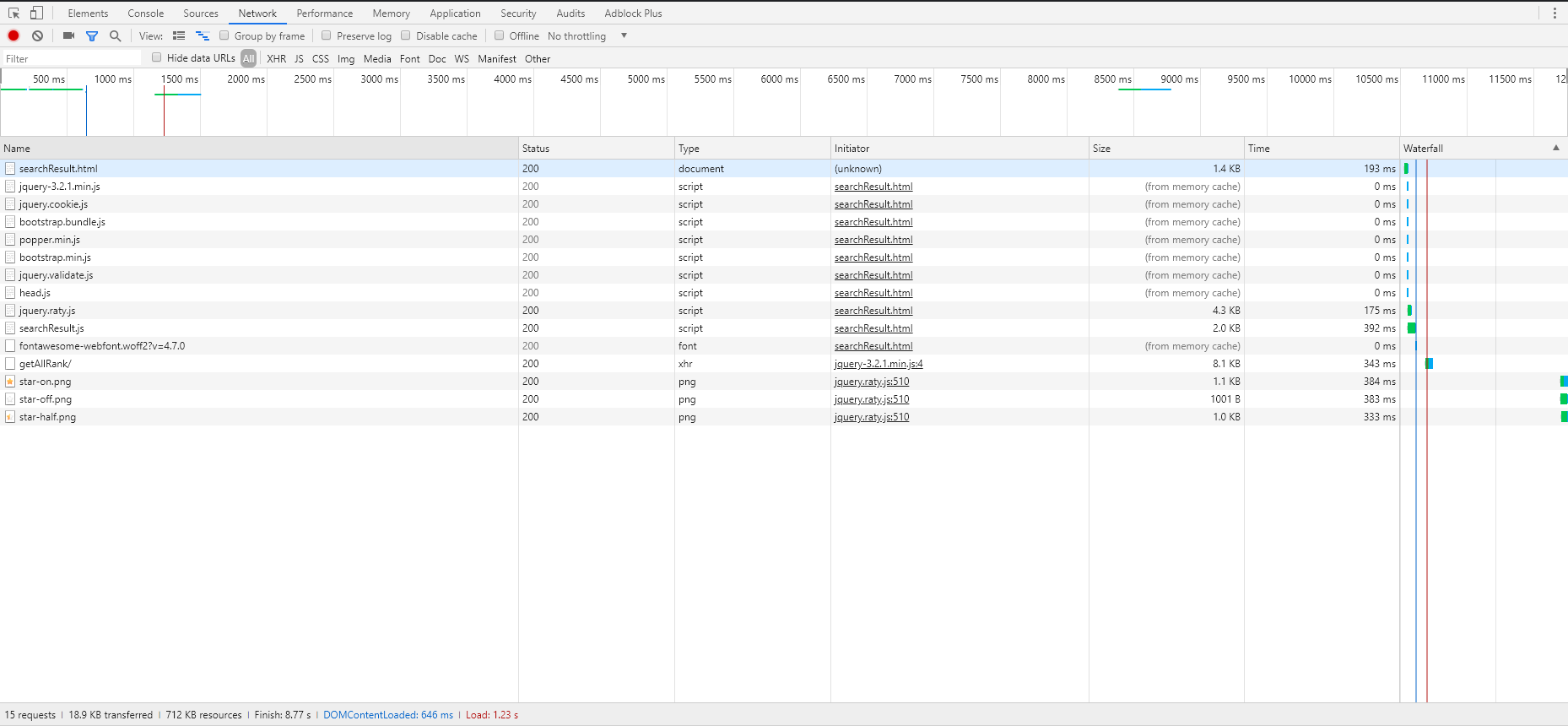
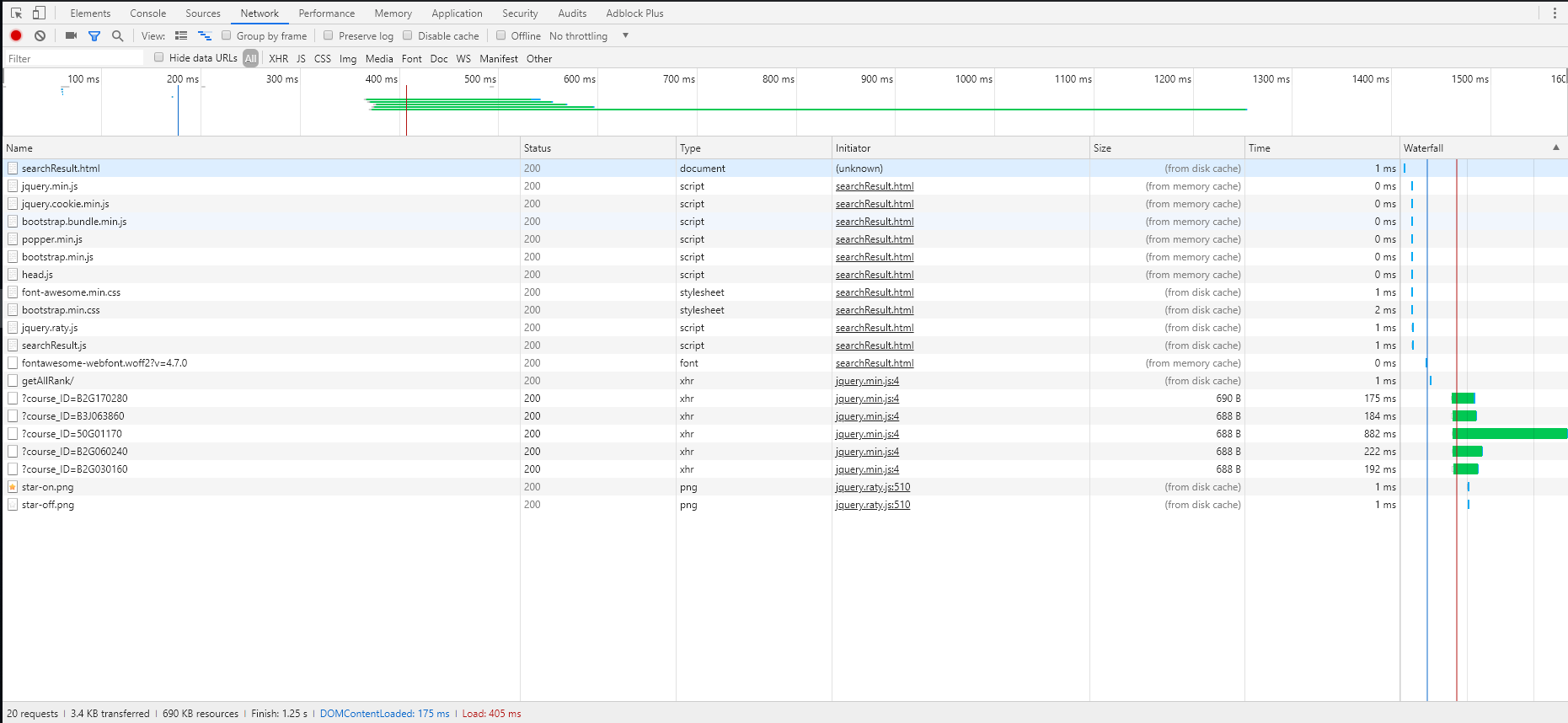
我们选取了三个典型页面利用chrome调试台做了分析,分别是首页(一定访问的页面),搜索所有课程页面(耗时最长,占用服务器资源最多),搜索“数学”关键字的页面(模拟随机搜索),加载的时间与瀑布图如下。
首页:
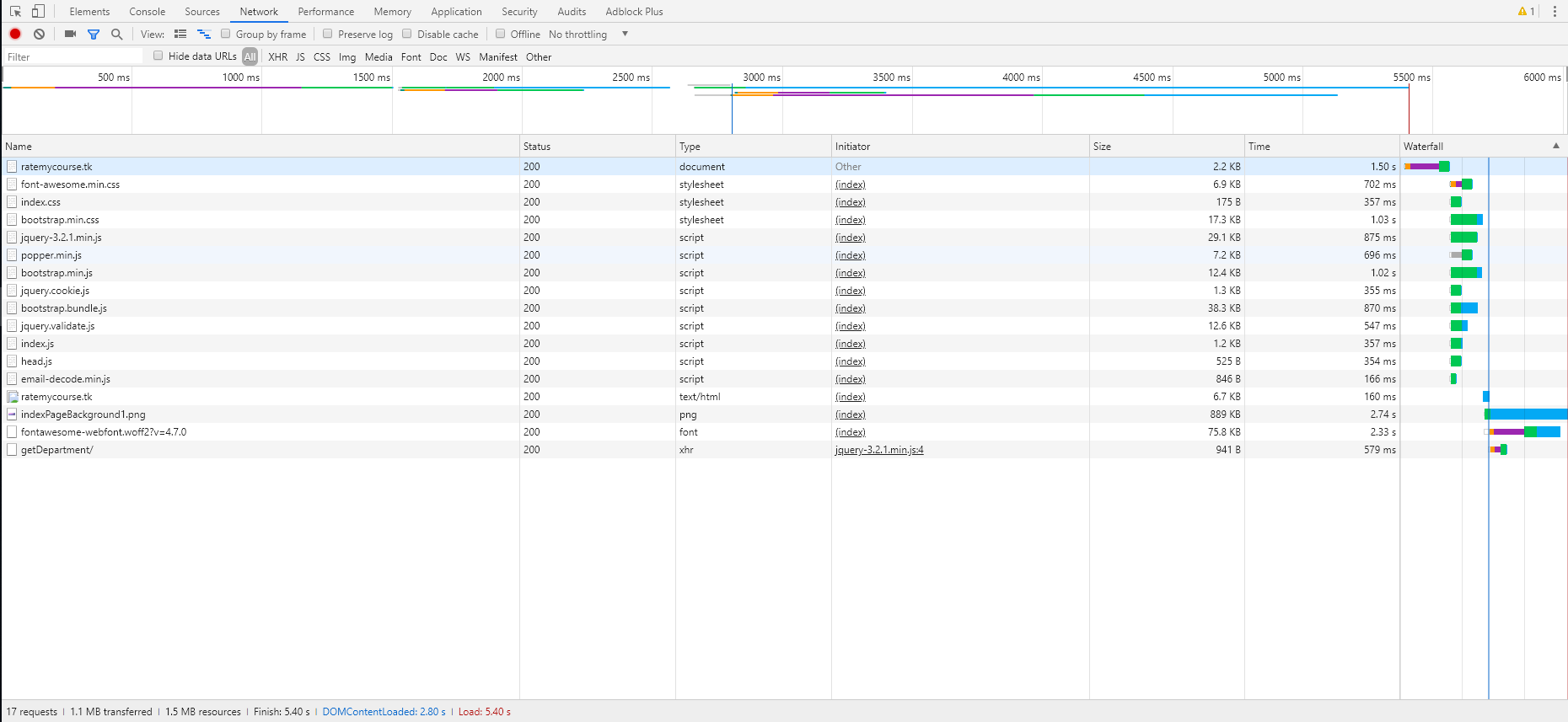
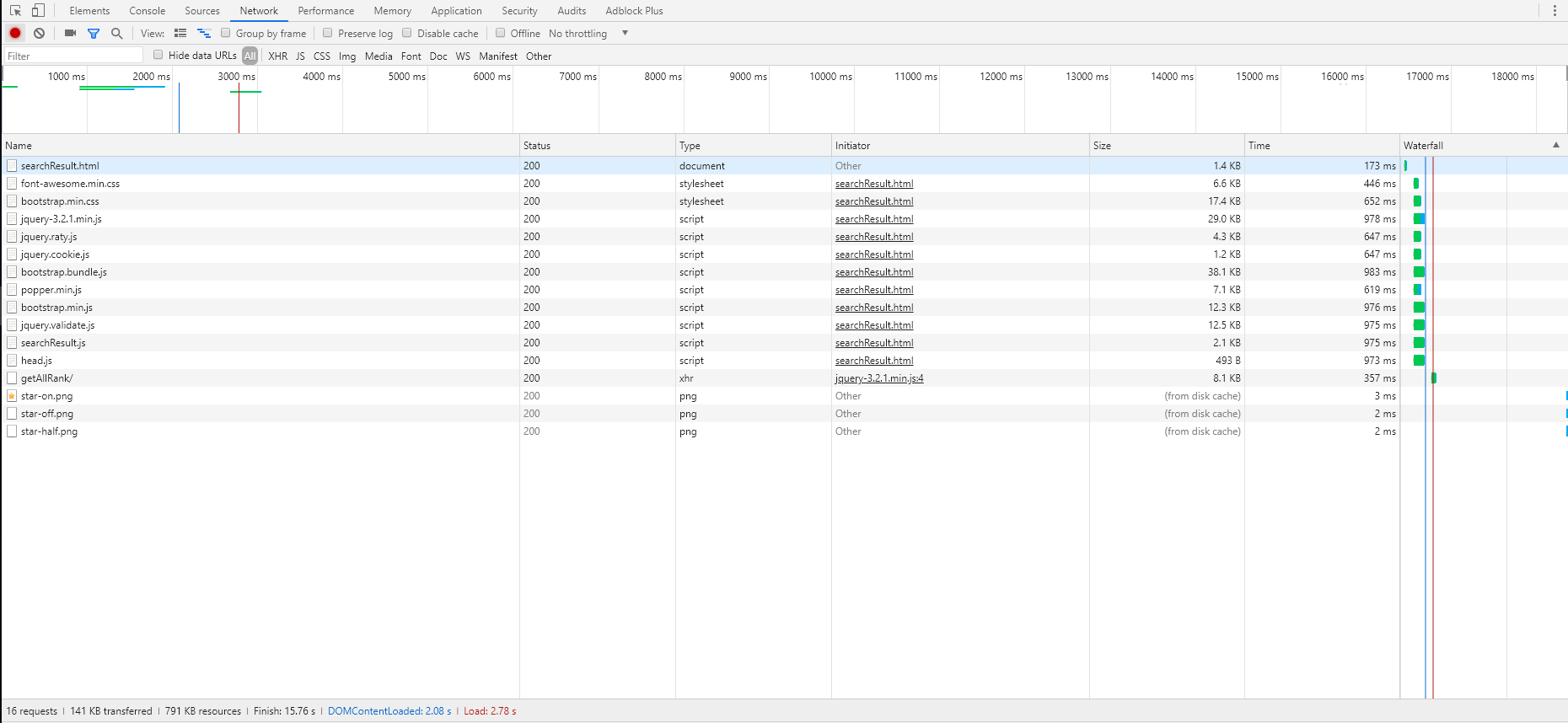
搜索全部课程:
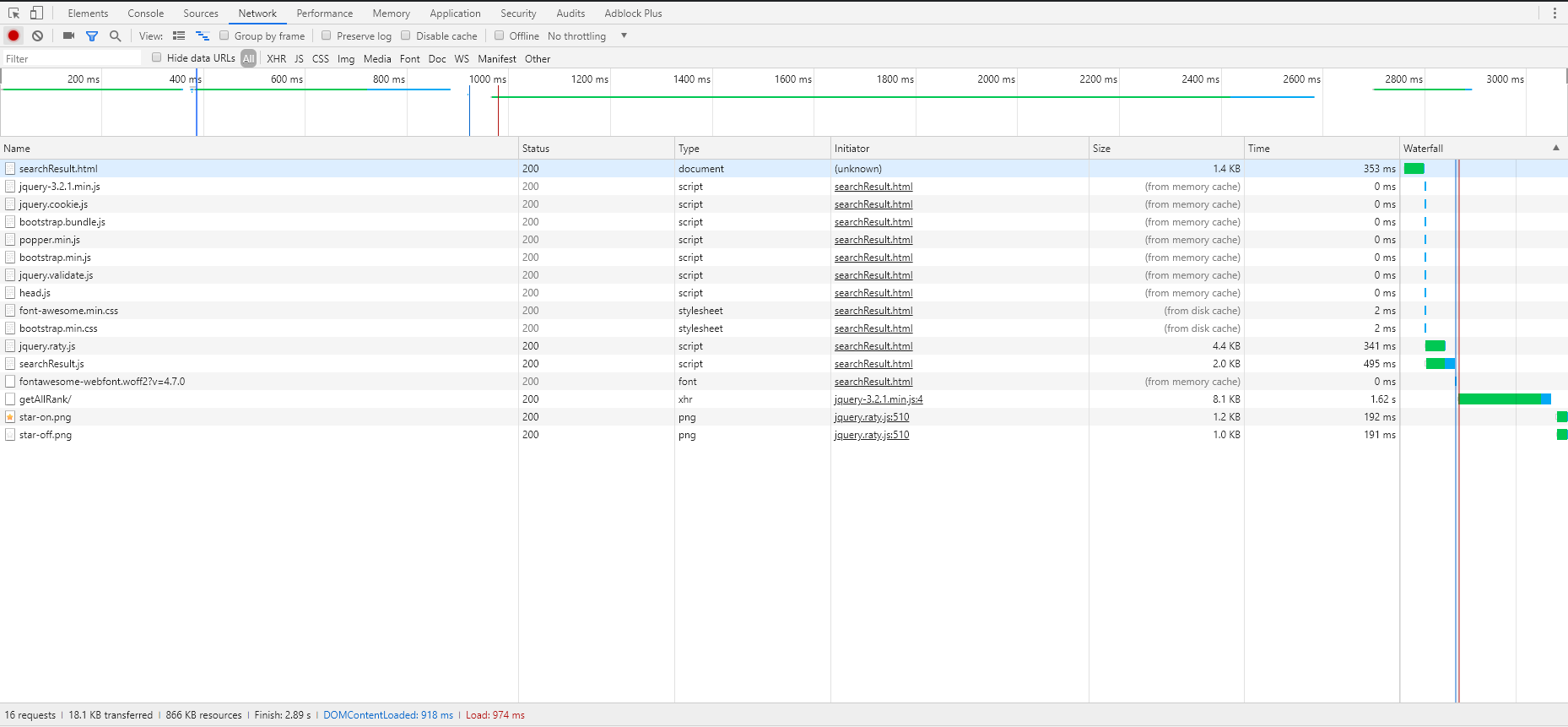
模拟随机搜索:
2.2. 详细分析
我们逐个分析这三个页面加载缓慢的原因,主要通过分析最花时间的部分。
2.2.1. 首页
可以看到,首页元素中加载最慢的是背景图片与font。此外,网站页面加载与js加载也耗费了较长的时间。因此我们打算采用静态资源使用公共CDN,网站使用cloudflare加速的方式解决。
2.2.2. 搜索全部课程页面
可以看到网页渲染耗费了最多的时间,此外,获取搜索结果也耗费了较长的时间(这里应该还有一个searchCourse的请求,不知道为什么截取不到),搜索过程服务器占用较高。
2.2.3. 模拟随机搜索页面
这个网页加载时间还算合格,但是实际上是因为js资源在访问主页是被加载了,这里直接读了缓存。此外网站渲染时间依然较长。
对于搜索结果页面,我们打算从前端代码(渲染逻辑)和后端(缓存),CDN(缓存)上解决。
3. 采用的技术
为了解决上述页面的加载缓慢问题,我们最后采用了以下技术:Django缓存,数据库建表缓存,网页渲染逻辑,CDN对于页面、资源的缓存,公共js/css库,图床。下面我们来逐个介绍一下。
3.1. Django 缓存
Django自带了一个较完善的缓存系统,用来对于一些频繁的请求或者占用资源的请求做一个缓存。我们这里的搜索课程接口就比较符合缓存的需求,主要原因有:搜索结果稳定,搜索过程在准备返回的json时会占用较多的资源(访问数据库,处理数据)。
Django缓存分为以下几种:Memcached、数据库、文件、本地内存以及GitHUb上的其他开源方法。具体部署可以自行谷歌或者参考这篇博客,部署过程比较简单。
在我们的实际应用中,考虑到本机磁盘空间较充足,读写速度可以接受,又不想多配置其他软件,我们使用了本地文件缓存的方式,并设置了缓存过期时间为15分钟。
关键代码如下:
settings.py:
CACHES = {
# 基于文件的缓存,基于其他的缓存参考上面的博客简单修改这段即可
# 在测试时,应该使用 dummy cache
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': YOUR_CACHE_DIR_PATH,
}
}
在每个需要缓存的view函数前面增加一个装饰器:
from django.views.decorators.cache import cache_page
@cache_page(15*60) # 15 minute
def xxx(request):
yyy
3.2. 数据库建表缓存
我们的获取评分排名接口是另一个比较占用资源的接口。由于我们的排名采取了一些科学的评分方法(详细),该算法执行一次时间随着评分条数增加而增加,有时需要2分钟左右,资源占用比上面的接口更加严重,而且如果是用户请求时再计算的话会导致网关超时,因此我们采用数据库建表的方式进行缓存。
我们通过一个定时任务(定时任务的使用方法可以参考教程),每两小时对课程,教师的排名进行一次更新,并将更新后的排名写入RankCache表。对于用户请求,直接在该表进行查表操作。这样就相当每两小时更新一次排名,用户查询的是最近一次更新的缓存。
关键代码如下:
settings.py增加:
CRONJOBS = [
('* */2 * * *', 'ratemycourse.view.rankcache.cronjob','>> django_crontab.log')
]
以及在installed app里添加
'django_crontab',
rankcache.py:
这里具体的排名算法可以参考上面的博客的实现
def cronjob():
a=Rankers() # 声明排名类
a.read_data() # 从数据库里获取评分信息
a.run_rank() # 计算评分
a.save_to_database() # 将评分写入数据库rancache表
3.3. 网页渲染逻辑
对于搜索结果页面,我们在alpha阶段简单的一次性渲染了整个网页,加载了所有课程的div,导致了渲染时间较长。现阶段我们改成了按需渲染,每次只渲染当前页面的几个课程信息,降低了渲染时间。
大致代码如下:
//2 获得到所要开始加载的课程序号
var course_to_show=(pagenum-1)*course_num_per_page;
//3 加载页码内容,使用adddiv
//将course_data清空
$("#course_data").html("");
for(var i = course_to_show;i < course_num && i < (course_to_show + course_num_per_page); i++){
//向course_data内插入
$("#course_data").append(adddiv(i));
}
3.4. CDN网站缓存
我们使用了cloudflare的免费套餐对网站进行了加速,基础配置流程十分简单,按照网站的步骤一步步做下来就行了。这里我们介绍一下我们针对我们的网站做的特殊调整。
3.4.1. page rule
page rule是cloudflare提供的一个较高级的功能,类似IFTTT,根据规则对部分URL做针对性的缓存选择,支持正则匹配。page rule是cloudflare的一个较高级的功能,免费套餐支持3条,虽然很少但是足够使用。操作方法类似下图,输入正则的网站地址,选择add a setting,再选择具体操作即可。
我们的配置如下:
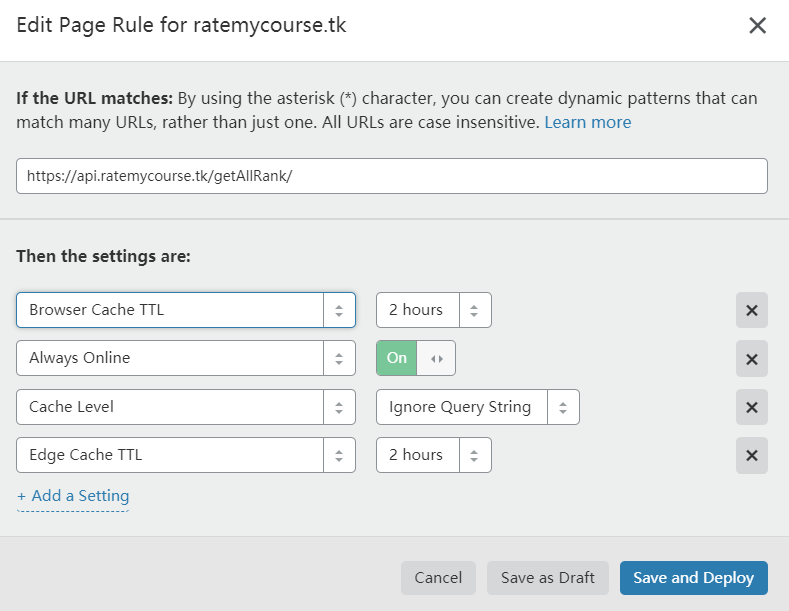
具体描述是:针对获得所有评分接口,设置浏览器缓存过期时间2h,设置CF edge节点缓存过期时间2h,忽略querystring进行缓存。
实际上这个接口也可以做成Django缓存,但是我们想尝试一下不同的缓存方式,因此我们采用了page rule。实际上采用page rule要略快一些,可能因为直接在edge节点就返回了缓存的信息,而不需要到达我们的服务器。
3.4.2. under attack mode
由于我们的网站曾经被攻击过,因此我们打开了under attack mode。这个开关可以针对请求用户的IP等信息,提供6种不同强度的js challenge,为网站提供防护。
3.4.3. 内容压缩
cloudflare可以对html,js,css进行压缩,减小传输数据的大小。此外,还可以启用Brotli,http2,Mirage,Mobile Redirect等新协议,算法,框架进一步压缩网站数据,加快传输速度。这些设置可以在控制台的speed选项卡中修改。
3.5. 公共js/css库
我们发现加载js,css,font也耗费了大量的时间。幸运的是,对于这些公共库,如jquery,bootstrap我们完全可以通过公共CDN进行加载,大幅提升这些文件的加载速度,节省服务器流量。经过调研,我们发现今日头条,七牛云等都提供了这方面的服务,例如:今日头条CDN,Staticfile CDN。
一个例子如下:
// 修改前
<link rel="stylesheet" href="./css/bootstrap.min.css" type="text/css">
// 修改后
<link rel="stylesheet" href="https://cdn.staticfile.org/twitter-bootstrap/4.0.0-beta.2/css/bootstrap.min.css" type="text/css">
对于网站的所有公共css,js都可以在上述CDN的搜索页面中找到,复制对应链接替换即可。
3.6. 公共图床
对于背景图片等,我们可以使用公共图床进行加速。我们使用了聚合图床,SM.MS 图床托管我们的图片,加快访问速度。操作方法与上面js,css类似。
聚合图床可以一次性提供多个备份,并在请求时自动选择一个返回,一般返回的是上传到阿里cdn或七牛云的图片,使用前需要注册,高级功能,如api,最大图片张数等需要收费方案。
SM.MS图床主要特点是免费,不需要注册就可任意上传(100张/分钟),提供api,支持ipv6。主服务器应该在香港,因此相较于聚合图床ipv4访问会慢一点,部分开会日期可能会比较缓慢,但是校园网ipv6访问一般很稳定。
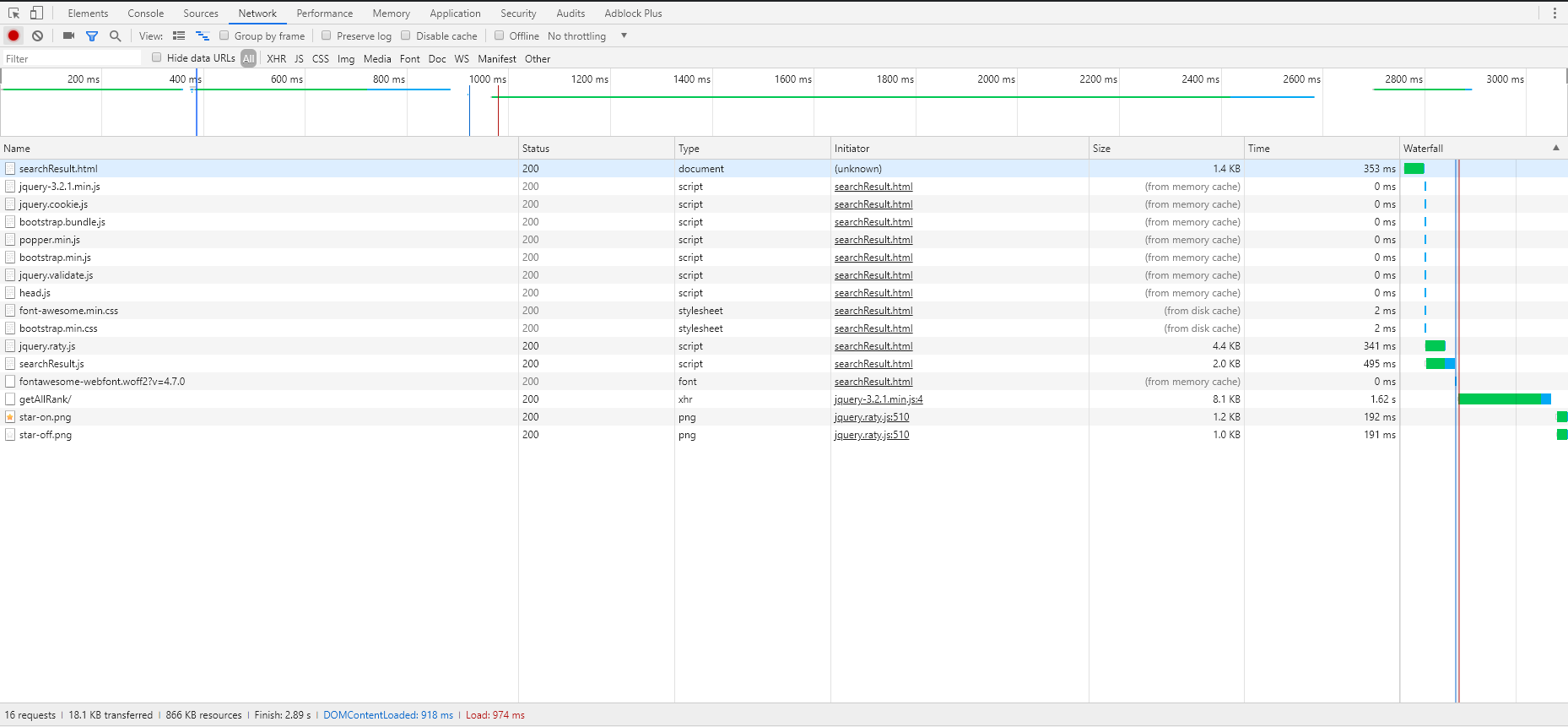
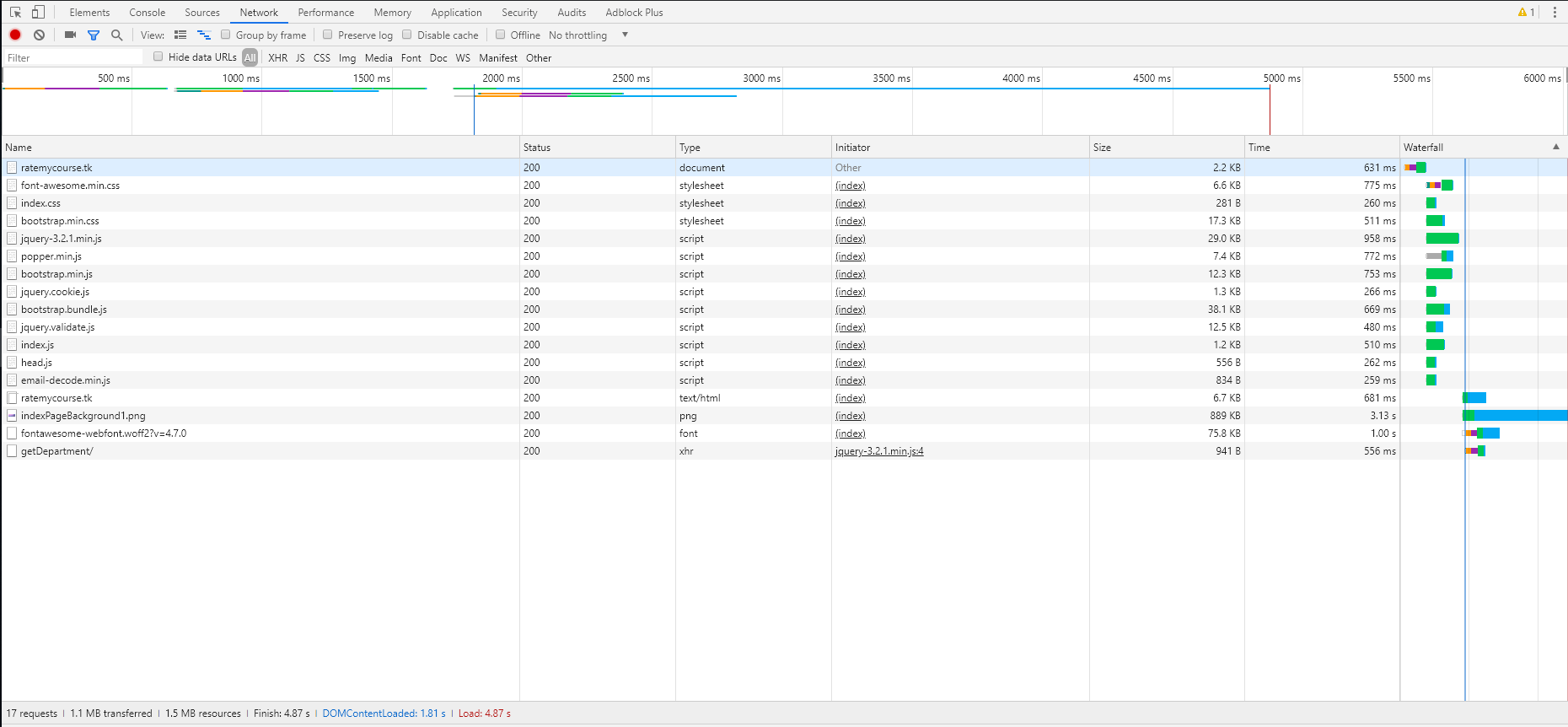
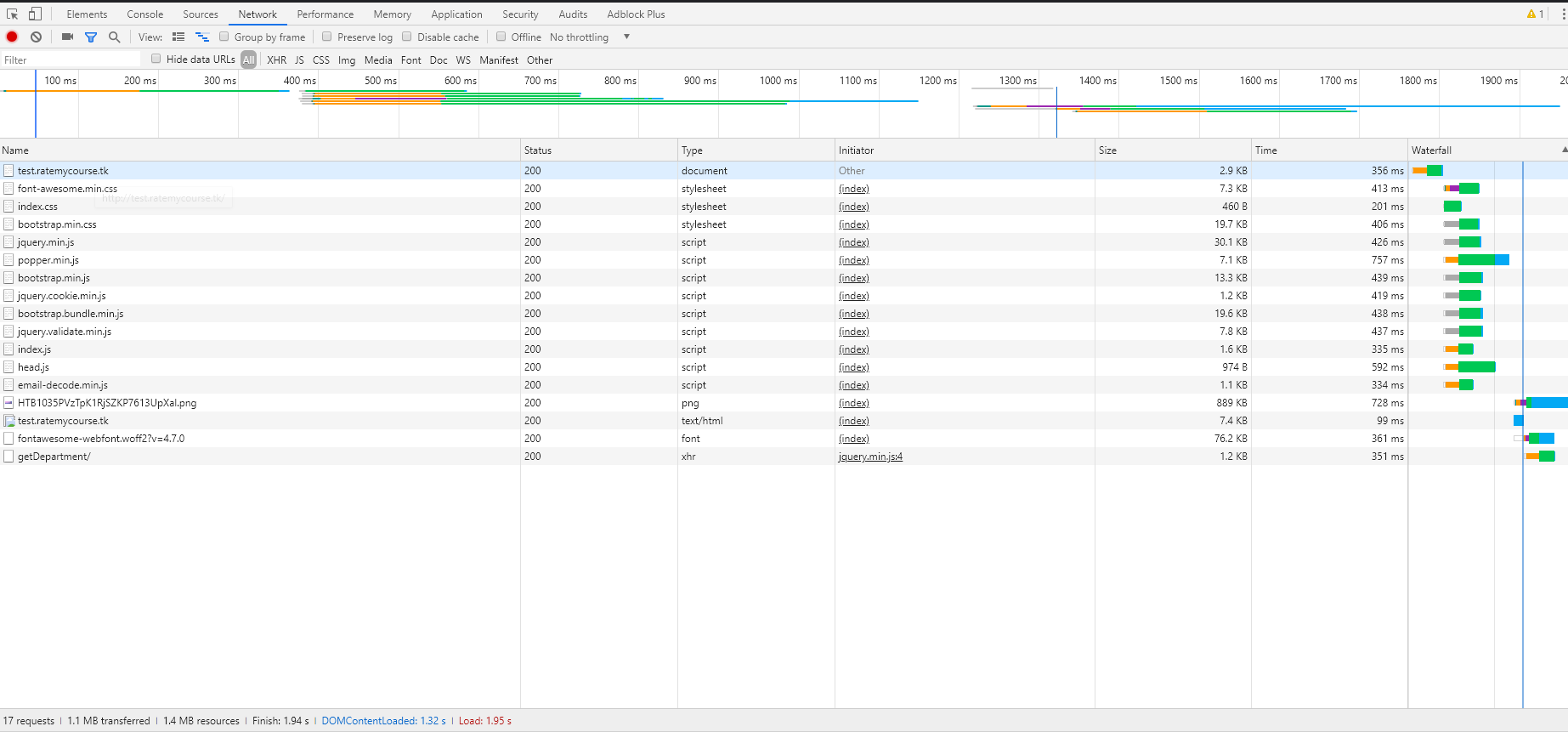
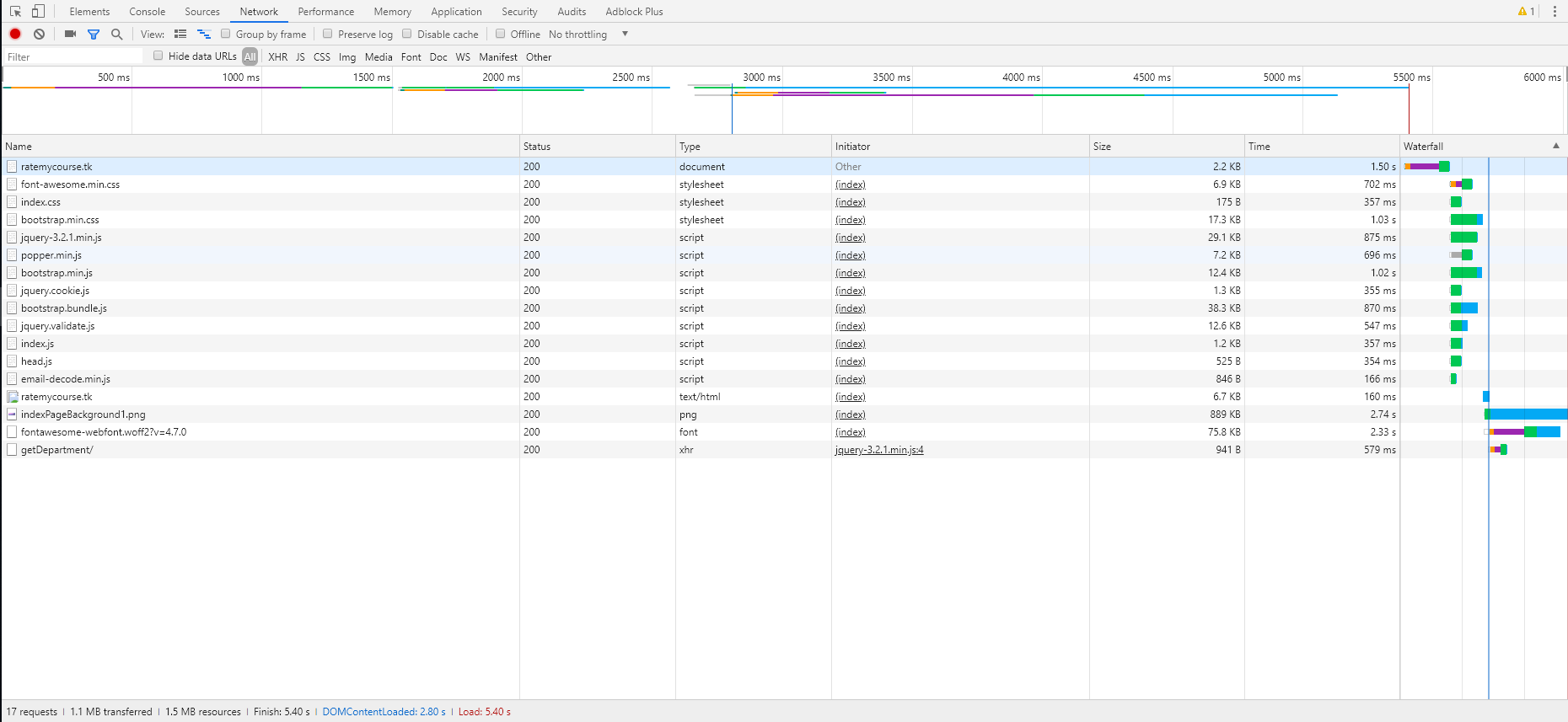
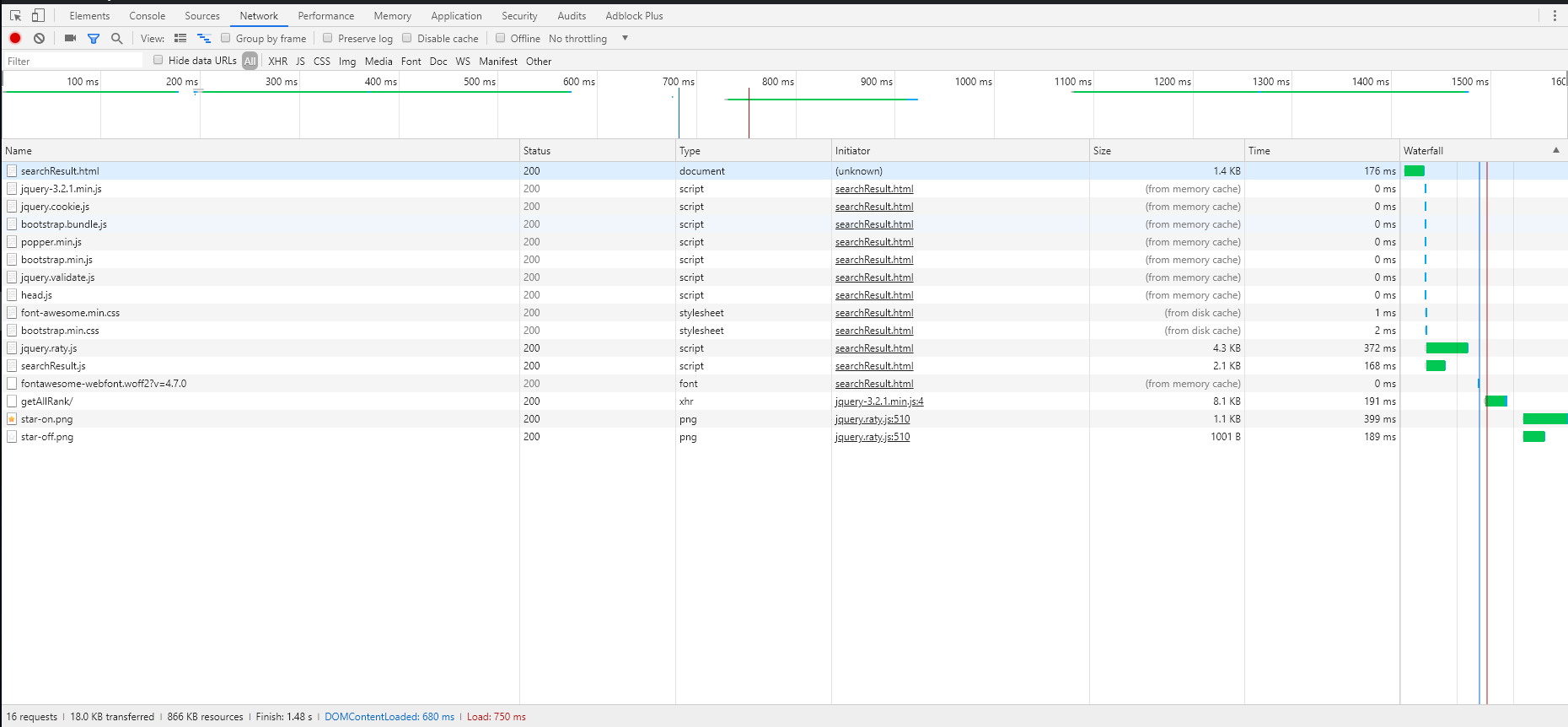
4. 加速效果
在使用了以上的方法后,我们的网页加载速度有了大幅度的提升。我们对比了alpha网页,alpha+CDN和beta(上述所有方法),效果如下:
| 首页 | 全部课程 | 随机搜索 | |
|---|---|---|---|
| alpha-CDN | 4.87s | 8.77s | 1.83s |
| alpha-no CDN | 5.4s | 15.76s | 2.89s |
| beta | 1.94s | 1.25s | 1.48s |
蓝色的是原始加载时间,橙色的是仅使用CDN的时间,灰色的是应用上述所有方法的加载时间。
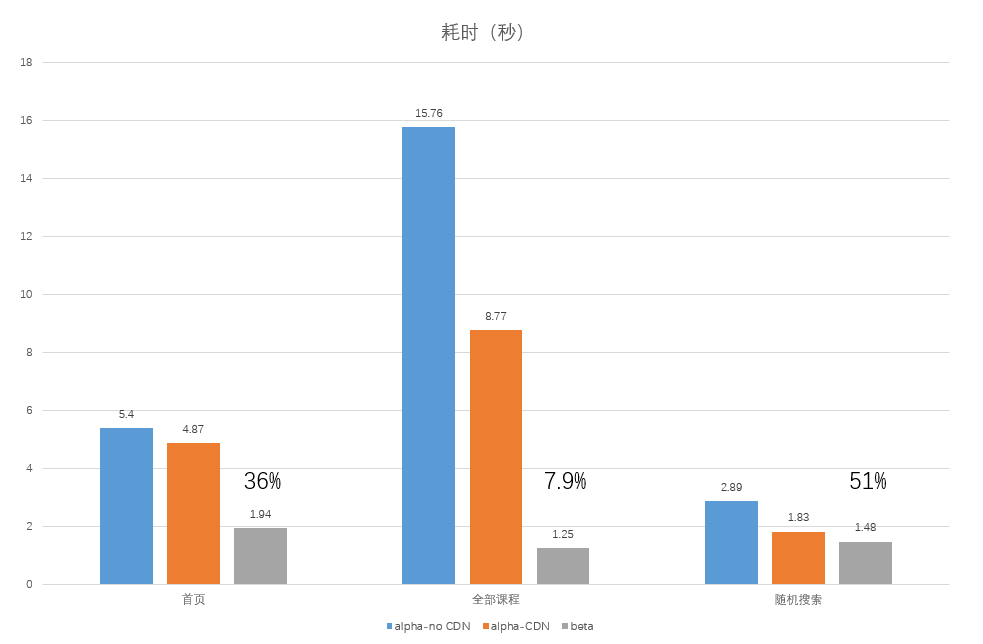
可见,所有页面都有较大幅度的提升。
所有页面的瀑布图如下,顺序分别为alpha-no CDN,alpha-CDN,beta:
[技术博客]使用CDN加快网站访问速度的更多相关文章
- Apache 使用gzip、deflate 压缩页面加快网站访问速度
Apache 使用gzip 压缩页面加快网站访问速度 介绍: 网页压缩来进一步提升网页的浏览速度,它完全不需要任何的成本,只不过是会让您的服务器CPU占用率稍微提升一两个百分点而已或者更少. 原理 ...
- 【转】加快网站访问速度——Yslow极限优化
Yslow是一套雅虎的网页评分系统,详细的列出了各项影响网页载入速度的参数,这里不做多说. 我之前就一直参考Yslow做博客优化,经过长时间的学习也算是有所收获,小博的YslowV2分数达到了94分( ...
- 2-12-配置squid代理服务器加快网站访问速度
本节所讲内容: squid服务器常见概念 squid服务器安装及相关配置文件 实战:配置squid正向代理服务器 实战:配置透明squid代理提升访问速度 实战:配置squid反向代理加速度内网web ...
- 欢迎访问我的最新个人技术博客http://zhangxuefei.top
博客园已停止更新,欢迎访问我的最新个人技术博客http://zhangxuefei.top
- 欢迎访问我的最新个人技术博客http://zhangxuefei.site
博客已经搬家,欢迎访问我的最新个人技术博客:http://zhangxuefei.site
- [技术博客] Django中文件的保存与访问
[技术博客] Django中文件的保存与访问 在TextMarking项目开发中,数据库需要保存用户上传的文本文档. 原型设计:用户点击上传文本->保存文本->文本发送到后端保存为文件. ...
- [置顶] 创建GitHub技术博客全攻略
[置顶] 创建GitHub技术博客全攻略 分类: GitHub2014-07-12 13:10 19710人阅读 评论(21) 收藏 举报 githubio技术博客网站生成 说明: 首先,你需要注册一 ...
- 创建GitHub技术博客
创建GitHub技术博客全攻略 githubio技术博客网站生成 说明: 首先,你需要注册一个 github 账号,最好取一个有意义的名字,比如姓名全拼,昵称全拼,如果被占用,可以加上有意义的数字.本 ...
- 一文搞定scrapy爬取众多知名技术博客文章保存到本地数据库,包含:cnblog、csdn、51cto、itpub、jobbole、oschina等
本文旨在通过爬取一系列博客网站技术文章的实践,介绍一下scrapy这个python语言中强大的整站爬虫框架的使用.各位童鞋可不要用来干坏事哦,这些技术博客平台也是为了让我们大家更方便的交流.学习.提高 ...
随机推荐
- rabbitmq:配置rabbitmq-management插件
rabbitmq提供了一个图形的管理界面,用于管理.监控rabbitmq的运行情况,它是以插件的形式提供的,如果要启用需要启用插件 一.启用插件 rabbitmq-plugins enable rab ...
- OCR1:开源库
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然后用字符识别方法将形状翻译 ...
- php mysql 按照指定年月查找数据 数据库create_time为时间戳
$moneyloglist = MoneyLog::where(['user_id' => $this->auth->id]) ->where($where) ->whe ...
- 【爬虫】Condition版的生产者和消费者模式
Condition版的生产者和消费者模式 threading.Condition 在没有数据的时候处于阻塞状态,有数据可以使用notify的函数通知等等待状态的线程运作 threading.Condi ...
- Django之auth认证
Auth模块是Django自带的用户认证模块: 我们在开发一个网站的时候,无可避免的需要设计实现网站的用户系统.此时我们需要实现包括用户注册.用户登录.用户认证.注销.修改密码等功能,这还真是个麻烦的 ...
- [加密]非对称加密STM32实现
转自:https://blog.csdn.net/kangerdong/article/details/82432701 把所有的准备工作都做完了以后,可以将加密算法移植到我们具体的项目中去了,在ST ...
- cobbler部署错误总结
web 报错500 Internal Server Error解决方案 在安装使用Cobbler web界面的时候提示HTTP 500错误,也就是服务器内部错误,检查防火墙和selinux都是为关闭状 ...
- 版本问题---keras和tensorflow的版本对应关系
keras和tensorflow的版本对应关系,可参考: Framework Env name (--env parameter) Description Docker Image Packages ...
- PAT 乙级 1012.数字分类 C++/Java
题目来源 给定一系列正整数,请按要求对数字进行分类,并输出以下 5 个数字: A1 = 能被 5 整除的数字中所有偶数的和: A2 = 将被 5 除后余 1 的数字按给出顺序进行交错求和, ...
- Android开发学习了这些,上帝都淘汰不了你
曾听过很多人说Android学习很简单,做个App就上手了,工作机会多,毕业后也比较容易找工作.这种观点可能是很多Android开发者最开始入行的原因之一. 在工作初期,工作主要是按照业务需求实现Ap ...