Use of Time-series Based Forecasting Technique for Balancing Load and Reducing Consumption of Energy in a Cloud Data Center
年份:2017
摘要:
由于工作负载分配不均,一些服务器变得过载,而另一些服务器仍处于欠载状态。 为了实现负载平衡,需要从过度使用的节点迁移一些虚拟机。 但是与此不同的是,本文提出了一种负载预测算法,该算法将根据系统的当前以及将来的工作量来决定是否迁移。 因此,一旦声明节点过载,我们提出的技术就不会立即启动虚拟机迁移。 我们的算法已在CloudSim中进行了仿真,并将其性能与现有的基准算法进行了比较。 结果证明,所提出的技术不仅使数据中心更节能,而且更有效地平衡了工作量。
介绍
当前的大多数研究工作[5-12]基于系统的当前利用率。 如果服务器当前过载,则VM迁移将立即启动[7]。 但是由于迁移的开销,不必要的VM迁移可能会导致违反SLA。 结果,每次VM迁移都会增加运营成本。 因此,问题在于确定何时应开始迁移,以使与SLA违规和额外能耗有关的成本降至最低。 为此,提出了一种基于时间序列的负载预测方法,该方法决定了VM迁移的决策。 当主机的利用率水平超过动态上限时,该主机将被声明为过度利用。 如果服务器现在过载,并且下一个预测的负载也大于动态上限,则将进行迁移。 负载预测模型使我们的算法能够成功减少VM迁移的数量,并通过提供绿色IT解决方案来节省能源。
相关工作
动态比较和平衡算法(DCABA)算法使用了两个云优化概念。 首先是在物理机器级别上优化云系统,其次是根据用户应用程序的行为使用自适应阈值对其进行优化[13]。当节点的负载大于预定义的上阈值时,该节点被视为过度使用。 因此,算法会将此主机的额外负载转移到另一台主机。 这是通过自适应比较和平衡负载平衡方法执行的。 在这里,选择另一台主机的概率为p [k],该主机具有可以接受此负载而不会变得过载的最小虚拟机。当主机负载低于预定义的下限阈值时,则声明为负载不足。 因此,应用服务器整合算法将该主机的负载转移到另一台计算机,并且关闭源计算机以节省能源并降低云的运营成本。 放置迁移后的VM的目标主机不得过载。 与DCABA不同,我们提出的算法基于动态上限阈值
在[14]中,作者已经通过使用负载预测模型准确地预测了应用程序的未来资源使用情况。 但是他们仅在动态虚拟机整合中使用了此方法。 如果未充分利用的服务器的预计负载很高,则将不会进行VM迁移。 它减少了VM迁移的数量和过载节点的数量。 与[14]不同,我们使用负载预测模型来确定是否从过载节点迁移。
Khanna等。 [15]监视物理机和虚拟机的资源(CPU和内存)。 他们提出了固定阈值的想法,这将限制资源的最大利用。 如果资源超过预定义的阈值,并且有可能违反SLA,则系统会将VM迁移到另一台物理计算机。 与此不同,我们提出的方法使用动态阈值和负载预测模型的概念来决定迁移。
在[8]安东等。 已经提出了用于将虚拟机节能映射到合适的物理机的算法。 作者认为,保持工作阈值不变是不明智的决定,因为工作负荷在不断变化。 在[7]中,作者提出了IQR(四分位间距),MAD(中值绝对偏差)和LR(局部回归)方法来动态地找到主机的自适应上限阈值。 在云环境中,动态阈值的概念远远优于静态阈值。 但是,在启动迁移时,作者只专注于当前负载,因此有时由于负载的瞬时峰值会发生不必要的迁移,在我们建议的工作中,考虑服务器的当前以及未来负载可以将这种迁移降至最低。 我们已使用基于时间序列的预测技术来根据过去的数据计算服务器的未来利用率。
在[16]中,作者提出了一个名为Sandpiper的系统,该系统可以自动进行热点检测并确定虚拟到物理资源的新映射,并在虚拟化数据中心内启动必要的迁移。为了确保一个小的临时峰值不会引发不必要的迁移,如果持续时间内超过阈值,则会发出热点信号。仅当n个最近的观测值中至少k个且下一个预测值超过阈值时才发生迁移。作者考虑的阈值是静态的。作者在这里使用自动回归方法来计算下一个预测值。检测到热点后,将迁移其卷体积比(VSR)最大的VM。当系统的整体负载很高时,移动具有最高VSR的VM是不可行的。因此,为减少热点,虚拟机被交换了。但是,此过程在高峰时段无法高效运行,因为交换虚拟机不必要地增加了迁移开销。与[16]不同,我们在提出的方法中提出了动态阈值。简单指数技术和双指数技术用于预测系统的未来负载.
诺曼(Norman)等人。 在[18]中,已经开发了一种用于将VM动态分配给物理服务器的管理算法。 该算法包括三个步骤:i)测量历史数据,ii)预测未来需求,并且iii)将VM重新映射到PM,因此被称为Measure-Forecast-Remap(MFR)。 结合了装箱启发式和基于时间序列的预测技术,以减少支持工作负载所需的物理机数量。 在该算法中,使用预测方法找到单个VM的资源需求。 根据预测值,VM以非递增顺序排列。 然后,使用首选拟合试探法迁移VM。 我们提出的算法使用预测的负载来从过度使用的节点中进行迁移决策。
预测方法
我们提出的方法将根据使用时间序列预测技术预测的当前和将来负载来决定是否确实需要迁移VM。 时间序列是一系列数据点,由一个时间段[17]上的连续测量组成。 借助时间序列预测模型,可以基于历史数据预测未来值。 指数平滑技术是一种特殊类型的加权移动平均值方法,已应用于时间序列数据.在移动平均线中,所有过去的数据都具有同等的重要性。 但是有时最好优先考虑最近的观察结果.这是通过对数据分配不同的权重来实现的,它是加权移动平均法,因此,与旧观测值相比,最新观测值对预测值的影响更大。 以下公式显示了指数平滑技术的最简单形式:


在我们提出的方法{x1,x2«[t-1}中,该集合包含在持续时间t的过去时间间隔内物理主机的总CPU利用率历史记录。 它实际上是该主机上运行的所有活动VM的CPU利用率的总和。 {s1,s2……st-1}是相应的CPU利用率预测值。 使用以下公式从这组值中计算出MSE(均方误差):
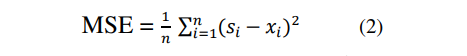
当数据遵循某种趋势时,简单的指数平滑将无法产生最佳结果[19]。 为了处理这种情况,使用了“双指数平滑”或“二阶指数平滑”方法。 “ Holt-Winters双指数平滑”就是这样一种技术。 它的工作原理几乎与简单平滑类似,不同的是每个阶段都必须更新两个组件-水平和趋势[19]。 级别给出了数据值的平滑估计,趋势是每个周期结束时平均增长的平滑估计。 使用的公式是:
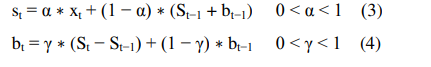
其中γ 是趋势平滑因子,0 <γ <1 并且α与之前相同。 {st}和{xt}与简单的平滑技术相同。 {bt}是在时间t处趋势的最佳估计。 该算法的输出即Ft + m,即在时间t + m,m> 0时x的估计值是:
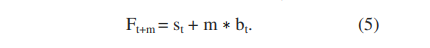
存在几种方法来选择St和bt的初始值。 通常,s1设置为x1。 b1的三个可能值是:
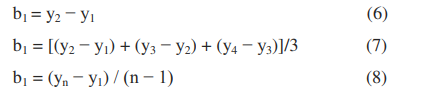
我们提出的算法不直接使用预测值。 而是用来决定迁移的关键决定。 因此,我们算法的效率并不直接取决于预测的准确性,而是取决于有关迁移的决策的准确性。
4 PROPOSED WORK
VM迁移问题可分为三个部分:I)何时迁移II)迁移哪个VM以及III)迁移到哪里[26]。 我们提出的方法处理迁移的第一个问题。


上述算法将主机作为输入,并给出迁移决定(第1行)。该决定基于动态上限阈值策略。在此策略中,如果主机的利用率高于上限,则将其声明为过度使用。中位数绝对偏差(MAD)技术用于查找上限阈值(第5行),如[7]中所述。阈值随着工作量的变化而动态变化。提议的方法首先将当前的CPU利用率(在第3行中计算)与上限阈值进行比较,类似于传统方法(第6行)。如果主机没有被过度利用,那么迁移将不会发生,并且现有流程不会发生任何变化。但是,如果主机被声明为过载,并且我们至少有10个旧的CPU利用率数据,则与传统流程不同,未来的CPU利用率是使用基于时间序列的预测模型(第9行)来计算的。简单和双指数平滑技术(SES和DES)。为了正确地预测未来价值,必须将足够的过去数据传递给预测技术。在这里,我们采用了通过实验找到的最小数据长度10。在[7]中,作者使用最小数据长度作为12来计算MAD。在我们的实验中,我们发现该算法在数据长度为10的情况下效果很好。他们使用数据长度为10的数据通过局部回归方法预测了未来的负荷。如果预测的CPU使用率高于上限(第10行),则主机将包括在过度使用的节点列表中(第11行),并且将进行迁移。否则,将不会发生迁移,因为预计在不久的将来主机将不会保持过载。因此,可以在短时间内以违反SLA的代价减少迁移数量。
5. 性能分析
本节将分析我们提出的算法的性能。 在像云这样的高度动态的环境中,很难以可重复和可靠的方式进行实验。 这就是为什么我们选择Cloudsim仿真工具[20]来测试我们的算法,然后再将它们部署到真实的云中。
A.环境安装
我们的算法使用了[7]中提出的动态上限阈值的概念。 因此,为了比较它们的性能,此处使用了[7]的实验设置。
B.工作量数据
使用Bitbrains工作负载跟踪[21]进行了实验。 所使用的数据来自代表业务关键型企业应用程序的Bitbrains托管中心的500个VM的CPU使用率。 每隔5分钟测量一次数据。 详细的工作负载特征在[21]中。
C.性能计量
为了将我们提出的算法与现有算法的性能进行比较,我们选择了四个参数:物理资源的总能耗,发生的VM迁移的总数,过度使用的节点的总数以及SLA违规百分比,这些百分比描述了分配的次数 资源少于所需的资源。
D.仿真结果
我们已经将我们提出的方法的性能与文献[7]中提出的算法之一进行了比较。 此方法使用中位数绝对偏差(MAD)技术来找到动态上限阈值。 与我们的方法相反,它在主机被声明为过载时立即启动迁移。 该算法已在Cloudsim中实现。 我们使用两种预测方法来模拟我们的算法。 简单指数平滑技术(SES)和双指数平滑技术(DES)。
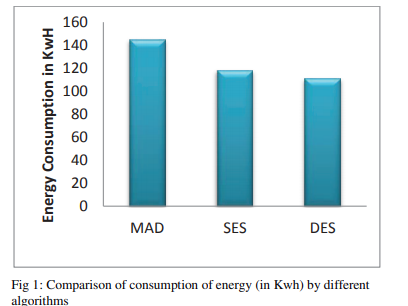
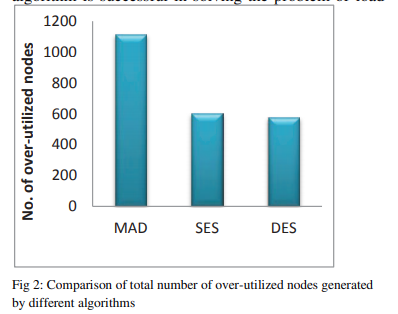
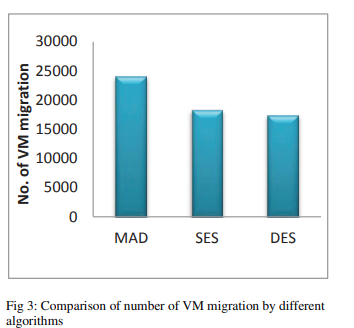
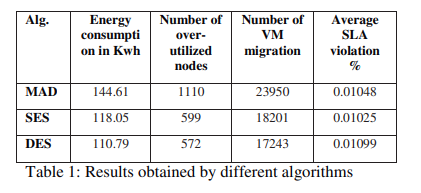
图1比较了上述三种技术的能耗(单位:千瓦)。 表1显示,能源消耗随着迁移数量的减少而减少。 减少幅度从18.36%到23.39%。 图2比较了生成的过度利用节点的总数。 SES显示最小减少量为46.03%,而DES最大减少量为48.47%。 过载节点数量的减少证明了我们的基于预测的算法成功解决了负载平衡问题。 图3显示VM迁移数量最多减少了28.00%。 由于我们根据当前以及将来的负载来决定迁移,因此根据预测算法的准确性,可以将因CPU利用率的瞬时提高而产生的迁移最小化。 反过来,它将减少迁移的总数。
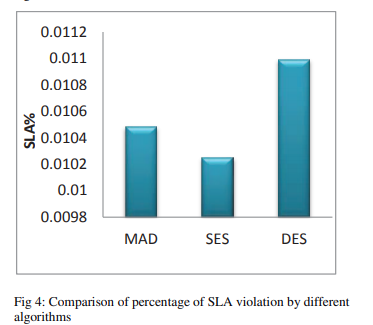
过度的迁移会降低系统的整体性能。 因此,迁移的数量应满足服务质量(QoS)要求,同时迁移开销要少。 SES能够产生最佳的迁移数量,从而将平均违反SLA的情况降低2.19%。 但是DES将违反SLA的百分比提高了4.86%。 因此,要在能耗和性能之间进行权衡。
结论和将来的工作
从以上讨论可以得出结论,我们提出的方法比采取立即迁移决策的方法性能更好。 我们已经成功降低了能耗,但是在性能方面还有一定的改进空间。 从环境的角度来看,所提出的算法是更好的,因为最小的能源消耗将减少冷却系统的成本和二氧化碳的排放。 根据服务质量要求,提供商可以选择任何算法。
Use of Time-series Based Forecasting Technique for Balancing Load and Reducing Consumption of Energy in a Cloud Data Center的更多相关文章
- 10 Best TV Series Based On Hacking And Technology
Technology is rapidly becoming the key point in human lives. Here we have discussed top TV shows whi ...
- Paper: A novel method for forecasting time series based on fuzzy logic and visibility graph
Problem Forecasting time series. Other methods' drawback: even though existing methods (exponential ...
- CNCF CloudNative Landscape
cncf landscape CNCF Cloud Native Interactive Landscape 1. App Definition and Development 1. Database ...
- CNCF LandScape Summary
CNCF Cloud Native Interactive Landscape 1. App Definition and Development 1. Database Vitess:itess i ...
- ARVE: Augmented Reality Applications in Vehicle to Edge Networks
ARVE:车辆到边缘网中的增强现实应用 本文为SIGCOMM 2018 Workshop (Mobile Edge Communications, MECOMM)论文. 笔者翻译了该论文.由于时间仓促 ...
- SSL加速卡调研的原因及背景
SSL加速卡调研的原因及背景 SSL加速卡调研的原因及背景 网络信息安全已经成为电子商务和网络信息业发展的一个瓶颈,安全套接层(SSL)协议能较好地解决安全处理问题,而SSL加速器有效地提高了网络安全 ...
- Distributed Management Task Force----分布式管理任务组
http://baike.baidu.com/link?url=Y9HGLs8Qj6pXbbgY6xPdfiGDsQO8Eu1e80B4giQtQ_hAfGNF59byxnLoERYri4Duw7Gw ...
- top 9 Cloud Computing Failures
top 9 Cloud Computing Failures Outages, hacks, bad weather, human error and other factors have led t ...
- An overview of time series forecasting models
An overview of time series forecasting models 2019-10-04 09:47:05 This blog is from: https://towards ...
随机推荐
- 使用Prometheus针对自己的服务器采集自定义的参数
用一个简单的例子来说明. 我用express和http搭了一个最简单的服务器,监听在8081端口上. 在metrics endpoint上,我会打印出这个服务器从启动至今,服务了多少次请求.这里我只是 ...
- linux上SVN出现 "Unable to connect to a repository at URL 'svn://xx.xx.xx.xx/xxx' 和 No repository ...
centos上安装了svn, 有时候会不知道什么原因出现客户端小乌龟无法连接或无法提交等情况. 1. 万能重启,xshell连接服务器,输入 service svnserve restart 命令. ...
- scrapy文件管道
安装scrapy pip install scrapy 新建项目 (python36) E:\www>scrapy startproject fileDownload New Scrapy pr ...
- 【故障处理】ORA-19809错误处理
[故障处理]ORA-19809错误处理 一.1 BLOG文档结构图 一.2 前言部分 一.2.1 导读和注意事项 各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它 ...
- PHP Lumen Laravel 解决validate方法自定义message无效的问题
/** * 由于 \Laravel\Lumen\Routing\ProvidesConvenienceMethods::validate 在验证不通过时, * 抛出 \Illuminate\Valid ...
- MySQL-查看DB文件位置
show global variables like "%datadir%"
- linux系统信息获取和上报
通过调用shell命令获取系统信息,如cpu个数,cpu/内存磁盘使用情况,网络信息等. #include <stdio.h> #include <stdlib.h> #inc ...
- 关于sql注入盲注,谈谈自己的心得
1.没做防御的站点,拿上sqlmap直接怼就行了. 2.做了防御,有的用函数过滤了,有的用了waf(比如安全狗,云锁,华为云waf,360waf,知道创宇盾,护卫神等等) 这些就相当麻烦了,首先要探测 ...
- beta版本——第三次冲刺
第三次冲刺 (1)SCRUM部分☁️ 成员描述: 姓名 李星晨 完成了哪个任务 认证学校那一栏增加检测机制的ui设计 花了多少时间 1h 还剩余多少时间 1h 遇到什么困难 没有困难 这两天解决的进度 ...
- dt框架自定义url规则
destoon的列表的地址规则是定义在/api/url.inc.php,然后又是在include/global.func.php中进行的listpages这个函数调用实现 if($page < ...