(转载)ranger原理
文章目录
一、业务背景
大数据集群最基本的就是数据以及用于计算的资源,是一个公司的宝贵财富,我们需要将它们很好管理起来,将相应的数据和资源开放给对应的用户使用,防止被窃取、被破坏等,这就涉及到大数据安全。
现状&&需求
目前我们大数据集群的现状是处于裸奔状态,只要可以登录linux机器即可对集群继续相关操作
所以集群安全对于我们来说迫在眉睫,主要需求有以下几个方面:
- 支持多组件,最好能支持当前公司技术栈的主要组件,HDFS、HBASE、HIVE、YARN、STORM、KAFKA等
- 支持细粒度的权限控制,可以达到HIVE列,HDFS目录,HBASE列,YARN队列,STORM拓扑,KAKFA的TOPIC
- 开源,社区活跃,按照现有的集群改情况造改动尽可能的小,而且要符合业界的趋势。
二、大数据安全组件介绍与对比
目前比较常见的安全方案主要有三种:
- Kerberos(业界比较常用的方案)
- Apache Sentry(Cloudera选用的方案,cdh版本中集成)
- Apache Ranger(Hortonworks选用的方案,hdp发行版中集成)
1、Kerberos
Kerberos是一种基于对称密钥的身份认证协议,它作为一个独立的第三方的身份认证服务,可以为其它服务提供身份认证功能,且支持SSO(即客户端身份认证后,可以访问多个服务如HBase/HDFS等)。
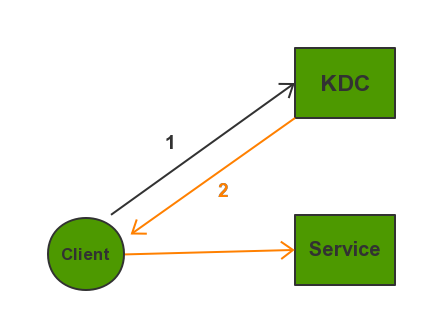
| 服务名 | 作用 |
|---|---|
| KDC | Kerberos的服务端程序,用于验证各个模块 |
| Client | 需要访问服务的用户,KDC和Service会对用户的身份进行认证 |
| Service | 即集成了Kerberos的服务,如HDFS/YARN/HBase等 |
Kerberos协议过程主要有三个阶段,第一个阶段Client向KDC申请TGT,第二阶段Client通过获得的TGT向KDC申请用于访问Service的Ticket,第三个阶段是Client用返回的Ticket访问Service。
优点:
服务认证,防止broker datanode regionserver等组件冒充加入集群
解决了服务端到服务端的认证,也解决了客户端到服务端的认证
缺点:
kerberos为了安全性使用临时ticket,认证信息会失效,用户多的情况下重新认证繁琐
kerberos只能控制你访问或者拒绝访问一个服务,不能控制到很细的粒度,比如hdfs的某一个路径,hive的某一个表,对用户级别上的认证并没有实现(需要配合LDAP)
2、Apache Sentry
Apache Sentry是Cloudera公司发布的一个Hadoop安全开源组件,它提供了细粒度级、基于角色的授权.

优点:
Sentry支持细粒度的hdfs元数据访问控制,对hive支持列级别的访问控制
Sentry通过基于角色的授权简化了管理,将访问同一数据集的不同特权级别授予多个角色
Sentry提供了一个统一平台方便管理
Sentry支持集成Kerberos
缺点:
- 组件只支持hive,hdfs,impala 不支持hbase,yarn,kafka,storm等
3、Apache Ranger
Apache Ranger是Hortonworks公司发布的一个Hadoop安全组件开源组件
优点:
- 提供了细粒度级(hive列级别)
- 基于访问策略的权限模型
- 权限控制插件式,统一方便的策略管理
- 支持审计日志,可以记录各种操作的审计日志,提供统一的查询接口和界面
- 丰富的组件支持(HDFS,HBASE,HIVE,YARN,KAFKA,STORM)
- 支持和kerberos的集成
- 提供了Rest接口供二次开发
4、为什么我们选择Ranger
- 多组件支持(HDFS,HBASE,HIVE,YARN,KAFKA,STORM),基本覆盖我们现有技术栈的组件
- 支持审计日志,可以很好的查找到哪个用户在哪台机器上提交的任务明细,方便问题排查反馈
- 拥有自己的用户体系,可以去除kerberos用户体系,方便和其他系统集成,同时提供各类接口可以调用
综上:我们考虑到和开放平台的集成,以及我们的技术栈和集群操作的审计等几个问题最终选用了apache ranger
三、Apache Ranger系统架构及实践
1、架构介绍

2、组件介绍
- RangerAdmin
以RESTFUL形式提供策略的增删改查接口,同时内置一个Web管理页面。
- Service Plugin
嵌入到各系统执行流程中,定期从RangerAdmin拉取策略,根据策略执行访问决策树,并且记录访问审计
| 插件名称 | 安装节点 |
|---|---|
| Hdfs-Plugin | NameNode |
| Hbase-Plugin | HMaster+HRegionServer |
| Hive-Plugin | HiveServer2 |
| Yarn-Plugin | ResourceManager |
- Ranger-SDK
对接开放平台,实现对用户、组、策略的管理
3、权限模型
访问权限无非是定义了”用户-资源-权限“这三者间的关系,Ranger基于策略来抽象这种关系,进而延伸出自己的权限模型。”用户-资源-权限”的含义详解:
用户
由User或Group来表达,User代表访问资源的用户,Group代表用户所属的用户组。
资源
不同的组件对应的业务资源是不一样的,比如
- HDFS的FilePath
- HBase的Table,Column-family,Column
- Hive的Database,Table,Column
- Yarn的对应的是Queue
权限
由(AllowACL, DenyACL)来表达,类似白名单和黑名单机制,AllowACL用来描述允许访问的情况,DenyACL用来描述拒绝访问的情况,不同的组件对应的权限也是不一样的。
| 插件 | 权限项 |
|---|---|
| Hdfs | Read Write Execute |
| Hbase | Read Write Create Admin |
| Hive | Select Create Update Drop Alter Index Lock Read Write All |
| Yarn | submit-app admin-queue |
4、权限实现
Ranger-Admin职责:
- 管理员对于各服务策略进行规划,分配相应的资源给相应的用户或组,存储在db中
Service Plugin职责:
- 定期从RangerAdmin拉取策略
- 根据策略执行访问决策树
- 实时记录访问审计
策略执行过程:
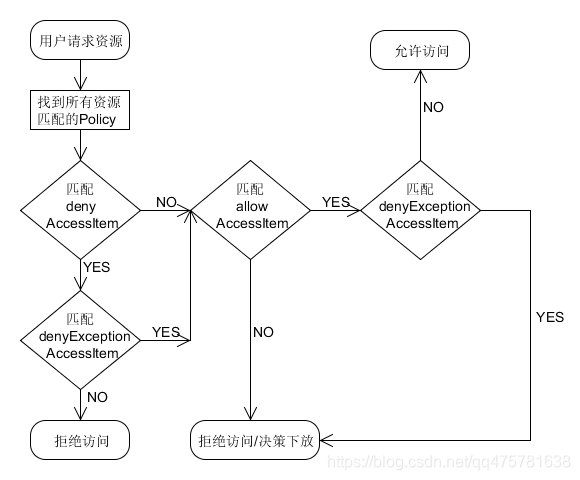
策略优先级:
- 黑名单优先级高于白名单
- 黑名单排除优先级高于黑名单
- 白名单排除优先级高于白名单
决策下放:
如果没有policy能决策访问,一般情况是认为没有权限拒绝访问,然而Ranger还可以选择将决策下放给系统自身的访问控制层
组件集成插件原理:
| Service | Extensible Interface | Ranger Implement Class |
|---|---|---|
| HDFS | org.apache.hadoop.hdfs.server.namenode.INodeAttributeProvider | org.apache.ranger.authorization.hadoop.RangerHdfsAuthorizer |
| HBASE | org.apache.hadoop.hbase.protobuf.generated.AccessControlProtos.AccessControlService.Interface | org.apache.ranger.authorization.hbase.RangerAuthorizationCoprocessor |
| Hive | org.apache.hadoop.hive.ql.security.authorization.plugin.HiveAuthorizerFactory | org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizerFactory |
| YARN | org.apache.hadoop.yarn.security.YarnAuthorizationProvider | org.apache.ranger.authorization.yarn.authorizer.RangerYarnAuthorizer |
ranger通过实现各组件扩展的权限接口,进行权限验证
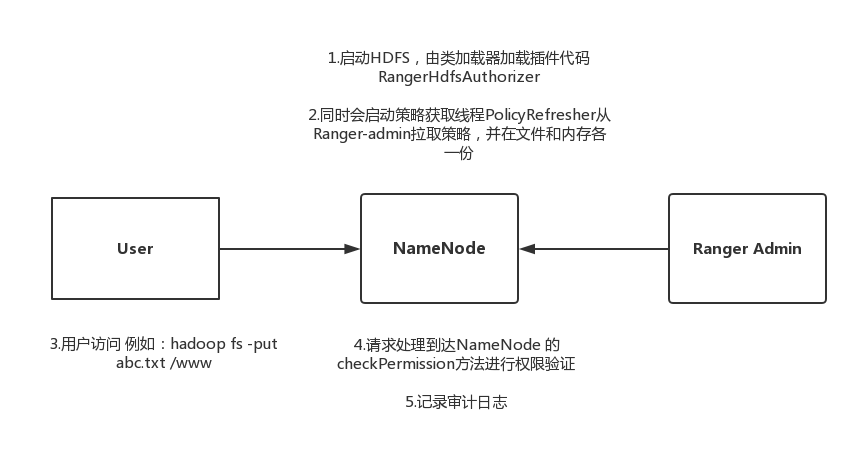
Hdfs实现原理
hdfs-site.xml会修改如下配置:
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.inode.attributes.provider.class</name>
<value>org.apache.ranger.authorization.hadoop.RangerHdfsAuthorizer</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
加载过程:
Hbase实现原理
在安装完hbase插件后,hbase-site.xml会修改如下配置:
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.ranger.authorization.hbase.RangerAuthorizationCoprocessor</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.ranger.authorization.hbase.RangerAuthorizationCoprocessor</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
加载过程:

Hive实现原理
hiveserver2-site.xml
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizerFactory</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
加载过程:

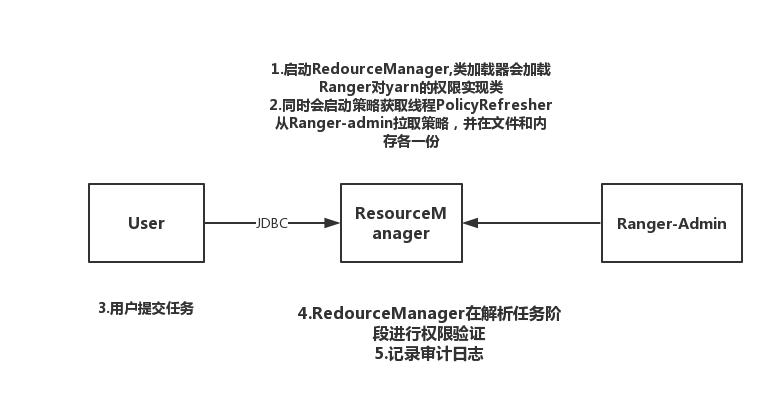
Yarn实现原理
yarn-site.xml
<property>
<name>yarn.acl.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.authorization-provider</name>
<value>org.apache.ranger.authorization.yarn.authorizer.RangerYarnAuthorizer</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
加载过程:
四、Ranger实践
1、组权限实现
由于在调用各服务过程中使用hdfs shell、hbase-shell、hive-jdbc只能获取到用户信息,在只有组策略时会匹配不成功,认为没有权限,实现办法是加入ldap组件同步用户组信息,这样增加了系统的复杂性,我们通过改写ranger-admin代码,在客户端plugin获取策略时,将组权限赋予用户,这样就实现了组策略功能。
原文:https://blog.csdn.net/qq475781638/article/details/90247153#Hive_227
(转载)ranger原理的更多相关文章
- [转载]SSD原理与实现
[转载]SSD原理与实现 这里只mark一下,对原论文讲解的很好的博文 https://zhuanlan.zhihu.com/p/33544892 这里有一个关于SSD的很好的程序实现,readme里 ...
- [转载] Thrift原理简析(JAVA)
转载自http://shift-alt-ctrl.iteye.com/blog/1987416 Apache Thrift是一个跨语言的服务框架,本质上为RPC,同时具有序列化.发序列化机制:当我们开 ...
- [转载] ConcurrentHashMap原理分析
转载自http://blog.csdn.net/liuzhengkang/article/details/2916620 集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的 ...
- [转载]NGINX原理分析 之 SLAB分配机制
作者:邹祁峰 邮箱:Qifeng.zou.job@hotmail.com 博客:http://blog.csdn.net/qifengzou 日期:2013.09.15 23:19 转载请注明来自&q ...
- (转载)ConcurrentHashMap 原理
集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的支持.比如两个线程需要同时访问一个中间临界区 (Queue),比如常会用缓存作为外部文件的副本(HashMap).这篇文章 ...
- [转载] ZooKeeper原理及使用
转载自http://www.wuzesheng.com/?p=2609 ZooKeeper是Hadoop Ecosystem中非常重要的组件,它的主要功能是为分布式系统提供一致性协调(Coordina ...
- [转载] kprobe原理解析(一)
From: https://www.cnblogs.com/honpey/p/4575928.html kprobe原理解析(一) kprobe是linux内核的一个重要特性,是一个轻量级的内核调试工 ...
- [转载]Redux原理(一):Store实现分析
写在前面 写React也有段时间了,一直也是用Redux管理数据流,最近正好有时间分析下源码,一方面希望对Redux有一些理论上的认识:另一方面也学习下框架编程的思维方式. Redux如何管理stat ...
- 转载--httpclient原理和应用
https://blog.csdn.net/wangpeng047/article/details/19624529/ 多谢大神的分享
随机推荐
- Java调用Http/Https接口(2)--HttpURLConnection/HttpsURLConnection调用Http/Https接口
HttpURLConnection是JDK自身提供的网络类,不需要引入额外的jar包.文中所使用到的软件版本:Java 1.8.0_191. 1.服务端 参见Java调用Http接口(1)--编写服务 ...
- js动态替换和插入字符串
替换 str是我要查询的内容loot.SERVE.file 是要被替换的内容g 全局替换"" 去替换的内容,我这里是空str.replace(new RegExp(loot.SER ...
- springboot多环境下maven打包
前言: 最近在项目中使用springboot时发现,采用在pom中定义不同的profile,并且maven打包时 采用-P参数并不能替换我application.properties文件中指定占位符的 ...
- Linux CentOs下安装lnmp
1.下载源码包 以root目录为例: cd ~ # 下载安装包 wget http://nginx.org/download/nginx-1.17.2.tar.gz # nginx wget http ...
- Python+Selenium+Appium对APP进行UI自动化测试
1. 安装Python3.7版本 pythonjava的JDK java -version javac nodejs node --versionappium 若nodejs安装完毕,使用npm安装a ...
- 个人第5次作业-Alpha2项目的测试
这个作业属于哪个课程 系统分析与设计 这个作业要求在哪里 作业要求 团队名称 卓越Code 这个作业的目标 选取3个非自己所在团队进行项目测试,协助该团队进行项目改进 前言 魏家田 201731062 ...
- python基础---python环境搭建windows版
Python3.7.1标准安装 1.官网下载 官网地址:https://www.python.org/downloads/ 下载3.7.1 下载64/32bitwindows安装文件,下图x86-64 ...
- Jmeter连接mysql,如何用delete、update、insert真正删除、更改、插入数据库里的数据;
1.如下图,当插入数据的时候如图对应填写,查询数据的时候上面插入的那条数据就会显示,但是如果不执行下图的提交数据:到数据库里查的时候,插入的这条数据实际上并没有插入成功: . 结果:如果没有提交数据, ...
- 注解@Transient
@Transient表示该属性并非一个到数据库表的字段的映射,ORM框架将忽略该属性. 如果一个属性并非数据库表的字段映射,就务必将其标示为@Transient,否则,ORM框架默认其注解为@Bas ...
- tf.logging.set_verbosity
tf.logging.set_verbosity (tf.logging.INFO) 作用:将 TensorFlow 日志信息输出到屏幕