MySQL 练习题目 二刷 - 2019-11-4 5:55 am
建表的过程
create table student(
sid int not null primary key,
sname varchar(20) not null,
sborn date,
ssex varchar(20) not null); create table course(
cid int not null primary key,
cname varchar(20) not null,
tid int not null); create table teacher(
tid int not null primary key,
tname varchar(20)); create table sc(
sid int not null,
cid int not null,
score int not null,
primary key( sid, cid) );
插入数据到student表
insert into Student values(1 , '赵雷' , '1990-01-01' , '男');
insert into Student values(2 , '钱电' , '1990-12-21' , '男');
insert into Student values('' , '孙风' , '1990-12-20' , '男');
insert into Student values('' , '李云' , '1990-12-06' , '男');
insert into Student values('' , '周梅' , '1991-12-01' , '女');
insert into Student values('' , '吴兰' , '1992-01-01' , '女');
insert into Student values('' , '郑竹' , '1989-01-01' , '女');
insert into Student values('' , '张三' , '2017-12-20' , '女');
insert into Student values('' , '李四' , '2017-12-25' , '女');
insert into Student values('' , '李四' , '2012-06-06' , '女');
insert into Student values('' , '赵六' , '2013-06-13' , '女');
insert into Student values('' , '孙七' , '2014-06-01' , '女');
insert into Course values('' , '语文' , ''),('' , '数学' , ''),('' , '英语' , ''),(4,'物理',4);
insert into Teacher values('' , '张三'),('' , '李四'),('' , '王五'),(4,'孙杨');
insert into SC values('' , '' , 80),
('' , '' , 90),
('' , '' , 99),
(1,4,46),
('' , '' , 70),
('' , '' , 60),
('' , '' , 80),
(2,4,76),
('' , '' , 80),
('' , '' , 80),
('' , '' , 80),
('' , '' , 50),
('' , '' , 30),
('' , '' , 20),
(4,4,87),
('' , '' , 76),
('' , '' , 87),
('' , '' , 31),
('' , '' , 34),
(6,4,93),
('' , '' , 89),
('' , '' , 98);
解题过程:
0、按平均成绩降序查询所有学生的课程成绩,按如下形式显示:学生姓名 课程名 课程数 所有成绩平均分
select student.sname,
max(case when cname='chinese' then sc.score else NULL end) as 'chinese', #已经按学号分组了,所以每组就是每个同学的所有课程成绩
max(case when cname='math' then sc.score else NULL end ) as 'math',
max(case when cname='english' then sc.score else NULL end) as 'english',
max(case when cname='PE' then sc.score else NULL end) as 'pe',
count(sc.cid) as '选课数',
avg(score) as '平均成绩' from sc join student on sc.sid=student.sid join course on sc.cid=course.cid group by sc.sid ,student.sname
order by avg(score) desc;
1、查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数
select student.*,a.score from (sc a join sc b on a.sid=b.sid
and a.cid=1
and b.cid=2
and a.score>b.score)
join student on a.sid=student.sid;
2、查询同时选修" 01 "课程和" 02 "课程的学生情况
select student.* from (sc a join sc b on a.sid=b.sid and a.cid=1 and b.cid=2) join student on a.sid=student.sid;
这里应该是从笛卡尔积形式的连接中查询需要的值,但是使用Join连接时,只设置了a.sid=b.sid,没有写a.cid=b.cid,所以也能达到笛卡尔积形式的连接
3、查询存在" 01 "课程但可能不存在" 02 "课程的情况(不存在时显示为 null )
#思路:题目的意思是选修1号课程的学生必须全部列出来,同时查看一下选修了1号课程的学生中有哪些选修了2号课程 select * from (select * from sc where cid=1 ) a left join (select * from sc where cid=2) b on a.sid=b.sid ;
4、查询不存在" 01 "课程但存在" 02 "课程的情况
select a.sid from (select sid from sc where cid=2 ) a left join (select sid from sc where cid=1) b on a.sid=b.sid
where b.sid is null;
5、查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
select sc.sid,student.sname, avg(sc.score) as '平均成绩'
from sc left join student on sc.sid=student.sid
group by sc.sid
having avg(sc.score)>=60;
6、查询在 SC 表存在成绩的学生信息
select distinct student.*
from sc left join student on sc.sid=student.sid;
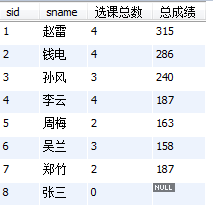
7、查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null )
#没成绩的显示null,说明有left join 或 right join,总有一个表内容要全部显示
select student.sid, student.sname, count(sc.cid) as '选课总数', sum(sc.score) as '总成绩'
from student left join sc on student.sid=sc.sid
group by sc.sid
order by student.sid; #为了更直观,对sid排了序
8、查有成绩的学生信息
select distinct student.*
from student join sc on student.sid=sc.sid
where sc.score is not null; #确保有成绩,0分也是有成绩,
9、查询「李」姓老师的数量
select count(tid) as '姓李的老师个数'
from teacher
where tname like '李%' ;
10、查询学过「张三」老师授课的同学的信息
思路:张三老师教的是哪门课程,有哪些学生选了张三老师教的那门课
select student.* from (sc left join course on sc.cid=course.cid left join teacher on course.tid=teacher.tid) left join student
on sc.sid=student.sid
where tname='张三';
11、查询没有学全所有课程的同学的信息
#有一些同学一门课都没有选,所以成绩表SC里面没有这些学生的任何信息,
#现在题目的要求是没有学全,我的理解是SC表里的同学 select student.*
from sc join student on sc.sid=student.sid
group by sc.sid
having count(sc.cid)<(select count(course.cid) from course);
12、查询至少有一门课与学号为" 01 "的同学所学相同的同学的信息
select distinct sid
from sc
where cid in (select cid from sc where sid=1) and sid!=1;
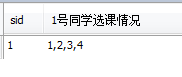
13、查询和" 01 "号的同学学习的课程 完全相同的其他同学的信息
PS:使用了group_concat( )函数,将分组后指定字段的值连接起来,感觉使用时最好对连接的字段排序,以免出错
select student.*
from
(select sid, group_concat(cid order by cid) as tt from sc where sid=1 group by sid) a #1号同学选修的课程
#为了避免cid插入顺序引起的group_concat()结果有差异,所以对cid进行了排序
left join ( select sid, group_concat(cid order by cid) as rr from sc where sid!=1 group by sid) b on a.tt=b.rr
#除1号同学外,其他同学选修的课程,将两张表进行连接,按照选修课程相同为条件进行连接 join student on b.sid=student.sid;
中间过程解析:
select sid, group_concat(cid order by cid) as '1号同学选课情况' from sc where sid=1 group by sid
运行结果:
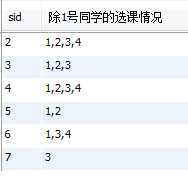
select sid, group_concat(cid order by cid) as '除1号同学的选课情况' from sc where sid!=1 group by sid;
运行结果:
14、查询没学过"张三"老师讲授的任一门课程的学生姓名
#差集, SC表里的所有学生-选修了张三老师课程的学生,即为没有选修过张三老师任一课程的学生
select student.*
from
(select distinct sid from sc ) a left join #SC表全部的学号,去重 (select sc.sid from ((sc left join course on sc.cid=course.cid) left join teacher on course.tid=teacher.tid) where teacher.tname='张三') b
on a.sid=b.sid left join student on a.sid=student.sid where b.sid is null;
15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
PS:不明白它的这个平均成绩,假如1号同学选了4门课,其中有3门不及格,那么这个平均成绩是指这4门的,还是指这3门不及格的平均成绩
下面两种方法都可以选出不及格的同学,但是计算的平均成绩有所不同
一:不及格同学的所有选修课平均成绩
#这种方法计算的是每个同学所有选修课的平均成绩
select student.sid, student.sname, avg(sc.score) as '平均分'
from sc join student on sc.sid=student.sid
group by sc.sid
having sum(sc.score<60)>=2; # 注意:使用的是sum()函数,不能使用count()函数
二:不及格同学的选修课中,不及格部分课程的平均成绩
#这种方法计算的是不及格同学中所选课程,不及格部分的平均成绩
select student.sid, student.sname, avg(sc.score) as '平均分'
from sc join student on sc.sid=student.sid
where sc.score<60 # 先筛选出不及格的
group by sc.sid
having count(sc.cid)>=2;
16、检索" 01 "课程分数小于 60,按分数降序排列的学生信息
select student.*
from sc join student on sc.sid=student.sid
where sc.cid=1 and sc.score<60
order by sc.score desc;
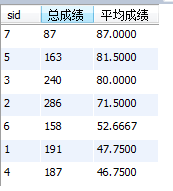
17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
A:当做总成绩处理,order by 排序时 平均成绩 这个字段绝对绝对不能加引号,加上引号之后就不能排序了
select sid, sum(score) as '总成绩', avg(score) as '平均成绩'
from sc
group by sid
order by 平均成绩 desc;
运行结果:真心搞不懂这个所有课程的成绩是指哪一种,这种按总成绩算好像没有什么意义,因为都知道平均成绩了
B:按每科成绩处理
select student.sid, sc.cid, sc.score, a.avgscore
from student left join sc on student.sid=sc.sid
left join
(select sid, avg(score) as avgscore from sc group by sid) a on sc.sid=a.sid #先计算每个同学的平均成绩
order by a.avgscore desc;
运行结果:图太大,分两张
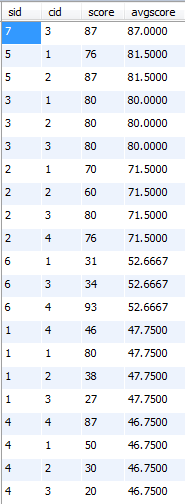

18、查询各科成绩最高分、最低分和平均分:
select cid, max(score) as '最高分', min(score) as '最低分', avg(score) as '平均分'
from sc
group by cid;
19、以如下形式显示:课程 ID,课程 name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
PS:round( )函数将小数保留2位,concat( )函数连接字符串
select sc.cid, course.cname, max(sc.score) as '最高分', min(sc.score) as '最低分', round(avg(sc.score),2) as '平均分', concat(round(sum(case when sc.score>=60 and sc.score<70 then 1 else 0 end) /count(sc.sid)*100,2),'%') as '及格率',
concat(round(sum(case when sc.score>=70 and sc.score<80 then 1 else 0 end)/count(sc.sid)*100,2),'%') as '中等率',
concat(round(sum(case when sc.score>=80 and sc.score<90 then 1 else 0 end)/count(sc.sid)*100,2),'%') as '优良率',
concat(round(sum(case when sc.score>=90 then 1 else 0 end )/count(sc.sid)*100,2),'%') as '优秀率' from sc join course on sc.cid=course.cid
group by sc.cid;
20、要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
PS:order by子句中的 选修人数 这个字段一定不能加引号,否则order by子句排序的功能消失
select cid, count(sid) as '选修人数'
from sc
group by cid
order by 选修人数 desc,cid;
运行结果:
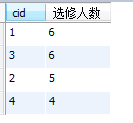
21、按各科成绩进行排序,并显示排名, Score 重复时保留名次空缺
PS:个人理解是,分课程,对学生进行排名,这道题目是名次不连续
select a.cid, a.sid, a.score , count(a.score<b.score)+1 as rank
from sc a left join sc b on a.cid=b.cid and a.score<b.score #笛卡尔积连接, 然后筛选满足a.score<b.score的
group by a.cid, a.sid
order by a.cid, a.score desc;
运行结果: 两张图是一样的,右边的做了点标记
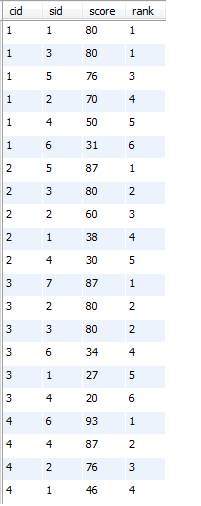
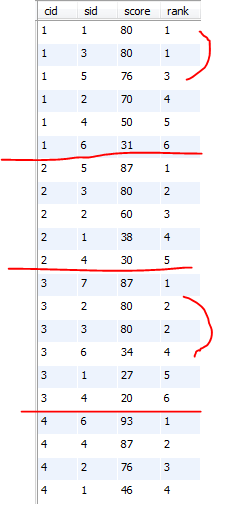
22、按各科成绩进行排序,并显示排名, Score 重复时合并名次
PS:个人理解,分课程,对学生排名,这道题目是名次要求连续
select a.cid, a.sid, a.score , count(distinct b.score)+1 as rank #这里使用的是distinct b.score
from sc a left join sc b on a.cid=b.cid and a.score<b.score #笛卡尔积连接, 然后筛选满足a.score<b.score的
group by a.cid, a.sid
order by a.cid, a.score desc;
运行结果:
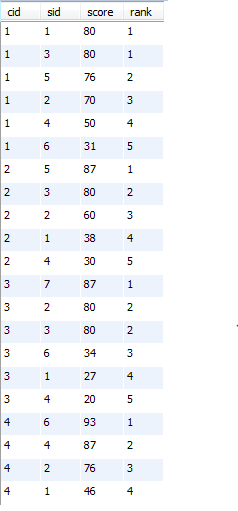
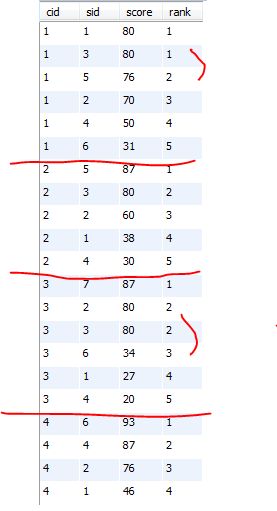
23、查询各科成绩前三名的记录
PS:这道题目就是在21,22题的基础上添加一个having子句,筛选名次rank<=3,即前三名
A:名次不连续时的前三名
select a.cid, a.sid, a.score , count(a.score<b.score)+1 as rank
from sc a left join sc b on a.cid=b.cid and a.score<b.score #笛卡尔积连接, 然后筛选满足a.score<b.score的
group by a.cid, a.sid
having rank<=3
order by a.cid, a.score desc;
运行结果:
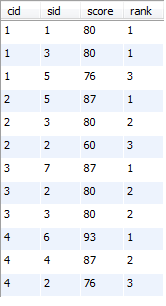
B:名次连续时的前三名
select a.cid, a.sid, a.score , count(distinct b.score)+1 as rank #这里使用的是distinct b.score
from sc a left join sc b on a.cid=b.cid and a.score<b.score #笛卡尔积连接, 然后筛选满足a.score<b.score的
group by a.cid, a.sid
having rank<=3
order by a.cid, a.score desc;
运行结果:
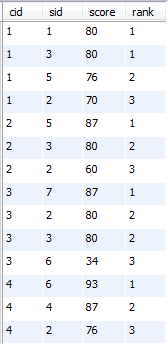
24、查询学生的总成绩,并进行排名,总分重复时保留名次空缺
select a.sid, count(a.tt<b.rr)+1 as rank
from
(select sid, sum(score) as tt from sc group by sid ) a
left join
(select sid, sum(score) as rr from sc group by sid ) b on a.tt<b.rr
group by a.sid
order by rank;
运行结果:

25、 查询学生的总成绩,并进行排名,总分重复时不保留名次空缺
select a.sid, count( distinct b.rr)+1 as rank
from
(select sid, sum(score) as tt from sc group by sid ) a
left join
(select sid, sum(score) as rr from sc group by sid ) b on a.tt<b.rr
group by a.sid
order by rank;
运行结果:

26、统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[60-0] 及所占百分比
select sc.cid, course.cname,count(sc.sid) as '人数',
concat(round(sum(case when score>=0 and score<60 then 1 else 0 end)/count(sc.sid)*100,2),'%') as '[0-60]',
concat(round(sum(case when score>=60 and score<70 then 1 else 0 end)/count(sc.sid)*100,2),'%') as '[60-70]',
concat(round((sum(case when score>=70 and score<85 then 1 else 0 end)/count(sc.sid))*100,2),'%') as '[70-85]',
concat(round((sum(case when score>=85 and score<100 then 1 else 0 end)/count(sc.sid))*100,2),'%') as '[85-100]' from sc join course on sc.cid=course.cid
group by sc.cid;
运行结果:
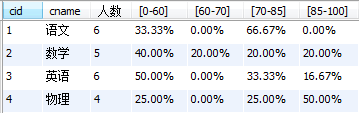
select sc.cid, course.cname,count(sc.sid) as '该课程的总人数',
sum(case when score>=0 and score<60 then 1 else 0 end) as '[0-60]人数',
concat(round(sum(case when score>=0 and score<60 then 1 else 0 end)/count(sc.sid)*100,2),'%') as '[0-60]',
sum(case when score>=60 and score<70 then 1 else 0 end) as '[60-70]人数',
concat(round(sum(case when score>=60 and score<70 then 1 else 0 end)/count(sc.sid)*100,2),'%') as '[60-70]',
sum(case when score>=70 and score<85 then 1 else 0 end) as '[70-85]人数',
concat(round((sum(case when score>=70 and score<85 then 1 else 0 end)/count(sc.sid))*100,2),'%') as '[70-85]',
sum(case when score>=85 and score<100 then 1 else 0 end) as '[85-100]人数',
concat(round((sum(case when score>=85 and score<100 then 1 else 0 end)/count(sc.sid))*100,2),'%') as '[85-100]' from sc join course on sc.cid=course.cid
group by sc.cid;
运行结果:

27、查询每门课程被选修的学生数
select cid, count(sid) as '学生数'
from sc
group by cid;
运行结果:

28、查询出只选修两门课程的学生学号和姓名
select student.sid, student.sname
from sc join student on sc.sid=student.sid
group by sc.sid
having count(sc.cid)=2;
29、查询男生、女生人数
select ssex ,count(sid) as '人数'
from student
group by ssex;
30、查询名字中含有「风」字的学生信息
select *
from student
#where sname like '%风%';
或使用正则表达式 REGEXP
select *
from student
where sname regexp '风';
运行结果:
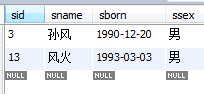
31、查询同名同性学生名单,并统计同名人数
#同性,不清楚是不是写错了
32、查询 1990 年出生的学生名单
select sid, sname
from student
where year(sborn)='';
33、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
select cid, avg(score) as '平均成绩'
from sc
group by cid
order by 平均成绩 desc, cid;
34、查询平均成绩大于等于 85 的所有学生的学号、姓名和平均成绩
select student.sid, student.sname, avg(score) as '平均成绩'
from sc join student on sc.sid=student.sid
group by sid
having avg(score)>=85;
35、查询课程名称为「数学」,且分数低于 60 的学生姓名和分数
select student.sname , sc.score
from sc join student on sc.sid=student.sid join course on sc.cid=course.cid
where course.cname='数学' and sc.score<60;
36、查询所有学生的课程及分数情况(存在学生没成绩,没选课的情况)
select student.sid, sc.cid, sc.score
from student left join sc on student.sid=sc.sid;
37、查询任何一门课程成绩在 70 分以上的姓名、课程名称和分数
select student.sname, course.cname, sc.score
from sc join student on sc.sid=student.sid join course on sc.cid= course.cid
where sc.cid in (select distinct sid from sc where score>70);
38、查询课程编号为 01 且课程成绩在 80 分以上的学生的学号和姓名
select student.sid, student.sname
from sc join student on sc.sid=student.sid
where sc.cid=1 and sc.score>80;
39、求每门课程的学生人数
select cid, count(sid) as '人数'
from sc
group by cid;
40、成绩不重复,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
41、成绩有重复的情况下,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
PS:这两道题,使用下面同样的代码都能运行出正确结果
select student.*, a.score
from sc a left join sc b on a.cid=b.cid and a.score<b.score #对每门课程下的学生成绩排名 join course on a.cid=course.cid
join teacher on course.tid=teacher.tid and tname='张三' #这一行和上一行,是为了筛选张三老师教的课
join student on a.sid=student.sid # 获取学生信息 group by a.cid, a.sid
having count( a.score< b.score)=0 #筛选名次rank=1, count(a.score<b.score)+1=1,两端减去1,简化为count(a.score<b.score)=0 #上面这一行having 子句,这种格式也可以:having count( distinct b.score)=0 ,使用distinct
;
42、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
A:不同课程,成绩相同的学生信息
select sc.cid , sc.sid, sc.score
from sc join (select cid, score from sc group by cid, score having count(sid)>=2) a
on sc.cid=a.cid and sc.score=a.score
order by cid ;
运行结果:
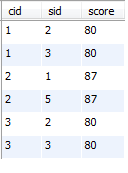
B:不同课程成绩相同的,学生信息
select sc.sid, sc.cid , sc.score
from sc join (select sid, score from sc group by sid, score having count(cid)>=2) a
on sc.sid=a.sid and sc.score=a.score
order by sid;
运行结果:
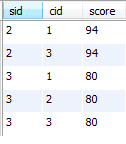
43、查询每门功成绩最好的前两名
A:保留名次空缺
select a.cid, a.sid,a.score , count(a.score<b.score)+1 as rank
from sc a left join sc b on a.cid=b.cid and a.score<b.score
group by a.cid,a.sid
having rank<=2
order by a.cid, a.score desc;
B:不保留名次空缺
select a.cid, a.sid,a.score , count(distinct b.score)+1 as rank
from sc a left join sc b on a.cid=b.cid and a.score<b.score
group by a.cid,a.sid
having rank<=2
order by a.cid, a.score desc;
44、统计每门课程的学生选修人数(超过 5 人的课程才统计)。
select cid, count(sid) as '选修人数'
from sc
group by cid
having count(sid)>5;
45、检索至少选修两门课程的学生学号
select sid
from sc
group by sid
having count(cid)>=2;
46、查询选修了全部课程的学生信息
select student.*
from sc join student on sc.sid=student.sid
group by sc.sid
having count(cid)=(select count(cid) from course);
47、查询各学生的年龄,只按年份来算
select sid , sname, year(now())-year(sborn) as age
from student;
48、按照出生日期来算,当前月日 < 出生年月的月日则,年龄减一
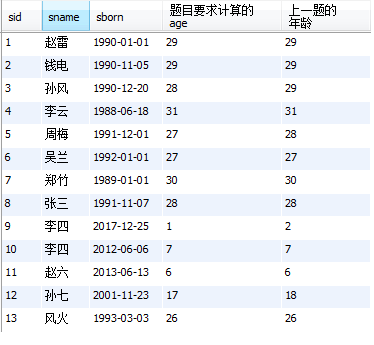
select sid, sname ,sborn, timestampdiff(year,sborn,date_format(now(),'%Y-%m-%d')) as '题目要求计算的age',
year(now())-year(sborn) as '上一题的年龄' from student;
运行结果:
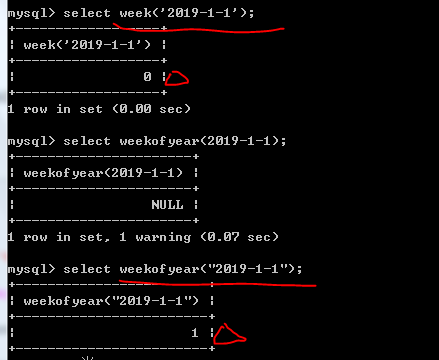
49、查询本周过生日的学生
PS:
a. 在where子句中两端使用的函数要相同,因为week( )函数的周数是从0开始,weekofyear( )函数是从1开始
b. concat( )函数、concat_ws( )函数都可以,
c. 连接中间的年月日时,有两种形式:一种是使用函数date_format( ),另一种是整理出年、月、日,然后进行连接
d. 中间的连接符:-, /, #, * , $,这几个试了都可以
下面的where 子句除了最后一行,任选一行都能运行出正确的结果
select *
from student where weekofyear(concat(year(now()),'-',date_format(sborn,'%m-%d')))=weekofyear(now()); #成功 where weekofyear(concat(year(now()),'/',month(sborn),'/',day(sborn)))=weekofyear(now()); where week(concat(year(now()),'-',month(sborn),'-',day(sborn)))=week(now()); where week(concat_ws('',year(now()),month(sborn),day(sborn)))=week(now()); where week(concat_ws('-',year(now()),date_format(sborn,'%m-%d')))=week(now()); #where weekofyear(year(now())&"-"&month(sborn)&"-"&day(sborn))=weekofyear(now()); #这种形式的连接报错
50、查询下周过生日的学生
select *
from student
where week(concat_ws('-',year(now()),date_format(sborn,'%m-%d')))=week(now())+1;
51、查询本月过生日的学生
select sid , sname, sborn
from student
where month(sborn)=month(now());
52、查询下月过生日的学生
select sid , sname, sborn
from student
where month(sborn)=month(now())+1;
做这些题目时,感觉自己语文水平有待提升,题目都读不懂了
MySQL 练习题目 二刷 - 2019-11-4 5:55 am的更多相关文章
- MySQL数据库管理(二)单机环境下MySQL Cluster的安装
上文<MySQL数据库管理(一)MySQL Cluster集群简单介绍>对MySQL Cluster集群做了简要介绍.本文将教大家一步步搭建单机环境下的MySQL数据库集群. 一.单机环境 ...
- EOJ Monthly 2019.11 E. 数学题(莫比乌斯反演+杜教筛+拉格朗日插值)
传送门 题意: 统计\(k\)元组个数\((a_1,a_2,\cdots,a_n),1\leq a_i\leq n\)使得\(gcd(a_1,a_2,\cdots,a_k,n)=1\). 定义\(f( ...
- MySQL索引(二)B+树在磁盘中的存储
MySQL索引(二)B+树在磁盘中的存储 回顾  上一篇文章<MySQL索引为什么要用B+树>讲了MySQL为什么选择用B+树来作为底层存储结构,提了两个知识点: B+树索引并不能直接找 ...
- 2019.11.9 csp-s 考前模拟
2019.11.9 csp-s 考前模拟 是自闭少女lz /lb(泪奔 T1 我可能(呸,一定是唯一一个把这个题写炸了的人 题外话: 我可能是一个面向数据编程选手 作为一个唯一一个写炸T1的人,成功通 ...
- leetcode二刷结束
二刷对一些常见的算法有了一些系统性的认识,对于算法的时间复杂度以及效率有了优化的意识,对于简单题和中等题目不再畏惧.三刷加油
- MySQL 系列(二) 你不知道的数据库操作
第一篇:MySQL 系列(一) 生产标准线上环境安装配置案例及棘手问题解决 第二篇:MySQL 系列(二) 你不知道的数据库操作 本章内容: 查看\创建\使用\删除 数据库 用户管理及授权实战 局域网 ...
- MySQL基础(二)——DDL语句
MySQL基础(二)--DDL语句 1.什么是DDL语句,以及DDL语句的作用 DDL语句时操作数据库对象的语句,这些操作包括create.drop.alter(创建.删除.修改)数据库对象. 2.基 ...
- MySQL系列(二)---MySQL事务
MySql 事务 目录 MySQL系列(一):基础知识大总结 MySQL系列(二):MySQL事务 什么是事务(transaction) 保证成批操作要么完全执行,要么完全不执行,维护数据的完整性.也 ...
- mysql 数据库(二)数据库的基本操作
mysql 数据库(二)数据库的基本操作 用户管理,添加权限,创建,显示,使用数据库 1 显示数据库:show databases; 默认数据库: mysql - 用户权限相关数据 test - 用于 ...
随机推荐
- ASP.NET Core 2.0升级到3.0的变化和问题
前言 在.NET Core 2.0发布的时候,博主也趁热使用ASP.NET Core 2.0写了一个独立的博客网站,现如今恰逢.NET Core 3.0发布之际,于是将该网站进行了升级. 下面就记录升 ...
- mybatis中用注解如何处理存储过程返回的多个结果集?
sql代码: create procedure sptest.getnamesanditems() reads sql data dynamic result sets 2 BEGIN ATOMIC ...
- 一篇文章搞定redis
Redis 简介 Redis 是完全开源免费的,遵守 BSD 协议,是一个高性能的 key - value 数据库 Redis 与 其他 key - value 缓存产品有以下三个特点: Redis ...
- 一.Linux
1.常用命令 Linux 命令的语法格式命令[选项][参数] Ctrl + l #清屏 clear #清屏 Ctrl +c #结束命令 man su #查看su 帮助信息,q 退出 su --help ...
- 使用node+vue实现简单的WebSocket聊天功能
最近学习了一下websocket的即时通信,感觉非常的强大,这里我用node启动了一个服务进行websocket链接,然后再vue的view里面进行了链接,进行通信,废话不多说,直接上代码吧, 首先, ...
- springboot脚手架liugh-parent源码研究参考
1. liugh-parent源码研究参考 1.1. 前言 这也是个开源的springboot脚手架项目,这里研究记录一些该框架写的比较好的代码段和功能 脚手架地址 1.2. 功能 1.2.1. 当前 ...
- CSS3 新增文本样式
CSS3 对原来的 CSS2 版本中已定义的属性取值进行修补,增加了更多的属性值,来适应复杂环境中文本的呈现. 一.定义文本阴影 可以给文字添加阴影效果了 Shadow 影子 语法: text-sha ...
- Java 7 NIO.2学习(Ing)
Path类 1.Path的基本用法 Path代表文件系统中的位置,即文件的逻辑路径,并不代表物理路径,程序运行的时候JVM会把Path(逻辑路径)对应到运行时的物理位置上. package com.j ...
- Python之路(第四十四篇)线程同步锁、死锁、递归锁、信号量
在使用多线程的应用下,如何保证线程安全,以及线程之间的同步,或者访问共享变量等问题是十分棘手的问题,也是使用多线程下面临的问题,如果处理不好,会带来较严重的后果,使用python多线程中提供Lock ...
- Oracle数据库主外键 级联删除记录
/** * 1. NO ACTION :指当删除主表中被引用列的数据时,如果子表的引用列中包含该值,则禁止该操作执行. * * 2. SET NULL :指当删除主表中被引用列的数据时,将子表中相应引 ...