Generative Adversarial Networks overview(1)
Libo1575899134@outlook.com
Libo
(原创文章,转发请注明作者)
本文章会先从Gan的简单应用示例讲起,从三个方面问题以及解决思路覆盖25篇GAN论文,第二个大部分会进一步讲Gan的所有领域应用
-----------------------------------------------------------------------------------
1: 下图GAN可以学到不同的字体,并且在字体之间进行不同的变换

2 下图可以用简笔画可以用GAN帮助生成想要画的东西,比如绿色的横线是想画一个草地,如果想把绿色的山变成雪山,可以在尖部画一些白色的线条。

3 下图展示了可以把线条进行填色,也可以把平面图变成立体图

4 下图是仿脸萌的一个应用,把人的真实头像换成一个卡通的头像。

5 下图展示了在不同物体之间做的转换,比如从夏天的图转换到冬天的,从莫奈的画变成一个真实的照片或者从马变成斑马。

6 下图是说把上面的任务应用到一个更流行的场景,可以合成口型,这个图看起来效果不是很好,但是可以通过后期处理让其变得非常真实。

----------------------------------------------------------------------------------------------------------------------------------
下面将来介绍一些内容包括GAN的难点,以及针对这些难点有哪些技术解决方法,我们通过三个思路概括25篇论文。
困难一:Gan的自由度太高了,引入了神经网络之后随之带来的问题
困难二:优化JS散度带来的梯度消失问题
困难三:替代版损失函数优化KL散度引发的mode missing问题

GAN最直观的理解是给定一个随机数或者一个随机的向量生成我们想要的东西,就象变戏法一样

它虽然是一个生成模型,它解决生成模型的想法是:假设有个造假币的人(生成模型),有个警察(判别模型),希望造出来的假币很难被识别出来,警察需要抓捕造假币的人,两者属于一种对抗的模式,这种对抗会使得造假币的人不断提高自己的造假技术,警察不断提高自己的侦察技术,最后导致了一种平衡,最后导致了假币和真币无法被区分出来,认为两方都不可能变得更好了。

把这个想法变得数学化来说就是:GAN用的是一种min-max的对抗模型来解决生成问题,刚才的假币制造商和警察对应着生成器G和判别器D,如图所示最左边输入一个随机数或者随机数组经过一个生成器(神经网络),生成假币或者图像,对于警察(判别器)要判别当前接触到的是真币还是假币。

如果从数学公式来看的话,对D来说 有两个目标,要最大可能的判断出真实的钱币(数据)是真实的,把正确的事情判断正确,要把不正确的事情判断出是不正确的

判别器要判定最大化两种情况下都正确的概率,生成器跟判别器相反,最小化目标。

吸引人的地方有很多,比如生成输入只需要是一个noise输出是x,因为需要反向传播的一些方法所以用神经网络量来模拟G,只需要用生成数据的分布去逼近真实数据的分布,逼近之后就可以直接从生成数据分布中采样就行了,最吸引人的地方在于并不需要写出一个如何生成数据的表达式,正如图模型的表现力有限,P的表达式越复杂,计算复杂度越高,gan解决了这个问题。

但是如下图生成的东西和我们希望的存在差异,甚至于真实的人脸可能会转换成一个卡通图像。


因为gan并不会对P有任何显性的要求,不需要写出一个具体的表达书,自由度太高了,失去控制,没有合理的引导生成不出想要的东西
困难一:因为用到了深度神经网络去逼近G,神经网络中很困惑的问题是如何在反向传播的过程中,如何让梯度传播的更好,需要考虑模型的深度和复杂度,梯度消失梯度爆炸的问题,把神经网络固有的问题引入进来。

困难二:是GAN的目标函数,判别器的目标是:1 最大化正确数据判断正确的概率,2 最大化不真实的情况下判断为不真实的概率
原始论文中提到,生成器的目标最好用下面alternative的,为什么呢?

使用原始的G目标函数会导致G的D梯度消失问题,因为直观上,在训练的初期阶段,D很容易对检测有信心G,所以D的输出几乎总是0
直观上来理解,因为生成器是从无到有学习起来的,在训练初期生成器生成的样本质量非常差,对于判别器非常容易判别出来,判别器的损失几乎为0,进而生成器也无法更新。

那么从原理上说,当均衡状态下判别器达到最优时,目标函数是在最小化JS散度,为啥呢?


当靠拢到最佳状态时,我们可以求得一个最优的判别器的表达式D*,r是真实数据的分布,g是生成数据的分布,损失函数就可以等价下式,2log2是常数,实际上是在优化这两个分布的JS散度

JS散度和KL散度是什么意思呢?
假设有两个人,一个人爱狗,说的频率很高,一个人爱猫,这里会引入一个交叉熵的概念

在语言系统中我们希望表达更加有效率,我们希望更常说的东西由更简单的编码去编,两个人说话词汇的频率不一样,则编码系统就会不一样,当一个人用到另一个人的编码系统时会导致信息量不一样,信息量就叫交叉熵H

Hp(q)和Hq(p)就是两个人分别说对方语言的交叉熵,alice 说“狗”时候,“狗”自己系统的编码长度很大。 Bob说猫的时候,就需要很大的信息量。所以是非对称的,导致KL散度就不是衡量两个非对称分布的度量。

所以KL散度的计算如以下公式,各自交叉熵不是同样大小,减去各自的熵,KL散度也不是对称的。

KL散度是计算距离的,如果是非对称的分布就会带来很多麻烦,需要变成对称的,方法是:
先找到r的分布,在p和q之间取一个平均值,就可以计算出每个单独分布和每个中间值r的KL散度,加起来后就是一个JS散度,JS散度就已经是一个对称散度了。

有个直观的例子:当两个分布完全重叠的时候,KL散度和JS散度都是0,当两个分布重合度很低的时候,KL和JS 都会增大,达到最大。

回头再来看问题2,当D达到最优的时候,等价是在优化JS散度,关键是优化JS散度是不太对的。

因为,如果两个分布几乎没有重叠的话,JS散度就会是一个常数,就会不贡献任何信息,传递导数时几乎没有导数传过来,导致了梯度消失的问题。

困难三:刚才都是一直在说原始的D是有问题的,提出了替代版的目标函数,但是同样有问题,因为生成器G一开始的目标是最小化让D把它抓出来的概率,D是最大化把它揪出来的概率。问题转换一下,最大化D抓不出来的概率,但实际上在理论上是不等价的

没有理论上的保证会带来很多问题,所以替代版的目标函数等价于优化下面的目标函数,最小化KL散度的同时,最大化JS散度,但是KL散度和JS散度是同增同减的,并不是相反的。则同时让一个最大化一个最小化是不对的。


两项是相反的,就会导致优化会乱跑就会导致梯度不稳定的问题。

那么如果暂时不考虑优化JSD的部分,因为在不overlap的时候JSD等于常数,只考虑只优化KL散度有没问题呢?同样是有问题的,因为之所以引入JS散度就是因为KL散度是不对成的,不对称带来的问题是,当生成器生成了一个不够真实的样本和生成器没有生成真实样本的时候,两种情况下得到惩罚是不一样的,D返回的数据是不一样的,这就是不对成的KL散度在这个问题中的直观反应,会导致,生成器为了减小自己可能得到的惩罚,就会生成很多看起来尽量真实,但是很可能都长一个样的样本,因为这样的得到的KL散度在某个方向的惩罚较小,导致了生成的样本多样性不够丰富,会出现一个叫mode missing的问题。

------------------------------------------------------------------------------------------------
解决思路如下:
方法1.1: 部分指导,显示的加入指导信息
方法1.2: 细粒度指导,隐性的知道,迭代学习
方法1.3: 神经网络优化技巧 skip-connection 等
Solution 1: Partial and Fine-grained Guidance

传统的输入是蓝色向量noise,绿色向量word2vec embding ,onehot编码的向量都可以,也可以是一个图片,可以是任何表达的信息,后面有很多版本,有人加到了中间层并不是输入层,在判别器的里面也要把输入的信息给他,做的实验就是加了word embding的标达。简单理解就是判别器要判定生成图像和输入conditional是不是一个pair

接着看2016年openAI的improved Gan的paper 提出了2个技巧.
一个技巧是feature matching. D学的很好,G学的不是很好,就把D的信息传过来,到底通过什么样的feature把G抓出来的,把这个feature也学出来。
第二个技巧minibatch disc解决的有点关乎mode missing 的问题,生成了太多长的一样的样本,因为每次判别器只看一样本,是否是真实的,会导致当前生成器生成的样本被判定为有效的时候就会导致生成器总是生成此个样本,解决办法是不要一次判断一个,把之前判断的其他样本的feature一起送进来,判断的时候会考虑一堆样本的信息,可以理解为其他样本的feature给了当前样本更多的信息,来指导靠拢其他的有效信息。

接下来的工作是朱骏彦团队的iGAN或者GVM,思路是GAN 不修正的话总是比较模糊,可以考虑把清楚的纹路贴过来,这个工作里会有两个监督信息,一个是如何来变形,user可以给定一个信息变成什么样的(低邦鞋变成高筒靴)。
另外一个监督信息是要把原始纹路贴过来,直接贴会有问题,因为如果变形的话贴过来肯定是不对应的。

下图所示就是给定一个变形的监督信息,给了一个变形的方向,根据指导去融合。

第二种监督信息是把变形的过程做interpolation(插值) , 在interpolation中捕捉光场,光场可以理解成一种motion+color的变化,目标是把光场的流向变形过来

如下图只要是可以捕捉到光场,就可以把光场的对应关系一点一点应用到贴片的对应关系中,先从光场的信息中学到了点对点的映射,利用映射把原始信息贴到对应位置上就行了,所以在损失函数中就有很对对应的term(空间和颜色)。

下面这个工作是除了变形靴子,变形物品意外,还可以用手残画变成更好的画,或者对画进行修饰和调整,如果北京雾霾比较严重,就可以给它画出一片蓝天,山等等

下面的工作pix2pix在18年年初特别火,目标是我们把线条画变成一个上色的画,把平面图变成立体图,之前的所有GAN的工作,都是让D去判断一张图片,或者一组图片一组图片也是来自于真实或者生成的,但是pix2pix 需要传入一个pair的数据给D,所以D分辨的是这一组之间的映射关系是不是对应的(是不是可以映射为一组)


假如下图要给kitty上色,真实的pair是左边,失败的上色是右边的pair,所以D需要判定的不是生成的是不是kitty,而是生成是不是符合我上色要求的kitty

下面展示的也是pix2pix的工作,景深图跟真实照片图的转换

下面的工作叫Gaussian-Poisson GAN,跟igan干的事情比较类似,在PS过程中经常会抠图跟明星合影或者是换一个场景呀,所以需要抠图+贴图,但是不清晰 融合也不好 各种问题,所以GP-gan 就是能让这个融合过程更真实,比如下面的天是不一样的。

他们是怎么做的呢?首先有个blending GAN,是有监督的模型,要把一个比较相似的融合好的图像/融合好的图像作为一个目标图像,所以是一个监督的损失函数,此外里面有一个Color Constraint 有点像IGAN中光场的那种限制条件,算是一种有监督信息的补充。

上面是解决方法一的第一小种,都是显性的给一些部分指导,显性的给一些有监督的信息。
下面是第二种,是给一些隐性的指导,并不是真的给一个图片或者向量。

LAPGAN是2015年facebook的工作,拉普拉斯GAN
第二篇Match-aware 做的事从文字合成图像的工作,我写你画
第三篇 stackGan 任务几乎一样
LAPGAN 在2015已经很厉害了,之前的GAN只能生成16*16 32*32的图像,LAPGAN是第一篇生成到64*64的图像,思想是不要一次性生成,一步一步生成的,从小到大。
具体实现技巧很欠缺,每个部分都是不同组的gan ,多个G和D,不能够端到端的train。下一步要基于上一步的生成信息,同时还有有noise和onehot的输入。

Matching-aware 的工作是从文本生成图像,大家可能认为C-gan就可以实现,但是他们提出了重要的改进,三种不同的可能性:
1, 非常真实的图像和文本
2, 我生成了非常真实的图像但是和文本是不对成的
3, 符合我的要求但是文本是一样的。
所以说D要分辨两种不同的error,判断两种可能性都是假的,

给左边的描述生成右边的图像,有些还是可以看的ICML2016。

接下来看StackGan ,当时引起了一定的轰动,是因为生成了256*256的图像,为什么叫stackGan呢?跟LAPGAN一样,有点像LAPGAN和matching-aware 的结合一样,不要一步到位的生成,先把鸟大致的轮廓和颜色分布画出来,再精修细节。
在实际训练过程中也是一样,GAN非常擅长分开学习前景和背景,这是GAN的特性,最近专门有人做成一个目标函数,要求先生成比较模糊的背景后生成细节。


接下来看PPGN 17年年底非常的火,全称叫“Plug and Play Generative Networks”,主要解决的是mode-missing的问题。PPGN可以生成非常丰富的样本,效果看起来非常solid


之所以把它归类为Fine-grained Guidance 的原因是:它们用一个迭代的,去噪声的自动编码器,生成的,经过了不断的迭代去噪的过程加了其他的限制导致图像很丰富。

之所以把它归类为Fine-grained Guidance 的原因是:它们用一个迭代的,去噪声的自动编码器,生成的,经过了不断的迭代去噪的过程加了其他的限制导致图像很丰富。
接下来介绍第一大类中的第三类,虽然有人已经用增强学习来自动选择网络结构了,但是还是更要相信手工炼丹的方法,需要了解下哪些结构在GAN的工作被证实有效。

第一篇DC Gan 的重要性在于,在它之前就有4,5篇成功应用了MLP的gan模型,MLP中基本都是全连接层,发现其他结构都不太work

做法如下: 把所有的pooling层 替代成了 strided conv , 也用了bn , 移除了 fc , 加了一些relu , leakyrelu , tanh

第一次在大规模上图像集,LF 大规模场景理解数据集上work的,有趣的是可以学出不带窗户过渡到带窗户的。

第二个pix2pix的工作,提出了U-net在里面表现的更好,最重要的原因是U-net加了skip-connection.

GP-GAN在Blending gan中是一个enconder – deconder的结构,但是在最中间加了FC层,完全抛弃了channel wise的fc,变成fully connect 的全连接层,可以帮助传播全局信息

给我们的启示就是要按照不同任务选择不同的网络结构,第一种会引发的梯度传导困难的问题基本解决了。


解决 2.1:encoder方法
解决 2.2:Noisy input
第二个问解决方案主要是针对于第三个困难,也就是mode-missing的问题,gan生成出来的样本经常不够丰富,这类方法统称为加encoder的方法,来解决两个问题,
1 : 强制生成分布和真实数据分布有一定重合度,使得JSD是有一定意义的,就不再是一个常数了,可以传梯度了
2 : 让encoder来作为真实数据和生成数据的桥梁,不要直接判别生成数据和真数据,让它判别假数据生成数据和一个编码过后的数据.

那么什么是mode missing的问题呢? 下面箭头代表了生成的流形,M1 和 M2 是数据里的两个Mode, 蓝色比较大, 紫色比较小, 蓝色样本特别多,就是一个大mode, 比如人脸数据集 白人多, 白人就是个大Mode.
OK,如果同时在数据集中存在两种不同大小的Mode的时候, 在做梯度传导的时候,大部分的梯度都会传向大Mode , 小Mode 无法学习.

从数学角度讲:最开始的任务是优化min max game 左边是真是, 让D 最大化正确的概率,让G最小化D正确的概率.
等式两边发现 理论上相等,但是实际不相等,如下图的直观理解, 如果让生成器去逼近8个高斯分布(8个平均的Mode,分布很散),学习时困惑,到低应该逼近哪一个Mode

Mode Regularized GANs , 我们引入了一个encoder, 让一个image 或者 noise 经过一个Encoder 之后会生成一个表达式, 再通过这个表达式生成真实的样本, 所以G 是附和在E的上面的. 就会有一个encoding 的L1 的loss,试过L2 但是不work, 那么生成器的目标函数就会有一些变化,除了要最大化D抓不到的概率 (这里是替代版的function) ,还要加上enconder的loss , 这些都被加到生成器的loss里.
判别器不变.

但是依然会出现梯度消失的问题,如果不用复杂的网络结构,目前还是用的DCGAN, 生成器前期还是比较差劲 那能不能用别的方式解决梯度消失的问题呢?

针对于梯度下降 就做了如下改进,
1 Manifold让生成分布和真实分布的流形尽量长得一个样,形状相似
Manifold 就可以利用encoder得到的信息, 去比较他们的流形
2 让两个东西的概率比较相似.
把整个生成过程拉成了2步, 直观的理解每一步都有一个D, 在MDGAN中有D1,D2,在两步分别判断, 第一个D1 在判断真实数据和编码数据的差异,不再是真实数据和生成数据的分布, 第二步变成了, 编码数据和生成数据的差异,也不是判断生成数据和真实数据的分布.
现在相当于缩短了,判别器比较的两种样本之间的本来的差距, 理论上会认为, 真实程度是生成的最不真实, 编码的东西比较真实,真实的数据最真实, 利用编码器在最不真实和最真实之间加了一座桥,让D在两个桥之间比较,缩短了他们之间不相似的概率 , 不相似的程度也就增大了梯度的大小,


假设需要逼近6个高斯,传统的GAN会在训练过程中不停的绕,如果用Reg-Gan 的话,很快就会把 分布散开, 散开之后会慢慢逼近6个分布,最后拟合的会比较好.

实验结果减少了Mode-missing的概率生成了不同形态的人.

还有人引入了encoder 做各种各样的问题, 此外比较火的还有,BE-GAN , 是基于EB-GAN,他们两个长得很像:

EB-Gan在生成器上方加了一个encoder , 让Enc 数据传给Dec 最后输出一个MSE, 然后再综合起来输出一个E(能量),把一个能量函数作为了D的输出.
那么BE-GAN比较不一样,把后面的简化了.
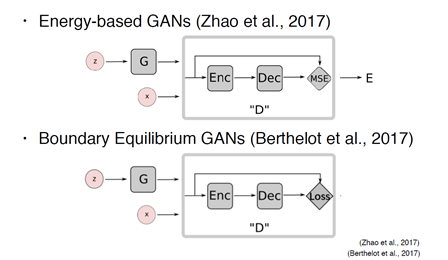
三个本质上都是通过encoder解决了一个问题, 解决了 PR和PG 有overlap 的问题 , 这个问题被很多人发现有更简单的解决办法, 可以概括为Noisy input, 我们只需要把样本和分布加一点点noise (其他空间的分布) , 就可以导致他们有overlap , JSD 就会变得很有指导意义.
1 之前也有人试验过 往生成器和 判别器的层里面加Noise
2 instance Noise,直接在image上面加Noise , 真实图像在传进去之前也要加Noise, 用这个简单的东西就可以实现让两个分布overlap
所以encoder的东西work 不work 还需要仔细探究一下.

最近有人给出了更加直观的解释:
从另一个角度理解,传统的A是我们希望的map,两个domain的图像,都是向左的map到一起,都是向右的map到一起,如果用传统Gan去学,会导致b的情况,Mode Missing的问题
这样会导致生成这样的东西很模糊,有点像生成的平均一样,可以和之前很多Gan的模型生成的比较模糊联系到一起
第三个是简单把一个Gan加一个encoder的办法,细节不一样,但是概括了刚才说的三种方法,

所以就有了后面三篇基本长得一样的论文
下一篇:Generative Adversarial Networks overview(2)
Generative Adversarial Networks overview(1)的更多相关文章
- Generative Adversarial Networks overview(2)
Libo1575899134@outlook.com Libo (原创文章,转发请注明作者) 本文章会先从Gan的简单应用示例讲起,从三个方面问题以及解决思路覆盖25篇GAN论文,第二个大部分会进一步 ...
- Generative Adversarial Networks overview(3)
Libo1575899134@outlook.com Libo (原创文章,转发请注明作者) 本文章主要介绍Gan的应用篇,3,主要介绍图像应用,4, 主要介绍文本以及医药化学其他领域应用 原理篇请看 ...
- Generative Adversarial Networks overview(4)
Libo1575899134@outlook.com Libo (原创文章,转发请注明作者) 本文章主要介绍Gan的应用篇,3,主要介绍图像应用,4, 主要介绍文本以及医药化学其他领域应用 原理篇请看 ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- 生成对抗网络(Generative Adversarial Networks, GAN)
生成对抗网络(Generative Adversarial Networks, GAN)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的学习方法之一. GAN 主要包括了两个部分,即 ...
- 论文解读(GAN)《Generative Adversarial Networks》
Paper Information Title:<Generative Adversarial Networks>Authors:Ian J. Goodfellow, Jean Pouge ...
- (转)Introductory guide to Generative Adversarial Networks (GANs) and their promise!
Introductory guide to Generative Adversarial Networks (GANs) and their promise! Introduction Neural ...
- 论文笔记之:Semi-Supervised Learning with Generative Adversarial Networks
Semi-Supervised Learning with Generative Adversarial Networks 引言:本文将产生式对抗网络(GAN)拓展到半监督学习,通过强制判别器来输出类 ...
- 《Self-Attention Generative Adversarial Networks》里的注意力计算
前天看了 criss-cross 里的注意力模型 仔细理解了 在: https://www.cnblogs.com/yjphhw/p/10750797.html 今天又看了一个注意力模型 < ...
随机推荐
- unity的yield
这里说的是Unity通过StartCoroutine开启IEnumerator协程里的yield相关 1.yield return 0,yield return null 等待下一帧接着执行下面的内容 ...
- [转帖]OLAP引擎这么多,为什么苏宁选择用Druid?
OLAP引擎这么多,为什么苏宁选择用Druid? 原创 51CTO 2018-12-21 11:24:12 [51CTO.com原创稿件]随着公司业务增长迅速,数据量越来越大,数据的种类也越来越丰富, ...
- [转帖]11G Undo使用率很高问题
11G Undo使用率很高问题 http://blog.itpub.net/12679300/viewspace-1164916/ 原创 Oracle 作者:wzq609 时间:2014-05-20 ...
- 2019 C/C++《阿里》面试题总结
一.C和C++的区别是什么? C是面向过程的语言,C++是在C语言的基础上开发的一种面向对象编程语言,应用广泛. C中函数不能进行重载,C++函数可以重载 C++在C的基础上增添类,C是一个结构化语言 ...
- Gridview中的编辑模板与项模板的用法
<asp:GridView ID="GridView1" AutoGenerateColumns="false" runat="server&q ...
- Java 8 HashMap 源码解析
HashMap 使用数组.链表和红黑树存储键值对,当链表足够长时,会转换为红黑树.HashMap 是非线程安全的. HashMap 中的常量 static final int DEFAULT_INIT ...
- .NET Core解析DNS域名或主机名的方法
在.NET Core中我们可以用System.Net.Dns类来解析域名或主机名的IP地址,我们新建一个.NET Core控制台项目,写入下面代码: using System; using Syste ...
- winform datagridview控件使用
最近做项目时,显示查询结果总需要绑定到datagridview控件上显示,总结了给datagridview绑定数据的方式,以及导出datagridview数据到excel表格,如有错误请多指教 1.直 ...
- "类"的讲稿
-----------------------面向对象基础------------------------------------方法(函数) { (c#p10为主,p27;javap96)+资料,讲 ...
- Golang 是否有必要内存对齐?
原文:https://ms2008.github.io/2019/08/01/golang-memory-alignment/ 内存模型 Posted by ms2008 on August 1, 2 ...