C++ 右值引用与move
C++ 右值引用与move
右值引用
T & ref = lvalue;
T && ref = rvalue;
看个例子:
int main(int argc, char** argv) {
// 左值引用
int i = ;
int &l = i;
//int &l = 10; // Error
cout << l << endl;
// 右值引用
int && r = ;
//int && r = i; // Error
int *p = &r;
cout << *p << endl;
return ;
}
可见,右值引用关联到右值时,右值被存储到特定位置,右值引用指向该特定位置,也就是说,右值虽然无法获取地址,但是右值引用是可以获取地址的,该地址表示临时对象的存储位置。
既然右值引用可以获取地址,左值引用虽然不能绑定右值,但能绑定右值引用,例如:
int &&r = ;
int &l = r;
l = ;
cout << r << endl; //
int main(int argc, char** argv) {
// const左值引用
const int &r = ;
//r = 11; // Error
const int* p = &r;
cout << *p << endl;
return ;
}
最后看一个例子:
class A {
public:
A(int x) :m(x) { cout<< "A(int) called" << endl; }
A(const A& other) {m=other.m; cout << "A(const A&)" << endl;}
~A() { cout<< "~A() called" << endl; }
int get() {return m;}
void set(int x) {m = x;}
private:
int m;
};
A getTemp(int x=) {
return A(x);
}
void AcceptVal(A a) {
}
void AcceptRef(const A& a) {
}
int main(int argc, char** argv) {
AcceptVal(getTemp()); // getTemp返回的是右值(临时变量),应该调用两次拷贝构造函数
AcceptRef(getTemp()); // const左值引用绑定右值, 应该只调用一次拷贝构造函数
return ;
}
说明:
getTemp函数返回值会先创建一个临时变量,该临时变量是右值,getTemp返回值拷贝给该变量:
如果将该变量以值传递调用函数AcceptVal(),实参到形参又会发生一次对象拷贝;
如果将该变量以引用传递调用函数AcceptRef(),形参是const左值引用,可以绑定右值(实参),不需要任何拷贝。
PS,以上代码编译需要关闭编译器返回值优化选项,g++ test.cpp -std=c++11 -fno-elide-constructors,否则会发现没有任何拷贝构造函数的调用!
以上,总结一下,其中T是一个具体类型:
- 左值引用, 使用
T&, 只能绑定左值; - 右值引用, 使用
T&&, 只能绑定右值; - 常量左值引用, 使用
const T&, 既可以绑定左值又可以绑定右值; - 已命名的右值引用,编译器会认为是个左值;
- 编译器有返回值优化,但不要过于依赖;
move操作
move函数在<utility>头文件中。
先看一个例子:
#include <iostream>
#include <cstring>
#include <vector>
using namespace std; class MyString
{
public:
static size_t CCtor; //统计调用拷贝构造函数的次数
// static size_t CCtor; //统计调用拷贝构造函数的次数
public:
// 构造函数
MyString(const char* cstr=){
if (cstr) {
m_data = new char[strlen(cstr)+];
strcpy(m_data, cstr);
}
else {
m_data = new char[];
*m_data = '\0';
}
} // 拷贝构造函数
MyString(const MyString& str) {
CCtor ++;
m_data = new char[ strlen(str.m_data) + ];
strcpy(m_data, str.m_data);
}
// 拷贝赋值函数 =号重载
MyString& operator=(const MyString& str){
if (this == &str) // 避免自我赋值!!
return *this; delete[] m_data;
m_data = new char[ strlen(str.m_data) + ];
strcpy(m_data, str.m_data);
return *this;
} ~MyString() {
delete[] m_data;
} char* get_c_str() const { return m_data; }
private:
char* m_data;
};
size_t MyString::CCtor = ; int main()
{
vector<MyString> vecStr;
vecStr.reserve(); //先分配好1000个空间,不这么做,调用的次数可能远大于1000
for(int i=;i<;i++){
vecStr.push_back(MyString("hello"));
}
cout << MyString::CCtor << endl;
}
1000次拷贝构造函数,如果MyString("hello")构造出来的字符串本来就很长,构造一遍就很耗时了,最后却还要拷贝一遍,而MyString("hello")只是临时对象,拷贝完就没什么用了,这就造成了没有意义的资源申请和释放操作,如果能够直接使用临时对象已经申请的资源,既能节省资源,又能节省资源申请和释放的时间。而C++11新增加的移动语义就能够做到这一点。改进版本:
#include <iostream>
#include <cstring>
#include <vector>
using namespace std; class MyString
{
public:
static size_t CCtor; //统计调用拷贝构造函数的次数
static size_t MCtor; //统计调用移动构造函数的次数
static size_t CAsgn; //统计调用拷贝赋值函数的次数
static size_t MAsgn; //统计调用移动赋值函数的次数 public:
// 构造函数
MyString(const char* cstr=){
if (cstr) {
m_data = new char[strlen(cstr)+];
strcpy(m_data, cstr);
}
else {
m_data = new char[];
*m_data = '\0';
}
} // 拷贝构造函数
MyString(const MyString& str) {
CCtor ++;
m_data = new char[ strlen(str.m_data) + ];
strcpy(m_data, str.m_data);
}
// 移动构造函数
MyString(MyString&& str) noexcept
:m_data(str.m_data) {
MCtor ++;
str.m_data = nullptr; //不再指向之前的资源了
} // 拷贝赋值函数 =号重载
MyString& operator=(const MyString& str){
CAsgn ++;
if (this == &str) // 避免自我赋值!!
return *this; delete[] m_data;
m_data = new char[ strlen(str.m_data) + ];
strcpy(m_data, str.m_data);
return *this;
} // 移动赋值函数 =号重载
MyString& operator=(MyString&& str) noexcept{
MAsgn ++;
if (this == &str) // 避免自我赋值!!
return *this; delete[] m_data;
m_data = str.m_data;
str.m_data = nullptr; //不再指向之前的资源了
return *this;
} ~MyString() {
delete[] m_data;
} char* get_c_str() const { return m_data; }
private:
char* m_data;
};
size_t MyString::CCtor = ;
size_t MyString::MCtor = ;
size_t MyString::CAsgn = ;
size_t MyString::MAsgn = ;
int main()
{
vector<MyString> vecStr;
vecStr.reserve(); //先分配好1000个空间
for(int i=;i<;i++){
vecStr.push_back(MyString("hello"));
}
cout << "CCtor = " << MyString::CCtor << endl;
cout << "MCtor = " << MyString::MCtor << endl;
cout << "CAsgn = " << MyString::CAsgn << endl;
cout << "MAsgn = " << MyString::MAsgn << endl;
} /* 结果
CCtor = 0
MCtor = 1000
CAsgn = 0
MAsgn = 0
*/
const MyString& str,是常量左值引用,而移动构造的参数是MyString&& str,是右值引用,而MyString("hello")是个临时对象,是个右值,优先进入移动构造函数而不是拷贝构造函数。而移动构造函数与拷贝构造不同,它并不是重新分配一块新的空间,将要拷贝的对象复制过来,而是"偷"了过来,将自己的指针指向别人的资源,然后将别人的指针修改为nullptr,这一步很重要,如果不将别人的指针修改为空,那么临时对象析构的时候就会释放掉这个资源,"偷"也白偷了。下面这张图可以解释copy和move的区别。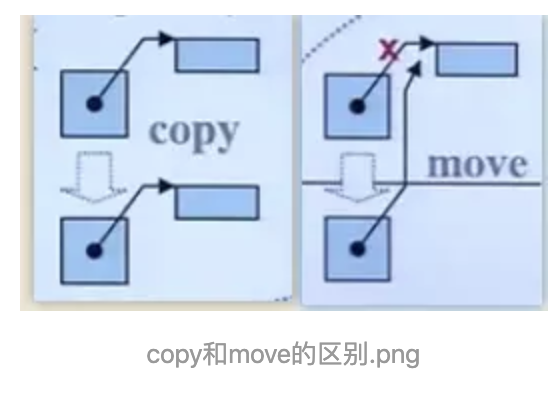
上面是对一个右值,可以进入移动构造函数,如果对于一个左值,肯定是优先调用拷贝构造函数了,但是有些左值是局部变量,生命周期也很短,能不能也移动而不是拷贝呢?C++11为了解决这个问题,提供了std::move()方法来将左值转换为右值,从而方便应用移动语义。我觉得它其实就是告诉编译器,虽然我是一个左值,但是不要对我用拷贝构造函数,而是用移动构造函数吧。。。
int main()
{
vector<MyString> vecStr;
vecStr.reserve(); //先分配好1000个空间
for(int i=;i<;i++){
MyString tmp("hello");
vecStr.push_back(tmp); //调用的是拷贝构造函数
}
cout << "CCtor = " << MyString::CCtor << endl;
cout << "MCtor = " << MyString::MCtor << endl;
cout << "CAsgn = " << MyString::CAsgn << endl;
cout << "MAsgn = " << MyString::MAsgn << endl; cout << endl;
MyString::CCtor = ;
MyString::MCtor = ;
MyString::CAsgn = ;
MyString::MAsgn = ;
vector<MyString> vecStr2;
vecStr2.reserve(); //先分配好1000个空间
for(int i=;i<;i++){
MyString tmp("hello");
vecStr2.push_back(std::move(tmp)); //调用的是移动构造函数
}
cout << "CCtor = " << MyString::CCtor << endl;
cout << "MCtor = " << MyString::MCtor << endl;
cout << "CAsgn = " << MyString::CAsgn << endl;
cout << "MAsgn = " << MyString::MAsgn << endl;
} /* 运行结果
CCtor = 1000
MCtor = 0
CAsgn = 0
MAsgn = 0 CCtor = 0
MCtor = 1000
CAsgn = 0
MAsgn = 0
*/
再看几个例子
MyString str1("hello"); //调用构造函数
MyString str2("world"); //调用构造函数
MyString str3(str1); //调用拷贝构造函数
MyString str4(std::move(str1)); // 调用移动构造函数、
// cout << str1.get_c_str() << endl; // 此时str1的内部指针已经失效了!不要使用
//注意:虽然str1中的m_dat已经称为了空,但是str1这个对象还活着,知道出了它的作用域才会析构!而不是move完了立刻析构
MyString str5;
str5 = str2; //调用拷贝赋值函数
MyString str6;
str6 = std::move(str2); // str2的内容也失效了,不要再使用
需要注意一下几点:
str6 = std::move(str2),虽然将str2的资源给了str6,但是str2并没有立刻析构,只有在str2离开了自己的作用域的时候才会析构,所以,如果继续使用str2的m_data变量,可能会发生意想不到的错误。- 如果我们没有提供移动构造函数,只提供了拷贝构造函数,
std::move()会失效但是不会发生错误,因为编译器找不到移动构造函数就去寻找拷贝构造函数,也这是拷贝构造函数的参数是const T&常量左值引用的原因! c++11中的所有容器都实现了move语义,move只是转移了资源的控制权,本质上是将左值强制转化为右值使用,以用于移动拷贝或赋值,避免对含有资源的对象发生无谓的拷贝。move对于拥有如内存、文件句柄等资源的成员的对象有效,如果是一些基本类型,如int和char[10]数组等,如果使用move,仍会发生拷贝(因为没有对应的移动构造函数),所以说move对含有资源的对象说更有意义。
通用引用(universal references)
当右值引用和模板结合的时候,就复杂了。T&&并不一定表示右值引用,它可能是个左值引用又可能是个右值引用。例如:
template<typename T>
void f( T&& param){ }
f(); //10是右值
int x = ; //
f(x); //x是左值
如果上面的函数模板表示的是右值引用的话,肯定是不能传递左值的,但是事实却是可以。这里的&&是一个未定义的引用类型,称为universal references,它必须被初始化,它是左值引用还是右值引用却决于它的初始化,如果它被一个左值初始化,它就是一个左值引用;如果被一个右值初始化,它就是一个右值引用。
注意:只有当发生自动类型推断时(如函数模板的类型自动推导,或auto关键字),&&才是一个universal references。
template<typename T>
void f( T&& param); //这里T的类型需要推导,所以&&是一个 universal references template<typename T>
class Test {
Test(Test&& rhs); //Test是一个特定的类型,不需要类型推导,所以&&表示右值引用
}; void f(Test&& param); //右值引用 //复杂一点
template<typename T>
void f(std::vector<T>&& param); //在调用这个函数之前,这个vector<T>中的推断类型
//已经确定了,所以调用f函数的时候没有类型推断了,所以是 右值引用 template<typename T>
void f(const T&& param); //右值引用
// universal references仅仅发生在 T&& 下面,任何一点附加条件都会使之失效
所以最终还是要看T被推导成什么类型,如果T被推导成了string,那么T&&就是string&&,是个右值引用,如果T被推导为string&,就会发生类似string& &&的情况,对于这种情况,c++11增加了引用折叠的规则,总结如下:
- 所有的右值引用叠加到右值引用上仍然使一个右值引用。
- 所有的其他引用类型之间的叠加都将变成左值引用。
#include <iostream>
#include <type_traits>
#include <string>
using namespace std; template<typename T>
void f(T&& param){
if (std::is_same<string, T>::value)
std::cout << "string" << std::endl;
else if (std::is_same<string&, T>::value)
std::cout << "string&" << std::endl;
else if (std::is_same<string&&, T>::value)
std::cout << "string&&" << std::endl;
else if (std::is_same<int, T>::value)
std::cout << "int" << std::endl;
else if (std::is_same<int&, T>::value)
std::cout << "int&" << std::endl;
else if (std::is_same<int&&, T>::value)
std::cout << "int&&" << std::endl;
else
std::cout << "unkown" << std::endl;
} int main()
{
int x = ;
f(); // 参数是右值 T推导成了int, 所以是int&& param, 右值引用
f(x); // 参数是左值 T推导成了int&, 所以是int&&& param, 折叠成 int&,左值引用
int && a = ;
f(a); //虽然a是右值引用,但它还是一个左值, T推导成了int&
string str = "hello";
f(str); //参数是左值 T推导成了string&
f(string("hello")); //参数是右值, T推导成了string
f(std::move(str));//参数是右值, T推导成了string
}
所以,归纳一下, 传递左值进去,就是左值引用,传递右值进去,就是右值引用。如它的名字,这种类型确实很"通用",下面要讲的完美转发,就利用了这个特性。
完美转发
void process(int& i){
cout << "process(int&):" << i << endl;
}
void process(int&& i){
cout << "process(int&&):" << i << endl;
}
void myforward(int&& i){
cout << "myforward(int&&):" << i << endl;
process(i);
}
int main()
{
int a = ;
process(a); //a被视为左值 process(int&):0
process(); //1被视为右值 process(int&&):1
process(move(a)); //强制将a由左值改为右值 process(int&&):0
myforward(); //右值经过forward函数转交给process函数,却称为了一个左值,
//原因是该右值有了名字 所以是 process(int&):2
myforward(move(a)); // 同上,在转发的时候右值变成了左值 process(int&):0
// forward(a) // 错误用法,右值引用不接受左值
}
上面的例子就是不完美转发,而c++中提供了一个std::forward()模板函数解决这个问题。将上面的myforward()函数简单改写一下:
void RunCode(int &&m) {
cout << "rvalue ref" << endl;
}
void RunCode(int &m) {
cout << "lvalue ref" << endl;
}
void RunCode(const int &&m) {
cout << "const rvalue ref" << endl;
}
void RunCode(const int &m) {
cout << "const lvalue ref" << endl;
}
// 这里利用了universal references,如果写T&,就不支持传入右值,而写T&&,既能支持左值,又能支持右值
template<typename T>
void perfectForward(T && t) {
RunCode(forward<T> (t));
}
template<typename T>
void notPerfectForward(T && t) {
RunCode(t);
}
int main()
{
int a = ;
int b = ;
const int c = ;
const int d = ;
notPerfectForward(a); // lvalue ref
notPerfectForward(move(b)); // lvalue ref
notPerfectForward(c); // const lvalue ref
notPerfectForward(move(d)); // const lvalue ref
cout << endl;
perfectForward(a); // lvalue ref
perfectForward(move(b)); // rvalue ref
perfectForward(c); // const lvalue ref
perfectForward(move(d)); // const rvalue ref
}
上面的代码测试结果表明,在universal references和std::forward的合作下,能够完美的转发这4种类型。
emplace*函数
vector一般都喜欢用push_back(),由上文可知容易发生无谓的拷贝,解决办法是为自己的类增加移动拷贝和赋值函数,但其实还有更简单的办法!就是使用emplace_back()替换push_back(),如下面的例子:class A {
public:
A(int i){
// cout << "A()" << endl;
str = to_string(i);
}
~A(){}
A(const A& other): str(other.str){
cout << "A&" << endl;
}
public:
string str;
};
int main()
{
vector<A> vec;
vec.reserve();
for(int i=;i<;i++){
vec.push_back(A(i)); //调用了10次拷贝构造函数
// vec.emplace_back(i); //一次拷贝构造函数都没有调用过
}
for(int i=;i<;i++)
cout << vec[i].str << endl;
}
emplace_back()可以直接通过构造函数的参数构造对象,但前提是要有对应的构造函数。
对于map和set,可以使用emplace()。基本上emplace_back()对应push_bakc(), emplce()对应insert()。
移动语义对swap()函数的影响也很大,之前实现swap可能需要三次内存拷贝,而有了移动语义后,就可以实现高性能的交换函数了。
template <typename T>
void swap(T& a, T& b)
{
T tmp(std::move(a));
a = std::move(b);
b = std::move(tmp);
}
如果T是可移动的,那么整个操作会很高效,如果不可移动,那么就和普通的交换函数是一样的,不会发生什么错误,很安全。
C++ 右值引用与move的更多相关文章
- 右值引用、move与move constructor
http://blog.chinaunix.net/uid-20726254-id-3486721.htm 这个绝对是新增的top特性,篇幅非常多.看着就有点费劲,总结更费劲. 原来的标准当中,参数与 ...
- c++ 右值引用,move关键字
c++ move关键字 move的由来:在 c++11 以前存在一个有趣的现象:T& 指向 lvalue (左传引用), const T& 既可以指向 lvalue 也可以指向 rv ...
- C++11中的右值引用及move语义编程
C++0x中加入了右值引用,和move函数.右值引用出现之前我们只能用const引用来关联临时对象(右值)(造孽的VS可以用非const引用关联临时对象,请忽略VS),所以我们不能修临时对象的内容,右 ...
- [转载]如何在C++03中模拟C++11的右值引用std::move特性
本文摘自: http://adamcavendish.is-programmer.com/posts/38190.htm 引言 众所周知,C++11 的新特性中有一个非常重要的特性,那就是 rvalu ...
- c++11 右值引用、move、完美转发forward<T>
#include <iostream> #include <string> using namespace std; template <typename T> v ...
- 翻译「C++ Rvalue References Explained」C++右值引用详解 Part6:Move语义和编译器优化
本文为第六部分,目录请参阅概述部分:http://www.cnblogs.com/harrywong/p/cpp-rvalue-references-explained-introduction.ht ...
- 翻译「C++ Rvalue References Explained」C++右值引用详解 Part1:概述
本文系对「C++ Rvalue References Explained」 该文的翻译,原文作者:Thomas Becker. 该文较详细的解释了C++11右值引用的作用和出现的意义,也同时被Scot ...
- C++11新特性之0——移动语义、移动构造函数和右值引用
C++引用现在分为左值引用(能取得其地址)和 右值引用(不能取得其地址).其实很好理解,左值引用中的左值一般指的是出现在等号左边的值(带名称的变量,带*号的指针等一类的数据),程序能对这样的左值进行引 ...
- 详解C++右值引用
C++0x标准出来很长时间了,引入了很多牛逼的特性[1].其中一个便是右值引用,Thomas Becker的文章[2]很全面的介绍了这个特性,读后有如醍醐灌顶,翻译在此以便深入理解. 目录 概述 mo ...
随机推荐
- 删除或关闭Word中的超链接
最近使用的word老是会把一些文字内容或者标题转换成乱七八糟的格式,看的莫名其妙的,找了好久也不知道什么问题,后来一查才知道是因为这些文字包含超链接,word自动转换了...你说是不是莫名其妙. 要关 ...
- php代理模式(proxy design)
结构模式最后一个,接着进入行为模式. <?php /* The proxy design pattern functions as an interface to an original obj ...
- Find the median(2019年牛客多校第七场E题+左闭右开线段树)
题目链接 传送门 题意 每次往集合里面添加一段连续区间的数,然后询问当前集合内的中位数. 思路 思路很好想,但是卡内存. 当时写的动态开点线段树没卡过去,赛后机房大佬用动态开点过了,\(tql\). ...
- 2019年牛客多校第四场 B题xor(线段树+线性基交)
题目链接 传送门 题意 给你\(n\)个基底,求\([l,r]\)内的每个基底是否都能异或出\(x\). 思路 线性基交板子题,但是一直没看懂咋求,先偷一份咖啡鸡板子写篇博客吧~ 线性基交学习博客:传 ...
- Spring Cloud 之 Gateway 知识点:网关
Spring Cloud Gateway 是使用 netty+webflux 实现因此不需要再引入 web 模块. Spring Cloud Gateway 提供了一种默认转发的能力,只要将 Spri ...
- mac 上配置flutter开发环境
(ios,Android,Xcode,Android Studio,VScode,IDEA) 1)安装Flutter SDK 2)iOS 环境配置 3)Android Studio配置 4)VS co ...
- 兰伯特余弦定理(Lambert)
兰伯特余弦定理(Lambert) 1.漫反射,是投射在粗糙表面上的光向各个方向反射的现象.当一束平行的入射光线射到粗糙的表面时,表面会把光线向着四面八方反射,所以入射线虽然互相平行,由于各点的法线方向 ...
- EFK收集nginx日志
准备三台centos7的服务器 两核两G的 关闭防火墙和SELinux systemctl stop firewalld setenforce 0 1.每一台都安装jdk rpm -ivh jdk-8 ...
- vim命令(转)
1.Linux下创建文件 vi test.txt 或者 vim test.txt 或者 touch test.txt 2.vi/vim 使用 基本上 vi/vim 共分为三种模式,分别是命令模式(Co ...
- HGNC数据库 HUGO基因命名委员会
http://www.genenames.org/ HGNC 全称为HUGO Gene Nomenclature Committee, 叫做 HUGO基因命名委员会,负责对人类基因组上包括蛋白编码基因 ...