Improving Sequential Recommendation with Knowledge-Enhanced Memory Networks(知识图谱)

本文作者:杨昆霖,2015级本科生,目前研究方向为知识图谱,推荐系统,来自中国人民大学大数据管理与分析方法研究北京市重点实验室。
引言
经常上购物网站时,注意力会被首页上的推荐吸引过去,往往本来只想买一件小商品,但却被推荐商品耗费不少时间与金钱。有时候会在想,虽然推荐商品挺吸引人的,但是它究竟为什么给出这些推荐,背后的原因却往往不得而知。本文将介绍的这篇SIGIR 2018论文提出了新的序列化推荐模型KSR(Knowledge-enhanced Sequential Recommender),利用了知识图谱与记忆网络,在提高推荐结果准确性的同时,还能捕捉更为细致的用户偏好,提高推荐系统的可解释性。
问题背景
相信推荐系统对大家并不陌生,众多互联网公司也花了大功夫在构建推荐系统上。为了给出精准的推荐,首先需要把握用户在想什么,对什么感兴趣,而这往往不是一成不变的,会随着用户在平台上的活动而日益变化。鉴于此,相较于以往的协同过滤等推荐方式,学术界提出基于时序神经模型的序列化推荐系统,利用循环神经网络RNN来捕捉用户兴趣点随着时间的动态变化。
在序列化推荐建模中,通常将用户过去的交互记录作为输入,利用隐状态向量来编码各个交互记录,以此来表示用户在序列中体现的偏好。但是,这种方法有两个不足之处:
- 只考虑了用户序列偏好,却忽视了细致的用户偏好,如用户具体喜欢某个物品的哪个属性等;
- 推荐过程中的隐含特征向量表示过于抽象,难以解释其推荐结果。
解决思路
本文的主要贡献在于用使用了融合知识库信息的记忆网络,通过细致地刻画用户对物品属性偏好提高准确率的同时,还增强了推荐系统的可解释性。
为了捕捉用户对物品属性偏好与增强可解释性,本文将知识库信息与商品信息结合。
为了将知识库信息与融入推荐系统,本文使用了键值对记忆网络(Key-Value Memory Networks)。
具体做法
因为从用户与商品的交互记录中只能体现出商品的隐语义模型,还不够更细粒度地刻画用户对商品的偏好,于是,本文借助知识库(knowledge base)中的实体(entity)信息来表示推荐物品在不同属性的特征,这样既可以更为细致地刻画物品,又可以增强可解释性。如一首歌曲拥有歌手、专辑等属性,通过知识库我们可以得知这些属性对应的具体实体,来利用embedding的方式(如TransE)可以将这个实体在知识库中的上下文信息(context)转化成一个嵌入向量(embeddings),也就是特征表示向量。本文选用的知识库是FreeBase,将数据集中的商品与知识库中已有的实体连接在一起。至此,每个物品除了有由交易历史得到的一个特征表示向量之外(此处本文使用bayesian personalized ranking),在其每个属性之上还会获得一个特征表示向量。
至于实体中的特征表示向量如何得到,这里以TransE为例进行说明。知识库中每一条数据都是一个三元组,每个三元组包含两个实体及实体间的关系,如(头实体A,关系R,尾实体B)。我们希望实体A+关系R与实体B在空间中的表示尽可能接近,英剧福尔摩斯(头实体A)+主演(关系R)应该约等于本尼迪(尾实体B)。
与现实理解不同的是,在知识库中每个实体与关系都是空间中的向量,我们以三元组的误差最小化为来训练即可得到对应的特征表示向量。但现在有个问题,主演不仅包含本尼迪,还有马丁,那么这样如何区分本尼迪与马丁的不同呢?本文对于每个目标实体,不直接使用目标实体的特征表示向量,而是使用物体特征表示向量+关系特征表示向量的方式。例如,对于本尼迪,不直接使用本尼迪的特征表示向量,而是使用英剧福尔摩斯+主演的特征表示向量和来作为阿凡达影片导演属性的特征表示向量。如下式就代表物品i的a属性 由物品i的实体
及其与属性a
的关系之和来表示。
当然,每个物体拥有那么多属性,将每个属性的特征表示向量全部都拼接在一起,计算量太大。本文将每个属性向量加权后求和,得到一个向量 来表示每个用户的细粒度兴趣,这里的权重
为用户对每个属性的关注程度,权重与属性的键
和当前序列偏好有关,如下式所示:
那么,在解决了细粒度表示与解释性问题之后,就要开始考虑如何将其与序列化推荐模型结合在一起。本文利用门控循环神经网络(Gated Recurrent Unit,简称GRU)来构建序列化推荐模型,然而GRU尽管可以记忆相邻几个节点的信息,但对于长期记忆存储知识库实体信息来说,GRU的记忆还是过于短暂。因此,本文引入了记忆网络(Memory Networks)来存储不同属性的信息,与知识库交互。
记忆网络利用精确的记忆机制来解决神经网络的信息记忆问题。它使用外部数组来存储要被“记忆”的数据,这个数组可以被神经网络反复读取,存储在数组中的信息也可以被更新或者扩展。本文使用记忆网络来管理物品属性时,考虑到物品的每个属性相对独立,本扩展了基础的记忆网络,使用键值对记忆网络(Key-Value Memory Networks,KV-MN)来更好的使用信息,其中,键为知识库中的关系(relation),值为对应的实体。需要注意的是,键因为表示的是物品与属性的关系,与用户无关,因此所有用户共享相同的键矩阵;而不同的用户对于不同属性的偏好有着较大差别,故值矩阵为用户私有,每个用户都有自己的值矩阵。由此不难发现,推荐模型中的物品,记忆网络中的键值对,正好与知识库的三元组相对应(物品,键(属性),值)。
现在问题转化为记忆网络与GRU的结合问题。为了同时考虑用户序列偏好与商品属性偏好,在GRU推荐的每一个节点,均可以得到一个序列偏好表示向量,利用该向量对键值对记忆网络进行查询,便可得到用户对每个属性的偏好表示。将两个向量拼接在一起得到的新向量,就可以更为全面地刻画用户的属性,既包括用户在序列中的偏好,又体现用户对物体属性的细致偏好。大致的流程可以参照下图:
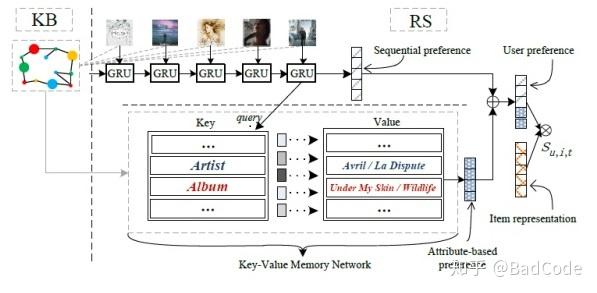
由上图还可以看到,对于键值对记忆网络,有个写入(write)和读取(read)的过程,这同时也是记忆网络最基本的操作之二。对于读取操作,根据之前所说,需要输入一个查询,也就是当前时刻的序列偏好向量 ,根据这个向量,按照前文所述,将序列偏好向量与属性偏好项量加权求和之后即得到最终的偏好向量
。
对于写入操作,目的是根据当前时刻感兴趣的物品来更新对各个属性的兴趣程度,于是就需要同时考虑两方面因素,当前物品的特征表示向量和当前用户的属性偏好向量。为了决定每个属性应该更新多少信息,本文先计算得到了一个门向量 z_a ,通过该门向量来对属性偏好向量进行更新。门向量的考量因素是物品特征表示向量 与对应属性的特征表示向量
,具体见下式:
经过这样的更新,本文模型就可以在用户的属性级别上长期检测用户兴趣偏好,并及时更新纳入推荐系统。写入操作具体如下:
本文的模型如下图所示:
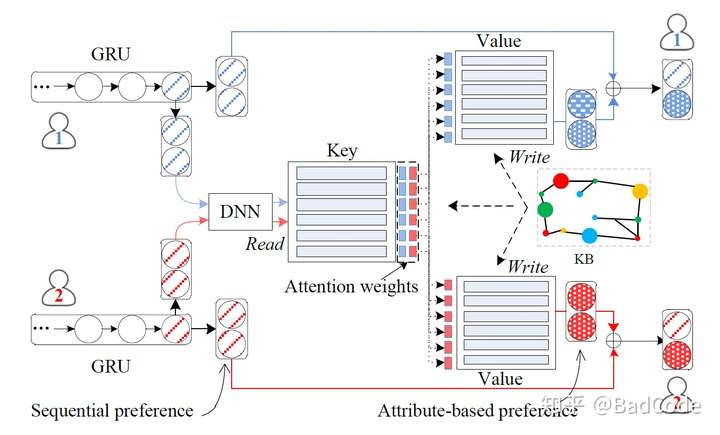
首先,GRU网络根据短程记忆得出用户序列兴趣表示向量;接着,键值对记忆网络根据GRU的表示向量与商品本身的特征表示向量得到细致的用户偏好特征表示向量,并于序列兴趣向量连接;最后,根据用户对各个兴趣的权重,即可解释推荐系统产生推荐的原因。
具体如何体现模型的解释性可以见下图:
 推荐过程阐述图
推荐过程阐述图
图中最上方的代表时间轴;第二行代表每个商品所具有的属性,也就是记忆网络中的键,此处以歌手和专辑为例;第三行为每个属性所产生的推荐列表。从图中第二行可以发现,一开始初始化时,推荐系统觉得用户更喜欢歌曲的专辑(一开始歌手权重较小,方框颜色较浅,专辑权重较大,颜色较深);后来随着时间的推移,推荐系统渐渐发现用户更喜欢歌曲的歌手而不是专辑(歌手方框颜色变深,专辑变浅)。从第三行可以发现,一开始推荐系统的判断是错误的,产生的推荐列表也不那么准确,但是时间越长,判断也趋向于准确,并且也给出了推荐理由,用户想听这个歌手的歌而不是这个专辑的歌。
总结
本文针对序列化推荐系统不具有解释性,无法获取用户细粒度特征的特点,提出了利用结合知识库的记忆网络来增强推荐系统的特征捕获能力与解释性,不仅获得了更高的准确率,还使得推荐系统具有了较强的解释性。并且实验结果表面,该模型比以往的模型在准确率与解释性方面均有显著突破。
本论文原文链接:https://pan.baidu.com/s/1WWhpHBjYpiftLcSAC8w3xA 密码:v19f
(SIGIR 2018 proceedings还未出 先用网盘代替)
Improving Sequential Recommendation with Knowledge-Enhanced Memory Networks(知识图谱)的更多相关文章
- 1. 通俗易懂解释知识图谱(Knowledge Graph)
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 从一开始的Google搜索,到现在的聊天机器人.大数据风控 ...
- Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation(知识图谱)
知识图谱(Knowledge Graph,KG)可以理解成一个知识库,用来存储实体与实体之间的关系.知识图谱可以为机器学习算法提供更多的信息,帮助模型更好地完成任务. 在推荐算法中融入电影的知识图谱, ...
- LSTM学习—Long Short Term Memory networks
原文链接:https://colah.github.io/posts/2015-08-Understanding-LSTMs/ Understanding LSTM Networks Recurren ...
- 论文笔记:Learning Dynamic Memory Networks for Object Tracking
Learning Dynamic Memory Networks for Object Tracking ECCV 2018Updated on 2018-08-05 16:36:30 Paper: ...
- End-To-End Memory Networks
End-To-End Memory Networks 2019-05-20 14:37:35 Paper:https://papers.nips.cc/paper/5846-end-to-end-me ...
- 哈工大知识图谱(Knowledge Graph)课程概述
一.什么是知识图谱 知识(Knowledge)可以理解为 精炼的数据,知识图谱(Knowledge Graph)即是对知识的图形化表示,本质上是一种大规模语义网络 (semantic network) ...
- 知识图谱顶刊综述 - (2021年4月) A Survey on Knowledge Graphs: Representation, Acquisition, and Applications
知识图谱综述(2021.4) 论文地址:A Survey on Knowledge Graphs: Representation, Acquisition, and Applications 目录 知 ...
- Semantic Parsing(语义分析) Knowledge base(知识图谱) 对用户的问题进行语义理解 信息检索方法
简单说一下所谓Knowledge base(知识图谱)有两条路走,一条是对用户的问题进行语义理解,一般用Semantic Parsing(语义分析),语义分析有很多种,比如有用CCG.DCS,也有用机 ...
- 学习笔记之知识图谱 (Knowledge Graph)
Knowledge Graph - Wikipedia https://en.wikipedia.org/wiki/Knowledge_Graph The Knowledge Graph is a k ...
随机推荐
- Appium脚本(5) 元素等待方法示例
思考 在自动化过程中,元素出现受网络环境,设备性能等多种因素影响.因此元素加载的时间可能不一致,从而会导致元素无法定位超时报错,但是实际上元素是正常加载了的,只是出现时间晚一点而已.那么如何解决这个问 ...
- 推荐一款好用的免费FTP客户端Filezilla
官网地址:https://filezilla-project.org/
- Zipkin+Sleuth 链路追踪整合
1.Zipkin 是一个开放源代码分布式的跟踪系统 它可以帮助收集服务的时间数据,以解决微服务架构中的延迟问题,包括数据的收集.存储.查找和展现 每个服务向zipkin报告计时数据,zipkin会根据 ...
- xmlrpc与jsonrpc
RPC是Remote Procedure Call的缩写,翻译成中文就是远程过程调用,是一种在本地的机器上调用远端机器上的一个过程(方法)的技术,这个过程也被大家称为“分布式计算”,是为了提高各个分立 ...
- 【LOJ502】[LibreOJ β Round] ZQC 的截图 (随机化)
真的是神仙题目啊-- 题目 LOJ502 官方题解 我认为官方题解比我讲得好. 分析 这是一道蒙特卡洛算法的好题 上面那个奇奇怪怪的词是从官方题解里看到的,意思大概就是随机化算法 -- ? 一句话题意 ...
- Java IO 与 NIO 服务器&客户端通信小栗子
本篇包含了入门小栗子以及一些问题的思考 BIO package com.demo.bio; import java.io.*; import java.net.ServerSocket; import ...
- [转帖]POW , POS 与 DPOS 一切都为了共识
POW , POS 与 DPOS 一切都为了共识 https://www.jianshu.com/p/f99e8fe57c9a 共识机制的背景 加密货币都是去中心化的,去中心化的基础就是P2P节点 ...
- Sqlite清空表数据以及重新设置主键操作
Sqlite清空表数据以及重新设置主键操作 delete from 表名; //清空数据 update sqlite_sequence SET seq = 0 where name ='表名';//自 ...
- ubuntu 安装和配置 GitLab
一.概述 GitLab 是一个基于 Web 的开源 Git 软件仓库管理器,用 Ruby 编写,包括 wiki,问题管理,代码审查,监控以及持续集成和部署.它使开发人员能够创建,审查和部署他们的项目. ...
- pytest_用例a失败,跳过测试用例b和c并标记失败xfail
前言 当用例a失败的时候,如果用例b和用例c都是依赖于第一个用例的结果,那可以直接跳过用例b和c的测试,直接给他标记失败xfail用到的场景,登录是第一个用例,登录之后的操作b是第二个用例,登录之后操 ...