Tachyon内存文件系统快速入门
一.简介
Tachyon是介于磁盘存储和计算框架之间的一种中间件,用于实现分布式的内存文件读写等功能,实现分布式集群内部共享数据。
应用实例:
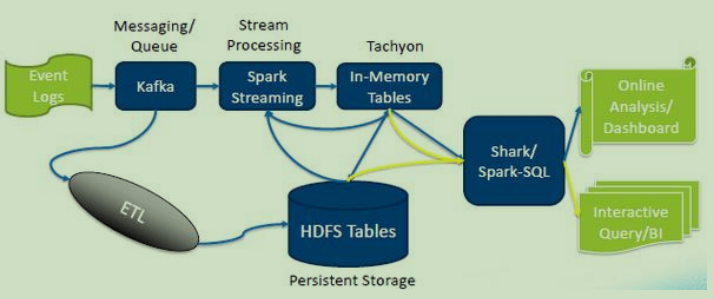
二.架构
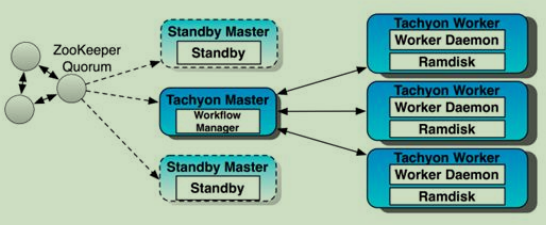
1.心跳机制
在Tachyon中,心跳用于Master/Worker/Client之间的定期通信以及Master/Worker自身的状态自检。
>Client向Master发送心跳信号,表示Client仍处在连接中,Client释放连接后重新获取连接会获得新的UserId。
>Client向Worker发送心跳信号,表示Client仍处在连接中,Client释放连接后Worker会回收该Client的用户空间。
>Worker自检,向Master发送心跳信号,Worker将自己的存储空间信息更新给Master【容量,移除的块信息】,同时清理超时的用户,回收用户空间。
>Master自检,检查所有Worker的状态,若有Worker失效,会统计丢失的文件并尝试重启该Worker。
2.文件组织
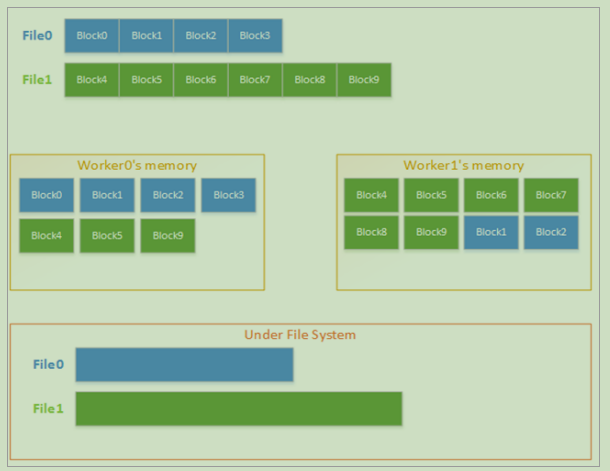
备注:与HDFS类似,Tachyon文件存储也是以块为单位的,在存储时,会先把文件拆分成一个一个的块,之后根据存储级别以及备份策略把一个一个的块分别存储到不同的节点之上。
3.容错机制
作为分布式文件系统,Tachyon具有良好的容错机制,Master和Worker都有自己的容错方式。从之前的系统架构图中可以看出,Master支持使用Zookeeper进行容错。同时,Master中保存的元数据使用Journal进行容错,具体包括Editlog记录所有对元数据的操作,以及Image持久化元数据信息。此外,Master还对各个Worker的状态进行监控,发现Worker失效时会自动重启对应的Worker。对于具体的文件数据,使用血统关系【Lineage】进行容错。文件元数据中记录了文件之间的依赖关系,当文件丢失时,能够根据依赖关系进行重计算来恢复文件数据。默认情况下,Lineage没有打开,可以设置tachyon.user.lineage.enabled=true。
Tachyon内存文件系统快速入门的更多相关文章
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- Tachyon:Spark生态系统中的分布式内存文件系统
转自: http://www.csdn.net/article/2015-06-25/2825056 摘要:Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专注计算的本身, ...
- OpenStack云计算快速入门之一:OpenStack及其构成简介
原文:http://blog.chinaunix.net/uid-22414998-id-3263551.html OpenStack云计算快速入门(1) 该教程基于Ubuntu12.04版,它将帮助 ...
- Linux快速入门02-文件系统管理
继续进入Linux文件系统的学习,加油,早日突破MS压在自己身上的那道束缚. Linux系列文章 快速入门系列--Linux--01基础概念 快速入门系列--Linux--02文件系统管理 快速入门系 ...
- Linux快速入门03-系统管理
这部分将涉及常用的各类linux命令和一些系统高级管理特性,尤其是shell script的创建,这部分在系统自动化运维时会很有作用. Linux系列文章 快速入门系列--Linux--01基础概念 ...
- 【转】Flask快速入门
迫不及待要开始了吗?本页提供了一个很好的 Flask 介绍,并假定你已经安装好了 Flask.如果没有,请跳转到 安装 章节. 一个最小的应用 一个最小的 Flask 应用看起来会是这样: from ...
- Node.js快速入门
Node.js是什么? Node.js是建立在谷歌Chrome的JavaScript引擎(V8引擎)的Web应用程序框架. 它的最新版本是:v0.12.7(在编写本教程时的版本).Node.js在官方 ...
- Node.js API快速入门
Node.js API 快速入门 一.事件EventEmitter const EventEmitter = require('events'); class MyEmitter extends Ev ...
- Hadoop生态圈-大数据生态体系快速入门篇
Hadoop生态圈-大数据生态体系快速入门篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.大数据概念 1>.什么是大数据 大数据(big data):是指无法在一定时间 ...
随机推荐
- 【Linux】bat文件如何执行
绝对路径,"/home/myDir/xxx.bat" OR 所在的目录,:"./xxx.bat".
- zzulioj - 2597: 角谷猜想2
题目链接: http://acm.zzuli.edu.cn/problem.php?id=2597 题目描述 大家想必都知道角谷猜想,即任何一个自然数,如果是偶数,就除以2,如果是奇数,就乘以3再加1 ...
- csv与openpyxl函数
csv 与openpyxl函数 csv函数 常用的存储数据的方式有两种--存储成csv格式文件.存储成Excel文件(不是复制黏贴的那种) 前面,我有讲到json是特殊的字符串.其实,csv也是一种字 ...
- GoogleHacking语法篇
常用GoogleHacking语法: 1.intext:(仅针对Google有效) 把网页中的正文内容中的某个字符作为搜索的条件 2.intitle: 把网页标题中的某个字符作为搜索的条件 3.cac ...
- 【BZOJ3508】开灯
[BZOJ3508]开灯 题面 bzoj 题解 其实变为目标操作和从目标操作变回来没有区别,我们考虑从目标操作变回来. 区间整体翻转(\(\text{Xor}\;1\))有点难受,我们考虑将这个操作放 ...
- 不刷新网页修改url链接:history.pushState()和history.replaceState()新增、修改历史记录用法介绍
最近遇到了在不刷新页面的情况下修改浏览器url链接的需求,考虑到可以通过history.pushState()解决.现在将我理解的一些内容分享一下,不对的地方欢迎大家指出. 在使用方法前首先需要了解它 ...
- 第02组Alpha冲刺(3/4)
队名:十一个憨批 组长博客 作业博客 组长黄智 过去两天完成的任务:写博客,复习C语言 GitHub签入记录 接下来的计划:构思游戏实现 还剩下哪些任务:敲代码 燃尽图 遇到的困难:Alpha冲刺时间 ...
- ZROI 暑期高端峰会 A班 Day6 DP
[THUPC2018]城市地铁规划 (日常讲题之前 YY--) 一眼出 \(O(n^3+nk)\) 做法. \(dp[i][j]\) 表示前 \(i\) 个点,前 \(i\) 个点度数和为 \(j\) ...
- LOAM笔记
CSDN有篇结合paper分析代码的博文,下面是我对paper的理解: 1. 综述 整个LOAM本质就是一个激光里程计,没有闭环检测,也就没有图优化框架在里面,该算法把SLAM问题分为两个算法同时运行 ...
- vultr的防火墙注意事项
如下图所示,你设置让任意IP的TCP,UDP,GRE,ESP,ICMP都允许访问,并不表示开放了任意协议和端口了. 下图只是表示开放了TCP,UDP,GRE,ESP,ICMP五个协议,比如ROS路由的 ...