【转】用Python做股市量化策略投资数据分析
金融量化分析介绍
本文摘要;
金融量化分析介绍
1、什么是金融量化分析
2、金融量化分析可以干什么
3、为什么将python运用于金融
- 4、常用库简介

1、什么是金融量化分析
从标题中我们可以简单的分析一下这个题目中的关键词,金融、量化、分析,接下来一个一个分析:
金融:金融是什么相信在大多数人心中都是比较神秘、高大上的,需要大量的资金与丰富的经验才可以在股市叱咤风云,也确实金融行业的风险非常大,任何人都不敢保证某一只股票的走向或者说是收益与否。金融其实与赌博很类似,但是为什么政府会禁止赌博而不禁止金融呢?这是因为金融行业的发展对国家经济是有好处的,而赌博单纯只是满足个人欲望,对经济发展一点好处都没有,就比如说:现在有个非常有想法的创业者,但是他没有资金,这个时候一个亿万富翁给他投资,经过一段时间的发展公司上市了,那创业者是不是就有钱了,而投资者的资产是不是也提升了,这就是通过金融的方式让资产进行流通。就算一个国家的人再有钱,但是他们都把钱存在地窖里,不生产不流通,那这个国家的整体经济一定不景气,所以说国家一定会大力发展经济。但是一定要记住一点,金融行业的风险很大。
量化:在这里量化也可以说是量化投资或是量化交易。刚才有介绍金融,金融行业最注重的就是投资和交易了,但是在之前都是通过人的一个主观判断和针对市场方面的一些分析做出的投资,但是有时候人的判断并不一定就是对的,有时候还会被自己的个人情绪所影响,所以说这个时候量化投资横空出世,通过数字化以及计算机技术通过相应的策略实现一种相对稳定的交易方式。
分析:结合本章所有内容来看,分析就是指的数据分析,只不过我们这个数据分析针对的金融方面的数据。当然只要我们学会这些数据分析的手段到时候无论是金融方面的数据还是其他任何行业的数据都可以手到擒来。
数据分析:
数据分析
专业点来说金融量化分析主要是指以先进的数学模型替代人为的主观判断,利用计算机技术从庞大的历史数据当中选出能够带来超额收益的多种“大概率”事件以此来指定策略。主要就是以下几步:
1、发现的一种能够赚钱的规律
2、将规律分解成可操作的步骤(策略)
3、编写程序,让机器去执行这个策略
4、机器返回结果,或者说是让机器直接实现自动化交易
2、金融量化分析可以干什么
相信大家都经常会使用百度、谷歌等之类的搜索引擎搜索我们想了解的问题,它就会从庞大的数据库当中找到你想要了解的问题,但是你要是直接去问它,我该怎么投资?我到底该买哪一支股票?什么股票可以挣钱?这样的问题会有答案吗,肯定是不会的,所以说金融量化的任务就是类似于这些搜索引擎的功能,它会通知你今天应该买什么,今天应该卖什么,当然如果有需求完全可以进行自动化交易。
那具体能干什么简单总结了几点:
1、可以帮你在几千只A股当中选择符合要求条件的股票
2、选择买进、卖出、以及平仓的时机
3、管理仓位风险
4、不会受到个人情绪影响
本文由 伯乐在线 - 小米云豆粥 翻译。未经许可,禁止转载!
英文出处:Curtis Miller。欢迎加入翻译组。
这篇博文是用Python分析股市数据系列两部中的第一部,内容基于我犹他大学 数学3900 (数据科学)的课程。在这些博文中,我会讨论一些基础知识。比如如何用pandas从雅虎财经获得数据, 可视化股市数据,平局数指标的定义,设计移动平均交汇点分析移动平均线的方法,回溯测试, 基准分析法。最后一篇博文会包含问题以供练习。第一篇博文会包含平局数指标以及之前的内容。
注意:本文仅代表作者本人的观点。文中的内容不应该被当做经济建议。我不对文中代码负责,取用者自己负责。
引言
金融业使用高等数学和统计已经有段时日。早在八十年代以前,银行业和金融业被认为是“枯燥”的;投资银行跟商业银行是分开的,业界主要的任务是处理“简单的”(跟当今相比)的金融职能,例如贷款。里根政府的减少调控和数学的应用,使该行业从枯燥的银行业变为今天的模样。在那之后,金融跻身科学,成为推动数学研究和发展的力量。例如数学上一个重大进展是布莱克-舒尔斯公式的推导。它被用来股票定价 (一份赋予股票持有者以一定的价格从股票发行者手中买入和卖出的合同)。但是, 不好的统计模型,包括布莱克-舒尔斯模型, 背负了部分导致2008金融危机的骂名。
近年来,计算机科学加入了高等数学的阵营,为金融和证券交易(为了盈利而进行的金融产品买入卖出行为)带来了革命性的变化。如今交易主要由计算机来完成:算法能以人类难以达到的速度做出交易决策(参看光速的限制已经成为系统设计中的瓶颈)。机器学习和数据挖掘也被越来越广泛的用到金融领域中,目测这个势头会保持下去。事实上很大一部分的算法交易都是高频交易(HFT)。虽然算法比人工快,但这些技术还是很新,而且被应用在一个以不稳定,高风险著称的领域。据一条被黑客曝光的白宫相关媒体推特表明HFT应该对2010 闪电式崩盘 and a 2013 闪电式崩盘 负责。
不过这节课不是关于如何利用不好的数学模型来摧毁证券市场。相反的,我将提供一些基本的Python工具来处理和分析股市数据。我会讲到移动平均值,如何利用移动平均值来制定交易策略,如何制定进入和撤出股市的决策,记忆如何利用回溯测试来评估一个决策。
免责申明:这不是投资建议。同时我私人完全没有交易经验(文中相关的知识大部分来自我在盐湖城社区大学参加的一个学期关于股市交易的课程)!这里仅仅是基本概念知识,不足以用于实际交易的股票。股票交易可以让你受到损失(已有太多案例),你要为自己的行为负责。
获取并可视化股市数据
从雅虎金融获取数据
在分析数据之前得先得到数据。股市数据可以从Yahoo! Finance、 Google Finance以及其他的地方拿到。同时,pandas包提供了轻松从以上网站获取数据的方法。这节课我们使用雅虎金融的数据。
下面的代码展示了如何直接创建一个含有股市数据的DataFrame。(更多关于远程获取数据的信息,点击这里)

import pandas as pd
import pandas.io.data as web # Package and modules for importing data; this code may change depending on pandas version
import datetime # We will look at stock prices over the past year, starting at January 1, 2016
start = datetime.datetime(2016,1,1)
end = datetime.date.today() # Let's get Apple stock data; Apple's ticker symbol is AAPL
# First argument is the series we want, second is the source ("yahoo" for Yahoo! Finance), third is the start date, fourth is the end date
apple = web.DataReader("AAPL", "yahoo", start, end) type(apple)
C:\Anaconda3\lib\site-packages\pandas\io\data.py:35: FutureWarning:
The pandas.io.data module is moved to a separate package (pandas-datareader) and will be removed from pandas in a future version.
After installing the pandas-datareader package (https://github.com/pydata/pandas-datareader), you can change the import ``from pandas.io import data, wb`` to ``from pandas_datareader import data, wb``.
FutureWarning) pandas.core.frame.DataFrame
apple.head()
| Open | High | Low | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2016-01-04 | 102.610001 | 105.370003 | 102.000000 | 105.349998 | 67649400 | 103.586180 |
| 2016-01-05 | 105.750000 | 105.849998 | 102.410004 | 102.709999 | 55791000 | 100.990380 |
| 2016-01-06 | 100.559998 | 102.370003 | 99.870003 | 100.699997 | 68457400 | 99.014030 |
| 2016-01-07 | 98.680000 | 100.129997 | 96.430000 | 96.449997 | 81094400 | 94.835186 |
| 2016-01-08 | 98.550003 | 99.110001 | 96.760002 | 96.959999 | 70798000 | 95.336649 |
让我们简单说一下数据内容。Open是当天的开始价格(不是前一天闭市的价格);high是股票当天的最高价;low是股票当天的最低价;close是闭市时间的股票价格。Volume指交易数量。Adjust close是根据法人行为调整之后的闭市价格。虽然股票价格基本上是由交易者决定的,stock splits (拆股。指上市公司将现有股票一拆为二,新股价格为原股的一半的行为)以及dividends(分红。每一股的分红)同样也会影响股票价格,也应该在模型中被考虑到。
可视化股市数据
获得数据之后让我们考虑将其可视化。下面我会演示如何使用matplotlib包。值得注意的是appleDataFrame对象有一个plot()方法让画图变得更简单。
import matplotlib.pyplot as plt # Import matplotlib
# This line is necessary for the plot to appear in a Jupyter notebook
%matplotlib inline # Control the default size of figures in this Jupyter notebook
%pylab inline pylab.rcParams['figure.figsize'] = (15, 9) # Change the size of plots apple["Adj Close"].plot(grid = True) # Plot the adjusted closing price of AAPL
Populating the interactive namespace from numpy and matplotlib
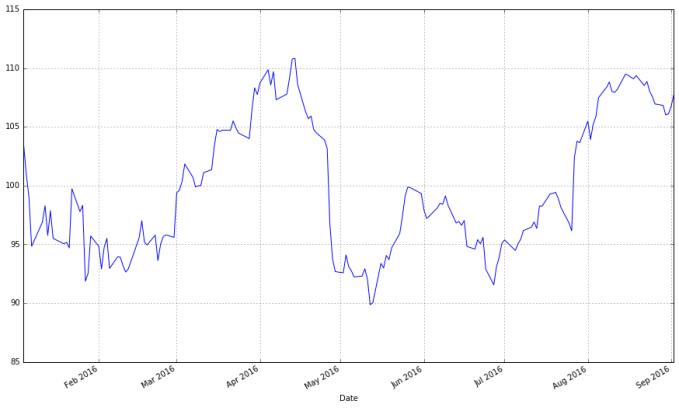
线段图是可行的,但是每一天的数据至少有四个变量(开市,股票最高价,股票最低价和闭市),我们希望找到一种不需要我们画四条不同的线就能看到这四个变量走势的可视化方法。一般来说我们使用烛柱图(也称为日本阴阳烛图表)来可视化金融数据,烛柱图最早在18世纪被日本的稻米商人所使用。可以用matplotlib来作图,但是需要费些功夫。
你们可以使用我实现的一个函数更容易地画烛柱图,它接受pandas的data frame作为数据来源。(程序基于这个例子, 你可以从这里找到相关函数的文档。)
from matplotlib.dates import DateFormatter, WeekdayLocator,\
DayLocator, MONDAY
from matplotlib.finance import candlestick_ohlc def pandas_candlestick_ohlc(dat, stick = "day", otherseries = None):
"""
:param dat: pandas DataFrame object with datetime64 index, and float columns "Open", "High", "Low", and "Close", likely created via DataReader from "yahoo"
:param stick: A string or number indicating the period of time covered by a single candlestick. Valid string inputs include "day", "week", "month", and "year", ("day" default), and any numeric input indicates the number of trading days included in a period
:param otherseries: An iterable that will be coerced into a list, containing the columns of dat that hold other series to be plotted as lines This will show a Japanese candlestick plot for stock data stored in dat, also plotting other series if passed.
"""
mondays = WeekdayLocator(MONDAY) # major ticks on the mondays
alldays = DayLocator() # minor ticks on the days
dayFormatter = DateFormatter('%d') # e.g., 12 # Create a new DataFrame which includes OHLC data for each period specified by stick input
transdat = dat.loc[:,["Open", "High", "Low", "Close"]]
if (type(stick) == str):
if stick == "day":
plotdat = transdat
stick = 1 # Used for plotting
elif stick in ["week", "month", "year"]:
if stick == "week":
transdat["week"] = pd.to_datetime(transdat.index).map(lambda x: x.isocalendar()[1]) # Identify weeks
elif stick == "month":
transdat["month"] = pd.to_datetime(transdat.index).map(lambda x: x.month) # Identify months
transdat["year"] = pd.to_datetime(transdat.index).map(lambda x: x.isocalendar()[0]) # Identify years
grouped = transdat.groupby(list(set(["year",stick]))) # Group by year and other appropriate variable
plotdat = pd.DataFrame({"Open": [], "High": [], "Low": [], "Close": []}) # Create empty data frame containing what will be plotted
for name, group in grouped:
plotdat = plotdat.append(pd.DataFrame({"Open": group.iloc[0,0],
"High": max(group.High),
"Low": min(group.Low),
"Close": group.iloc[-1,3]},
index = [group.index[0]]))
if stick == "week": stick = 5
elif stick == "month": stick = 30
elif stick == "year": stick = 365 elif (type(stick) == int and stick >= 1):
transdat["stick"] = [np.floor(i / stick) for i in range(len(transdat.index))]
grouped = transdat.groupby("stick")
plotdat = pd.DataFrame({"Open": [], "High": [], "Low": [], "Close": []}) # Create empty data frame containing what will be plotted
for name, group in grouped:
plotdat = plotdat.append(pd.DataFrame({"Open": group.iloc[0,0],
"High": max(group.High),
"Low": min(group.Low),
"Close": group.iloc[-1,3]},
index = [group.index[0]])) else:
raise ValueError('Valid inputs to argument "stick" include the strings "day", "week", "month", "year", or a positive integer') # Set plot parameters, including the axis object ax used for plotting
fig, ax = plt.subplots()
fig.subplots_adjust(bottom=0.2)
if plotdat.index[-1] - plotdat.index[0] < pd.Timedelta('730 days'):
weekFormatter = DateFormatter('%b %d') # e.g., Jan 12
ax.xaxis.set_major_locator(mondays)
ax.xaxis.set_minor_locator(alldays)
else:
weekFormatter = DateFormatter('%b %d, %Y')
ax.xaxis.set_major_formatter(weekFormatter) ax.grid(True) # Create the candelstick chart
candlestick_ohlc(ax, list(zip(list(date2num(plotdat.index.tolist())), plotdat["Open"].tolist(), plotdat["High"].tolist(),
plotdat["Low"].tolist(), plotdat["Close"].tolist())),
colorup = "black", colordown = "red", width = stick * .4) # Plot other series (such as moving averages) as lines
if otherseries != None:
if type(otherseries) != list:
otherseries = [otherseries]
dat.loc[:,otherseries].plot(ax = ax, lw = 1.3, grid = True) ax.xaxis_date()
ax.autoscale_view()
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right') plt.show() pandas_candlestick_ohlc(apple)
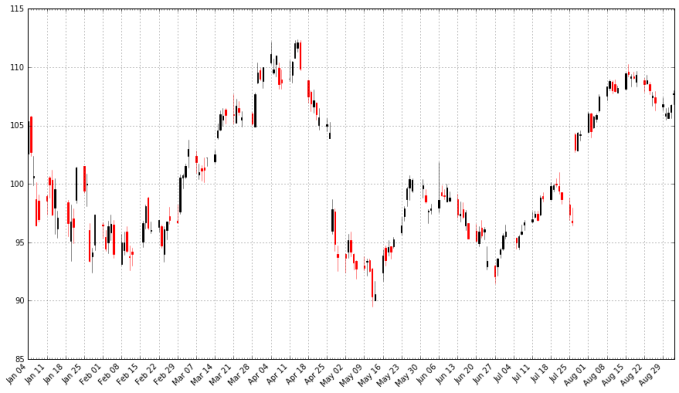
烛状图中黑色线条代表该交易日闭市价格高于开市价格(盈利),红色线条代表该交易日开市价格高于闭市价格(亏损)。刻度线代表当天交易的最高价和最低价(影线用来指明烛身的哪端是开市,哪端是闭市)。烛状图在金融和技术分析中被广泛使用在交易决策上,利用烛身的形状,颜色和位置。我今天不会涉及到策略。
我们也许想要把不同的金融商品呈现在一张图上:这样我们可以比较不同的股票,比较股票跟市场的关系,或者可以看其他证券,例如交易所交易基金(ETFs)。在后面的内容中,我们将会学到如何画金融证券跟一些指数(移动平均)的关系。届时你需要使用线段图而不是烛状图。(试想你如何重叠不同的烛状图而让图表保持整洁?)
下面我展示了不同技术公司股票的数据,以及如何调整数据让数据线聚在一起。
microsoft = web.DataReader("MSFT", "yahoo", start, end)
google = web.DataReader("GOOG", "yahoo", start, end)
# Below I create a DataFrame consisting of the adjusted closing price of these stocks, first by making a list of these objects and using the join method
stocks = pd.DataFrame({"AAPL": apple["Adj Close"],
"MSFT": microsoft["Adj Close"],
"GOOG": google["Adj Close"]})
stocks.head()
| AAPL | GOOG | MSFT | |
|---|---|---|---|
| Date | |||
| 2016-01-04 | 103.586180 | 741.840027 | 53.696756 |
| 2016-01-05 | 100.990380 | 742.580017 | 53.941723 |
| 2016-01-06 | 99.014030 | 743.619995 | 52.961855 |
| 2016-01-07 | 94.835186 | 726.390015 | 51.119702 |
| 2016-01-08 | 95.336649 | 714.469971 | 51.276485 |
stocks.plot(grid = True)
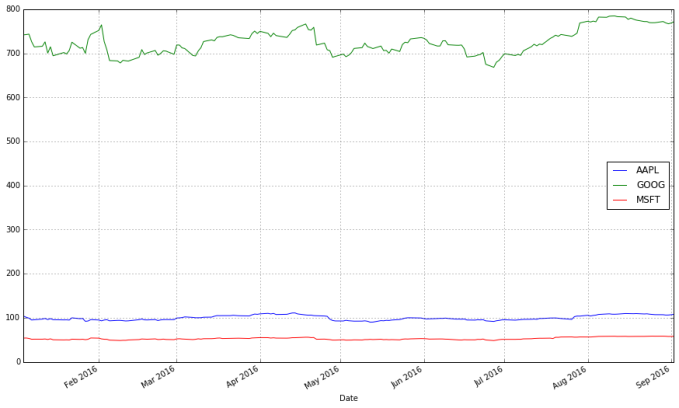
这张图表的问题在哪里呢?虽然价格的绝对值很重要(昂贵的股票很难购得,这不仅会影响它们的波动性,也会影响你交易它们的难易度),但是在交易中,我们更关注每支股票价格的变化而不是它的价格。Google的股票价格比苹果微软的都高,这个差别让苹果和微软的股票显得波动性很低,而事实并不是那样。
一个解决办法就是用两个不同的标度来作图。一个标度用于苹果和微软的数据;另一个标度用来表示Google的数据。
stocks.plot(secondary_y = ["AAPL", "MSFT"], grid = True)

一个“更好”的解决方法是可视化我们实际关心的信息:股票的收益。这需要我们进行必要的数据转化。数据转化的方法很多。其中一个转化方法是将每个交易日的股票交个跟比较我们所关心的时间段开始的股票价格相比较。也就是:

这需要转化stock对象中的数据,操作如下:
# df.apply(arg) will apply the function arg to each column in df, and return a DataFrame with the result
# Recall that lambda x is an anonymous function accepting parameter x; in this case, x will be a pandas Series object
stock_return = stocks.apply(lambda x: x / x[0])
stock_return.head()
| AAPL | GOOG | MSFT | |
|---|---|---|---|
| Date | |||
| 2016-01-04 | 1.000000 | 1.000000 | 1.000000 |
| 2016-01-05 | 0.974941 | 1.000998 | 1.004562 |
| 2016-01-06 | 0.955861 | 1.002399 | 0.986314 |
| 2016-01-07 | 0.915520 | 0.979173 | 0.952007 |
| 2016-01-08 | 0.920361 | 0.963105 | 0.954927 |
stock_return.plot(grid = True).axhline(y = 1, color = "black", lw = 2)
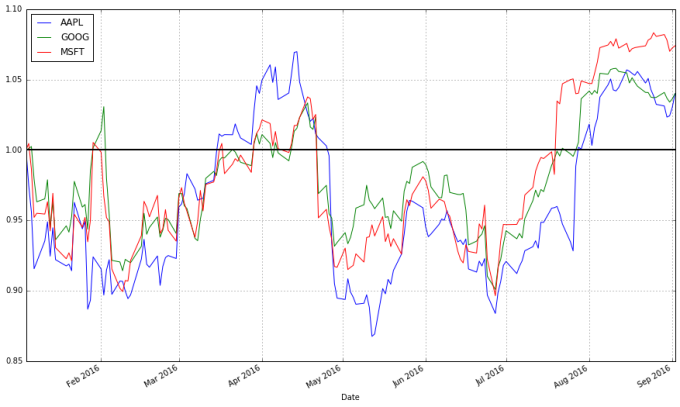
这个图就有用多了。现在我们可以看到从我们所关心的日期算起,每支股票的收益有多高。而且我们可以看到这些股票之间的相关性很高。它们基本上朝同一个方向移动,在其他类型的图表中很难观察到这一现象。
我们还可以用每天的股值变化作图。一个可行的方法是我们使用后一天$t + 1$和当天$t$的股值变化占当天股价的比例:

我们也可以比较当天跟前一天的价格:
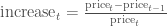
以上的公式并不相同,可能会让我们得到不同的结论,但是我们可以使用对数差异来表示股票价格变化:

(这里的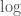

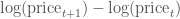
下面的代码演示了如何计算和可视化股票的对数差异:
# Let's use NumPy's log function, though math's log function would work just as well
import numpy as np stock_change = stocks.apply(lambda x: np.log(x) - np.log(x.shift(1))) # shift moves dates back by 1.
stock_change.head()
| AAPL | GOOG | MSFT | |
|---|---|---|---|
| Date | |||
| 2016-01-04 | NaN | NaN | NaN |
| 2016-01-05 | -0.025379 | 0.000997 | 0.004552 |
| 2016-01-06 | -0.019764 | 0.001400 | -0.018332 |
| 2016-01-07 | -0.043121 | -0.023443 | -0.035402 |
| 2016-01-08 | 0.005274 | -0.016546 | 0.003062 |
stock_change.plot(grid = True).axhline(y = 0, color = "black", lw = 2)
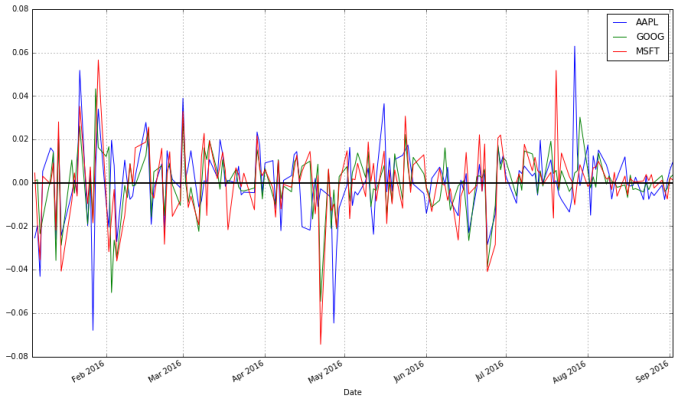
你更倾向于哪种转换方法呢?从相对时间段开始日的收益差距可以明显看出不同证券的总体走势。不同交易日之间的差距被用于更多预测股市行情的方法中,它们是不容被忽视的。
移动平均值
图表非常有用。在现实生活中,有些交易人在做决策的时候几乎完全基于图表(这些人是“技术人员”,从图表中找到规律并制定交易策略被称作技术分析,它是交易的基本教义之一。)下面让我们来看看如何找到股票价格的变化趋势。
一个q天的移动平均值(用
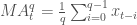
移动平均值可以让一个系列的数据变得更平滑,有助于我们找到趋势。q值越大,移动平均对短期的波动越不敏感。移动平均的基本目的就是从噪音中识别趋势。快速的移动平均有偏小的q,它们更接近股票价格;而慢速的移动平均有较大的q值,这使得它们对波动不敏感从而更加稳定。
pandas提供了计算移动平均的函数。下面我将演示使用这个函数来计算苹果公司股票价格的20天(一个月)移动平均值,并将它跟股票价格画在一起。
apple["20d"] = np.round(apple["Close"].rolling(window = 20, center = False).mean(), 2)
pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:], otherseries = "20d")
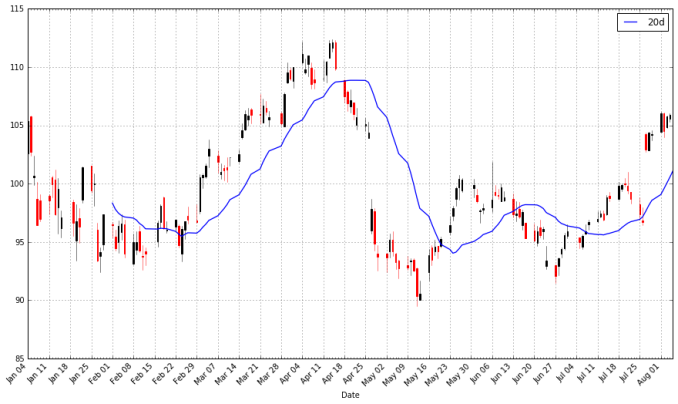
注意到平均值的起始点时间是很迟的。我们必须等到20天之后才能开始计算该值。这个问题对于更长时间段的移动平均来说是个更加严重的问题。因为我希望我可以计算200天的移动平均,我将扩展我们所得到的苹果公司股票的数据,但我们主要还是只关注2016。
start = datetime.datetime(2010,1,1)
apple = web.DataReader("AAPL", "yahoo", start, end)
apple["20d"] = np.round(apple["Close"].rolling(window = 20, center = False).mean(), 2) pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:], otherseries = "20d")

你会发现移动平均比真实的股票价格数据平滑很多。而且这个指数是非常难改变的:一支股票的价格需要变到平局值之上或之下才能改变移动平均线的方向。因此平均线的交叉点代表了潜在的趋势变化,需要加以注意。
交易者往往对不同的移动平均感兴趣,例如20天,50天和200天。要同时生成多条移动平均线也不难:
apple["50d"] = np.round(apple["Close"].rolling(window = 50, center = False).mean(), 2)
apple["200d"] = np.round(apple["Close"].rolling(window = 200, center = False).mean(), 2) pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:], otherseries = ["20d", "50d", "200d"])

20天的移动平均线对小的变化非常敏感,而200天的移动平均线波动最小。这里的200天平均线显示出来总体的熊市趋势:股值总体来说一直在下降。20天移动平均线所代表的信息是熊市牛市交替,接下来有可能是牛市。这些平均线的交叉点就是交易信息点,它们代表股票价格的趋势会有所改变因而你需要作出能盈利的相应决策。
请移动下节内容。你将读到如何使用移动平局线来设计和测试交易策略。
更新:该文章早期版本提到算法交易跟高频交易是一个意思。但是网友评论指出这并不一定:算法可以用来进行交易但不一定就是高频。高频交易是算法交易中间很大的一部分,但是两者不等价。
这篇博文是用Python分析股市数据系列两部中的第二部,内容基于我在犹他大学 数学3900 (数据科学)的课程 (阅读第一部分)。在这两篇博文中,我会讨论一些基础知识,包括比如如何用pandas从雅虎财经获得数据, 可视化股市数据,平均数指标的定义,设计移动平均交汇点分析移动平均线的方法,回溯测试和 基准分析法。这篇文章会讨论如何设计用移动平均交汇点分析移动平均线的系统,如何做回溯测试和基准分析,最后留有一些练习题以飨读者。
注意:本文仅代表作者本人的观点。文中的内容不应该被当做经济建议。我不对文中代码负责,取用者自己负责
交易策略
在特定的预期条件达成时一个开放头寸会被关闭。多头头寸表示交易中需要金融商品价格上升才能产生盈利,空头头寸表示交易中需要金融商品价格下降才能产生盈利。在股票交易中,多头头寸是牛市,空头头寸是熊市,反之则不成立。(股票期权交易中这个非常典型)
例如你在预计股价上涨的情况下购入股票,并计划在股票价格上涨高于购入价时抛出,这就是多头头寸。就是说你持有一定的金融产品,如果它们价格上涨,你将会获利,并且没有上限;如果它们价格下降,你会亏损。由于股票价格不会为负,亏损是有限度的。相反的,如果你预计股价会下跌,就从交易公司借贷股票然后卖出,同时期待未来股票价格下降后再低价买入还贷来赚取差额,这就是空头股票。如果股价下跌你会获利。空头头寸的获利额度受股价所限(最佳情况就是股票变得一文不值,你不用花钱就能将它们买回来),而损失却没有下限,因为你有可能需要花很多钱才能买回股票。所以交换所只会在确定投资者有很好的经济基础的情况下才会让他们空头借贷股票。
所有股民都应该决定他在每一股上可以冒多大的风险。比如有人决定无论什么情况他都不会在某一次交易中投入总额的10%去冒险。同时在交易中,股民要有一个撤出策略,这是让股民退出头寸的各种条件。股民也可以设置一个目标,这是导致股民退出头寸的最小盈利额。同样的,股民也需要有一个他能承受的最大损失额度。当预计损失大于可承受额度时,股民应该退出头寸以避免更大损失(这可以通过设置停止损失委托来避免未来的损失)。
我们要设计一个交易策略,它包含用于快速交易的交易激发信号、决定交易额度的规则和完整的退出策略。我们的目标是设计并评估该交易策略。
假设每次交易金额占总额的比例是固定的(10%)。同时设定在每一次交易中,如果损失超过了20%的交易值,我们就退出头寸。现在我们要决定什么时候进入头寸,什么时候退出以保证盈利。
这里我要演示移动平均交汇点分析移动平均线的方法。我会使用两条移动平均线,一条快速的,另一条是慢速的。我们的策略是:
- 当快速移动平均线和慢速移动线交汇时开始交易
- 当快速移动平均线和慢速移动线再次交汇时停止交易
做多是指在快速平均线上升到慢速平均线之上时开始交易,当快速平均线下降到慢速平均线之下时停止交易。卖空正好相反,它是指在快速平均线下降到慢速平均线之下时开始交易,快速平均线上升到慢速平均线之上时停止交易。
现在我们有一整套策略了。在使用它之前我们需要先做一下测试。回溯测试是一个常用的测试方法,它使用历史数据来看策略是否会盈利。例如这张苹果公司的股票价值图,如果20天的移动平均是快速线,50天的移动平均是慢速线,那么我们这个策略不是很挣钱,至少在你一直做多头头寸的时候。
下面让我们来自动化回溯测试的过程。首先我们要识别什么时候20天平均线在50天之下,以及之上。
apple['20d-50d'] =apple['20d'] -apple['50d']
apple.tail()
| Open | High | Low | Close | Volume | Adj Close | 20d | 50d | 200d | 20d-50d | |
|---|---|---|---|---|---|---|---|---|---|---|
| Date | ||||||||||
| 2016-08-26 | 107.410004 | 107.949997 | 106.309998 | 106.940002 | 27766300 | 106.940002 | 107.87 | 101.51 | 102.73 | 6.36 |
| 2016-08-29 | 106.620003 | 107.440002 | 106.290001 | 106.820000 | 24970300 | 106.820000 | 107.91 | 101.74 | 102.68 | 6.17 |
| 2016-08-30 | 105.800003 | 106.500000 | 105.500000 | 106.000000 | 24863900 | 106.000000 | 107.98 | 101.96 | 102.63 | 6.02 |
| 2016-08-31 | 105.660004 | 106.570000 | 105.639999 | 106.099998 | 29662400 | 106.099998 | 108.00 | 102.16 | 102.60 | 5.84 |
| 2016-09-01 | 106.139999 | 106.800003 | 105.620003 | 106.730003 | 26643600 | 106.730003 | 108.04 | 102.39 | 102.56 | 5.65 |
我们将差异的符号称为状态转换。快速移动平均线在慢速移动平均线之上代表牛市状态;相反则为熊市。以下的代码用于识别状态转换。
# np.where() is a vectorized if-else function, where a condition is checked for each component of a vector, and the first argument passed is used when the condition holds, and the other passed if it does not
apple["Regime"] = np.where(apple['20d-50d'] > 0, 1, 0)
# We have 1's for bullish regimes and 0's for everything else. Below I replace bearish regimes's values with -1, and to maintain the rest of the vector, the second argument is apple["Regime"]
apple["Regime"] = np.where(apple['20d-50d'] < 0, -1, apple["Regime"])
apple.loc['2016-01-01':'2016-08-07',"Regime"].plot(ylim = (-2,2)).axhline(y = 0, color = "black", lw = 2)

apple["Regime"].plot(ylim =(-2,2)).axhline(y =0, color ="black", lw =2)

apple["Regime"].value_counts()
1 966
-1 663
0 50
Name: Regime, dtype: int64
从上面的曲线可以看到有966天苹果公司的股票是牛市,663天是熊市,有54天没有倾向性。(原文中牛市和熊市说反了,译文中更正;原文数字跟代码结果对不上,译文按照代码结果更正)
交易信号出现在状态转换之时。牛市出现时,买入信号被激活;牛市完结时,卖出信号被激活。同样的,熊市出现时卖出信号被激活,熊市结束时,买入信号被激活。(只有在你空头股票,或者使用一些其他的方法例如用股票期权赌市场的时候这种情况才对你有利)

# To ensure that all trades close out, I temporarily change the regime of the last row to 0
regime_orig = apple.ix[-1, "Regime"]
apple.ix[-1, "Regime"] = 0
apple["Signal"] = np.sign(apple["Regime"] - apple["Regime"].shift(1))
# Restore original regime data
apple.ix[-1, "Regime"] = regime_orig
apple.tail()
| Open | High | Low | Close | Volume | Adj Close | 20d | 50d | 200d | 20d-50d | Regime | Signal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | ||||||||||||
| 2016-08-26 | 107.410004 | 107.949997 | 106.309998 | 106.940002 | 27766300 | 106.940002 | 107.87 | 101.51 | 102.73 | 6.36 | 1.0 | 0.0 |
| 2016-08-29 | 106.620003 | 107.440002 | 106.290001 | 106.820000 | 24970300 | 106.820000 | 107.91 | 101.74 | 102.68 | 6.17 | 1.0 | 0.0 |
| 2016-08-30 | 105.800003 | 106.500000 | 105.500000 | 106.000000 | 24863900 | 106.000000 | 107.98 | 101.96 | 102.63 | 6.02 | 1.0 | 0.0 |
| 2016-08-31 | 105.660004 | 106.570000 | 105.639999 | 106.099998 | 29662400 | 106.099998 | 108.00 | 102.16 | 102.60 | 5.84 | 1.0 | 0.0 |
| 2016-09-01 | 106.139999 | 106.800003 | 105.620003 | 106.730003 | 26643600 | 106.730003 | 108.04 | 102.39 | 102.56 | 5.65 | 1.0 | -1.0 |
apple["Signal"].plot(ylim =(-2, 2))

apple["Signal"].value_counts()
0.0 1637
-1.0 21
1.0 20
Name: Signal, dtype: int64
我们会买入苹果公司的股票20次,抛出21次 (原文数字跟代码结果不符,译文根据代码结果更正)。如果我们只选了苹果公司的股票,六年内只有21次交易发生。如果每次多头转空头的时候我们都采取行动,我们将会参与21次交易。(请记住交易次数不是越多越好,毕竟交易不是免费的)
你也许注意到了这个系统不是很稳定。快速平均线在慢速平均线之上就激发交易,即使这个状态只是短短一瞬,这样会导致交易马上终止(这样并不好因为现实中每次交易都要付费,这个费用会很快消耗掉收益)。同时所有的牛市瞬间转为熊市,如果你允许同时押熊市和牛市,那就会出现每次交易结束就自动激发另一场押相反方向交易的诡异情况。更好的系统会要求有更多的证据来证明市场的发展方向,但是这里我们不去追究那个细节。
下面我们来看看每次买入卖出时候的股票价格。
apple.loc[apple["Signal"] ==1, "Close"]
Date
2010-03-16 224.449997
2010-06-18 274.070011
2010-09-20 283.230007
2011-05-12 346.569988
2011-07-14 357.770004
2011-12-28 402.640003
2012-06-25 570.770020
2013-05-17 433.260010
2013-07-31 452.529984
2013-10-16 501.110001
2014-03-26 539.779991
2014-04-25 571.939980
2014-08-18 99.160004
2014-10-28 106.739998
2015-02-05 119.940002
2015-04-28 130.559998
2015-10-27 114.550003
2016-03-11 102.260002
2016-07-01 95.889999
2016-07-25 97.339996
Name: Close, dtype: float64
apple.loc[apple["Signal"] ==-1, "Close"]
Date
2010-06-11 253.509995
2010-07-22 259.020000
2011-03-30 348.630009
2011-03-31 348.510006
2011-05-27 337.409992
2011-11-17 377.410000
2012-05-09 569.180023
2012-10-17 644.610001
2013-06-26 398.069992
2013-10-03 483.409996
2014-01-28 506.499977
2014-04-22 531.700020
2014-06-11 93.860001
2014-10-17 97.669998
2015-01-05 106.250000
2015-04-16 126.169998
2015-06-25 127.500000
2015-12-18 106.029999
2016-05-05 93.239998
2016-07-08 96.680000
2016-09-01 106.730003
Name: Close, dtype: float64
# Create a DataFrame with trades, including the price at the trade and the regime under which the trade is made.
apple_signals = pd.concat([
pd.DataFrame({"Price": apple.loc[apple["Signal"] == 1, "Close"],
"Regime": apple.loc[apple["Signal"] == 1, "Regime"],
"Signal": "Buy"}),
pd.DataFrame({"Price": apple.loc[apple["Signal"] == -1, "Close"],
"Regime": apple.loc[apple["Signal"] == -1, "Regime"],
"Signal": "Sell"}),
])
apple_signals.sort_index(inplace = True)
apple_signals
|
Price |
Regime |
Signal |
|
|
Date |
|||
|
2010-03-16 |
224.449997 |
1.0 |
Buy |
|
2010-06-11 |
253.509995 |
-1.0 |
Sell |
|
2010-06-18 |
274.070011 |
1.0 |
Buy |
|
2010-07-22 |
259.020000 |
-1.0 |
Sell |
|
2010-09-20 |
283.230007 |
1.0 |
Buy |
|
2011-03-30 |
348.630009 |
0.0 |
Sell |
|
2011-03-31 |
348.510006 |
-1.0 |
Sell |
|
2011-05-12 |
346.569988 |
1.0 |
Buy |
|
2011-05-27 |
337.409992 |
-1.0 |
Sell |
|
2011-07-14 |
357.770004 |
1.0 |
Buy |
|
2011-11-17 |
377.410000 |
-1.0 |
Sell |
|
2011-12-28 |
402.640003 |
1.0 |
Buy |
|
2012-05-09 |
569.180023 |
-1.0 |
Sell |
|
2012-06-25 |
570.770020 |
1.0 |
Buy |
|
2012-10-17 |
644.610001 |
-1.0 |
Sell |
|
2013-05-17 |
433.260010 |
1.0 |
Buy |
|
2013-06-26 |
398.069992 |
-1.0 |
Sell |
|
2013-07-31 |
452.529984 |
1.0 |
Buy |
|
2013-10-03 |
483.409996 |
-1.0 |
Sell |
|
2013-10-16 |
501.110001 |
1.0 |
Buy |
|
2014-01-28 |
506.499977 |
-1.0 |
Sell |
|
2014-03-26 |
539.779991 |
1.0 |
Buy |
|
2014-04-22 |
531.700020 |
-1.0 |
Sell |
|
2014-04-25 |
571.939980 |
1.0 |
Buy |
|
2014-06-11 |
93.860001 |
-1.0 |
Sell |
|
2014-08-18 |
99.160004 |
1.0 |
Buy |
|
2014-10-17 |
97.669998 |
-1.0 |
Sell |
|
2014-10-28 |
106.739998 |
1.0 |
Buy |
|
2015-01-05 |
106.250000 |
-1.0 |
Sell |
|
2015-02-05 |
119.940002 |
1.0 |
Buy |
|
2015-04-16 |
126.169998 |
-1.0 |
Sell |
|
2015-04-28 |
130.559998 |
1.0 |
Buy |
|
2015-06-25 |
127.500000 |
-1.0 |
Sell |
|
2015-10-27 |
114.550003 |
1.0 |
Buy |
|
2015-12-18 |
106.029999 |
-1.0 |
Sell |
|
2016-03-11 |
102.260002 |
1.0 |
Buy |
|
2016-05-05 |
93.239998 |
-1.0 |
Sell |
|
2016-07-01 |
95.889999 |
1.0 |
Buy |
|
2016-07-08 |
96.680000 |
-1.0 |
Sell |
|
2016-07-25 |
97.339996 |
1.0 |
Buy |
|
2016-09-01 |
106.730003 |
1.0 |
Sell |
# Let's see the profitability of long trades
apple_long_profits = pd.DataFrame({
"Price": apple_signals.loc[(apple_signals["Signal"] == "Buy") &
apple_signals["Regime"] == 1, "Price"],
"Profit": pd.Series(apple_signals["Price"] - apple_signals["Price"].shift(1)).loc[
apple_signals.loc[(apple_signals["Signal"].shift(1) == "Buy") & (apple_signals["Regime"].shift(1) == 1)].index
].tolist(),
"End Date": apple_signals["Price"].loc[
apple_signals.loc[(apple_signals["Signal"].shift(1) == "Buy") & (apple_signals["Regime"].shift(1) == 1)].index
].index
})
apple_long_profits
| End Date | Price | Profit | |
|---|---|---|---|
| Date | |||
| 2010-03-16 | 2010-06-11 | 224.449997 | 29.059998 |
| 2010-06-18 | 2010-07-22 | 274.070011 | -15.050011 |
| 2010-09-20 | 2011-03-30 | 283.230007 | 65.400002 |
| 2011-05-12 | 2011-05-27 | 346.569988 | -9.159996 |
| 2011-07-14 | 2011-11-17 | 357.770004 | 19.639996 |
| 2011-12-28 | 2012-05-09 | 402.640003 | 166.540020 |
| 2012-06-25 | 2012-10-17 | 570.770020 | 73.839981 |
| 2013-05-17 | 2013-06-26 | 433.260010 | -35.190018 |
| 2013-07-31 | 2013-10-03 | 452.529984 | 30.880012 |
| 2013-10-16 | 2014-01-28 | 501.110001 | 5.389976 |
| 2014-03-26 | 2014-04-22 | 539.779991 | -8.079971 |
| 2014-04-25 | 2014-06-11 | 571.939980 | -478.079979 |
| 2014-08-18 | 2014-10-17 | 99.160004 | -1.490006 |
| 2014-10-28 | 2015-01-05 | 106.739998 | -0.489998 |
| 2015-02-05 | 2015-04-16 | 119.940002 | 6.229996 |
| 2015-04-28 | 2015-06-25 | 130.559998 | -3.059998 |
| 2015-10-27 | 2015-12-18 | 114.550003 | -8.520004 |
| 2016-03-11 | 2016-05-05 | 102.260002 | -9.020004 |
| 2016-07-01 | 2016-07-08 | 95.889999 | 0.790001 |
| 2016-07-25 | 2016-09-01 | 97.339996 | 9.390007 |
从上表可以看出2013年5月17日那天苹果公司股票价格大跌,我们的系统会表现很差。但是那个价格下降不是因为苹果遇到了什么大危机,而仅仅是一次分股。由于分红不如分股那么显著,这也许会影响系统行为。
# Let's see the result over the whole period for which we have Apple data
pandas_candlestick_ohlc(apple, stick = 45, otherseries = ["20d", "50d", "200d"])

我们不希望我们的交易系统的表现受到分红和分股的影响。一个解决方案是利用历史的分红分股数据来设计交易系统,这些数据可以真实地反映股市的行为从而帮助我们找到最佳解决方案,但是这个方法要更复杂一些。另一个方案就是根据分红和分股来调整股票的价格。
雅虎财经只提供调整之后的股票闭市价格,不过这些对于我们调整开市,高价和低价已经足够了。调整闭市股价是这样实现的:

让我们回到开始,先调整股票价格,然后再来评价我们的交易系统。
def ohlc_adj(dat):
"""
:param dat: pandas DataFrame with stock data, including "Open", "High", "Low", "Close", and "Adj Close", with "Adj Close" containing adjusted closing prices :return: pandas DataFrame with adjusted stock data This function adjusts stock data for splits, dividends, etc., returning a data frame with
"Open", "High", "Low" and "Close" columns. The input DataFrame is similar to that returned
by pandas Yahoo! Finance API.
"""
return pd.DataFrame({"Open": dat["Open"] * dat["Adj Close"] / dat["Close"],
"High": dat["High"] * dat["Adj Close"] / dat["Close"],
"Low": dat["Low"] * dat["Adj Close"] / dat["Close"],
"Close": dat["Adj Close"]}) apple_adj = ohlc_adj(apple) # This next code repeats all the earlier analysis we did on the adjusted data apple_adj["20d"] = np.round(apple_adj["Close"].rolling(window = 20, center = False).mean(), 2)
apple_adj["50d"] = np.round(apple_adj["Close"].rolling(window = 50, center = False).mean(), 2)
apple_adj["200d"] = np.round(apple_adj["Close"].rolling(window = 200, center = False).mean(), 2) apple_adj['20d-50d'] = apple_adj['20d'] - apple_adj['50d']
# np.where() is a vectorized if-else function, where a condition is checked for each component of a vector, and the first argument passed is used when the condition holds, and the other passed if it does not
apple_adj["Regime"] = np.where(apple_adj['20d-50d'] > 0, 1, 0)
# We have 1's for bullish regimes and 0's for everything else. Below I replace bearish regimes's values with -1, and to maintain the rest of the vector, the second argument is apple["Regime"]
apple_adj["Regime"] = np.where(apple_adj['20d-50d'] < 0, -1, apple_adj["Regime"])
# To ensure that all trades close out, I temporarily change the regime of the last row to 0
regime_orig = apple_adj.ix[-1, "Regime"]
apple_adj.ix[-1, "Regime"] = 0
apple_adj["Signal"] = np.sign(apple_adj["Regime"] - apple_adj["Regime"].shift(1))
# Restore original regime data
apple_adj.ix[-1, "Regime"] = regime_orig # Create a DataFrame with trades, including the price at the trade and the regime under which the trade is made.
apple_adj_signals = pd.concat([
pd.DataFrame({"Price": apple_adj.loc[apple_adj["Signal"] == 1, "Close"],
"Regime": apple_adj.loc[apple_adj["Signal"] == 1, "Regime"],
"Signal": "Buy"}),
pd.DataFrame({"Price": apple_adj.loc[apple_adj["Signal"] == -1, "Close"],
"Regime": apple_adj.loc[apple_adj["Signal"] == -1, "Regime"],
"Signal": "Sell"}),
])
apple_adj_signals.sort_index(inplace = True)
apple_adj_long_profits = pd.DataFrame({
"Price": apple_adj_signals.loc[(apple_adj_signals["Signal"] == "Buy") &
apple_adj_signals["Regime"] == 1, "Price"],
"Profit": pd.Series(apple_adj_signals["Price"] - apple_adj_signals["Price"].shift(1)).loc[
apple_adj_signals.loc[(apple_adj_signals["Signal"].shift(1) == "Buy") & (apple_adj_signals["Regime"].shift(1) == 1)].index
].tolist(),
"End Date": apple_adj_signals["Price"].loc[
apple_adj_signals.loc[(apple_adj_signals["Signal"].shift(1) == "Buy") & (apple_adj_signals["Regime"].shift(1) == 1)].index
].index
}) pandas_candlestick_ohlc(apple_adj, stick = 45, otherseries = ["20d", "50d", "200d"])

apple_adj_long_profits
| End Date | Price | Profit | |
|---|---|---|---|
| Date | |||
| 2010-03-16 | 2010-06-10 | 29.355667 | 3.408371 |
| 2010-06-18 | 2010-07-22 | 35.845436 | -1.968381 |
| 2010-09-20 | 2011-03-30 | 37.043466 | 8.553623 |
| 2011-05-12 | 2011-05-27 | 45.327660 | -1.198030 |
| 2011-07-14 | 2011-11-17 | 46.792503 | 2.568702 |
| 2011-12-28 | 2012-05-09 | 52.661020 | 21.781659 |
| 2012-06-25 | 2012-10-17 | 74.650634 | 10.019459 |
| 2013-05-17 | 2013-06-26 | 57.882798 | -4.701326 |
| 2013-07-31 | 2013-10-04 | 60.457234 | 4.500835 |
| 2013-10-16 | 2014-01-28 | 67.389473 | 1.122523 |
| 2014-03-11 | 2014-03-17 | 72.948554 | -1.272298 |
| 2014-03-24 | 2014-04-22 | 73.370393 | -1.019203 |
| 2014-04-25 | 2014-10-17 | 77.826851 | 16.191371 |
| 2014-10-28 | 2015-01-05 | 102.749105 | -0.028185 |
| 2015-02-05 | 2015-04-16 | 116.413846 | 6.046838 |
| 2015-04-28 | 2015-06-26 | 126.721620 | -3.184117 |
| 2015-10-27 | 2015-12-18 | 112.152083 | -7.897288 |
| 2016-03-10 | 2016-05-05 | 100.015950 | -7.278331 |
| 2016-06-23 | 2016-06-27 | 95.582210 | -4.038123 |
| 2016-06-30 | 2016-07-11 | 95.084904 | 1.372569 |
| 2016-07-25 | 2016-09-01 | 96.815526 | 9.914477 |
可以看到根据分红和分股调整之后的价格图变得很不一样了。之后的分析我们都会用到这个调整之后的数据。
假设我们在股市有一百万,让我们来看看根据下面的条件,我们的系统会如何反应:
- 每次用总额的10%来进行交易
- 退出头寸如果亏损达到了交易额的20%
模拟的时候要记住:
- 每次交易有100支股票
- 我们的避损规则是当股票价格下降到一定数值时就抛出。我们需要检查这段时间内的低价是否低到可以出发避损规则。现实中除非我们买入看空期权,我们无法保证我们能以设定低值价格卖出股票。这里为了简洁我们将设定值作为卖出值。
- 每次交易都会付给中介一定的佣金。这里我们没有考虑这个。
下面的代码演示了如何实现回溯测试:
# We need to get the low of the price during each trade.
tradeperiods =pd.DataFrame({"Start": apple_adj_long_profits.index,
"End": apple_adj_long_profits["End Date"]})
apple_adj_long_profits["Low"] =tradeperiods.apply(lambdax: min(apple_adj.loc[x["Start"]:x["End"], "Low"]), axis =1)
apple_adj_long_profits
|
End Date |
Price |
Profit |
Low |
|
|
Date |
||||
|
2010-03-16 |
2010-06-10 |
29.355667 |
3.408371 |
26.059775 |
|
2010-06-18 |
2010-07-22 |
35.845436 |
-1.968381 |
31.337127 |
|
2010-09-20 |
2011-03-30 |
37.043466 |
8.553623 |
35.967068 |
|
2011-05-12 |
2011-05-27 |
45.327660 |
-1.198030 |
43.084626 |
|
2011-07-14 |
2011-11-17 |
46.792503 |
2.568702 |
46.171251 |
|
2011-12-28 |
2012-05-09 |
52.661020 |
21.781659 |
52.382438 |
|
2012-06-25 |
2012-10-17 |
74.650634 |
10.019459 |
73.975759 |
|
2013-05-17 |
2013-06-26 |
57.882798 |
-4.701326 |
52.859502 |
|
2013-07-31 |
2013-10-04 |
60.457234 |
4.500835 |
60.043080 |
|
2013-10-16 |
2014-01-28 |
67.389473 |
1.122523 |
67.136651 |
|
2014-03-11 |
2014-03-17 |
72.948554 |
-1.272298 |
71.167335 |
|
2014-03-24 |
2014-04-22 |
73.370393 |
-1.019203 |
69.579335 |
|
2014-04-25 |
2014-10-17 |
77.826851 |
16.191371 |
76.740971 |
|
2014-10-28 |
2015-01-05 |
102.749105 |
-0.028185 |
101.411076 |
|
2015-02-05 |
2015-04-16 |
116.413846 |
6.046838 |
114.948237 |
|
2015-04-28 |
2015-06-26 |
126.721620 |
-3.184117 |
119.733299 |
|
2015-10-27 |
2015-12-18 |
112.152083 |
-7.897288 |
104.038477 |
|
2016-03-10 |
2016-05-05 |
100.015950 |
-7.278331 |
91.345994 |
|
2016-06-23 |
2016-06-27 |
95.582210 |
-4.038123 |
91.006996 |
|
2016-06-30 |
2016-07-11 |
95.084904 |
1.372569 |
93.791913 |
|
2016-07-25 |
2016-09-01 |
96.815526 |
9.914477 |
95.900485 |
# Now we have all the information needed to simulate this strategy in apple_adj_long_profits
cash =1000000
apple_backtest =pd.DataFrame({"Start Port. Value": [],
"End Port. Value": [],
"End Date": [],
"Shares": [],
"Share Price": [],
"Trade Value": [],
"Profit per Share": [],
"Total Profit": [],
"Stop-Loss Triggered": []})
port_value =.1# Max proportion of portfolio bet on any trade
batch =100# Number of shares bought per batch
stoploss =.2# % of trade loss that would trigger a stoploss
forindex, row inapple_adj_long_profits.iterrows():
batches =np.floor(cash *port_value) //np.ceil(batch *row["Price"]) # Maximum number of batches of stocks invested in
trade_val =batches *batch *row["Price"] # How much money is put on the line with each trade
ifrow["Low"] < (1-stoploss) *row["Price"]: # Account for the stop-loss
share_profit =np.round((1-stoploss) *row["Price"], 2)
stop_trig =True
else:
share_profit =row["Profit"]
stop_trig =False
profit =share_profit *batches *batch # Compute profits
# Add a row to the backtest data frame containing the results of the trade
apple_backtest =apple_backtest.append(pd.DataFrame({
"Start Port. Value": cash,
"End Port. Value": cash +profit,
"End Date": row["End Date"],
"Shares": batch *batches,
"Share Price": row["Price"],
"Trade Value": trade_val,
"Profit per Share": share_profit,
"Total Profit": profit,
"Stop-Loss Triggered": stop_trig
}, index =[index]))
cash =max(0, cash +profit) apple_backtest
|
End Date |
End Port. Value |
Profit per Share |
Share Price |
Shares |
Start Port. Value |
Stop-Loss Triggered |
Total Profit |
Trade Value |
|
|
2010-03-16 |
2010-06-10 |
1.011588e+06 |
3.408371 |
29.355667 |
3400.0 |
1.000000e+06 |
0.0 |
11588.4614 |
99809.2678 |
|
2010-06-18 |
2010-07-22 |
1.006077e+06 |
-1.968381 |
35.845436 |
2800.0 |
1.011588e+06 |
0.0 |
-5511.4668 |
100367.2208 |
|
2010-09-20 |
2011-03-30 |
1.029172e+06 |
8.553623 |
37.043466 |
2700.0 |
1.006077e+06 |
0.0 |
23094.7821 |
100017.3582 |
|
2011-05-12 |
2011-05-27 |
1.026536e+06 |
-1.198030 |
45.327660 |
2200.0 |
1.029172e+06 |
0.0 |
-2635.6660 |
99720.8520 |
|
2011-07-14 |
2011-11-17 |
1.031930e+06 |
2.568702 |
46.792503 |
2100.0 |
1.026536e+06 |
0.0 |
5394.2742 |
98264.2563 |
|
2011-12-28 |
2012-05-09 |
1.073316e+06 |
21.781659 |
52.661020 |
1900.0 |
1.031930e+06 |
0.0 |
41385.1521 |
100055.9380 |
|
2012-06-25 |
2012-10-17 |
1.087343e+06 |
10.019459 |
74.650634 |
1400.0 |
1.073316e+06 |
0.0 |
14027.2426 |
104510.8876 |
|
2013-05-17 |
2013-06-26 |
1.078880e+06 |
-4.701326 |
57.882798 |
1800.0 |
1.087343e+06 |
0.0 |
-8462.3868 |
104189.0364 |
|
2013-07-31 |
2013-10-04 |
1.086532e+06 |
4.500835 |
60.457234 |
1700.0 |
1.078880e+06 |
0.0 |
7651.4195 |
102777.2978 |
|
2013-10-16 |
2014-01-28 |
1.088328e+06 |
1.122523 |
67.389473 |
1600.0 |
1.086532e+06 |
0.0 |
1796.0368 |
107823.1568 |
|
2014-03-11 |
2014-03-17 |
1.086547e+06 |
-1.272298 |
72.948554 |
1400.0 |
1.088328e+06 |
0.0 |
-1781.2172 |
102127.9756 |
|
2014-03-24 |
2014-04-22 |
1.085120e+06 |
-1.019203 |
73.370393 |
1400.0 |
1.086547e+06 |
0.0 |
-1426.8842 |
102718.5502 |
|
2014-04-25 |
2014-10-17 |
1.106169e+06 |
16.191371 |
77.826851 |
1300.0 |
1.085120e+06 |
0.0 |
21048.7823 |
101174.9063 |
|
2014-10-28 |
2015-01-05 |
1.106140e+06 |
-0.028185 |
102.749105 |
1000.0 |
1.106169e+06 |
0.0 |
-28.1850 |
102749.1050 |
|
2015-02-05 |
2015-04-16 |
1.111582e+06 |
6.046838 |
116.413846 |
900.0 |
1.106140e+06 |
0.0 |
5442.1542 |
104772.4614 |
|
2015-04-28 |
2015-06-26 |
1.109035e+06 |
-3.184117 |
126.721620 |
800.0 |
1.111582e+06 |
0.0 |
-2547.2936 |
101377.2960 |
|
2015-10-27 |
2015-12-18 |
1.101928e+06 |
-7.897288 |
112.152083 |
900.0 |
1.109035e+06 |
0.0 |
-7107.5592 |
100936.8747 |
|
2016-03-10 |
2016-05-05 |
1.093921e+06 |
-7.278331 |
100.015950 |
1100.0 |
1.101928e+06 |
0.0 |
-8006.1641 |
110017.5450 |
|
2016-06-23 |
2016-06-27 |
1.089480e+06 |
-4.038123 |
95.582210 |
1100.0 |
1.093921e+06 |
0.0 |
-4441.9353 |
105140.4310 |
|
2016-06-30 |
2016-07-11 |
1.090989e+06 |
1.372569 |
95.084904 |
1100.0 |
1.089480e+06 |
0.0 |
1509.8259 |
104593.3944 |
|
2016-07-25 |
2016-09-01 |
1.101895e+06 |
9.914477 |
96.815526 |
1100.0 |
1.090989e+06 |
0.0 |
10905.9247 |
106497.0786 |
apple_backtest["End Port. Value"].plot()

我们的财产总额六年增加了10%。考虑到每次交易额只有总额的10%,这个成绩不算差。
同时我们也注意到这个策略并没有引发停止损失委托。这意味着我们可以不需要它么?这个难说。毕竟这个激发事件完全取决于我们的设定值。
停止损失委托是被自动激活的,它并不会考虑股市整体走势。也就是说不论是股市真正的走低还是暂时的波动都会激发停止损失委托。而后者是我们需要注意的因为在现实中,由价格波动激发停止损失委托不仅让你支出一笔交易费用,同时还无法保证最终的卖出价格是你设定的价格。
下面的链接分别支持和反对使用停止损失委托,但是之后的内容我不会要求我们的回溯测试系统使用它。这样可以简化系统,但不是很符合实际(我相信工业系统应该有停止损失委托)。
现实中我们不会只用总额的10%去押一支股票而是投资多种股票。在给定的时间可以跟不同公司同时交易,而且大部分财产应该在股票上,而不是现金。现在我们开始投资多支股票 (原文是stops,感觉是typo,译文按照stocks翻译),并且在两条移动平均线交叉的时候退市(不使用止损)。我们需要改变回溯测试的代码。我们会用一个pandas的DataFrame来存储所有股票的买卖,上一层的循环也需要记录更多的信息。
下面的函数用于产生买卖订单,以及另一回溯测试函数。
def ma_crossover_orders(stocks, fast, slow):
"""
:param stocks: A list of tuples, the first argument in each tuple being a string containing the ticker symbol of each stock (or however you want the stock represented, so long as it's unique), and the second being a pandas DataFrame containing the stocks, with a "Close" column and indexing by date (like the data frames returned by the Yahoo! Finance API)
:param fast: Integer for the number of days used in the fast moving average
:param slow: Integer for the number of days used in the slow moving average :return: pandas DataFrame containing stock orders This function takes a list of stocks and determines when each stock would be bought or sold depending on a moving average crossover strategy, returning a data frame with information about when the stocks in the portfolio are bought or sold according to the strategy
"""
fast_str =str(fast) +'d'
slow_str =str(slow) +'d'
ma_diff_str =fast_str +'-'+slow_str trades =pd.DataFrame({"Price": [], "Regime": [], "Signal": []})
fors instocks:
# Get the moving averages, both fast and slow, along with the difference in the moving averages
s[1][fast_str] =np.round(s[1]["Close"].rolling(window =fast, center =False).mean(), 2)
s[1][slow_str] =np.round(s[1]["Close"].rolling(window =slow, center =False).mean(), 2)
s[1][ma_diff_str] =s[1][fast_str] -s[1][slow_str] # np.where() is a vectorized if-else function, where a condition is checked for each component of a vector, and the first argument passed is used when the condition holds, and the other passed if it does not
s[1]["Regime"] =np.where(s[1][ma_diff_str] > 0, 1, 0)
# We have 1's for bullish regimes and 0's for everything else. Below I replace bearish regimes's values with -1, and to maintain the rest of the vector, the second argument is apple["Regime"]
s[1]["Regime"] =np.where(s[1][ma_diff_str] < 0, -1, s[1]["Regime"])
# To ensure that all trades close out, I temporarily change the regime of the last row to 0
regime_orig =s[1].ix[-1, "Regime"]
s[1].ix[-1, "Regime"] =0
s[1]["Signal"] =np.sign(s[1]["Regime"] -s[1]["Regime"].shift(1))
# Restore original regime data
s[1].ix[-1, "Regime"] =regime_orig # Get signals
signals =pd.concat([
pd.DataFrame({"Price": s[1].loc[s[1]["Signal"] ==1, "Close"],
"Regime": s[1].loc[s[1]["Signal"] ==1, "Regime"],
"Signal": "Buy"}),
pd.DataFrame({"Price": s[1].loc[s[1]["Signal"] ==-1, "Close"],
"Regime": s[1].loc[s[1]["Signal"] ==-1, "Regime"],
"Signal": "Sell"}),
])
signals.index =pd.MultiIndex.from_product([signals.index, [s[0]]], names =["Date", "Symbol"])
trades =trades.append(signals) trades.sort_index(inplace =True)
trades.index =pd.MultiIndex.from_tuples(trades.index, names =["Date", "Symbol"]) returntrades defbacktest(signals, cash, port_value =.1, batch =100):
"""
:param signals: pandas DataFrame containing buy and sell signals with stock prices and symbols, like that returned by ma_crossover_orders
:param cash: integer for starting cash value
:param port_value: maximum proportion of portfolio to risk on any single trade
:param batch: Trading batch sizes :return: pandas DataFrame with backtesting results This function backtests strategies, with the signals generated by the strategies being passed in the signals DataFrame. A fictitious portfolio is simulated and the returns generated by this portfolio are reported.
""" SYMBOL =1# Constant for which element in index represents symbol
portfolio =dict() # Will contain how many stocks are in the portfolio for a given symbol
port_prices =dict() # Tracks old trade prices for determining profits
# Dataframe that will contain backtesting report
results =pd.DataFrame({"Start Cash": [],
"End Cash": [],
"Portfolio Value": [],
"Type": [],
"Shares": [],
"Share Price": [],
"Trade Value": [],
"Profit per Share": [],
"Total Profit": []}) forindex, row insignals.iterrows():
# These first few lines are done for any trade
shares =portfolio.setdefault(index[SYMBOL], 0)
trade_val =0
batches =0
cash_change =row["Price"] *shares # Shares could potentially be a positive or negative number (cash_change will be added in the end; negative shares indicate a short)
portfolio[index[SYMBOL]] =0# For a given symbol, a position is effectively cleared old_price =port_prices.setdefault(index[SYMBOL], row["Price"])
portfolio_val =0
forkey, val inportfolio.items():
portfolio_val +=val *port_prices[key] ifrow["Signal"] =="Buy"androw["Regime"] ==1: # Entering a long position
batches =np.floor((portfolio_val +cash) *port_value) //np.ceil(batch *row["Price"]) # Maximum number of batches of stocks invested in
trade_val =batches *batch *row["Price"] # How much money is put on the line with each trade
cash_change -=trade_val # We are buying shares so cash will go down
portfolio[index[SYMBOL]] =batches *batch # Recording how many shares are currently invested in the stock
port_prices[index[SYMBOL]] =row["Price"] # Record price
old_price =row["Price"]
elifrow["Signal"] =="Sell"androw["Regime"] ==-1: # Entering a short
pass
# Do nothing; can we provide a method for shorting the market?
#else:
#raise ValueError("I don't know what to do with signal " + row["Signal"]) pprofit =row["Price"] -old_price # Compute profit per share; old_price is set in such a way that entering a position results in a profit of zero # Update report
results =results.append(pd.DataFrame({
"Start Cash": cash,
"End Cash": cash +cash_change,
"Portfolio Value": cash +cash_change +portfolio_val +trade_val,
"Type": row["Signal"],
"Shares": batch *batches,
"Share Price": row["Price"],
"Trade Value": abs(cash_change),
"Profit per Share": pprofit,
"Total Profit": batches *batch *pprofit
}, index =[index]))
cash +=cash_change # Final change to cash balance results.sort_index(inplace =True)
results.index =pd.MultiIndex.from_tuples(results.index, names =["Date", "Symbol"]) returnresults # Get more stocks
microsoft =web.DataReader("MSFT", "yahoo", start, end)
google =web.DataReader("GOOG", "yahoo", start, end)
facebook =web.DataReader("FB", "yahoo", start, end)
twitter =web.DataReader("TWTR", "yahoo", start, end)
netflix =web.DataReader("NFLX", "yahoo", start, end)
amazon =web.DataReader("AMZN", "yahoo", start, end)
yahoo =web.DataReader("YHOO", "yahoo", start, end)
sony =web.DataReader("SNY", "yahoo", start, end)
nintendo =web.DataReader("NTDOY", "yahoo", start, end)
ibm =web.DataReader("IBM", "yahoo", start, end)
hp =web.DataReader("HPQ", "yahoo", start, end)
signals =ma_crossover_orders([("AAPL", ohlc_adj(apple)),
("MSFT", ohlc_adj(microsoft)),
("GOOG", ohlc_adj(google)),
("FB", ohlc_adj(facebook)),
("TWTR", ohlc_adj(twitter)),
("NFLX", ohlc_adj(netflix)),
("AMZN", ohlc_adj(amazon)),
("YHOO", ohlc_adj(yahoo)),
("SNY", ohlc_adj(yahoo)),
("NTDOY", ohlc_adj(nintendo)),
("IBM", ohlc_adj(ibm)),
("HPQ", ohlc_adj(hp))],
fast =20, slow =50)
signals
|
Price |
Regime |
Signal |
||
|
Date |
Symbol |
|||
|
2010-03-16 |
AAPL |
29.355667 |
1.0 |
Buy |
|
AMZN |
131.789993 |
1.0 |
Buy |
|
|
GOOG |
282.318173 |
-1.0 |
Sell |
|
|
HPQ |
20.722316 |
1.0 |
Buy |
|
|
IBM |
110.563240 |
1.0 |
Buy |
|
|
MSFT |
24.677580 |
-1.0 |
Sell |
|
|
NFLX |
10.090000 |
1.0 |
Buy |
|
|
NTDOY |
37.099998 |
1.0 |
Buy |
|
|
SNY |
16.360001 |
-1.0 |
Sell |
|
|
YHOO |
16.360001 |
-1.0 |
Sell |
|
|
2010-03-17 |
SNY |
16.500000 |
1.0 |
Buy |
|
YHOO |
16.500000 |
1.0 |
Buy |
|
|
2010-03-22 |
GOOG |
278.472004 |
1.0 |
Buy |
|
2010-03-23 |
MSFT |
25.106096 |
1.0 |
Buy |
|
2010-05-03 |
GOOG |
265.035411 |
-1.0 |
Sell |
|
2010-05-10 |
HPQ |
19.435830 |
-1.0 |
Sell |
|
2010-05-14 |
NTDOY |
35.799999 |
-1.0 |
Sell |
|
2010-05-17 |
SNY |
16.270000 |
-1.0 |
Sell |
|
YHOO |
16.270000 |
-1.0 |
Sell |
|
|
2010-05-19 |
AMZN |
124.589996 |
-1.0 |
Sell |
|
MSFT |
23.835187 |
-1.0 |
Sell |
|
|
2010-05-21 |
IBM |
108.322991 |
-1.0 |
Sell |
|
2010-06-10 |
AAPL |
32.764038 |
0.0 |
Sell |
|
2010-06-11 |
AAPL |
33.156405 |
-1.0 |
Sell |
|
2010-06-18 |
AAPL |
35.845436 |
1.0 |
Buy |
|
2010-06-28 |
IBM |
111.397697 |
1.0 |
Buy |
|
2010-07-01 |
IBM |
105.861499 |
-1.0 |
Sell |
|
2010-07-06 |
IBM |
106.630175 |
1.0 |
Buy |
|
2010-07-09 |
NTDOY |
36.950001 |
1.0 |
Buy |
|
2010-07-20 |
IBM |
109.298956 |
-1.0 |
Sell |
|
… |
… |
… |
… |
… |
|
2016-06-23 |
AAPL |
95.582210 |
1.0 |
Buy |
|
TWTR |
17.040001 |
1.0 |
Buy |
|
|
2016-06-27 |
AAPL |
91.544087 |
-1.0 |
Sell |
|
FB |
108.970001 |
-1.0 |
Sell |
|
|
2016-06-28 |
SNY |
36.040001 |
-1.0 |
Sell |
|
YHOO |
36.040001 |
-1.0 |
Sell |
|
|
2016-06-30 |
AAPL |
95.084904 |
1.0 |
Buy |
|
NFLX |
91.480003 |
0.0 |
Sell |
|
|
2016-07-01 |
NFLX |
96.669998 |
-1.0 |
Sell |
|
SNY |
37.990002 |
1.0 |
Buy |
|
|
YHOO |
37.990002 |
1.0 |
Buy |
|
|
2016-07-11 |
AAPL |
96.457473 |
-1.0 |
Sell |
|
NTDOY |
27.700001 |
1.0 |
Buy |
|
|
2016-07-14 |
MSFT |
53.407133 |
1.0 |
Buy |
|
2016-07-25 |
AAPL |
96.815526 |
1.0 |
Buy |
|
FB |
121.629997 |
1.0 |
Buy |
|
|
2016-07-26 |
GOOG |
738.419983 |
1.0 |
Buy |
|
2016-08-18 |
NFLX |
96.160004 |
1.0 |
Buy |
|
2016-09-01 |
AAPL |
106.730003 |
1.0 |
Sell |
|
2016-09-02 |
AMZN |
772.440002 |
1.0 |
Sell |
|
FB |
126.510002 |
1.0 |
Sell |
|
|
GOOG |
771.460022 |
1.0 |
Sell |
|
|
HPQ |
14.490000 |
1.0 |
Sell |
|
|
IBM |
159.550003 |
1.0 |
Sell |
|
|
MSFT |
57.669998 |
1.0 |
Sell |
|
|
NFLX |
97.379997 |
1.0 |
Sell |
|
|
NTDOY |
28.840000 |
1.0 |
Sell |
|
|
SNY |
43.279999 |
1.0 |
Sell |
|
|
TWTR |
19.549999 |
1.0 |
Sell |
|
|
YHOO |
43.279999 |
1.0 |
Sell |
475 rows × 3 columns
bk =backtest(signals, 1000000)
bk
|
End Cash |
Portfolio Value |
Profit per Share |
Share Price |
Shares |
Start Cash |
Total Profit |
Trade Value |
Type |
||
|
Date |
Symbol |
|||||||||
|
2010-03-16 |
AAPL |
9.001907e+05 |
1.000000e+06 |
0.000000 |
29.355667 |
3400.0 |
1.000000e+06 |
0.0 |
99809.2678 |
Buy |
|
AMZN |
8.079377e+05 |
1.000000e+06 |
0.000000 |
131.789993 |
700.0 |
9.001907e+05 |
0.0 |
92252.9951 |
Buy |
|
|
GOOG |
8.079377e+05 |
1.000000e+06 |
0.000000 |
282.318173 |
0.0 |
8.079377e+05 |
0.0 |
0.0000 |
Sell |
|
|
HPQ |
7.084706e+05 |
1.000000e+06 |
0.000000 |
20.722316 |
4800.0 |
8.079377e+05 |
0.0 |
99467.1168 |
Buy |
|
|
IBM |
6.089637e+05 |
1.000000e+06 |
0.000000 |
110.563240 |
900.0 |
7.084706e+05 |
0.0 |
99506.9160 |
Buy |
|
|
MSFT |
6.089637e+05 |
1.000000e+06 |
0.000000 |
24.677580 |
0.0 |
6.089637e+05 |
0.0 |
0.0000 |
Sell |
|
|
NFLX |
5.090727e+05 |
1.000000e+06 |
0.000000 |
10.090000 |
9900.0 |
6.089637e+05 |
0.0 |
99891.0000 |
Buy |
|
|
NTDOY |
4.126127e+05 |
1.000000e+06 |
0.000000 |
37.099998 |
2600.0 |
5.090727e+05 |
0.0 |
96459.9948 |
Buy |
|
|
SNY |
4.126127e+05 |
1.000000e+06 |
0.000000 |
16.360001 |
0.0 |
4.126127e+05 |
0.0 |
0.0000 |
Sell |
|
|
YHOO |
4.126127e+05 |
1.000000e+06 |
0.000000 |
16.360001 |
0.0 |
4.126127e+05 |
0.0 |
0.0000 |
Sell |
|
|
2010-03-17 |
SNY |
3.136127e+05 |
1.000000e+06 |
0.000000 |
16.500000 |
6000.0 |
4.126127e+05 |
0.0 |
99000.0000 |
Buy |
|
YHOO |
2.146127e+05 |
1.000000e+06 |
0.000000 |
16.500000 |
6000.0 |
3.136127e+05 |
0.0 |
99000.0000 |
Buy |
|
|
2010-03-22 |
GOOG |
1.310711e+05 |
1.000000e+06 |
0.000000 |
278.472004 |
300.0 |
2.146127e+05 |
0.0 |
83541.6012 |
Buy |
|
2010-03-23 |
MSFT |
3.315733e+04 |
1.000000e+06 |
0.000000 |
25.106096 |
3900.0 |
1.310711e+05 |
0.0 |
97913.7744 |
Buy |
|
2010-05-03 |
GOOG |
1.126680e+05 |
9.959690e+05 |
-13.436593 |
265.035411 |
0.0 |
3.315733e+04 |
-0.0 |
79510.6233 |
Sell |
|
2010-05-10 |
HPQ |
2.059599e+05 |
9.897939e+05 |
-1.286486 |
19.435830 |
0.0 |
1.126680e+05 |
-0.0 |
93291.9840 |
Sell |
|
2010-05-14 |
NTDOY |
2.990399e+05 |
9.864139e+05 |
-1.299999 |
35.799999 |
0.0 |
2.059599e+05 |
-0.0 |
93079.9974 |
Sell |
|
2010-05-17 |
SNY |
3.966599e+05 |
9.850339e+05 |
-0.230000 |
16.270000 |
0.0 |
2.990399e+05 |
-0.0 |
97620.0000 |
Sell |
|
YHOO |
4.942799e+05 |
9.836539e+05 |
-0.230000 |
16.270000 |
0.0 |
3.966599e+05 |
-0.0 |
97620.0000 |
Sell |
|
|
2010-05-19 |
AMZN |
5.814929e+05 |
9.786139e+05 |
-7.199997 |
124.589996 |
0.0 |
4.942799e+05 |
-0.0 |
87212.9972 |
Sell |
|
MSFT |
6.744502e+05 |
9.736573e+05 |
-1.270909 |
23.835187 |
0.0 |
5.814929e+05 |
-0.0 |
92957.2293 |
Sell |
|
|
2010-05-21 |
IBM |
7.719409e+05 |
9.716411e+05 |
-2.240249 |
108.322991 |
0.0 |
6.744502e+05 |
-0.0 |
97490.6919 |
Sell |
|
2010-06-10 |
AAPL |
8.833386e+05 |
9.832296e+05 |
3.408371 |
32.764038 |
0.0 |
7.719409e+05 |
0.0 |
111397.7292 |
Sell |
|
2010-06-11 |
AAPL |
8.833386e+05 |
9.832296e+05 |
3.800738 |
33.156405 |
0.0 |
8.833386e+05 |
0.0 |
0.0000 |
Sell |
|
2010-06-18 |
AAPL |
7.865559e+05 |
9.832296e+05 |
0.000000 |
35.845436 |
2700.0 |
8.833386e+05 |
0.0 |
96782.6772 |
Buy |
|
2010-06-28 |
IBM |
6.974378e+05 |
9.832296e+05 |
0.000000 |
111.397697 |
800.0 |
7.865559e+05 |
0.0 |
89118.1576 |
Buy |
|
2010-07-01 |
IBM |
7.821270e+05 |
9.788006e+05 |
-5.536198 |
105.861499 |
0.0 |
6.974378e+05 |
-0.0 |
84689.1992 |
Sell |
|
2010-07-06 |
IBM |
6.861598e+05 |
9.788006e+05 |
0.000000 |
106.630175 |
900.0 |
7.821270e+05 |
0.0 |
95967.1575 |
Buy |
|
2010-07-09 |
NTDOY |
5.900898e+05 |
9.788006e+05 |
0.000000 |
36.950001 |
2600.0 |
6.861598e+05 |
0.0 |
96070.0026 |
Buy |
|
2010-07-20 |
IBM |
6.884589e+05 |
9.812025e+05 |
2.668781 |
109.298956 |
0.0 |
5.900898e+05 |
0.0 |
98369.0604 |
Sell |
|
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
|
2016-06-23 |
AAPL |
3.951693e+05 |
1.863808e+06 |
0.000000 |
95.582210 |
1900.0 |
5.767755e+05 |
0.0 |
181606.1990 |
Buy |
|
TWTR |
2.094333e+05 |
1.863808e+06 |
0.000000 |
17.040001 |
10900.0 |
3.951693e+05 |
0.0 |
185736.0109 |
Buy |
|
|
2016-06-27 |
AAPL |
3.833670e+05 |
1.856135e+06 |
-4.038123 |
91.544087 |
0.0 |
2.094333e+05 |
-0.0 |
173933.7653 |
Sell |
|
FB |
5.795130e+05 |
1.862921e+06 |
3.770004 |
108.970001 |
0.0 |
3.833670e+05 |
0.0 |
196146.0018 |
Sell |
|
|
2016-06-28 |
SNY |
7.885450e+05 |
1.880959e+06 |
3.110001 |
36.040001 |
0.0 |
5.795130e+05 |
0.0 |
209032.0058 |
Sell |
|
YHOO |
9.975770e+05 |
1.898997e+06 |
3.110001 |
36.040001 |
0.0 |
7.885450e+05 |
0.0 |
209032.0058 |
Sell |
|
|
2016-06-30 |
AAPL |
8.169157e+05 |
1.898997e+06 |
0.000000 |
95.084904 |
1900.0 |
9.975770e+05 |
0.0 |
180661.3176 |
Buy |
|
NFLX |
9.907277e+05 |
1.893981e+06 |
-2.640000 |
91.480003 |
0.0 |
8.169157e+05 |
-0.0 |
173812.0057 |
Sell |
|
|
2016-07-01 |
NFLX |
9.907277e+05 |
1.893981e+06 |
2.549995 |
96.669998 |
0.0 |
9.907277e+05 |
0.0 |
0.0000 |
Sell |
|
SNY |
8.045767e+05 |
1.893981e+06 |
0.000000 |
37.990002 |
4900.0 |
9.907277e+05 |
0.0 |
186151.0098 |
Buy |
|
|
YHOO |
6.184257e+05 |
1.893981e+06 |
0.000000 |
37.990002 |
4900.0 |
8.045767e+05 |
0.0 |
186151.0098 |
Buy |
|
|
2016-07-11 |
AAPL |
8.016949e+05 |
1.896589e+06 |
1.372569 |
96.457473 |
0.0 |
6.184257e+05 |
0.0 |
183269.1987 |
Sell |
|
NTDOY |
6.133349e+05 |
1.896589e+06 |
0.000000 |
27.700001 |
6800.0 |
8.016949e+05 |
0.0 |
188360.0068 |
Buy |
|
|
2016-07-14 |
MSFT |
4.264099e+05 |
1.896589e+06 |
0.000000 |
53.407133 |
3500.0 |
6.133349e+05 |
0.0 |
186924.9655 |
Buy |
|
2016-07-25 |
AAPL |
2.424604e+05 |
1.896589e+06 |
0.000000 |
96.815526 |
1900.0 |
4.264099e+05 |
0.0 |
183949.4994 |
Buy |
|
FB |
6.001543e+04 |
1.896589e+06 |
0.000000 |
121.629997 |
1500.0 |
2.424604e+05 |
0.0 |
182444.9955 |
Buy |
|
|
2016-07-26 |
GOOG |
-8.766857e+04 |
1.896589e+06 |
0.000000 |
738.419983 |
200.0 |
6.001543e+04 |
0.0 |
147683.9966 |
Buy |
|
2016-08-18 |
NFLX |
-2.703726e+05 |
1.896589e+06 |
0.000000 |
96.160004 |
1900.0 |
-8.766857e+04 |
0.0 |
182704.0076 |
Buy |
|
2016-09-01 |
AAPL |
-6.758557e+04 |
1.915427e+06 |
9.914477 |
106.730003 |
0.0 |
-2.703726e+05 |
0.0 |
202787.0057 |
Sell |
|
2016-09-02 |
AMZN |
1.641464e+05 |
1.979327e+06 |
213.000000 |
772.440002 |
0.0 |
-6.758557e+04 |
0.0 |
231732.0006 |
Sell |
|
FB |
3.539114e+05 |
1.986647e+06 |
4.880005 |
126.510002 |
0.0 |
1.641464e+05 |
0.0 |
189765.0030 |
Sell |
|
|
GOOG |
5.082034e+05 |
1.993255e+06 |
33.040039 |
771.460022 |
0.0 |
3.539114e+05 |
0.0 |
154292.0044 |
Sell |
|
|
HPQ |
7.081654e+05 |
2.006030e+06 |
0.925746 |
14.490000 |
0.0 |
5.082034e+05 |
0.0 |
199962.0000 |
Sell |
|
|
IBM |
8.996254e+05 |
2.015652e+06 |
8.018727 |
159.550003 |
0.0 |
7.081654e+05 |
0.0 |
191460.0036 |
Sell |
|
|
MSFT |
1.101470e+06 |
2.030572e+06 |
4.262865 |
57.669998 |
0.0 |
8.996254e+05 |
0.0 |
201844.9930 |
Sell |
|
|
NFLX |
1.286492e+06 |
2.032890e+06 |
1.219993 |
97.379997 |
0.0 |
1.101470e+06 |
0.0 |
185021.9943 |
Sell |
|
|
NTDOY |
1.482604e+06 |
2.040642e+06 |
1.139999 |
28.840000 |
0.0 |
1.286492e+06 |
0.0 |
196112.0000 |
Sell |
|
|
SNY |
1.694676e+06 |
2.066563e+06 |
5.289997 |
43.279999 |
0.0 |
1.482604e+06 |
0.0 |
212071.9951 |
Sell |
|
|
TWTR |
1.907771e+06 |
2.093922e+06 |
2.509998 |
19.549999 |
0.0 |
1.694676e+06 |
0.0 |
213094.9891 |
Sell |
|
|
YHOO |
2.119843e+06 |
2.119843e+06 |
5.289997 |
43.279999 |
0.0 |
1.907771e+06 |
0.0 |
212071.9951 |
Sell |
475 rows × 9 columns
bk["Portfolio Value"].groupby(level =0).apply(lambdax: x[-1]).plot()

更为现实的投资组合可以投资任何12支股票而达到100%的收益。这个看上去不错,但是我们可以做得更好。
基准分析法
基准分析法可以分析交易策略效率的好坏。所谓基准分析,就是将策略和其他(著名)策略进行比较从而评价该策略的表现好坏。
每次你评价交易系统的时候,都要跟买入持有策略(SPY)进行比较。除了一些信托基金和少数投资经理没有使用它,该策略在大多时候都是无敌的。有效市场假说强调没有人能战胜股票市场,所以每个人都应该购入指数基金,因为它能反应整个市场的构成。SPY是一个交易型开放式指数基金(一种可以像股票一样交易的信托基金),它的价格有效反映了S&P 500中的股票价格。买入并持有SPY,说明你可以有效地匹配市场回报率而不是战胜它。
下面是SPY的数据,让我们看看简单买入持有SPY能得到的回报:
spyder =web.DataReader("SPY", "yahoo", start, end)
spyder.iloc[[0,-1],:]
|
Open |
High |
Low |
Close |
Volume |
Adj Close |
|
|
Date |
||||||
|
2010-01-04 |
112.370003 |
113.389999 |
111.510002 |
113.330002 |
118944600 |
99.292299 |
|
2016-09-01 |
217.369995 |
217.729996 |
216.029999 |
217.389999 |
93859000 |
217.389999 |
batches =1000000//np.ceil(100*spyder.ix[0,"Adj Close"]) # Maximum number of batches of stocks invested in
trade_val =batches *batch *spyder.ix[0,"Adj Close"] # How much money is used to buy SPY
final_val =batches *batch *spyder.ix[-1,"Adj Close"] +(1000000-trade_val) # Final value of the portfolio
final_val
2180977.0
# We see that the buy-and-hold strategy beats the strategy we developed earlier. I would also like to see a plot.
ax_bench =(spyder["Adj Close"] /spyder.ix[0, "Adj Close"]).plot(label ="SPY")
ax_bench =(bk["Portfolio Value"].groupby(level =0).apply(lambdax: x[-1]) /1000000).plot(ax =ax_bench, label ="Portfolio")
ax_bench.legend(ax_bench.get_lines(), [l.get_label() forl inax_bench.get_lines()], loc ='best')
ax_bench

买入持有SPY比我们当前的交易系统好——我们的系统还没有考虑不菲的交易费用。考虑到机会成本和该策略的消耗,我们不应该用它。
怎样才能改进我们的系统呢?对于初学者来尽量多样化是一个选择。目前我们所有的股票都来自技术公司,这意味着技术型公司的不景气会反映在我们的投资组合上。我们应该设计一个可以利用空头头寸和熊市的系统,这样不管市场如何变动,我们都可以盈利。我们也可以寻求更好的方法预测股票的最高期望价格。但是不论如何我们都需要做得比SPY更好,不然由于我们的系统会自带机会成本,是没用的。
其他的基准策略也是存在的。如果我们的系统比“买入持有SPY”更好,我们可以进一步跟其他的系统比较,例如:

(我最初在这里接触到这些策略)基本准则仍然是:不要使用一个复杂的,包含大量交易的系统如果它赢不了一个简单的交易不频繁的指数基金模型。(事实上这个标准挺难实现的)
最后要强调的是,假设你的交易系统在回溯测试中打败了所有的基准系统,也不意味着它能够准确地预测未来。因为回溯测试容易过拟合,它不能用于预测未来。
结论
虽然讲座最后的结论不是那么乐观,但记住有效市场理论也有缺陷。我个人的观点是当交易更多依赖于算法的时候,就更难战胜市场。有一个说法是:信托基金都不太可能战胜市场,你的系统能战胜市场仅仅是一个可能性而已。(当然信托基金表现很差的原因是收费太高,而指数基金不存在这个问题。)
本讲座只简单地说明了一种基于移动平均的交易策略。还有许多别的交易策略这里并没有提到。而且我们也没有深入探讨空头股票和货币交易。特别是股票期权有很多东西可以讲,它也提供了不同的方法来预测股票的走向。你可以在Derivatives Analytics with Python: Data Analysis, Models, Simulation, Calibration and Hedging书中读到更多的相关内容。(犹他大学的图书馆有这本书)
另一个资源是O’Reilly出的Python for Finance,犹他大学的图书馆里也有。
记住在股票里面亏钱是很正常的,同样股市也能提供其他方法无法提供的高回报,每一个投资策略都应该是经过深思熟虑的。这个讲座旨在抛砖引玉,希望同学们自己进一步探讨这个话题。
作业
问题1
建立一个基于移动平均的交易系统(不需要止损条件)。选择15支2010年1月1日之前上市的股票,利用回溯测试检验你的 系统,并且SPY基准作比较,你的系统能战胜市场吗?
问题2
在现实中每一笔交易都要支付一笔佣金。弄明白如何计算佣金,然后修改你的backtes()函数,使之能够计算不同的佣金模式(固定费用,按比例收费等等)。
我们现在的移动平均交汇点分析系统在两条平均线交叉的时候触发交易。修改系统令其更准确:


当你完成修改之后,重复问题1,使用一个真实的佣金策略(从交易所查)来模拟你的系统,同时要求移动平均差异达到一定的移动标准差再激发交易。
问题3
我们的交易系统无法处理空头股票。空头买卖的复杂性在于损失是没有下限的(多头头寸的最大损失等于购入股票的总价格)。学习如何处理空头头寸,然后修改backtest()使其能够处理空头交易。思考要如何实现空头交易,包括允许多少空头交易?在进行其他交易的时候如何处理空头交易?提示:空头交易的量在函数中可以用一个负数来表示。
完成之后重复问题1,也可以同时考虑问题2中提到的因素。
【转】用Python做股市量化策略投资数据分析的更多相关文章
- 用Python做股市数据分析(二)
本文由 伯乐在线 - 小米云豆粥 翻译.未经许可,禁止转载!英文出处:Curtis Miller.欢迎加入翻译组. 这篇博文是用Python分析股市数据系列两部中的第二部,内容基于我在犹他大学 数学3 ...
- 用Python做股市数据分析(一)
本文由 伯乐在线 - 小米云豆粥 翻译.未经许可,禁止转载!英文出处:Curtis Miller.欢迎加入翻译组. 这篇博文是用Python分析股市数据系列两部中的第一部,内容基于我犹他大学 数学39 ...
- python做量化交易干货分享
http://www.newsmth.NET/nForum/#!article/Python/128763 最近程序化交易很热,量化也是我很感兴趣的一块. 国内量化交易的平台有几家,我个人比较喜欢用的 ...
- Python与金融量化分析----金融与量化投资
一:金融了解 金融:就是对现有资源进行重新的整合之后,进行价值和利润的等效流通. 金融工具: 股票 期货 黄金 外汇 基金 ............. 股票: 股票是股份公司发给出资人多的一种凭证,股 ...
- 你用 Python 做过什么有趣的数据挖掘项目?
有网友在知乎提问:「你用 Python 做过什么有趣的数据挖掘项目?」 我最近刚开始学习 Python, numpy, scipy 等, 想做一些数据方面的项目,但是之前又没有这方面的经验.所以想知道 ...
- day32 Python与金融量化分析(二)
第一部分:金融与量化投资 股票: 股票是股份公司发给出资人的一种凭证,股票的持有者就是股份公司的股东. 股票的面值与市值 面值表示票面金额 市值表示市场价值 上市/IPO: 企业通过证券交易所公开向社 ...
- python做语音信号处理
音频信号的读写.播放及录音 标准的python已经支持WAV格式的书写,而实时的声音输入输出需要安装pyAudio(http://people.csail.mit.edu/hubert/pyaudio ...
- 【Python必学】Python爬虫反爬策略你肯定不会吧?
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 正文 Python爬虫反爬策略三部曲,拥有这三步曲就可以在爬虫界立足了: ...
- 用python做时间序列预测九:ARIMA模型简介
本篇介绍时间序列预测常用的ARIMA模型,通过了解本篇内容,将可以使用ARIMA预测一个时间序列. 什么是ARIMA? ARIMA是'Auto Regressive Integrated Moving ...
随机推荐
- woocommerce直接调取产品描述内容
最近一位客户想让woocommerce产品页直接调取描述内容,不想太多的tab切换,太复杂,这个蛮简单的,woocommerce是在wordpress基础开发的,产品也是post的一种类型,直接调用c ...
- springboot 整合 mybatis 入门
springboot整合mybatis 0.yml 配置文件 1.创建数据库表. 2.创建实体类. 3.创建 Mapper 接口 ,添加 @Mapper 注解. 4.创建 Mapper 映射文件. & ...
- ValueError: Dependency on app with no migrations: customuser
You haven't run manage.py makemigrations customuser to create the migrations for your CustomUser app ...
- 常用dos命令(3)
网络命令 ping 进行网络连接测试.名称解析 ftp 文件传输 net 网络命令集及用户管理 telnet 远程登陆 ipconfig显示.修改TCP/IP设置 msg 给用户发送消息 arp 显示 ...
- hdu1005-Number Sequence-(循环节)
题意:已知f(1) = 1, f(2) = 1, f(n) = (A * f(n - 1) + B * f(n - 2)) mod 7,给出A,B,n,求f(n) 题解:n巨大,循环肯定超时,在模7的 ...
- .Net反射-基础2-BindingFlags参数
BindingFlags参数用于指定反射查找的范围在调用下列方法时会用到BindingFlags参数 // 调用方法. InvokeMethod // 创建实例. CreateInstance // ...
- SFTP 文件上传下载工具类
SFTPUtils.java import com.jcraft.jsch.*; import com.jcraft.jsch.ChannelSftp.LsEntry; import lombok.e ...
- prototype、__proto__、constructor
prototype:每个函数都有一个prototype属性,这个属性指向一个对象,这个对象叫原型对象. 作用:节约内存.扩展属性和方法.可以实现类之间的继承 __proto__:每个通过构造函数new ...
- T2:中间值(median)———2019.10.15
代码: #include <bits/stdc++.h> int ri() { , f = ; ; ) + (x << ) - ' + c; return x * f; } ; ...
- TensorFlow多层感知机函数逼近过程详解
http://c.biancheng.net/view/1924.html Hornik 等人的工作(http://www.cs.cmu.edu/~bhiksha/courses/deeplearni ...