[机器学习&数据挖掘]机器学习实战决策树plotTree函数完全解析
在看机器学习实战时候,到第三章的对决策树画图的时候,有一段递归函数怎么都看不懂,因为以后想选这个方向为自己的职业导向,抱着精看的态度,对这本树进行地毯式扫描,所以就没跳过,一直卡了一天多,才差不多搞懂,才对那个函数中的plotTree.xOff的取值,以及计算cntrPt的方法搞懂,相信也有人和我一样,希望能够相互交流。
先把代码贴在这里:
import matplotlib.pyplot as plt #这里是对绘制是图形属性的一些定义,可以不用管,主要是后面的算法
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-") #这是递归计算树的叶子节点个数,比较简单
def getNumLeafs(myTree):
numLeafs = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
#这是递归计算树的深度,比较简单
def getTreeDepth(myTree):
maxDepth = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
#这个是用来一注释形式绘制节点和箭头线,可以不用管
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args )
#这个是用来绘制线上的标注,简单
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
#重点,递归,决定整个树图的绘制,难(自己认为)
def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) #this determines the x width of this tree
depth = getTreeDepth(myTree)
firstStr = myTree.keys()[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key],cntrPt,str(key)) #recursion
else: #it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#if you do get a dictonary you know it's a tree, and the first element will be another dict #这个是真正的绘制,上边是逻辑的绘制
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False) #no ticks
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '')
plt.show() #这个是用来创建数据集即决策树
def retrieveTree(i):
listOfTrees =[{'no surfacing': {0:{'flippers': {0: 'no', 1: 'yes'}}, 1: {'flippers': {0: 'no', 1: 'yes'}}, 2:{'flippers': {0: 'no', 1: 'yes'}}}},
{'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
]
return listOfTrees[i] createPlot(retrieveTree(0))
绘制出来的图形如下:
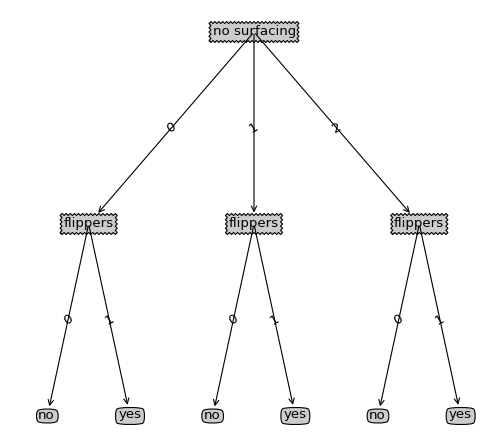
先导:这里说一下为什么说一个递归树的绘制为什么会是很难懂,这里不就是利用递归函数来绘图么,就如递归计算树的深度、叶子节点一样,问题不是递归的思路,而是这本书中一些坐标的起始取值、以及在计算节点坐标所作的处理,而且在树中对这部分并没有取讲述,所以在看这段代码的时候可能大体思路明白但是具体的细节却知之甚少,所以本篇主要是对其中书中提及甚少的作详细的讲述,当然代码的整体思路也不会放过的
准备:这里说一下具体绘制的时候是利用自定义plotNode函数来绘制,这个函数一次绘制的是一个箭头和一个节点,如下图:

思路:这里绘图,作者选取了一个很聪明的方式,并不会因为树的节点的增减和深度的增减而导致绘制出来的图形出现问题,当然不能太密集。这里利用整棵树的叶子节点数作为份数将整个x轴的长度进行平均切分,利用树的深度作为份数将y轴长度作平均切分,并利用plotTree.xOff作为最近绘制的一个叶子节点的x坐标,当再一次绘制叶子节点坐标的时候才会plotTree.xOff才会发生改变;用plotTree.yOff作为当前绘制的深度,plotTree.yOff是在每递归一层就会减一份(上边所说的按份平均切分),其他时候是利用这两个坐标点去计算非叶子节点,这两个参数其实就可以确定一个点坐标,这个坐标确定的时候就是绘制节点的时候
整体算法的递归思路倒是很容易理解:
每一次都分三个步骤:
(1)绘制自身
(2)判断子节点非叶子节点,递归
(3)判断子节点为叶子节点,绘制
详细解析:
def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) #this determines the x width of this tree
depth = getTreeDepth(myTree)
firstStr = myTree.keys()[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key],cntrPt,str(key)) #recursion
else: #it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#if you do get a dictonary you know it's a tree, and the first element will be another dict def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False) #no ticks
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;#totalW为整树的叶子节点树,totalD为深度
plotTree(inTree, (0.5,1.0), '')
plt.show()
上边代码中红色部分如此处理原理:
首先由于整个画布根据叶子节点数和深度进行平均切分,并且x轴的总长度为1,即如同下图:

1、其中方形为非叶子节点的位置,@是叶子节点的位置,因此每份即上图的一个表格的长度应该为1/plotTree.totalW,但是叶子节点的位置应该为@所在位置,则在开始的时候plotTree.xOff的赋值为-0.5/plotTree.totalW,即意为开始x位置为第一个表格左边的半个表格距离位置,这样作的好处为:在以后确定@位置时候可以直接加整数倍的1/plotTree.totalW,
2、对于plotTree函数中的红色部分即如下:
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotTree.xOff即为最近绘制的一个叶子节点的x坐标,在确定当前节点位置时每次只需确定当前节点有几个叶子节点,因此其叶子节点所占的总距离就确定了即为float(numLeafs)/plotTree.totalW*1(因为总长度为1),因此当前节点的位置即为其所有叶子节点所占距离的中间即一半为float(numLeafs)/2.0/plotTree.totalW*1,但是由于开始plotTree.xOff赋值并非从0开始,而是左移了半个表格,因此还需加上半个表格距离即为1/2/plotTree.totalW*1,则加起来便为(1.0 + float(numLeafs))/2.0/plotTree.totalW*1,因此偏移量确定,则x位置变为plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW
3、对于plotTree函数参数赋值为(0.5, 1.0)
因为开始的根节点并不用划线,因此父节点和当前节点的位置需要重合,利用2中的确定当前节点的位置便为(0.5, 1.0)
总结:利用这样的逐渐增加x的坐标,以及逐渐降低y的坐标能能够很好的将树的叶子节点数和深度考虑进去,因此图的逻辑比例就很好的确定了,这样不用去关心输出图形的大小,一旦图形发生变化,函数会重新绘制,但是假如利用像素为单位来绘制图形,这样缩放图形就比较有难度了
[机器学习&数据挖掘]机器学习实战决策树plotTree函数完全解析的更多相关文章
- 机器学习&&数据挖掘之一:决策树基础认识
决策树入门篇 前言:分类是数据挖掘中的主要分析手段,其任务就是对数据集进行学习并构造一个拥有预测功能的分类模型,用于预测未知样本的类标号,把类标号未知的样本按照某一规则映射到预先给定的类标号中. 分类 ...
- 机器学习实战 -- 决策树(ID3)
机器学习实战 -- 决策树(ID3) ID3是什么我也不知道,不急,知道他是干什么的就行 ID3是最经典最基础的一种决策树算法,他会将每一个特征都设为决策节点,有时候,一个数据集中,某些特征属 ...
- 机器学习实战---决策树CART回归树实现
机器学习实战---决策树CART简介及分类树实现 一:对比分类树 CART回归树和CART分类树的建立算法大部分是类似的,所以这里我们只讨论CART回归树和CART分类树的建立算法不同的地方.首先,我 ...
- 《机器学习实践》程序清单3-7 plotTree函数
这个plotTree函数,比较聪明,比较简化,比较抽象,作者一定是逐步优化和简化到这个程度的.我是花了小两天时间,断断续续看明白的,还是在参考了另一篇文章以后.这里是链接http://www.cnbl ...
- 机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
前言: 找工作时(IT行业),除了常见的软件开发以外,机器学习岗位也可以当作是一个选择,不少计算机方向的研究生都会接触这个,如果你的研究方向是机器学习/数据挖掘之类,且又对其非常感兴趣的话,可以考虑考 ...
- 机器学习&数据挖掘笔记_14(GMM-HMM语音识别简单理解)
为了对GMM-HMM在语音识别上的应用有个宏观认识,花了些时间读了下HTK(用htk完成简单的孤立词识别)的部分源码,对该算法总算有了点大概认识,达到了预期我想要的.不得不说,网络上关于语音识别的通俗 ...
- 机器学习&数据挖掘笔记(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 前言: 找工作时( ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- [resource-]Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
reference: http://www.52nlp.cn/python-%e7%bd%91%e9%a1%b5%e7%88%ac%e8%99%ab-%e6%96%87%e6%9c%ac%e5%a4% ...
随机推荐
- vector 简介
vector简介 vector是STL中最常见的容器,它是一种顺序容器,支持随机访问.vector是一块连续分配的内存,从数据安排的角度来讲,和数组极其相似, 不同的地方就是:数组是静态分配空间,一旦 ...
- 机器学习英雄访谈录之 DL 自由职业者:Tuatini Godard
目录 机器学习英雄访谈录之 DL 自由职业者:Tuatini Godard 正文 对我的启发 机器学习英雄访谈录之 DL 自由职业者:Tuatini Godard Sanyam Bhutani 是 M ...
- K8s爆严重安全漏洞?有何应对措施与建议
Kubernetes最近爆出严重安全漏洞,影响几乎目前所有的版本.实际影响究竟多大?老版本用户是否必须升级?以下是华为云容器服务团队对该漏洞的分析解读. Kubernetes爆出的严重安全漏洞: 攻击 ...
- rethinking virtual network embedding..substrate support for path splitting and migration阅读笔记
1.引言 网络虚拟化, 1.支持同一个底层网络有多种网络架构,每种架构定制一个应用或用户社区. 2.也可以让多个服务提供者在共同的物理基础设施上定制端到端的服务.如Voice over IP(VoIP ...
- 组件 -- Button
.btn --------------------------------- button的背景色: .btn-primary .btn-success .btn-secondary .btn-dan ...
- 【iMooc】全面解析java注解
在慕课上学习了一个关于java注解的课程,下面是笔记以及一些源码. Annotation——注解 1.JDK中的注解 JDK中包括下面三种注解: @Override:标记注解(marker annot ...
- OneZero第二周第三次站立会议(2016.3.30)
会议时间:2016年3月30日 13:00~13:20 会议成员:冉华,张敏,王巍,夏一鸣. 会议目的:汇报前一天工作,全体成员评论,确定会后修改内容或分配下一步任务. 会议内容: 1.前端,完成功 ...
- 洛谷P4301 [CQOI2013]新Nim游戏
P4301 [CQOI2013]新Nim游戏 题目描述 传统的Nim游戏是这样的:有一些火柴堆,每堆都有若干根火柴(不同堆的火柴数量可以不同).两个游戏者轮流操作,每次可以选一个火柴堆拿走若干根火柴. ...
- 去除百度搜索结果中的广告的 js 代码
在百度页面下控制台里执行如下代码, 然后关掉控制台 setInterval(() => { try{ Array.from( document.querySelectorAll('#conten ...
- 【AI科技大本营】
从AutoML.机器学习新算法.底层计算.对抗性攻击.模型应用与底层理解,到开源数据集.Tensorflow和TPU,Google Brain 负责人Jeff Dean发长文来总结他们2017年所做的 ...