爬虫笔记之刷小怪练级:yymp3爬虫(音乐类爬虫)
一、目标
爬取http://www.yymp3.com网站歌曲相关信息,包括歌曲名字、作者相关信息、歌曲的音频数据、歌曲的歌词数据。
二、分析
2.1 歌曲信息、歌曲音频数据下载地址的获取
随便打开一首歌曲的详情页:
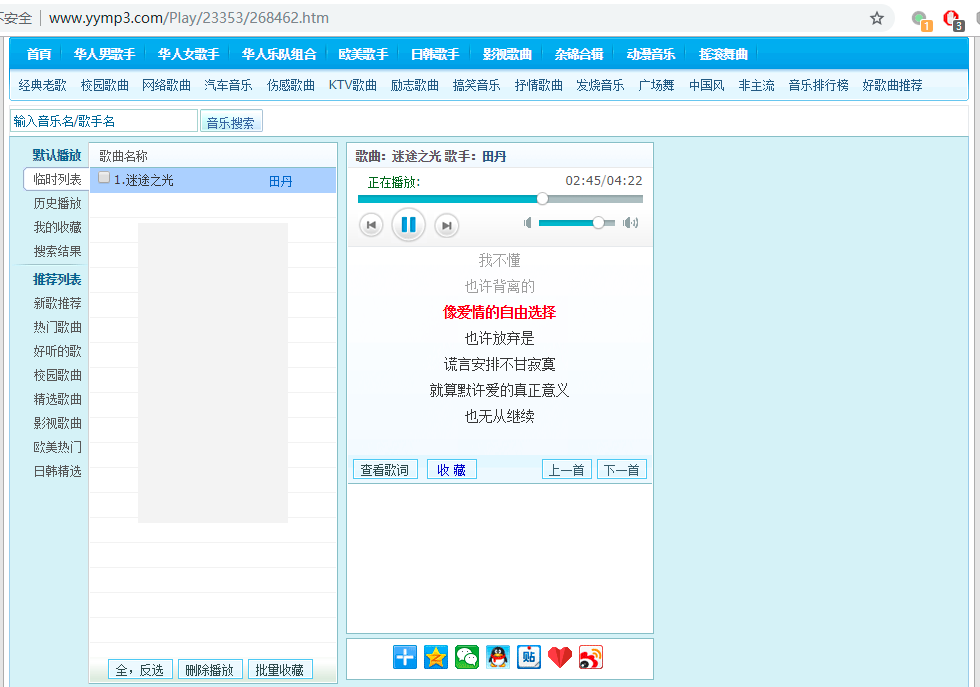
歌曲的名字、作者相关信息可以通过解析html得到,这些信息在html中能够搜索得到,那么歌曲的音频数据的下载链接如何得到呢?
要在网页中播放音频,首先要有一个audio标签,已经加载完毕的网页的内存DOM模型中会有一个audio标签挂载着,使用Chrome的开发者工具,切换到Elements选项卡,搜索audio标签:
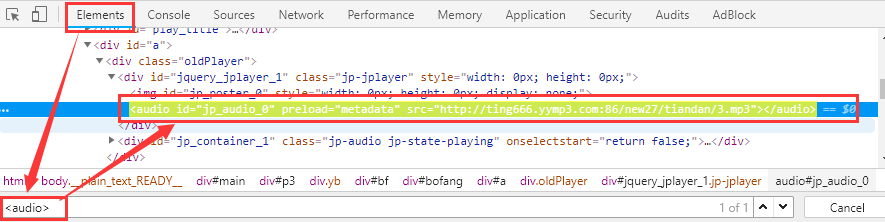
第一个想法就是立刻试下在页面中搜索一下http://ting666.yymp3.com:86/new27/tiandan/3.mp3看看能不能搜索到,先冷静想一下,前端开发的时候对于url地址一般都是会有一个变量存放baseUrl,然后使用其它的相对路径拼接出完整的url,这样做是为了方便在测试环境和开发环境切换,比如测试环境是test.foo.com,开发环境是www.foo.com,那么测试通过上线的时候只需要修改一个变量值就可以了,这样比较方便。所以正确的搜索方式是只拿相对路径搜索或者只拿文件名在html中搜索:

有点尴尬,网页中没有搜索到,是因为网页中没有携带音频播放地址吗?再冷静想一下,想到前端技术栈那一箩筐乱七八糟的兼容性问题,所以基本可以肯定在播放的时候肯定会检测当前的浏览器环境选择不同的播放格式,那么很有可能是返回的地址是一个player/foo.wma这种格式的,然后经过检测环境后发现使用mp3更合适,所以直接修改了扩展名为player/foo.mp3,不妨将扩展名去掉只使用new27/tiandan/3搜索试一下:

这次果然搜到了,看上面这个变量是将歌曲的相关信息都赋给了一个变量,那么后面一定有一个地方使用到了这个变量,在html页面中搜索了一下:

看来不是在当前页面中使用的,那么一定是在这个变量声明之后引入的js中使用到的,找了一下,找到了这个js文件:http://img.yymp3.com/jplay/jplayer.ready.js,在这个文件的第一行就有如何处理音频播放地址的逻辑:
try{var firstplay="http://ting666.yymp3.com:86/"+$song_data[0].split("|")[4].toLowerCase().replace(".wma",".mp3");}catch(e){var firstplay='';}
将$song_data[0]="268462|迷途之光|10888|田丹|new27/tiandan/3.wma|23353||";按照| split取下标为4的,将.wma格式的换为.mp3格式的,作为播放地址,这个替换有点奇怪,不太清楚是因为什么原因。
接下来就是搞懂$song_data这个变量按照| split之后数组中每个元素的意思。
这是歌曲的详情页url:
http://www.yymp3.com/Play/23353/268462.htm
经过对比可以得到0下标存放的是歌曲的id,那么23353是个什么鬼呢?注意到网站有一个专辑功能,随便找一个专辑:
http://www.yymp3.com/Album/23304.htm
上面的23304就是专辑的id,然后随便进入专辑下的某个歌曲的详情页:
http://www.yymp3.com/Play/23304/268053.htm
由此可以证明,歌曲详情页的格式是:
http://www.yymp3.com/Play/{专辑id}/{歌曲id}.htm
即5下标的数字是此歌曲所属的专辑id。
还有一个没搞懂的2下标的数字,歌曲id有了,专辑id有了,貌似还差个作者id,还是上面那首歌:
http://www.yymp3.com/Play/23304/268053.htm
查看其源代码中:
$song_data[0]="268053|失语|10845|王思远|new27/wansiyuan2/1.wma|23304||";
然后打开作者详情页:
http://www.yymp3.com/singer/10845.htm
由此可以确定,下标为2的是作者id。
至此$song_data[0]中的所有列表示的含义都已被推测出:
268053|失语|10845|王思远|new27/wansiyuan2/1.wma|23304||";
歌曲id | 歌曲名字 | 作者id | 作者名字 | 歌曲音频播放地址 | 歌曲所属专辑id
2.2 lrc数据的获取
爬取歌曲信息与普通音频类爬虫不同的是歌曲还需要额外的抓取歌词信息,歌词使用的格式是lrc,关于lrc的更多知识可以看这里:lrc详解。
那么歌曲的lrc数据如何得到呢?
回到歌曲详情页,在播放页上能够看到歌词在滚动,说明这一页必定有得到lrc的方式,在html找了下没有,那么比较可能的方式就是请求的js然后将此歌曲的id传入,好,来根据歌曲的id在network下搜索:

搜索出来四个请求,第一个是doc类型,是html的请求,前面已经确定其中没有lrc格式的歌词了,第二个看了下是个访问统计信息,也没什么作用,第三个是我的卡巴斯基检测,也没啥用,第四个是最可疑的,把完整的请求路径拿出来看一下:
http://www.yymp3.com/lrc/27/268462.js
路径中带着lrc三个字,又传递了歌曲的id,八成就是请求去请求歌词的,看下它的返回内容是什么:
$song_Lrc[268462] = "0,0,1000,2000,3000,4000,5000,6000,7000,16000,18000,21000,29000,35000,43000,47000,50000,57000,61000,64000,72000,74000,79000,81000,86000,90000,93000,104000,107000,110000,114000,118000,120000,124000,128000,132000,136000,139000,146000,149000,153000,160000,162000,166000,168000,173000,177000,180000,186000,187000,189000,194000,196000,201000,205000,208000,213000,217000,220000,224000,230000,234000,237000[/]迷途之光[n]田丹 - 迷途之光[n]作词:田丹、弓强子[n]作曲:田丹[n]编曲:程天禹[n]吉他:胡阁 [n]混音:顾潇予[n]母带:全相彦@OKMastering[n]制作人:程天禹[n]不想了[n]不要再想着[n]不要再等了 ye[n]我们 再说过以后[n]就不要骗了 呜哦[n]爱像坐过山车[n]经过一路颠簸[n]路过迷泊[n]走过圣地亚哥[n]徘徊海的颜色[n]我不懂[n]也许背离的[n]很像爱情的自由选择[n]也许放弃[n]是谎言安排不甘寂寞[n]就算默数爱的真正意义[n]也无从继续[n]来得实际不如再说一句[n]结果[n]还不是猜测[n]有什么好说[n]Ye[n]我们[n]在说过以后[n]就不要骗了[n]wo[n]爱像坐过山车[n]经过一路颠簸[n]路过迷泊[n]走过圣地亚哥[n]徘徊海的颜色[n]我不懂[n]也许背离的[n]像爱情的自由选择[n]也许放弃是[n]谎言安排不甘寂寞[n]就算默许爱的真正意义[n]也无从继续[n]来得实际不如再说一句[n]哦[n]也许背离的[n]像爱情的自由选择[n]也许放弃是[n]谎言安排不甘寂寞[n]就算默许爱的真正意义[n]也无从继续[n]来得实际不如再说一句[n]哦哦哦哦[n]哦哦哦哦哦哦哦[n]哦哦哦哦哦哦哦[n]哦哦哦哦哦哦哦[n]哦哦哦哦哦哦哦[n]哦哦哦哦哦哦哦[n]哦哦哦哦哦哦哦[n]";
看上去乱七八糟的,应该只是为了方便程序解析才返回这个格式的,虽然我感觉搞成这个格式程序解析起来一点也不方便,而且人看起来也一点也不方便...那么接下来的事情也可以脑补出来了,这个请求的返回值声明了一个变量,那么一定有一个地方是使用了这个变量的,只需要找到使用这个变量的地方分析其使用规则即可解析出lrc格式的歌词来:

这个调用栈是从下往上的,整理一下加载歌词的逻辑,首先初始化了一个播放器:
var pu = new PlayerUtils();optlist(0);pu.utils(0,0,3);
在初始化的时候会加载歌词数据:
this.downloadlrc(song_u[0]);
然后看下是怎么去请求歌词的:
this.downloadlrc = function(t) {
var tfolder = "";
var fdata = t / 10000 + 1;
fdata = fdata.toString();
tfolder = fdata;
if (fdata.indexOf(".") != -1) {
tfolder = fdata.split(".")[0];
}
if (!$song_Lrc[t]) {
this.led('', '', '', '正在载入歌词...', '', '', '');
this.ledColor(4);
$download(_url + 'lrc/' + tfolder + '/' + t + '.js');
}
lrctimea = 8888888;
};
这段代码大概就是检查当前歌曲的歌词数据是否已经被加载,如果没有加载的话就取服务器将对应的歌词数据拉取一下,这里有个比较奇怪的地方:
var fdata = t / 10000 + 1;
fdata = fdata.toString();
tfolder = fdata;
为什么要除以10000呢?事情到这里就比较有意思了,现在我们站在站长的角度来思考一下,如果我有几十万歌曲的lrc数据我应该如何存储呢?由上面的这段代码我猜测站长应该是将这些歌词数据放在磁盘上,以小文件的形式存储,然后每10000个小文件新建一个文件夹避免一个文件夹下存放过多。
分析到这里只是为了满足一下我的好奇心,其实还有更好的方式获取歌词数据,在歌曲详情页有个链接:
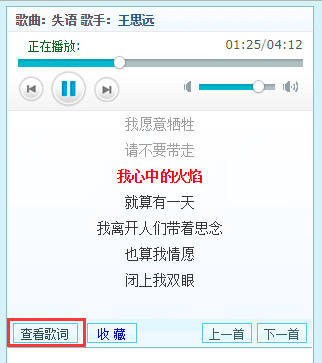

在Chrome的控制台直接输入showword回车:
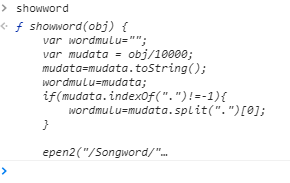
返回值打印的是函数体,直接单击即可跳到对应js文件的对应位置:
function showword(obj) {
var wordmulu = "";
var mudata = obj / 10000;
mudata = mudata.toString();
wordmulu = mudata;
if (mudata.indexOf(".") != -1) {
wordmulu = mudata.split(".")[0];
}
epen2("/Songword/" + wordmulu + "/" + obj + ".htm");
}
上面的这个反倒是没有+1,直接对10000整除即可,由此可以确定获取lrc数据的规则,
http://www.yymp3.com/Songword/{歌曲id // 10000}/{歌曲id}.htm
三、代码实现
写此篇文章的目的只是为了训练下分析能力,并不是为了爬取全站数据,所以仅仅是对上面分析写了个简单的实现,输入歌曲详情页,返回歌曲的相关信息:
#! /usr/bin/python3
# -*- coding: utf-8 -*-
"""
音乐mp3爬虫 http://www.yymp3.com/
"""
import json
import logging
import re
import time import requests
from bs4 import BeautifulSoup, NavigableString logging.basicConfig(level=logging.INFO, format='%(asctime)s %(filename)s : %(levelname)s %(message)s')
logger = logging.getLogger(__name__) last_request_time = 0
REQUEST_MIN_INTERVAL = 1 def download_html(url):
rate_limiter()
logger.info('download url ' + url)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36'}
response = requests.get(url, headers=headers)
return response.content def rate_limiter():
"""
用来对请求限度,以免请求过快对网站产生较大压力影响其正常运行
:return:
"""
global last_request_time
interval_seconds = time.time() - last_request_time
if interval_seconds < REQUEST_MIN_INTERVAL:
time.sleep(REQUEST_MIN_INTERVAL - interval_seconds)
last_request_time = time.time() def parse_music_info(music_detail_page_url):
"""
解析音乐的相关信息
:param music_detail_page_url:
:return:
"""
html = download_html(music_detail_page_url)
music_info_array = re.search('song_data\[0\]="([^"]+)"', html.decode('UTF-8')).group(1).split('|')
return {
"music_name": music_info_array[1],
"music_id": music_info_array[0],
"music_audio_link": 'http://ting666.yymp3.com:86/' + music_info_array[4].replace('.wma', '.mp3'),
"lrc": get_lrc_by_music_id(music_info_array[0]),
"author_name": music_info_array[3],
"author_id": music_info_array[2],
"album_id": music_info_array[5]
} def get_lrc_by_music_id(music_id):
"""
根据歌曲id抓取lrc格式的歌词
:param music_id:
:return:
"""
lrc_page_url = 'http://www.yymp3.com/Songword/%d/%s.htm' % (int(music_id) // 10000, music_id)
html = download_html(lrc_page_url)
dom = BeautifulSoup(html)
lrc_box = dom.select_one('#lrc')
return lrc_box_to_text(lrc_box) def lrc_box_to_text(lrc_box):
"""
使用bs4的text没有把br解析成换行符,还是手动实现一下这个功能吧
:param lrc_box:
:return:
"""
lrc_lines = []
for e in lrc_box.children:
# 只有非空白的文本节点才被认为是有效的歌词
if type(e) == NavigableString and not str(e).isspace():
lrc_lines.append(str(e).strip())
return '\n'.join(lrc_lines) if __name__ == '__main__':
music_info = parse_music_info('http://www.yymp3.com/Play/15042/191056.htm')
print(json.dumps(music_info))
抓取结果:
{
"music_name":"乡恋",
"music_id":"191056",
"music_audio_link":"http://ting666.yymp3.com:86/new17/Gongyue10/12.mp3",
"lrc":"[00:40.11]你的身影
[00:45.10]你的歌声
[00:50.19]永远印在
[00:54.22]我的心中
[00:59.26]昨天虽已消逝
[01:03.87]分别难相逢
[01:08.22]怎能忘记
[01:13.04]你的一片深情
[01:18.09]昨天虽已消逝
[01:22.19]分别难相逢
[01:27.29]怎能忘记
[01:31.19]你的一片深情
[02:33.91]我的情爱
[02:38.17]我的美梦
[02:43.01]永远留在
[02:46.95]你的怀中
[02:52.14]明天就要来临
[02:57.07]却难得和你相逢
[03:01.23]只有风儿
[03:05.29]送去我的一片深情
[03:11.00]明天就要来临
[03:16.10]却难得和你相逢
[03:19.98]只有风儿
[03:24.68]送去我的深情
[[03:50.18]",
"author_name":"龚玥",
"author_id":"2974",
"album_id":"15042"
}
.
爬虫笔记之刷小怪练级:yymp3爬虫(音乐类爬虫)的更多相关文章
- [Python爬虫笔记][随意找个博客入门(一)]
[Python爬虫笔记][随意找个博客入门(一)] 标签(空格分隔): Python 爬虫 2016年暑假 来源博客:挣脱不足与蒙昧 1.简单的爬取特定url的html代码 import urllib ...
- nodejs爬虫笔记(三)---爬取YouTube网站上的视频信息
思路:通过笔记(二)中代理的设置,已经可以对YouTube的信息进行爬取了,这几天想着爬取网站下的视频信息.通过分析YouTube,发现可以从订阅号入手,先选择几个订阅号,然后爬取订阅号里面的视频分类 ...
- nodejs爬虫笔记(二)---代理设置
node爬虫代理设置 最近想爬取YouTube上面的视频信息,利用nodejs爬虫笔记(一)的方法,代码和错误如下 var request = require('request'); var chee ...
- Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页 下载下面这个链接的销售数据 https://item.jd.com/6733026.html#comment 1. 翻页的时候,谷歌F12的Network页签可以看到下面 ...
- 爬虫笔记之自如房屋价格图片识别(价格字段css背景图片偏移显示)
一.前言 自如房屋详情页的价格字段用图片显示,特此破解一下以丰富一下爬虫笔记系列博文集. 二.分析 & 实现 先打开一个房屋详情页观察一下: 网页的源代码中没有直接显示价格字段,价格的显示是使 ...
- Java网络爬虫笔记
Java网络爬虫笔记 HttpClient来代替浏览器发起请求. select找到的是元素,也就是elements,你想要获取具体某一个属性的值,还是要用attr("")方法.标签 ...
- Python爬虫笔记一(来自MOOC) Requests库入门
Python爬虫笔记一(来自MOOC) 提示:本文是我在中国大学MOOC里面自学以及敲的一部分代码,纯一个记录文,如果刚好有人也是看的这个课,方便搬运在自己电脑上运行. 课程为:北京理工大学-嵩天-P ...
- python爬虫笔记Day01
python爬虫笔记第一天 Requests库的安装 先在cmd中pip install requests 再打开Python IDM写入import requests 完成requests在.py文 ...
- Scrapy爬虫笔记
Scrapy是一个优秀的Python爬虫框架,可以很方便的爬取web站点的信息供我们分析和挖掘,在这记录下最近使用的一些心得. 1.安装 通过pip或者easy_install安装: 1 sudo p ...
随机推荐
- MyBatis3-动态SQL语句
MyBatis的动态SQL语句是基于OGNL表达式的.可以方便的在SQL语句中实现某些逻辑,总体说来MyBatis动态SQL语句主要有以下几类: 1.if语句(简单的条件判断). 2.choose(w ...
- 读书笔记(chapter5)
系统调用 5.1与内核通信 1.系统调用在用户空间进程和硬件设备之间添加一个中间层.作用有三个:它为用户空间提供了一种硬件的抽象接口:系统调用保证了系统的稳定和安全:系统调用是用户空间访问内核的唯一手 ...
- Scalable Object Detection using Deep Neural Networks译文
原文:https://arxiv.org/abs/1312.2249
- Leetcode题库——38.报数
@author: ZZQ @software: PyCharm @file: countAndSay.py @time: 2018/11/9 14:07 说明:报数序列是一个整数序列,按照其中的整数的 ...
- Semantic Versioning Specification & 语义化版本
Semantic Versioning Specification & 语义化版本 Semantic Versioning Specification http://semver.org 16 ...
- Python 零基础 快速入门 趣味教程 (咪博士 海龟绘图 turtle) 2. 变量
大家在中学就已经学过变量的概念了.例如:我们令 x = 100,则可以推出 x*2 = 200 试试下面这段 Python 代码 import turtle turtle.shape("tu ...
- FMDB基本操作
1.以前使用数据库,因为一般就建立一张表,所以都是自己写代码创建,没用过fmdb,这次因为项目中涉及聊天模块,需要多张表格和数据库保存聊天记录 按照以前方法不好操作,就研究了下fmdb,发现确实挺方便 ...
- 洛谷P4831 Scarlet loves WenHuaKe
这道题告诉我们推式子的时候头要够铁. 题意 问一个\(n\times m\)的棋盘,摆上\(n\times 2\)个中国象棋的炮使其两两不能攻击的方案数,对\(998244353\)取模. \((n\ ...
- 「TJOI / HEOI2016」字符串
「TJOI / HEOI2016」字符串 题目描述 佳媛姐姐过生日的时候,她的小伙伴从某东上买了一个生日礼物.生日礼物放在一个神奇的箱子中.箱子外边写了一个长为 \(n\) 的字符串 \(s\),和 ...
- 在Mac上快速Kill掉Tomcat
最近IDEA总是会莫名其妙的挂掉,而挂掉之后通过IDEA开启的Tomcat却没有同步给关掉,等我再在IDEA里要启动的时候,就不行了.... 这时,就需要手动去kill掉tomcat,每次先 ps - ...