二叉搜索树、AVL平衡二叉搜索树、红黑树、多路查找树
1.二叉搜索树
1.1定义
是一棵二叉树,每个节点一定大于等于其左子树中每一个节点,小于等于其右子树每一个节点
1.2插入节点
从根节点开始向下找到合适的位置插入成为叶子结点即可;在向下遍历时,如果要插入的值比节点的值小,则向节点的左子树遍历,大于等于则向右子树遍历,如此循环。
1.3删除节点
删除节点x有3种情况:
1.x是叶子结点,则直接删除;
2.x只有一棵子树(左子树或者右子树),则直接将x的父结点指向x的孩子,再删除x节点,如果x是根结点,则要更新x的孩子为树根;
3.x有两棵子树,则要找到x在右子树中的后驱节点y,然后将y的右子树成为y的父结点的左子树,再用y替换掉x。
后驱节点y:大于x的节点中的最小结点,也就是x的右子树中的最小结点,即x的右子树中最左侧的不拥有左子树的节点;下图是一个实例:
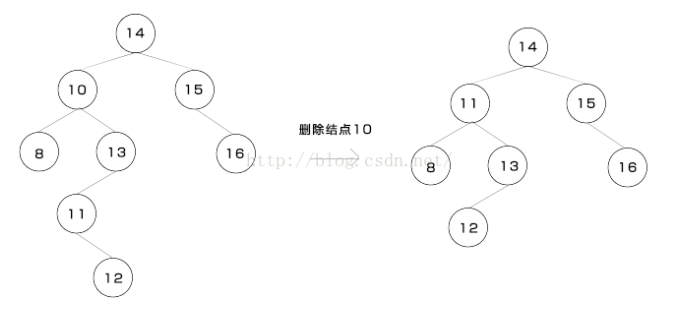
参考资料:
https://blog.csdn.net/ivan_zgj/article/details/51502767
2.AVL平衡二叉搜索树(要平衡先搜索)
2.1定义
一棵二叉搜索树,任何节点的左子树高度和右子树高度最多相差1(严格平衡)
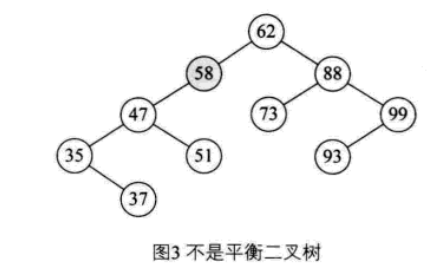
节点58左子树高度3,右子树高度0,相差3,所以图中不是平衡二叉树
AVL树的高度为 ⌊logn⌋ (n为节点总个数,向下取整符号)
满二叉树是平衡树吗?看标题,要平衡先搜索,搜索树是考虑了节点值的树
2.2节点结构
data、bf(平衡因子=左子树高度-右子树高度)、left指针、right指针
2.3插入节点
1)按二叉搜索树的规则找到插入位置;
2)节点插入后,若节点X的左子树和右子树高度的差变成了2,破坏了平衡,则需要调整,可分为四种情况:
1.外侧插入:左左——插入点位于X的左儿子的左子树
2.外侧插入:右右——插入点位于X的右儿子的右子树
3.内侧插入:左右——插入点位于X的左儿子的右子树
4.内侧插入:右左——插入点位于X的右儿子的左子树
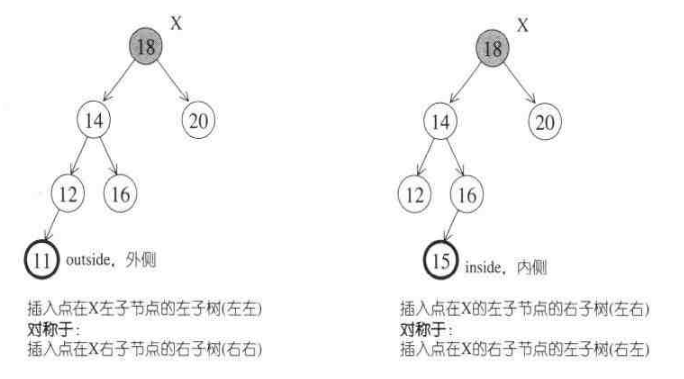
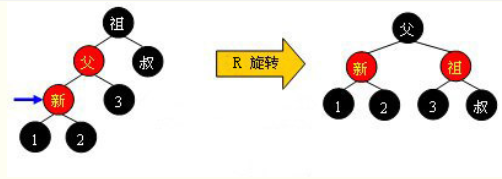
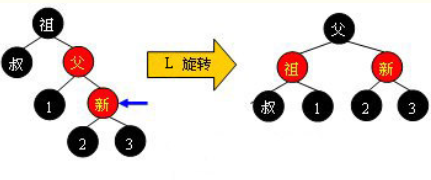
3)对于外侧插入,采用单旋转修正:左左(右单旋),右右(左单旋);
4)单旋转:拿右旋转举例,捏起X节点的左儿子,让X节点自然下滑,并将X节点的左子节点的右子树挂到X节点的左侧,整个过程就像向右边旋转一样;
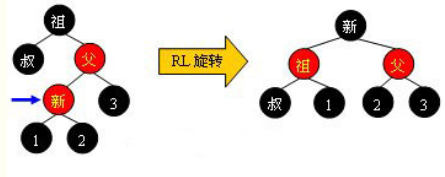
5)对于内侧插入,采用双旋转(两次单旋转)修正:左右(左单旋+右单旋),右左(右单旋+左单旋);
6)旋转操作都是O(1)
2.4删除节点(不太懂)
按二叉搜索树的规则找到要删除的节点,然后再找到“最先发生树高变化的节点”,进行旋转调整,删除节点x有3种情况:
1. x是叶子节点,“最先发生树高变化的节点”为x的父节点;
2. x只有一棵子树,“最先发生树高变化的节点”为x的父节点;
3. x有两棵子树,则“最先发生树高变化的节点”为x的后驱的父节点。
2.5各种操作的时间复杂度
查找、插入、删除:O(logn)
3.红黑树
3.1定义
是一棵二叉搜索树,确保最长路径不大于两倍的最短路径的长度,不是严格平衡,是近似平衡,满足5个规则:
1.每个节点要么是红色,要么是黑色
2.根节点必为黑色
3.NULL视为黑色
4.如果某个节点为红色,其儿子节点必须为黑色
5.任何一个节点至NULL的任何路径,所含黑色节点的数目相同
一般情况下,规则5导致新插的节点必须为红色,进而根据规则4,需要新插节点的父节点为黑色,如果不为黑色,就需要调整颜色或旋转来修正
3.2节点结构的数据成员
color(枚举型)、key、value、left指针、right指针、parent指针(红黑树的各种操作经常要上溯到父节点)
3.3插入节点
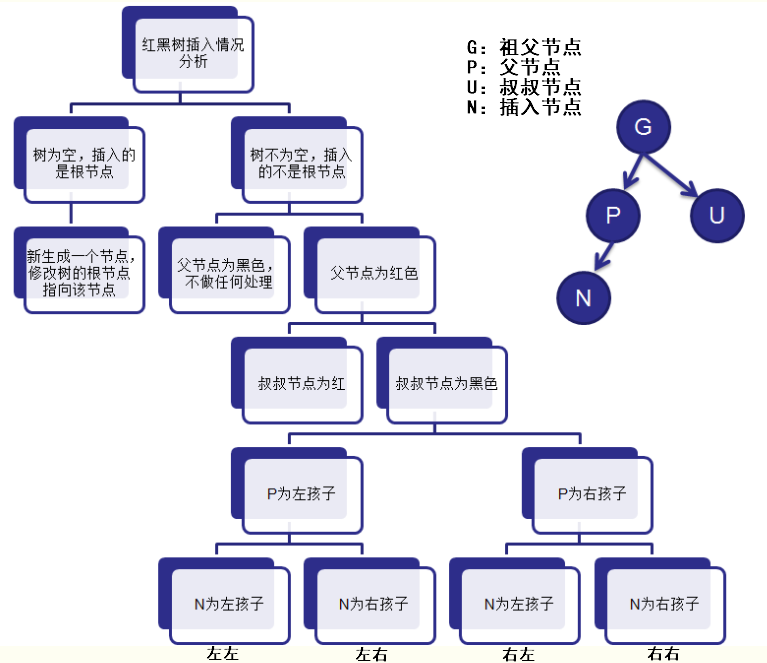
case 1:如果插入的节点是根节点,直接将该节点标识成黑色即可
case 2:插入的节点不是根节点,如果插入的节点的父节点是黑色的话,那么不需要调整
case 3:如果父节点是红色,则需要看叔节点的颜色
case 3.1:叔节点为也红色,则将父和叔结点变为黑色,将祖父结点变为红色;由于祖父结点的父结点有可能为红,则将祖父结点作为新的判定点向上修正
case 3.2:叔节点为黑色,则需要旋转并调整颜色来修正
case 3.2.1:左左,右旋转
case 3.2.1:右右,左旋转
case 3.2.1:左右,左旋转+右旋转
case 3.2.1:右左,右旋转+左旋转

参考资料:
http://blog.csdn.net/hackbuteer1/article/details/7740956
http://www.cnblogs.com/xuqiang/archive/2011/05/16/2047001.html
3.4删除节点
太复杂。。。红黑树删除节点最多只需3次旋转调整
根据被删除节点x的颜色可分为2种情况:
1.x为红色,删除x后不会影响红黑树的平衡性,不需要做任何调整;
2.x为黑色,则x所在的路径上的黑色节点总数减少1,红黑树失去平衡,需要调整。
参考资料:
https://www.cnblogs.com/sandy2013/p/3271497.html
3.5插入、删除节点源码
// sgi stl _Rb_tree 插入算法 insert_equal() 实现.
// 策略概述: insert_equal() 在红黑树找到自己的位置,
// 然后交由 _M_insert() 来处理接下来的工作.
// _M_insert() 会将节点插入红黑树中, 接着调整红黑树,
// 维持性质.
template <class _Key, class _Value, class _KeyOfValue,class _Compare, class _Alloc>
typename _Rb_tree<_Key, _Value, _KeyOfValue, _Compare, _Alloc>::iterator
_Rb_tree<_Key, _Value, _KeyOfValue, _Compare, _Alloc>::insert_equal(const _Value& __v)
{
// 在红黑树中有头结点和根节点的概念, 头结点位于根节点之上,
// 头结点只为管理而存在, 根节点是真正存储数据的地方. 头结点和根节点互为父节点,
// 是一种实现的技巧.
_Link_type __y = _M_header; // 指向头结点
_Link_type __x = _M_root(); // _M_header->_M_parent, 即指向根节点 // 寻找插入的位置
while (__x != ) {
__y = __x; // 小于当前节点要走左边, 大于等于当前节点走右边
__x = _M_key_compare(_KeyOfValue()(__v), _S_key(__x)) ?
_S_left(__x) : _S_right(__x);
}
// __x 为需要插入的节点的位置, __y 为其父节点
return _M_insert(__x, __y, __v);
} // sgi stl _Rb_tree 插入算法 insert_unique() 实现.
// 策略概述: insert_unique() 同样也在红黑树中找到自己的位置; 我们知道,
// 如果小于等于当前节点会往右走, 所以遇到一个相同键值的节点后, 会往右走一步,
// 接下来一直往左走, 所以下面的实现会对往左走的情况做特殊的处理.
template <class _Key, class _Value, class _KeyOfValue,class _Compare, class _Alloc>
pair<typename _Rb_tree<_Key, _Value, _KeyOfValue, _Compare, _Alloc>::iterator,bool>
_Rb_tree<_Key, _Value, _KeyOfValue, _Compare, _Alloc>::insert_unique(const _Value& __v)
{
_Link_type __y = _M_header; // 指向头结点
_Link_type __x = _M_root(); // 指向根节点, 可能为空
bool __comp = true; // 寻找插入的位置
while (__x != ) {
__y = __x;
__comp = _M_key_compare(_KeyOfValue()(__v), _S_key(__x));//_M_key_compare:v<x返回true // 小于当前节点要走左边, 大于等于当前节点走右边
__x = __comp ? _S_left(__x) : _S_right(__x);
}
//离开while循环之后,__y所指为插入点的父节点 iterator __j = iterator(__y); // 令迭代器__j指向插入点的父节点__y // 我认为下面判断树中是否有存在键值的情况有点绕,
// 它充分利用了二叉搜索树的性质, 如此做很 hack, 但不易理解.
// 要特别注意往左边插入的情况. // HACKS:
// 下面的 if 语句是比 __x 小走左边的情况: 会发现, 如果插入一个已存在的键的话,
// __y 最终会定位到已存在键的右子树的最左子树.
// 譬如, 红黑树中已经存在一个键为 100 的节点, 其右孩子节点为 101,
// 此时如果再插入键为 100 的节点, 因为 100<=100, 所以会往右走到达 101 节点,
// 有 100<101, 继而往左走, 会一直往左走.大家稍微画一个例子就能理解. if (__comp) //如果离开while循环__comp为真,也就是说,最后一次while循环选择的是左边 if (__j == begin())//特殊情况,如果插入点的父节点为最左节点,那么肯定要插入这个新节点.
return pair<iterator, bool>(_M_insert(__x, __y, __v), true);
else// 那么 --__j 能定位到此重复的键的节点.
--__j; // HACKS: 这里比较的是 __j 和 __v, 如果存在键值, 那么 __j == __v,
// 会跳过 if 语句. 否则执行插入. 也就是说如果存在重复的键, 那么 __j
// 的值肯定是等于 __v
if (_M_key_compare(_S_key(__j._M_node), _KeyOfValue()(__v)))
return pair<iterator, bool>(_M_insert(__x, __y, __v), true); // 此时 __y.value = __v, 不允许插入, 返回键值所在位置
return pair<iterator, bool>(__j, false);
} // _M_insert() 是真正执行插入的地方.
// 策略概述: 插入策略已经在上篇中详述, 可以根据上篇文章的描述,
// 和下面代码的注释, 加深对红黑树插入算法里理解
template <class _Key, class _Value, class _KeyOfValue,class _Compare, class _Alloc>
typename _Rb_tree<_Key, _Value, _KeyOfValue, _Compare, _Alloc>::iterator
_Rb_tree<_Key, _Value, _KeyOfValue, _Compare, _Alloc>::_M_insert(_Base_ptr __x_, _Base_ptr __y_, const _Value& __v)
{
_Link_type __x = (_Link_type)__x_; // 新节点插入的位置.
// 关于 __x 的疑问:
// 1. 它被放到下面的, 第一个 if 语句中, 我觉得是没有必要的,
// 因为从调用 _M_insert() 的函数来看, __x 总是为空.
// 2. 既然 __x 是新节点插入的位置, 那么为什么不直接在 __x 上创建节点,
// 还要在下面通过比较来决定新节点是左孩子还是右孩子;
// 不如直接用指针的指针或者指针的引用来完成, 省去了下面的判断. _Link_type __y = (_Link_type)__y_; // 新节点的父节点
_Link_type __z; // 新节点的位置 if (__y == _M_header || __x != ||
_M_key_compare(_KeyOfValue()(__v), _S_key(__y))) {
// 新节点应该为左孩子
__z = _M_create_node(__v);
_S_left(__y) = __z; // also makes _M_leftmost() = __z
// when __y == _M_header
if (__y == _M_header) {
_M_root() = __z;
_M_rightmost() = __z;
}
else if (__y == _M_leftmost())
_M_leftmost() = __z; // maintain _M_leftmost() pointing to min node
}
// 新节点应该为右孩子
else {
__z = _M_create_node(__v);
_S_right(__y) = __z;
if (__y == _M_rightmost())
_M_rightmost() = __z; // maintain _M_rightmost() pointing to max node
}
_S_parent(__z) = __y;
_S_left(__z) = ;
_S_right(__z) = ; // 重新调整
_Rb_tree_rebalance(__z, _M_header->_M_parent); // 更新红黑树节点数
++_M_node_count; // 返回迭代器类型
return iterator(__z);
} // 插入新节点后, 可能会破坏红黑树性质, _Rb_tree_rebalance() 负责维持性质.
// 其中:
// __x 新插入的节点
// __root 根节点
// 策略概述: 红黑树插入重新调整的策略已经在上篇中讲述,
// 可以结合上篇文章和这里的代码注释,
// 理解红黑树的插入算法.
inline void
_Rb_tree_rebalance(_Rb_tree_node_base* __x, _Rb_tree_node_base*& __root)
{
// 将新插入的节点染成红色
__x->_M_color = _S_rb_tree_red; while (__x != __root && __x->_M_parent->_M_color == _S_rb_tree_red) {
// __x 的父节点也是红色的情况. 提示: 如果是黑色节点, 不会破坏红黑树性质. if (__x->_M_parent == __x->_M_parent->_M_parent->_M_left) {
// 叔父节点
_Rb_tree_node_base* __y = __x->_M_parent->_M_parent->_M_right; if (__y && __y->_M_color == _S_rb_tree_red) {
// 第 1 种情况, N,P,U 都红(G 肯定黑).
// 策略: G->红, N,P->黑. 此时, G 红, 如果 G 的父亲也是红, 性质又被破坏了,
// HACK: 可以将 GPUN 看成一个新的红色 N 节点, 如此递归调整下去;
// 特俗的, 如果碰巧将根节点染成了红色, 可以在算法的最后强制 root->红.
__x->_M_parent->_M_color = _S_rb_tree_black;
__y->_M_color = _S_rb_tree_black;
__x->_M_parent->_M_parent->_M_color = _S_rb_tree_red;
__x = __x->_M_parent->_M_parent;
}
else { if (__x == __x->_M_parent->_M_right) {
// 第 2 种情况, P 为红, N 为 P 右孩子, U 为黑或缺少.
// 策略: 旋转变换, 从而进入下一种情况:
__x = __x->_M_parent;
_Rb_tree_rotate_left(__x, __root);
}
// 第 3 种情况, 可能由第二种变化而来, 但不是一定: P 为红, N 为红.
// 策略: 旋转, 交换 P,G 颜色, 调整后, 因为 P 为黑色, 所以不怕
// P 的父节点是红色的情况. over
__x->_M_parent->_M_color = _S_rb_tree_black;
__x->_M_parent->_M_parent->_M_color = _S_rb_tree_red;
_Rb_tree_rotate_right(__x->_M_parent->_M_parent, __root);
}
}
else { // 下面的代码是镜像得出的, 脑补吧.
_Rb_tree_node_base* __y = __x->_M_parent->_M_parent->_M_left;
if (__y && __y->_M_color == _S_rb_tree_red) {
__x->_M_parent->_M_color = _S_rb_tree_black;
__y->_M_color = _S_rb_tree_black;
__x->_M_parent->_M_parent->_M_color = _S_rb_tree_red;
__x = __x->_M_parent->_M_parent;
}
else {
if (__x == __x->_M_parent->_M_left) {
__x = __x->_M_parent;
_Rb_tree_rotate_right(__x, __root);
}
__x->_M_parent->_M_color = _S_rb_tree_black;
__x->_M_parent->_M_parent->_M_color = _S_rb_tree_red;
_Rb_tree_rotate_left(__x->_M_parent->_M_parent, __root);
}
}
}
__root->_M_color = _S_rb_tree_black;
} // 删除算法, 直接调用底层的删除实现 _Rb_tree_rebalance_for_erase().
template <class _Key, class _Value, class _KeyOfValue,class _Compare, class _Alloc>
inline void _Rb_tree<_Key, _Value, _KeyOfValue, _Compare, _Alloc>::erase(iterator __position)
{
_Link_type __y =
(_Link_type)_Rb_tree_rebalance_for_erase(__position._M_node,
_M_header->_M_parent,
_M_header->_M_left,
_M_header->_M_right);
destroy_node(__y);
--_M_node_count;
} // 删除节点底层实现, 删除可能会破坏红黑树性质,
// _Rb_tree_rebalance()
// 负责维持性质. 其中:
// __z 需要删除的节点
// __root 根节点
// __leftmost 红黑树内部数据, 即最左子树
// __rightmost 红黑树内部数据, 即最右子树
// 策略概述: _Rb_tree_rebalance_for_erase() 会根据
// 删除节点的位置在红黑树中找到顶替删除节点的节点,
// 即无非是删除节点左子树的最大节点或右子树中的最小节点,
// 此处用的是有一种策略. 接着, 会调整红黑树以维持性质.
// 调整的算法已经在上篇文章中详述, 可以根据上篇文章的描述
// 和此篇的代码注释, 加深对红黑树删除算法的理解.
inline _Rb_tree_node_base* _Rb_tree_rebalance_for_erase(
_Rb_tree_node_base* __z,
_Rb_tree_node_base*& __root,
_Rb_tree_node_base*& __leftmost,
_Rb_tree_node_base*& __rightmost)
{
// __z 是要删除的节点 // __y 最终会指向要删除的节点
_Rb_tree_node_base* __y = __z;
// N 节点
_Rb_tree_node_base* __x = ;
// 记录 N 节点的父节点
_Rb_tree_node_base* __x_parent = ; // 只有一个孩子或者没有孩子的情况
if (__y->_M_left == ) // __z has at most one non-null child. y == z.
__x = __y->_M_right; // __x might be null.
else
if (__y->_M_right == ) // __z has exactly one non-null child. y == z.
__x = __y->_M_left; // __x is not null. // 有两个非空孩子
else { // __z has two non-null children. Set __y to
__y = __y->_M_right; // __z's successor. __x might be null. // __y 取右孩子中的最小节点, __x 记录他的右孩子(可能存在右孩子)
while (__y->_M_left != )
__y = __y->_M_left;
__x = __y->_M_right;
} // __y != __z 说明有两个非空孩子的情况,
// 此时的删除策略就和文中提到的普通二叉搜索树删除策略一样:
// __y 记录了 __z 右子树中最小的节点
// __x 记录了 __y 的右孩子
// 用 __y 顶替 __z 的位置, __x 顶替 __y 的位置, 最后用 __y 指向 __z,
// 从而 __y 指向了要删除的节点
if (__y != __z) { // relink y in place of z. y is z's successor // 将 __z 的记录转移至 __y 节点
__z->_M_left->_M_parent = __y;
__y->_M_left = __z->_M_left; // 如果 __y 不是 __z 的右孩子, __z->_M_right 有左孩子
if (__y != __z->_M_right) { __x_parent = __y->_M_parent; // 如果 __y 有右孩子 __x, 必须有那个 __x 替换 __y 的位置
if (__x)
// 替换 __y 的位置
__x->_M_parent = __y->_M_parent; __y->_M_parent->_M_left = __x; // __y must be a child of _M_left
__y->_M_right = __z->_M_right;
__z->_M_right->_M_parent = __y;
}
// __y == __z->_M_right
else
__x_parent = __y; // 如果 __z 是根节点
if (__root == __z)
__root = __y; // __z 是左孩子
else if (__z->_M_parent->_M_left == __z)
__z->_M_parent->_M_left = __y; // __z 是右孩子
else
__z->_M_parent->_M_right = __y; __y->_M_parent = __z->_M_parent;
// 交换需要删除节点 __z 和 替换节点 __y 的颜色
__STD::swap(__y->_M_color, __z->_M_color);
__y = __z;
// __y now points to node to be actually deleted
}
// __y != __z 说明至多一个孩子
else { // __y == __z
__x_parent = __y->_M_parent;
if (__x) __x->_M_parent = __y->_M_parent; // 将 __z 的父亲指向 __x
if (__root == __z)
__root = __x;
else
if (__z->_M_parent->_M_left == __z)
__z->_M_parent->_M_left = __x;
else
__z->_M_parent->_M_right = __x; // __leftmost 和 __rightmost 是红黑树的内部数据, 因为 __z 可能是
// __leftmost 或者 __rightmost, 因此需要更新.
if (__leftmost == __z)
if (__z->_M_right == ) // __z->_M_left must be null also
// __z 左右孩子都为空, 没有孩子
__leftmost = __z->_M_parent;
// makes __leftmost == _M_header if __z == __root
else
__leftmost = _Rb_tree_node_base::_S_minimum(__x); if (__rightmost == __z)
if (__z->_M_left == ) // __z->_M_right must be null also
__rightmost = __z->_M_parent;
// makes __rightmost == _M_header if __z == __root
else // __x == __z->_M_left
__rightmost = _Rb_tree_node_base::_S_maximum(__x); // __y 同样已经指向要删除的节点
} // __y 指向要删除的节点
// __x 即为 N 节点
// __x_parent 指向 __x 的父亲, 即 N 节点的父亲
if (__y->_M_color != _S_rb_tree_red) {
// __y 的颜色为黑色的时候, 会破坏红黑树性质 while (__x != __root && (__x == || __x->_M_color == _S_rb_tree_black))
// __x 不为红色, 即为空或者为黑. 提示: 如果 __x 是红色, 直接将 __x 替换成黑色 if (__x == __x_parent->_M_left) { // 如果 __x 是左孩子 _Rb_tree_node_base* __w = __x_parent->_M_right; // 兄弟节点 if (__w->_M_color == _S_rb_tree_red) {
//第 2 情况, S 红, 根据红黑树性质P,SL,SR 一定黑.
// 策略: 旋转, 交换 P,S 颜色. __w->_M_color = _S_rb_tree_black;
__x_parent->_M_color = _S_rb_tree_red; // 交换颜色
_Rb_tree_rotate_left(__x_parent, __root); // 旋转
__w = __x_parent->_M_right; // 调整关系
} if ((__w->_M_left == ||
__w->_M_left->_M_color == _S_rb_tree_black) &&
(__w->_M_right == ||
__w->_M_right->_M_color == _S_rb_tree_black)) {
// 提示: 这是 第 1 情况和第 2.1 情况的合并, 因为处理的过程是一样的.
// 但他们的情况还是要分门别类的. 已经在文章中详细支出,
// 似乎大多数的博文中没有提到这一点. // 第 1 情况, N,P,S,SR,SL 都黑.
// 策略: S->红. 通过 PN,PS 的黑色节点数量相同了, 但会比其他路径多一个,
// 解决的方法是在 P 上从情况 0 开始继续调整.
// 为什么要这样呢? HACKS: 因为既然 PN,PS
// 路径上的黑节点数量相同而且比其他路径会少一个黑节点,
// 那何不将其整体看成了一个 N 节点! 这是递归原理. // 第 2.1 情况, S,SL,SR 都黑.
// 策略: P->黑. S->红, 因为通过 N 的路径多了一个黑节点,
// 通过 S 的黑节点个数不变, 所以维持了性质 5. over // 可能大家会有疑问, 不对啊, 2.1 的情况,
// 策略是交换父节点和兄弟节点的颜色, 此时怎么没有对父节点的颜色赋值呢?
// HACKS: 这就是合并情况的好处, 因为就算此时父节点是红色,
// 而且也将兄弟节点颜色改为红色, 你也可以将 PS,PN 看成一个红色的 N 节点,
// 这样在下一个循环当中, 这个 N 节点也会变成黑色. 因为此函数最后有一句话:
// if (__x) __x->_M_color = _S_rb_tree_black;
// 合并情况, 节省代码量 // 当然是可以分开写的 // 兄弟节点染成黑色
__w->_M_color = _S_rb_tree_red; // 调整关系
__x = __x_parent;
__x_parent = __x_parent->_M_parent;
}
else {
if (__w->_M_right == ||
__w->_M_right->_M_color == _S_rb_tree_black) {
// 第 2.2.1 情况, S,SR 黑, SL 红.
// 策略: 旋转, 变换 SL,S 颜色. if (__w->_M_left) __w->_M_left->_M_color = _S_rb_tree_black;
__w->_M_color = _S_rb_tree_red;
_Rb_tree_rotate_right(__w, __root); // 调整关系
__w = __x_parent->_M_right;
} // 第 2.2.2 情况, S 黑, SR 红.
// 策略: 旋转, 交换 S,P 颜色, SR->黑色, 重新获得平衡.
__w->_M_color = __x_parent->_M_color;
__x_parent->_M_color = _S_rb_tree_black;
if (__w->_M_right) __w->_M_right->_M_color = _S_rb_tree_black;
_Rb_tree_rotate_left(__x_parent, __root);
break;
} // 下面的代码是镜像得出的, 脑补吧.
}
else { // same as above, with _M_right <-> _M_left.
_Rb_tree_node_base* __w = __x_parent->_M_left;
if (__w->_M_color == _S_rb_tree_red) {
__w->_M_color = _S_rb_tree_black;
__x_parent->_M_color = _S_rb_tree_red;
_Rb_tree_rotate_right(__x_parent, __root);
__w = __x_parent->_M_left;
}
if ((__w->_M_right == ||
__w->_M_right->_M_color == _S_rb_tree_black) &&
(__w->_M_left == ||
__w->_M_left->_M_color == _S_rb_tree_black)) {
__w->_M_color = _S_rb_tree_red;
__x = __x_parent;
__x_parent = __x_parent->_M_parent;
}
else {
if (__w->_M_left == ||
__w->_M_left->_M_color == _S_rb_tree_black) {
if (__w->_M_right) __w->_M_right->_M_color = _S_rb_tree_black;
__w->_M_color = _S_rb_tree_red;
_Rb_tree_rotate_left(__w, __root);
__w = __x_parent->_M_left;
}
__w->_M_color = __x_parent->_M_color;
__x_parent->_M_color = _S_rb_tree_black;
if (__w->_M_left) __w->_M_left->_M_color = _S_rb_tree_black;
_Rb_tree_rotate_right(__x_parent, __root);
break;
}
}
if (__x) __x->_M_color = _S_rb_tree_black;
}
return __y;
}
3.6各种操作的时间复杂度
查找、插入、删除:O(logn)
插入和删除都要先查找,所以是O(logn)
3.7与AVL平衡二叉搜索树的比较
从操作复杂度看:AVL树和红黑树查找、插入、删除都是O(logn)
进一步考虑:
1)查找:红黑树牺牲了严格平衡,但是保证了最长路径不大于最短路径的两倍,所以查找某个节点也可以保证O(logn);但是对于大规模数据的查找,AVL树的严格平衡显然使得查询效率更高(查找上:AVL树胜)
2)插入:如果是插入一个节点引起的不平衡,AVL树和红黑树都是最多通过2次旋转来修正,两者均是O(1)。如果新节点的父结点为黑色,那么插入一个红点将不会影响红黑树的平衡。但红黑树这种黑父的情况比较常见,从而使红黑树需要旋转的概率0比AVL树小
3)删除:如果删除某个节点引起了不平衡,AVL树需要维护被删除节点到根节点的整条路径上所有节点的平衡性,需要O(logn);而红黑树最多只需3次旋转,只需要O(1)
所以说,在大规模数据插入或者删除时,AVL树的效率不如红黑树(插入和删除上:红黑树胜)
4.多路查找树
1)多路查找树的每一个节点的儿子可以多于两个,且每一个节点可以存储多个元素
2)常见的多路查找树有:2-3树、2-3-4树、B树、B+树
3)为什么需要多路查找树:
- 当要处理的数据非常多,多到内存已经装不下,就要把数据存储在磁盘上,从磁盘中把数据读入内存进行处理
- 磁盘I/O操作的基本单位为块,从磁盘上读取数据时,会把包含数据的整个块读入内存,读取磁盘数据的过程:磁头移动到包含所请求数据的磁盘位置上方,然后磁盘旋转至相应位置,磁头将下方的整个块传读入内存:
磁盘数据访问时间= 寻道时间 + 转动延迟 + 数据传送时间
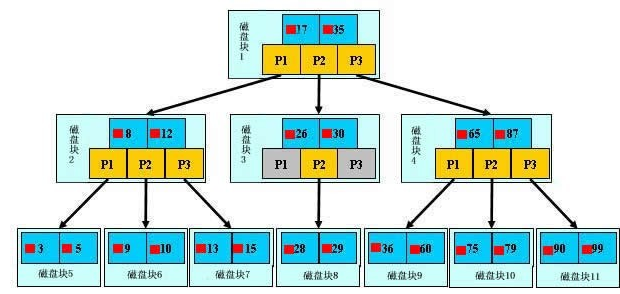
- 如果用平衡树(AVL,RB)作为在磁盘上存储数据的结构,那么平衡树的节点可能不均匀地分布在磁盘的不同块上,这样访问磁盘数据的时间就会显著增加:

- 而B树(一种平衡的多路查找树)有一个重要的特点是每个节点的大小与磁盘块的大小相等,同时每个节点可以存储多个元素,元素的数量可以根据磁盘块的大小而定,这样每次加载一个块就能完整覆盖一个节点,以便选择下一层子树,大大加快磁盘数据的访问速度
参考资料:
https://blog.csdn.net/bit_clearoff/article/details/53197436
5.2-3树
1)2-3树有2节点和3节点
2)2节点包含一个元素和两个儿子(要么没有儿子,要么就有两个儿子),每个节点一定大于等于其左子树中每一个节点,小于等于其右子树每一个节点
3)3节点包含一小一大两个元素和三个儿子(要么没有儿子,要么就有三个儿子),左子树包含小于较小元素的元素,右子树包含大于较大元素的元素,中间子树包含介于两元素之间的元素
4)所有叶子节点在同一层

6.2-3-4树
1)2-3-4树在2-3-4树的基础上多了一种4节点
2)4节点包含小中大三个元素和四个儿子(要么没有儿子,要么就有四个儿子),子树元素大小排列规则类似于3节点
3)所有叶子节点在同一层
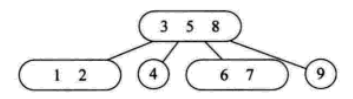
7.B树
1)B树是一种平衡的多路查找树,2-3树和2-3-4树都是B树的特例
2)节点的最大孩子数称为B树的阶
3)m阶B树具有以下性质:
- 根节点如果不是叶子节点,则至少有两个儿子
- 每个分支节点都有k-1元素和k个儿子,元素以升序排列,⌈ m/2 ⌉ <= k <= m
- 所有的叶子节点都在同一层
- key [i]和key [i+ 1 ]之间的儿子节点的元素介于key [i]、key [i+ 1 ]之间
4)B树的查找过程是一个查找节点和遍历节点上的所有元素的交叉过程
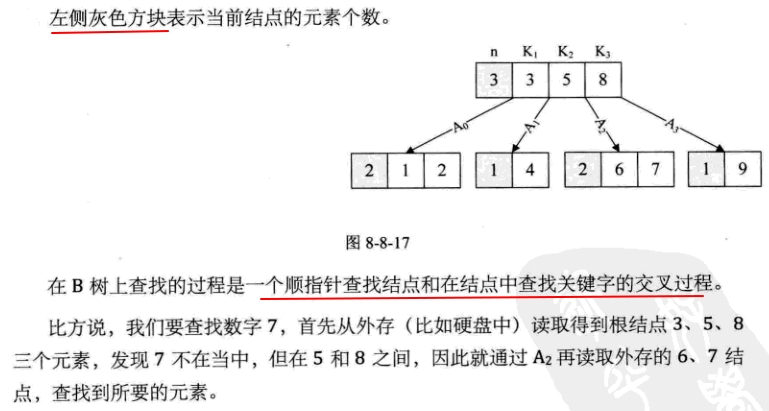
8.B+树
1)B树的查找过程是一个交叉过程,为了加快B树的遍历效率,产生了B树的变形:B+树
2)n阶B+树具有以下性质:
- 根节点如果不是叶子节点,则至少有两个儿子
- 每个分支节点都有k元素和k个儿子,⌈ m / 2 ⌉ <= k <= m
- 所有的叶子节点都在同一层
- 分支节点仅仅具有索引功能,它存储的元素不包含实际的值,而是其子树最大的(或最小的)关键字,仅仅是用来定位,用来索引,所有的值均存在叶子节点中
- 同一层的叶子节点构成一个升序链表,每个叶子节点里的元素也从小到大排列
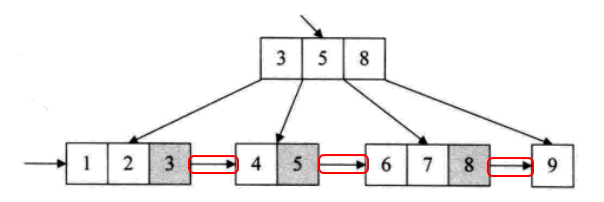
3)B+树的查找过程:

4)B+树特别适合带有范围的查找,比如查找18~22岁学生,可以从根节点出发找到第一个18岁的学生,然后在叶子层按顺序结合链表同层查找即可
5)为什么说B+树比B树更适合数据库索引:
- 基于范围的查询是非常频繁的,B+树的区间访问能力强,不用回溯到分支节点,直接在叶子节点这一层完成操作
- B+树磁盘读写的代价更低:B+树的节点少了很多指向儿子的指针,因此其节点能存放更多的关键字,那么一次性读入内存的的关键字也就越多,相对IO读写次数就降低了,效率提高
参考资料:
https://www.cnblogs.com/vincently/p/4526560.html
二叉搜索树、AVL平衡二叉搜索树、红黑树、多路查找树的更多相关文章
- 手写AVL平衡二叉搜索树
手写AVL平衡二叉搜索树 二叉搜索树的局限性 先说一下什么是二叉搜索树,二叉树每个节点只有两个节点,二叉搜索树的每个左子节点的值小于其父节点的值,每个右子节点的值大于其左子节点的值.如下图: 二叉搜索 ...
- 1.红黑树和自平衡二叉(查找)树区别 2.红黑树与B树的区别
1.红黑树和自平衡二叉(查找)树区别 1.红黑树放弃了追求完全平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单. 2.平衡 ...
- B树,B+树,红黑树应用场景AVL树,红黑树,B树,B+树,Trie树
B B+运用在file system database这类持续存储结构,同样能保持lon(n)的插入与查询,也需要额外的平衡调节.像mysql的数据库定义是可以指定B+ 索引还是hash索引. C++ ...
- AVL树、红黑树以及B树介绍
简介 首先,说一下在数据结构中为什么要引入树这种结构,在我们上篇文章中介绍的数组与链表中,可以发现,数组适合查询这种静态操作(O(1)),不合适删除与插入这种动态操作(O(n)),而链表则是适合删除与 ...
- 树:BST、AVL、红黑树、B树、B+树
我们这个专题介绍的动态查找树主要有: 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree).这四种树都具备下面几个优势: (1) 都是动态结构.在删除,插入操 ...
- 二叉查找树、平衡二叉树(AVLTree)、平衡多路查找树(B-Tree),B+树
B+树索引是B+树在数据库中的一种实现,是最常见也是数据库中使用最为频繁的一种索引. B+树中的B代表平衡(balance),而不是二叉(binary),因为B+树是从最早的平衡二叉树演化而来的. 在 ...
- AVL树,红黑树,B-B+树,Trie树原理和应用
前言:本文章来源于我在知乎上回答的一个问题 AVL树,红黑树,B树,B+树,Trie树都分别应用在哪些现实场景中? 看完后您可能会了解到这些数据结构大致的原理及为什么用在这些场景,文章并不涉及具体操作 ...
- 数据结构(一)二叉树 & avl树 & 红黑树 & B-树 & B+树 & B*树 & R树
参考文档: avl树:http://lib.csdn.net/article/datastructure/9204 avl树:http://blog.csdn.net/javazejian/artic ...
- HTTP协议漫谈 C#实现图(Graph) C#实现二叉查找树 浅谈进程同步和互斥的概念 C#实现平衡多路查找树(B树)
HTTP协议漫谈 简介 园子里已经有不少介绍HTTP的的好文章.对HTTP的一些细节介绍的比较好,所以本篇文章不会对HTTP的细节进行深究,而是从够高和更结构化的角度将HTTP协议的元素进行分类讲 ...
随机推荐
- IOS是否存在32位和64位版本的区分
苹果于2013年9月推出了iPhone 5S新手机,采用的全新A7处理器其最大特色就是支持64位运算.其64位A7处理器的使用意味着iPhone性能会大有提高,性能和速度更加出色:而要到达到这样的性能 ...
- JDBC、ODBC、OLE DB、ADO、ADOMD区别与联系
ODBC: (Open Database Connectivity,开放数据库互连),它建立了一组规范,并提供了一组对数据库访问的标准API(应用程序编程接口).这些API利用SQL来完成其大部分任务 ...
- Server2003+IIS6+TP-Link+花生壳配置
Server2003+IIS6+TP-Link+花生壳配置外网一共分四步: 固定Server2003电脑的局域网IP地址. 设置IIS网站中的TCP端口. 在TP-Link中设置转发规则. 申请花生壳 ...
- Java_10 继承
1 继承的好处 继承的出现提高了代码的复用性,提高软件开发效率. 继承的出现让类与类之间产生了关系,提供了多态的前提. 2 继承的注意事项 在Java中,类只支持单继承,不允许多继承,也就是说一个类只 ...
- Specified key was too long; max key length is 767 bytes
MySQL) )); Database changed ERROR (): Specified bytes drop table if exists test; ) primary key)chars ...
- JAVA软件安装
Java配置----JDK开发环境搭建及环境变量配置 文章来源:http://www.cnblogs.com/smyhvae/p/3788534.html Tomcat安装.配置和部署笔记 文章来源: ...
- 让 div中的div垂直居中的方法!!同样是抄袭来的(*^__^*)
同样 ,水平居中很简单,给子div设置margin:0px auto; 垂直居中也不难::给父div设置display:table-cell;vertical-align:middle; 重点是dis ...
- win10 x64中 windbg x64 安装配置符号库
根据系统安装好x64版本,我的系统是win10 x64 ; windbg下载地址 https://developer.microsoft.com/zh-cn/windows/hardware/down ...
- JAVA动手动脑及课后作业
1.查看其输出结果.如何解释这样的输出结果?从中你能总结出什么? 运行结果 true true false 原因 1)在Java中,内容相同的字串常量(“Hello”)只保存一份以节约内存,所以s0, ...
- Eclipse安装和使用windowbuilder插件开发图形界面
windowbuilder插件的安装 windowbuilder的官方网站:http://www.eclipse.org/windowbuilder/download.php 在Eclipse中 安装 ...