大数据入门第十七天——storm上游数据源 之kafka详解(一)入门与集群安装
一、概述
1.kafka是什么
根据标题可以有个概念:kafka是storm的上游数据源之一,也是一对经典的组合,就像郭德纲和于谦
根据官网:http://kafka.apache.org/intro 的解释呢,是这样的:
Apache Kafka® is a distributed streaming platform
ApacheKafka®是一个分布式流媒体平台
l Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
l Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
l Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
l Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
l 无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性
2.主要feature
1:It lets you publish and subscribe to streams of records.发布和订阅消息流,这个功能类似于消息队列,这也是kafka归类为消息队列框架的原因
2:It lets you store streams of records in a fault-tolerant way.以容错的方式记录消息流,kafka以文件的方式来存储消息流
3:It lets you process streams of records as they occur.可以再消息发布的时候进行处理
3.使用场景
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
经典组合是:kafka+storm+redis
4.消息队列补充
JMS参考基础篇ActiveMQ相关介绍:http://www.cnblogs.com/jiangbei/p/8311148.html
为什么需要消息队列:
消息系统的核心作用就是三点:解耦,异步和并行
kafka是类JMS,它吸收了JMS两种模式,将发布/订阅模式中消费者或者数据的方式从被动推送变成主动拉取
二、相关概念与组件
- Topics:一类消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
- Producers:We'll call processes that publish messages to a Kafka topic producers。
- Consumers:We'll call processes that subscribe to topics and process the feed of published messages consumers。消费组是逻辑上的一个订阅者
- Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。(相应的同个topic的不同分区,有消费者组的概念)
- Segment:partition物理上由多个segment组成。
更多详细介绍,参考:http://kafka.apache.org/intro
http://blog.csdn.net/a568078283/article/details/51464524
消息发送流程:
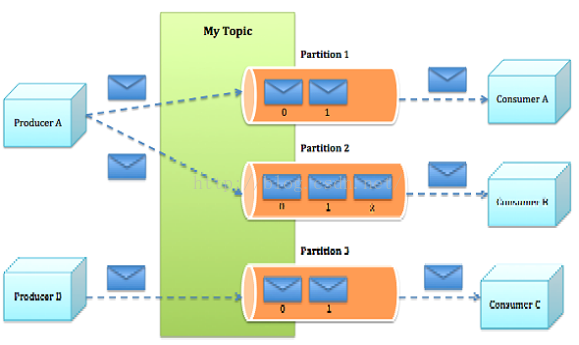
请带着以下问题思考:
分组策略
如何保证数据的完全生产 partition数量和broker的关系
每个partition数据如何保存到硬盘上
kafka有什么独特的特点(为什么它是大数据下消息队列的宠儿) 消费者如何标记消费状态
消费者负载均衡的策略
如何保证消费者消费数据是有序的
三、kafka集群安装
1.下载
这里换成一下wget,下载速度还是非常快的!
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/0.11.0.2/kafka_2.11-0.11.0.2.tgz
// 这里也可以使用windows下载完成后通过ftp进行上传(help命令进行提示),rz/sz请勿使用!属于远古时代的协议!大文件速度堪忧!
前导条件是java环境和zk,当然,新版的kafka已经内置了zk(属于可选配置了)
2.解压
tar -zxvf kafka_2.-0.11.0.2.tgz -C apps/
这里就不采用mv进行解压后目录的重命名了,采用一下创建软连接的方式!
ln -s kafka_2.-0.11.0.2/ kafka
3.修改配置文件
同样的,养成一个备份出厂设置的习惯:
[hadoop@mini1 config]$ cp server.properties server.properties.bak
此配置文件的各项说明参考:http://blog.csdn.net/lizhitao/article/details/25667831
[hadoop@mini1 config]$ vim server.properties
主要修改的配置如下:
最重要的参数为:broker.id、log.dir、zookeeper.connect
broker.id=
listeners=PLAINTEXT://192.168.137.128:9092
port=
log.dirs=home/hadoop/apps/kafka/logs
number.partition=2
zookeeper.connect=mini1:,mini2:,mini3:
// 注意listener处必须是IP!原因参考:http://blog.csdn.net/louisliaoxh/article/details/51567515
4.分发安装包
[hadoop@mini1 apps]$ scp -r kafka_2.-0.11.0.2/ mini2:/home/hadoop/apps/
[hadoop@mini1 apps]$ scp -r kafka_2.-0.11.0.2/ mini3:/home/hadoop/apps/
5.修改分发的节点配置
先依次给mini2,mini3创建软连接:
ln -s kafka_2.-0.11.0.2/ kafka
再修改配置:
修改broker.id分别是1和2(不得重复);修改监听处的IP
6.启动kafka
先启动zk(使用了自己的zk)
这里可以配置一下环境变量,可以方便后续的一些操作,并且这里配置了软连接的话是非常方便的(后续即使安装新版本,环境变量也无需变更)
模仿zk写一个一键启动脚本
#!/bin/bash BROKERS="mini1 mini2 mini3"
KAFKA_HOME="/home/hadoop/apps/kafka" for BROKER in $BROKERS
do
echo "Starting kafka on ${BROKER} ... "
ssh ${BROKER} "source /etc/profile; nohup sh ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties > /dev/null 2>&1 &"
if [[ $? -ne ]]; then
echo "Start kafka on ${BROKER} is OK !"
fi
done
kafka启动命令如下:(这里使用后台启动)
bin/kafka-server-start.sh config/server.properties &
四、相关配置
参考博文:https://www.cnblogs.com/jun1019/p/6256371.html
官网配置讲解:http://kafka.apache.org/0110/documentation.html#configuration
大数据入门第十七天——storm上游数据源 之kafka详解(一)入门与集群安装的更多相关文章
- 大数据入门第十七天——storm上游数据源 之kafka详解(二)常用命令
一.kafka常用命令 1.创建topic bin/kafka-topics. --replication-factor --zookeeper mini1: // 如果配置了PATH可以省略相关命令 ...
- 大数据入门第十七天——storm上游数据源 之kafka详解(三)其他问题
一.kafka文件存储机制 1.topic存储 在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序 ...
- 大数据入门第五天——离线计算之hadoop(上)概述与集群安装
一.概述 根据之前的凡技术必登其官网的原则,我们当然先得找到它的官网:http://hadoop.apache.org/ 1.什么是hadoop 先看官网介绍: The Apache™ Hadoop® ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- 大数据入门第十六天——流式计算之storm详解(三)集群相关进阶
一.集群提交任务流程分析 1.集群提交操作 参考:https://www.jianshu.com/p/6783f1ec2da0 2.任务分配与启动流程 参考:https://www.cnblogs.c ...
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- 大数据入门第十八天——kafka整合flume、storm
一.实时业务指标分析 1.业务 业务: 订单系统---->MQ---->Kakfa--->Storm 数据:订单编号.订单时间.支付编号.支付时间.商品编号.商家名称.商品价格.优惠 ...
- 大数据入门第十六天——流式计算之storm详解(二)常用命令与wc实例
一.常用命令 1.提交命令 提交任务命令格式:storm jar [jar路径] [拓扑包名.拓扑类名] [拓扑名称] torm jar examples/storm-starter/storm-st ...
- 大数据入门第八天——MapReduce详解(三)MR的shuffer、combiner与Yarn集群分析
/mr的combiner /mr的排序 /mr的shuffle /mr与yarn /mr运行模式 /mr实现join /mr全局图 /mr的压缩 今日提纲 一.流量汇总排序的实现 1.需求 对日志数据 ...
随机推荐
- DevExpress.XtraCharts曲线上的点所对应的坐标值
private void chartControl_ObjectSelected(object sender, HotTrackEventArgs e) { e.Cancel = false; XYD ...
- 个人理解的Lambda表达式的演化过程
之前在组内进行过相关分享,为防止以后再单独整理,故在此将自己的PPT内容存放下. 所以,多数代码都是以图片的方式展现. 委托 什么是委托? 定义:委托是方法的抽象,它存储的就是一系列具有相同签名和返回 ...
- jQuery事件和JSON点语法
<head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" ...
- 树莓派Pi2 使用入门
1. 材料和环境 树莓派Pi2, microSD卡(大于等于4G), 网线 官网下载: 系统镜像 Raspbian Jessie (https://downloads.raspberrypi.org/ ...
- C# socket 发送图片和文件
先说服务端:界面:如图: 界面设计源码 namespace SocketJPGToTxt { partial class Form1 { /// <summary> /// 必需的设计器变 ...
- 减少MySQL的Sleep进程有效方法
经常遇到很多朋友问到,他的MySQL中有很多Sleep进程,严重占用MySQL的资源,现在分析一下出现这种现象的原因和解决办法: 1,通常来说,MySQL出现大量Sleep进程是因为采用的PHP的My ...
- 转:C#常用的集合类型(ArrayList类、Stack类、Queue类、Hashtable类、Sort)
C#常用的集合类型(ArrayList类.Stack类.Queue类.Hashtable类.Sort) .ArrayList类 ArrayList类主要用于对一个数组中的元素进行各种处理.在Array ...
- python虚拟环境 -- virtualenv , virtualenvwrapper
virtualenv -- python虚拟沙盒 有人说:virtualenv.fabric 和 pip 是 pythoneer 的三大神器. 一.安装 pip install virtualenv ...
- word文档重新打开后文档结构错乱
word文档重新打开后文档结构错乱,然后通过如下方法解决了. OFFICE2007及以上. 在打开word的时候左下角会有提示word自动更新文档样式,按esc键取消,然后在大纲模式下任 ...
- DevExpress12、DocumentManager
DocumentManager控件 你用过Photoshop吗?里面每打开一个照片,就有一个小窗体承载这个照片,你可以在这些小窗体间切换,最小化.最大化.排列窗体, 这些操作都在Photoshop的大 ...