spark streaming集成kafka接收数据的方式
spark streaming是以batch的方式来消费,strom是准实时一条一条的消费。当然也可以使用trident和tick的方式来实现batch消费(官方叫做mini batch)。效率嘛,有待验证。不过这两种方式都是先把数据从kafka中读取出来,然后缓存在内存或者第三方,再定时处理。如果这时候集群退出,而偏移量又没处理好的话,数据就丢掉了。
而spark streaming提供了两种获取方式,一种是同storm一样,实时读取缓存到内存中;另一种是定时批量读取。
这两种方式分别是:
Receiver-base
Direct
下面分别介绍两种方式的实现
Receiver-base
spark streaming启动过后,会选择一台excetor作为ReceiverSupervior
1:Reciver的父级ReciverTracker分发多个job(task)到不同的executor,并启动ReciverSupervisor.
2:ReceiverSupervior会启动对应的实例reciver(kafkareciver,TwitterReceiver),并调用onstart()
3:kafkareciver在通过onstart()启动后就开启线程源源不断的接收数据,并交给ReceiverSupervior,通过ReceiverSupervior.store函数一条一条接收
4:ReceiverSupervior会调用BlockGenertor.adddata填充数据。
所有的中间数据都缓存在BlockGenertor
1:首先BlockGenertor维护了一个缓冲区,currentbuffer,一个无限长度的arraybuffer。为了防止内存撑爆,这个currentbuffer的大小可以被限制,通过设置参数spark.streaming.reciver.maxRate,以秒为单位。currentbuffer所使用的内存不是storage(负责spark计算过程中的所有存储,包括磁盘和内存),而是珍贵的计算内存。所以currentbuffer应该被限制,防止占用过多计算内存,拖慢任务计算效率,甚至有可能拖垮Executor甚至集群。
2:维护blockforpushing队列,它是等待被拉到到BlockManager的中转站。它是currentbuffer和BlockManager的中间环节。它里面的每一个元素其实就是一个currentbuffer。
3:维护两个定时器,其实就是一个生产-消费模式。blockintervaltimer定时器,负责生产端,定时将currentbuffer放进blockforpushing队列。blockforpushingthread负责消费端,定时将blockforpushing里的数据转移到BlockManager。

Direct
首先这种方式是延迟的。也就是说当action真正触发时才会去kafka里接数据。因此不存在currentbuffer的概念。它把kafka每个分区里的数据,映射为KafkaRdd的概念。题外话,在structured streaming中,也已经向DataFrame和DataSet统一了,弱化了RDD的概念。
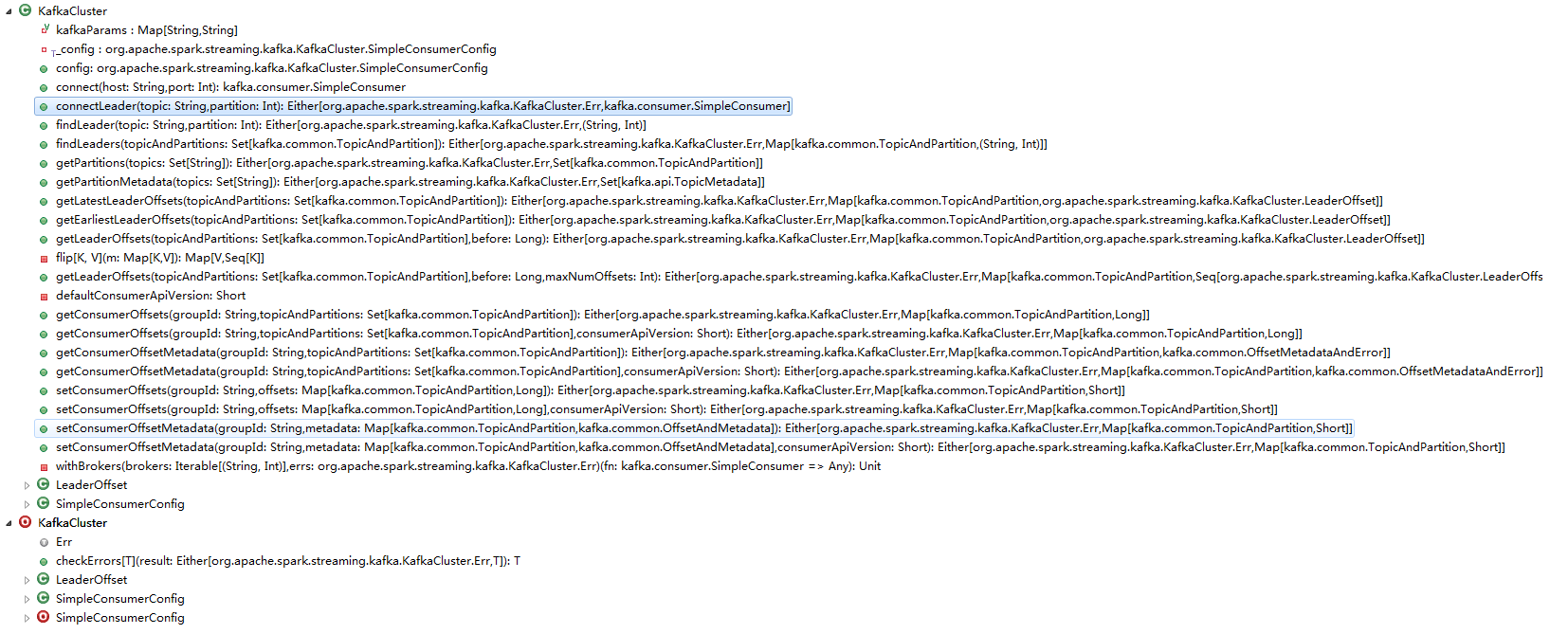
真正与kafka打交道的是KafkaCluster,全限定名: org.apache.spark.streaming.kafka.KafkaCluster。包括设备kafka各种参数,连接,获取分区,以及偏移量,设置偏移量范围等。
spark streaming集成kafka接收数据的方式的更多相关文章
- spark streaming集成kafka
Kakfa起初是由LinkedIn公司开发的一个分布式的消息系统,后成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Clouder ...
- Spark Streaming 交互 Kafka的两种方式
一.Spark Streaming连Kafka(重点) 方式一:Receiver方式连:走磁盘 使用High Level API(高阶API)实现Offset自动管理,灵活性差,处理数据时,如果某一时 ...
- Spark Streaming使用Kafka保证数据零丢失
来自: https://community.qingcloud.com/topic/344/spark-streaming使用kafka保证数据零丢失 spark streaming从1.2开始提供了 ...
- Spark Streaming连接Kafka的两种方式 direct 跟receiver 方式接收数据的区别
Receiver是使用Kafka的高层次Consumer API来实现的. Receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming ...
- 解决spark streaming集成kafka时只能读topic的其中一个分区数据的问题
1. 问题描述 我创建了一个名称为myTest的topic,该topic有三个分区,在我的应用中spark streaming以direct方式连接kakfa,但是发现只能消费一个分区的数据,多次更换 ...
- spark streaming 对接kafka记录
spark streaming 对接kafka 有两种方式: 参考: http://group.jobbole.com/15559/ http://blog.csdn.net/kwu_ganymede ...
- Spark streaming消费Kafka的正确姿势
前言 在游戏项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从kafka中不 ...
- Spark Streaming、Kafka结合Spark JDBC External DataSouces处理案例
场景:使用Spark Streaming接收Kafka发送过来的数据与关系型数据库中的表进行相关的查询操作: Kafka发送过来的数据格式为:id.name.cityId,分隔符为tab zhangs ...
- Spark Streaming之四:Spark Streaming 与 Kafka 集成分析
前言 Spark Streaming 诞生于2013年,成为Spark平台上流式处理的解决方案,同时也给大家提供除Storm 以外的另一个选择.这篇内容主要介绍Spark Streaming 数据接收 ...
随机推荐
- MyBatis与Hibernate的区别?
1.MyBatis学习成本低,Hibernate学习成本高: 2.MyBatis程序员编写SQL,Hibernate自动生成SQL:前者灵活及可优化高,后者不灵活及可优化低: 3.MyBatis适合需 ...
- mybatis-spring 集成
http://www.mybatis.org/spring/zh/index.html http://www.mybatis.org/mybatis-3/zh/java-api.html 编程API: ...
- 3. group_concat与oracle中wm_concat用法一样
例子如下: select group_concat(rp.ROLE_ID) from eic_right_role_operator rp where rp.OPERATOR_ID = #id#
- ASP.NET Core MVC 概述
https://docs.microsoft.com/zh-cn/aspnet/core/mvc/overview?view=aspnetcore-2.2 ASP.NET Core MVC 概述 20 ...
- Nginx 设置负载均衡
1. 在nginx配置文件目录下另外单独创建一个文件用于管理负载均衡配置,这里起名为 fzjh.conf vim /etc/nginx/fzjh.conf #在文件下添加以下内容 upstream m ...
- js乱码问题解决
乱码有可能出现在下面两种情况 1.高级浏览器直接访问js路径 2.jsp引用js 针对上述两种情况的解决方式: 1.查看设置浏览器的字符集 2.查看web服务器的字符集,比如Tomcat 配置UTF- ...
- 爬虫--Scrapy-持久化存储操作2
1.管道的高级操作 将爬取到的数据值分别存储到本地磁盘.redis数据库.mysql数据. 需求:将爬取到的数据值分别存储到本地磁盘.redis数据库.mysql数据. 1.需要在管道文件中编写对应平 ...
- APP-8.2-Postman应用
用户在开发或者调试网络程序或者是网页B/S模式的程序的时候是需要一些方法来跟踪网页请求的,用户可以使用一些网络的监视工具比如著名的Firebug等网页调试工具.今天给大家介绍的这款网页调试工具不仅可以 ...
- Model操作补充
参考: http://www.cnblogs.com/wupeiqi/articles/6216618.html
- 黑马2018年JavaEE课程大纲
包含 黑马旅游网 企业级权限管理系统 品优购 十次方 乐优(没有,十次方级别) http://www.itheima.com/course/javaeetext.html 传智 ...